关于如何避免时间序列预测机器学习方法中
方法论错误的案例研究。
在时间序列预测问题中评估机器学习模型具有挑战性。
在问题构建或模型评估中很容易犯小错误,这些错误可能会产生令人印象深刻的结果,但却导致无效的发现。
一个有趣的时间序列分类问题是仅根据脑电波数据(EEG)预测受试者的眼睛是睁开还是闭合。
在本教程中,您将了解根据脑电波预测眼睛睁闭状态的问题,以及在评估时间序列预测模型时常见的 методологической 陷阱。
通过本教程的学习,您将了解如何在评估时间序列预测问题中的机器学习算法时避免常见陷阱。这些陷阱既困扰初学者,也困扰专家从业者和学者。
完成本教程后,您将了解:
- 眼部状态预测问题以及您可以使用的标准机器学习数据集。
- 如何在 Python 中重现从脑电波预测眼部状态的熟练结果。
- 如何揭示评估预测模型中一个有趣的方法论缺陷。
通过我的新书《时间序列预测深度学习》**开启您的项目**,其中包括**逐步教程**和所有示例的**Python 源代码文件**。
让我们开始吧。
教程概述
本教程分为七个部分,它们是:
- 根据脑电波预测眼睛睁开/闭合
- 数据可视化和去除异常值
- 开发预测模型
- 模型评估方法的问题
- 带时间顺序的训练-测试分割
- 逐时验证
- 要点和关键教训
根据脑电波预测眼睛睁开/闭合
在这篇文章中,我们将仔细研究一个根据脑电波数据预测受试者眼睛是睁开还是闭合的问题。
该问题由 Oliver Rosler 和 David Suendermann 在他们 2013 年的论文《使用脑电图预测眼部状态的第一步》中描述并收集了数据。
我看到这个数据集后,就想了解更多。
具体来说,对一个人进行了 117 秒(不到两分钟)的脑电图 (EEG) 记录,期间受试者睁开和闭合眼睛,并通过摄像机记录下来。然后,根据脑电图轨迹中的每个时间步手动记录睁开/闭合状态。
脑电图是使用 Emotiv EEG Neuroheadset 记录的,产生了 14 条轨迹。
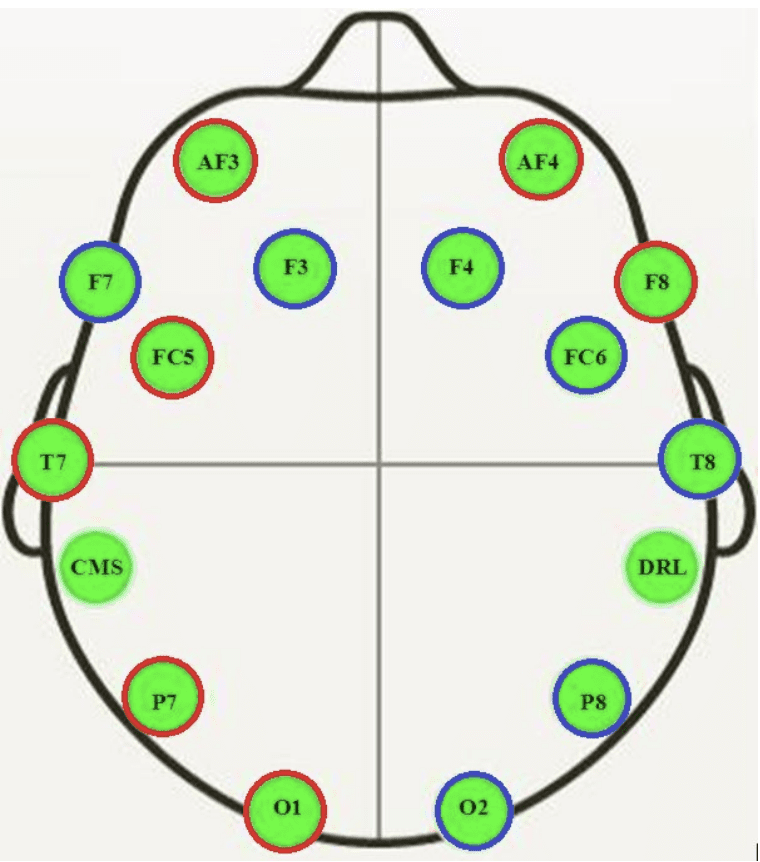
脑电图传感器在受试者头部的卡通图
摘自《使用脑电图预测眼部状态的第一步》,2013年。
输出变量是二进制的,这意味着这是一个二分类问题。
在 117 秒内共进行了 14,980 次观测(行),这意味着每秒大约有 128 次观测。
该语料库包含 14,977 个实例,每个实例有 15 个属性(14 个属性表示电极值和眼部状态)。实例按时间顺序存储在语料库中,以便分析时间依赖性。语料库中 8,255 个实例(55.12%)对应于眼睛睁开状态,6,722 个实例(44.88%)对应于眼睛闭合状态。
- 使用脑电图预测眼部状态的第一步, 2013.
还有一些脑电图观测值的幅度远高于预期。这些很可能是异常值,可以通过简单的统计方法识别和去除,例如删除观测值与平均值相差 3 到 4 个标准差的行。
最简单的问题框架是根据当前时间步的脑电图轨迹预测眼部状态(睁开/闭合),忽略轨迹信息。更高级的问题框架可能旨在对每个脑电图轨迹的多变量时间序列进行建模,以预测当前的眼部状态。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据可视化和去除异常值
该数据集可从 UCI 机器学习库免费下载
原始数据为 ARFF 格式(Weka 中使用),但可以通过删除 ARFF 头部转换为 CSV 格式。
下面是删除 ARFF 头部后的数据前五行的示例。
|
1 2 3 4 5 6 |
4329.23,4009.23,4289.23,4148.21,4350.26,4586.15,4096.92,4641.03,4222.05,4238.46,4211.28,4280.51,4635.9,4393.85,0 4324.62,4004.62,4293.85,4148.72,4342.05,4586.67,4097.44,4638.97,4210.77,4226.67,4207.69,4279.49,4632.82,4384.1,0 4327.69,4006.67,4295.38,4156.41,4336.92,4583.59,4096.92,4630.26,4207.69,4222.05,4206.67,4282.05,4628.72,4389.23,0 4328.72,4011.79,4296.41,4155.9,4343.59,4582.56,4097.44,4630.77,4217.44,4235.38,4210.77,4287.69,4632.31,4396.41,0 4326.15,4011.79,4292.31,4151.28,4347.69,4586.67,4095.9,4627.69,4210.77,4244.1,4212.82,4288.21,4632.82,4398.46,0 ... |
我们可以将数据加载为 DataFrame,并绘制每个 EEG 轨迹和输出变量(开/闭状态)的时间序列。
完整的代码示例如下所示。
此示例假定您在与代码相同的目录中有一个 CSV 格式的数据集副本,文件名为“*EEG_Eye_State.csv*”。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 可视化数据集 from pandas import read_csv from matplotlib import pyplot # 加载数据集 data = read_csv('EEG_Eye_State.csv', header=None) # 将数据检索为 NumPy 数组 values = data.values # 为每个时间序列创建一个子图 pyplot.figure() for i in range(values.shape[1]): pyplot.subplot(values.shape[1], 1, i+1) pyplot.plot(values[:, i]) pyplot.show() |
运行示例将为每个脑电图轨迹和输出变量创建一个折线图。
我们可以看到异常值冲刷掉了每个轨迹中的数据。我们还可以看到眼睛随着时间的推移的睁开/闭合状态,分别为 0/1。
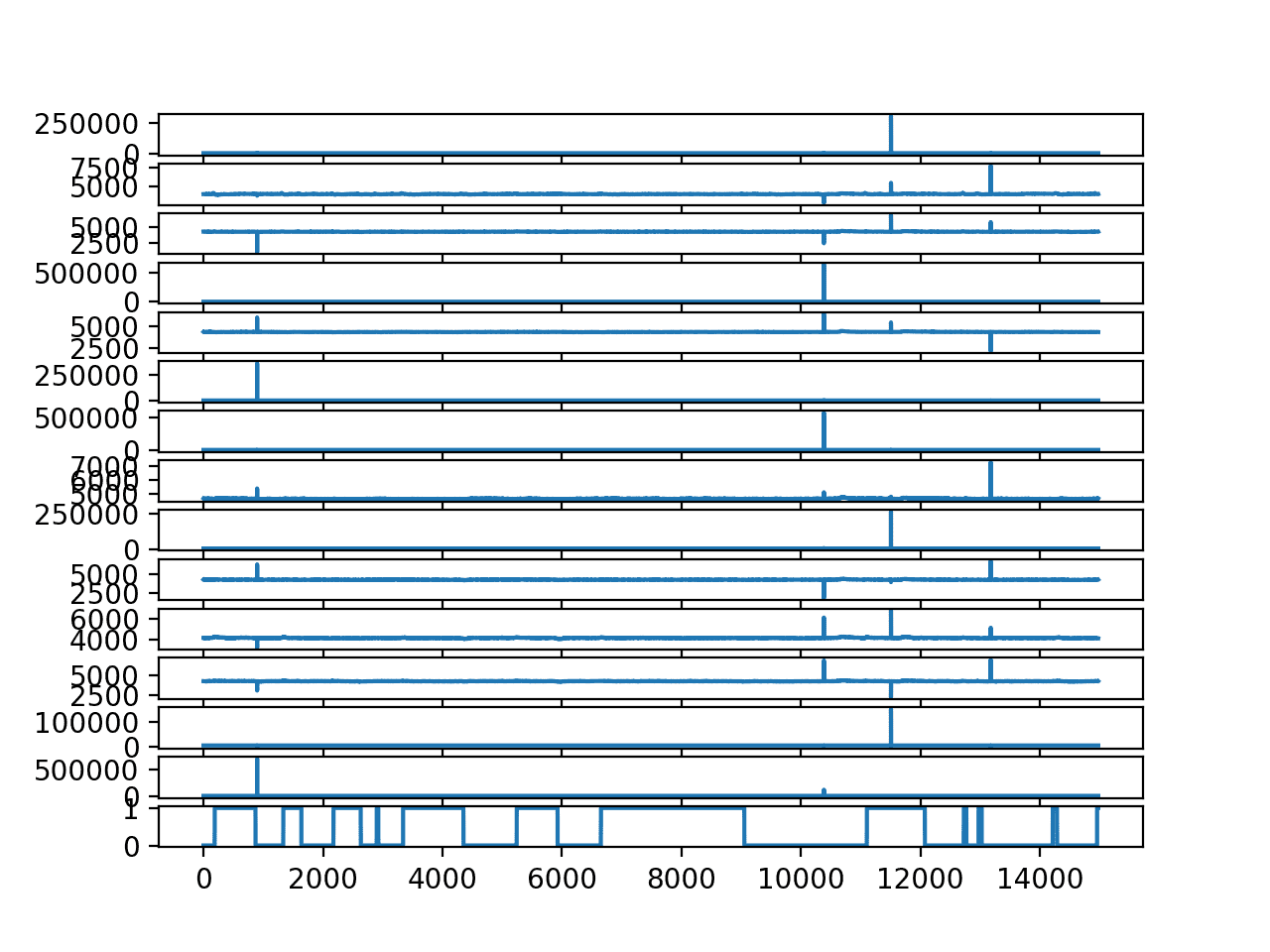
每个脑电图轨迹和输出变量的折线图
去除异常值有助于更好地理解脑电图轨迹与眼睛开闭状态之间的关系。
下面的示例删除了所有脑电图观测值与平均值相差四个或更多标准差的行。数据集保存到一个名为“*EEG_Eye_State_no_outliers.csv*”的新文件中。
这是一种快速粗糙的异常值检测和去除实现,但能完成任务。我相信您可以设计出更高效的实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 从脑电图数据中移除异常值 from pandas import read_csv from numpy import mean from numpy import std from numpy import delete from numpy import savetxt # 加载数据集。 data = read_csv('EEG_Eye_State.csv', header=None) values = data.values # 遍历每个脑电图列 for i in range(values.shape[1] - 1): # 计算列均值和标准差 data_mean, data_std = mean(values[:,i]), std(values[:,i]) # 定义异常值边界 cut_off = data_std * 4 lower, upper = data_mean - cut_off, data_mean + cut_off # 移除过小值 too_small = [j for j in range(values.shape[0]) if values[j,i] < lower] values = delete(values, too_small, 0) print('>deleted %d rows' % len(too_small)) # 移除过大值 too_large = [j for j in range(values.shape[0]) if values[j,i] > upper] values = delete(values, too_large, 0) print('>deleted %d rows' % len(too_large)) # 将结果保存到新文件 savetxt('EEG_Eye_State_no_outliers.csv', values, delimiter=',') |
运行示例会总结在处理脑电图数据中每个列的异常值时删除的行数(高于和低于平均值)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
>已删除 0 行 >已删除 1 行 >已删除 2 行 >已删除 1 行 >已删除 0 行 >已删除 142 行 >已删除 0 行 >已删除 48 行 >已删除 0 行 >已删除 153 行 >已删除 0 行 >已删除 43 行 >已删除 0 行 >已删除 0 行 >已删除 0 行 >已删除 15 行 >已删除 0 行 >已删除 5 行 >已删除 10 行 >已删除 0 行 >已删除 21 行 >已删除 53 行 >已删除 0 行 >已删除 12 行 >已删除 58 行 >已删除 53 行 >已删除 0 行 >已删除 59 行 |
现在,我们可以通过加载新的“*EEG_Eye_State_no_outliers.csv*”文件来可视化没有异常值的数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 可视化无异常值的数据集 from pandas import read_csv from matplotlib import pyplot # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) # 将数据检索为 NumPy 数组 values = data.values # 为每个时间序列创建一个子图 pyplot.figure() for i in range(values.shape[1]): pyplot.subplot(values.shape[1], 1, i+1) pyplot.plot(values[:, i]) pyplot.show() |
运行示例会创建一个更好的图,清楚地显示当眼睛闭合时(1)出现小的正峰,当眼睛睁开时(0)出现负峰。
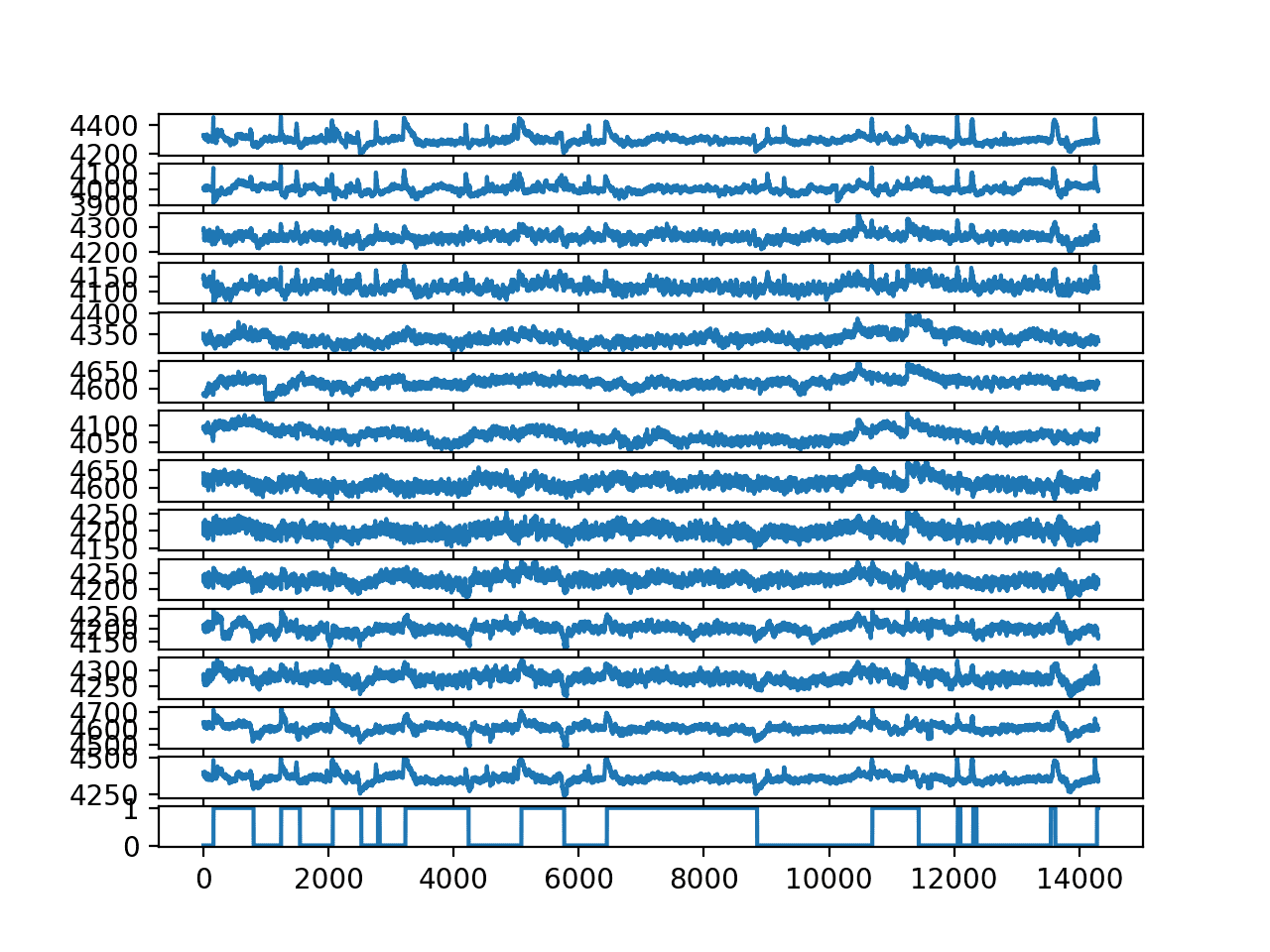
每个脑电图轨迹和输出变量的折线图(无异常值)
开发预测模型
最简单的预测模型是根据当前的脑电图观测值预测眼睛开闭状态,忽略轨迹信息。
直观上,人们不会期望这种方法有效,然而,Rosler 和 Suendermann 在 2013 年的论文中却使用了这种方法。
具体来说,他们使用 10 倍交叉验证对 Weka 软件中的大量分类算法进行了评估,解决了这个问题的框架。他们使用多种方法,包括基于实例的方法(如 k 近邻和 KStar),实现了超过 90% 的准确率。
然而,像 IB1 和 KStar 这样的基于实例的学习器再次显著优于决策树。后者取得了明显最佳的性能,分类错误率仅为 3.2%。
—— 使用脑电图预测眼部状态的第一步,2013年。
在许多其他论文中,使用相同和相似的数据集也采用了类似的方法和发现。
我读到这些时很惊讶,所以重现了结果。
完整的示例列出了 k=3 KNN。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import KFold from sklearn.neighbors import KNeighborsClassifier from numpy import mean # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 使用 10 折交叉验证评估 KNN scores = list() kfold = KFold(10, shuffle=True, random_state=1) for train_ix, test_ix in kfold.split(values): # 定义训练/测试 X/y trainX, trainy = values[train_ix, :-1], values[train_ix, -1] testX, testy = values[test_ix, :-1], values[test_ix, -1] # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估预测结果 score = accuracy_score(testy, yhat) # 存储 scores.append(score) print('>%.3f' % score) # 计算每次运行的平均分数 print('最终得分: %.3f' % (mean(scores))) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例会打印交叉验证每个折叠的分数,以及所有 10 个折叠平均得分为 97% 的平均分数。
|
1 2 3 4 5 6 7 8 9 10 11 |
>0.970 >0.975 >0.978 >0.977 >0.973 >0.979 >0.978 >0.976 >0.974 >0.969 最终分数:0.975 |
非常令人印象深刻!
但总觉得有些不对劲。
我很有兴趣看看那些考虑了数据在开到闭和闭到开转换时明显峰值的模型表现如何。
我尝试的所有模型,只要它们尊重数据的时序性,表现都差很多。
为什么?
提示:思考所选的模型评估策略和表现最佳的算法类型。
模型评估方法的问题
**免责声明**:我并非指责该论文或相关论文的作者。我不在乎。根据我的经验,大多数已发表的论文都无法重现或存在严重的方法论缺陷(包括我写过的很多东西)。我只对学习和教学感兴趣。
时间序列模型评估方法存在缺陷。
我曾告诫人们不要犯这个错误,但在阅读论文并重现结果后,我还是被它绊倒了。
希望通过这个示例,它能帮助您在自己的预测问题中避免类似错误。
模型评估中的方法论缺陷在于使用了 k 折交叉验证。具体来说,模型的评估方式没有尊重观测值的时间顺序。
解决这个问题的关键是发现基于实例的方法,例如 k 近邻,在解决该问题时表现出色。KNN 将在数据集中寻找 *k* 个最相似的行,并计算输出状态的众数作为预测值。
在评估模型时不尊重实例的时间顺序,这使得模型可以在进行预测时使用来自未来的信息。这在 KNN 算法中尤其明显。
由于观测频率高(每秒 128 次),最相似的行将是与被预测实例在时间上相邻的行,包括过去和未来。
我们可以通过一些小实验来阐明这一点。
带时间顺序的训练-测试分割
我们可以做的第一个测试是评估 KNN 模型在数据集打乱和未打乱两种情况下的训练/测试分割技能。
如果数据在分割前被打乱,我们预期结果将与上一节中的交叉验证结果相似,特别是如果测试集占数据集的 10%。
如果关于时间顺序重要性以及基于实例的方法利用未来相邻示例的理论是正确的,我们预期在分割前未打乱数据集的测试结果会更差。
首先,下面的示例将数据集按 90%/10% 的比例分割为训练/测试集。数据集在分割前进行了打乱。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.1, shuffle=True, random_state=1) # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估预测 score = accuracy_score(testy, yhat) print(score) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例后,我们可以看到,其技能确实与我们在交叉验证示例中看到的相似,或接近,准确率为 96%。
|
1 |
0.9699510831586303 |
接下来,我们重复实验,但在分割前不打乱数据集。
这意味着训练数据是按时间顺序排列的前 90% 的数据,而测试数据是后 10% 的数据,大约 1400 个观测值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.1, shuffle=False, random_state=1) # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估预测 score = accuracy_score(testy, yhat) print(score) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例显示模型技能差很多,只有 52%。
|
1 |
0.5269042627533194 |
这是一个好的开始,但并非决定性的。
考虑到我们在结果变量图中可以看到的非常短的开/关间隔,数据集的最后 10% 可能很难预测。
我们可以重复实验,使用前 10% 的数据作为测试集,后 90% 作为训练集。我们可以通过使用 flip() 函数在分割数据之前反转行的顺序来做到这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from numpy import flip # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 颠倒行的顺序 values = flip(values, 0) # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.1, shuffle=False, random_state=1) # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集上拟合模型 model.fit(trainX, trainy) # 预测测试集 yhat = model.predict(testX) # 评估预测 score = accuracy_score(testy, yhat) print(score) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行实验产生了相似的结果,准确率约为 52%。
这提供了更多证据,表明并非特定连续观测块导致模型技能不佳。
|
1 |
0.5290006988120196 |
看来需要立即相邻的观测值才能做出良好的预测。
逐时验证
模型可能需要过去(而非未来)的相邻观测值才能做出熟练的预测。
这听起来一开始合理,但也有问题。
然而,我们可以通过对测试集进行逐时验证来实现这一点。这允许模型在预测每个新时间步时使用所有先前的观测值,因为我们在测试数据集中的每个新时间步都验证一个新模型。
有关逐时验证的更多信息,请参阅帖子
下面的示例评估了 KNN 在数据集最后 10%(约 10 秒)上使用逐时验证的技能,同时尊重时间顺序。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from numpy import array # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.1, shuffle=False, random_state=1) # 步进验证 historyX, historyy = [x for x in trainX], [x for x in trainy] predictions = list() for i in range(len(testy)): # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集上拟合模型 model.fit(array(historyX), array(historyy)) # 预测下一个时间步 yhat = model.predict([testX[i, :]])[0] # 存储预测结果 predictions.append(yhat) # 将真实观测值添加到历史记录 historyX.append(testX[i, :]) historyy.append(testy[i]) # 评估预测 score = accuracy_score(testy, predictions) print(score) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例给出了令人印象深刻的模型技能,准确率约为 95%。
|
1 |
0.9531795946890287 |
我们可以进一步推动这项测试,只允许模型在做出预测时使用前 10 个观测值。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 用于预测眼部状态的 KNN from pandas import read_csv from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from numpy import array # 加载数据集 data = read_csv('EEG_Eye_State_no_outliers.csv', header=None) values = data.values # 将数据拆分为输入和输出 X, y = values[:, :-1], values[:, -1] # 分割数据集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.1, shuffle=False, random_state=1) # 步进验证 historyX, historyy = [x for x in trainX], [x for x in trainy] predictions = list() for i in range(len(testy)): # 定义模型 model = KNeighborsClassifier(n_neighbors=3) # 在训练集的一个小 subset 上拟合模型 tmpX, tmpy = array(historyX)[-10:,:], array(historyy)[-10:] model.fit(tmpX, tmpy) # 预测下一个时间步 yhat = model.predict([testX[i, :]])[0] # 存储预测结果 predictions.append(yhat) # 将真实观测值添加到历史记录 historyX.append(testX[i, :]) historyy.append(testy[i]) # 评估预测 score = accuracy_score(testy, predictions) print(score) |
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
运行示例后,模型技能进一步提高,准确率接近 99%。
我预计唯一的错误是脑电图序列在从开到闭或从闭到开的转折点处发生的错误,这是问题的真正难点。这方面需要进一步调查。
|
1 |
0.9923130677847659 |
的确,我们已经证实模型需要相邻观测值及其结果才能进行预测,并且仅凭过去的相邻观测值,而非未来的观测值,它就能做得非常好。
这很有趣。但这个发现并没有实际用处。
如果部署这个模型,它需要模型知道最近过去(例如前 1/128 秒)的眼睛开闭状态。
这将不可用。
根据脑电波预测眼睛状态的整个模型理念是让它在没有这种确认的情况下运行。
要点和关键教训
让我们回顾一下我们目前学到的知识
1. 模型评估方法必须考虑观测值的时间顺序。
这意味着使用不按时间分层(例如,打乱或随机选择行)的 k 折交叉验证在方法论上是无效的。
这也意味着在分割前打乱数据的训练/测试分割在方法论上是无效的。
我们从使用 k 折交叉验证和打乱训练/测试分割的模型的高技能评估中看到了这一点,与在预测时无法获得直接相邻时间观测值时的模型低技能形成了对比。
2. 模型评估方法必须对最终模型的使用有意义。
这意味着即使您使用了一种尊重观测时间顺序的方法,模型也应该只拥有在实际使用该模型时可用的信息。
我们看到,在逐时验证方法下,模型表现出高技能,该方法尊重观测顺序,但提供了诸如眼部状态之类的信息,而这些信息在模型实际使用时是不可用的。
关键在于,从最终模型的使用角度来构建问题,并反推哪些数据可用,以及如何在该框架下评估模型,使其仅在可用的信息下运行。
当您试图理解他人的工作时,这一点尤其重要。
展望未来
希望这能帮助您,无论是在评估自己的预测模型还是评估他人的模型时。
那么,如果给你原始数据,你会如何处理这个问题呢?
我认为解决这个问题的关键是脑电图数据中,当眼睛从睁开到闭合或从闭合到睁开转换时出现的明显正/负峰值。我期望一个有效的模型会利用这个特征,也许使用半秒或类似的先前的脑电图观测值。
这甚至可能只需单条轨迹,而非 15 条,并且使用信号处理中的简单峰值检测方法,而非机器学习方法即可实现。
如果你尝试了,请告诉我;我很想知道你的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 脑电图眼部状态数据集,UCI 机器学习库
- 使用脑电图预测眼部状态的第一步, 2013.
- 使用时间序列分类的增量属性学习进行脑电图眼部状态识别, 2014.
总结
在本教程中,您了解了根据脑电波预测眼睛睁开或闭合的问题,以及在评估时间序列预测模型时常见的方法论陷阱。
具体来说,你学到了:
- 眼部状态预测问题以及您可以使用的标准机器学习数据集。
- 如何在 Python 中重现从脑电波预测眼部状态的熟练结果。
- 如何揭示评估预测模型中一个有趣的方法论缺陷。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。
")





嗨,Jason,
感谢这篇精彩的案例研究!
我希望您将来能处理更细微的案例。
祝好,
Elie
谢谢。
我可能看错了,但在您提到准确率超过 99% 并查看过去眼部状态的示例中,您的模型不就是学习到当前状态最可能是过去状态,因为眼睛开闭的频率非常慢吗?
是的,我相信是这样。
这更多是关于不仔细思考方法论的危险。
谢谢!很棒的文章!
谢谢 Tony。
关于机器学习和评估陷阱的精彩文章!!!
请给我们更多这样的分析,让我们从错误中学习。
谢谢。很高兴它有帮助。
您尝试过对股市进行时间序列预测吗?希望了解更多金融话题!
我尽量避免金融应用,这个话题的感情色彩太浓了。
在您的数据清洗中,您可能应该使用与中位数之间的标准差,因为与平均值之间的偏差本身就存在偏差,因为异常值会使平均值发生偏移。这可能不会产生太大影响,但我使用了这段代码
filtered = data[data.apply(lambda x: np.abs(x - x.median()) / x.std() < 4).all(axis=1)]
我使用了两层有状态 LSTM,得到了 99% 的准确率,可能是因为过拟合(它预测了一个常数输出)。比我更擅长 LSTM 的人可能会解决我的方法。
如果数据更多就好了。
我的代码在这里:https://gist.github.com/JonnoFTW/f94f8d97e57f6796da83b834ce66aa45
非常棒,Jonathan!
了不起的工作。
谢谢。
你好 Jason,
请您帮我澄清一下下面这行代码的疑问吗?
“在 117 秒内共进行了 14,980 次观测(行),这意味着每秒大约有 128 次观测。”
一秒钟内怎么能进行 128 次观测呢?一次观测是什么意思?
我的理解是,一次观测是指一个人使用 14 个(输入属性)脑电图传感器记录的眼睛睁开或闭合状态,对吗?
那么 117 秒,难道不应该是一个人每秒 117 次观测吗?
一次观测就是一次脑电波测量。
14980/117 ≈ 每秒 128.03 次观测。
一如既往的棒!谢谢你 Jason。你对变量大小的情况有什么想法吗?
也许这会有帮助。
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
你好,
我收到以下错误
yhat = model.predict(test_inputs_tf)
102
–> 103 score = accuracy_score(test_output_tf, yhat,normalize=False)
104
105
/usr/local/lib/python2.7/dist-packages/sklearn/metrics/classification.pyc in accuracy_score(y_true, y_pred, normalize, sample_weight)
174
175 # 计算每个可能表示的准确性
–> 176 y_type, y_true, y_pred = _check_targets(y_true, y_pred)
177 if y_type.startswith(‘multilabel’)
178 differing_labels = count_nonzero(y_true – y_pred, axis=1)
/usr/local/lib/python2.7/dist-packages/sklearn/metrics/classification.pyc in _check_targets(y_true, y_pred)
86 # 不支持“多分类-多输出”格式的指标
87 if (y_type not in [“binary”, “multiclass”, “multilabel-indicator”])
—> 88 raise ValueError(“{0} 不受支持”.format(y_type))
89
90 if y_type in [“binary”, “multiclass”]
ValueError: 未知类型不受支持
其中 test_output_tf 是我的 testy。有什么解决这个问题的建议吗?
这很令人惊讶,我这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好杰森
很棒的教程。谢谢你的工作!
以下是我的评论,如果对任何人有用的话
1) 我喜欢这个分析 14 个脑电图信号(即使它们是模拟的(我们必须先采样))并获得一些输出事实(眼睛睁开或闭合)的教程:因为我认为有很多问题涉及到记录许多与状态标签(例如医疗保健)相关的信号,这些问题可以受益于这种时间序列方法
2) 在从原始 CSV 文件中删除异常值的过程中,我使用了“numpy.where()”函数(如果值高于或低于行的特定上限或下限信号值用于异常值识别)。我清理了 676 行。我认为这比使用“for in … 循环”更快。
3) 我对可逆性预测的使用感到惊讶,即您从先前的训练数据(正常情况)预测未来的测试值,以及当您反向操作从未来的训练值预测先前的测试值时。恰好在您的教程中使用“numpy.flip”函数反转行时间顺序的时候。
我很难接受它,因为有多种物理现象,如熵不可逆性、相同效应的不同原因等。我很高兴我们能做到这一点,但我仍然感到有点“不自信”。
4) 这是我第一次在几个教程之后清楚地理解“逐时验证”(我认为这个奇怪的术语来自金融分析),它指的是每次进行新预测时,通过新的测试数据更新训练集。令人印象深刻的是分数是如何提高的!
5) 关于真实的开眼闭眼数据集脑电图轨迹,当信号突然(急剧)变化时,就是眼睛状态发生变化的时候,所以如果你知道之前的状态(标签),我猜这就像改变新测试向前预测的标签状态一样简单。
当然,也感谢您分享了关于这篇原始论文在带有洗牌的训练中犯了一些错误,这些错误将未来的数据引入了输入先前的训练数据,从而使结果失效和造假……当然,我也认同您的工作目标,即“……学习和教学”,这非常诚实!
谢谢,非常感谢。
一如既往的富有洞察力的评论和反馈!
了不起的工作…太棒了…我希望你能提供关于使用PPIN进行蛋白质功能预测的信息或材料
感谢您的建议。
你好 Jason Brownlee
极好的解释。
很棒。
情况1:在交叉折叠验证中,我们有十个(10)模型
情况2:在训练测试分割中,我们有一个模型。
情况3:在这里,在这项工作(即,带逐时验证的训练测试分割)中,我们有“len(testy)”(即1431)个模型。
所有这些情况“逐时验证”都提供了最佳性能。
这里我的疑问是:除了训练测试分割(情况2)之外,所有剩余情况(即情况1和2)都有多个模型。
在这些模型中,哪个模型最适合保存以供进一步操作。
也就是说,最适合用于嵌入式系统以预测其他数据的模型。
我们正在测试模型构建过程,而不是任何给定的模型。
如果您想要一个单一模型,那么您必须构建一个测试工具来精确评估它。
很棒的文章,当我查看准确率达 99% 的模型的分类报告时,我只能看到一个类别,它没有显示另一个类别
抱歉,我不知道您可能对示例做了哪些更改。
考虑到数据高度不平衡,我预计分类报告可能不适用。
你好,我正在使用这个数据库,你能帮我解决 1D CNN 的输入形状问题吗?我不知道如何更改这个数据库,确切地说,我不知道我需要更改什么。
我不建议使用这个数据集,或许可以查看文章的最后一节。
不过,本教程将向您展示如何使用 1D CNN 处理时间序列
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
很棒的文章,
想了解一些关于未来可能的工作
谢谢!
你好 Jason,一如既往的精彩文章。但这让我好奇,如果我们添加一些偏移列,例如 t-1、t-2、t-3 的变量,上述方法是否仍然适用?
我正在尝试将其应用于预测性维护问题,即传感器在一段时间内提供读数,并对给定机器在一段时间内是否发生故障进行分类。
任何指导都将不胜感激,谢谢!
当然,这个方法仍然适用。但这是否有帮助是另一个问题。一般来说,如果历史存在某种依赖性或轨迹(例如天气预报),这会有帮助;但如果不存在(例如彩票以往的中奖结果),那只会是噪音并会混淆模型。
您能否告知我此代码是否
1. 对每个脑电图轨迹的多变量时间序列进行建模,以预测当前的眼部状态。
2. 预测模型是基于当前的脑电图观察,同时也考虑了轨迹信息来预测眼睛睁开/闭合状态。
先谢谢您了。
你好 Anna…请澄清你的问题,以便我们更好地帮助你。
你好,你能解释一下它是如何工作的吗?
在 model.fit(trainX, trainy) 中,trainX 的形状是 – (12873, 15)
看起来在训练模型中,你每次传输一行,包含15个EEG值。
我认为最好将15个通道的数据传输到模型,但每个通道都有几秒钟的测量数据,
所以 trainX 数据的形状将是 (128, 15, 100),这是否正确?
你好 Ron…请按照你的想法继续,并告诉我们你的发现。
非常感谢这篇精彩的文章。我有一些问题。请指导我。你对主要的原始数据进行了分类。是真的吗?我们没有任何关于预处理的信息吗?数据是否经过预处理然后保存为CSV格式?是否使用了带通滤波等等……
另一个问题是关于特征的。为什么你没有提取一些统计和频段特征进行分类?为什么你直接对主要数据进行分类?
我逐一重新实现了你的代码,并在提供的数据上得到了相同的结果。但是当我在我们实验室收集的数据上应用它时,我无法获得高准确性和分数?我不知道原因?我们以500的采样频率在两个通道上记录信号,进行4次试验(睁眼/闭眼)。每次试验持续一分钟。
你好 Nima…听起来你正在探索基于脑电图的分类来预测眼睛状态(睁眼/闭眼)。让我澄清一下你问题中的几点。
1. **预处理和原始数据**:如果原始代码/分类是直接在原始数据上执行的,没有明确提及预处理,那么需要注意的是,预处理(如带通滤波或噪声去除)是大多数脑电图分析中的关键步骤。如果没有滤波,原始数据可能包含噪声或不需要的频率成分,这会降低分类性能。如果未提及预处理,则可能在将数据保存为CSV格式之前已经完成,可能包括带通滤波、基线校正或伪影去除。你可以尝试对感兴趣的频率范围(例如,EEG数据的0.5-30 Hz)应用**带通滤波器**,以减少噪声并隔离相关的信号特征。
2. **特征提取**:在你的案例中,原始方法可能没有提取特定的统计或频率特征,这有时也可能奏效,但EEG数据通常受益于特征提取。频域特征,如特定频段(delta、theta、alpha、beta等)的**功率谱密度**(PSD),以及统计特征,如**均值、方差、偏度**或熵,通常能提高分类性能。仅使用原始数据可能会错过这些重要特性,你可以尝试提取这些特征并将其用作分类器的输入。
3. **实验室数据性能差异**:你的实验室数据观察到的较低准确性可能是由于数据质量、噪声水平或与提供数据集相比记录设置的微小差异。你可以尝试以下方法:
– **预处理**:对你的EEG数据应用带通滤波(例如,0.5-30 Hz)和陷波滤波以去除工频噪声(例如,50/60 Hz)。
– **特征提取**:从你的数据中提取统计和频域特征(如PSD、频带功率)。
– **模型调优**:检查模型超参数是否需要针对你的特定数据进行调整。
– **数据增强**:由于你的数据相对有限(2个通道,4次试验),你可以考虑进行数据增强或尽可能尝试从类似的预训练模型进行迁移学习。
如果你能分享更多关于你的模型架构的细节,我可以提供更有针对性的改进性能的建议。