权重约束提供了一种方法,用于减少深度学习神经网络模型在训练数据上的过拟合,并提高模型在新数据(如留存测试集)上的性能。
权重约束有多种类型,例如最大和单位向量范数,其中一些需要配置超参数。
在本教程中,您将了解 Keras API,用于向深度学习神经网络模型添加权重约束以减少过拟合。
完成本教程后,您将了解:
- 如何使用 Keras API 创建向量范数约束。
- 如何使用 Keras API 将权重约束添加到 MLP、CNN 和 RNN 层。
- 如何通过将权重约束添加到现有模型来减少过拟合。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 更新于 2019 年 3 月:修复了在某些使用示例中将赋值误用为等号的拼写错误。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何使用 Keras 中的权重约束减少深度神经网络中的过拟合
照片由 Ian Sane 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Keras 中的权重约束
- 层上的权重约束
- 权重约束案例研究
Keras 中的权重约束
Keras API 支持权重约束。
约束是按层指定的,但应用于层内的每个节点并强制执行。
使用约束通常涉及设置层上的 *kernel_constraint* 参数(用于输入权重)和 *bias_constraint* 参数(用于偏置权重)。
通常,权重约束不用于偏置权重。
一系列不同的向量范数可用作约束,在 keras.constraints 模块 中提供。它们是:
- 最大范数(*max_norm*),强制权重具有等于或小于给定限制的幅度。
- 非负范数(*non_neg*),强制权重具有正幅度。
- 单位范数(*unit_norm*),强制权重具有 1.0 的幅度。
- 最小-最大范数(*min_max_norm*),强制权重具有介于某个范围内的幅度。
例如,可以导入并实例化一个约束:
|
1 2 3 4 |
# 导入范数 from keras.constraints import max_norm # 实例化范数 norm = max_norm(3.0) |
层上的权重约束
权重范数可用于 Keras 中的大多数层。
在本节中,我们将介绍一些常见的示例。
MLP 权重约束
下面的示例为 Dense 全连接层设置了最大范数权重约束。
|
1 2 3 4 5 6 |
# 示例:为 Dense 层设置最大范数约束 from keras.layers import Dense from keras.constraints import max_norm ... model.add(Dense(32, kernel_constraint=max_norm(3), bias_constraint=max_norm(3))) ... |
CNN 权重约束
下面的示例为卷积层设置了最大范数权重约束。
|
1 2 3 4 5 6 |
# 示例:为 CNN 层设置最大范数约束 从 keras.layers 导入 Conv2D from keras.constraints import max_norm ... model.add(Conv2D(32, (3,3), kernel_constraint=max_norm(3), bias_constraint=max_norm(3))) ... |
RNN 权重约束
与其它层类型不同,循环神经网络允许您同时为输入权重和偏置以及循环输入权重设置权重约束。
循环权重的约束通过层的 *recurrent_constraint* 参数进行设置。
下面的示例为 LSTM 层设置了最大范数权重约束。
|
1 2 3 4 5 6 |
# 示例:为 LSTM 层设置最大范数约束 从 keras.layers 导入 LSTM from keras.constraints import max_norm ... model.add(LSTM(32, kernel_constraint=max_norm(3), recurrent_constraint=max_norm(3), bias_constraint=max_norm(3))) ... |
现在我们知道了如何使用权重约束 API,让我们来看一个实际示例。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
权重约束案例研究
在本节中,我们将演示如何使用权重约束来减少 MLP 在一个简单的二分类问题上的过拟合。
此示例提供了一个模板,用于将权重约束应用于您自己的用于分类和回归问题的神经网络。
二分类问题
我们将使用一个标准的二分类问题,该问题定义了两个半圆形的观测点,每个半圆形代表一个类别。
每个观测值都有两个具有相同尺度的输入变量和一个类别输出值0或1。这个数据集被称为“moons”数据集,因为绘制时每个类别中的观测值的形状。
我们可以使用 make_moons() 函数 从这个问题中生成观测点。我们将向数据添加噪声并设置随机数生成器的种子,以便在每次运行时生成相同的样本。
|
1 2 |
# 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) |
我们可以绘制数据集,其中两个变量作为图上的x和y坐标,类别值作为观测值的颜色。
生成数据集并绘制它的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成两个月牙形数据集 from sklearn.datasets import make_moons from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) colors = {0:'red', 1:'blue'} fig, ax = pyplot.subplots() grouped = df.groupby('label') for key, group in grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行示例将创建一个散点图,显示每个类别中观测值的半圆或月牙形。我们可以看到点分散中的噪声使得月牙形不那么明显。
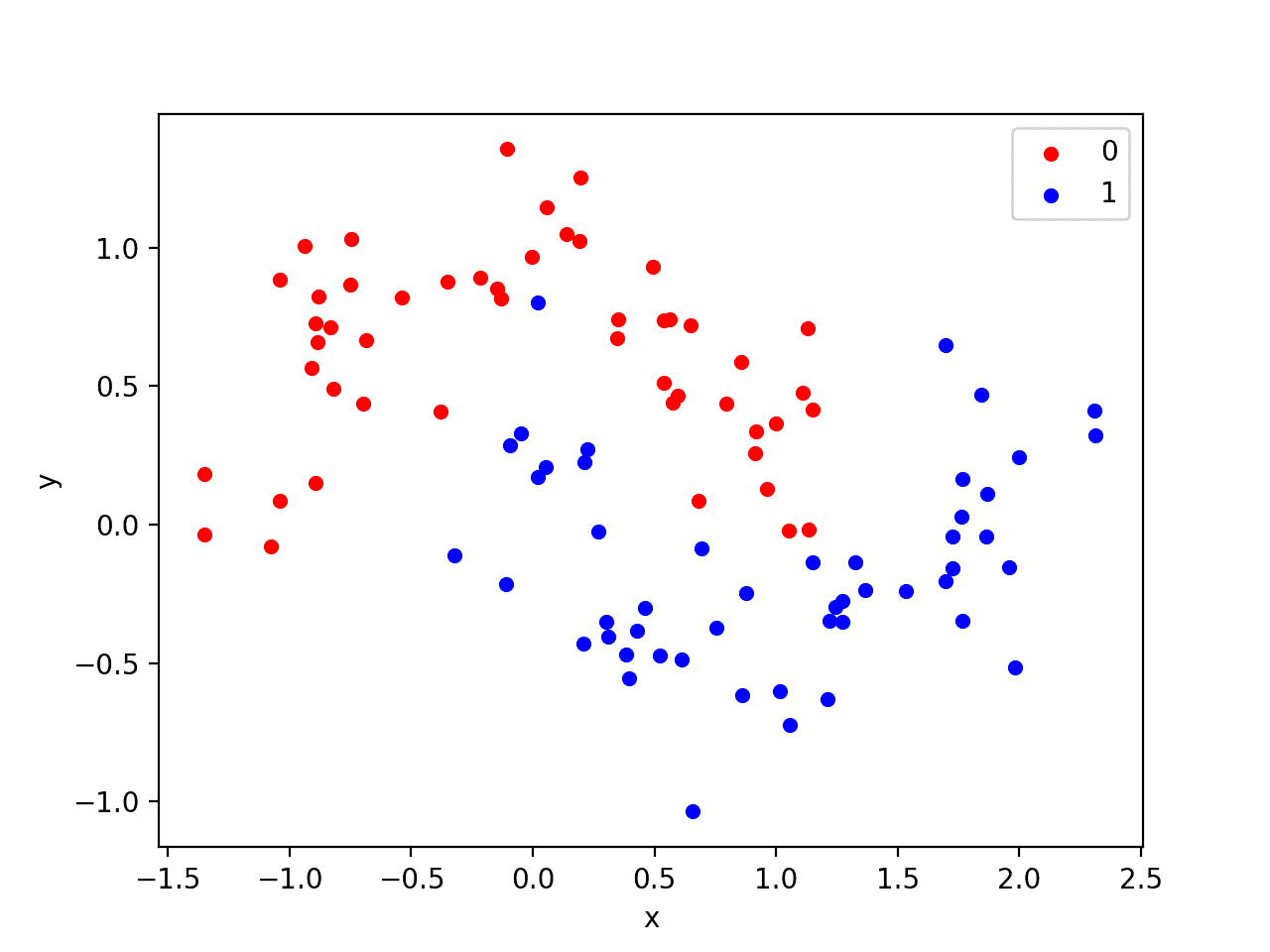
月牙形数据集的散点图,点颜色显示每个样本的类别值
这是一个很好的测试问题,因为这些类别不能用一条线分开,例如,它们不是线性可分的,需要一种非线性方法(如神经网络)来解决。
我们只生成了 100 个样本,对于神经网络来说太少了,这为过拟合训练数据集和在测试数据集上产生更高的误差提供了机会:这是使用正则化的一个好案例。此外,样本带有噪声,这使得模型有机会学习样本中不能泛化的方面。
过拟合多层感知器
我们可以开发一个MLP模型来解决这个二分类问题。
该模型将有一个隐藏层,其节点数可能超过解决此问题所需的数量,从而提供过拟合的机会。我们还将训练模型的时间延长到超过所需时间,以确保模型过拟合。
在定义模型之前,我们将数据集拆分为训练集和测试集,使用30个示例来训练模型,70个示例来评估拟合模型的性能。
|
1 2 3 4 5 6 |
# 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
接下来,我们可以定义模型。
隐藏层使用 500 个节点和 ReLU 激活函数。输出层使用 sigmoid 激活函数,以预测类别值为 0 或 1。
该模型使用二元交叉熵损失函数进行优化,适用于二元分类问题和梯度下降的有效 Adam 版本。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
然后,将定义的模型在训练数据上拟合4,000个周期,并使用默认的批量大小32。
我们还将测试数据集用作验证数据集。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) |
我们可以评估模型在测试数据集上的性能并报告结果。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,我们将绘制每个 epoch 模型在训练集和测试集上的性能。
如果模型确实过拟合了训练数据集,我们预计训练集上的准确度线图将继续增加,而测试集将先上升然后再次下降,因为模型学习了训练数据集中的统计噪声。
|
1 2 3 4 5 |
# 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
我们可以将所有这些部分结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# MLP 在 moons 数据集上的过拟合 from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential from matplotlib import pyplot # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
我们可以看到模型在训练数据集上的性能优于测试数据集,这可能是过拟合的一个迹象。
注意:您的结果可能会因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
由于模型过拟合,我们通常不期望在同一数据集上重复运行模型时,准确率有很大甚至任何差异。
|
1 |
训练:1.000,测试:0.914 |
创建了一个图,显示模型在训练集和测试集上的准确度线图。
我们可以看到一个过拟合模型的预期形状,其中测试准确度会增加到一个点,然后再次开始下降。
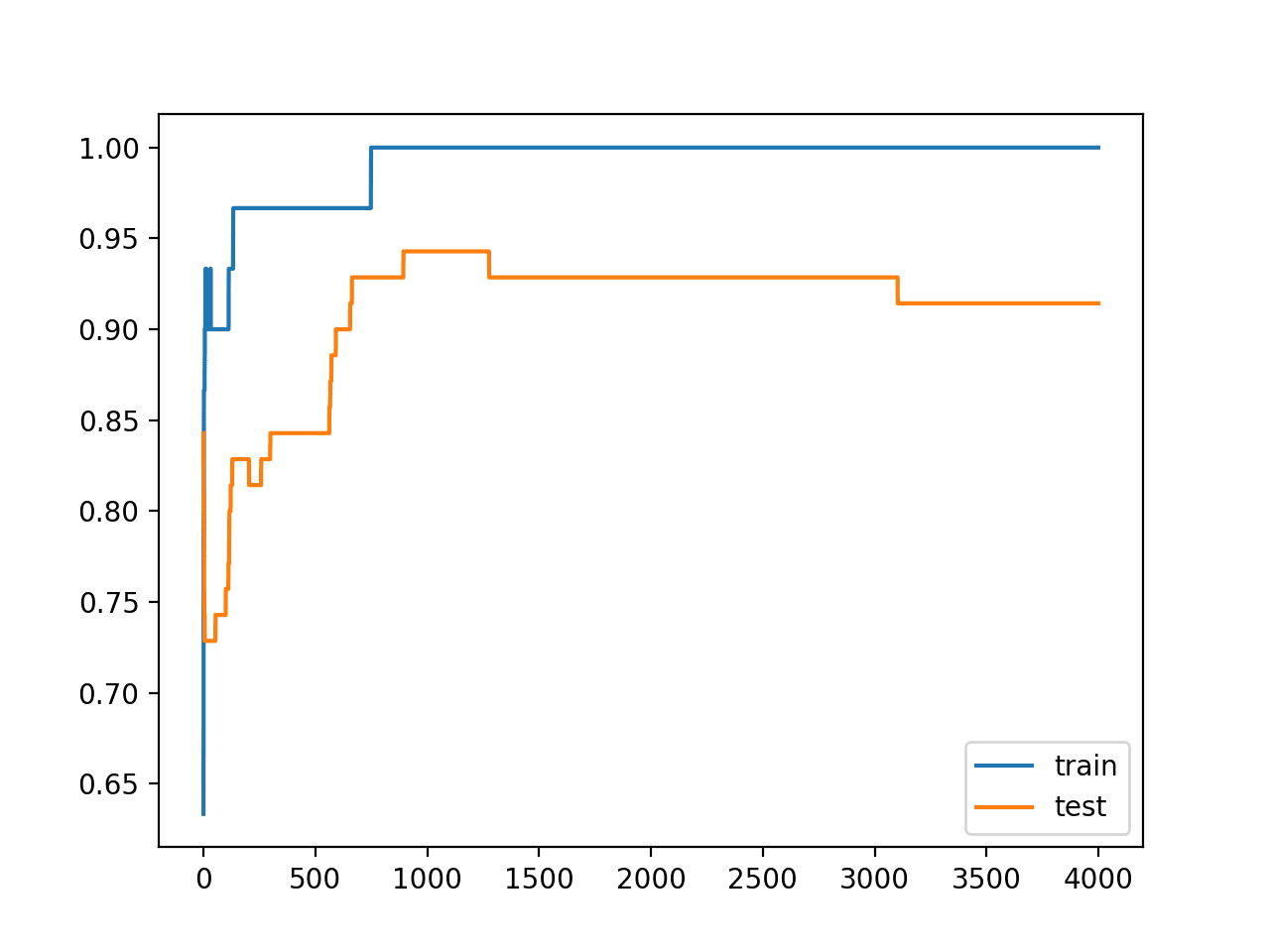
训练期间训练集和测试集准确度线图,显示过拟合
带权重约束的过拟合 MLP
我们可以更新示例以使用权重约束。
有几种不同的权重约束可供选择。对于此模型,一个好的简单约束是简单地对权重进行归一化,使范数等于 1.0。
这种约束的效果是强制所有传入权重都很小。
我们可以通过在 Keras 中使用 *unit_norm* 来做到这一点。此约束可以像下面这样添加到第一个隐藏层:
|
1 |
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm())) |
我们也可以通过使用 *min_max_norm* 并将最小值和最大值设置为 1.0 来达到相同的结果,例如:
|
1 |
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=min_max_norm(min_value=1.0, max_value=1.0))) |
我们无法使用最大范数约束达到相同的结果,因为它允许范数等于或小于指定的限制;例如:
|
1 |
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=max_norm(1.0))) |
下面列出了包含单位范数约束的完整更新示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# MLP 在 moons 数据集上使用单位范数约束进行过拟合 from sklearn.datasets import make_moons from keras.layers import Dense from keras.models import Sequential from keras.constraints import unit_norm from matplotlib import pyplot # 生成二维分类数据集 X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm())) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
注意:您的结果可能会因算法或评估程序的随机性,或数值精度的差异而有所不同。考虑多次运行示例并比较平均结果。
我们可以看到,对权重大小的严格约束确实在不影响训练集性能的情况下提高了模型在留存集上的性能。
|
1 |
训练:1.000,测试:0.943 |
回顾训练和测试准确率的折线图,我们可以看到模型不再像之前那样明显过拟合了训练数据集。
模型在训练集和测试集上的准确率都持续提高并达到平台期。
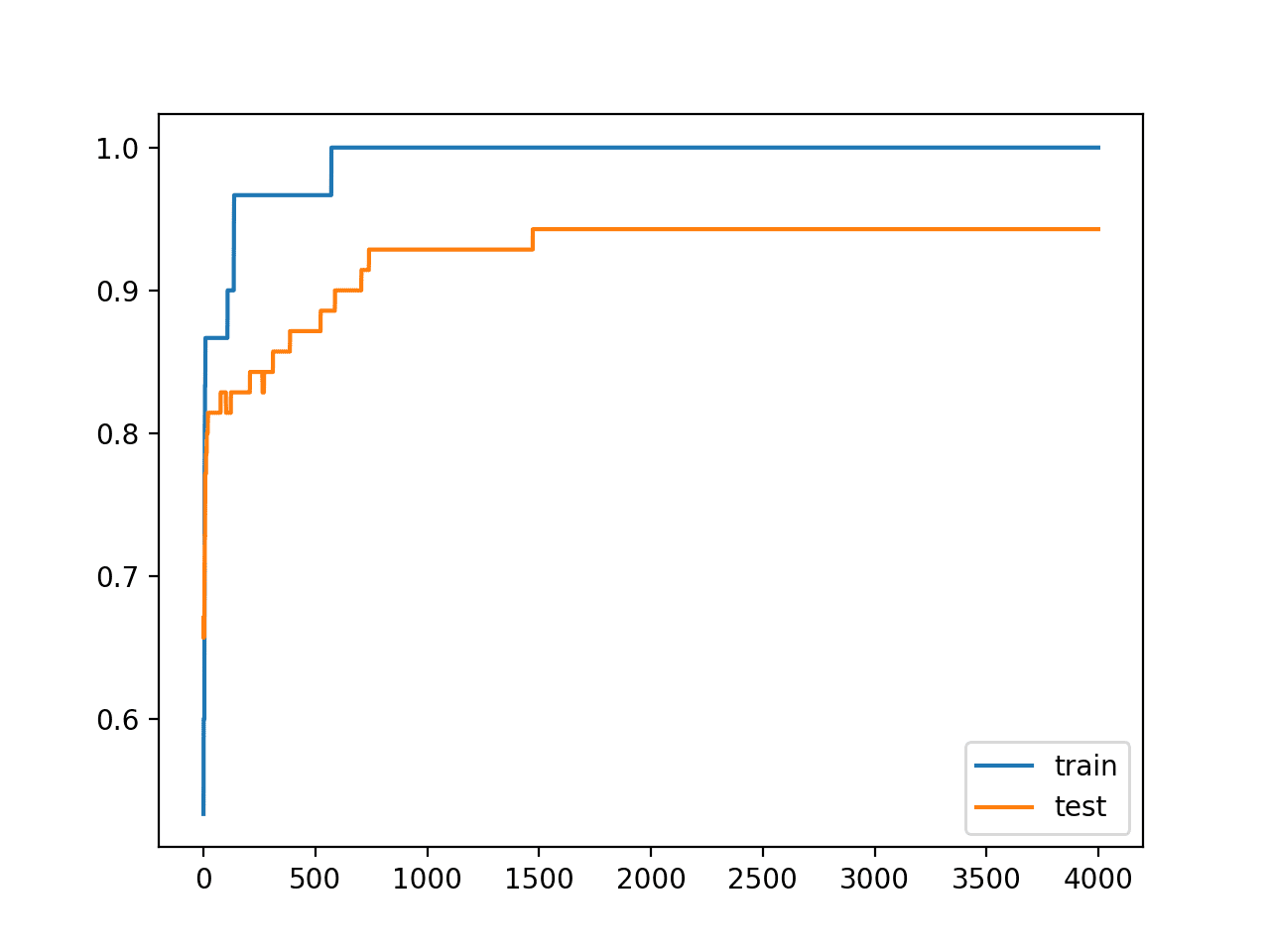
训练期间使用权重约束时,训练集和测试数据集准确率的折线图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 报告权重范数。更新示例以计算网络权重的幅度,并演示约束确实减小了幅度。
- 约束输出层。更新示例以将约束添加到模型的输出层并比较结果。
- 约束偏置。更新示例以将约束添加到偏置权重并比较结果。
- 重复评估。更新示例以多次拟合和评估模型,并报告模型性能的平均值和标准差。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
API
- Keras 约束 API
- Keras constraints.py
- Keras核心层API
- Keras卷积层API
- Keras循环层API
- sklearn.datasets.make_moons API
总结
在本教程中,您了解了 Keras API,用于向深度学习神经网络模型添加权重约束。
具体来说,你学到了:
- 如何使用 Keras API 创建向量范数约束。
- 如何使用 Keras API 将权重约束添加到 MLP、CNN 和 RNN 层。
- 如何通过将权重约束添加到现有模型来减少过拟合。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







梯度裁剪是否类似于权重约束?
很好的问题!
不太对。
权重约束应用于权重,是一种正则化技术。
梯度裁剪应用于用于更新权重的误差梯度,用于避免梯度爆炸。
感谢分享,但为什么像正则化,因为没有惩罚?我认为权重约束更像归一化
是的,就像每次更新后的权重归一化一样。
很棒的文章。这有助于提高 Kaggle 竞赛“Don’t call me turkey!”的预测能力。
祝好,
很高兴听到这个,做得好!
约束每层权重之和为一是否使模型更容易解释?
也许在输入层上,但在隐藏层上可能不行。
如果 kernel_constraint=max_norm(A)。我应该根据什么来设置“A”的值?
尝试一系列小的整数值,通常在 [1,4] 范围内。
应该将它应用于哪个层?因为 CNN 中的大多数网络都更深。有办法弄清楚吗?
应用于所有层。
你好杰森
好帖子!谢谢。
我认为本教程旨在通过“权重约束”来帮助减少过拟合,它与另一个名为“如何使用权重正则化减少深度学习模型的过拟合”的教程密切相关,该教程使用“权重正则化”技术。因此,这两个教程(kernel_constraint vs kernel_regularizer 参数)具有相似的实现和结果。
事实上,它们达到了相同的 94.3% 的测试准确率。
在此意义上,我决定也实现网格搜索“Limiter”超参数分析(此处省略),作为前一篇帖子“Grid Regularizer”的复制,并定义一个 ALPHA 参数列表,其设置值为 = [0.3, 0.6, 0.9, 1., 1.3, 1.6],这些是用于 min_max_norm 等参数的值(ALPHA 对于 min 和 max 都是相同的值)。
我的 Alpha 探索表明,除了参数 1.0(例如 unit_norm)之外,Alpha 参数值 0.9 和 1.3 也能达到相同的最大测试准确率(94.3%),但 Alpha 参数值更高或更低会降低准确率(测试数据为 92.9%)。
谢谢
非常好的发现,做得好!
不错的帖子
谢谢。
如何计算相等错误率?有公式吗?
什么是相等错误率?
嗨,Jason,
我在 CNN 中尝试使用 bias_constraint==max_norm(3),但是 == 会导致错误
SyntaxError: positional argument follows keyword argument
我认为它应该只是 =
是的,使用单个 = 进行赋值。
我已经修复了示例,谢谢。
你好 Jason Brownlee
手动将权重添加到 LSTM 的代码是什么?
model.set_weights()
如何使用 model.set_weights() 与 LSTM(回归)?
如何从 csv 文件添加权重?
你能给我提供代码吗?
非常感谢
抱歉,我没有能力为您准备示例。
为什么你想从 CSV 文件设置模型权重?
因为我从 PSO 算法生成权重,并且我想将它们放入 csv,然后尝试将它们加载到 LSTM 中。
我明白了。在最开始不使用 LSTM 结构的情况下,你如何评估权重?
嗨,Jason,
当使用 max_norm 等约束时,您是在处理权重向量 w 的范数,对吗?如果我也想对单个权重(即向量元素 w_i)施加约束,该怎么办?
例如,我想让输入层的向量范数等于 1,但我也想让该层的所有单个权重都在 0 和 0.05 之间,比如。
在只有一层输入、一层隐藏和一层输出的简单情况下,您将如何实现这一点?我是否遗漏了什么明显的东西?
是的。
听起来您在描述权重裁剪。
也许这篇博文中缺少的是对 max_norm() 规范中 axis= 参数的讨论。
axis/axes 的不同选择会导致不同强度和含义的约束。在某些情况下,一些选择比其他选择更有说服力。
https://tensorflowcn.cn/api_docs/python/tf/keras/constraints/MaxNorm
您可以在这里了解更多关于 axis 参数的信息
https://machinelearning.org.cn/numpy-axis-for-rows-and-columns/
权重约束是否只能用于输入权重,那卷积核权重呢?
我想知道是否可以使用此约束来对训练后量化设置输入权重的最小值和最大值。
权重约束可以与网络中的任何权重一起使用。
通常,它们是逐层指定的。
核约束可以应用于每个层(隐藏层),范数值是否应该成为前一层节点数的函数?
例如,有两个隐藏层,分别是 500 和 10。如果对两者都应用单位范数,那么第一隐藏层的权重将远小于第二层。那么,是否建议改变范数值,使得权重在不同隐藏层之间保持相同的幅度?
期待您的回复,我在任何地方都找不到答案。
不行。