激活正则化提供了一种鼓励神经网络学习稀疏特征或原始观测内部表示的方法。
在自编码器中(称为稀疏自编码器)以及编码器-解码器模型中,通常会寻求稀疏的学习表示,尽管这种方法也可以广泛用于减少过拟合并提高模型对新观测的泛化能力。
在本教程中,您将学习 Keras API,了解如何将激活正则化添加到深度学习神经网络模型中。
完成本教程后,您将了解:
- 如何使用 Keras API 创建向量范数正则化器。
- 如何使用 Keras API 将激活正则化添加到 MLP、CNN 和 RNN 层。
- 如何通过向现有模型添加激活正则化来减少过拟合。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何在 Keras 中使用激活正则化减少深度神经网络中的泛化误差
图片来源:Johan Neven,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Keras 中的激活正则化
- 层上的激活正则化
- 激活正则化案例研究
Keras 中的激活正则化
Keras 支持激活正则化。
支持三种不同的正则化技术,每种技术都在 keras.regularizers 模块中作为类提供
- l1:激活量计算为绝对值之和。
- l2:激活量计算为平方值之和。
- l1_l2:激活量计算为绝对值之和与平方值之和。
每个 l1 和 l2 正则化器都带有一个超参数,用于控制每个激活量对总和的贡献量。l1_l2 正则化器带有两个超参数,一个用于 l1 方法,一个用于 l2 方法。
必须导入并实例化正则化器类;例如
|
1 2 3 4 |
# 导入正则化器 from keras.regularizers import l1 # 实例化正则化器 reg = l1(0.001) |
层上的激活正则化
激活正则化在 Keras 的层上指定。
这可以通过将层的 activity_regularizer 参数设置为实例化并配置的正则化器类来实现。
正则化器应用于层的输出,但您可以控制层的“输出”实际意味着什么。具体来说,您可以灵活选择正则化是应用于“激活”函数之前还是之后。
例如,您可以在层上指定函数和正则化,在这种情况下,激活正则化应用于激活函数的输出,在本例中为修正线性激活函数或 ReLU。
|
1 2 3 |
... model.add(Dense(32, activation='relu', activity_regularizer=l1(0.001))) ... |
或者,您可以指定一个线性激活函数(默认情况下,不执行任何变换),这意味着激活正则化应用于原始输出,然后,激活函数可以作为后续层添加。
|
1 2 3 4 |
... model.add(Dense(32, activation='linear', activity_regularizer=l1(0.001))) model.add(Activation('relu')) ... |
后者可能是在“深度稀疏修正神经网络”中所述的激活正则化的首选用法,以便模型能够学习结合修正线性激活函数将激活值设置为真正的零值。尽管如此,可以探索激活正则化的两种可能用法,以发现哪种最适合您的特定模型和数据集。
让我们看看如何将激活正则化与一些常见的层类型一起使用。
MLP 激活正则化
下面的示例在 Dense 全连接层上设置 l1 范数激活正则化。
|
1 2 3 4 5 6 |
# 全连接层激活的 l1 范数示例 from keras.layers import Dense from keras.regularizers import l1 ... model.add(Dense(32, activity_regularizer=l1(0.001))) ... |
CNN 激活正则化
下面的示例在 Conv2D 卷积层上设置 l1 范数激活正则化。
|
1 2 3 4 5 6 |
# CNN 层激活的 l1 范数示例 从 keras.layers 导入 Conv2D from keras.regularizers import l1 ... model.add(Conv2D(32, (3,3), activity_regularizer=l1(0.001))) ... |
RNN 激活正则化
下面的示例在 LSTM 循环层上设置 l1 范数激活正则化。
|
1 2 3 4 5 6 |
# LSTM 层激活的 l1 范数示例 从 keras.layers 导入 LSTM from keras.regularizers import l1 ... model.add(LSTM(32, activity_regularizer=l1(0.001))) ... |
现在我们了解了如何使用激活正则化 API,接下来看一个实际示例。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
激活正则化案例研究
在本节中,我们将演示如何使用激活正则化来减少 MLP 在简单二分类问题上的过拟合。
尽管激活正则化最常用于鼓励自编码器和编码器-解码器模型中的稀疏学习表示,但它也可以直接用于普通神经网络以实现相同的效果并提高模型的泛化能力。
此示例提供了一个模板,用于将激活正则化应用于您自己的分类和回归问题的神经网络。
二分类问题
我们将使用一个标准的二分类问题,该问题定义了两个二维同心圆的观测值,每个类别一个圆。
每个观测值都有两个具有相同比例的输入变量和一个类别输出值 0 或 1。由于绘制时每个类别中观测值的形状,此数据集称为“*circles*”数据集。
我们可以使用 make_circles() 函数从这个问题生成观测值。我们将向数据添加噪声并为随机数生成器设置种子,以便每次运行代码时都会生成相同的样本。
|
1 2 |
# 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) |
我们可以绘制数据集,其中两个变量作为图上的x和y坐标,类别值作为观测值的颜色。
生成数据集并绘制它的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成两个圆数据集 from sklearn.datasets import make_circles from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) colors = {0:'red', 1:'blue'} fig, ax = pyplot.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行示例会创建一个散点图,显示每个类中观测值的同心圆形状。
我们可以看到点分散中的噪声使得圆圈不那么明显。
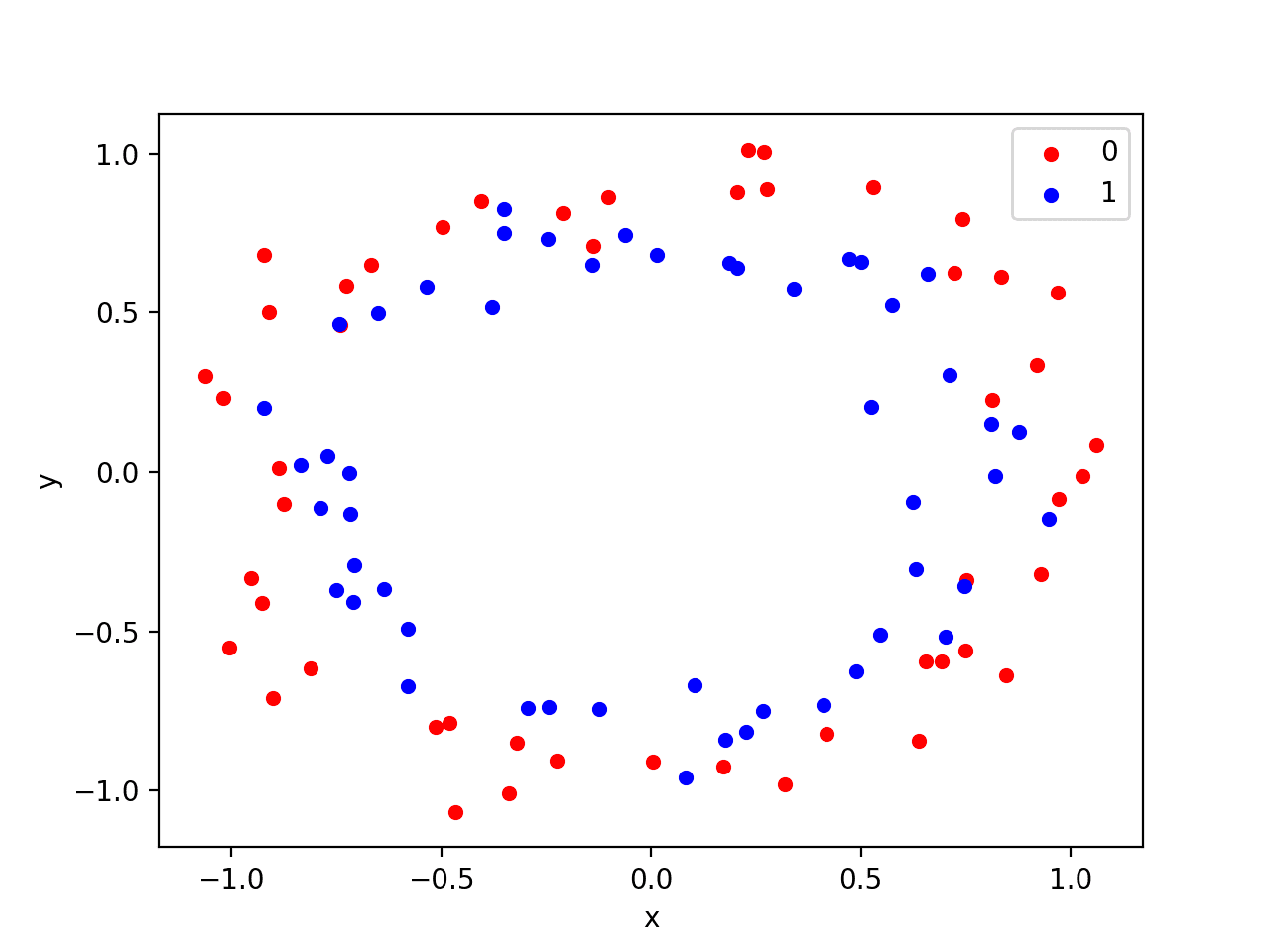
带有颜色显示每个样本类别值的圆数据集散点图
这是一个很好的测试问题,因为这些类别不能用一条线分开,例如,它们不是线性可分的,需要一种非线性方法(如神经网络)来解决。
我们只生成了 100 个样本,这对于神经网络来说很少,这提供了过拟合训练数据集并在测试数据集上产生更高误差的机会:这是使用正则化的一个很好的案例。
此外,样本带有噪声,使模型有机会学习样本中不泛化的方面。
过拟合多层感知器
我们可以开发一个MLP模型来解决这个二分类问题。
该模型将有一个隐藏层,其节点可能多于解决此问题所需的节点,从而提供了过拟合的机会。我们还将训练模型比所需时间更长,以确保模型过拟合。
在定义模型之前,我们将数据集拆分为训练集和测试集,使用30个示例来训练模型,70个示例来评估拟合模型的性能。
|
1 2 3 4 5 6 |
# 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
接下来,我们可以定义模型。
隐藏层使用 500 个节点和修正线性激活函数。输出层使用 Sigmoid 激活函数,以便预测 0 或 1 的类别值。
该模型使用适用于二分类问题的二元交叉熵损失函数和高效的Adam 版本的梯度下降进行优化。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
然后,将定义的模型在训练数据上拟合4,000个周期,并使用默认的批量大小32。
我们还将测试数据集用作验证数据集。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) |
我们可以评估模型在测试数据集上的性能并报告结果。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,我们将绘制每个 epoch 模型在训练集和测试集上的性能。
如果模型确实过拟合了训练数据集,我们预计训练集上的准确度线图将继续增加,而测试集将先上升然后再次下降,因为模型学习了训练数据集中的统计噪声。
|
1 2 3 4 5 |
# 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
我们可以将所有这些部分结合起来,完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# MLP 在两个圆数据集上过拟合 from sklearn.datasets import make_circles from keras.layers import Dense from keras.models import Sequential from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
我们可以看到模型在训练数据集上的性能优于测试数据集,这可能是过拟合的一个迹象。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
因为模型严重过拟合,我们通常不期望在相同数据集上重复运行模型时,准确性会有很大(如果有的话)差异。
|
1 |
训练集:1.000,测试集:0.786 |
创建了一个图,显示模型在训练集和测试集上的准确度线图。
我们可以看到过拟合模型的预期形状,其中测试准确率增加到一定程度,然后开始再次下降。
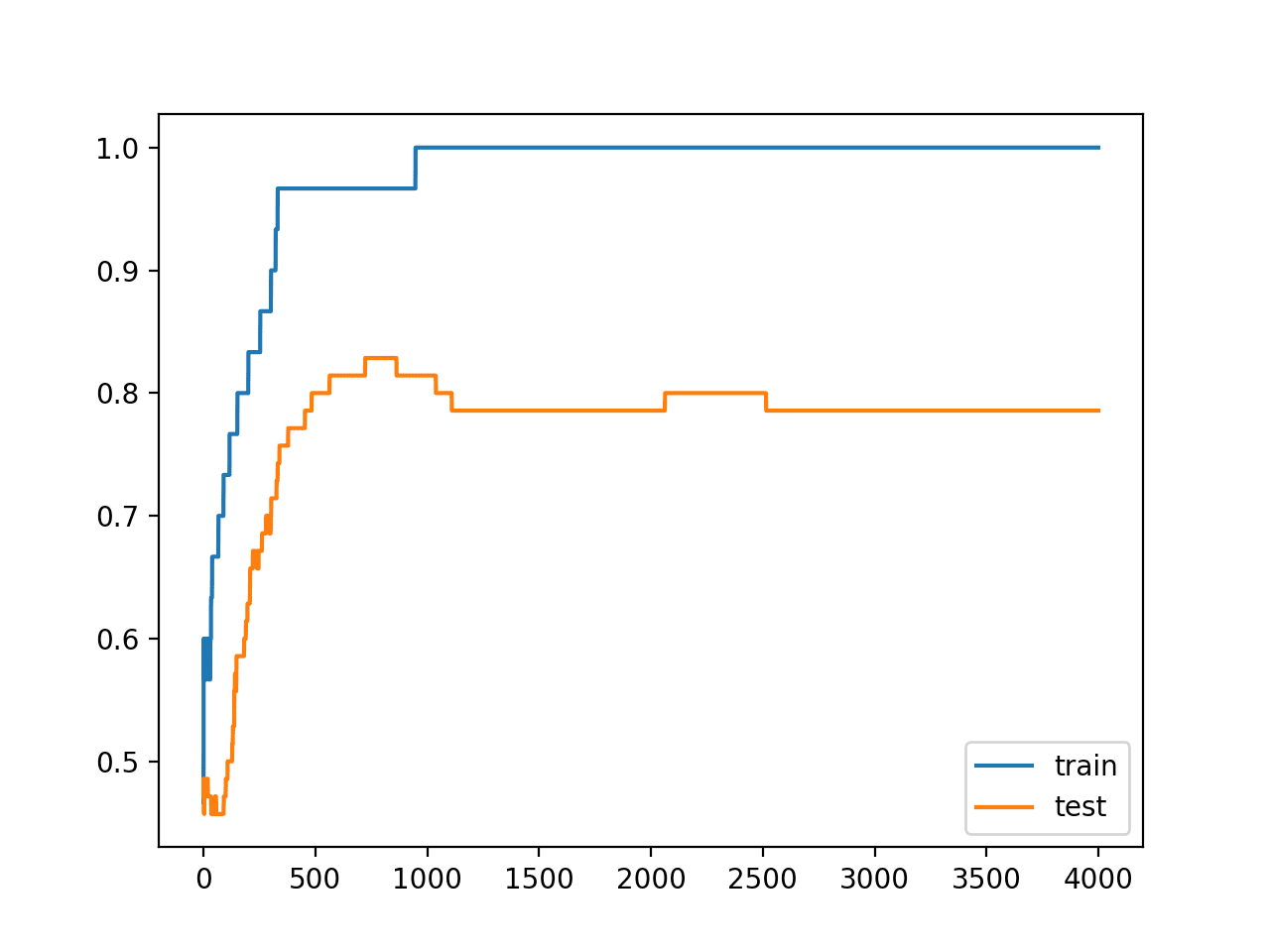
训练期间训练集和测试集准确度线图,显示过拟合
带激活正则化的过拟合 MLP
我们可以更新示例以使用激活正则化。
有几种不同的正则化方法可供选择,但使用最常见的 L1 范数可能是一个好主意。
这种正则化的作用是鼓励稀疏表示(大量零),这得到了允许真零值的修正线性激活函数的支持。
我们可以通过使用 Keras 中的 keras.regularizers.l1 类来实现这一点。
我们将配置该层以使用线性激活函数,以便我们可以对原始输出进行正则化,然后在该层的正则化输出之后添加一个 relu 激活层。我们将正则化超参数设置为 1E-4 或 0.0001,这是通过反复试验找到的。
|
1 2 |
model.add(Dense(500, input_dim=2, activation='linear', activity_regularizer=l1(0.0001))) model.add(Activation('relu')) |
完整的更新示例,带 L1 范数约束,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 在带有激活正则化的两个圆形数据集上过拟合的 MLP from sklearn.datasets import make_circles from keras.layers import Dense from keras.models import Sequential from keras.regularizers import l1 from keras.layers import Activation from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='linear', activity_regularizer=l1(0.0001))) model.add(Activation('relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
我们可以看到,激活正则化导致训练数据集的准确率略有下降,从 100% 降至 96%,而测试集的准确率从 78% 升至 82%。
|
1 |
训练集:0.967,测试集:0.829 |
回顾训练和测试准确率的折线图,我们可以看到模型似乎不再过拟合训练数据集。
模型在训练集和测试集上的准确率继续提高,直至达到平台期。
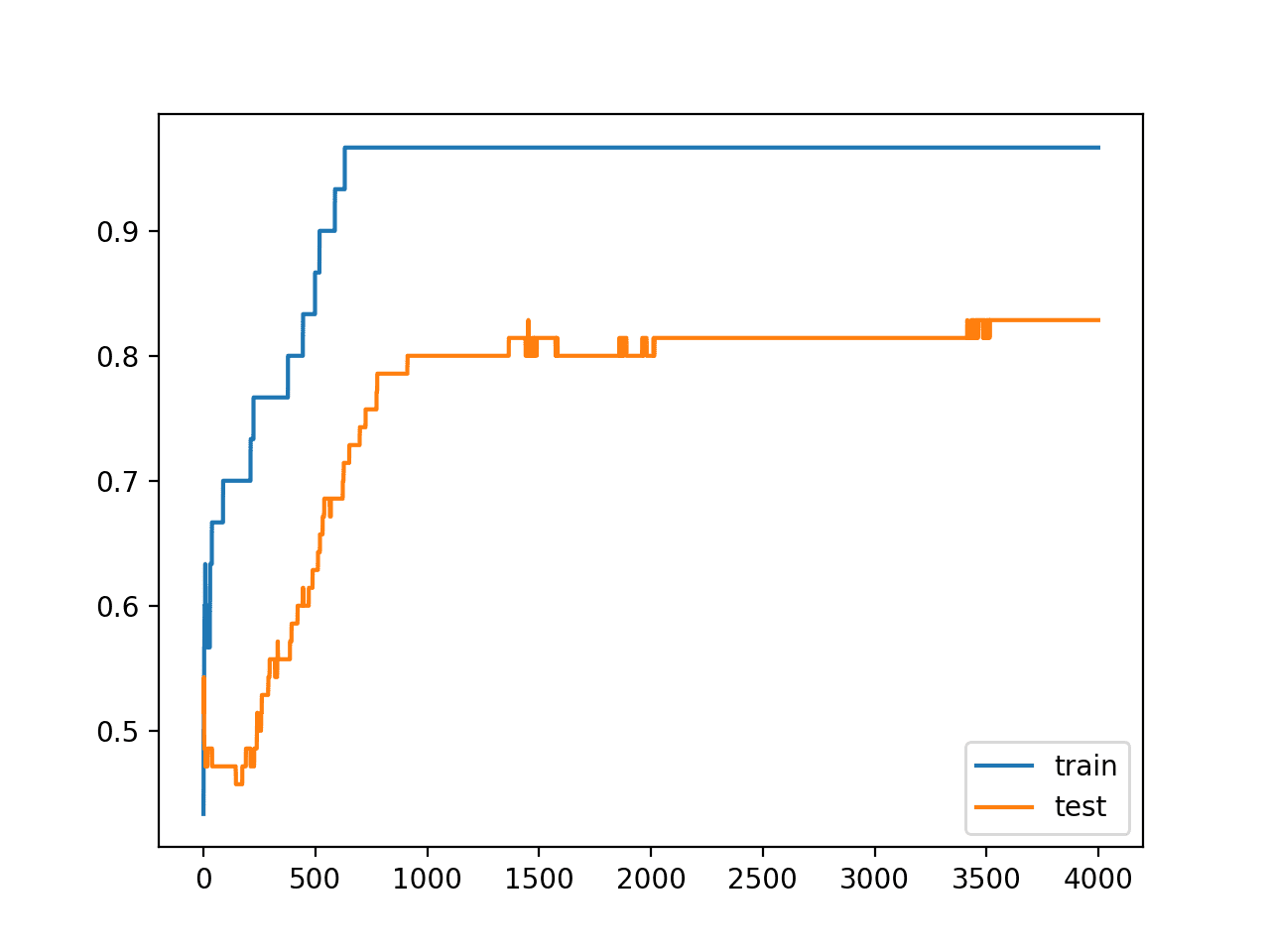
使用激活正则化训练期间的训练集和测试集准确率折线图
为了完整起见,我们可以将结果与在 relu 激活函数之后应用激活正则化的模型版本进行比较。
|
1 |
model.add(Dense(500, input_dim=2, activation='relu', activity_regularizer=l1(0.0001))) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 在带有激活正则化的两个圆形数据集上过拟合的 MLP from sklearn.datasets import make_circles from keras.layers import Dense from keras.models import Sequential from keras.regularizers import l1 from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu', activity_regularizer=l1(0.0001))) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑多次运行示例并比较平均结果。
我们可以看到,至少在这个问题和这个模型上,激活函数后的激活正则化并没有改善泛化误差;事实上,它使其变得更糟。
|
1 |
训练:1.000,测试:0.743 |
查看训练和测试准确率的折线图,我们可以看到模型确实仍然显示出过拟合训练数据集的迹象。
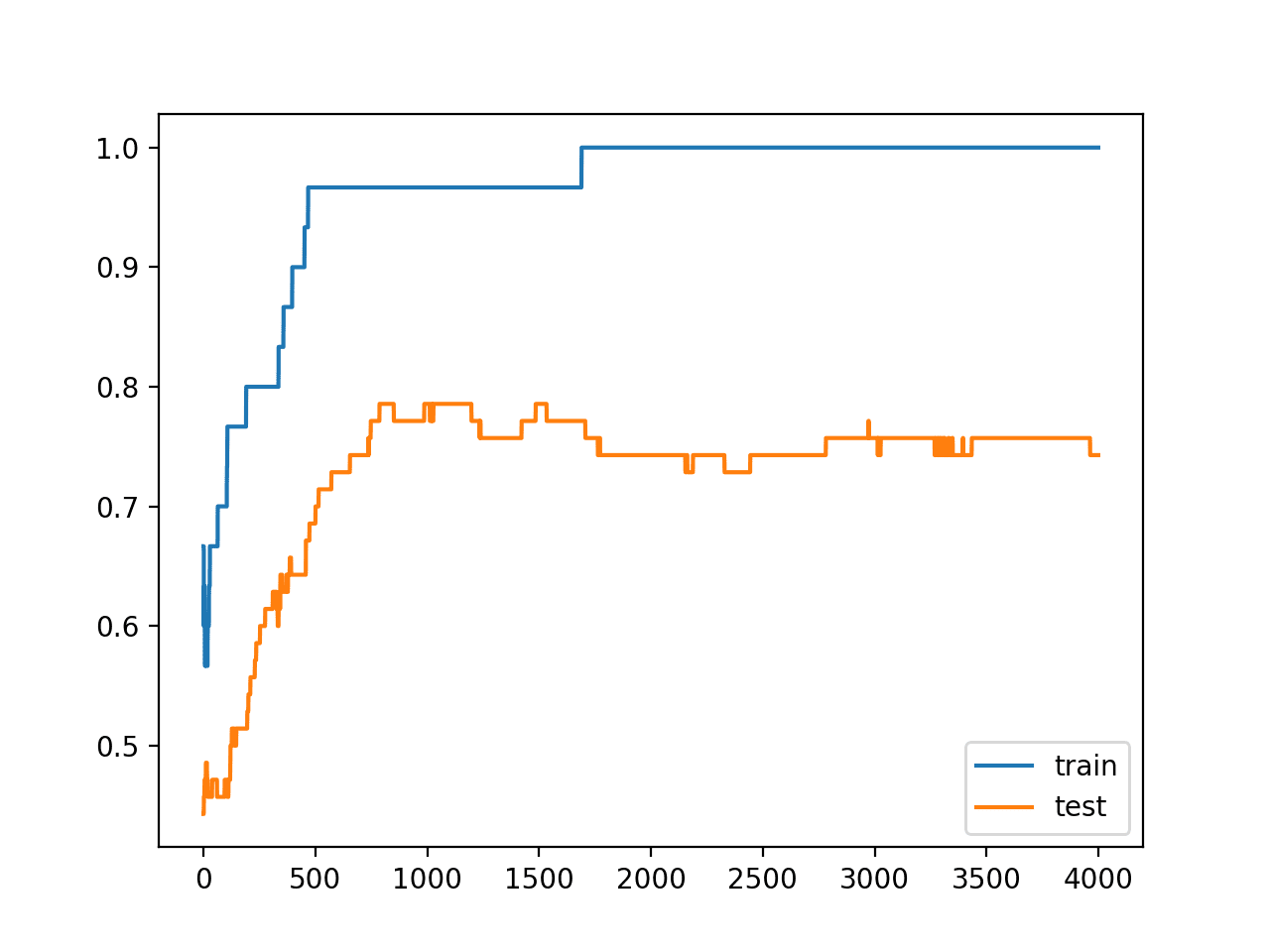
使用激活正则化训练期间的训练集和测试集准确率折线图,仍然过拟合
这表明,对于您自己的数据集,可能值得尝试两种实现激活正则化的方法,以确认您正在充分利用该方法。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 报告激活均值。更新示例以计算正则化层的平均激活,并确认激活确实变得更加稀疏。
- 网格搜索。更新示例以网格搜索正则化超参数的不同值。
- 替代范数。更新示例以评估 L2 或 L1_L2 向量范数,用于正则化隐藏层输出。
- 重复评估。更新示例以多次拟合和评估模型,并报告模型性能的均值和标准差。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
总结
在本教程中,您了解了 Keras API,用于向深度学习神经网络模型添加激活正则化。
具体来说,你学到了:
- 如何使用 Keras API 创建向量范数正则化器。
- 如何使用 Keras API 将激活正则化添加到 MLP、CNN 和 RNN 层。
- 如何通过向现有模型添加激活正则化来减少过拟合。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。



 From Scratch With Python")



train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print(‘Train: %.3f, Test: %.3f’ % (train_acc, test_acc)) <<< 不起作用
错误是 TypeError: must be real number, not list
这个例子确实有效。
请确保您的库是最新的,并且您正在使用 Python 3。
请确保您从命令行运行示例。
这有帮助吗?
谢谢这个。我以前没有使用过这种形式的正则化;会做一些测试!
稀疏激活可能非常有效!
嗨 Jason,"kernel_regularizer" 和 "activity_regularizer" 之间有什么区别?
一个正则化权重,另一个正则化激活。
你好 Jason,
感谢您的分享。但我有一个问题,如果我想将一层的输出作为损失的一部分怎么办?使用 activity_regularization?我应该如何将这种 activity_regularization 添加到自定义 Keras 层中?谢谢
听起来很有趣,但我不太明白,你能详细说明你的意思吗 Hayley?
正则化是损失函数的一部分,对吗?有没有办法在 Keras 的损失函数中应用正则化?
不总是。
我们可以使用正则化(例如 L2 范数)来保持权重较小。这并不直接与损失函数交互。
我正在训练一个 MLP,包含 1328->442->147->50->1 的密集层,使用 10 万个样本,训练 50 个 epoch。然而,每当我向这些层添加 L1 或 L2 核正则化器或将 StandardScaler 应用于输入时,它只会为每个样本预测一个单一值(这个值接近训练集的平均值)。这种情况是可重复的,即使拓扑结构和各种超参数有微小的变化。与没有这些变化相比,损失更大。以前见过这种情况吗?对此是我的数据集的特征还是某个地方的错误有什么看法吗?
感谢您的精彩内容。我经常在我的 Google 搜索结果中查找并找到您的内容。
这表明您的模型可能不稳定。通常,性能会随着结构变化而缓慢下降。
也许可以探索更简单的模型并比较它们?也许可以准备 10-20 个不同的想法,在晚上启动它们,看看早上什么看起来不错。
嗨,Jason,
感谢您投入时间维护这个网站,您的文章总是写得很好且深思熟虑。自从我进入数据科学领域以来,这里一直是我需要帮助时的首选之地。
最近,我一直在为一些关于正则化的概念而苦恼,如果您能稍微扩展一下您在这篇文章中写的内容,我将不胜感激。
例如,您为什么选择激活正则化来防止过拟合,而不是核正则化或循环正则化?在我看来,所有这些技术都大同小异。我是否遗漏了什么?
此外,在多层神经网络的情况下,在每一层添加正则化是否有意义?还是只需要第一层?
如果您能抽出时间回答,提前感谢您,
此致,
Lilian
谢谢!
不,它们大相径庭。将上述教程与本教程进行比较
https://machinelearning.org.cn/weight-regularization-to-reduce-overfitting-of-deep-learning-models/
例如:
激活正则化 – 训练层以产生稀疏输出。
权重正则化 – 训练层以产生稀疏权重。
是的,正则化被添加到每一层。
明白了!我稍后会查看教程。
再次感谢您的工作!
不客气。
嗨,Jason,
“””...如“深度稀疏修正神经网络”中所述,为了让模型能够学习将激活值设置为与修正线性激活函数结合的真正的零值。””” 这里您说的将激活值设置为真正的零值是什么意思?什么是真正的零值?
谢谢你
0.0
而不是
0.00000001
嗨,Jason,
选择正则化超参数(低值还是高值?)的一般思路是什么?(例如0.01 0.0001),这些如何影响学习?
它对模型施加或多或少的压力,使其激活值较小。
谢谢你,Jason!
不客气。
再次感谢您的这篇文章。
我有一个问题想请教。
将正则化超参数设置为0是否等同于没有正则化?
例如,使用您的例子,
model.add(Dense(500, input_dim=2, activation='relu'))
是否等同于
model.add(Dense(500, input_dim=2, activation='relu', activity_regularizer=l1(0.0)))
?
因此,通过精确地设置为0来迭代不同的正则化超参数,我们将涵盖“完全没有正则化”的情况。
如果我设想简单的回归情况,它应该如此,但我在这里不确定。
我相信是的。
感谢您的快速回复。
不客气。
感谢分享。我非常喜欢这篇文章。
我有几个问题
1. 您对哪些超参数值或值范围能产生最佳结果,或者任何正则化器有何见解?
2. 最佳正则化器及其超参数值是否与任何事物相关或依赖于任何事物,或者发现最佳组合是否需要对模型进行实验?
通常,我建议测试一系列不同的配置,以发现最适合您的模型和数据集的方案。
嗨,Jason,感谢您的这个教程!我有一个问题。我明白活动正则化和核正则化的效果是不同的。同时使用这两种方法是否是常见的做法,或者它可能产生负面影响?谢谢!
不客气。
通常您只需要其中一个。如果您想要同时使用,可以尝试看看效果。
嗨,Jason,谢谢你的帖子。
你为什么决定使用活动正则化器而不是核正则化器?
本教程的目的是演示活动正则化。
好的,谢谢。您能详细说明两者的区别吗?
活动正则化侧重于惩罚节点的输出,权重正则化侧重于惩罚节点内的权重。
我们惩罚权重以创建稀疏表示,我们惩罚权重以创建稀疏模型。
谢谢你!
不客气。
很棒的文章!!但请详细阐述为什么需要活动正则化器,以及它们比权重正则化更有益的原因,以及其惩罚机制背后的数学原理。
例如:在L1或L2权重正则化中,权重的绝对值或平方值与正则化系数一起添加到损失函数中,从而使权重更小,以减少损失函数。
.
活动正则化有助于使层的输出稀疏。这反过来又对某些预测任务有帮助。
它们与权重正则化不同,权重正则化使节点中的权重稀疏,例如模型更简单,而不是模型的输出更简单。
活动正则化对于自动编码器和编码器-解码器来说可能很好。
权重正则化可以作为一种通用的正则化方法来减少过拟合。
我在各自的教程中直接提到过这一点,也许可以重新阅读一下。
你好 Jason,
以上代码在LSTM中使用了L1活动正则化器……为什么不能在LSTM中使用L2正则化器……L2是否有利于预测任务。如果在LSTM层中同时使用L1和L2会发生什么……最后一个问题,我可以在最后一层使用L1或L2吗……我可以在LSTM层之后使用两个密集层吗……它会改善预测任务吗。
您可以使用L1或L2,请尝试两者并与您的数据集上不进行正则化的结果进行比较,然后使用能产生最佳性能模型的配置。
嗨,杰森,
使用集成技术结合L1活动正则化的LSTM、L2正则化的LSTM以及L1和L2结合的LSTM,以实现更好的预测任务。
尝试一系列配置,并找出最适合您的数据集的方案。
谢谢您的解释,先生。我想知道如何在CNN (Conv2d) 中使用自定义 `activity_regularizer`。我尝试将非局部块 ( https://github.com/titu1994/keras-non-local-nets/blob/master/non_local.py ) 作为正则化器,但遇到了错误。这是我的代码
inp=Input(shape=(50,50,1))
conv1=Conv2D(64,(3,3),padding="same",activity_regularizer=non_local_block1)(inp)
relu1=Activation('relu')(conv1)
它在conv1处失败了。
错误
ValueError: Shapes must be equal rank, but are 0 and 4
From merging shape 0 with other shapes. for '{{node AddN}} = AddN[N=2, T=DT_FLOAT](custom_loss/weighted_loss/value, model_6/conv2d_14/ActivityRegularizer/truediv)' with input shapes: [], [25,50,50,64].
我想知道 `activity_regularizer` 是将权重还是输出作为输入参数,以及如何修改我的代码来纠正这个错误。
也许直接联系作者,了解如何使用他们的代码?
嗨,杰森,
我可以在LSTM输入层使用L1正则化器,在LSTM输出层同时使用L2正则化器来减少过拟合吗?
如果你想,可以尝试一下,看看是否有帮助。
嗨,杰森,
我可以在LSTM的单元状态上使用L1正则化,同时在LSTM的输入、输出和遗忘门上使用L2正则化吗?
或者我可以在LSTM的输出层结合L1和L2来防止过拟合吗?
也许,试试看。
你好 Jason,
L1和L2正则化技术的取值范围
通常使用对数尺度的较小值。
嗨,杰森,
L1、L2以及L1+L2的组合……哪种正则化技术(L1、L2或组合)最能克服LSTM的过拟合问题?
您必须尝试每一种,并发现最适合您的数据集和模型的方案。
嗨,杰森,
哪种激活函数有助于多阶段分类?
好问题,暂时不清楚。猜测一下——也许每一层都用softmax?
我建议您查阅文献。
非常感谢..