生成对抗网络,简称 GANs,在生成高质量合成图像方面非常有效。
GANs 的一个局限性是它们只能生成相对较小的图像,例如 64x64 像素。
渐进增长 GAN 是 GAN 训练过程的扩展,它涉及训练 GAN 生成非常小的图像(例如 4x4),然后逐步增加生成图像的大小,直到达到所需的输出大小,例如 8x8、16x16。这使得渐进增长 GAN 能够生成 1024x1024 像素分辨率的逼真合成人脸。
渐进增长 GAN 的关键创新是两阶段训练过程,包括新块的“淡入”以支持更高分辨率图像,然后是微调。
在本教程中,您将学习如何在 Keras 中实现和训练渐进增长生成对抗网络,以生成名人面孔。
完成本教程后,您将了解:
- 如何准备名人面孔数据集以训练渐进增长 GAN 模型。
- 如何定义和训练渐进增长 GAN 以生成名人面孔数据集。
- 如何加载已保存的生成器模型并使用它们生成即时合成名人面孔。
通过我的新书《Python 生成对抗网络》启动您的项目,其中包括逐步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019年9月更新:修复了训练期间总结性能时的一个小错误。

如何在 Keras 中训练渐进增长 GAN 以合成人脸。
照片来源:Alessandro Caproni,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是渐进增长 GAN
- 如何准备名人面孔数据集
- 如何开发渐进增长 GAN 模型
- 如何训练渐进增长 GAN 模型
- 如何使用渐进增长 GAN 模型合成图像
什么是渐进增长 GAN
GANs 在生成清晰的合成图像方面是有效的,尽管通常受限于可生成图像的大小。
渐进增长 GAN 是 GAN 的扩展,它允许训练生成器模型能够生成大型高质量图像,例如 1024x1024 像素大小的逼真人脸。它由 Nvidia 的 Tero Karras 等人在 2017 年的论文“GAN 的渐进增长以提高质量、稳定性和多样性”中描述。
渐进增长 GAN 的关键创新是生成器输出图像尺寸的逐步增加,从 4x4 像素图像开始,然后倍增到 8x8、16x16,依此类推,直到达到所需的输出分辨率。
这是通过一个训练过程实现的,该过程包括在给定输出分辨率下对模型进行微调的阶段,以及缓慢引入更大分辨率新模型的阶段。在训练过程中,所有层都保持可训练,包括添加新层时的现有层。
渐进增长 GAN 涉及使用具有相同通用结构且从非常小的图像开始的生成器和判别器模型。在训练过程中,新的卷积层块系统地添加到生成器模型和判别器模型中。
层的增量添加使模型能够有效地学习粗粒度细节,然后学习越来越精细的细节,无论是在生成器还是判别器方面。
这种渐进的性质使得训练首先发现图像分布的大尺度结构,然后将注意力转移到越来越精细的细节,而不是同时学习所有尺度。
下一步是选择一个数据集来开发渐进增长 GAN。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何准备名人面孔数据集
在本教程中,我们将使用 大规模名人面孔属性数据集,简称 CelebA。
该数据集由 Ziwei Liu 等人在其 2015 年的论文“从面部部分响应到面部检测:一种深度学习方法”中开发和发布。
该数据集提供了大约 20 万张名人面孔照片,以及照片中出现内容的注释,例如眼镜、脸型、帽子、发型等。作为数据集的一部分,作者提供了每张照片以脸部为中心并裁剪成肖像的版本,大小约为 150 像素宽和 200 像素高。我们将以此作为开发 GAN 模型的基础。
该数据集可以轻松地从 Kaggle 网页下载。注意:这可能需要一个 Kaggle 账户。
具体来说,下载文件“img_align_celeba.zip”,大小约为 1.3 GB。为此,请在 Kaggle 网站上点击文件名,然后点击下载图标。
下载可能需要一段时间,具体取决于您的互联网连接速度。
下载后,解压存档。
这将创建一个名为“img_align_celeba”的新目录,其中包含所有图像,文件名类似 202599.jpg 和 202598.jpg。
使用 GAN 时,如果所有图像都小而呈方形,则更容易建模数据集。
此外,由于我们只对照片中的面部感兴趣,而不是背景,因此我们可以执行面部检测并仅提取面部,然后将结果调整为固定大小。
有多种方法可以执行人脸检测。在本例中,我们将使用预训练的 多任务级联卷积神经网络(MTCNN)。这是一种最先进的深度学习人脸检测模型,在 2016 年题为“使用多任务级联卷积网络进行联合人脸检测和对齐”的论文中有所描述。
我们将使用 Iván de Paz Centeno 在 ipazc/mtcnn 项目中提供的实现。也可以通过 pip 安装,如下所示:
|
1 |
sudo pip install mtcnn |
我们可以通过导入库并打印版本来确认库是否正确安装;例如
|
1 2 3 4 |
# 确认 mtcnn 是否正确安装 import mtcnn # 打印版本 print(mtcnn.__version__) |
运行示例会打印库的当前版本。
|
1 |
0.0.8 |
MTCNN 模型非常易于使用。
首先,创建一个 MTCNN 模型实例,然后可以调用 detect_faces() 函数,传入一张图像的像素数据。
结果是一个检测到的人脸列表,其中包含以像素偏移值定义的边界框。
|
1 2 3 4 5 6 7 |
... # 准备模型 model = MTCNN() # 检测图像中的人脸 faces = model.detect_faces(pixels) # 提取人脸细节 x1, y1, width, height = faces[0]['box'] |
尽管渐进增长 GAN 支持合成大图像,例如 1024x1024,但这需要巨大的资源,例如一台顶级 GPU 训练模型一个月。
相反,我们将生成图像的大小减小到 128x128,这将使我们能够在数小时内在 GPU 上训练一个合理的模型,并且仍然能够了解如何实现、训练和使用渐进增长模型。
因此,我们可以开发一个函数来加载文件并从照片中提取面部,然后将提取的面部像素调整为预定义的大小。在这种情况下,我们将使用 128x128 像素的正方形形状。
下面的 load_image() 函数将给定照片文件名加载为像素的 NumPy 数组。
|
1 2 3 4 5 6 7 8 9 |
# 将图像加载为 rgb numpy 数组 def load_image(filename): # 从文件加载图像 image = Image.open(filename) # 如果需要,转换为 RGB image = image.convert('RGB') # 转换为数组 pixels = asarray(image) return pixels |
下面的 extract_face() 函数将 MTCNN 模型和单张照片的像素值作为参数,并返回一个 128x128x3 的仅含面部的像素值数组,如果未检测到面部则返回 None(这种情况很少发生)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 从加载的图像中提取人脸并调整大小 def extract_face(model, pixels, required_size=(128, 128)): # 检测图像中的人脸 faces = model.detect_faces(pixels) # 跳过未检测到人脸的情况 if len(faces) == 0: return None # 提取人脸细节 x1, y1, width, height = faces[0]['box'] # 强制检测到的像素值为正(bug 修复) x1, y1 = abs(x1), abs(y1) # 转换为坐标 x2, y2 = x1 + width, y1 + height # 检索人脸像素 face_pixels = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face_pixels) image = image.resize(required_size) face_array = asarray(image) return face_array |
下面的 load_faces() 函数枚举目录中的所有照片文件,提取并调整每张照片中的面部,然后返回一个 NumPy 面部数组。
我们通过 n_faces 参数限制加载的面部总数,因为我们不需要所有面部。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 加载图像并提取目录中所有图像的人脸 def load_faces(directory, n_faces): # 准备模型 model = MTCNN() faces = list() # 枚举文件 for filename in listdir(directory): # 加载图像 pixels = load_image(directory + filename) # 获取人脸 face = extract_face(model, pixels) if face is None: continue # 存储 faces.append(face) print(len(faces), face.shape) # 一旦我们加载了足够的面孔,就停止 if len(faces) >= n_faces: break return asarray(faces) |
综合以上,下面列出了准备名人面孔数据集以训练 GAN 模型的完整示例。
在本例中,我们将加载的面孔总数增加到 50,000,为我们的 GAN 模型提供一个良好的训练数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
# 提取人脸并调整大小以创建新数据集的示例 from os import listdir from numpy import asarray from numpy import savez_compressed from PIL import Image from mtcnn.mtcnn import MTCNN from matplotlib import pyplot # 将图像加载为 rgb numpy 数组 def load_image(filename): # 从文件加载图像 image = Image.open(filename) # 如果需要,转换为 RGB image = image.convert('RGB') # 转换为数组 pixels = asarray(image) return pixels # 从加载的图像中提取人脸并调整大小 def extract_face(model, pixels, required_size=(128, 128)): # 检测图像中的人脸 faces = model.detect_faces(pixels) # 跳过未检测到人脸的情况 if len(faces) == 0: return None # 提取人脸细节 x1, y1, width, height = faces[0]['box'] # 强制检测到的像素值为正(bug 修复) x1, y1 = abs(x1), abs(y1) # 转换为坐标 x2, y2 = x1 + width, y1 + height # 检索人脸像素 face_pixels = pixels[y1:y2, x1:x2] # 将像素调整到模型大小 image = Image.fromarray(face_pixels) image = image.resize(required_size) face_array = asarray(image) return face_array # 加载图像并提取目录中所有图像的人脸 def load_faces(directory, n_faces): # 准备模型 model = MTCNN() faces = list() # 枚举文件 for filename in listdir(directory): # 加载图像 pixels = load_image(directory + filename) # 获取人脸 face = extract_face(model, pixels) if face is None: continue # 存储 faces.append(face) print(len(faces), face.shape) # 一旦我们加载了足够的面孔,就停止 if len(faces) >= n_faces: break return asarray(faces) # 包含所有图像的目录 directory = 'img_align_celeba/' # 加载并提取所有面孔 all_faces = load_faces(directory, 50000) print('Loaded: ', all_faces.shape) # 以压缩格式保存 savez_compressed('img_align_celeba_128.npz', all_faces) |
鉴于要加载的面孔数量较多,运行此示例可能需要几分钟。
运行结束时,提取并调整大小的面部数组将以压缩的 NumPy 数组格式保存,文件名为“img_align_celeba_128.npz”。
然后,可以随时加载准备好的数据集,如下所示。
|
1 2 3 4 5 6 |
# 加载准备好的数据集 from numpy import load # 加载人脸数据集 data = load('img_align_celeba_128.npz') faces = data['arr_0'] print('Loaded: ', faces.shape) |
加载数据集会汇总数组的形状,显示 50K 张图像,大小为 128x128 像素,具有三个颜色通道。
|
1 |
已加载:(50000, 128, 128, 3) |
我们可以详细说明这个例子,并将数据集中的前 100 张人脸绘制成 10x10 的网格。完整的示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 加载准备好的数据集 from numpy import load from matplotlib import pyplot # 绘制已加载人脸列表 def plot_faces(faces, n): for i in range(n * n): # 定义子图 pyplot.subplot(n, n, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(faces[i].astype('uint8')) pyplot.show() # 加载人脸数据集 data = load('img_align_celeba_128.npz') faces = data['arr_0'] print('Loaded: ', faces.shape) plot_faces(faces, 10) |
运行该示例将加载数据集并创建前 100 张图像的图。
我们可以看到每张图像只包含面部,并且所有面部都具有相同的方形形状。我们的目标是生成具有相同通用属性的新面部。
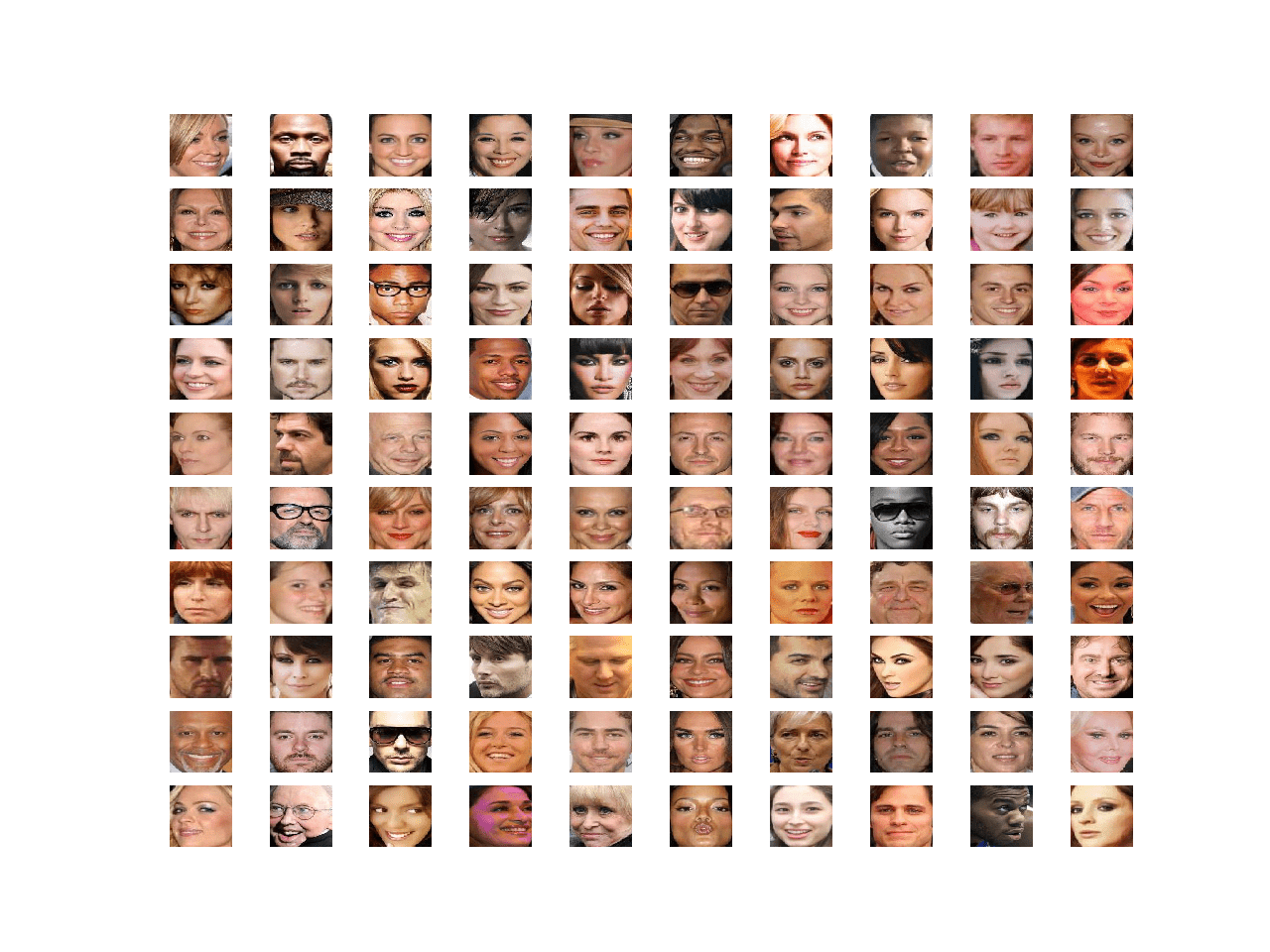
10x10 网格中的 100 张名人面孔图
我们现在准备开发一个 GAN 模型,使用该数据集生成面孔。
如何开发渐进增长 GAN 模型
实现渐进增长 GAN 模型有多种方法。
在本教程中,我们将把每个增长阶段开发和实现为单独的 Keras 模型,并且每个模型将共享相同的层和权重。
这种方法允许像训练普通 Keras 模型一样方便地训练每个模型,尽管它需要稍微复杂的模型构建过程,以确保层被正确重用。
首先,我们将定义生成器和判别器模型定义中所需的某些自定义层,然后继续定义用于创建和增长判别器和生成器模型本身的函数。
渐进增长自定义层
实现渐进增长生成对抗网络需要三个自定义层。
它们是以下层:
- WeightedSum:用于控制增长阶段旧层和新层的加权和。
- MinibatchStdev:用于总结判别器中图像批次的统计信息。
- PixelNormalization:用于归一化生成器模型中的激活图。
此外,论文中使用了称为“均衡学习率”的权重约束。这同样需要作为自定义层实现。为了简洁起见,本教程中我们不使用均衡学习率,而是使用简单的最大范数权重约束。
WeightedSum 层
`WeightedSum` 层是一个合并层,它结合了来自两个输入层(例如判别器中的两个输入路径或生成器模型中的两个输出路径)的激活。它使用一个名为 `alpha` 的变量,该变量控制对第一个和第二个输入的加权程度。
它用于训练的增长阶段,当模型从一个图像大小过渡到宽度和高度翻倍(面积翻四倍)的新图像大小时,例如从 4x4 到 8x8 像素。
在生长阶段,alpha 参数从开始时的 0.0 线性缩放到结束时的 1.0,允许层的输出从对旧层给予完全权重过渡到对新层(第二个输入)给予完全权重。
- 加权和 = ((1.0 – alpha) * input1) + (alpha * input2)
`WeightedSum` 类定义如下,作为 `Add` 合并层的扩展。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output |
MinibatchStdev
迷你批次标准差层(MinibatchStdev)仅用于判别器层的输出块。
该层的目标是提供激活批次的统计摘要。判别器可以学习更好地从真实样本批次中检测伪造样本批次。这反过来鼓励通过判别器训练的生成器创建具有真实批次统计的样本批次。
它的实现方式是计算激活图中每个像素值在批次中的标准差,计算该值的平均值,然后创建一个新的激活图(一个通道),并将其附加到作为输入提供的激活图列表中。
MinibatchStdev 层定义如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 迷你批次标准差层 class MinibatchStdev(Layer): # 初始化层 def __init__(self, **kwargs): super(MinibatchStdev, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算跨通道每个像素的平均值 mean = backend.mean(inputs, axis=0, keepdims=True) # 计算像素值与平均值之间的平方差 squ_diffs = backend.square(inputs - mean) # 计算平方差的平均值(方差) mean_sq_diff = backend.mean(squ_diffs, axis=0, keepdims=True) # 添加一个很小的值以避免在计算标准差时出现爆炸 mean_sq_diff += 1e-8 # 方差的平方根(标准差) stdev = backend.sqrt(mean_sq_diff) # 计算每个像素坐标的平均标准差 mean_pix = backend.mean(stdev, keepdims=True) # 将此放大到每个样本的一个输入特征图的大小 shape = backend.shape(inputs) output = backend.tile(mean_pix, (shape[0], shape[1], shape[2], 1)) # 与输出连接 combined = backend.concatenate([inputs, output], axis=-1) return combined # 定义层的输出形状 def compute_output_shape(self, input_shape): # 创建输入形状的副本作为列表 input_shape = list(input_shape) # 通道维度加一(假设通道在最后) input_shape[-1] += 1 # 将列表转换为元组 return tuple(input_shape) |
PixelNormalization
生成器和判别器模型不使用批归一化,与其他 GAN 模型不同;相反,激活图中的每个像素都被归一化到单位长度。
这是局部响应归一化的一种变体,在论文中被称为像素级特征向量归一化。此外,与其他 GAN 模型不同,归一化仅用于生成器模型,而不用于判别器。
这是一种活动正则化类型,可以作为活动约束实现,尽管它可以很容易地作为新层实现,以缩放前一层次的激活。
下面的 PixelNormalization 类实现了这一点,可以在生成器中每个卷积层之后,但在任何激活函数之前使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 像素级特征向量归一化层 class PixelNormalization(Layer): # 初始化层 def __init__(self, **kwargs): super(PixelNormalization, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算像素平方值 values = inputs**2.0 # 计算平均像素值 mean_values = backend.mean(values, axis=-1, keepdims=True) # 确保均值不为零 mean_values += 1.0e-8 # 计算均方值的平方根 (L2 范数) l2 = backend.sqrt(mean_values) # 通过 L2 范数归一化值 normalized = inputs / l2 return normalized # 定义层的输出形状 def compute_output_shape(self, input_shape): return input_shape |
我们现在已经具备了所有必需的自定义层,可以定义我们的模型了。
渐进增长判别器模型
判别器模型被定义为一个深度卷积神经网络,它接受 4x4 的彩色图像作为输入,并预测它是真实的还是伪造的。
第一个隐藏层是一个 1x1 卷积层。输出块包括 MinibatchStdev、3x3 和 4x4 卷积层,以及一个输出预测的全连接层。Leaky ReLU 激活函数用于所有层之后,输出层使用线性激活函数。
该模型经过正常间隔训练后,将进入增长阶段,尺寸增加到 8x8。这涉及添加一个包含两个 3x3 卷积层和一个平均池化下采样层的块。输入图像通过新的块,其中包含一个新的1x1 卷积隐藏层。输入图像也通过下采样层和旧的 1x1 卷积隐藏层。旧的 1x1 卷积层和新块的输出通过 WeightedSum 层组合。
在 WeightedSum 的 alpha 参数从 0.0(全部旧)过渡到 1.0(全部新)的训练间隔之后,将运行另一个训练阶段来微调新的模型,同时移除旧的层和路径。
这个过程重复进行,直到达到所需的图像大小,在我们的例子中是 128x128 像素的图像。
我们可以通过两个函数实现这一点:`define_discriminator()` 函数定义接受 4x4 图像的基本模型,而 `add_discriminator_block()` 函数接受一个模型并创建该模型的增长版本,该版本具有两条路径和 `WeightedSum`,以及该模型的第二个版本,具有相同的层/权重,但没有旧的 1x1 层和 `WeightedSum` 层。然后,`define_discriminator()` 函数可以根据需要多次调用 `add_discriminator_block()` 函数,以创建达到所需增长级别的模型。
所有层都用标准差为 0.02 的小高斯随机数初始化,这在 GAN 模型中很常见。这里使用了值为 1.0 的最大范数权重约束,而不是论文中使用的更复杂的“均衡学习率”权重约束。
论文中定义了随着模型深度增加而增加的滤波器数量,从 16 到 32、64,一直到 512。这需要在增长阶段投影特征图的数量,以便正确计算加权和。为了避免这种复杂性,我们将所有层中的滤波器数量固定为相同。
每个模型都将被编译并进行拟合。在这种情况下,我们将使用 Wasserstein 损失(或 WGAN 损失)和Adam 版本的随机梯度下降,按照论文中指定的方式进行配置。论文的作者建议探索使用 WGAN-GP 损失和最小二乘损失,并发现前者表现略好。然而,我们将使用 Wasserstein 损失,因为它大大简化了实现。
首先,我们必须将损失函数定义为平均预测值乘以目标值。目标值对于真实图像为 1,对于伪造图像为 -1。这意味着权重更新将寻求增加真实图像和伪造图像之间的差异。
|
1 2 3 |
# 计算 Wasserstein 损失 def wasserstein_loss(y_true, y_pred): return backend.mean(y_true * y_pred) |
下面列出了定义和创建判别器模型增长版本的函数。
我们巧妙地利用了函数式 API 和对模型结构的了解,为每个增长阶段创建了两个模型。增长阶段也总是使预期输入形状加倍。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
# 添加判别器块 def add_discriminator_block(old_model, n_input_layers=3): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 定义新输入形状为现有尺寸的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 d = Conv2D(128, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(in_image) d = LeakyReLU(alpha=0.2)(d) # 定义新块 d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # 跳过旧模型的输入、1x1 和激活层 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model1 = Model(in_image, d) # 编译模型 model1.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 对新的大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧输入处理连接到下采样的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 将旧模型输入层的输出与新输入进行淡入融合 d = WeightedSum()([block_old, block_new]) # 跳过旧模型的输入、1x1 和激活层 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model2 = Model(in_image, d) # 编译模型 model2.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # 定义每个图像分辨率的判别器模型 def define_discriminator(n_blocks, input_shape=(4,4,3)): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) model_list = list() # 基本模型输入 in_image = Input(shape=input_shape) # 卷积 1x1 d = Conv2D(128, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(in_image) d = LeakyReLU(alpha=0.2)(d) # 卷积 3x3(输出块) d = MinibatchStdev()(d) d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) # 卷积 4x4 d = Conv2D(128, (4,4), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) # 全连接输出层 d = Flatten()(d) out_class = Dense(1)(d) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取之前没有淡入的模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_discriminator_block(old_model) # 存储模型 model_list .append(models) return model_list |
调用 define_discriminator() 函数时需要指定要创建的块的数量。
我们将创建 6 个块,这将创建 6 对模型,它们期望的输入图像大小分别为 4x4、8x8、16x16、32x32、64x64 和 128x128。
该函数返回一个列表,列表中每个元素都包含两个模型。第一个模型是“正常模型”或直通模型,第二个是包含旧的 1x1 和新的带有加权和的块的模型版本,用于训练的过渡或增长阶段。
渐进增长生成器模型
生成器模型接收潜在空间中的随机点作为输入,并生成合成图像。
生成器模型的定义方式与判别器模型相同。
具体来说,定义了一个用于生成 4x4 图像的基础模型,并为大型图像输出尺寸创建了模型的增长版本。
主要区别在于,在增长阶段,模型的输出是 WeightedSum 层的输出。模型的增长阶段版本首先涉及添加一个最近邻上采样层;然后将其连接到带有新输出层的新块以及旧的输出层。然后通过 WeightedSum 输出层将旧的和新的输出层组合起来。
基础模型有一个输入块,其定义为具有足够激活的全连接层,以创建给定数量的 4x4 特征图。这之后是4x4 和 3x3 卷积层,以及一个生成彩色图像的1x1 输出层。新的块通过一个上采样层和两个 3x3 卷积层添加。
在每个卷积层之后使用 LeakyReLU 激活函数和 PixelNormalization 层。输出层使用线性激活函数,而不是更常见的 tanh 函数,但真实图像仍被缩放至 [-1,1] 范围,这在大多数 GAN 模型中很常见。
论文中定义的特征图数量随着模型深度的增加而减少,从 512 减少到 16。与判别器一样,块之间特征图数量的差异给 WeightedSum 带来了挑战,因此为简单起见,我们将所有层的滤波器数量固定为相同。
与判别器模型一样,权重用标准差为 0.02 的高斯随机数初始化,并使用值为 1.0 的最大范数权重约束,而不是论文中使用的均衡学习率权重约束。
下面定义了用于定义和增长生成器模型的函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# 添加生成器块 def add_generator_block(old_model): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) # 获取上一个块的末端 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(upsampling) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新的输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(g) # 定义模型 model1 = Model(old_model.input, out_image) # 从旧模型获取输出层 out_old = old_model.layers[-1] # 将上采样连接到旧输出层 out_image2 = out_old(upsampling) # 将新输出图像定义为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) return [model1, model2] # 定义生成器模型 def define_generator(latent_dim, n_blocks, in_dim=4): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) model_list = list() # 基本模型潜在输入 in_latent = Input(shape=(latent_dim,)) # 线性缩放至激活图 g = Dense(128 * in_dim * in_dim, kernel_initializer=init, kernel_constraint=const)(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # 卷积 4x4,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 1x1,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(g) # 定义模型 model = Model(in_latent, out_image) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取之前没有淡入的模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_generator_block(old_model) # 存储模型 model_list .append(models) return model_list |
调用 define_generator() 函数需要定义潜在空间的大小。
与判别器一样,我们将 n_blocks 参数设置为 6,以创建六对模型。
该函数返回一个模型列表,其中列表中的每个项都包含每个生成器的正常或直通版本,以及用于在新块逐步引入更大输出图像尺寸时的增长版本。
用于训练生成器的复合模型
生成器模型不会被编译,因为它们不是直接训练的。
相反,生成器模型通过判别器模型使用 Wasserstein 损失进行训练。
这涉及将生成的图像作为真实图像呈现给判别器,并计算损失,然后用于更新生成器模型。
给定的生成器模型必须与给定的判别器模型配对,两者在图像尺寸(例如 4×4 或 8×8)和训练阶段(例如增长阶段(引入新块)或微调阶段(正常或直通))都必须相同。
我们可以通过为每对模型创建一个新模型来实现这一点,该模型将生成器堆叠在判别器之上,以便合成图像直接馈入判别器模型以被判定为真实或虚假。然后,这个复合模型可以用于通过判别器训练生成器,并且判别器的权重可以被标记为不可训练(仅在此模型中),以确保它们在此误导过程中不会被改变。
因此,我们可以创建多对复合模型,例如针对六个图像增长级别创建六对,其中每对都由一个用于正常或直通模型的复合模型和模型的增长版本组成。
define_composite() 函数实现了这一点,定义如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 定义用于通过判别器训练生成器的复合模型 def define_composite(discriminators, generators): model_list = list() # 创建复合模型 for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # 直通模型 d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 渐入模型 d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储 model_list.append([model1, model2]) return model_list |
现在我们已经了解了如何定义生成器和判别器模型,接下来让我们看看如何将这些模型拟合到名人面部数据集。
如何训练渐进增长 GAN 模型
首先,我们需要定义一些方便处理数据样本的函数。
下面的 load_real_samples() 函数加载我们准备好的名人面部数据集,然后将像素转换为浮点值并将其缩放到 [-1,1] 范围,这在大多数 GAN 实现中很常见。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载数据集 def load_real_samples(filename): # 加载数据集 data = load(filename) # 提取 numpy 数组 X = data['arr_0'] # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 return X |
接下来,我们需要能够检索用于更新判别器的图像随机样本。
下面的 generate_real_samples() 函数实现了这一点,它从加载的数据集中返回图像的随机样本及其对应的目标值 class=1,以表明这些图像是真实的。
|
1 2 3 4 5 6 7 8 9 |
# 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 选择图像 X = dataset[ix] # 生成类别标签 y = ones((n_samples, 1)) return X, y |
接下来,我们需要一个潜在点样本,用于通过生成器模型创建合成图像。
下面的 generate_latent_points() 函数实现了这一点,返回一批具有所需维度的潜在点。
|
1 2 3 4 5 6 7 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input |
潜在点可以用作生成器的输入,以创建一批合成图像。
这对于更新判别器模型是必需的。对于通过上一节中定义的复合模型通过判别器模型更新生成器模型也是必需的。
下面的 generate_fake_samples() 函数接受一个生成器模型,并生成并返回一批合成图像以及判别器的相应目标 class=-1,以表明这些图像是假的。调用 generate_latent_points() 函数以创建所需批次的随机潜在点。
|
1 2 3 4 5 6 7 8 9 |
# 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = generator.predict(x_input) # 创建类别标签 y = -ones((n_samples, 1)) return X, y |
模型的训练分为两个阶段:渐入阶段,涉及从低分辨率图像到高分辨率图像的转换;正常阶段,涉及在给定较高分辨率图像下对模型进行微调。
在渐入阶段,判别器和生成器模型中给定级别的 WeightedSum 层的 alpha 值需要根据训练步数从 0.0 线性过渡到 1.0。下面的 update_fadein() 函数实现了这一点;给定模型列表(例如生成器、判别器和复合模型),该函数在每个模型中找到 WeightedSum 层,并根据当前训练步数设置 alpha 属性的值。
重要的是,这个 alpha 属性不是一个常量,而是被定义为 WeightedSum 类中一个可更改的变量,其值可以使用 Keras 后端 set_value() 函数更改。
这是一种笨拙但有效的更改 alpha 值的方法。也许更简洁的实现会涉及 Keras 回调,并留作读者的练习。
|
1 2 3 4 5 6 7 8 9 |
# 更新 WeightedSum 的每个实例上的 alpha 值 def update_fadein(models, step, n_steps): # 计算当前 alpha(从 0 到 1 线性) alpha = step / float(n_steps - 1) # 更新每个模型的 alpha 值 for model in models: for layer in model.layers: if isinstance(layer, WeightedSum): backend.set_value(layer.alpha, alpha) |
接下来,我们可以定义给定训练阶段的模型训练过程。
一个训练阶段接受一个生成器、一个判别器和一个复合模型,并在数据集上更新它们,持续给定数量的训练 epoch。训练阶段可以是渐入到更高分辨率的过渡,在这种情况下必须每次迭代调用 update_fadein(),或者可以是正常的调整训练阶段,在这种情况下不存在 WeightedSum 层。
下面的 train_epochs() 函数实现了单个训练阶段的判别器和生成器模型的训练。
一次训练迭代首先从数据集中选择半批真实图像,并从生成器模型的当前状态生成半批虚假图像。然后使用这些样本来更新判别器模型。
接下来,通过判别器和复合模型更新生成器模型,表明生成的图像实际上是真实的,并更新生成器权重以更好地欺骗判别器。
在每次训练迭代结束时,会打印模型性能摘要,总结判别器在真实 (d1) 和虚假 (d2) 图像上的损失以及生成器 (g) 的损失。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 训练生成器和判别器 def train_epochs(g_model, d_model, gan_model, dataset, n_epochs, n_batch, fadein=False): # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset.shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_steps): # 在渐入新块时更新所有 WeightedSum 层的 alpha 值 if fadein: update_fadein([g_model, d_model, gan_model], i, n_steps) # 准备真实和虚假样本 X_real, y_real = generate_real_samples(dataset, half_batch) X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新判别器模型 d_loss1 = d_model.train_on_batch(X_real, y_real) d_loss2 = d_model.train_on_batch(X_fake, y_fake) # 通过判别器的误差更新生成器 z_input = generate_latent_points(latent_dim, n_batch) y_real2 = ones((n_batch, 1)) g_loss = gan_model.train_on_batch(z_input, y_real2) # 总结此批次的损失 print('>%d, d1=%.3f, d2=%.3f g=%.3f' % (i+1, d_loss1, d_loss2, g_loss)) |
接下来,我们需要为每个训练阶段调用 train_epochs() 函数。
这首先涉及将训练数据集缩放到所需的像素维度,例如 4×4 或 8×8。下面的 scale_dataset() 函数实现了这一点,它接收数据集并返回缩放后的版本。
这些缩放版本的数据集可以预先计算并加载,而不是在每次运行时重新缩放。如果您打算多次运行示例,这可能是一个不错的扩展。
|
1 2 3 4 5 6 7 8 9 |
# 将图像缩放到首选大小 def scale_dataset(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) |
每次训练运行后,我们还需要保存生成的图像的图和生成器模型的当前状态。
这很有用,这样在运行结束时我们可以看到模型能力和质量的进展,并且可以在训练过程中的任何时间点加载和使用生成器模型。生成器模型可以用于创建临时图像,或者用作继续训练的起点。
下面的 summarize_performance() 函数实现了这一点,它接受一个状态字符串(例如“faded”或“tuned”)、一个生成器模型和潜在空间的大小。该函数将使用“status”字符串为系统状态创建一个唯一名称,例如“04×04-faded”,然后创建 25 个生成图像的图,并使用定义好的名称将该图和生成器模型保存到文件中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 生成样本并保存为图,并保存模型 def summarize_performance(status, g_model, latent_dim, n_samples=25): # 设计名称 gen_shape = g_model.output_shape name = '%03dx%03d-%s' % (gen_shape[1], gen_shape[2], status) # 生成图像 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将像素值归一化到 [0,1] 范围 X = (X - X.min()) / (X.max() - X.min()) # 绘制真实图像 square = int(sqrt(n_samples)) for i in range(n_samples): pyplot.subplot(square, square, 1 + i) pyplot.axis('off') pyplot.imshow(X[i]) # 保存图到文件 filename1 = 'plot_%s.png' % (name) pyplot.savefig(filename1) pyplot.close() # 保存生成器模型 filename2 = 'model_%s.h5' % (name) g_model.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) |
下面的 train() 函数将这些功能整合在一起,它将已定义的模型列表作为输入,以及每个模型增长级别的批处理大小列表和正常和渐入阶段的训练周期数。
通过调用 train_epochs() 拟合 4×4 图像的第一个生成器和判别器模型,并通过调用 summarize_performance() 保存。
然后列举增长步骤,首先将图像数据集缩放到首选大小,训练并保存新图像大小的渐入模型,然后训练并保存新图像大小的正常或微调模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 训练生成器和判别器 def train(g_models, d_models, gan_models, dataset, latent_dim, e_norm, e_fadein, n_batch): # 拟合基线模型 g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm[0], n_batch[0]) summarize_performance('tuned', g_normal, latent_dim) # 处理每个增长级别 for i in range(1, len(g_models)): # 检索此增长级别的模型 [g_normal, g_fadein] = g_models[i] [d_normal, d_fadein] = d_models[i] [gan_normal, gan_fadein] = gan_models[i] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练渐入模型以进行下一级别的增长 train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein[i], n_batch[i], True) summarize_performance('faded', g_fadein, latent_dim) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm[i], n_batch[i]) summarize_performance('tuned', g_normal, latent_dim) |
然后,我们可以定义配置、模型,并调用 train() 开始训练过程。
该论文建议对尺寸在 4×4 到 128×128 之间的图像使用 16 的批处理大小,然后再减小尺寸。它还建议每个阶段训练大约 800K 图像。论文还建议使用 512 维的潜在空间。
模型定义了六个增长级别,以满足我们数据集 128×128 像素的大小。我们还将潜在空间相应地缩小到 100 维。
我们不是保持 批处理大小和 epoch 数量 不变,而是通过改变它们来加速训练过程,在早期训练阶段使用较大的批处理大小,在后期训练阶段使用较小的批处理大小进行微调和稳定性。此外,较小的模型使用较少的训练 epoch,较大的模型使用较多的 epoch。
批处理大小和训练 epoch 的选择有些随意,您可能需要尝试不同的值并查看它们的效果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 增长阶段的数量,例如 6 == [4, 8, 16, 32, 64, 128] n_blocks = 6 # 潜在空间的大小 latent_dim = 100 # 定义模型 d_models = define_discriminator(n_blocks) # 定义模型 g_models = define_generator(latent_dim, n_blocks) # 定义复合模型 gan_models = define_composite(d_models, g_models) # 加载图像数据 dataset = load_real_samples('img_align_celeba_128.npz') print('Loaded', dataset.shape) # 训练模型 n_batch = [16, 16, 16, 8, 4, 4] # 10 个 epoch == 每个训练阶段 50 万张图像 n_epochs = [5, 8, 8, 10, 10, 10] train(g_models, d_models, gan_models, dataset, latent_dim, n_epochs, n_epochs, n_batch) |
我们可以将所有这些结合起来。
下面列出了在名人面部数据集上训练渐进式生成对抗网络的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 |
# 名人面部数据集上的渐进式生成对抗网络示例 from math import sqrt from numpy import load from numpy import asarray from numpy import zeros from numpy import ones from numpy.random import randn from numpy.random import randint from skimage.transform import resize from keras.optimizers import Adam from keras.models import Sequential from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Flatten from keras.layers import Reshape 从 keras.layers 导入 Conv2D from keras.layers import UpSampling2D from keras.layers import AveragePooling2D from keras.layers import LeakyReLU from keras.layers import Layer from keras.layers import Add from keras.constraints import max_norm from keras.initializers import RandomNormal from keras import backend from matplotlib import pyplot # 像素级特征向量归一化层 class PixelNormalization(Layer): # 初始化层 def __init__(self, **kwargs): super(PixelNormalization, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算像素平方值 values = inputs**2.0 # 计算平均像素值 mean_values = backend.mean(values, axis=-1, keepdims=True) # 确保均值不为零 mean_values += 1.0e-8 # 计算均方值的平方根 (L2 范数) l2 = backend.sqrt(mean_values) # 通过 L2 范数归一化值 normalized = inputs / l2 return normalized # 定义层的输出形状 def compute_output_shape(self, input_shape): return input_shape # 迷你批次标准差层 class MinibatchStdev(Layer): # 初始化层 def __init__(self, **kwargs): super(MinibatchStdev, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算跨通道每个像素的平均值 mean = backend.mean(inputs, axis=0, keepdims=True) # 计算像素值与平均值之间的平方差 squ_diffs = backend.square(inputs - mean) # 计算平方差的平均值(方差) mean_sq_diff = backend.mean(squ_diffs, axis=0, keepdims=True) # 添加一个很小的值以避免在计算标准差时出现爆炸 mean_sq_diff += 1e-8 # 方差的平方根(标准差) stdev = backend.sqrt(mean_sq_diff) # 计算每个像素坐标的平均标准差 mean_pix = backend.mean(stdev, keepdims=True) # 将此放大到每个样本的一个输入特征图的大小 shape = backend.shape(inputs) output = backend.tile(mean_pix, (shape[0], shape[1], shape[2], 1)) # 与输出连接 combined = backend.concatenate([inputs, output], axis=-1) return combined # 定义层的输出形状 def compute_output_shape(self, input_shape): # 创建输入形状的副本作为列表 input_shape = list(input_shape) # 通道维度加一(假设通道在最后) input_shape[-1] += 1 # 将列表转换为元组 return tuple(input_shape) # 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # 计算 Wasserstein 损失 def wasserstein_loss(y_true, y_pred): return backend.mean(y_true * y_pred) # 添加判别器块 def add_discriminator_block(old_model, n_input_layers=3): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) # 获取现有模型的形状 in_shape = list(old_model.input.shape) # 定义新输入形状为现有尺寸的两倍 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value) in_image = Input(shape=input_shape) # 定义新的输入处理层 d = Conv2D(128, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(in_image) d = LeakyReLU(alpha=0.2)(d) # 定义新块 d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) d = AveragePooling2D()(d) block_new = d # 跳过旧模型的输入、1x1 和激活层 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model1 = Model(in_image, d) # 编译模型 model1.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 对新的大图像进行下采样 downsample = AveragePooling2D()(in_image) # 将旧输入处理连接到下采样的新输入 block_old = old_model.layers[1](downsample) block_old = old_model.layers[2](block_old) # 将旧模型输入层的输出与新输入进行淡入融合 d = WeightedSum()([block_old, block_new]) # 跳过旧模型的输入、1x1 和激活层 for i in range(n_input_layers, len(old_model.layers)): d = old_model.layers[i](d) # 定义直通模型 model2 = Model(in_image, d) # 编译模型 model2.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) return [model1, model2] # 定义每个图像分辨率的判别器模型 def define_discriminator(n_blocks, input_shape=(4,4,3)): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) model_list = list() # 基本模型输入 in_image = Input(shape=input_shape) # 卷积 1x1 d = Conv2D(128, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(in_image) d = LeakyReLU(alpha=0.2)(d) # 卷积 3x3(输出块) d = MinibatchStdev()(d) d = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) # 卷积 4x4 d = Conv2D(128, (4,4), padding='same', kernel_initializer=init, kernel_constraint=const)(d) d = LeakyReLU(alpha=0.2)(d) # 全连接输出层 d = Flatten()(d) out_class = Dense(1)(d) # 定义模型 model = Model(in_image, out_class) # 编译模型 model.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取之前没有淡入的模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_discriminator_block(old_model) # 存储模型 model_list .append(models) return model_list # 添加生成器块 def add_generator_block(old_model): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) # 获取上一个块的末端 block_end = old_model.layers[-2].output # 上采样,并定义新块 upsampling = UpSampling2D()(block_end) g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(upsampling) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 添加新的输出层 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(g) # 定义模型 model1 = Model(old_model.input, out_image) # 从旧模型获取输出层 out_old = old_model.layers[-1] # 将上采样连接到旧输出层 out_image2 = out_old(upsampling) # 将新输出图像定义为旧模型和新模型的加权和 merged = WeightedSum()([out_image2, out_image]) # 定义模型 model2 = Model(old_model.input, merged) return [model1, model2] # 定义生成器模型 def define_generator(latent_dim, n_blocks, in_dim=4): # 权重初始化 init = RandomNormal(stddev=0.02) # 权重约束 const = max_norm(1.0) model_list = list() # 基本模型潜在输入 in_latent = Input(shape=(latent_dim,)) # 线性缩放至激活图 g = Dense(128 * in_dim * in_dim, kernel_initializer=init, kernel_constraint=const)(in_latent) g = Reshape((in_dim, in_dim, 128))(g) # 卷积 4x4,输入块 g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 3x3 g = Conv2D(128, (3,3), padding='same', kernel_initializer=init, kernel_constraint=const)(g) g = PixelNormalization()(g) g = LeakyReLU(alpha=0.2)(g) # 卷积 1x1,输出块 out_image = Conv2D(3, (1,1), padding='same', kernel_initializer=init, kernel_constraint=const)(g) # 定义模型 model = Model(in_latent, out_image) # 存储模型 model_list.append([model, model]) # 创建子模型 for i in range(1, n_blocks): # 获取之前没有淡入的模型 old_model = model_list[i - 1][0] # 为下一个分辨率创建新模型 models = add_generator_block(old_model) # 存储模型 model_list .append(models) return model_list # 定义用于通过判别器训练生成器的复合模型 def define_composite(discriminators, generators): model_list = list() # 创建复合模型 for i in range(len(discriminators)): g_models, d_models = generators[i], discriminators[i] # 直通模型 d_models[0].trainable = False model1 = Sequential() model1.add(g_models[0]) model1.add(d_models[0]) model1.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 渐入模型 d_models[1].trainable = False model2 = Sequential() model2.add(g_models[1]) model2.add(d_models[1]) model2.compile(loss=wasserstein_loss, optimizer=Adam(lr=0.001, beta_1=0, beta_2=0.99, epsilon=10e-8)) # 存储 model_list.append([model1, model2]) return model_list # 加载数据集 def load_real_samples(filename): # 加载数据集 data = load(filename) # 提取 numpy 数组 X = data['arr_0'] # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 return X # 选择真实样本 def generate_real_samples(dataset, n_samples): # 选择随机实例 ix = randint(0, dataset.shape[0], n_samples) # 选择图像 X = dataset[ix] # 生成类别标签 y = ones((n_samples, 1)) 返回 X, y # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 x_input = x_input.reshape(n_samples, latent_dim) return x_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 x_input = generate_latent_points(latent_dim, n_samples) # 预测输出 X = generator.predict(x_input) # 创建类别标签 y = -ones((n_samples, 1)) 返回 X, y # 更新 WeightedSum 的每个实例上的 alpha 值 def update_fadein(models, step, n_steps): # 计算当前 alpha(从 0 到 1 线性) alpha = step / float(n_steps - 1) # 更新每个模型的 alpha 值 for model in models: for layer in model.layers: if isinstance(layer, WeightedSum): backend.set_value(layer.alpha, alpha) # 训练生成器和判别器 def train_epochs(g_model, d_model, gan_model, dataset, n_epochs, n_batch, fadein=False): # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset.shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) # 手动枚举 epoch for i in range(n_steps): # 在渐入新块时更新所有 WeightedSum 层的 alpha 值 if fadein: update_fadein([g_model, d_model, gan_model], i, n_steps) # 准备真实和虚假样本 X_real, y_real = generate_real_samples(dataset, half_batch) X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) # 更新判别器模型 d_loss1 = d_model.train_on_batch(X_real, y_real) d_loss2 = d_model.train_on_batch(X_fake, y_fake) # 通过判别器的误差更新生成器 z_input = generate_latent_points(latent_dim, n_batch) y_real2 = ones((n_batch, 1)) g_loss = gan_model.train_on_batch(z_input, y_real2) # 总结此批次的损失 print('>%d, d1=%.3f, d2=%.3f g=%.3f' % (i+1, d_loss1, d_loss2, g_loss)) # 将图像缩放到首选大小 def scale_dataset(images, new_shape): images_list = list() for image in images: # 使用最近邻插值进行大小调整 new_image = resize(image, new_shape, 0) # 存储 images_list.append(new_image) return asarray(images_list) # 生成样本并保存为图,并保存模型 def summarize_performance(status, g_model, latent_dim, n_samples=25): # 设计名称 gen_shape = g_model.output_shape name = '%03dx%03d-%s' % (gen_shape[1], gen_shape[2], status) # 生成图像 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将像素值归一化到 [0,1] 范围 X = (X - X.min()) / (X.max() - X.min()) # 绘制真实图像 square = int(sqrt(n_samples)) for i in range(n_samples): pyplot.subplot(square, square, 1 + i) pyplot.axis('off') pyplot.imshow(X[i]) # 保存图到文件 filename1 = 'plot_%s.png' % (name) pyplot.savefig(filename1) pyplot.close() # 保存生成器模型 filename2 = 'model_%s.h5' % (name) g_model.save(filename2) print('>Saved: %s and %s' % (filename1, filename2)) # 训练生成器和判别器 def train(g_models, d_models, gan_models, dataset, latent_dim, e_norm, e_fadein, n_batch): # 拟合基线模型 g_normal, d_normal, gan_normal = g_models[0][0], d_models[0][0], gan_models[0][0] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm[0], n_batch[0]) summarize_performance('tuned', g_normal, latent_dim) # 处理每个增长级别 for i in range(1, len(g_models)): # 检索此增长级别的模型 [g_normal, g_fadein] = g_models[i] [d_normal, d_fadein] = d_models[i] [gan_normal, gan_fadein] = gan_models[i] # 将数据集缩放到适当的大小 gen_shape = g_normal.output_shape scaled_data = scale_dataset(dataset, gen_shape[1:]) print('Scaled Data', scaled_data.shape) # 训练渐入模型以进行下一级别的增长 train_epochs(g_fadein, d_fadein, gan_fadein, scaled_data, e_fadein[i], n_batch[i], True) summarize_performance('faded', g_fadein, latent_dim) # 训练正常或直通模型 train_epochs(g_normal, d_normal, gan_normal, scaled_data, e_norm[i], n_batch[i]) summarize_performance('tuned', g_normal, latent_dim) # 增长阶段的数量,例如 6 == [4, 8, 16, 32, 64, 128] n_blocks = 6 # 潜在空间的大小 latent_dim = 100 # 定义模型 d_models = define_discriminator(n_blocks) # 定义模型 g_models = define_generator(latent_dim, n_blocks) # 定义复合模型 gan_models = define_composite(d_models, g_models) # 加载图像数据 dataset = load_real_samples('img_align_celeba_128.npz') print('Loaded', dataset.shape) # 训练模型 n_batch = [16, 16, 16, 8, 4, 4] # 10 个 epoch == 每个训练阶段 50 万张图像 n_epochs = [5, 8, 8, 10, 10, 10] train(g_models, d_models, gan_models, dataset, latent_dim, n_epochs, n_epochs, n_batch) |
注意:该示例可以在 CPU 上运行,但建议使用 GPU。
在现代 GPU 硬件上运行此示例可能需要数小时才能完成。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行该示例几次并比较平均结果。
如果在训练迭代期间损失值变为零或非常大/小的数字,这可能是失效模式的一个例子,可能需要重新启动训练过程。
运行示例首先报告成功加载准备好的数据集并将数据集缩放到第一个图像大小,然后报告训练过程中每个步骤中每个模型的损失。
|
1 2 3 4 5 6 7 8 |
已加载 (50000, 128, 128, 3) 缩放数据 (50000, 4, 4, 3) >1, d1=0.993, d2=0.001 g=0.951 >2, d1=0.861, d2=0.118 g=0.982 >3, d1=0.829, d2=0.126 g=0.875 >4, d1=0.774, d2=0.202 g=0.912 >5, d1=0.687, d2=0.035 g=0.911 ... |
在每个渐入训练阶段之后,生成的图像图和生成器模型都会被保存,文件名如下:
- plot_008x008-faded.png
- model_008x008-faded.h5
在每个微调阶段之后,图和模型也会被保存,文件名如下:
- plot_008x008-tuned.png
- model_008x008-tuned.h5
审查每个点的生成图像图有助于了解支持图像大小及其在微调阶段之前和之后的质量进展。
例如,下面是第一个 4×4 训练阶段(plot_004x004-tuned.png)后生成的图像样本。此时,我们几乎什么都看不到。

渐进式生成对抗网络生成的 4×4 分辨率合成名人面部
在 8×8 图像的渐入训练阶段之后审查生成的图像显示出更多结构(plot_008x008-faded.png)。图像是块状的,但我们可以看到面部。

渐进式生成对抗网络生成的 8×8 分辨率合成名人面部(渐入后)
接下来,我们可以对比 16×16 图像在渐入训练阶段(plot_016x016-faded.png)之后和微调训练阶段(plot_016x016-tuned.png)之后生成的图像。
我们可以看到图像清晰可见为面部,并且微调阶段似乎改善了面部的着色或色调,或许还有结构。

渐进式生成对抗网络生成的 16×16 分辨率合成名人面部(渐入后)

渐进式生成对抗网络生成的 16×16 分辨率合成名人面部(微调后)
最后,我们可以回顾剩余的 32×32、64×64 和 128×128 分辨率经过调整后生成的面部。我们可以看到,随着分辨率的每一步提高,图像质量都得到了改善,模型能够填充更多的结构和细节。
尽管并不完美,但生成的图像表明,渐进式生成对抗网络不仅能够生成不同分辨率的逼真人脸,而且能够利用在较低分辨率下学到的知识进行扩展,以生成较高分辨率的逼真人脸。

渐进式生成对抗网络生成的 32×32 分辨率合成名人面部(微调后)

渐进式生成对抗网络生成的 64×64 分辨率合成名人面部(微调后)

渐进式生成对抗网络生成的 128×128 分辨率合成名人面部(微调后)
现在我们已经了解了如何拟合生成器模型,接下来我们可以看看如何加载和使用已保存的生成器模型。
如何使用渐进增长 GAN 模型合成图像
在本节中,我们将探讨如何加载生成器模型并使用它按需生成合成图像。
保存的 Keras 模型 可以通过 load_model() 函数加载。
由于生成器模型使用自定义层,我们必须指定如何加载自定义层。这通过向 load_model() 函数提供一个字典来实现,该字典将每个自定义层名称映射到相应的类。
|
1 2 3 4 |
... # 加载模型 cust = {'PixelNormalization': PixelNormalization, 'MinibatchStdev': MinibatchStdev, 'WeightedSum': WeightedSum} model = load_model('model_016x016-tuned.h5', cust) |
然后,我们可以使用上一节中的 generate_latent_points() 函数生成潜在空间中的点作为生成器模型的输入。
|
1 2 3 4 5 6 7 8 9 |
... # 潜在空间的大小 latent_dim = 100 # 要生成的图像数量 n_images = 25 # 生成图像 latent_points = generate_latent_points(latent_dim, n_images) # 生成图像 X = model.predict(latent_points) |
然后,我们可以通过首先将像素值缩放到 [0,1] 范围来绘制结果,然后绘制每个图像,在这种情况下以方形网格模式绘制。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 创建生成图像的图 def plot_generated(images, n_images): # 绘制图像 square = int(sqrt(n_images)) # 将像素值归一化到 [0,1] 范围 images = (images - images.min()) / (images.max() - images.min()) for i in range(n_images): # 定义子图 pyplot.subplot(square, square, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(images[i]) pyplot.show() |
综合以上,下面列出了加载已保存的渐进式生成对抗网络生成器模型并使用它生成新面部的完整示例。
在这种情况下,我们演示了加载用于生成 16×16 面部的微调模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
# 加载生成器模型并生成图像的示例 from math import sqrt from numpy import asarray from numpy.random import randn from numpy.random import randint from keras.layers import Layer from keras.layers import Add from keras import backend from keras.models import load_model from matplotlib import pyplot # 像素级特征向量归一化层 class PixelNormalization(Layer): # 初始化层 def __init__(self, **kwargs): super(PixelNormalization, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算像素平方值 values = inputs**2.0 # 计算平均像素值 mean_values = backend.mean(values, axis=-1, keepdims=True) # 确保均值不为零 mean_values += 1.0e-8 # 计算均方值的平方根 (L2 范数) l2 = backend.sqrt(mean_values) # 通过 L2 范数归一化值 normalized = inputs / l2 return normalized # 定义层的输出形状 def compute_output_shape(self, input_shape): return input_shape # 迷你批次标准差层 class MinibatchStdev(Layer): # 初始化层 def __init__(self, **kwargs): super(MinibatchStdev, self).__init__(**kwargs) # 执行操作 def call(self, inputs): # 计算跨通道每个像素的平均值 mean = backend.mean(inputs, axis=0, keepdims=True) # 计算像素值与平均值之间的平方差 squ_diffs = backend.square(inputs - mean) # 计算平方差的平均值(方差) mean_sq_diff = backend.mean(squ_diffs, axis=0, keepdims=True) # 添加一个很小的值以避免在计算标准差时出现爆炸 mean_sq_diff += 1e-8 # 方差的平方根(标准差) stdev = backend.sqrt(mean_sq_diff) # 计算每个像素坐标的平均标准差 mean_pix = backend.mean(stdev, keepdims=True) # 将此放大到每个样本的一个输入特征图的大小 shape = backend.shape(inputs) output = backend.tile(mean_pix, (shape[0], shape[1], shape[2], 1)) # 与输出连接 combined = backend.concatenate([inputs, output], axis=-1) return combined # 定义层的输出形状 def compute_output_shape(self, input_shape): # 创建输入形状的副本作为列表 input_shape = list(input_shape) # 通道维度加一(假设通道在最后) input_shape[-1] += 1 # 将列表转换为元组 return tuple(input_shape) # 加权和输出 class WeightedSum(Add): # 使用默认值初始化 def __init__(self, alpha=0.0, **kwargs): super(WeightedSum, self).__init__(**kwargs) self.alpha = backend.variable(alpha, name='ws_alpha') # 输出输入的加权和 def _merge_function(self, inputs): # 只支持两个输入的加权和 assert (len(inputs) == 2) # ((1-a) * input1) + (a * input2) output = ((1.0 - self.alpha) * inputs[0]) + (self.alpha * inputs[1]) return output # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 x_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 z_input = x_input.reshape(n_samples, latent_dim) return z_input # 创建生成图像的图 def plot_generated(images, n_images): # 绘制图像 square = int(sqrt(n_images)) # 将像素值归一化到 [0,1] 范围 images = (images - images.min()) / (images.max() - images.min()) for i in range(n_images): # 定义子图 pyplot.subplot(square, square, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(images[i]) pyplot.show() # 加载模型 cust = {'PixelNormalization': PixelNormalization, 'MinibatchStdev': MinibatchStdev, 'WeightedSum': WeightedSum} model = load_model('model_016x016-tuned.h5', cust) # 潜在空间的大小 latent_dim = 100 # 要生成的图像数量 n_images = 25 # 生成图像 latent_points = generate_latent_points(latent_dim, n_images) # 生成图像 X = model.predict(latent_points) # 绘制结果 plot_generated(X, n_images) |
运行示例将加载模型并生成 25 张面部,这些面部以 5×5 网格模式绘制。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。请考虑运行该示例几次并比较平均结果。

最终渐进式生成对抗网络模型生成的 25 张 16×16 分辨率合成面部图
然后,我们可以将文件名更改为不同的模型,例如用于生成 128×128 面部的微调模型。
|
1 2 |
... model = load_model('model_128x128-tuned.h5', cust) |
重新运行示例会生成更高分辨率的合成面部图。

最终渐进式生成对抗网络模型生成的 25 张 128×128 分辨率合成面部图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 通过回调更改 Alpha。更新示例,使用 Keras 回调在渐入训练期间更新 WeightedSum 层的 alpha 值。
- 预缩放数据集。更新示例,预缩放每个数据集并将每个版本保存到文件,以便在训练期间需要时加载。
- 均衡学习率。更新示例以实现论文中描述的均衡学习率权重缩放方法。
- 滤波器数量的进展。更新示例以减少生成器深度处的滤波器数量,并增加判别器深度处的滤波器数量,以匹配论文中的配置。
- 更大的图像尺寸。更新示例以生成更大的图像尺寸,例如 512×512。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
官方
- GAN 的渐进式增长以提高质量、稳定性和变异性, 2017.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,官方.
- progressive_growing_of_gans 项目(官方),GitHub.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性。开放评论.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,YouTube.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,主题演讲,YouTube.
API
- Keras 数据集 API.
- Keras 序列模型 API
- Keras卷积层API
- 我如何“冻结”Keras层?
- Keras Contrib 项目
- skimage.transform.resize API
文章
- Keras-progressive_growing_of_gans 项目,GitHub.
- Hands-On-Generative-Adversarial-Networks-with-Keras 项目,GitHub.
总结
在本教程中,您学习了如何实现和训练渐进式生成对抗网络以生成名人面部。
具体来说,你学到了:
- 如何准备名人面孔数据集以训练渐进增长 GAN 模型。
- 如何定义和训练渐进增长 GAN 以生成名人面孔数据集。
- 如何加载已保存的生成器模型并使用它们生成即时合成名人面孔。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...


 From Scratch with Keras")



很高兴看到我们的 Keras pggan 实现被引用 : ) 。
谢谢。
请至少为您的一个示例提供将数据保存到特定类别文件夹(此处为 faces 文件夹)的代码片段。这有助于我们为自定义数据集生成合成数据。提前致谢。
如果您需要保存图像方面的帮助,这或许会有所帮助:
https://machinelearning.org.cn/how-to-load-convert-and-save-images-with-the-keras-api/
我们可以让 SRGAN (https://arxiv.org/abs/1609.04802) 渐进式增长吗?
好问题,我不太确定。也许可以尝试一下?
你好,我遇到了一个问题
当我运行
”’
# 包含所有图像的目录
directory = ‘img_align_celeba/’
# 加载并提取所有面孔
all_faces = load_faces(directory, 50000)
”’
它显示
‘AttributeError: module ‘tensorflow’ has no attribute ‘ConfigProto’ ‘
我正在使用 Tensorflow 2.0.0
谢谢。
抱歉,我以前没有见过这个错误,而且我不认为它与本教程相关。
我在这里有一些建议可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
TF 2.0 移除了 tf.ConfigProto()。请使用 TensorFlow 1.14 作为后端,这样就能运行了。
显然,您可以使用 tf.compat.v1.ConfigProto(),但我建议不要这样做,因为您会遇到更多错误。只需创建一个 1.14 版本的虚拟环境即可!
嗨,Jason,
感谢这个精彩的教程!它真的很有帮助,因为我从您的 GAN 书中获得了大部分理论,而这些代码是一个甜蜜的奖励。
这里提到的模型能够生成高达 64×64 的高质量人脸,但在 128×128 训练时会陷入模式崩溃,因为生成的面部看起来非常相似。这不是一个大问题,我相信这可以通过一些实验来解决。
我注意到判别器和生成器的损失在初始 epoch 中保持在 1 到 -1 的范围内,但之后会急剧增加到巨大的数字,但模型仍然能够生成一些自然的人脸
训练日志中的几行
>9273, d1=-7246121533440.000, d2=8692378370048.000 g=-1543880310784.000
>9274, d1=-10451597393920.000, d2=2355663208448.000 g=1763277799424.000
我尝试增加潜在维度并降低学习率,但行为保持不变。有没有人知道这可能是什么原因造成的?
嗯,我对这个例子不太满意。它能用,但效果不是很好。
我认为通过添加论文中描述的正则化技术可以大大改进。我实际上尝试过,效果很好,但对于本教程来说太复杂了。
嗨,Jason,
两个问题
1. 您说:“我认为通过添加论文中描述的正则化技术可以大大改进。我实际上尝试过,效果很好,但对于本教程来说太复杂了。”
您能否列出您在教程中尚未应用的那些技术?我看到了“MinibatchStdev”和“PixelNormalization”。还缺少哪些技术?
2. 原始论文似乎建议使用 He 的“kernel_initializer”,但您使用的是 RandomNormal(stddev=0.02)。请解释一下您的选择?
我和 Manjeet 有同样的问题
>67000, d1=9151679823872.000, d2=14003751354368.000 g=-61246267195392.000
>67500, d1=-84513548952141824.00, d2=59292667766374400.00 g=-25230321523884032。
>68000, d1=-511915038081024.000, d2=908596707590144.000 g=31027279953920.000
>68500, d1=nan, d2=nan g=nan
>69000, d1=nan, d2=nan g=nan
…
我仍然喜欢这个例子,因为它能将我们带到下一个层次。完成这些教程后,总会有所收获。Jason从不让我们空手而归。它可能是一个数字分类器,可能是一个识别猫狗的工具,或者其他一些有趣的东西。学生们总能在努力之后收到一份礼物,这非常激励人心。在困难的时候,这有助于坚持下去。然而,我一直在想,如果坚持不懈地努力工作,我们是否能够超越玩具的范畴。现在我们已经做到了,这是真实存在的,我们可以触及挑战并获得成年人的奖励。让我们面对现实吧,我们需要一次性加载5万张大小为128×128的彩色图像。我们可以看到sys.getsizeof(np.ones((50000,128,128,3))) = 19.6 GB。这不适用于配置较差的机器(我立即就停止了我的机器)。我们可以加载较小的批次,但这会影响性能,GANs需要一定的效率;这就是商业,如果我们想与专业人士一起玩。因此,所有辅助设施都需要解决,如AWS、CGC等。然后,在环境准备就绪之后,我们需要将所有GAN概念整合在一起并使其工作。按照这个例子,所有的部分都吻合,我们最终确实创建了人脸。它有点粗糙,耗尽了我的试用版谷歌账户,但最终确实生成了人脸;从潜在点生成的人脸。这不是简单地从眼睛、嘴巴和鼻子的仓库中剪切粘贴、组合在一起,而是从头开始创建所有这些元素,并验证它们单独和作为一个整体都符合我们对人脸的设想。这难道不是魔法吗?这些例子要求很高,但它们向我们证明了通过这些教程我们能走多远。谢谢你,Jason!
精彩的评论。
是的,这是令人印象深刻的技术,但这些例子开始触及业余爱好的极限,需要昂贵的、大型的机器才能运行。
我花了几周时间研究这个例子,花费了几千美元的EC2时间,但我的结果仍未达到论文中的水平。这很辛苦。
你花了数千美元,而不是直接购买一个比这便宜,并且可以免费给你无限时间的GPU?为什么??
很好的问题。
我更喜欢及时租用GPU,而不是(1)拥有、(2)操作和(3)维护一个额外的盒子。对我来说,这种权衡是显而易见的。
我不认为这说得通。
完全不是。这取决于你更看重金钱还是时间。
如果例子这么大,你需要免费的GPU,那么Google Colab是最好的选择。
谢谢你的建议。我从未使用过colab,对此一无所知。
它只是一个简单的笔记本,具有GPU和TPU(明确选择其中之一)的计算能力,而且是免费的。
你好 Jason,
很棒的教程,谢谢。
您刚才写道,您尝试实现论文中描述的正则化技术,但对于本教程来说太困难了。由于我是GAN编程的完全新手,如果您能分享代码,我将非常高兴。
我还想知道,第410行是否不应该是
summarize_performance(‘faded’, g_fadein, latent_dim)
而不是
summarize_performance(‘faded’, g_normal, latent_dim)。
非常感谢,祝好
是的,我想你是对的。已修复。
我将来可能会分享它。现在,也许可以查看帖子末尾相关项目的一些链接,以获取不同的实现?
嗨,Jason,
很棒的教程,我确实学到了很多。
我的表现非常差——可能是因为GPU限制,我只使用了5K样本。总的来说表现不佳,但我学到了很多!——谢谢!!!!
我想问你是否可以就一些人脸生成任务做一个BigGAN的教程?
另外,我还有一个问题是,你是否可以深入探讨数据准备的话题,我的意思是展示如何从Keras导入的库中准备数据或者只是下载数据?
最后,我想问你是否可以做一个教程,使用一个预训练的网络(如VGG16),只使用它的conv_base,然后用你自己的数据集(例如猫狗)进行训练?我似乎无法训练我的网络——可能是因为我不知道如何正确准备数据。
总而言之,
感谢您所做的一切,您帮了我很多。
祝好
谢谢!
是的,这不是一个高效的实现。
好建议,谢谢!
是的,我有很多关于加载和缩放图像数据的教程。从这里开始
https://machinelearning.org.cn/how-to-manually-scale-image-pixel-data-for-deep-learning/
是的,我也有很多关于迁移学习的教程。从这里开始
https://machinelearning.org.cn/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/
非常感谢!!
我非常感谢您的帮助,真诚地感激。
祝好
不客气。
感谢这篇精彩的帖子。我正在尝试修改代码以适用于灰度图像,即(N, N, 1)而不是(N, N, 3)。我认为我应该在define_discriminator中将input_shape=(4,4,3)更改为(4,4,1)。我还认为我可能应该在add_discriminator_block中将n_input_layers=3更改为1。我还需要进行其他更改吗?谢谢。
这看起来是个不错的开始。
告诉我进展如何!
n_input_layers应该保持设置为3。
我有一个疑问,在这个教程中我找不到你用于将训练好的较小模型的权重复制到较大模型的代码。
我们不复制权重,我们只是在现有层/模型中添加更多层。
嗨Jason,非常感谢你精彩的教程。
如果你不从训练好的较小模型复制权重到较大模型,那么就不需要训练较小模型。直接训练最终最大的模型可以得到相同的结果。我说得对吗?
不行。
我们的想法是保留较小模型的权重,这样可以更容易地学习较大的模型。
嗨,Jason,
感谢这篇精彩的教程。我对我的GAN结果不满意,一位同事建议我尝试PGAN。(人们的半身侧面照,它无法学习人脸)
你的结果非常好,我看到了你关于为此在EC2上花费了很多钱的评论。你是否使用了[5, 8, 8, 10, 10, 10]作为你的epoch,或者更多,如果是,那是什么?
另外,批次大小是否对不同阶段影响太大?我的980Ti可以处理8000张图像的批次大小64,所以我一直在GAN上使用它。我应该在PGAN的每个阶段都使用它,还是有一个关于在整个过程中缩放批次大小的经验法则?
祝好,
乔丹
我使用的epoch次数已在教程中列出。
或许可以尝试一下,看看效果如何,然后根据需要进行调整。
嗨,Jason,
首先,非常感谢这个精彩的教程。您制作的每个教程都将我们带到学习过程的下一个阶段。
不过我有一个问题,为什么学习率保持如此之小?256或512的批次大小可以轻松适应VRAM,为什么我们不这样做(假设我们也会提高学习率,乘以k或sqrt(k),假设new_batch_size/old_batch_size = k)?
提前感谢
弗洛里安
或许可以试试?
我试过了,效果不错,但我想知道为什么论文里没有这么做?
我不知道。
嗨,Jason,
我正在尝试按照你的例子实现一个渐进式增长的GAN。你能告诉我为什么在增长网络时,我们取倒数第二层而不是最后一层吗?即索引为old_model.layers[-2].output的那一层。这对我将非常有帮助。此外,我们是否应该说我们对该层进行上采样以使其匹配新增长输出模型的大小?这样我们就可以对两个输出进行加权和。
非常感谢!
因为我们丢弃了最后一个,把它移除了。我相信这在教程中有所描述。
我将查看教程以确保理解;无论如何,我们为什么不直接从最后一个开始以保持网络增长呢?
我们就是这样做的,我们只是移除最后一个输出层,因为它不合适。或许重新阅读一下教程?
附言:我关心的是更好地理解add_generator_block函数以及它为何以那种方式工作。
关于它是如何开发的,请参见此文:
https://machinelearning.org.cn/how-to-implement-progressive-growing-gan-models-in-keras/
亲爱的 Jason,
模型出现负损失正常吗?为什么?
是的,Wasserstein损失可以是负的。
亲爱的 Jason,
谢谢您的回复;但是,我得到的损失非常惊人地大!像-487258742855746.00或等值的正数,这正常吗?
今天我将调试并尝试找出原因,但在此期间我也从损失计算中得到了“nan”。
再次感谢。
哎哟。不是。
也许现在改用最小二乘损失?
Jason,
感谢您精彩的教程!
当我运行这个渐进式GAN教程时,我也遇到了同样的问题——在前几个epoch之后出现了巨大的数字,有正有负。
我们是否需要重新运行并更改整个模型中所有loss = wasserstein_loss的地方?
或许可以试试看。
我会尝试的!多谢!
嗨,Jason,
如果我某时需要停止训练,然后想重新开始,我该如何解决这个问题?
所以我保存的模型是
model_004x004-tuned.h5
model_008x008-faded.h5
…
等等,需要将它们整理到d_models和g_models列表中,这样我就可以调用:gan_models = define_composite(d_models, g_models)
我使用keras方法load_model导入我的模型。
我不知道如何将它们放入d_models和g_models列表中。
你能帮我解决这个问题吗?谢谢!
将模型保存到文件,从文件加载模型,再次使用加载的模型调用训练方案。
您可能需要修改函数以接受加载的模型。
嗨@Jason,请您给我们展示一个使用加载模型的例子吗?谢谢!
我在“如何使用渐进式增长GAN模型合成图像”一节中做到了。
你好!
感谢这个精彩的教程。我想知道您能否解释一下如何计算这两个数据集(真实数据集和合成数据集)中10000张随机图像的FID分数。此外,是否有可能在这个训练好的模型之上使用条件生成。如果可以,那么我如何探索潜在空间并创建条件图像。
我建议从这里开始
https://machinelearning.org.cn/how-to-implement-the-frechet-inception-distance-fid-from-scratch/
先生,我对我们这里采用的损失函数感到困惑。这样做有什么特殊原因吗?为什么我们没有采用均方误差?
是的,您可以在这里了解更多关于GAN对抗性损失的信息
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
我实现了最小二乘作为损失函数并训练了指定epoch的模型,但它仍然无法预测预期的图像。而且损失增加到非常高的值,高达1e+7。那么还有其他方法可以使其更好吗?
提前感谢…。
听到这个消息我很难过。
或许可以尝试多次运行示例,看看是否能得到不同的结果。
或许可以尝试本教程“扩展”部分中提到但尚未实现的一些功能。
嗨
感谢这个精彩的教程。我们能否使用渐进式增长GAN生成1024*1024或2048*2048的图像?如果不能,那么哪种GAN更适合生成1024*1024或2048*2048的高质量图像?
谢谢
也许吧。尝试一下看看,或者查阅文献了解该技术已经发展到什么程度。
嗨
很棒的文章,谢谢!
我正在尝试实现它并添加均衡学习率。如果我理解正确,这应该很容易:我正在计算值,并在每次调用Conv2D层时将它的权重乘以这个缩放因子
class EqualizedConv2D(Conv2D)
def __init__(self, filters, kernel, *args, **kwargs)
self.filters = filters
self.kernel = kernel
self.scale = None
super(EqualizedConv2D, self).__init__(filters, kernel, *args, **kwargs)
def build(self, input_shape)
fan_in = self.kernel[0] * self.kernel[1] * self.filters * input_shape[-1]
self.scale = np.sqrt(2/fan_in)
print(self.scale)
return super(EqualizedConv2D, self).build(input_shape)
def call(self, inputs)
if self.scale is not None
weights = self.get_weights()
weights = np.multiply(weights, self.scale)
self.set_weights(weights)
return super(EqualizedConv2D, self).call(inputs)
但缩放因子非常小,10^-5,权重很快变为0。我是否遗漏/误解了什么?
干得不错。
抱歉,我无法调试您的代码示例。
嗨,Pawel,
我想知道你是否已经找到了均衡学习率的实现方法。我从你提供的代码中得到以下错误:
ValueError:形状(3, 3, 129, 128)和(3, 1, 127, 128)不兼容。
嗨,Jason,
这是一篇很棒的文章!我正在尝试通过添加条件数据(文本嵌入)来实现此模型的变体。因此,我修改了生成器以具有多个输入。但是Sequential API不允许我们使用多个输入,这使得构建复合模型变得困难。有没有其他方法可以解决这个问题?或者我应该使用Model子类API吗?
谢谢!
谢谢。
您可能需要实现一个自定义层/模型。或许可以尝试原型化几种方法。
感谢这个精彩的教程。我将代码应用于生成大型医学图像。然而,当分辨率达到32x32时,损失值变得非常大。有没有办法避免这种情况?我尝试降低学习率,但没有帮助。
好问题,你可以尝试在“扩展”部分添加一些建议。
非常感谢先生您这个探索性的教程。我已单独执行了所有部分,直到数据集准备,之后我执行了上一个最后部分中提到的合并代码,并收到以下错误。
—————————————————————————
AttributeError Traceback (最近一次调用)
in
418 latent_dim = 100
419 # 定义模型
–> 420 d_models = define_discriminator(n_blocks)
421 # 定义模型
422 g_models = define_generator(latent_dim, n_blocks)
in define_discriminator(n_blocks, input_shape)
182 old_model = model_list[i – 1][0]
183 # 为下一个分辨率创建新模型
–> 184 models = add_discriminator_block(old_model)
185 # 存储模型
186 model_list.append(models)
in add_discriminator_block(old_model, n_input_layers)
114 in_shape = list(old_model.input.shape)
115 # 将新的输入形状定义为原来的两倍
–> 116 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
117 in_image = Input(shape=input_shape)
118 # 定义新的输入处理层
AttributeError: ‘int’ object has no attribute ‘value’
我不知道如何解决这个问题。我对它的功能不太了解。你能帮我摆脱这个错误吗?
或许可以尝试复制教程末尾的完整示例,以防出现复制粘贴错误?
也许这里的某些建议会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好。这种方法可以用于合成前后图像对,作为图像到图像翻译的额外训练数据吗?
可能不行,我建议使用图像增强。
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
很棒的GAN教程。先生,我正在尝试只使用500张图像,请问我应该使用多少批次大小和epoch来处理500张图像,因为我遇到了错误
—————————————————————————
AttributeError Traceback (最近一次调用)
in
416 latent_dim = 100
417 # 定义模型
–> 418 d_models = define_discriminator(n_blocks)
419 # 定义模型
420 g_models = define_generator(latent_dim, n_blocks)
in define_discriminator(n_blocks, input_shape)
181 old_model = model_list[i – 1][0]
182 # 为下一个分辨率创建新模型
–> 183 models = add_discriminator_block(old_model)
184 # 存储模型
185 model_list.append(models)
in add_discriminator_block(old_model, n_input_layers)
113 in_shape = list(old_model.input.shape)
114 # 将新的输入形状定义为原来的两倍
–> 115 input_shape = (in_shape[-2].value*2, in_shape[-2].value*2, in_shape[-1].value)
116 in_image = Input(shape=input_shape)
117 # 定义新的输入处理层
AttributeError: ‘int’ object has no attribute ‘value’
执行时出现。请先生给我一些建议。
谢谢您
普拉尼莎
很抱歉您遇到错误,也许其中一些建议会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我也遇到了同样的错误……显然变量“value”未定义。
我不知道这个问题是否仍然相关,但也许对初学者有用。
我使用包含1000张图像的数据集,并得到了相同的错误。
我通过将代码更改为(in_shape[-2]*2, in_shape[-2]*2, in_shape[-1])修复了它。
使用 TensorFlow 后端。
/usr/local/lib/python3.6/dist-packages/keras/engine/saving.py:341: UserWarning: 在保存文件中未找到训练配置:模型*未*编译。请手动编译。
warnings.warn('在保存文件中未找到训练配置:')
此错误在使用保存的模型生成新图像时发生。
您可以安全地忽略此警告。
/usr/local/lib/python3.6/dist-packages/keras/engine/saving.py:341: UserWarning: 在保存文件中未找到训练配置:模型*未*编译。请手动编译。
warnings.warn('在保存文件中未找到训练配置:')
当我使用保存的模型生成图像时,会发生此错误
这是一个警告,不是错误,您可以忽略它。
感谢这篇精彩的教程。我想使用PGAN生成皮肤病变图像,这些图像分为两类:良性和恶性。当我使用PGAN生成更多病变图像时,我如何标记它们是良性还是恶性,以将其作为目标用于模型训练以提高模型准确性。您能否告诉我方法或您分享此类工作的教程?
也许你可以改用条件GAN或条件版PGAN——如果这种东西存在的话。
亲爱的 Jason,
非常感谢您提供的本教程。它对我的工作非常有帮助。
当我尝试以h5格式保存生成器模型时(g_model.save(filename2)),我收到一个错误:“TypeError: ('Not JSON Serializable:', )”。
另一个有趣的事情是,对于4x4模型,一切都运行顺利,当8x8褪色模型要保存时,就会弹出错误。
有没有人遇到过同样的错误?您对如何继续有什么建议吗?
(我尝试只保存模型权重,那没有问题,但我对保存模型感兴趣)
提前感谢!
不客气。
听到这个消息很遗憾。您能否确认您的库是最新的。
另外,这些提示可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我检查了库并用pip更新了它们以确保,但问题仍然存在,我会更好地查看您发送给我的链接。再次感谢。
不客气。
嗨Filippo,
我也遇到了和你一样的错误,我的错误是在8x8褪色模型之后生成的。我一直在寻找解决方案,只有注释掉model.save函数才对我有用。
如果你能解决,请告诉我。
提前感谢。
嗨,我在Weighted Sum类中找到了一个临时修复,添加以下方法应该可以工作:
def get_config(self)
config = super().get_config().copy()
config.update({'alpha':self.alpha.numpy(),})
return config
完整的类应该是这样的:
class WeightedSum(Add)
# 用默认值初始化
def __init__(self, alpha=0.0, **kwargs)
super(WeightedSum, self).__init__(**kwargs)
self.alpha = backend.variable(alpha, name='ws_alpha')
# 输出输入的加权和
def _merge_function(self, inputs)
# 只支持两个输入的加权和
assert (len(inputs) == 2)
# ((1-a) * input1) + (a * input2)
output = ((1.0 – self.alpha) * inputs[0]) + (self.alpha * inputs[1])
return output
def get_config(self)
config = super().get_config().copy()
config.update({'alpha':self.alpha.numpy(),})
return config
嘿Jason,我的笔记本电脑上有一个GTX1650 GPU,你认为我能在上面运行这段代码吗?如果可以,你认为我应该对批次大小或学习率做些什么更改?提前感谢。
或许可以试试?
感谢Jason提供的精彩教程
我尝试训练1万张图像,在64x64微调阶段,损失变为nan,生成的图像是黑色图像,请建议一些克服此问题的方法。
此外,在4x4之后保存模型不起作用,给出不是json可序列化的错误,可能是因为加权和层。
但是保存权重是可能的。
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason
很棒的文章!!!
请帮助我找到解决方案,
1. 我如何在Google Colab上使用指定数据运行此代码?
2. 我如何获得更多关于GANs的细节?
提前感谢。
在 Colab 上
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
更多关于 GANs
https://machinelearning.org.cn/start-here/#gans
嗨Jason,当我使用TPU时,我遇到了这个错误。
帮帮我。
WARNING:tensorflow:7 out of the last 7 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:7 out of the last 7 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:8 out of the last 8 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:8 out of the last 8 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:9 out of the last 9 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
WARNING:tensorflow:9 out of the last 9 calls to <function Model.make_predict_function..predict_function at 0x7fbaa1340268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://tensorflowcn.cn/tutorials/customization/performance#python_or_tensor_args and https://tensorflowcn.cn/api_docs/python/tf/function for more details.
—————————————————————————
InvalidArgumentError 回溯(最近一次调用在最后)
in ()
45 with strategy.scope()
46 directory = ‘/content/img_align_celeba/img_align_celeba/’
—> 47 all_faces = load_faces(directory, 500)
48 print(‘Loaded: ‘, all_faces.shape)
49 savez_compressed(‘img_align_celeba_128.npz’, all_faces)
9 frames
/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/context.py in sync_executors(self)
656 “””
657 if self._context_handle
–> 658 pywrap_tfe.TFE_ContextSyncExecutors(self._context_handle)
659 else
660 raise ValueError(“Context is not initialized.”)
InvalidArgumentError: 发现9个根错误。
(0) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_287]]
(1) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_283]]
(2) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_275]]
(3) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_295]]
(4) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_291]]
(5) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_279]]
(6) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_303]]
(7) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:不支持动态空间卷积:lhs形状为f32[<=2,<=54,<=66,3]
[[{{节点 functional_13/conv2d_24/Conv2D}}]]
TPU编译失败
[[tpu_compile_succeeded_assert/_1842486143609259834/_4]]
[[cluster_predict_function/control_after/_1/_299]]
(8) Invalid argument: {{function_node __inference_predict_function_22890}} 编译失败:动态空间卷积不支持:lhs形状为f32[ ... [截断]]
抱歉,我不知道您问题的起因。或许可以尝试将您的错误发布到stackoverflow上。
“鉴于需要加载大量人脸,运行此示例可能需要几分钟。”
对我来说,使用mtcnn v0.1.0(使用tensorflow后端)运行此示例需要很长时间。根据mtcnn的基准测试,我应该能获得两位数的FPS,但我甚至无法达到1 FPS。这看起来很奇怪,因为我使用的是RTX 3090 GPU。
我将使用整个图像(而不仅仅是人脸)来测试此实现。
对我来说,理解实现的每一个步骤以及你为什么这样做很重要。
你的教程对我非常有帮助,让我开始学习机器学习。非常感谢你,先生。
谢谢。
很抱歉速度慢。也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/how-do-i-speed-up-the-training-of-my-model
很棒的教程。这对我帮助很大。非常感谢!
当我阅读您关于lstm自编码器的介绍时,我很好奇是否有将这些概念结合起来的可能性:比如渐进式增长的lstm gan?
谢谢!
我相信你可以,尽管需要做一些工作才能使其稳定。
本教程中的想法可能会有所帮助:
https://machinelearning.org.cn/greedy-layer-wise-pretraining-tutorial/
谢谢这个教程!
您对train函数的调用没有e_norm、e_fadein参数,这使得我无法运行您的示例,您有什么解决方案吗?
或许可以尝试教程末尾提供的完整且可运行的代码示例。
先生,出现了“Add”未定义的错误。
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
先生,我已经安装了mtcnn..但是当我运行时,在model=MTCNN()处给我一个错误。
name MTCNN 未定义
或许检查一下你的库版本是否与MTCNN库的预期相符。
感谢这个教程,
我有一个问题,我想修改这段代码。所以,当我使用d_model.trainable_weights来计算梯度时,它返回[]值。你对这个问题有什么想法吗?
抱歉,我没有。
嗨,Jason,
两个问题
1. 您说:“我认为通过添加论文中描述的正则化技术可以大大改进。我实际上尝试过,效果很好,但对于本教程来说太复杂了。”
您能否列出您在教程中尚未应用的那些技术?我看到了“MinibatchStdev”和“PixelNormalization”。还缺少哪些技术?
2. 原始论文似乎建议使用 He 的“kernel_initializer”,但您使用的是 RandomNormal(stddev=0.02)。请解释一下您的选择?
确实,您可以查阅论文作者发布的代码:https://github.com/tkarras/progressive_growing_of_gans
关于He初始化,您可以查看https://machinelearning.org.cn/weight-initialization-for-deep-learning-neural-networks/
嗨,渐进式GAN和StyleGAN只对合成高分辨率图像有效吗?在生成MNIST等低分辨率图像的情况下,与简单GAN相比质量有差异吗?
嗨Kiki……希望以下内容对您有所帮助
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-an-mnist-handwritten-digits-from-scratch-in-keras/
您在这里使用的是哪个版本的TensorFlow?
嗨Nicholas…您指的是哪个代码列表?Keras库对特定版本的Tensorflow没有很强的依赖性。
发布的图片太糟糕了……你觉得它真的有用吗?
嗨Ladofa…请澄清您的问题,以便我更好地协助您。
很棒的教程!
有人能分享一个256X256分辨率的预训练模型吗?因为我的电脑没有足够的算力来训练它。
使用
backend.rsqrt进行快速逆平方根归一化可能会更快。rl2 = backend.rsqrt(mean_values)
# 根据rl2范数归一化值
normalized = inputs * l2
感谢Giles的反馈!
你好,实际上我认为评论具有误导性。在文献中,它有一个1/N项,你的代码正确实现了均方根(这应该被称为RMS归一化?),但评论提到了L2归一化,它没有1/N项。L2范数只是和,而不是平均值。如果你想要L2范数,你可以直接这样做:backend.l2_normalize(inputs, axis=-1)
无论如何,我提到了错误的rsqrt模块,它来自tensorflow.python.ops.math_ops,完整示例应该是
# 执行操作
def call(self, inputs)
# 计算平方像素值
values = inputs**2.0
# 计算平均像素值
mean_values = backend.mean(values, axis=-1, keepdims=True)
# 确保均值不为零
mean_values += 1.0e-8
# 计算均方值(RMS范数)的逆平方根
rms = math_ops.rsqrt(mean_values)
# 通过rms归一化值
normalized = inputs * rms
return normalized
嗨,Jason,
我无法让你的例子工作,但我认为我发现了一个bug,你将[g_model, d_model, gan_model]传递给update_fadein函数,并检查每个`model.layer`是否是`WeightedSum`的实例,然而gan_model是嵌套的,它只有两层,分别是生成器模型和判别器模型。我想你必须在层是`isinstance(Model)`时进行递归调用,或者只传递gan_model.layers[0], gan_model.layers[1]。
我通过在生成器和判别器优化器中都使用clipvalue=0.1成功修复了NaN错误问题。
然而,我不确定这是否可行,因为理论上它可能导致生成器中出现不良梯度。
嗨drime…我建议在将模型投入实践之前,确定NaN的来源。
您能分享您的预训练模型吗?
嗨Grigoris…虽然我们不提供预训练模型,但我们可以推荐以下资源
https://towardsdatascience.com/5-websites-to-download-pre-trained-machine-learning-models-6d136d58f4e7
谢谢!我还想问您一些问题。我试图在一种电子眼镜中创建一个实时人脸识别系统,但我遇到了一些问题,例如分辨率低,人脸模糊等。您认为使用GANs恢复人脸,然后将其应用于模型以获取嵌入更好,还是您可以建议一种更好的方法,无需人脸恢复(例如,在低分辨率数据集上训练FR模型)。我还观察到模型在Celeba数据集上表现良好,但在自定义数据集上则不然,那么有没有办法在人脸检测(裁剪和对齐)后转换人脸,使其看起来像Celeba数据?
嗨,Jason,
您的模型确实令人印象深刻,但我花了一整天的时间尝试实现它,并且遇到了困难。我设法修复了所有问题,除了一个。当我训练模型时,我有一个形状为(13153, 128, 128, 3)的numpy数组数据集,我将其转换为npz以匹配您的代码。我的模型在第一个尺度(13153, 4, 4, 3)上训练,在4110步后我得到了004x–4 tuned png的图。然而,对于(13153, 8, 8, 3),我在6576步后收到了一个错误,这是错误,请帮助我,我尝试了一切。如果知道如何调试,请告诉我,我渴望看到这个模型的最终结果!提前感谢,并感谢这篇帖子,它对学习PGAN非常有帮助,我很喜欢它。
>6576, d1=-36738.984, d2=43196.312 g=-29011.340
1/1 [==============================] – 0s 32ms/步
WARNING:tensorflow:已编译加载的模型,但编译的指标尚未构建。在训练或评估模型之前,`model.compile_metrics`将为空。
>已保存:plot_008x008-faded.png 和 model_008x008-faded.h5
1/1 [==============================] – 0s 129ms/步
ValueError 回溯 (最近一次调用)
in ()
6 n_epochs = [5, 8, 8, 10, 10, 10]
7
----> 8 history_pcgan = train(g_models, d_models, gan_models, dataset, latent_dim, n_epochs, n_epochs, n_batch)
ValueError:在用户代码中
文件“/usr/local/lib/python3.9/dist-packages/keras/engine/training.py”,第1249行,函数train_function *
返回step_function(self, iterator)
文件“”,第78行,函数wasserstein_loss *
返回backend.mean(y_true * y_pred)
ValueError:维度必须相等,但'{{node wasserstein_loss/mul}} = Mul[T=DT_FLOAT](IteratorGetNext:1, model_25/minibatch_stdev_3/concat)'的输入形状为:[8,1],[8,4,4,129],因此8和4不相等。
——————————————————
嗨Lana…你是复制粘贴代码还是手动输入的?我建议在命令行和Google Colab中执行代码。