Dropout 正则化是一种计算开销小,可以正则化深度神经网络的方法。
Dropout 的工作原理是,以概率方式移除(或“丢弃”)层的输入,这些输入可以是数据样本中的输入变量,也可以是前一层中的激活值。它具有模拟大量具有非常不同网络结构的网络的效应,从而使网络中的节点通常对输入更具鲁棒性。
在本教程中,您将了解 Keras API,用于向深度学习神经网络模型添加 Dropout 正则化。
完成本教程后,您将了解:
- 如何使用 Keras API 创建 Dropout 层。
- 如何使用 Keras API 向 MLP、CNN 和 RNN 层添加 Dropout 正则化。
- 如何通过向现有模型添加 Dropout 正则化来减少过拟合。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 10 月更新:更新至 Keras 2.3 和 TensorFlow 2.0。

如何在 Keras 中使用 Dropout 正则化减少过拟合
图片由 PROJorge Láscar 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- Keras 中的 Dropout 正则化
- 层上的 Dropout 正则化
- Dropout 正则化案例研究
Keras 中的 Dropout 正则化
Keras 支持 Dropout 正则化。
Keras 中最简单的 Dropout 形式由 Dropout 核心层提供。
创建时,可以将 Dropout 率指定给层,作为将层中的每个输入设置为零的概率。这与论文中 Dropout 率的定义不同,论文中,该率指的是保留输入的概率。
因此,当论文中建议 Dropout 率为 0.8(保留 80%)时,这实际上将是 0.2 的 Dropout 率(将 20% 的输入设置为零)。
下面是创建一个 Dropout 层,其中有 50% 的机会将输入设置为零的示例。
|
1 |
层 = Dropout(0.5) |
层上的 Dropout 正则化
Dropout 层添加到现有层之间,并应用于馈送到后续层的前一层的输出。
例如,给定两个全连接层
|
1 2 3 4 |
... 模型.append(Dense(32)) 模型.append(Dense(32)) ... |
我们可以在它们之间插入一个 Dropout 层,在这种情况下,第一层的输出或激活值将应用 Dropout,然后作为下一层的输入。
现在是第二层应用了 Dropout。
|
1 2 3 4 5 |
... 模型.append(Dense(32)) 模型.append(Dropout(0.5)) 模型.append(Dense(32)) ... |
Dropout 也可以应用于可见层,例如网络的输入。
这要求您将 Dropout 层定义为第一层,并向该层添加 *input_shape* 参数以指定输入样本的预期形状。
|
1 2 3 |
... 模型.add(Dropout(0.5, input_shape=(2,))) ... |
让我们来看看 Dropout 正则化如何与一些常见的网络类型一起使用。
MLP Dropout 正则化
以下示例在两个密集全连接层之间添加了 Dropout。
|
1 2 3 4 5 6 7 8 |
# 全连接层之间 Dropout 的示例 from keras.layers import Dense from keras.layers import Dropout ... 模型.add(Dense(32)) 模型.add(Dropout(0.5)) 模型.add(Dense(1)) ... |
CNN Dropout 正则化
Dropout 可以在卷积层(例如 Conv2D)之后和池化层(例如 MaxPooling2D)之后使用。
通常,Dropout 仅在池化层之后使用,但这只是一个粗略的启发式方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# CNN 的 Dropout 示例 from keras.layers import Dense 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D from keras.layers import Dropout ... 模型.add(Conv2D(32, (3,3))) 模型.add(Conv2D(32, (3,3))) 模型.add(MaxPooling2D()) 模型.add(Dropout(0.5)) 模型.add(Dense(1)) ... |
在这种情况下,Dropout 应用于特征图中的每个元素或单元。
另一种使用卷积神经网络的 Dropout 方法是,从卷积层中丢弃整个特征图,这些特征图在池化过程中将不再使用。这称为空间 Dropout(或“*SpatialDropout*”)。
相反,我们提出了一种新的 Dropout 方法,我们称之为 SpatialDropout。对于给定的卷积特征张量 […] [我们] 将 Dropout 值扩展到整个特征图。
— 使用卷积网络进行高效目标定位,2015。
Keras 通过 SpatialDropout2D 层(以及 1D 和 3D 版本)提供空间 Dropout。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# CNN 的空间 Dropout 示例 from keras.layers import Dense 从 keras.layers 导入 Conv2D 从 keras.layers 导入 MaxPooling2D 从 keras.layers 导入 SpatialDropout2D ... 模型.add(Conv2D(32, (3,3))) 模型.add(Conv2D(32, (3,3))) 模型.add(SpatialDropout2D(0.5)) 模型.add(MaxPooling2D()) 模型.add(Dense(1)) ... |
RNN Dropout 正则化
以下示例在两个层之间添加了 Dropout:一个 LSTM 循环层和一个密集全连接层。
|
1 2 3 4 5 6 7 8 9 |
# LSTM 和全连接层之间 Dropout 的示例 from keras.layers import Dense 从 keras.layers 导入 LSTM from keras.layers import Dropout ... 模型.add(LSTM(32)) 模型.add(Dropout(0.5)) 模型.add(Dense(1)) ... |
此示例将 Dropout 应用于 LSTM 层的 32 个输出(在本例中)作为密集层的输入。
或者,LSTM 的输入可能会受到 Dropout 的影响。在这种情况下,不同的 Dropout 掩码应用于呈现给 LSTM 的每个样本中的每个时间步。
|
1 2 3 4 5 6 7 8 9 |
# LSTM 层之前的 Dropout 示例 from keras.layers import Dense 从 keras.layers 导入 LSTM from keras.layers import Dropout ... 模型.add(Dropout(0.5, input_shape=(...))) 模型.add(LSTM(32)) 模型.add(Dense(1)) ... |
还有一种使用 LSTM 等循环层的 Dropout 的替代方法。LSTM 可以对样本中的所有输入使用相同的 Dropout 掩码。对于样本的时间步长中的循环输入连接,也可以使用相同的方法。这种使用循环模型的 Dropout 方法称为变分 RNN。
所提出的技术(变分 RNN […])在每个时间步使用相同的 Dropout 掩码,包括循环层。[…] 实施我们的近似推理与在 RNN 中实施 Dropout 相同,每个时间步都丢弃相同的网络单元,随机丢弃输入、输出和循环连接。这与现有技术形成对比,现有技术中,不同的网络单元将在不同的时间步被丢弃,并且不会对循环连接应用 Dropout
— 循环神经网络中 Dropout 的理论基础应用,2016。
Keras 通过循环层上的两个参数支持变分 RNN(即对于输入和循环输入,样本的时间步长中一致的 Dropout),即用于输入的“*dropout*”和用于循环输入的“*recurrent_dropout*”。
|
1 2 3 4 5 6 7 8 |
# 变分 LSTM Dropout 示例 from keras.layers import Dense 从 keras.layers 导入 LSTM from keras.layers import Dropout ... 模型.add(LSTM(32, dropout=0.5, recurrent_dropout=0.5)) 模型.add(Dense(1)) ... |
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Dropout 正则化案例研究
在本节中,我们将演示如何使用 Dropout 正则化来减少 MLP 在简单二分类问题上的过拟合。
此示例提供了一个模板,用于将 Dropout 正则化应用于您自己的神经网络以解决分类和回归问题。
二分类问题
我们将使用一个标准的二分类问题,该问题定义了两个二维同心圆的观测值,每个类别一个圆。
每个观测值都有两个具有相同比例的输入变量和一个类别输出值 0 或 1。由于绘制时每个类别中观测值的形状,此数据集称为“*circles*”数据集。
我们可以使用 make_circles() 函数从此问题生成观测值。我们将向数据添加噪声并为随机数生成器设置种子,以便每次运行代码时都会生成相同的样本。
|
1 2 |
# 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) |
我们可以绘制数据集,其中两个变量作为图上的x和y坐标,类别值作为观测值的颜色。
生成数据集并绘制它的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 生成两个圆数据集 from sklearn.datasets import make_circles from matplotlib import pyplot from pandas import DataFrame # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 散点图,点按类别值着色 df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y)) 颜色 = {0:'red', 1:'blue'} fig, ax = pyplot.subplots() grouped = df.groupby('label') 对于 键, 组 在 grouped: group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key]) pyplot.show() |
运行示例会创建一个散点图,显示每个类别中观测值的同心圆形状。我们可以看到点的分散中的噪声使得圆圈不那么明显。
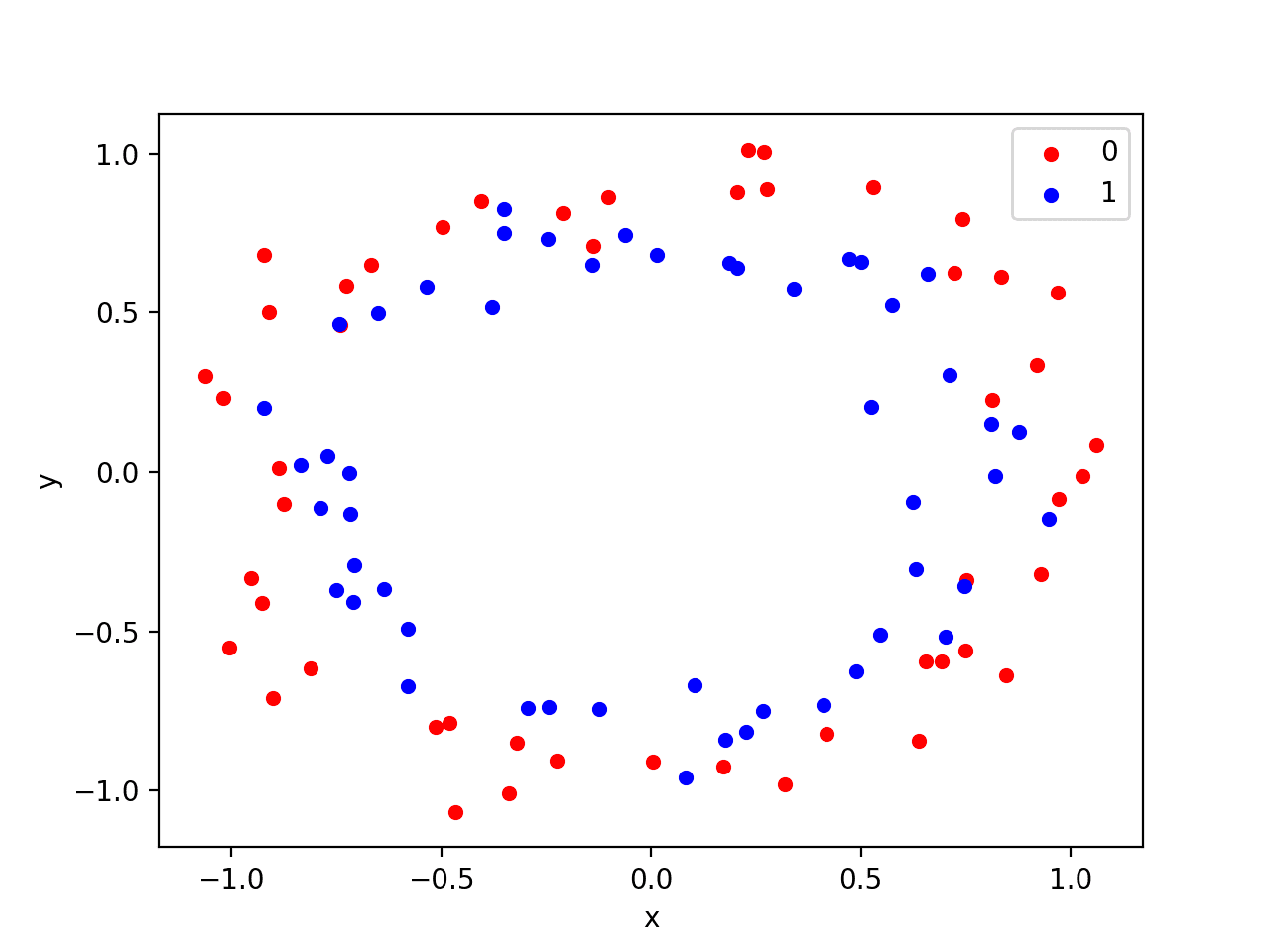
带有颜色显示每个样本类别值的圆数据集散点图
这是一个很好的测试问题,因为这些类别不能用一条线分开,例如,它们不是线性可分的,需要一种非线性方法(如神经网络)来解决。
我们只生成了 100 个样本,这对于神经网络来说太少了,这提供了过拟合训练数据集并在测试数据集上产生更高错误的机会:这是使用正则化的一个很好的例子。此外,样本具有噪声,使得模型有机会学习不泛化的样本的方面。
过拟合多层感知器
我们可以开发一个MLP模型来解决这个二分类问题。
该模型将有一个隐藏层,其节点数可能超过解决此问题所需的数量,从而提供过拟合的机会。我们还将训练模型的时间延长到超过所需时间,以确保模型过拟合。
在定义模型之前,我们将数据集拆分为训练集和测试集,使用30个示例来训练模型,70个示例来评估拟合模型的性能。
|
1 2 3 4 5 6 |
# 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] |
接下来,我们可以定义模型。
隐藏层使用 500 个节点,并使用 ReLU 激活函数。输出层使用 Sigmoid 激活函数,以预测类别值 0 或 1。
该模型使用二元交叉熵损失函数进行优化,适用于二元分类问题和梯度下降的有效 Adam 版本。
|
1 2 3 4 5 |
# 定义模型 model = Sequential() 模型.add(Dense(500, input_dim=2, activation='relu')) 模型.add(Dense(1, activation='sigmoid')) 模型.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
然后,将定义的模型在训练数据上拟合4,000个周期,并使用默认的批量大小32。
我们还将测试数据集用作验证数据集。
|
1 2 |
# 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) |
我们可以评估模型在测试数据集上的性能并报告结果。
|
1 2 3 4 |
# 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) |
最后,我们将绘制每个 epoch 模型在训练集和测试集上的性能。
如果模型确实过拟合了训练数据集,我们预计训练集上的准确度线图将继续增加,而测试集将先上升然后再次下降,因为模型学习了训练数据集中的统计噪声。
|
1 2 3 4 5 |
# 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
我们可以将所有这些部分结合起来;完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# MLP 在两个圆数据集上过拟合 from sklearn.datasets import make_circles from keras.layers import Dense from keras.models import Sequential from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() 模型.add(Dense(500, input_dim=2, activation='relu')) 模型.add(Dense(1, activation='sigmoid')) 模型.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
我们可以看到模型在训练数据集上的性能优于测试数据集,这可能是过拟合的一个迹象。
注意:由于算法或评估过程的随机性,或数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
因为模型严重过拟合,我们通常不期望在相同数据集上重复运行模型时,准确性会有很大(如果有的话)差异。
|
1 |
训练:1.000,测试:0.757 |
创建了一个图,显示模型在训练集和测试集上的准确度线图。
我们可以看到一个过拟合模型的预期形状,其中测试准确度会增加到一个点,然后再次开始下降。
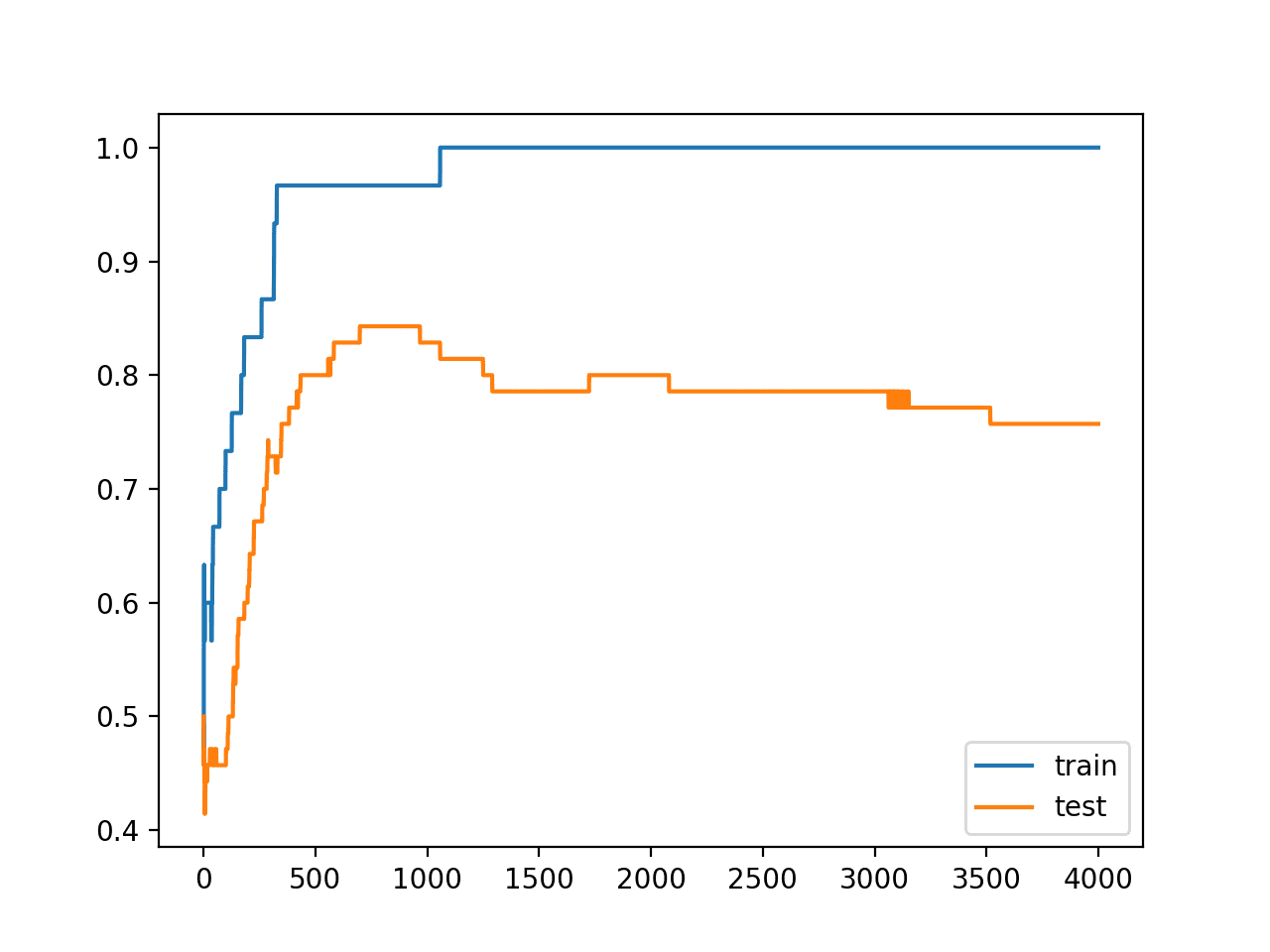
训练期间训练集和测试集准确度线图,显示过拟合
带 Dropout 正则化的过拟合 MLP
我们可以更新示例以使用 Dropout 正则化。
我们可以通过简单地在隐藏层和输出层之间插入一个新的 Dropout 层来做到这一点。在这种情况下,我们将丢弃率(将隐藏层输出设置为零的概率)指定为 40% 或 0.4。
|
1 2 3 4 5 6 |
# 定义模型 model = Sequential() 模型.add(Dense(500, input_dim=2, activation='relu')) 模型.add(Dropout(0.4)) 模型.add(Dense(1, activation='sigmoid')) 模型.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
下面列出了在隐藏层之后添加 Dropout 的完整更新示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 带有 Dropout 的 MLP 在两个圆数据集上 from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 Dropout from matplotlib import pyplot # 生成二维分类数据集 X, y = make_circles(n_samples=100, noise=0.1, random_state=1) # 分割成训练集和测试集 n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # 定义模型 model = Sequential() 模型.add(Dense(500, input_dim=2, activation='relu')) 模型.add(Dropout(0.4)) 模型.add(Dense(1, activation='sigmoid')) 模型.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 拟合模型 history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0) # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # 绘制历史记录 pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show() |
运行示例会报告模型在训练数据集和测试数据集上的性能。
注意:由于算法或评估过程的随机性,或数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种特殊情况下,我们可以看到 Dropout 导致训练数据集的准确度略有下降,从 100% 降至 96%,并且测试集的准确度有所提高,从 75% 升至 81%。
|
1 |
训练:0.967,测试:0.814 |
回顾训练期间训练和测试准确度线图,我们可以看到模型似乎不再过拟合训练数据集。
模型在训练集和测试集上的准确度继续增加到一个平台,尽管在训练期间使用了 Dropout,但仍有许多噪声。
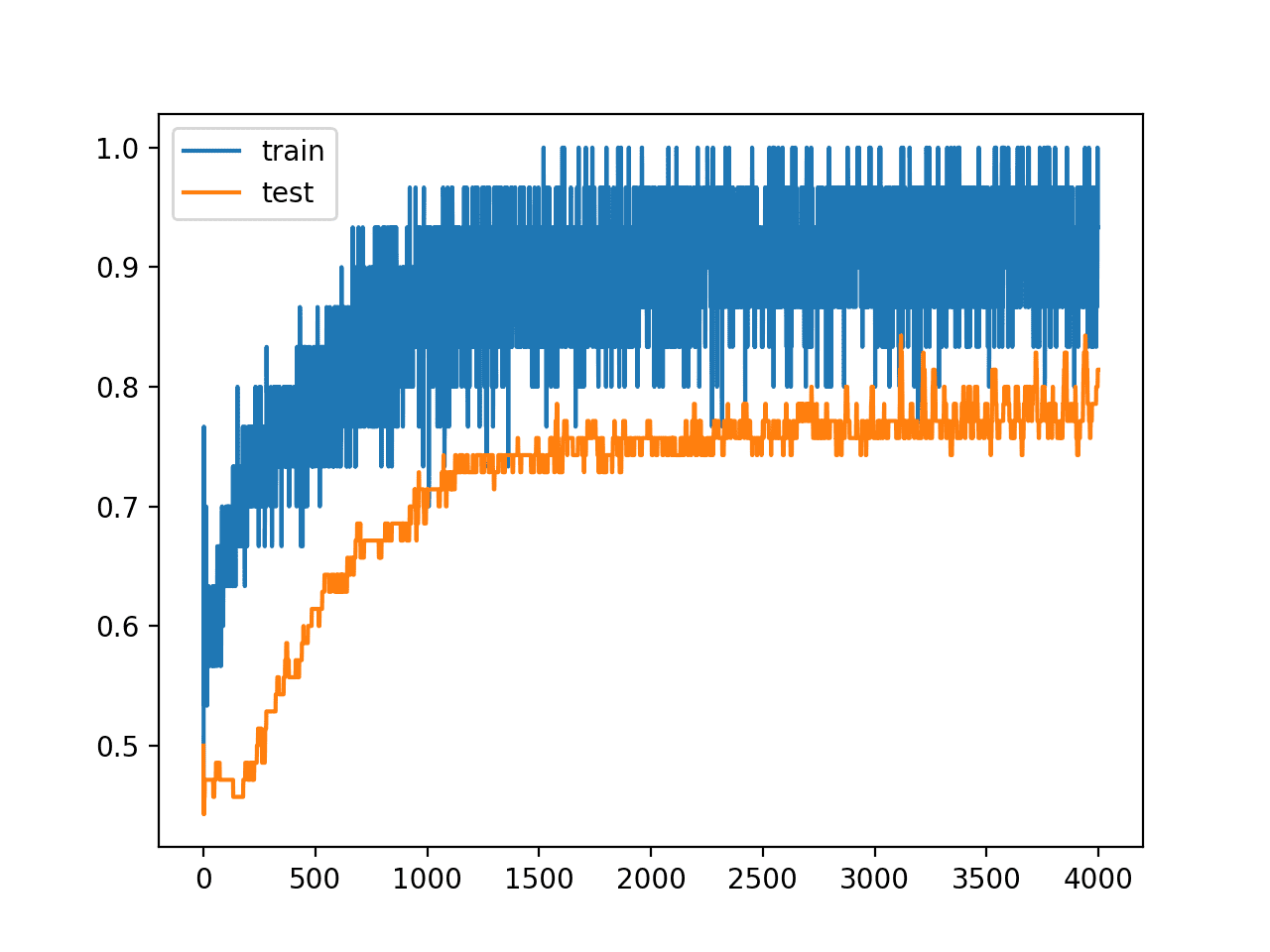
训练期间训练集和测试集准确度线图,带有 Dropout 正则化
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 输入 Dropout。更新示例以在输入变量上使用 Dropout 并比较结果。
- 权重约束。更新示例以向隐藏层添加最大范数权重约束并比较结果。
- 重复评估。更新示例以重复评估过拟合和 Dropout 模型,并总结和比较平均结果。
- 网格搜索率。开发 Dropout 概率的网格搜索,并报告 Dropout 率和测试集准确度之间的关系。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 使用卷积网络进行高效目标定位, 2015.
- 循环神经网络中 Dropout 的理论基础应用, 2016.
文章
API
总结
在本教程中,您学习了 Keras API,用于向深度学习神经网络模型添加 Dropout 正则化。
具体来说,你学到了:
- 如何使用 Keras API 创建 Dropout 层。
- 如何使用 Keras API 向 MLP、CNN 和 RNN 层添加 Dropout 正则化。
- 如何通过向现有模型添加 Dropout 正则化来减少过拟合。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






嗨,Jason,
我正在撰写一篇关于深度学习的学期论文,我想使用您的这张图“训练时训练集和测试集准确度线图,显示过拟合”来说明过拟合问题。我是否可以引用它?非常感谢。
没问题,请看这里
https://machinelearning.org.cn/faq/single-faq/how-do-i-reference-or-cite-a-book-or-blog-post
尊敬的 Jason,非常感谢您的许可和信息。干杯 🙂
你好 Jason,感谢您这篇精彩的文章!我想知道变分 dropout 的实现是否正确。据我所知,要实现变分 dropout,您必须将相同的 dropout 掩码应用于输入、循环连接和输出。目前我正在 Keras 中设计一个两层双向 GRU。我也想应用变分 dropout,并想知道我是否也必须在每一层之后添加一个具有相同 dropout 掩码的 dropout 层?!
所以代码将是
model_input = Input(shape=(seq_len, ))
embedding_a = Embedding(len(port_fwd_dict), 50, input_length=seq_len, mask_zero=True (model_input)
gru_a = Bidirectional(GRU(25, dropout=0.2,recurrent_dropout=0.2return_sequences=True,implementation=2, reset_after=True, recurrent_activation=’sigmoid’), merge_mode=”concat”)(embedding_a)
dropout_a = Dropout(0.2)(gru_a)
gru_b = Bidirectional(GRU(25, dropout=0.2, recurrent_dropout=0.2,return_sequences=False, activation=”relu”, implementation=2, reset_after=True, recurrent_activation=’sigmoid’), merge_mode=”concat”)(dropout_a)
dropout_b = Dropout(0.2)(gru_b)
dense_layer = Dense(100, activation=”linear”)(dropout_b)
dropout_c = Dropout(0.2)(dense_layer)
model_output = Dense(len(port_fwd_dict)-1, activation=”softmax”)(dropout_c)
我需要在每个 GRU 层之后添加 dropout 层吗?
提前感谢您的帮助。非常感谢!
不,我不建议混合使用 Dropout 层和循环 Dropout。
感谢您的快速回复。即使在密集层和输出层之间也不行吗?还是这无关紧要?
您可以尝试一下,并根据结果指导您。
听起来不错,非常感谢您的帮助。由于我需要 Gal 和 Ghahramani 的变分 dropout 的正确 Keras 实现,我想知道如何在 Keras GRU 中正确实现它?!论文中说应该对输入、循环连接和输出应用 dropout。您只对输入和循环连接实现了“变分 dropout”。如果我想完全按照论文中的方法对两层 GRU 应用该技术,我是否应该在每个 GRU 层之后使用一个 dropout 输出层,该层对“输出”应用 dropout,如论文中所述?我是这个领域的新手,在互联网上找不到任何关于如何完全按照 Gal 和 Ghahramani 提出的方法实现它的信息?!我是否需要设置任何其他参数,例如“有状态”?总结一下:我的实验需要变分 dropout 在 Keras 中的确切实现,如果您能验证我的方法,我将不胜感激。提前感谢!
也许论文作者有一个您可以找到并进行比较的参考实现?
甚至可以联系论文作者并确认您对他们方法的理解?
Hi Jason,我也想在测试数据上实现变分 dropout。在您的示例中,变分 dropout 是否应用于测试数据?我尝试过 model.add(dropout(training=True)),它可以将 dropout 应用于测试数据。我也尝试过 model.add(LSTM(dropout=0.2)),但无法将 dropout 应用于测试数据。
通常,您可以添加一个 dropout 层,例如:
model.add(Dropout(0.2, training=True))
我认为您无法通过 LSTM 层中的 dropout 实现相同的功能。
尊敬的 Jason 教授
如果我在深度模型中使用 dropout 结果却没有改善呢?
问题可能出在哪里?标签(数据集标注)可能会影响结果吗?
我的模型是分类深度模型,基于 text 的 word2vec 特征,我在平衡数据集上尝试了所有深度模型构建,结果在测试中从未好转……尽管我在训练中得到了 0.014 的损失,但测试损失达到了 1.4030,这是一个非常大的值。我想上传结果图,但我不知道怎么做……谢谢
Dropout 旨在减少过拟合。您可能还有其他可以诊断的问题,或者您甚至可能需要不同的正则化方法来解决您的过拟合问题。
改善神经网络性能的一个很好的起点在这里
https://machinelearning.org.cn/start-here/#better
你好 Jason,感谢你提供这篇非常有用的文章。
我有一个疑问,如果我保存我的 Keras 模型以便通过将其导入到另一个文件来使用 .predict() 函数,我是否需要以某种方式禁用这些 dropout 层?预测时有 50% 的机会丢弃输入似乎不正确。直观上它们似乎应该只用于训练,或者我漏掉了什么?
谢谢
好问题。
不,dropout 层知道在推理(进行预测)期间不应使用它们。
提问是令人愉快的
如果你没有完全理解什么,然而这篇文章提供了很好的
理解力。
谢谢!
.
疑问。
如果模型的准确度图上有尖峰,那么我们可以推断出什么
数据集
&
模型用于训练它?
什么也推断不出。你到底是什么意思?