权重正则化提供了一种方法,可以减少深度学习神经网络模型在训练数据上的过拟合,并提高模型在新数据(例如保留测试集)上的性能。
权重正则化有多种类型,例如L1 和 L2 向量范数,每种类型都需要配置一个超参数。
在本教程中,您将了解如何使用 Python 和 Keras 应用权重正则化来提高过拟合深度学习神经网络的性能。
完成本教程后,您将了解:
- 如何使用 Keras API 为 MLP、CNN 或 LSTM 神经网络添加权重正则化。
- 书籍和最新研究论文中使用的权重正则化配置示例。
- 如何通过案例研究来识别过拟合模型并使用权重正则化提高测试性能。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何使用权重正则化减少深度学习中的过拟合
图片由 Seabamirum 提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Keras 中的权重正则化
- 权重正则化示例
- 权重正则化案例研究
Keras 中的权重正则化 API
Keras 提供了一个权重正则化 API,允许您向损失函数添加权重大小的惩罚。
提供了三种不同的正则化器实例;它们是:
- L1:权重绝对值之和。
- L2:权重平方和。
- L1L2:权重绝对值和平方和。
这些正则化器在 keras.regularizers 下提供,名称分别为 l1、l2 和 l1_l2。每个都将正则化超参数作为参数。例如:
|
1 2 3 |
keras.regularizers.l1(0.01) keras.regularizers.l2(0.01) keras.regularizers.l1_l2(l1=0.01, l2=0.01) |
默认情况下,任何层中都不使用正则化器。
在 Keras 模型中定义层时,可以向每个层添加权重正则化器。
这可以通过在每个层上设置 kernel_regularizer 参数来实现。也可以通过 bias_regularizer 参数为偏差使用单独的正则化器,尽管这种情况较少使用。
让我们看一些例子。
密集层的权重正则化
以下示例在 Dense 全连接层上设置了一个 l2 正则化器
|
1 2 3 4 5 6 |
# 密集层上的 l2 示例 from keras.layers import Dense 从 keras.regularizers 导入 l2 ... model.add(Dense(32, kernel_regularizer=l2(0.01), bias_regularizer=l2(0.01))) ... |
卷积层的权重正则化
与 Dense 层一样,卷积层(例如 Conv1D 和 Conv2D)也使用 kernel_regularizer 和 bias_regularizer 参数来定义正则化器。
以下示例在 Conv2D 卷积层上设置了一个 l2 正则化器
|
1 2 3 4 5 6 |
# 卷积层上的 l2 示例 从 keras.layers 导入 Conv2D 从 keras.regularizers 导入 l2 ... model.add(Conv2D(32, (3,3), kernel_regularizer=l2(0.01), bias_regularizer=l2(0.01))) ... |
循环层的权重正则化
像 LSTM 这样的循环层在权重正则化方面提供了更大的灵活性。
输入、循环和偏差权重都可以通过 kernel_regularizer、recurrent_regularizer 和 bias_regularizer 参数单独进行正则化。
以下示例在 LSTM 循环层上设置了一个 l2 正则化器
|
1 2 3 4 5 6 |
# lstm 层上的 l2 示例 从 keras.layers 导入 LSTM 从 keras.regularizers 导入 l2 ... model.add(LSTM(32, kernel_regularizer=l2(0.01), recurrent_regularizer=l2(0.01), bias_regularizer=l2(0.01))) ... |
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
权重正则化示例
查看文献中报道的一些权重正则化配置示例可能会有所帮助。
选择和调整适合您的网络和数据集的正则化技术非常重要,尽管真实示例也可以提供常见配置的思路,这可能是一个有用的起点。
回想一下,0.1 可以写成科学记数法 1e-1 或 1E-1 或指数 10^-1,0.01 写成 1e-2 或 10^-2,依此类推。
MLP 权重正则化示例
权重正则化是从统计学中的惩罚回归模型中借鉴的。
最常见的正则化类型是 L2,也简称为“权重衰减”,其值通常在 0 到 0.1 之间的对数尺度上,例如 0.1、0.001、0.0001 等。
lambda [正则化超参数] 的合理值范围在 0 到 0.1 之间。
— 第 144 页,《应用预测建模》,2013 年。
关于多层感知器的经典著作《神经网络锻造:前馈人工神经网络中的监督学习》提供了一个工作示例,通过首先训练一个没有任何正则化的模型,然后稳步增加惩罚来演示权重衰减的影响。他们通过图示证明,权重衰减具有改善所得决策函数的效果。
……网络经过训练 […] 权重衰减从 1200 纪元的 0 增加到 1E-5,2500 纪元增加到 1E-4,400 纪元增加到 1E-3。 […] 表面更平滑,过渡更渐进
— 第 270 页,《神经网络锻造:前馈人工神经网络中的监督学习》,1999 年。
这是一个值得研究的有趣过程。作者还评论了预测权重衰减对问题的影响的难度。
……很难提前预测达到预期结果所需的值。0.001 的值是随意选择的,因为它是一个典型的引用整数
— 第 270 页,《神经网络锻造:前馈人工神经网络中的监督学习》,1999 年。
CNN 权重正则化示例
权重正则化似乎并未广泛用于 CNN 模型中,或者如果使用,其使用也未广泛报道。
使用非常小的正则化超参数(例如 0.0005 或 5 x 10^-4)的 L2 权重正则化可能是一个很好的起点。
多伦多大学的 Alex Krizhevsky 等人在其 2012 年题为“使用深度卷积神经网络进行 ImageNet 分类”的论文中开发了一个用于 ImageNet 数据集的深度 CNN 模型,取得了当时最先进的结果,报道称
……以及 0.0005 的权重衰减。我们发现,这种少量权重衰减对于模型学习很重要。换句话说,这里的权重衰减不仅仅是正则化器:它降低了模型的训练误差。
牛津大学的 Karen Simonyan 和 Andrew Zisserman 在其 2015 年题为“用于大规模图像识别的非常深的卷积网络”的论文中开发了一个用于 ImageNet 数据集的 CNN,并报道称
训练通过权重衰减进行正则化(L2 惩罚乘数设置为 5 x 10^-4)
来自 Google(以及 Keras 作者)的 Francois Chollet 在其 2016 年题为“Xception:使用深度可分离卷积的深度学习”的论文中报道了 Google 的 Inception V3 CNN 模型(Inception V3 论文中不清楚)和其改进的 Xception 用于 ImageNet 数据集的权重衰减
Inception V3 模型使用 4e-5 的权重衰减(L2 正则化)率,该率已针对 ImageNet 上的性能进行了仔细调整。我们发现该率对于 Xception 来说相当不理想,因此选择了 1e-5。
LSTM 权重正则化示例
将权重正则化与 LSTM 模型结合使用是很常见的。
一个常用的配置是 L2(权重衰减)和非常小的超参数(例如 10^-6)。通常不会报告哪些权重受到正则化(输入、循环和/或偏差),尽管可以假设只有输入和循环权重受到正则化。
Google Brain 的 Gabriel Pereyra 等人在 2017 年题为“通过惩罚置信输出分布来正则化神经网络”的论文中将 seq2seq LSTM 模型应用于预测《华尔街日报》中的字符,并报道称
所有模型均使用 10^-6 的权重衰减
Google Brain 的 Barret Zoph 和 Quoc Le 在 2017 年题为“使用强化学习进行神经网络架构搜索”的论文中,使用 LSTM 和强化学习来学习网络架构以最佳解决 CIFAR-10 数据集,并报道称
权重衰减为 1e-4
Google Brain 和 Nvidia 的 Ron Weiss 等人在其 2017 年题为“序列到序列模型可以直接翻译外语语音”的论文中开发了一个用于语音翻译的序列到序列 LSTM,并报道称
使用 L2 权重衰减,权重为 10^-6
权重正则化案例研究
在本节中,我们将演示如何使用权重正则化来减少 MLP 在简单二元分类问题上的过拟合。
此示例提供了一个模板,用于将权重正则化应用于您自己的神经网络以解决分类和回归问题。
二分类问题
我们将使用一个标准的二元分类问题,该问题定义了两个半圆形观测值:每个类别一个半圆形。
每个观测值都有两个具有相同尺度的输入变量和一个类别输出值0或1。这个数据集被称为“moons”数据集,因为绘制时每个类别中的观测值的形状。
我们可以使用 make_moons() 函数从这个问题生成观测值。我们将向数据添加噪声并为随机数生成器设置种子,以便每次运行代码时都生成相同的样本。
|
1 2 |
# 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) |
我们可以绘制数据集,其中两个变量作为图上的x和y坐标,类别值作为观测值的颜色。
生成数据集并绘制它的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成两个月牙形数据集 from sklearn.datasets import make_moons from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) colors = {0:'red', 1:'blue'} fig, ax = pyplot.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行示例将创建一个散点图,显示每个类别中观测值的半圆或月牙形。我们可以看到点分散中的噪声使得月牙形不那么明显。
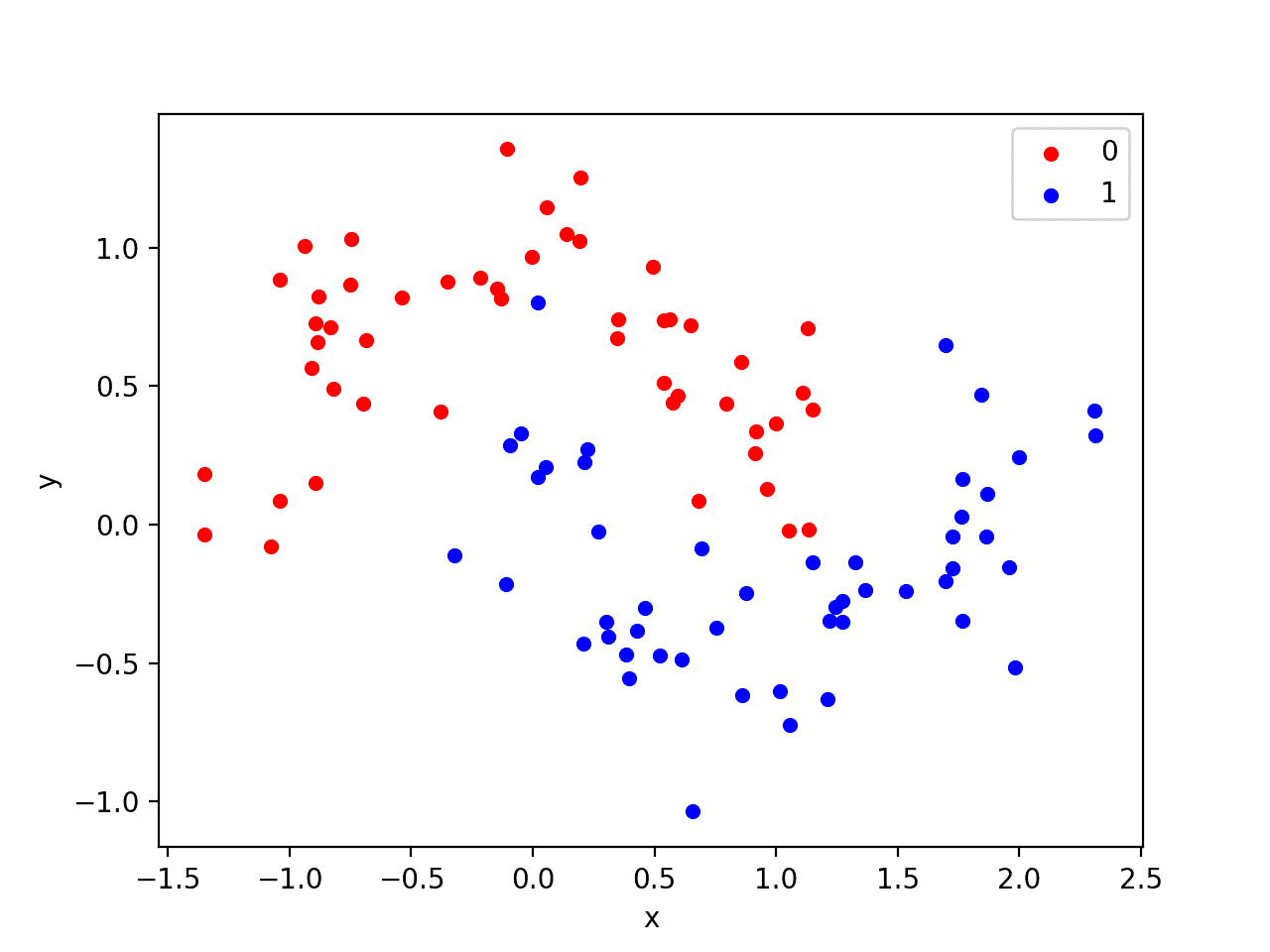
月牙形数据集的散点图,点颜色显示每个样本的类别值
这是一个很好的测试问题,因为这些类别不能用一条线分开,例如,它们不是线性可分的,需要一种非线性方法(如神经网络)来解决。
我们只生成了 100 个样本,这对于神经网络来说太少了,这提供了过拟合训练数据集并在测试数据集上产生更高误差的机会:这是使用正则化的一个很好的案例。此外,样本具有噪声,这使得模型有机会学习样本中不泛化的方面。
过拟合多层感知器模型
我们可以开发一个MLP模型来解决这个二分类问题。
该模型将有一个隐藏层,其节点数量可能比解决此问题所需的更多,从而提供了过拟合的机会。我们还将对模型进行更长时间的训练,以确保模型过拟合。
在定义模型之前,我们将数据集拆分为训练集和测试集,使用30个示例来训练模型,70个示例来评估拟合模型的性能。
|
1 2 3 4 5 6 |
# 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
接下来,我们可以定义模型。
该模型在隐藏层中使用 500 个节点和修正线性激活函数。
输出层使用 sigmoid 激活函数,以便预测类别值 0 或 1。
该模型使用二元交叉熵损失函数进行优化,适用于二元分类问题和梯度下降的有效 Adam 版本。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
然后,将定义的模型在训练数据上拟合4,000个周期,并使用默认的批量大小32。
|
1 2 |
# 拟合模型 model.fit(trainX, trainy, epochs=4000, verbose=0) |
最后,我们可以评估模型在测试数据集上的性能并报告结果。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
我们可以将所有这些部分结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 针对 moons 数据集的过拟合 mlp from sklearn.datasets import make_moons from keras.layers import Dense 从 keras.models 导入 Sequential # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
运行示例会报告模型在训练数据集和测试数据集上的性能。
我们可以看到模型在训练数据集上的性能优于测试数据集,这可能是过拟合的一个迹象。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
因为模型严重过拟合,我们通常不期望在相同数据集上重复运行模型时,准确性会有很大(如果有的话)差异。
|
1 |
训练:1.000,测试:0.914 |
过拟合的另一个迹象是在训练过程中绘制模型在训练和测试数据集上的学习曲线。
过拟合的模型应该显示训练集和测试集的准确率都在增加,并且在某个点上测试集的准确率下降,但训练集的准确率继续上升。
我们可以更新示例来绘制这些曲线。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 针对 moons 数据集的过拟合 mlp 绘制历史记录 from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential from matplotlib import pyplot # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 绘制历史记录 # 总结准确率的历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
运行示例会创建模型在训练集和测试集上准确率的折线图。
我们可以看到过拟合模型的预期形状,即测试准确率增加到某个点后开始再次下降。
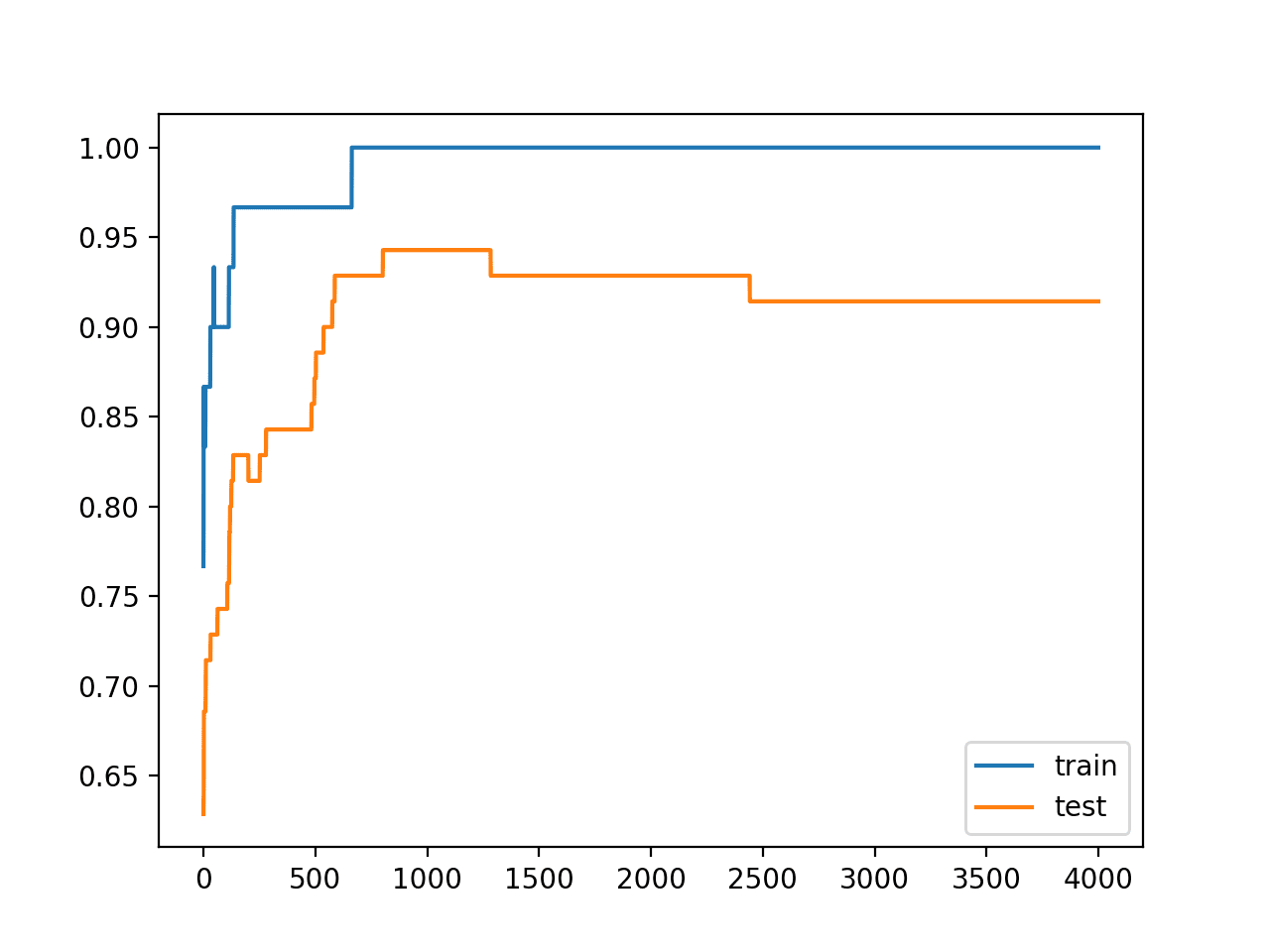
训练期间训练集和测试集准确率的折线图
带权重正则化的 MLP 模型
我们可以在隐藏层中添加权重正则化,以减少模型对训练数据集的过拟合,并提高在保留集上的性能。
我们将使用 L2 向量范数,也称为权重衰减,正则化参数(称为 alpha 或 lambda)为 0.001,任意选择。
这可以通过向层添加 kernel_regularizer 参数并将其设置为 l2 的实例来完成。
|
1 |
model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(0.001))) |
以下是使用权重正则化在 moons 数据集上拟合和评估模型的更新示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 针对 moons 数据集带权重正则化的 mlp from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential 从 keras.regularizers 导入 l2 # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(0.001))) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
运行示例报告了模型在训练和测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到训练数据集上的准确率没有变化,而测试数据集上的准确率有所提高。
|
1 |
训练:1.000,测试:0.943 |
我们预计过拟合的典型学习曲线也会因使用权重正则化而改变。
模型的测试集准确率不再是先上升后下降,而是在训练过程中持续上升。
以下是拟合模型并绘制训练和测试学习曲线的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 针对 moons 数据集带权重正则化的 mlp 绘制历史记录 from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential 从 keras.regularizers 导入 l2 from matplotlib import pyplot # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(0.001))) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 绘制历史记录 # 总结准确率的历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'] label='test') pyplot.legend() pyplot.show() |
运行示例会创建模型在训练期间每个 epoch 的训练和测试准确率的折线图。
正如所料,我们看到测试数据集上的学习曲线上升然后趋于平稳,这表明模型可能没有过拟合训练数据集。
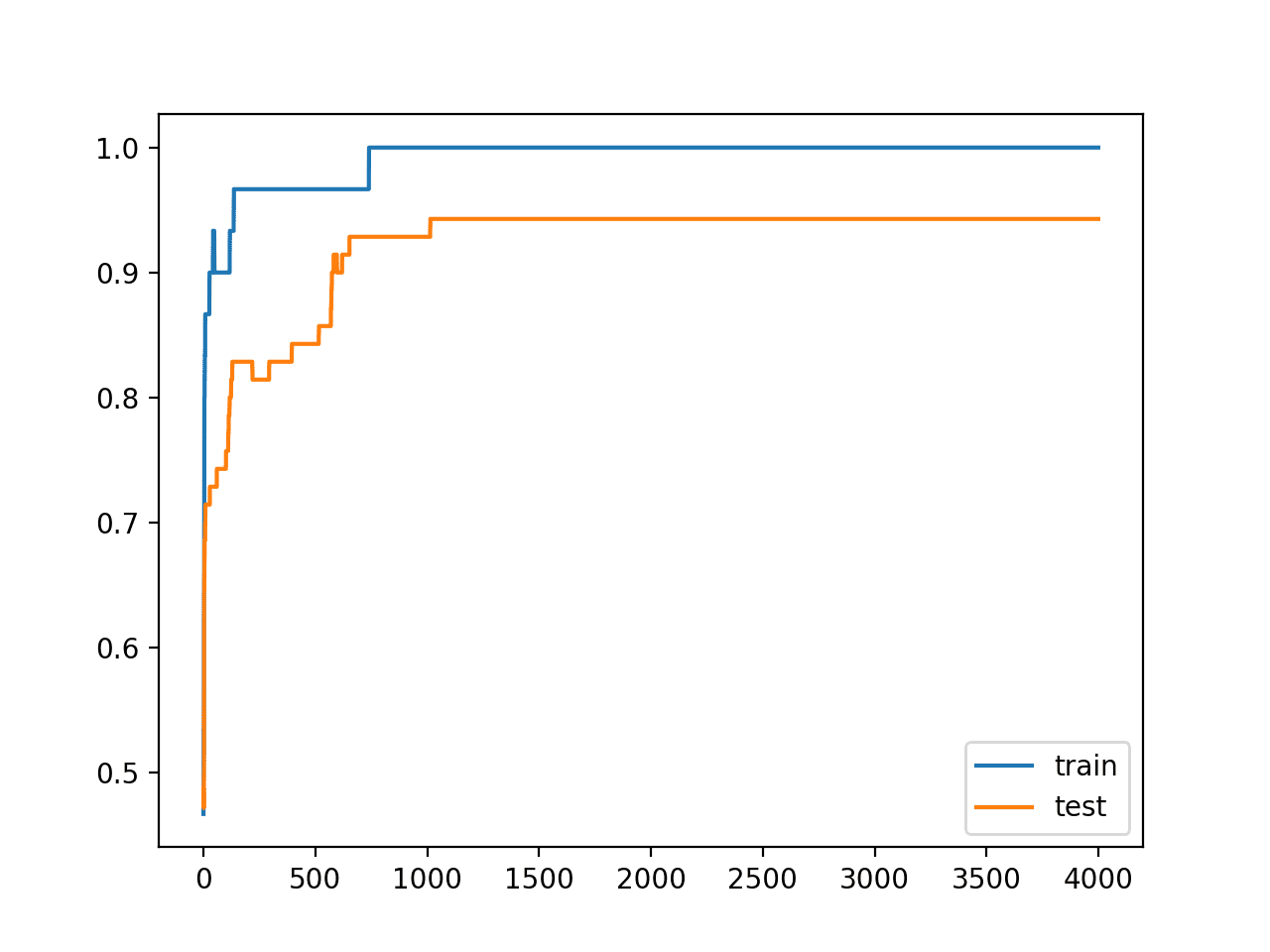
训练期间训练集和测试集准确率的折线图,没有过拟合
网格搜索正则化超参数
一旦您确认权重正则化可能会改进您的过拟合模型,您就可以测试正则化参数的不同值。
一个好的做法是首先在 0.0 到 0.1 之间的一些数量级上进行网格搜索,然后一旦找到一个级别,就在该级别上进行网格搜索。
我们可以通过定义要测试的值、遍历每个值并记录训练和测试性能来网格搜索数量级。
|
1 2 3 4 5 6 7 8 9 10 |
... # 网格搜索值 values = [1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6] all_train, all_test = list(), list() for param in values: ... model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(param))) ... all_train.append(train_acc) all_test.append(test_acc) |
一旦我们得到了所有值,我们就可以将结果绘制成折线图,以帮助发现配置与训练和测试准确率之间的任何模式。
由于参数以数量级(10 的幂)跳跃,我们可以使用对数刻度创建结果的折线图。Matplotlib 库通过 semilogx() 函数允许这样做。例如:
|
1 2 |
pyplot.semilogx(values, all_train, label='train', marker='o') pyplot.semilogx(values, all_test, label='test', marker='o') |
以下是在 moons 数据集上进行权重正则化值网格搜索的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 对 moons 数据集进行正则化值网格搜索 from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential 从 keras.regularizers 导入 l2 from matplotlib import pyplot # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 网格搜索值 values = [1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6] all_train, all_test = list(), list() for param in values: # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu', kernel_regularizer=l2(param))) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 model.fit(trainX, trainy, epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Param: %f, Train: %.3f, Test: %.3f' % (param, train_acc, test_acc)) all_train.append(train_acc) all_test.append(test_acc) # 绘制训练和测试均值 pyplot.semilogx(values, all_train, label='train', marker='o') pyplot.semilogx(values, all_test, label='test', marker='o') pyplot.legend() pyplot.show() |
运行示例会打印每个评估模型的参数值以及在训练集和测试集上的准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
结果表明 0.01 或 0.001 可能足够了,并且可能为进一步的网格搜索提供了很好的范围。
|
1 2 3 4 5 6 |
参数:0.100000,训练:0.967,测试:0.829 参数:0.010000,训练:1.000,测试:0.943 参数:0.001000,训练:1.000,测试:0.943 参数:0.000100,训练:1.000,测试:0.929 参数:0.000010,训练:1.000,测试:0.929 参数:0.000001,训练:1.000,测试:0.914 |
还创建了结果的折线图,显示了随着权重正则化参数值的增大,测试准确率的增加,至少到某个点。
我们可以看到,使用最大值 0.1 会导致训练和测试准确率都大幅下降。
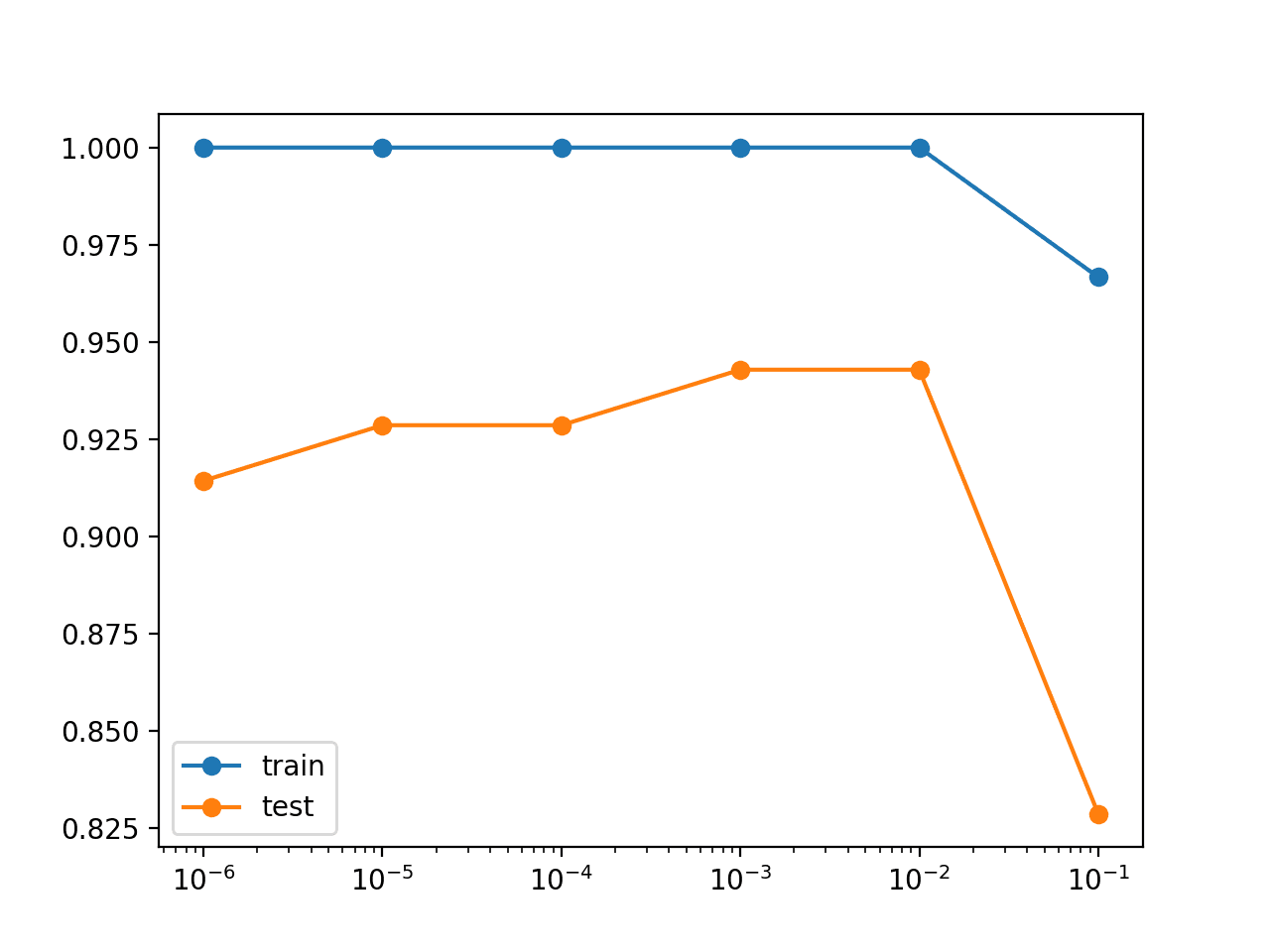
不同权重正则化参数下模型在训练集和测试集上的准确率折线图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 尝试替代方法。更新示例以使用 L1 或组合 L1L2 方法代替 L2 正则化。
- 报告权重范数。更新示例以计算网络权重的幅度,并证明正则化确实使幅度更小。
- 正则化输出层。更新示例以正则化模型的输出层并比较结果。
- 正则化偏差。更新示例以正则化偏差权重并比较结果。
- 重复模型评估。更新示例以多次拟合和评估模型,并报告模型性能的均值和标准差。
- 按数量级网格搜索。更新网格搜索示例,在性能最佳的参数值数量级内进行网格搜索。
- 重复模型正则化。创建一个新示例,以递增的正则化级别(例如 1E-6、1E-5 等)继续训练已拟合的模型,并查看是否能在测试集上获得性能更好的模型。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
- Keras 正则化 API
- Keras核心层API
- Keras卷积层API
- Keras循环层API
- sklearn.datasets.make_moons API
- matplotlib.pyplot.semilogx API
总结
在本教程中,您学习了如何在 Python 和 Keras 中应用权重正则化来提高过拟合深度学习神经网络的性能。
具体来说,你学到了:
- 如何使用 Keras API 为 MLP、CNN 或 LSTM 神经网络添加权重正则化。
- 书籍和最新研究论文中使用的权重正则化配置示例。
- 如何通过案例研究来识别过拟合模型并使用权重正则化提高测试性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






你好 Jason,
– 我已经完成了这个很棒的 MLP 神经网络模型权重正则化案例研究,并使用了 sklearn 库中的 make_moons 函数作为数据集生成器。谢谢。非常清晰的练习,我完全复现了您的所有输出数据!
– 关于本练习的一些扩展,正如您开头提到的,LSTM 和 CNN 模型类型也接受 keras 正则化器,例如 l1、l2、l1_l2……我想知道我们如何使用相同的 make_moons 函数,但现在使用 LSTM 和/或 CNN 模型来实现另一个案例研究?
只需在您的代码的密集层之前添加一个新的卷积 2D 层(我想还要添加 maxpool 层和展平层)吗?那么 LSTM 呢,直接将密集层代码行替换为新的正则化 LSTM 层吗?或者可能它更复杂,不适用于这个 moons 数据集练习?如果有人能写下这些 CNN 和/或 LSTM 模型定义的几行代码,那会很方便……
谢谢
谢谢,干得好!
CNN 和 LSTM 不适用于 moons 问题。它们需要一个序列预测问题。您可以设计一个小的序列预测问题进行测试。
除了之前关于 CNN/LSTM 正则化器代码实现的问题,如果您能提供一些关于
– 如何在多个模型层中实现正则化器(从这个意义上说)
我是否必须在第一层(泛化问题解决方案更好的层)设置强权重衰减(例如更高的 L2 值),而在最后一层(更抽象的层)设置较弱的权重衰减(例如更低的 L2 值)?还是反之?
我的直觉会告诉我尝试在第一层(泛化能力更强的层)使用更高的衰减(强权重衰减),而在最后一层(抽象层)使用更低的衰减(更平滑的衰减)……
也因为从模型不稳定性(输出响应输入在收敛方面的表现)的角度来看,模型对第一层权重值更敏感(所以更大的值会产生更多的不稳定性)……但所有这些都是直觉想法,尚未确认……Jason,您怎么看?
据我所知,所有层都使用相同级别的权重正则化。也许可以尝试不同的方法,看看是否有区别。
人类与机器学习的比较
了解人类感知在识别欺骗方面是否重要,从而人类在检测欺骗攻击方面能否比自动化方法取得更好的性能,这一点非常有趣。曾有一项基准研究比较了自动系统与人类在说话人验证和合成语音欺骗检测任务(SS 和 VC 欺骗)中的性能。结果发现,除了 USS 语音外,人类听觉检测欺骗的效果不如大多数自动化方法。在类似的研究中,发现当使用窄带语音信号(8 kHz 采样频率)时,人类和机器在欺骗检测方面都存在困难。因此,对于电话线语音信号,由于可用带宽较低,最高为 4 kHz,因此进行 SSD 更具挑战性。研究人类在重放 SSD 任务中的性能可能非常有趣。
有意思,谢谢分享。
Jason,很棒的文章!!感谢您的见解……有没有办法从 CNN 模型中提取特征重要性?请提供一些提示或链接到您在此方面发表的文章。
此致
Sowmya
也许吧。很抱歉我没有这方面的示例。
写得真棒!期待强化学习方面的类似教学!
谢谢!
勇
谢谢。
感谢 Jason 博士提供的最有帮助的主题。您的教程帮助我将模型准确率从 60% 提高到 95%。
您解释的一切都非常清晰,这对于像我一样来自阿富汗的非英语母语者来说非常棒。
干得好!
谢谢,很高兴听到这个。
Jason,这真是一篇精彩的文章。
我想问一件事……您知道 l2-l1 与 dropout 层在减少过拟合方面有什么不同吗?
谢谢,
此致,
Abhilash Mandal
谢谢!
是的,向量范数使权重保持较小,模型稳定/通用。Dropout 迫使层中的其他节点进行泛化。
“过拟合的模型应该显示训练集和测试集的准确率都在增加,并且在某个点上测试集的准确率下降,但训练集的准确率继续上升。”
这一行最后一个词有误,应该是训练集。
顺便说一句,
你做得非常棒。 😀
谢谢,已修复!
嗨,Jason,
在我的情况下,当出现过拟合时,我会在密集层添加一些权重正则化,然后训练数据的损失会增加(R 平方分数下降),但验证数据的损失并没有改善(R 平方保持没有大的变化),最终验证数据和训练数据的损失相似,但都很高。
这正常吗?请问如何处理这种情况?
谢谢你。
也许可以尝试另一种正则化方法
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
首先,非常感谢您的本教程。它确实很有帮助。
其次,我想指出一点,在绘制历史(损失/准确率)时,如果我没记错的话,X 轴应该从“1”而不是“0”开始。因为评估只发生在每个 epoch 结束时。
当然可以。
你好,
循环正则化器是指 LSTM 内存单元与其后的单元之间的权重吗?
权重衰减将在训练期间使模型中的权重变小。这适用于 LSTM、CNN 和 MLP。
在 keras 中,权重衰减 == L2 正则化吗?
是的。
我非常感谢您在这些方面所做的工作……
不过有一个问题:这里(https://fastai.net.cn/2018/07/02/adam-weight-decay/#understanding-adamw-weight-decay-or-l2-regularization)说权重衰减和 L2 正则化仅适用于普通 SGD,但您正在使用 Adam 和 L2 正则化并将其称为权重衰减,如果我理解正确的话——您能澄清一下吗?
这篇文章的意思是基于权重的正则化,当然我们可以用 Adam 和 L2 来实现。您引用的文章说 L2 正则化(在公式中有严格定义)与权重衰减(更像一个概念而不是精确的算法)根据作者的说法是相同的公式。
亲爱的 Jason 先生,
我再次参考您的精彩文章 🙂
我有一个有点奇怪的问题……
我们可以在模型中包含多个正则化层,如下图所示吗?我不知道这种做法是否可行……您能告诉我您的想法吗?
模型 = keras.Sequential([
layers.Dense(20, activation=’relu’),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(10, kernel_regularizer=regularizers.L2(l2=0.01)),
layers.Dense(20, activation=’relu’),
layers.Dense(10, kernel_regularizer=regularizers.L2(l2=0.01)),
layers.Dense(2, activation=’sigmoid’),
])
我不是 Jason,但是是的。
我相信引用的研究模型应该在大多数甚至所有层中使用正则化,但如果我错了请纠正我。