Weka使学习应用机器学习变得简单、高效且有趣。它是一个GUI工具,允许您加载数据集、运行算法并设计和运行具有统计上足够鲁棒以供发布的实验。
我向机器学习初学者推荐Weka,因为它能让他们专注于学习应用机器学习的流程,而不是陷入数学和编程 — 这些可以以后再学。
在这篇文章中,我想向您展示加载数据集、运行高级分类算法和审查结果有多么容易。
如果您跟着操作,您将在5分钟内获得机器学习结果,并具备尝试更多数据集和更多算法的知识和信心。
通过我的新书《Weka机器学习精通》来启动您的项目,其中包含分步教程和所有示例的清晰屏幕截图。
1. 下载并安装Weka
访问Weka下载页面,找到适合您计算机的版本(Windows、Mac或Linux)。
Weka需要Java。您可能已经安装了Java,如果没有,下载页面上列出了Weka的版本(适用于Windows),其中包含Java并会为您安装。我自己使用的是Mac,像Mac上的所有东西一样,Weka开箱即用。
如果您对机器学习感兴趣,那么我知道您可以弄清楚如何下载和安装软件到您自己的计算机上。如果您在安装Weka时需要帮助,请参阅以下提供分步说明的帖子
2. 启动Weka
启动Weka。这可能涉及在程序启动器中找到它,或双击 weka.jar 文件。这将启动 Weka GUI 选择器。
Weka GUI 选择器让您可以选择 Explorer、Experimenter、KnowledgeExplorer 和 Simple CLI(命令行界面)中的一个。
Weka GUI 选择器
点击“Explorer”按钮启动Weka Explorer。
这个GUI允许您加载数据集并运行分类算法。它还提供其他功能,如数据过滤、聚类、关联规则提取和可视化,但我们现在不使用这些功能。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
3. 打开 data/iris.arff 数据集
点击“Open file…”按钮打开数据集,然后双击“data”目录。
Weka提供了许多小型常见机器学习数据集供您练习。
选择“iris.arff”文件加载Iris数据集。
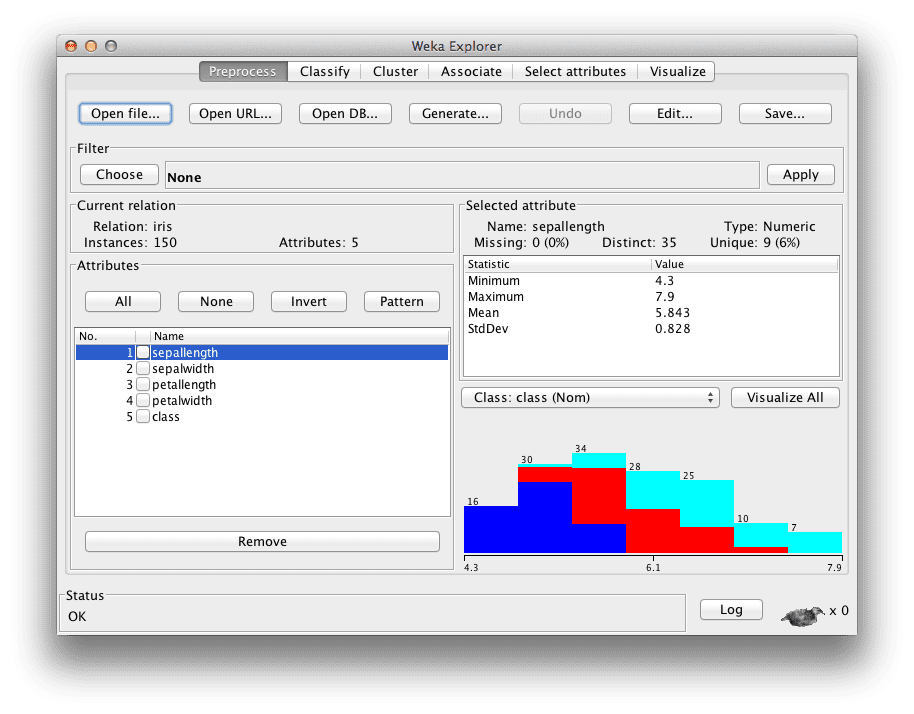
加载鸢尾花数据集的Weka Explorer界面
Iris花卉数据集是统计学中一个著名的数据集,被机器学习研究人员广泛借用。它包含150个实例(行)和4个属性(列),以及一个用于鸢尾花品种(setosa、versicolor和virginica之一)的类属性。您可以在Wikipedia上的Iris花卉数据集上阅读更多关于它的信息。
4. 选择并运行算法
现在您已经加载了数据集,是时候选择一个机器学习算法来建模问题并进行预测了。
点击“Classify”选项卡。这是在Weka中针对已加载数据集运行算法的区域。
您会注意到“ZeroR”算法是默认选中的。
点击“Start”按钮运行该算法。
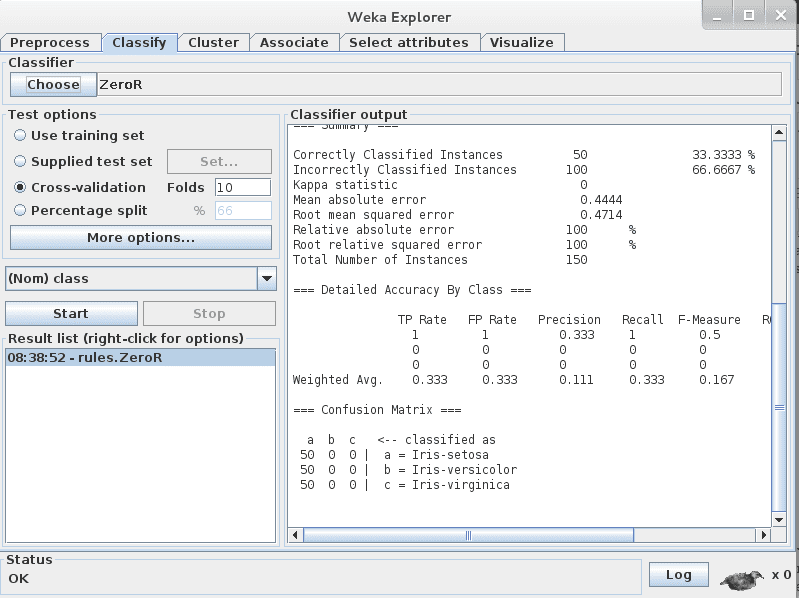
Weka在Iris花卉数据集上运行ZeroR算法的结果
ZeroR算法选择数据集中最常见的类别(数据中所有三个鸢尾花物种的比例相等,因此它选择第一个:setosa),并用它来进行所有预测。这是该数据集的基准,也是所有算法都可以与之比较的度量。结果是33%,正如预期的那样(3个类别,每个类别平均分布,将其中一个分配给每个预测,结果分类准确率为33%)。
您还会注意到,测试选项默认选择交叉验证,折数为10。这意味着数据集被分成10个部分:前9个用于训练算法,第10个用于评估算法。此过程重复进行,允许数据集的10个部分都有机会成为保留的测试集。您可以在这里阅读更多关于交叉验证的信息。
ZeroR算法很重要,但也很无聊。
点击“Classifier”部分中的“Choose”按钮,然后点击“trees”,再点击“J48”算法。
这是Java中C4.8算法的实现(“J”代表Java,“48”代表C4.8,因此得名J48),并且是著名C4.5算法的一个小扩展。您可以在这里阅读更多关于C4.5算法的信息。
点击“Start”按钮运行算法。
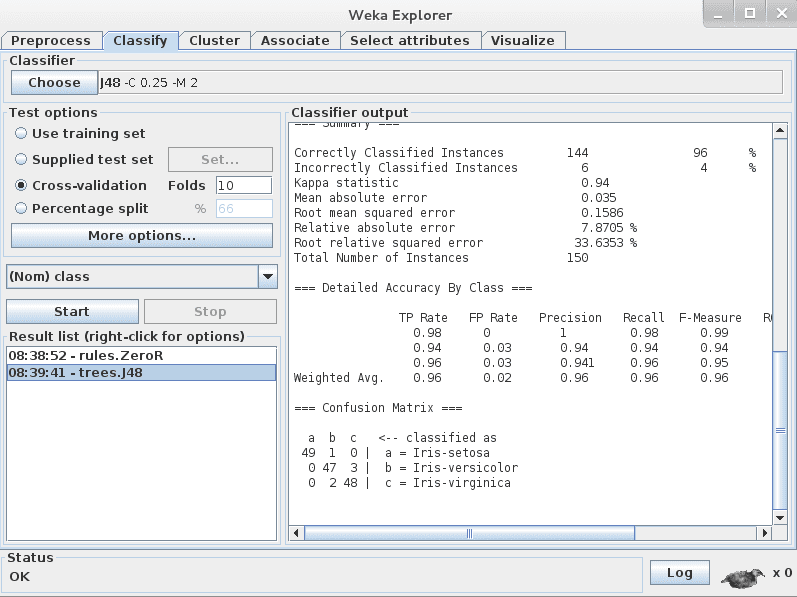
Weka J48算法在Iris花卉数据集上的结果
5. 审阅结果
运行J48算法后,您可以在“Classifier output”部分注意到结果。
该算法使用10折交叉验证运行:这意味着它有机会为数据集中的每个实例进行预测(使用不同的训练折),并且呈现的结果是这些预测的摘要。
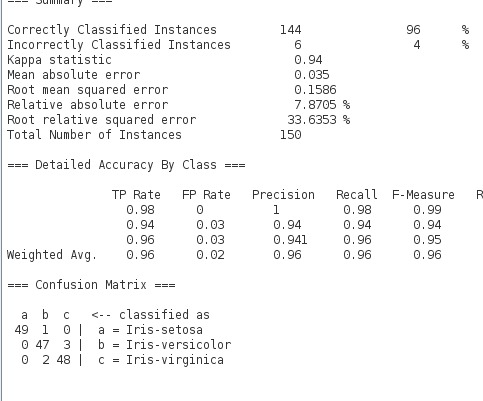
仅Weka中J48算法在Iris花卉数据集上的结果
首先,请注意分类准确率。您可以看到模型取得了144/150次正确的结果,即96%,这比33%的基准好很多。
其次,查看混淆矩阵。您可以看到实际类别与预测类别进行比较的表格,并且可以看到有1例Iris-setosa被错误分类为Iris-versicolor,2例Iris-virginica被错误分类为Iris-versicolor,以及3例Iris-versicolor被错误分类为Iris-setosa(总共6个错误)。此表有助于解释算法实现的准确性。
总结
在这篇文章中,您在Weka中加载了您的第一个数据集并运行了您的第一个机器学习算法(C4.8算法的实现)。ZeroR算法不算数:它只是一个有用的基准。
您现在知道如何加载Weka附带的数据集以及如何运行算法:继续尝试不同的算法,看看您能取得什么结果。
如果您在Iris数据集上能达到96%以上的准确率,请在评论区留言。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗯,只是学习工具等,但使用上述设置,我将测试选项更改为“Use Training Set”并获得了98%的准确率。
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.980 0.020 0.961 0.980 0.970 0.955 0.990 0.969 Iris-versicolor
0.960 0.010 0.980 0.960 0.970 0.955 0.990 0.970 Iris-virginica
加权平均值 0.980 0.010 0.980 0.980 0.980 0.970 0.993 0.980
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
我通过10折的相同交叉验证设置,还获得了97.3%的多层感知器。
Sandra,你做得真棒!
将测试选项更改为“use training set”改变了实验的性质,结果实际上没有可比性。此更改告诉您模型在训练数据上(已经知道答案)的表现如何。
这对于您创建描述性模型很有用,但对于您想使用该模型进行预测则没有帮助。为了了解它在预测方面的能力,我们需要在它“见过”但必须进行预测的数据上进行测试,然后才能与实际结果进行比较。交叉验证可以为我们做到这一点(事实上是10次)。
恭喜你在多层感知器上取得的成就!这是一个复杂的算法,有很多参数可以调整。
也许你可以尝试Weka中“data”目录下的其他数据集。
在IRIS数据集上执行Weka K=1(仅1个最近邻)的最近邻算法,并回答以下问题:
(a) 查看混淆矩阵。Iris数据集共有多少个错误的分类实例?
(b) 此分类器的加权精确率是多少?
(c) 此分类器的加权召回率是多少?
(d) 此分类器总共有多少个错误分类的实例?
(e) 哪些类别存在错误分类?
您能尽快回答以上问题吗?
你好Weka用户。请帮帮我。我想在2010年至2017年间17家银行的17家银行的时间序列数据上使用LAD分类器,有4个类别。我该如何进行?谢谢
也许可以尝试发布到Weka用户组
https://machinelearning.org.cn/help-with-weka/
我想知道为什么我的j48被禁用?
可能是因为它无法用于您加载的数据集。
我们如何处理为某个问题选择分类器的问题?
考虑到多层感知器比J48具有更高的准确率。
多层感知器 = 97.33%,而J48 = 96%
Oluwole,好问题。
我们需要评估一系列算法,看看哪种效果最好。这意味着我们需要一个健壮的测试框架(所以我们不会被结果愚弄)。这涉及到对指标和重采样方法(如交叉验证)的仔细选择。
然后,我们可以选择一个性能良好且复杂度较低(易于理解、向他人解释/用于生产)的算法。
因为您的类别是数值型的,而不是标称型的。它只适用于标称型类别。
您好,我刚接触机器学习,想知道如何选择一个模型来预测房价。我可以在Weka Explorer中使用它吗?如果可以,请问我该如何进行?
我的目标
我想根据一些标准来预测房价。
这个过程将教您如何端到端地处理您自己的问题。
https://machinelearning.org.cn/start-here/#process
functions.SMO 96.27 %,默认设置
您能举例说明“functions.SMO 96.27 %,默认设置”是什么意思吗?
SMO是Weka中支持向量机分类的实现。
默认设置意味着在算法对数据集运行之前,没有修改算法的任何参数。
您好,祝贺您的文章,它们非常有帮助!我想问您,如何确定一个数据集是否可靠来选择它?
诚挚的问候,
Nikos Vassilakis
谢谢 Nikos。
这篇文章可能有助于定义您的问题。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
你好
您是如何修改选项来提高准确率的?
谢谢
你好,我注意到有时此页面会显示403服务器错误消息。我想您会对此感兴趣。祝好。
谢谢 Mark,非常感谢。我没有亲身遇到过这种情况,但我会设置一些监控。
这是个很好的开始,希望您会爱上机器学习!
这真是一篇极好的文章!鉴于分类器(对数值类别的预测)模型以及来自训练集或测试集的实例,您是否知道在WEKA输出的“Predictions on test data”部分中,计算预测值是如何进行的?
通过向已训练的分类器提供输入属性(不包含数值输出属性),然后进行预测。对测试数据集中的所有实例都重复此过程。然后,Weka使用诸如平均绝对误差和均方根误差之类的度量来提供预测误差的摘要。
这样是否回答了您的问题 @NoelE?
真是个很棒的第一个课程,Jason!致敬。
顺便说一下,我使用了多层感知器,准确率达到了97.333%。
我是weka的新手,我想使用简单的CLI,我想从arff文件中删除一些属性,然后输入
[java weka.filters.unsupervised.attribute.Remove –R 5-34 -i data/kdd_01.arff -o data/kdd_02.arff]
但它不起作用!!!
希望您能帮助我…
您好,您的教程是否涵盖了预测(forecast)选项卡?另外,我们如何确定在特定场景下应该使用哪个算法?
您好 Tushar,我不认为有预测选项卡。您具体指的是什么?
为了找到最佳算法,我教授了一种通过抽样检查然后进行算法调优的流程。
哈喽 杰森,
我正在尝试使用我自己的.arff文件,但是对于我构建的模型,正确率不超过65%。有没有办法可以改进它,或者这意味着数据可能与结果类别无关?
谢谢。
您可以尝试一些不同的算法。您可以尝试对数据进行进一步的准备,例如标准化、归一化和特征工程。您还可以尝试调整表现良好的算法的参数。
在您的方法中要科学和有条理,提出具体问题并进行调查,并记录您的发现。
如何对我的arff扩展名数据进行归一化???我想在我的数据集上使用朴素贝叶斯,但在那之前需要进行归一化以获得更好的结果。
以ARFF格式打开iris数据集
选择j48分类器
选择百分比分割为66%
有多少实例被错误分类?
分类器产生的平均绝对误差是多少?
我认为Weka会在混淆矩阵中报告错误分类的示例数量。
我试了一下,通过调整多层感知器(只需将隐藏层设置为10),我获得了98%的成功率。
正确分类实例 147 98 %
错误分类实例 3 2 %
Kappa系数 0.97
平均绝对误差 0.0304
均方根误差 0.1296
相对绝对误差 6.8454 %
相对均方根误差 27.4907 %
总实例数 150
我得说这很令人上瘾。而且非常令人兴奋。
做得好 Tobias,尝试探索Weka附带的一些其他数据集。
您好!我在哪里可以修改隐藏层?谢谢!
在多层感知器算法中。查看算法属性。
我得到了相同的结果(98%),其中隐藏层 = i(输入特征的数量)。
做得好,看看这个结果是否能推广到UCI ML Repo的其他问题类型。
我经常使用隐藏层节点数等于输入特征数的启发式方法。
Jason,还有另一个问题
Weka能否根据数据属于某个类别,输出属于该类别的数据集?当然,可能有许多数据集满足该类别,但也有某些问题有唯一的解决方案。
我想用8皇后问题来尝试。
非常感谢您的回答。
我想在GUI中不行,Soto。您可能需要编写一个使用WEKA API的程序来处理这种情况。我相信我读过有关神经网络用于解决8皇后和TSP问题的例子。这都取决于问题的表示。
祝你好运。
在您对文章中混淆矩阵的解释中,“3 cases where a Iris-versicolor was classified as a Iris-setosa”应该改为“3 cases where a Iris-versicolor was classified as a Iris-virginica”。不过,这是一篇很棒的文章,干杯。
您好,这与本课略有偏离,但我需要帮助!我正在使用J48-交叉验证,但我想改变模型运行次数以及赋予每个变量的权重 - 如果您能理解的话。也称为周期/迭代次数。我以前做过,而且我相信这是一个简单的修复,但我记不起在Weka中的位置或名称。
非常感谢
Holly
大家好,
你好 Jason,我必须说这很令人兴奋,我完全没有计算机科学或编程基础,数学也不是很好,但不知何故
我爱上了机器学习的想法,可能是因为我有一个真实场景想尝试。
我有长达20个周末以上的比赛历史数据,我想看看Weka如何在20周内预测比赛结果
时期。
我的数据是表格形式,存储在Microsoft Word中。
它是过去比赛的预测。
模式检测是关键,通过仔细研究过去比赛的历史数据,模式开始出现,我用它来预测下一场比赛的结果
比赛。
我使用以下属性来检测模式并进行预测,虽然纸面上总是准确率在80-100%,但当我下注时,它就会失败。
(结果、球队名称、代码、周颜色、行号)
结果=平局的比赛
球队名称=信不信由你,球队名称被用作预测的参数,如何?它们以字母开头。
代码=这些是3-4个字符串,可以是数字,也可以是字母和数字的组合,取决于它们在表中的战略位置,它们提供了对
模式检测的见解。
周颜色=在足球预测领域,有4种颜色用于代表一个月中的每一周。红色、蓝色、棕色和紫色。这也能让
预测者看到新兴的模式。
行号=每周,数据都以表格形式呈现,两支竞争球队占据一行,并且有一个数字与该行相关联。这些数字用于
进行预测。
所以我想教WEKA我如何检测这些模式,以便我的任务可以自动化并以我喜欢的任何方式进行调整。
简而言之,我如何写出我的“模式检测风格”让WEKA理解,以及如何将这些信息加载到WEKA中进行处理以获得我
期望的结果?
根据我的场景,我的属性会是什么?
我的实例会是什么?
分类器会是什么?
我应该使用什么算法来实现我的目标,还是需要编写新算法?
我真诚地希望有人能来救我。
谢谢
在这篇文章之前,数据挖掘和机器学习是如此天体般难以理解的事物。但这篇文章改变了它。非常感谢。
谢谢!
很高兴听到它!
我想知道如何知道C4.5的平均高度和平均准确度。谢谢
使用交叉验证,收集您树木的统计数据,例如每个折叠的深度和准确度,然后对结果取平均值。
你能帮我处理多标签问题吗?
您能否帮帮我。我确实是数据挖掘概念的新手。我想知道如何提取给定URL名称的特征和准确度。例如:如果URL名称是 http://www.some@url_name.com,它会提取特征是其中的_和@,并且还会告诉我URL的年龄以及一些特征提取,比如IP地址、长URL或短URL、https和ssl、hsf、重定向页面、锚点标签等,它应该提取并显示准确度。然后使用c4.5分类器算法实现,以确定给定的URL名称是恶意还是良性URL。
请有人帮助我完成这个过程。
听起来是一个很棒的项目。与任何项目一样,您需要从构建一个数据集开始,以便您进行分析。
我怀疑URL中的单词将很有用,SSL证书或不是(https)也可能很有用,等等。很难事先知道什么将最有价值,我建议您集思广益,并在您的模型中尝试许多不同的特征。还应考虑使用重要性度量或与输出变量的相关性来查看哪些特征看起来有希望,哪些特征显得多余。
嗨!
我正在尝试在10折交叉验证模式下使用libsvm进行分类(2类)。我获得的输出预测具有实例#,但我不知道这些实例对应于我的数据集中的哪个实例。例如,我的输出预测看起来像这样
inst#, actual, predicted, error, probability distribution
1 2:R 2:R 0 *1
2 2:R 2:R 0 *1
3 2:R 2:R 0 *1
4 2:R 2:R 0 *1
5 1:S 1:S *1 0
6 1:S 1:S *1 0
1 2:R 2:R 0 *1
2 2:R 1:S + *1 0
3 2:R 2:R 0 *1
4 2:R 2:R 0 *1
5 1:S 1:S *1 0
6 1:S 2:R + 0 *1
....
我的数据集是如何分成10部分的?这些实例对应于哪些文件?
我想知道哪些文件被错误分类了。有没有其他/更好的方法来做到这一点?
我有同样的问题,如果有人有什么输入,请分享。
我已经安装了weka,但是我的smo函数不活跃,如何激活它?
我想使用支持向量机进行预测
嗨 Jason。我玩了WEKA一段时间了,现在我得到了很好的预测结果。但我仍然想知道如何进一步应用模型?
我的意思是,我训练和调整算法并获得更好的结果,但是然后呢?
当我尝试输入一组对应于IRIS数据集的四个属性时,它不将其识别为可用于模型的内容。
如果我输入这四个属性和一个空列,它会接受,但我不知道如何预测该类?我应该如何设置WEKA中的参数,请?
预先感谢。
我正在WEKA中使用多层感知器。我想了解在4个预测因子中,我如何决定哪个是最好的?
你好,
我正在尝试使用不同类型的分类规则处理数值数据(独立变量和依赖变量)。如果您能告诉我WEKA或R中适用于数值数据的分类规则和结果解释,那将是很好的。
提前感谢。
你好Jason。我有一个包含皮肤像素数据的arff文件。arff文件很大(>500MB)。一旦我在WEKA中加载数据,它就会显示“内存不足……”这个问题有什么解决方案吗?谢谢
你好
我只是在下载csv格式的已接受论文数据集。
但是它不能通过weka打开
它说“无法确定结构为csv。值数量错误”
我该怎么办?如果您能尽快回复,那将是很大的赞赏。
谢谢你
已接受论文数据集链接: https://archive.ics.uci.edu/ml/datasets/AAAI+2013+Accepted+Papers#
嗨
你能把AAAI 2013已接受论文的预测分析Python代码发给我吗?
电子邮件:nikhilkumar2838@gmail.com
嗨,Jason,
很棒的网站和很棒的努力:)
我想知道如何理解混淆矩阵,请?
嗨,我想知道如何查看嵌入在软件中的算法,我该如何查看它,以及如何修改或插入一个新算法
你好
我想使用UCI存储库网站的数据集,但在weka中运行数据时,所有属性都显示为一个属性。
我该怎么办?
一旦我训练了模型,我该如何运行它?
例如,我训练了一个模型,根据年龄、身高、体重和腹围来预测体脂百分比。现在,我想输入我自己的参数来看看模型的预测。
任何帮助将不胜感激。
我使用多层感知器获得了约97.3%的准确率。
Trees.FT使用20折产生98%的准确率(147个正确,3个错误)
你好,我有一个带有数值预测的数据集。我想在Weka中应用规则学习算法。我注意到Weka不像对标称预测那样支持数值预测的基于规则的算法。我不知道为什么。另外,为什么准确度显示的与标称预测不一样?我也注意到规则的形式也不同?如何计算正确分类的准确度?非常感谢
嗨。即使我的数据集中没有像“class”这样的字段,我也可以应用j48吗?
嗨!谢谢你的精彩指南!我想知道Weka在使用分类器时是否会对数据进行归一化,还是我们需要输入归一化后的数据本身?非常感谢。
嗨,这是一项很棒的工作。谢谢。一件事。你能否详细说明一下“测试选项”。知道了“使用训练集”选项的用途。但是其他呢?交叉验证已经在使用。其他两个呢?“提供的测试集和百分比分割”??
谢谢!
终于有人用平实的语言解释了机器学习,我已经为这方面的培训材料抓狂了好几周。写得非常好,用几个简单的步骤就解释清楚了。非常感谢:)
在“审查结果”下,最后的比较不应该是三个鸢尾花(Iris-versicolor)被分类为鸢尾花(Iris-virginica)吗?我对表格中的模式感到困惑,并且使用维基百科的例子,它似乎与您提到的不符?我对此是全新的,所以不知道我在说什么,但我希望得到一些澄清。
嗨。我叫Azhar,来自巴基斯坦白沙瓦。我是一名博士生。我需要实际地进行机器学习。
WEKA是最好的软件,但不知道如何使用。
嗨,我刚刚训练了一个用于文本分类的随机森林分类器。我也得到了结果。当他们说-训练你的分类器,然后用不同的数据进行测试以进行评估时,我想知道接下来该做什么来评估这个分类器?有人能帮助我完成后续步骤吗?我不确定如何保存这个训练好的分类器模型并上传测试数据。
谢谢!
嗨,我想知道如何选择一个数据库来用于分类,请帮帮我
我想在 http://archive.ics.uci.edu/ml/datasets/Abalone 数据集上使用朴素贝叶斯和J-48,但它不起作用。你能告诉我该怎么做吗?
嗨,我在Ubuntu上安装了Weka。我正在尝试在Explorer中获取数据集,但没有找到data文件夹。如何获取data文件夹?
我也有同样的问题……这是我在Weka的第一天……我正在尝试加载德国信贷数据,在Weka 3.8发行版中可以作为credit-g.arff获得。我无法加载此数据集,因为当我打开“打开文件”时,它只显示我计算机中的文件夹,而不是weka数据集……请,如果有人知道如何解决这个问题……
嗨Dadi,数据集可能没有随你的Weka版本分发。
您可以在这里下载带有数据集的Weka .zip文件,标题为“其他平台”
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
希望这能有所帮助。
使用朴素贝叶斯,未经任何修改就获得了96%的准确率。
非常感谢您,先生。那个教程确实很酷:)
只是快速说明一下,我喜欢整个网站,并且从未如此轻松地建立一个新的事业方向,同时又充满信心和理解!这篇帖子让我在10分钟内就启动、运行有效数据并评估了分类器的输出!简直太棒了!
不过,有一个小问题需要注意。第5节的最后一段,在“总结”之前,讲的是混淆矩阵。在该段中,引用的第三个案例是指“Iris-versicolor被分类为Iris-setosa”的三种情况。然而,根据我对表格的理解,有三种情况是Iris-versicolor被分类为Iris-verginica,而不是如所述的Iris-setosa。当然,墨菲先生会选择最具有讽刺意味的地方来混淆这种解释。
我可以在weka中使用kdd 99数据集吗?我可以使用weka检测dos攻击吗?是否有合适的分类算法?…尽快回复…我的时间不多了…
感谢您提供的信息。
我有一个具体的问题。使用您提到的步骤,我们可以在WEKA中训练一个机器学习模型并测试其准确性。我想知道如何使用我们在WEKA中训练的模型来分类新的、没有类别标签的实例。例如,假设我们有1000个积极和消极的句子实例。我们使用一个算法来训练一个机器学习模型。之后,我们想要标记100个新的、尚未分类的句子,这些句子还没有被标记为积极或消极。我们如何在WEKA中完成这样的工作?
你好,
这是开始和理解Weka的很棒的教程。
非常感谢。
太棒了!!
非常有帮助。我父亲曾经试图定义一个模板来定义花卉质量,现在我有一个想法。
现在我已经运行了我的第一个机器学习实验!
你好,
我是Weka的新手,我正在尝试弄清楚如何在分类中根据其他独立变量的值来预测一个变量的值。我想知道如何进行。
谢谢!
我正在制作一个基于手写数字识别的应用程序,它将是一个Android应用程序。用户将拍摄一个数字的图片,它将被发送到服务器,然后使用机器学习来识别文本。
我将使用Java语言编写我的应用程序的后端,所以WEKA是否提供与Java的接口?
不错的帖子。我买了您的《机器学习算法精通》一书,这本书非常好,但我不知道如何在weka包和Java中使用它来复制“逻辑回归”的例子。请协助。谢谢。
嗨,
所以我们只提供数据集并选择一个分类器,它就会自动分类,是吗?
我的意思是,如果我们提供一个新的训练集?
大家好,对我来说,能快速访问这个网站真是太好了,它包含了宝贵的信息。
一个快速的问题:我运行了SMO分类器,因为我需要一个支持向量机,并得到了一组结果,其中包含一个列表,列出了使用的特征,在“Machine Linear:显示属性权重,而不是支持向量”这一行下面。每个特征都有一个左侧的值,旁边标有“(normalised)”。
这是什么意思?每个特征的值都用于分类,所以我假设这些数字指的是某种权重,即每个特征对结果的影响程度。是这样吗?
有没有可能有人能用简单的术语解释一下,因为我是一个初学者,或者至少指给我一个网站,详细解释SMO分类器和所有结果部分的内容。
当我打开Weka控制台时,我看不到“data”目录。它只显示我本地驱动器上的文件。
“data”目录是您Weka安装下的一个子目录。
如果看不到它,您可以下载Weka的.zip版本,解压缩它,然后访问data目录。
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
嗨,我对weka不太熟悉。我面临着数据聚类的问题。我有一个包含13个不同属性的数据集,但只有12个对数据集很重要。我希望使用kmeans算法和欧氏距离作为距离函数。
遇到的问题是将属于1个类的数据聚类到数据集中。
我该如何处理?
请尽快给出答复。
我是weka的新手,我使用了自己的数据集来运行Libsvm分类器。但是libsvm报错信息“它不能处理数值类”
我在.arff文件的头部将其转换为标称值,但它使得.arff文件不可读。
我该如何解决这个问题?
也许您可以使用数据过滤器将数值类转换为标称类?也许是Discretize过滤器?
另外,考虑支持向量回归。
我是Weka的新手。我使用weka进行ECG分类,而不是使用数据集,而是逐条记录分类……首先,我将.mat文件转换为.csv,然后用weka将其转换为.arff,因为我无法获得文件的关系和头部>>>我有一个问题,在ECG中,我使用.mat文件还是使用注释文件??
这篇帖子可能有助于您将文件转换为ARFF
https://machinelearning.org.cn/load-csv-machine-learning-data-weka/
嗨,我是weka工具的新手。我使用过音频分类……但结果总是低于50%。
很棒的帖子!!
谢谢Gagan。
你好,
我在朴素贝叶斯多项式上训练Facebook帖子的数据集,如果我使用üsed training set test选项,数据分类效果会更好,但如果我使用cross folds和percentage split,正确分类实例的百分比会急剧下降(我得到40%或以下)。为什么会这样?我尝试搜索这个问题但找不到解决方案。我用3个不同的分类器重复了(SMO,IBkanns J45),但问题仍然存在。可能是什么问题以及如何解决?
(SMO,IBkanns J45),但相同的问题仍然存在。可能是什么问题以及如何解决?
谢谢您。
嗨,Jason,
我使用weka在训练数据上创建了模型。
例如
年龄、性别、状态
15,男,拒绝
19,男,批准
我尝试在测试数据上运行模型,它说状态属性的类型不匹配。
例如
年龄、性别、状态
10,男,?
21,男,?
我尝试将状态属性保留为“?”标记,而不是空着。它仍然显示相同的错误
我做错了什么?
嗨Gramcha,Weka中的测试数据需要一个已知的输出。它正在测试您的模型,并且需要将预测与实际值进行比较。您不能在测试数据中有“?”值。
如果您想预测新数据,请参阅这篇帖子
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
如何将模型应用于测试数据?
很好的问题。
您可以使用训练/测试拆分选项。
这篇帖子包含如何预测新数据的相关信息
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
Weka太棒了。我相信每个统计学家都应该知道这个!
谢谢Mark,我同意!
您能否提供一个分类未标记数据的示例/演示代码链接?我有一组未标记数据、训练数据和测试数据。使用weka,我无法为未标记数据获取标签。
提前感谢
嗨Justin,这篇帖子有您想要的内容
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
大家好
我从 WEKA 收到了这个错误:类索引为负(未设置)!你能对此进行更详细的说明,以及如何解决它吗?
你能帮我用 weka 工具做网页挖掘分类吗?
抱歉,Deena,我没有网页挖掘的例子。
我正在处理多类问题。我的疑问是,使用具有相同属性的不同分类器的准确率结果存在差异。例如:使用 SMO 准确率为 84%,随机森林为 92%。这种差异是如何产生的?有没有办法在 weka 中提高 SMO 的性能?请尽快告知。谢谢。
是的,不同的算法会获得不同的性能,Rajesh。
应用机器学习的目标是找到能够获得最佳性能的模型和模型参数。
你能指导我如何在 WEKA 中更改参数吗?我想更改分类技术,并使用不同的参数值(每个参数至少 3 个不同的值),以及它们的分类结果。
谢谢
抱歉,Nor,我不太明白。
你可以在这里学习如何使用 Weka
https://machinelearning.org.cn/start-here/#weka
function.MultilayerPerceptron 98%,动量为 0.11
Viorel,非常棒。
我正在使用 AutoWEKA Tab 来分类我的 Owen 数据集。现在我想对另一个数据集运行获得的最佳条件,以进行比较。如何做到这一点?
祝好
你好 mtokhy,抱歉,我对 AutoWEKA 不熟悉。
通过在测试选项中选择训练集来获得 98% 的准确率。你能详细说明一下吗?
抱歉,我没听懂。你能再说一遍你的问题吗?
亲爱的同事,
我需要 Weka 程序的帮助。我无法构建树。
你能发送给我 Excel 文件并帮助我吗。
谢谢你
我是 Weka 和机器学习的新手。我正在尝试加载以下数据集。对于
以下数据集,J48 分类器被禁用。我需要生成 java 类文件。你能帮忙解决这个问题吗
@relation Icelandincnamedataset
@attribute First_Name string
@attribute Last_Name string
@attribute Last_Name_suffix {son , dottir, None }
@attribute Iceland_native {Yes, No}
@data
Bjarni,Benediktsson,son,Yes
也许你的数据文件中需要更多的例子?
嗨,你能推荐一个适用于 WEKA 的手写字符/数字识别数据集吗?谢谢
你好 Shaurya,
MNIST 是手写字符识别的标准。我不知道是否有适合与 Weka 配合使用的数据版本,抱歉。
你好,Gamified online WEKA (www.gamifiedonlineweka.ga) 是一个非常好的桌面 WEKA 的在线替代品,具有更好的可视化效果,请尝试一下。
谢谢你的提示,ania。
嘿,杰森!
你能告诉我如何将训练好的模型应用于新数据吗?
我想构建一个决策支持系统,为具有给定适应症的患者预测最佳放射学程序。我尝试了 Weka,但找不到如何将模型应用于新的患者状况并获得预测。
谢谢你
这篇帖子会帮助 Chelly
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
尊敬的 Jason Brownlee,现在我有一个问题:使用数据挖掘技术,特别是 Weka 软件,进行分析/研究或撰写论文需要多少记录(属性和实例)?最低和最高是多少?
这取决于问题的复杂程度。一般来说,数据越多越好。
嗨,Jason!
我将在四月在加州大学圣地亚哥分校学习预测分析课程,我想先开始研究 WEKA。这将是我们课程中使用的工具。
我喜欢你提供的鸢尾花文件示例,以及它是如何分析数据并找到数据集中一定数量的错误分类记录的。我正在尝试理解这个工具的实际应用,并想到了我以前作为经理的职位,负责处理客户在访问我们网站时报告的所有事件。其中一些问题是数据相关的,例如缺少数据、字段中数据不正确等。
那么,我能否运行数据分析并识别数据集中存在这些数据问题的记录,然后深入到实际记录以识别真正的根本原因,并在数据 ETL 过程中解决上游问题?
我相信可以,Tammi。
总的来说,我认为 Weka 在学习应用机器学习和处理预测建模问题方面非常出色。
我也认为 Weka 非常适合一次性项目。
对于更工业化/操作化的东西,可能需要编程。
希望这能有所帮助。
嗨,Jason!
我觉得我昨晚发表了一条评论,但没看到 🙁 无论如何,这是我的问题/想法。
我将在下个月在加州大学圣地亚哥分校学习预测分析,并将在这门课程中使用 WEKA。你关于鸢尾花的例子让我更容易理解如何使用这个工具,我为此感谢你。
我正在考虑这个工具在我日常工作中的实际应用。我在一家大型保险公司工作,负责 7 个网站以及这些门户网站上客户(内部和外部)报告的所有问题/事件。我假设这是一个很好的工具来查看数据相关问题,例如,我们从大型机获取数据馈送到存储库。在该数据中,可能存在缺陷,例如缺少数据、字段中数据不正确等。我假设这将有助于解决这类问题。
我的问题是——我的假设是否正确,如果正确,这个工具是否允许我轻松地以行级别识别数据?
谢谢
评论由我审核,通常需要 24 小时以上。
我已经回答了你的另一条评论。
你好先生,
如何使用 Weka KnowledgeFlow 环境。我正在尝试使用 weka knowledge flow
环境,但输出没有显示。
我正在从事利用 Weka 分析医学数据集进行慢性肾脏疾病检测的工作。
谢谢
我建议使用 Explorer 和 Experimenter。
嗨 Jason,
我正试图将推文分类为 3 个类别:+ve、-ve 和中性。
目前我有大约 800 条推文。我遵循的步骤
1.使用 NomialtoString 将推文文本列转换为字符串。
2.应用 StringtoWordVector(词干提取器:Snowball,分词器:NGramTokenizer 或 CharNGramTokenizer。
3.在“preprocess”下应用 AttributeSelection(默认设置),以便自动选择属性。
使用朴素贝叶斯,我的准确率大约为 65%。如何改进结果??
我需要确切的流程或设置。还有其他我应该做的事情吗??
谢谢
也许可以尝试其他算法?
也许可以尝试另一种表示方法?
也许可以尝试过滤一些数据。
我有下一个问题
例如,我有 3 个属性和一个决策:蓝色、圆形、小 -> 球
Weka 会分析这个数据集并建立决策,但如何以类似“如果(蓝色、圆形、小)则 -> 球”的方式查看这些决策?
非常尊敬
谢谢
附注:我们的团队将实现自己的分类算法到 Weka(LEM2),如果您有类似的想法,我将非常感谢您的帮助
我猜你使用的是基于规则的模型。
你也许可以配置模型的调试来输出规则。
你也许可以使用 Java API 来访问学习到的规则。
我曾为 weka 实现过算法,发现它很直接。文档非常好。
以下是我十多年前实现的一些算法
http://wekaclassalgos.sourceforge.net/
嗨,Jason,
我想知道 Weka 是否能帮助评估网络钓鱼邮件检测模型,不仅基于内容中的单词,还基于通过在线黑名单服务检查其他特征,例如发件人 IP,然后如果发件人 IP 被列入黑名单,则提高其为网络钓鱼的可能性?如果 Weka 可以帮助,那么如何帮助?
一切顺利
也许可以,Joe,我建议在选择算法/平台之前花时间制定预测建模问题。
请看这篇文章
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
谢谢 Jason,
阅读完帖子后,我的问题仍然一样
我能否知道在使用我的 Java 代码中的 Weka 时,是否需要检查某些挖掘出的 IP 地址是否被列入黑名单,然后将结果作为输入再次用于 Weka?还是这个可以单独用 Weka 工具完成?
老实说,我不是程序员,并努力理解这个问题!
也许你可以使用 Weka,但我无法确定,除非我更深入地了解你的数据集。
本教程应该为你提供了足够的背景信息,以便你能够将其应用到你自己的问题中。
我的建议是尝试一下。
如何在 WEKA 的结果中计算均方根误差?我是否可以从混淆矩阵中计算,也许?
它会自动为回归问题计算,而不是为分类问题计算。
嗨 Jason,我想报告我的一些 weka 结果——但正在努力如何报告(包含什么等)。你能推荐一个网站或文章来说明 weka 结果的报告吗?谢谢!
Conny,你说的报告是什么意思?
你是说如何呈现结果?
这篇文章可能会有帮助
https://machinelearning.org.cn/how-to-use-machine-learning-results/
Jason,非常感谢你提出的这个伟大倡议。
我使用 Lazy K-Star(使用训练集)获得了 100% 的准确率????????
KStar 选项:-B 20 -M a
模型构建时间:0 秒
=== 训练集评估 ===
在训练数据上测试模型的时间:0.06 秒
=== 总结 ===
正确分类的实例 150 100 %
错误分类的实例 0 0 %
Kappa 统计量 1
平均绝对误差 0.0062
均方根误差 0.0206
相对绝对误差 1.3992 %
相对均方根误差 4.3621 %
总实例数 150
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-versicolor
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-virginica
加权平均值 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 50 0 | b = Iris-versicolor
0 0 50 | c = Iris-virginica
非常好!
IB1 也提供了 100% 的准确率
IB1 基于实例的分类器
使用 1 个最近邻居进行分类
模型构建时间:0 秒
=== 训练集评估 ===
在训练数据上测试模型的时间:0 秒
=== 总结 ===
正确分类的实例 150 100 %
错误分类的实例 0 0 %
Kappa 统计量 1
平均绝对误差 0.0085
均方根误差 0.0091
相对绝对误差 1.9219 %
相对均方根误差 1.9335 %
总实例数 150
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-versicolor
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-virginica
加权平均值 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 50 0 | b = Iris-versicolor
0 0 50 | c = Iris-virginica
感谢分享!
嘿。有人能帮帮我吗?
我想通过提供数据集来训练我的神经网络
@attribute activity {A, B, C}
@attribute resource {x, c, e}
@data
A,x
B,x
A,x
B,c
C,e
B,e
A,x
C,x
A,e
B,e
C,e
B,c
C,c
然后,我想输入 A,c 到神经网络,得到错误的答案。因为我的训练集中没有这样的实例。
我正在 Weka 中尝试使用 MultilayerPerceptron 来完成此操作。但它不起作用……
有人能帮我吗?
这个过程将帮助你系统地解决问题
https://machinelearning.org.cn/start-here/#process
你好,我是 weka 工具的新手。我不知道如何编写程序。所以请帮帮我……。
我建议学习使用 Weka
https://machinelearning.org.cn/start-here/#weka
先生,你好
明天将是我的外部口试。我的主题是使用 CBIR 的肺结节。NN 技术。
我有一个特征提取表……我按照你在此 PDF 中所说的相同方式运行。请告诉我一些关于这方面的新东西。
谢谢
抱歉,我没有特征提取的例子。也许你把我误认为是别人了?
我如何将 csv 文件上传到 Weka?我收到了类似“需要数字,读取标记 [什么] 第 7 行”的错误!
这篇帖子可能有助于你在 Weka 中加载数据
https://machinelearning.org.cn/load-csv-machine-learning-data-weka/
你好,
非常感谢这篇文章。它非常有帮助。
我想了解更多关于 weka 的信息。
如何将我自己的机器学习算法上传到 weka?
我想这样做并检查算法的性能指标。
提前致谢。
是的,你可以为 Weka 编写自己的算法,我以前这样做过。
http://wekaclassalgos.sourceforge.net/
抱歉,我没有这方面的教程,也许将来会有。
嗨。我是机器学习和 WEKA 的新手。
我对你的教程很满意。那么我该如何进行下一个教程呢?我在网上找不到。
谢谢!
英语是我的第二语言,所以我希望你能理解我想表达的意思。
从这里开始使用 Weka
https://machinelearning.org.cn/start-here/#weka
感谢这个强大的机器学习工具。我尝试使用 Weka 将 spambase 数据集分类为垃圾邮件或非垃圾邮件,但结果不正确。你能解释一下如何使用 Weka 对垃圾邮件进行分类,使用任何数据集吗?我首先将文本文件转换为 .cvs 文件,然后在 Weka 中进行标准化,然后选择我想要的分类算法。得到的结果如下:
=== 运行信息 ===
方案:weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a
关系:spambase_name
实例:47
属性:1
make
测试模式:10 折交叉验证
=== 分类器模型(完整训练集)===
MultilayerPerceptron
====================
警告:未构建模型,因此使用了 ZeroR 模型
ZeroR 预测类值:address
模型构建时间:0.07 秒
=== 分层交叉验证 ===
=== 总结 ===
正确分类的实例 0 0 %
错误分类的实例 47 100 %
Kappa 统计量 -0.0217
平均绝对误差 0.0421
均方根误差 0.1458
相对绝对误差 100 %
相对均方根误差 100 %
总实例数 47
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
0.000 0.913 0.000 0.000 0.000 -0.427 0.043 0.021 address
0.000 0.109 0.000 0.000 0.000 -0.051 0.043 0.021 all
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 3d
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 our
0.000 0.000 0.000 0.000 0.000 0.000 0.043 0.021 over
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 remove
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 internet
0.000 0.000 0.000 0.000 0.000 0.000 0.033 0.021 order
抱歉,我没有处理 Weka 中文本数据的例子。
如何决定分类中的决策和关系?
你具体指的是什么?
对我来说是一个不错的开始。刚下载了 Weka 并按照描述运行了鸢尾花数据集。现在开始有些明白了,希望在课程结束时我能掌握这些知识。
做得好,乔治!
谢谢 Jason。
我正在为我的数据集使用多层感知器,并且得到了以下结果。
构建模型所需时间:1064.19 秒
=== 训练集评估 ===
=== 总结 ===
正确分类的实例 39341 78.7655 %
错误分类的实例 10606 21.2345 %
Kappa 统计量 0.7819
平均绝对误差 0.0152
均方根误差 0.0853
相对绝对误差 31.9084 %
均方根相对误差 55.3309 %
总实例数 49947
我需要更高的准确率,即使用相同的模型,准确率 >= 90%。
那里有些奇怪的事情在发生…
先生
你能详细说明一下吗?
我正在处理 49947 条记录。
如何通过 WEKA 绘制误差图或 ROC 曲线?
是否可以根据 TP 率和 FP 率构建此图?
请回复
我相信 Weka 已内置此功能。尝试右键单击算法结果并查看菜单选项。
嗨 Jason,你能帮我分析一下这个分类输出吗?
=== 运行信息 ===
方案:weka.classifiers.trees.J48 -C 0.25 -M 2
关系:信用筛查
实例:125
属性:11
失业
购买物品
性别
未婚
问题区域
年龄
银行存款
月供
月数
工作年限
已授信
测试模式:10 折交叉验证
=== 分类器模型(完整训练集)===
J48 剪枝树
——————
失业 = n
| 工作年限 <= 2
| | 购买物品 = pc: p (4.0)
| | 购买物品 = car
| | | 月供 9: p (3.0/1.0)
| | 购买物品 = stereo
| | | 未婚 = p: n (5.0/1.0)
| | | 未婚 = n: p (3.0)
| | 购买物品 = jewel
| | | 工作年限 1
| | | | 月供 9: n (3.0/1.0)
| | 购买物品 = medinstru: p (7.0/1.0)
| | 购买物品 = bike: n (6.0/1.0)
| | 购买物品 = furniture: n (2.0)
| 工作年限 > 2: p (70.0/7.0)
失业 = p: n (14.0/2.0)
叶子数:13
树的大小:20
构建模型所需时间:0.04 秒
=== 分层交叉验证 ===
=== 总结 ===
正确分类的实例 95 76 %
错误分类的实例 30 24 %
总实例数 125
=== 按类别详细准确率 ===
精确率 召回率 F值 类别
0.809 0.847 0.828 p
0.639 0.575 0.605 n
加权平均值 0.755 0.760 0.756
=== 混淆矩阵 ===
a b <– 分类为
72 13 | a = p
17 23 | b = n
你想了解哪一部分?
在 WEKA 的分类中,准确率是什么意思?
准确率是衡量模型技能的指标,它是总的正确预测数除以总的预测数,再乘以 100,使其成为百分比。
Hy Mr.Jaon….我正在诊断甲状腺……我创建了两个单独的数据集文件……训练文件和测试文件,其中 ? 代替了输出。WEKA 在训练文件上运行良好,但当我执行测试文件时,会弹出一个错误消息:没有足够的具有类别标签的训练实例(需要 1,提供 0)。你能帮帮我吗?
看起来你的训练数据集中每个类别的示例可能不够。
嗨 Jason,我们可以使用 weka 进行 LSTM 吗?如果可以,请提供一些教程作为帮助。
我认为不行。
你好!感谢分享这篇帖子。
我是 Weka 的新手,我想知道是否知道如何使用 Java 命令向 Weka 添加新过滤器……我正在尝试添加 LSH-IS 进行实例选择,它可以在这个页面上找到
https://github.com/alvarag/LSH-IS/
我想知道是否知道如何解决这个错误:“找不到或加载主类 weka.gui.GUIChooser”
抱歉,我没有关于向 Weka 添加新功能的资料。
很好。以一种有用且有趣的方式开始机器学习。我做了一些研究,令我惊讶的是,许多机器学习工作机会都要求精通 Weka!它不仅仅是一个玩具 🙂
很高兴听到这个!
好的,我用多层感知器和百分比分割 61% 获得了 98.2759%。
干得好!
好的,我用 Logistic 和训练集提高了这个数字,得到了 98.6667%。只有 2 个错误!
祝好!
好的,我最后一个帖子(抱歉!)使用 lazy IBk 并使用训练集获得了 100%。
=== 运行信息 ===
方案:weka.classifiers.functions.MultilayerPerceptron -L 0.3 -M 0.2 -N 500 -V 0 -S 0 -E 20 -H a
关系:鸢尾花
实例:150
属性:5
花萼长度
花萼宽度
花瓣长度
花瓣宽度
class
测试模式:10 折交叉验证
=== 分类器模型(完整训练集)===
Sigmoid 节点 0
输入权重
阈值 -3.5015971588434014
节点 3 -1.0058110853859945
节点 4 9.07503844669134
节点 5 -4.107780453339234
Sigmoid 节点 1
输入权重
阈值 1.0692845992273177
节点 3 3.8988736877894024
节点 4 -9.768910360340264
节点 5 -8.599134493151348
Sigmoid 节点 2
输入权重
阈值 -1.007176238343649
节点 3 -4.2184061338270356
节点 4 -3.626059686321118
节点 5 8.805122981737854
Sigmoid 节点 3
输入权重
阈值 3.382485556685675
属性 花萼长度 0.9099827458022276
属性 花萼宽度 1.5675138827531276
属性 花瓣长度 -5.037338107319895
属性 花瓣宽度 -4.915469682506087
Sigmoid 节点 4
输入权重
阈值 -3.330573592291832
属性 花萼长度 -1.1116750023770083
属性 花萼宽度 3.125009686667653
属性 花瓣长度 -4.133137022912305
属性 花瓣宽度 -4.079589727871456
Sigmoid 节点 5
输入权重
阈值 -7.496091023618089
属性 花萼长度 -1.2158878822058787
属性 花萼宽度 -3.5332821317534897
属性 花瓣长度 8.401834252274096
属性 花瓣宽度 9.460215580472827
类别 Iris-setosa
输入
节点 0
类别 Iris-versicolor
输入
节点 1
类别 Iris-virginica
输入
节点 2
构建模型所需时间:0.45 秒
=== 分层交叉验证 ===
=== 总结 ===
正确分类的实例 146 97.3333 %
错误分类的实例 4 2.6667 %
Kappa 统计量 0.96
平均绝对误差 0.0327
均方根误差 0.1291
相对绝对误差 7.3555 %
均方根相对误差 27.3796 %
总实例数 150
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-versicolor
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-virginica
加权平均值 0.973 0.013 0.973 0.973 0.973 0.960 0.998 0.995
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 48 2 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
干得不错。
我有一个数据集,我已经加载到 weka 中并且运行正常,问题是我想要对这个数据集应用 j48,但是当我尝试应用时,j48 没有被激活。可能不适用于 j48,如何使我的数据集适用于 j48。
例如:使用此链接中的数据不适用于 j48
http://archive.ics.uci.edu/ml/machine-learning-databases/00432/Data/
谢谢
也许你的数据没有分类输出?
嗨,Jason,
真的很难为情承认。我在这个教程的开头就卡住了。我安装了 Weka 3.8 版本,并按照教程步骤进行了操作,直到 3. 打开 data/iris.arff 数据集。但是,我找不到 data 目录的位置。它应该在哪里?我错过了什么吗?
非常感谢你的好意回复。
我很抱歉……已解决。我重新安装了所有东西,并找到了你提到的目录……谢谢。
很高兴听到这个消息。
它应该在你安装 Weka 的位置。
感谢分享您对网站的看法。此致
我很高兴它有帮助。
我安装了 weka 并找到了 iris 数据集。现在将开始学习课程。
干得好。
嗨 Jason,工作出色。我发现了一段文字,其中混淆矩阵和你的文字不匹配。
……有 3 个案例将 Iris-versicolor 分类为“Iris-setosa”(总共 6 个错误)。此表有助于解释算法达到的准确性。
作为 iris-setosa 或 Iris-virginica?
a b c <– 分类为
49 1 0 | a = Iris-setosa
0 47 3 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
非常感谢你的课程和文章。
谢谢,你可以在这里了解更多关于混淆矩阵的信息
https://machinelearning.org.cn/confusion-matrix-machine-learning/
嗨,Jason,
我运行了 Weka Version 3.9.2,并在交叉验证设置为 10 的情况下,通过多层感知器获得了 98.6667%。
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 1 49 | c = Iris-virginica
Weka Version 3.9.2 是否使用了更强大的算法?
非常感谢你的网站。
干得不错。
不,可能是不同 weka 版本之间模型训练存在一些随机差异。
嗨,Jason,
当准确率为 100% 时,精确率和召回率都为 1 是正常的吗?
是的。更多信息请参见此处
https://en.wikipedia.org/wiki/Precision_and_recall
好的,我今天第一次使用它。
1) 首先,在让 Weka Explorer 读取 iris ARFF 文件时遇到了一些麻烦。搜索了一下,在 Stack Overflow 上找到了一些复杂的答案(没什么大不了的,用 R 重新格式化),在 Research Gate 上找到了最简单的方法,只需使用 Notepad++ 查看所有隐藏的非 ASCII7 字符(很多,主要是用于注释的 %,我全部删掉了),并且了解到 ARFF 有特殊字符问题(有点荒谬,但是…)。其他人可能通过了解这一点而跳过了一些搜索。我花在格式化数据集上的时间比运行分类器的时间还多。
2) 然后按照你上面的说明运行了一些,很好。得到了和你一样以及 2014 年评论中的结果(最新?)。ZeroR 起始为 33%,树和朴素贝叶斯为 96%,感知器为 97.33%。很好。感知器模型是 1 层吗?有没有办法从 Weka 运行更复杂、更深层次的神经网络?我也会在几天后学习 Python/Tensor Flow 时尝试一下,并且如果我能快速找到一个小型图像数据集,我也会尝试 Wela 感知器。
感谢你的 Weka 指南。也许会尝试更多,甚至超越 Weka — 认为它会是一种快速完成一些简单分类器/等的简单方法。
3) 问题:有没有办法仅使用 Weka 工具生成像我得到的 97.33% 的混淆矩阵之类的图表?我也会在可视化中查找,但第一次查看时没有说。
Bob
做得好,Bob。
关于数据集问题感到奇怪,我以前从未见过/听说过。
我认为 Weka 没有生成混淆矩阵的工具。
我们可以使用 Meka 而不是 weka 吗?
Meka 是什么?
=== 运行信息 ===
方案:weka.classifiers.trees.J48 -C 0.25 -M 2
关系:鸢尾花
实例:150
属性:5
花萼长度
花萼宽度
花瓣长度
花瓣宽度
class
测试模式:在训练数据上评估
=== 分类器模型(完整训练集)===
J48 剪枝树
——————
花瓣宽度 0.6
| 花瓣宽度 <= 1.7
| | 花瓣长度 4.9
| | | 花瓣宽度 1.5: Iris-versicolor (3.0/1.0)
| 花瓣宽度 > 1.7: Iris-virginica (46.0/1.0)
叶子数:5
树的大小:9
模型构建时间:0.07 秒
=== 训练集评估 ===
在训练数据上测试模型所需时间:0.02 秒
=== 总结 ===
正确分类实例 147 98 %
错误分类实例 3 2 %
Kappa系数 0.97
平均绝对误差 0.0233
均方根误差 0.108
相对绝对误差 5.2482 %
均方根相对误差 22.9089 %
总实例数 150
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.980 0.020 0.961 0.980 0.970 0.955 0.990 0.969 Iris-versicolor
0.960 0.010 0.980 0.960 0.970 0.955 0.990 0.970 Iris-virginica
加权平均值 0.980 0.010 0.980 0.980 0.980 0.970 0.993 0.980
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
干得好!
嗨,Jason,
做得好,为 Weka 工具做出了巨大贡献,并为查询提供了快速答案!我刚开始使用 weka 工具,我本身是一名 dotnet 开发者。
我需要你为我的工作提供建议/帮助。我需要将 CSV 文件中的数据分类到三个类别/领域
4 个文件
1.数据在一个 CSV 文件中,包含 Slno、时间戳、用户搜索查询
2.基于领域 1 的关键字
3.基于领域 2 的关键字
4.基于领域 3 的关键字
我想根据其他文件中存在的关键字来分类文件 1 中的用户搜索查询。
是否可以在 weka 中对这种情况进行分类?如果有建议的话
非常感谢!
非常感谢你的帮助!
拉维
我建议在处理 Weka 时将所有数据合并到一个文件中,并考虑此框架来帮助理解预测问题
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
谢谢 Jason!!,
我浏览了该框架,并理解了问题定义和解决方案的重要性。
我正在探索如何根据不同领域的特定关键字来分类给定的用户搜索查询。而且我不知道如何合并用户查询数据集
和关键字
如果你有任何样本或更简单的问题,你能分享一下吗?
谢谢
拉维
抱歉,我没有这类问题的样本。
构建模型所需时间:0.41 秒
=== 分层交叉验证 ===
=== 总结 ===
正确分类的实例 146 97.3333 %
错误分类的实例 4 2.6667 %
Kappa 统计量 0.96
平均绝对误差 0.0327
均方根误差 0.1291
相对绝对误差 7.3555 %
均方根相对误差 27.3796 %
总实例数 150
=== 按类别详细准确率 ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-versicolor
0.960 0.020 0.960 0.960 0.960 0.940 0.996 0.993 Iris-virginica
加权平均值 0.973 0.013 0.973 0.973 0.973 0.960 0.998 0.995
=== 混淆矩阵 ===
a b c <– 分类为
50 0 0 | a = Iris-setosa
0 48 2 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
干得好!
嗨,Jason,
首先,恭喜发帖!
其次,我不知道括号中的值是什么意思。
例如 Iris-versicolor (3.0/1.0)。3.0/1.0 是什么意思?
花瓣宽度 0.6
| 花瓣宽度 1.7: Iris-virginica (46.0/1.0)
谢谢!
你这些例子是从哪里得到的?
很棒的教程,我也想补充一下,weka 中使用的数据集是 arff 格式。你也可以上传自己的数据集来查看,但我有一个问题,我尝试了 UCI 存储库中的 Wisconsin 乳腺癌数据集。我将 csv 文件格式转换为 arff 格式。我还应用了一些 weka 分类器,但我发现其中一些没有用于我的这个数据集,而同样的分类器我曾用于 weka 工具的内置数据集。
我不知道为什么?有解决方案吗?
好问题,Weka 只会让你使用适合你数据的模型。
例如,如果这是一个分类问题,那么你只能使用分类算法。
你好!一个很棒且有用的教程,可以帮助我开始使用 weka!!我想知道如果你使用 Experimenter 而不是 Explorer,你该如何查看结果?你有什么相关的教程吗?
我正在进行数据集、算法和结果目标的设置,然后我在 Run 选项卡中运行实验,它运行得没有错误,然后在 Analyse 选项卡中加载 result-file.arff,但结果格式与 Explorer 分类器/聚类器输出大不相同。
换句话说,我如何才能看到在 Experimenter 中运行的实验的“摘要”和“按类别详细准确性”?
此外,到目前为止我还找不到如何在 Experimenter 中可视化生成的结果。
实验器仅用于运行实验,而不是数据可视化或其他在 Explorer 中执行的任务。
你好!有没有什么方法可以在 weka 中为回归类型问题绘制 RMSE 图,例如 LibSVM、SMOReg、REPTree 等算法?
例如,如果我们正在预测房价,那么如何绘制预测价格和原始价格的图表?
我不太确定,抱歉。
你好,
在我的例子中,它没有识别出类标签。有什么办法可以解决这个问题吗?
你具体指的是什么?
嘿,非常感谢您与我分享关于 weka 工具的信息,作为一名学生,能够从您提供的图片和材料开始,非常有帮助,非常感谢。
不客气!
你好,
在成功安装 Weka 3.8 后,我一直按照到第 02 步。但是在第 03 步,我找不到(或看不到)数据目录。你能帮我找到数据目录吗?
您可能需要单独下载数据文件,请参阅此帖子。
https://machinelearning.org.cn/download-install-weka-machine-learning-workbench/
我不是在谈论 weka 文件夹数据中已有的数据集,我有一个 excel 表格中的数据集,我如何将其导入 weka 进行分析?
是的,您可以通过与示例数据集相同的方式加载新数据集。
首先,您必须准备好数据并将其保存为 CSV 文件。
在 weka 中是否可以将一个数据集训练的分类器用于另一个数据集的测试?
是的,请看这篇文章
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
你好,Jason Brownlee!我是 Bobby R.J.
感谢您分享您的知识,我们非常感激!
顺便说一下,有没有办法和您讨论?我在做我的项目时遇到了麻烦,尤其是在进行在线/实时分类方面……
如果您有时间,请给我发邮件!
非常感谢!
您可以随时联系我。
https://machinelearning.org.cn/contact/
正确分类实例 146 97.9866 %
错误分类实例 3 2.0134 %
Kappa 统计量 0.9698
平均绝对误差 0.0223
均方根误差 0.1189
相对绝对误差 5.008 %
均方根相对误差 25.2267 %
总实例数 149
逻辑回归分类器
干得好!
嗨,Jason,
需要 Java 代码来计算准确率、TP 率、FP 率、精确率、MCC、PRC、ROC、混淆矩阵,并将其输出到 netbeans IDE 的控制台。如果我运行任何数据集,netbeans 控制台应该显示为
准确率 =
TP 率 =
FP 率 =
精确率 =
MCC =
ROC =
PRC =
混淆矩阵 =
此致
Ashish
也许您可以调用 Weka API 中的 Java 函数?
抱歉,我没有这方面的例子。
你好 Jason,感谢你的教程!
我以前用 Python 编写机器学习模型。当我使用 WEKA 时,我很好奇这个训练好的模型是否可以在未标记的数据集上使用?WEKA 有这个功能吗?
好问题,可能可以,我不太确定,抱歉。
Jason,你有一个很棒的方法。感谢分享你的知识(和鼓励)!
有趣的是,交叉验证折叠的数量显然会影响哪些样本被分组在一起以及三个不同分类器的正确分类百分比。
J48 与交叉验证折叠
2 –> 93.3%
4 –> 95.3%
5 –> 96.0%
7 –> 94.0%
9 –> 96.0%
11 –> 95.3%
12–> 96.0%
13 –> 94.0%
14–> 95.3%
16 –> 94.7%
17 –> 94.0%
18–> 96.0%
19 –> 95.3%
20 –> 96.0%
…
逻辑回归与交叉验证折叠
2 –> 94.0%
3 –> 94.7%
5 –> 95.5%
7 –> 97.3%
8 –> 96.0%
11 –> 98.0%
12–> 96.7%
14 –> 98.0%
15–> 96.7%
16 –> 98.0%
17 –> 97.3%
18–> 96.7%
19 –> 98.0%
20 –> 97.3%
…
多层感知器与交叉验证折叠
2 –> 94.7%
3 –> 94.0%
4 –> 95.3%
5 –> 96.0%
6 –> 95.3%
7 –> 96.0%
8 –> 95.3%
9 –> 96.0%
10 –> 97.3%
11 –> 96.7%
12–> 96.0%
13 –> 95.3%
14 –> 97.3%
15–> 96.0%
17 –> 96.7%
18–> 96.0%
19 –> 96.7%
20 –> 97.3%
…
干得好。
是的,模型评估很棘手。几乎没有站得住脚的理由。
多层感知器的准确率为 97.3333%。
干得好!
我使用了 LMT 和 66% 的数据拆分,准确率为 98.0392%。虽然只处理了 51 个实例,但模型只错误地将 51 个实例中的 1 个分类了。我认为这相当不错。
=== 总结 ===
正确分类实例 50 98.0392 %
错误分类实例 1 1.9608 %
Kappa 统计量 0.9704
平均绝对误差 0.0166
均方根误差 0.1031
相对绝对误差 3.7161 %
均方根相对误差 21.8099 %
总实例数 51
=== 混淆矩阵 ===
a b c <– 分类为
15 0 0 | a = Iris-setosa
0 19 0 | b = Iris-versicolor
0 1 16 | c = Iris-virginica
我会考虑采用这个模型,并将整个数据集输入其中,看看它的表现如何。
干得好!
作为跟进,我做了。准确率保持在 98% 左右。太棒了!你让我着迷了,Jason。节日快乐!🙂
我正在学习其他课程,并且很享受。如果我这样调整它会怎样?或者如果我这样做 X,或者让我试试 Y?嘿,如果我使用集成算法而不是分类器会怎样?
这比我一直在忍受的“学习数据科学”的自下而上方法有趣多了。
干得好。
我很高兴听到您的进展和热情!
你好,我有一个疑问,当你添加一个实例 Petalwidth= 1.6 cm, Petallength= 4 cm, Sepalwidth= 3.4 cm, Sepallength= 6 cm,它会被归类到哪个类别?
¿你需要指定最后的类别吗?还是会被归类到 Iris-setosa (50.0)
很好的问题!
不,您只需要输入数据即可进行预测。
请参阅此教程以获取示例。
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
你好:我尝试通过 weka gui 对我加载的数据集进行分类,使用 DL4j 的深度学习架构,但我找不到它。我使用的步骤是数据加载后,weka.classify.function 查看 DL4J。
抱歉,我不知道 DL4J。
你好 Ibrahim,我的问题和你一样。
你知道如何使用深度学习吗?
首先,非常感谢您的教程。这对于我们许多想进入 ML 世界的人非常有帮助。
我看了这些步骤,有一个问题。在 J48 分类器中,Iris-versicolor 和 Iris-virginica 的 FP 率显示为 0.030。
但是,当我尝试从混淆矩阵计算 FP 率时,
对于 Iris-versicolor = 3/50 = 0.06。该工具是如何得到 0.030 的?我是否遗漏了什么?
请澄清。
不客气。
也许可以尝试其他算法?
你好 Jason Brownlee,我是机器学习和数据挖掘的新手。我正在撰写我的四年级项目,主题是使用 Weka 和 Python 对机器学习算法性能进行比较分析。我的问题是,系统处理能力是否会影响不同数据集上的分类器结果?
不会。只会影响执行速度。
你好,
我是 Weka 的新手,需要一些帮助。有没有办法在 weka 中自动运行 timeseries forecast 包,使用相同的参数但每次使用不同的时间序列?我的数据集是 2172 个产品的月度需求,我想分别对每个产品进行预测。这意味着我必须为每个算法运行 2172 次。你能帮忙吗??
抱歉,我不知道 Weka 中的时间序列预测。
有没有关于如何通过命令从简单 CLI 运行 weka 的想法或教程,以便更快地完成工作?我将调整它以适应我的时间序列包。谢谢!
这是可能的,而且我已经这样做了,但我没有关于这个主题的教程,抱歉。
我建议您直接查看 Weka 文档。
我像往常一样运行 ZeroR,但不运行 J48。开始按钮不亮。为什么会这样?
也许请确保您使用的是完全相同的数据集。
开始按钮不亮。