如何在 Python 中对概率预测进行评分并
培养对不同指标的直观理解。
在分类问题中预测概率而不是类标签,可以为预测提供额外的细微差别和不确定性。
这种额外的细微差别允许使用更复杂的指标来解释和评估预测的概率。总的来说,评估预测概率准确性的方法被称为评分规则或评分函数。
在本教程中,您将发现三种评分方法,您可以在分类预测建模问题中使用它们来评估预测的概率。
完成本教程后,您将了解:
- 对数损失分数,它会严重惩罚与期望值相距甚远的预测概率。
- Brier 分数,它比对数损失更温和,但仍然会根据与期望值的距离进行惩罚。
- ROC 曲线下面积,它总结了模型为真阳性案例预测比真阴性案例更高的概率的可能性。
启动您的项目,阅读我的新书《机器学习概率》,其中包含分步教程和所有示例的Python 源文件。
让我们开始吧。
- 更新 2018 年 9 月:修正了 AUC 无技能的描述。

Python 中概率评分方法的简明介绍
照片作者:Paul Balfe,部分权利保留。
教程概述
本教程分为四个部分;它们是
- 对数损失分数
- 布里尔分数
- ROC AUC 分数
- 调整预测概率
对数损失分数
对数损失,也称为“逻辑损失”、“对数损失”或“交叉熵”,可用作评估预测概率的度量。
将每个预测概率与实际类别输出值(0 或 1)进行比较,并计算一个分数,该分数根据与期望值的距离来惩罚该概率。惩罚是对数的,对于小的差异(0.1 或 0.2)给出小的分数,对于大的差异(0.9 或 1.0)给出巨大的分数。
一个技能完美的模型得分为 0.0。
为了总结模型使用对数损失的技能,对每个预测概率计算对数损失,并报告平均损失。
对数损失可以使用 scikit-learn 中的 log_loss() 函数在 Python 中实现。
例如
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.metrics import log_loss ... model = ... testX, testy = ... # 预测概率 probs = model.predict_proba(testX) # 只保留类别 1 的预测 probs = probs[:, 1] # 计算对数损失 loss = log_loss(testy, probs) |
在二元分类的情况下,该函数以实际结果值列表和概率列表作为参数,并计算预测的平均对数损失。
我们可以通过一个例子使单个对数损失分数具体化。
给定一个特定的已知结果为 0,我们可以以 0.01 的增量(101 个预测)预测 0.0 到 1.0 的值,并计算每个预测的对数损失。结果是一条曲线,显示随着概率偏离期望值,每个预测受到多少惩罚。我们可以对已知结果为 1 的情况重复此操作,并看到相同的曲线(反向)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 绘制对数损失对单个预测的影响 from sklearn.metrics import log_loss from matplotlib import pyplot from numpy import array # 预测值从 0 到 1,增量为 0.01 yhat = [x*0.01 for x in range(0, 101)] # 评估对于真实值为 0 的预测 losses_0 = [log_loss([0], [x], labels=[0,1]) for x in yhat] # 评估对于真实值为 1 的预测 losses_1 = [log_loss([1], [x], labels=[0,1]) for x in yhat] # 绘制输入到损失的图 pyplot.plot(yhat, losses_0, label='true=0') pyplot.plot(yhat, losses_1, label='true=1') pyplot.legend() pyplot.show() |
运行示例将创建一个折线图,显示当真实标签为 0 和 1 时,从 0.0 到 1.0 的概率预测的损失分数。
这有助于建立对损失分数在评估预测时所产生影响的直观认识。
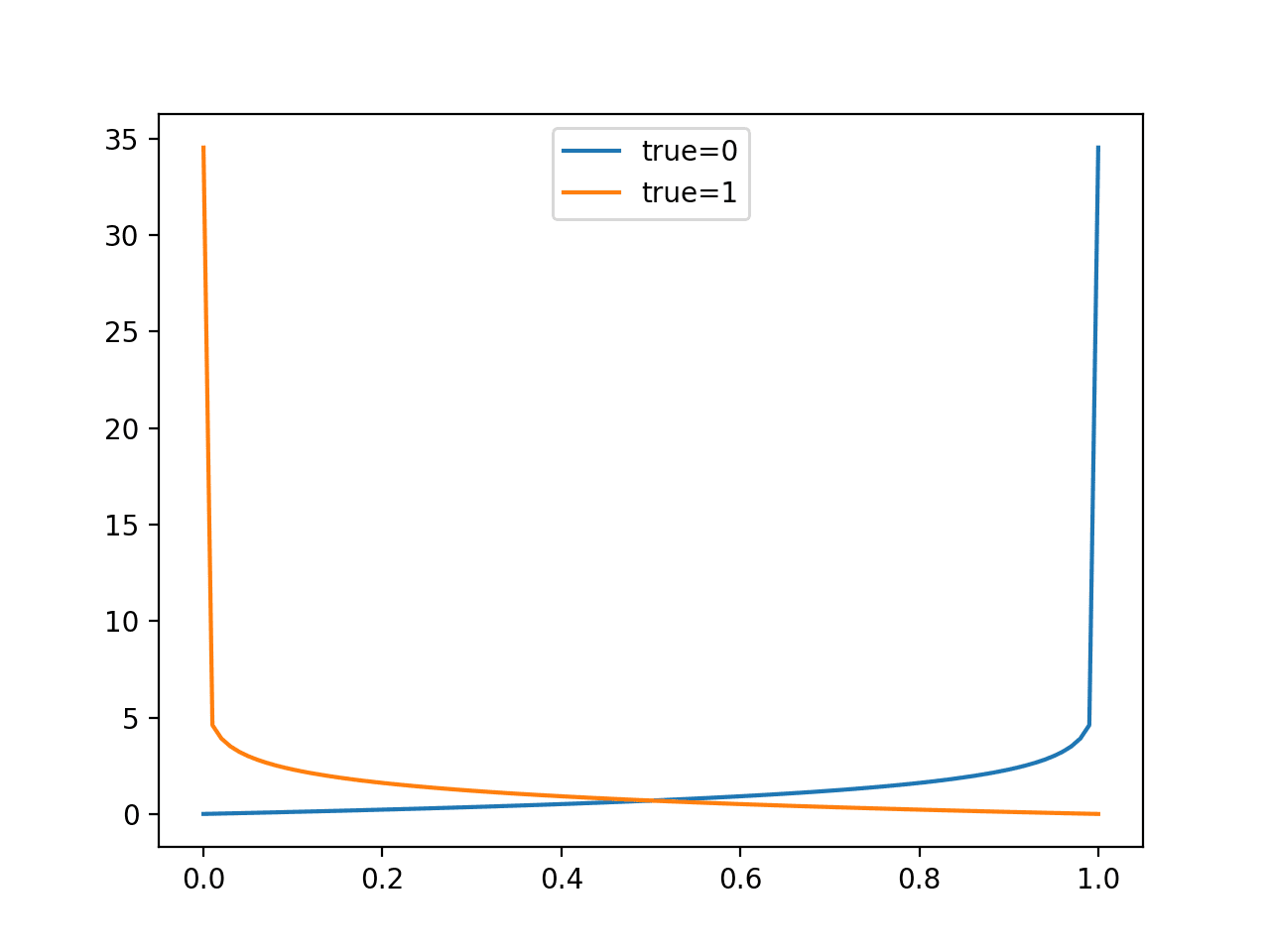
对数损失评估预测的折线图
模型技能报告为测试数据集中预测的平均对数损失。
作为平均值,我们可以预期该分数在数据集平衡时是合适的,而在测试集中两个类别之间存在较大不平衡时则具有误导性。这是因为预测 0 或小数概率会导致较小的损失。
我们可以通过比较在平衡和不平衡数据集上预测不同恒定概率时的损失值分布来证明这一点。
首先,下面的示例预测 50 个类别 0 和 1 的平衡数据集,其值从 0.0 到 1.0,增量为 0.1。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制对数损失在平衡数据集上的影响 from sklearn.metrics import log_loss from matplotlib import pyplot from numpy import array # 定义一个平衡数据集 testy = [0 for x in range(50)] + [1 for x in range(50)] # 预测不同固定概率值的损失 predictions = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] losses = [log_loss(testy, [y for x in range(len(testy))]) for y in predictions] # 绘制预测值与损失的关系图 pyplot.plot(predictions, losses) pyplot.show() |
运行示例,我们可以看到,模型最好是预测不那么“尖锐”(接近边缘)而更偏向分布中部的概率值。
对于尖锐概率的错误会受到非常大的惩罚。
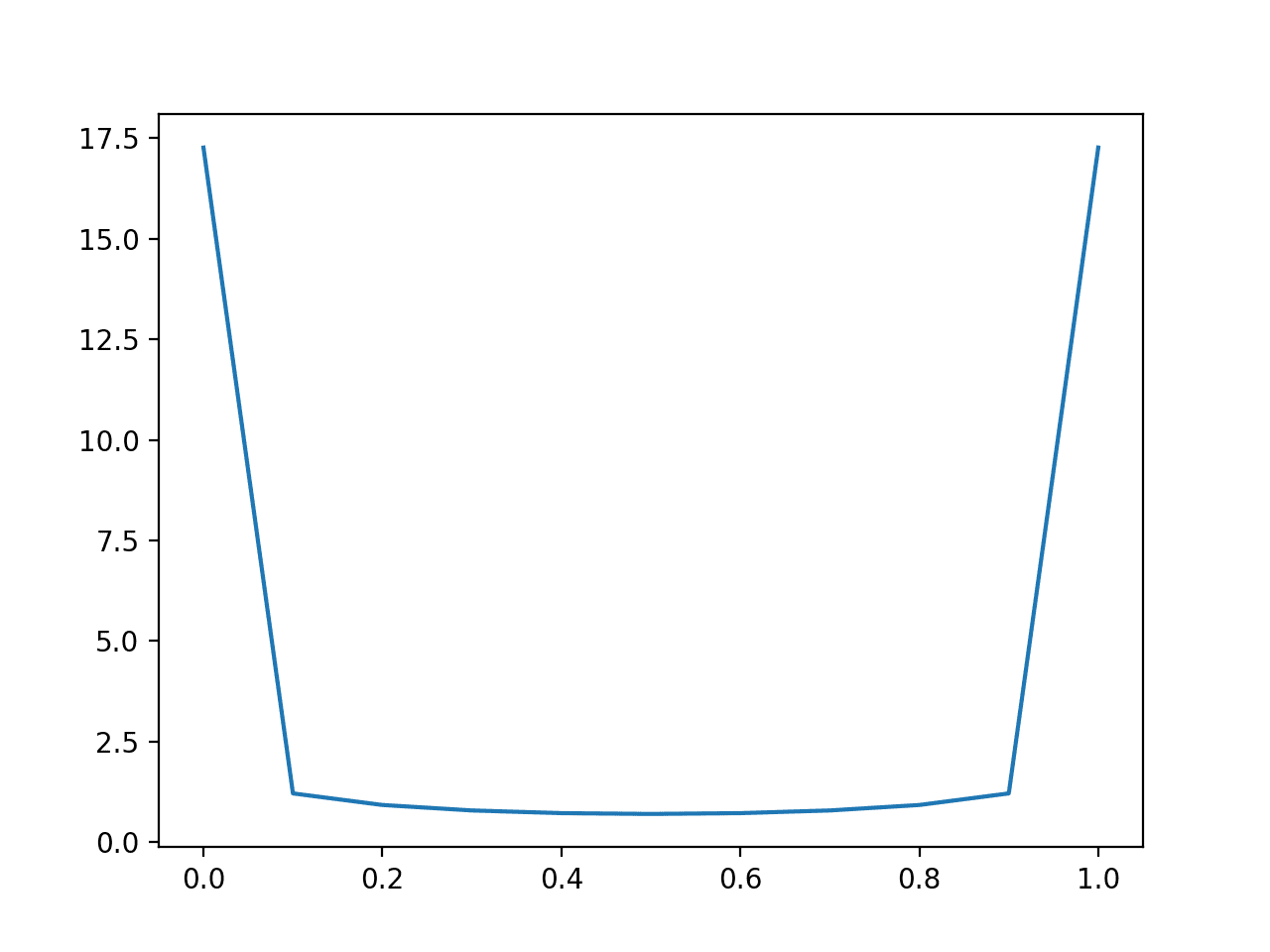
平衡数据集预测对数损失的折线图
我们可以用类别比例为 10:1 的不平衡数据集重复此实验。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制对数损失在不平衡数据集上的影响 from sklearn.metrics import log_loss from matplotlib import pyplot from numpy import array # 定义一个不平衡数据集 testy = [0 for x in range(100)] + [1 for x in range(10)] # 预测不同固定概率值的损失 predictions = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] losses = [log_loss(testy, [y for x in range(len(testy))]) for y in predictions] # 绘制预测值与损失的关系图 pyplot.plot(predictions, losses) pyplot.show() |
在这里,我们可以看到,一个倾向于预测非常小概率的模型表现会很好,甚至过于乐观。
预测恒定概率 0.1 的朴素模型将是需要超越的基准模型。
结果表明,在使用对数损失评估的模型技能时,在数据集不平衡的情况下应谨慎解释,可能需要相对于数据集中类别 1 的基础率进行调整。
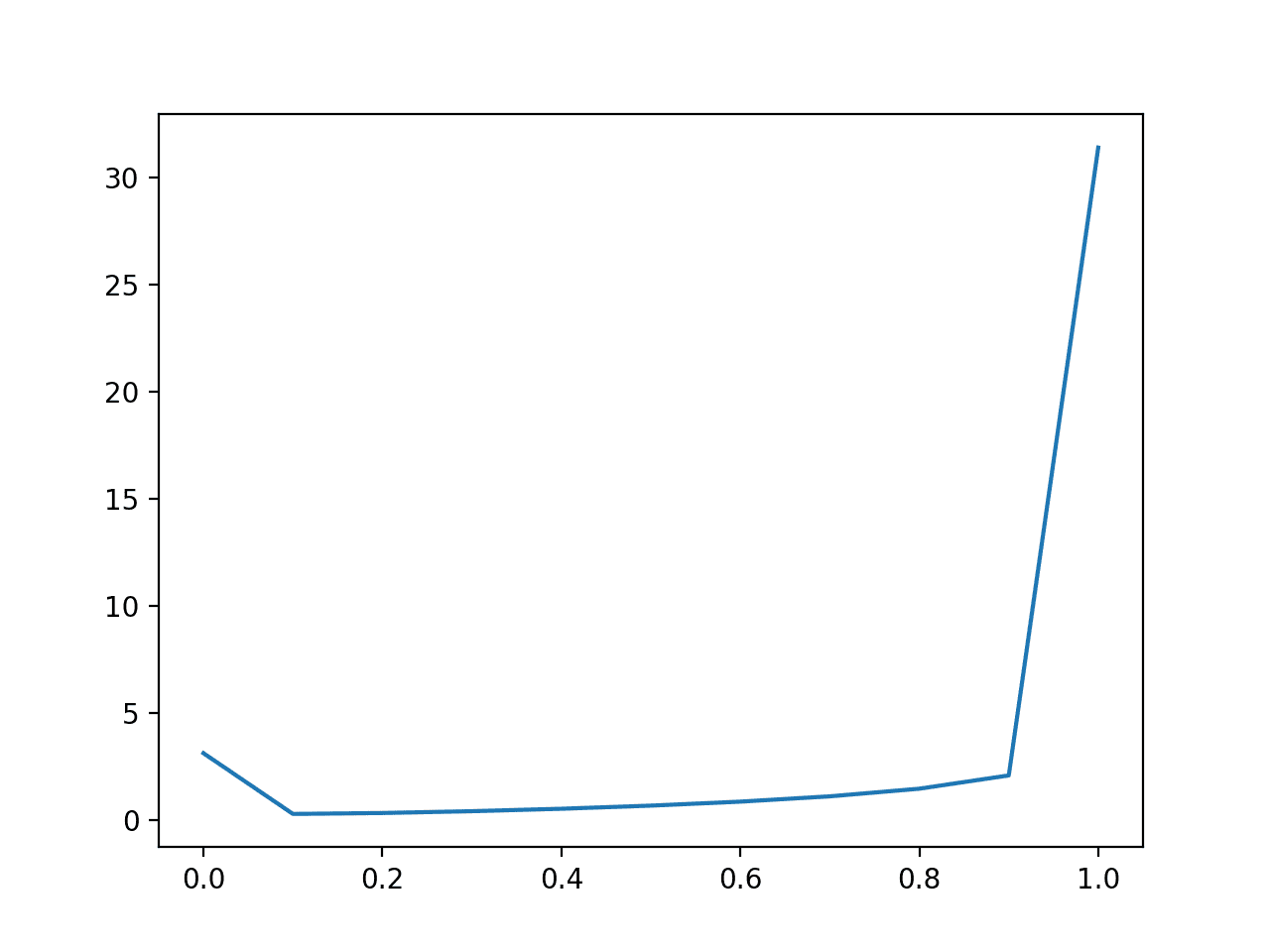
不平衡数据集预测对数损失的折线图
想学习机器学习概率吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
布里尔分数
Brier 分数,以 Glenn Brier 命名,计算预测概率与期望值之间的均方误差。
该分数总结了概率预测中的误差大小。
误差分数总是在 0.0 和 1.0 之间,其中技能完美的模型的得分为 0.0。
与对数损失相比,离期望概率越远的预测会受到惩罚,但惩罚力度较轻。
模型技能可以概括为测试数据集中所有预测概率的平均 Brier 分数。
Brier 分数可以使用 scikit-learn 中的 brier_score_loss() 函数在 Python 中计算。它以测试数据集中的所有示例的实际类别值(0、1)和预测概率作为参数,并返回平均 Brier 分数。
例如
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.metrics import brier_score_loss ... model = ... testX, testy = ... # 预测概率 probs = model.predict_proba(testX) # 只保留类别 1 的预测 probs = probs[:, 1] # 计算 Brier 分数 loss = brier_score_loss(testy, probs) |
我们可以通过比较从 0.0 到 1.0 的单次概率预测的 Brier 分数来评估预测误差的影响。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 绘制 Brier 分数对单个预测的影响 from sklearn.metrics import brier_score_loss from matplotlib import pyplot from numpy import array # 预测值从 0 到 1,增量为 0.01 yhat = [x*0.01 for x in range(0, 101)] # 评估对于真实值为 1 的预测 losses = [brier_score_loss([1], [x], pos_label=[1]) for x in yhat] # 绘制输入到损失的图 pyplot.plot(yhat, losses) pyplot.show() |
运行示例,将概率预测误差(x 轴)与计算出的 Brier 分数(y 轴)绘制出来。
我们可以看到熟悉的二次曲线,随着平方误差的增加,从 0 到 1 递增。
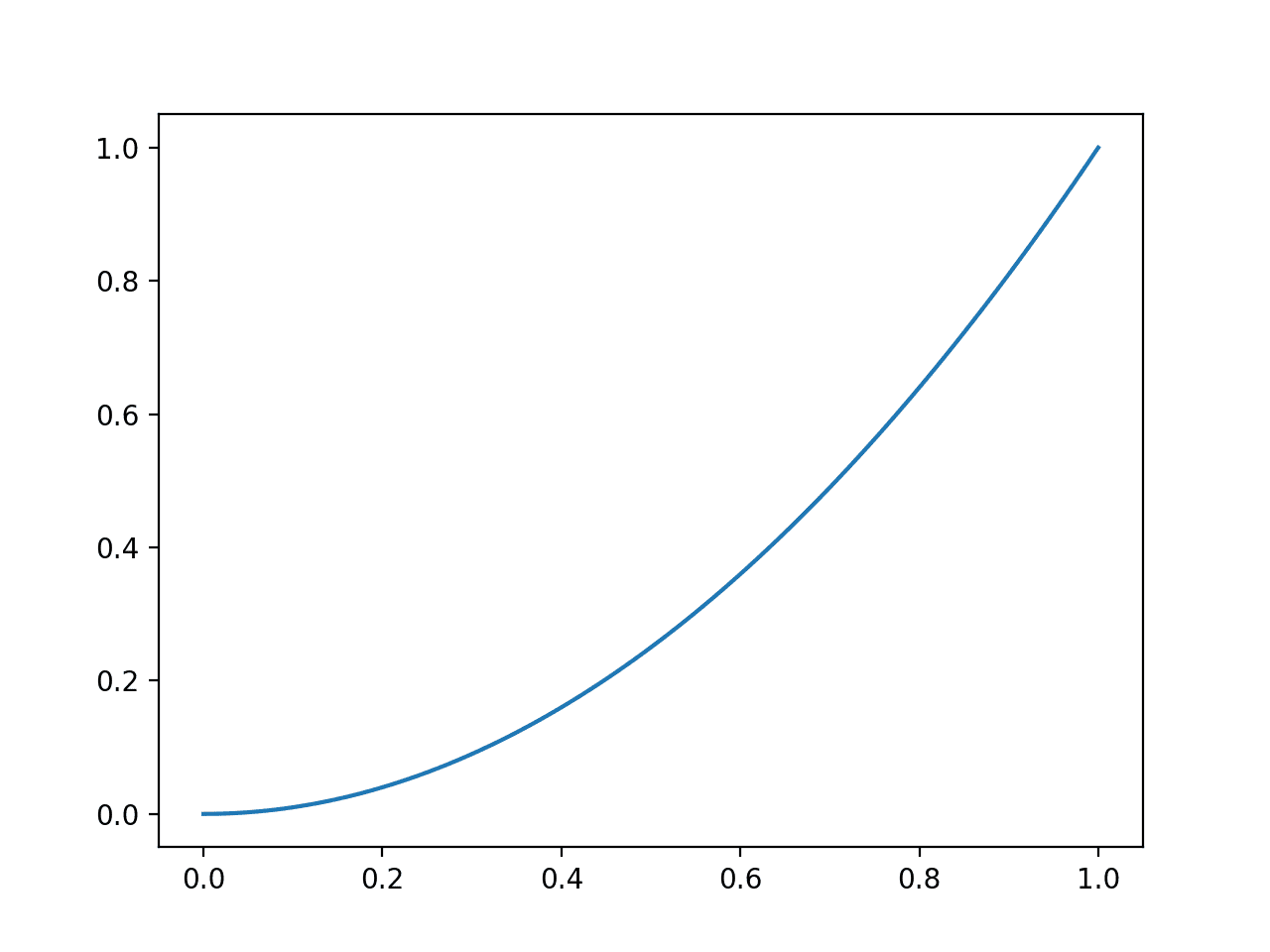
Brier 分数评估预测的折线图
模型技能报告为测试数据集中预测的平均 Brier 分数。
与对数损失一样,我们可以预期该分数在数据集平衡时是合适的,而在测试集中两个类别之间存在较大不平衡时则具有误导性。
我们可以通过比较在平衡和不平衡数据集上预测不同恒定概率时的损失值分布来证明这一点。
首先,下面的示例预测 50 个类别 0 和 1 的平衡数据集,其值从 0.0 到 1.0,增量为 0.1。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制 Brier 分数在平衡数据集上的影响 from sklearn.metrics import brier_score_loss from matplotlib import pyplot from numpy import array # 定义一个平衡数据集 testy = [0 for x in range(50)] + [1 for x in range(50)] # 预测不同固定概率值的 Brier 分数 predictions = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] losses = [brier_score_loss(testy, [y for x in range(len(testy))]) for y in predictions] # 绘制预测值与损失的关系图 pyplot.plot(predictions, losses) pyplot.show() |
运行示例,我们可以看到,模型最好是预测像 0.5 这样的中间概率值。
与对数损失不同,对数损失对于接近的概率非常平坦,而抛物线形状显示了分数惩罚随着误差的增加而呈二次方增长。
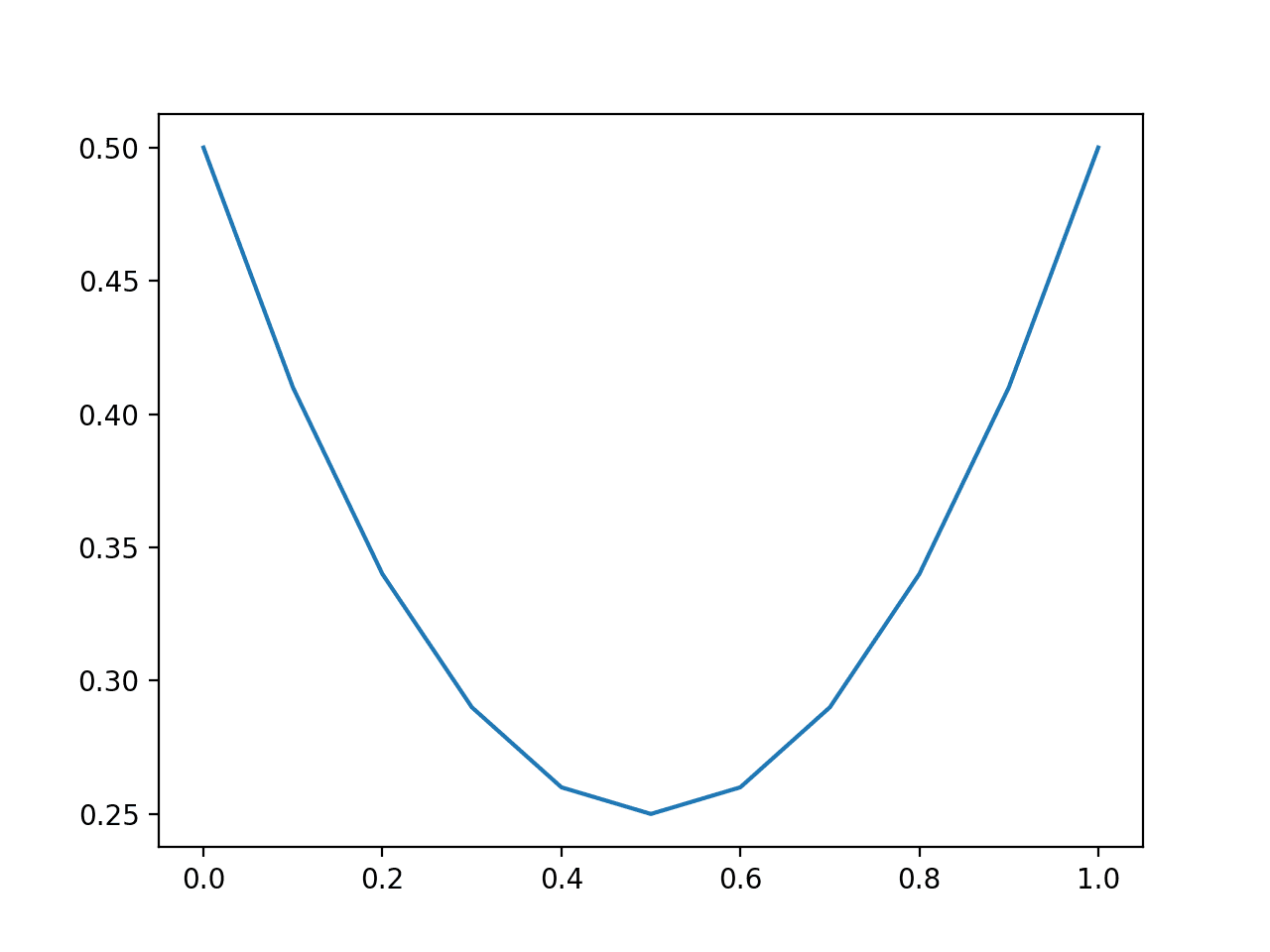
平衡数据集预测 Brier 分数的折线图
我们可以用类别比例为 10:1 的不平衡数据集重复此实验。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制 Brier 分数在不平衡数据集上的影响 from sklearn.metrics import brier_score_loss from matplotlib import pyplot from numpy import array # 定义一个不平衡数据集 testy = [0 for x in range(100)] + [1 for x in range(10)] # 预测不同固定概率值的 Brier 分数 predictions = [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] losses = [brier_score_loss(testy, [y for x in range(len(testy))]) for y in predictions] # 绘制预测值与损失的关系图 pyplot.plot(predictions, losses) pyplot.show() |
运行示例,我们看到不平衡数据集的情况大相径庭。
与平均对数损失一样,平均 Brier 分数在不平衡数据集上会呈现出过于乐观的分数,奖励减小多数类别误差的小预测值。
在这些情况下,Brier 分数应与朴素预测(例如,少数类别的基线率或上面示例中的 0.1)进行比较,或者按朴素分数进行归一化。
后一个示例很常见,称为 Brier 技能分数 (BSS)。
|
1 |
BSS = 1 - (BS / BS_ref) |
其中 BS 是模型的 Brier 技能,BS_ref 是朴素预测的 Brier 技能。
Brier 技能分数报告了概率预测相对于朴素预测的相对技能。
对 scikit-learn API 的一个好改进是,为 brier_score_loss() 添加一个参数来支持 Brier 技能分数的计算。
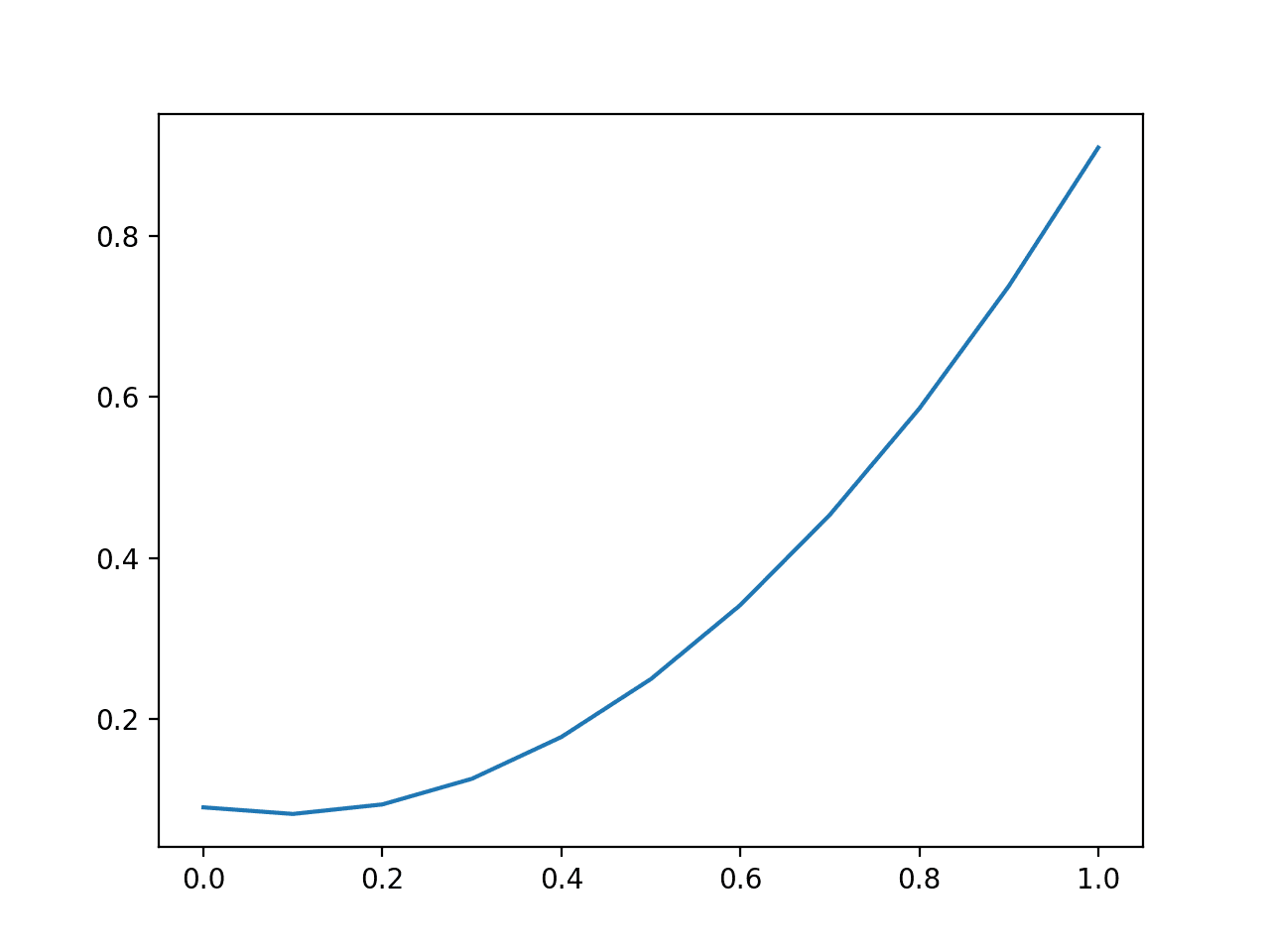
不平衡数据集预测 Brier 分数的折线图
ROC AUC 分数
对于二元(两类)分类问题,预测概率可以根据阈值进行解释。
阈值定义了概率映射到类别 0 或类别 1 的点,默认阈值为 0.5。替代阈值允许模型针对更高或更低的误报率和漏报率进行调整。
在其中一种错误比另一种更重要或不重要的项目,或者模型产生特定类型错误的比率不成比例地更高或更低时,操作员对阈值进行调整尤为重要。
接收者操作特征(ROC)曲线是模型在多个 0.0 到 1.0 之间的阈值下进行预测的真阳性率与假阳性率的图。
对于给定阈值没有技能的预测绘制在图的对角线上,从左下角到右上角。这条线代表了每个阈值的无技能预测。
有技能的模型在对角线上方有一条曲线,该曲线向左上角弯曲。
下面是一个示例,在二元分类问题上拟合逻辑回归模型,并计算和绘制在 500 个新数据实例的测试集上预测概率的 ROC 曲线。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# ROC 曲线 from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import roc_curve from matplotlib import pyplot # 生成 2 类数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2) # 拟合模型 model = LogisticRegression() model.fit(trainX, trainy) # 预测概率 probs = model.predict_proba(testX) # 只保留正向结果的概率 probs = probs[:, 1] # 计算 roc 曲线 fpr, tpr, thresholds = roc_curve(testy, probs) # 绘制无技能线 pyplot.plot([0, 1], [0, 1], linestyle='--') # 绘制模型的 ROC 曲线 pyplot.plot(fpr, tpr) # 显示绘图 pyplot.show() |
运行示例将创建一个 ROC 曲线的示例,可以与主对角线上的无技能线进行比较。
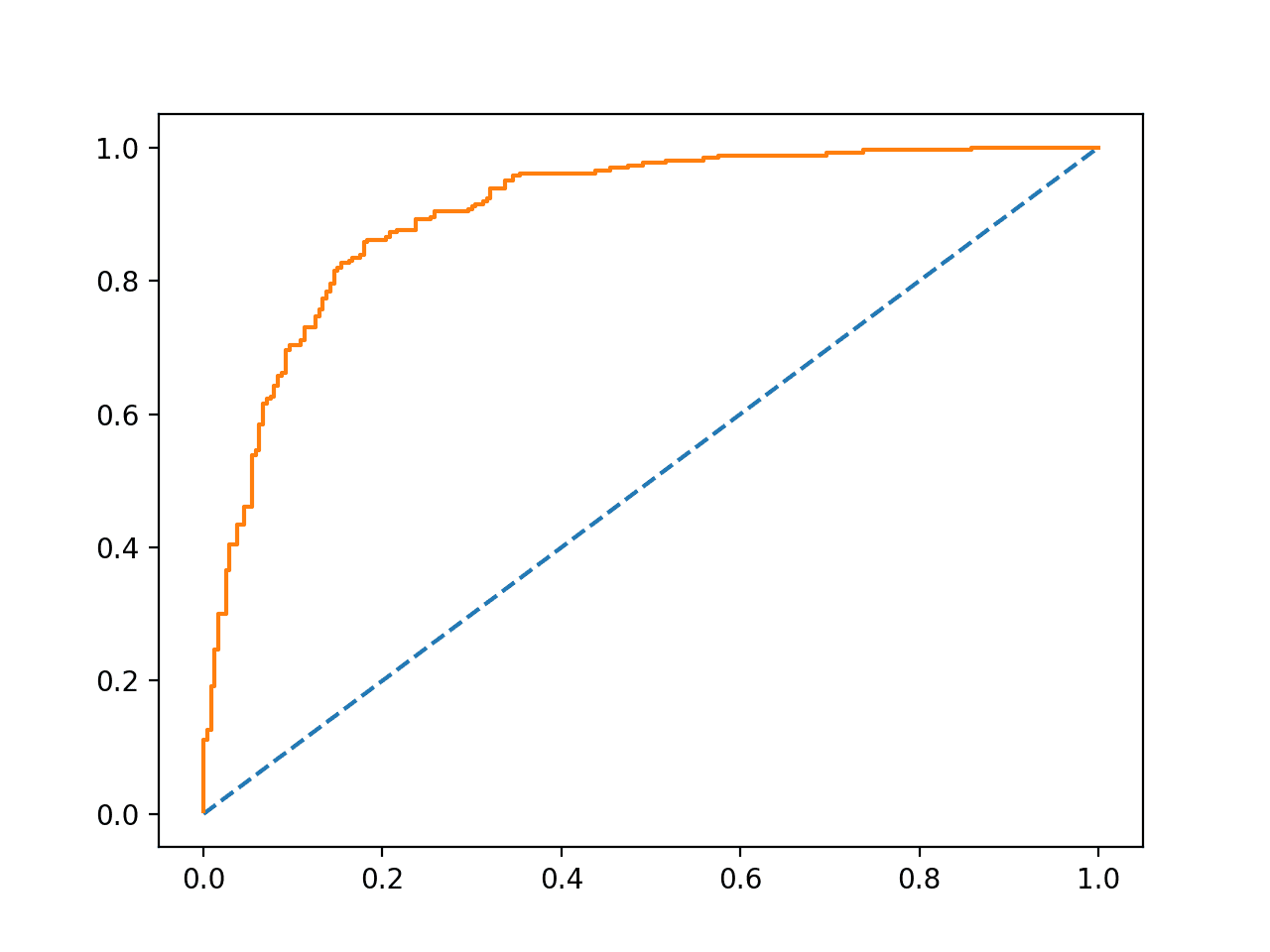
示例 ROC 曲线
ROC 曲线下的积分面积,称为 AUC 或 ROC AUC,提供了模型在所有评估阈值上的技能度量。
AUC 分数为 0.5 表示无技能,例如沿着对角线的曲线;而 AUC 为 1.0 表示技能完美,所有点都沿着左侧 y 轴和顶部 x 轴向左上角移动。AUC 为 0.0 表示完全错误的预测。
具有更大面积的模型在各个阈值上具有更好的技能,尽管不同模型之间的曲线形状会有所不同,这可能为操作员在模型准备好之后选择特定阈值来优化模型提供了机会。
AUC 可以使用 scikit-learn 中的 roc_auc_score() 函数在 Python 中计算。
该函数以实际输出值列表和预测概率列表作为参数,并返回 ROC AUC。
例如
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.metrics import roc_auc_score ... model = ... testX, testy = ... # 预测概率 probs = model.predict_proba(testX) # 只保留类别 1 的预测 probs = probs[:, 1] # 计算对数损失 loss = roc_auc_score(testy, probs) |
AUC 分数是衡量产生预测的模型将随机选择的正例排在随机选择的负例之前的可能性。具体来说,它衡量了真实事件(类别=1)的概率是否高于真实非事件(类别=0)的概率。
这是一个富有启发性的定义,提供了两个重要的直观认识:
- 朴素预测。ROC AUC 下的朴素预测是任何恒定概率。如果对每个示例都预测相同的概率,则正例和负例之间没有区分,因此模型没有技能(AUC=0.5)。
- 对类别不平衡的鲁棒性。ROC AUC 总结了模型在不同阈值下正确区分单个示例的能力。因此,它不关心每个类别的基本可能性。
下面,演示 ROC 曲线的示例已更新为计算和显示 AUC。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# ROC AUC from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score from matplotlib import pyplot # 生成 2 类数据集 X, y = make_classification(n_samples=1000, n_classes=2, random_state=1) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2) # 拟合模型 model = LogisticRegression() model.fit(trainX, trainy) # 预测概率 probs = model.predict_proba(testX) # 只保留正向结果的概率 probs = probs[:, 1] # 计算 ROC AUC auc = roc_auc_score(testy, probs) print(auc) |
运行示例将计算并打印逻辑回归模型在 500 个新示例上评估的 ROC AUC。
|
1 |
0.9028044871794871 |
选择 ROC AUC 的一个重要考虑因素是,它不总结模型的特定判别能力,而是总结所有阈值上的通用判别能力。
它可能更适合用于模型选择,而不是量化模型预测概率的实际技能。
调整预测概率
预测的概率可以调整以提高甚至“操纵”性能指标。
例如,对数损失和 Brier 分数量化了概率的平均误差量。因此,可以通过几种方式调整预测概率来提高这些分数:
- 使概率不那么“尖锐”(不那么自信)。这意味着将预测概率从硬性的 0 和 1 界限移开,以限制完全错误的惩罚影响。
- 将分布转移到朴素预测(基础率)。这意味着将预测概率的平均值转移到基础率的概率,例如平衡预测问题的 0.5。
通常,使用可靠性图等工具来审查概率的校准可能很有用。这可以使用 scikit-learn 中的 calibration_curve() 函数来实现。
某些算法,例如 SVM 和神经网络,可能无法原生预测校准的概率。在这些情况下,可以校准这些概率,进而可能改进所选的指标。可以使用 scikit-learn 中的 CalibratedClassifierCV 类来校准分类器。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
- sklearn.metrics.log_loss API
- sklearn.metrics.brier_score_loss API
- sklearn.metrics.roc_curve API
- sklearn.metrics.roc_auc_score API
- sklearn.calibration.calibration_curve API
- sklearn.calibration.CalibratedClassifierCV API
文章
总结
在本教程中,您了解了可用于评估分类预测建模问题中的预测概率的三种指标。
具体来说,你学到了:
- 对数损失分数,它会严重惩罚与期望值相距甚远的预测概率。
- Brier 分数,它比对数损失更温和,但仍然会根据与期望值的距离进行惩罚
- ROC 曲线下面积,它总结了模型为真阳性案例预测比真阴性案例更高的概率的可能性。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







非常感谢。我计算了我马匹评分的 Brier 技能分数。我是通过计算朴素分数来做到的,即使用 Brier 应用于数据集中获胜者的比例,即 0.1055 或 10.55%。将其与 Brier 技能分数公式和原始 Brier 分数一起使用,我得到的 BSS 为 0.0117。
这比零好,这很好,但有多好?
要使其成为有效的模型性能分数,您需要计算一个时期内所有预测的分数。
您是否有最大似然分类的教程?基本上,我想为 X 中的每个特征计算一个概率阈值,以针对类别 0 或 1。您知道如何实现吗?
没有,抱歉。
是的,我计算了 Brier 基础得分 0.1055,然后计算了我所有评分的 Brier 得分,总共有 49,277 个。
谢谢你,Jason。
我注意到 Brier 得分有些奇怪
brier_score_loss([1], [1], pos_label=1)返回 1 而不是 0。brier_score_loss([1], [0], pos_label=1)返回 0 而不是 1。查看源代码,
brier_score_loss仅在y_true包含单个唯一类别(例如[1])时才会出现此故障。这源于一个已在此报告的错误
https://github.com/scikit-learn/scikit-learn/issues/9300
您的代码的一个快速解决方法是将此行替换为
losses = [brier_score_loss([1], [x], pos_label=[1]) for x in yhat]
为以下内容
losses = [2 * brier_score_loss([0, 1], [0, x], pos_label=[1]) for x in yhat]
有趣。我猜使用 Brier 评估单个预测没有太大意义。
Brier 得分应适用于任何数量的预测。
sklearn中的错误不应改变这一点。🙂当您有多个预测但它们都共享相同的真实标签时,该 sklearn 错误也会被触发。
感谢分享。
“AUC 值为 0.0 表示没有技能”——这里应该是 0.5 AUC,对吧?0.0 将表示完美的技能,您只需要反转类别。
好文章!解释得非常好。谢谢。
谢谢,已修复!
嗨,Jason,
我正在为 Random Forest Model 使用 Log Loss,但不知何故我的 Log Loss 分数高于 1 (1.53)。您是否知道这是为什么?
谢谢!
是的,这可能是很多原因。
我在这里有一些建议
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
嗨,Jason!
感谢您的机器学习帖子。非常有帮助!
我的问题与更好地理解二元分类的概率预测与相同二元分类的回归预测(具有连续数值输出)有关。
想象一下我有两组事物,所以我说的是二元分类。例如,我使用“sigmoid”函数作为我的 keras 模型中唯一的输出神经元。好的。
但无论如何,想象一下内在问题不是离散的(两个值或类别),而是类之间的连续值演变,无论如何我都可以通过设置例如 0.5 的概率作为区分一个类别与另一个类别的边界或阈值来简化。好的。没问题。
但是当我应用回归预测时(我也在我的模型中设置了一个输出层作为单个神经元)。但我得到了连续的输出值。
我的问题是:二元分类的连续概率(介于 0 和 1 之间)是否等同于回归分类的回归值,在两个类别之间的演变方面(即使回归值不是 0 和 1 的限制,而是可以从负无穷到正无穷)?对吗?
谢谢你
可能,如果我没理解错的话。
如果我们使用交叉熵损失来优化模型,那么网络的输出层可以是 sigmoid 或线性。我们使用 sigmoid 是因为我们知道它总是会得到 [0,1] 之间的值。它可以是线性激活,模型需要更努力地去做正确的事情。
这有帮助吗?
嗨 Jason,感谢您发布这篇出色且有用的教程!我学到的东西
(1) AUC ROC 分数的解释,即模型将随机选择的阳性示例排名高于随机选择的阴性示例的几率。
(2) AUC ROC 分数对类别不平衡具有鲁棒性。
(3) Brier 分数和交叉熵损失在类别不平衡下都受到“过度自信偏差”的影响
(4) Brier Skill Score 对类别不平衡具有鲁棒性
问题:交叉熵损失是否有修改版本,它是 Brier Skill Score 的类似物?也就是说,是否有修改版本的交叉熵损失可以减轻类别不平衡下的“过度自信偏差”?
做得好!
我不确定我是否理解,它们衡量的是不同的东西。各有利弊,等等。
明白了“各有利弊”这一点。
那我再试一次。忽略对 Brier 分数的任何提及
是否存在一个修改版的交叉熵分数,在类别不平衡下是无偏的?
据我所知,没有。
嗨,Jason,
嗨,Jason,
我创建了分类模型,
但我发现对于相同的数据,我得到了其他概率,
当我运行训练过程和使用模型时。
请建议
您具体指的是什么,或许您可以详细说明一下?
感谢 Jason 的精彩文章。
我有一个关于 Brier 分数使用的问题(请记住,我对 ML 和 Python 都非常陌生)。我目前正在使用 Brier 分数来评估构建的模型。模型的目标是预测二元事件的估计概率,因此我认为 Brier 分数适用于此情况。但是,我正在使用 lightgbm 包中的交叉验证和 random_search 来确定最佳超参数。‘brier’s score’ 不是 ‘lgb.cv’ 中可用的指标,这意味着我无法轻松选择导致 Brier 分数最低值的参数。在这种情况下,MSE 等效吗?也就是说,我能否使用 MSE 作为 CV 和超参数选择的评估指标,然后使用 Brier 分数评估最终模型以获得更合理的解释?
谢谢,
Rex
谢谢 Rex。
好问题。
一般来说,我鼓励您使用模型进行预测,将其保存到文件,然后在新的 Python 程序中加载它们并进行一些分析,包括计算指标。
我不了解 lightgbm,但也许您可以定义一个新指标函数并利用 sklearn 的 brier skill?
嗨,Jason,
感谢这个很棒的教程!
我对 Brier 感到有些困惑,但当我运行示例时,它清楚地表明您的图片被镜像了,并且 yhat==1 的 Brier 损失为零。
我使用的是 sklearn 0.21.3。
谢谢,很高兴对您有帮助。
你好,我似乎无法理解阳性类别和阴性类别的概念。例如,在患者是否患有癌症的背景下。阳性类别是“患有癌症”类别。但在预测一个物体是狗还是猫的背景下,我们如何确定哪个类别是阳性类别?或者无论我们做出何种选择,都没有任何重要性?
谢谢你
在这种情况下不适用,或者选择是任意的。
Jason,精彩的文本!
在讲座期间发现了 2 个小笔误(在 Log-Loss 和 Brier Score 部分)
# 定义一个*不平衡*数据集
testy = [0 for x in range(50)] + [1 for x in range(50)]
此致!
谢谢,已修复!
嗨,Jason,
看起来“Brier 分数评估的线图”不正确
怎么会呢?
嗨,Jason,
很棒的文章!谢谢。我认为“Brier 分数评估的线图”应该反过来。因为您正在评估 1 个真实值而非 0 个真实值的预测。
谢谢。
你好 Jason。如何使用分数来衡量特征重要性?我希望在估计概率后选择少数特征。
您必须使用统计特征选择方法,请参阅此
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
嗨,Jason,
一如既往的精彩帖子。考虑一个不平衡的分类问题。5% 是阳性病例。二元分类问题。我们要求一个能够预测概率的模型,并且阳性类别更重要。
在包含数据采样方法(例如 SmoteTeeNN)的管道中使用概率预测方法指标(如 Brier skill score)是否有意义?
PS:我向这里的用户推荐您的书籍!🙂 值得投资,以自上而下的方式学习机器学习。
我尽量避免带有前瞻性,也许这个决策树会有帮助。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
感谢您提供信息丰富的文章。
Brier 分数似乎与均方误差 (MSE) 相同。
这正确吗?
如果确实如此,那么通过取 MSE 的平方根,即 RMSE,使用与数据相同的单位来报告误差项是否更好?
是的,计算相同。
我不这么认为——我还没有看到报告的 Brier 分数(RMSE)的平方根。
嗨,Jason,
我们感谢您的观点。
一个快速的问题:如何将 ROC AUC 应用于涉及多个类的情况?
嗨 Issakafadil……您可能会发现以下内容很有趣
https://towardsdatascience.com/multiclass-classification-evaluation-with-roc-curves-and-roc-auc-294fd4617e3a