您需要了解的关于训练稳定生成对抗网络(GAN)的经验法则、技巧和窍门。
生成对抗网络(简称GANs)是一种使用深度学习方法(如深度卷积神经网络)的生成建模方法。
尽管GANs生成的模型可能非常出色,但训练一个稳定的模型却可能充满挑战。这是因为训练过程本身就不稳定,导致两个竞争模型同时进行动态训练。
然而,经过大量的经验试错,以及许多从业者和研究人员的努力,已经发现并报道了一些模型架构和训练配置,这些配置能够可靠地训练出稳定的GAN模型。
在本篇文章中,您将发现关于配置和训练稳定的通用对抗网络模型的经验法则。
阅读本文后,你将了解:
- GANs中生成器和判别器模型的同步训练本质上是不稳定的。
- DCGAN提供的、经过艰苦经验发现的配置,为大多数GAN应用提供了一个强大的起点。
- GANs的稳定训练仍然是一个开放性的问题,许多其他经验发现的技巧和窍门已被提出,并且可以立即采纳。
立即开始您的项目,阅读我的新书《Python生成对抗网络》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何训练稳定的生成对抗网络
由Chris Sternal-Johnson拍摄,保留部分权利。
概述
本教程分为三个部分;它们是:
- 训练GANs的挑战
- 深度卷积生成对抗网络
- 其他技巧和窍门
训练生成对抗网络的挑战
GANs难以训练。
它们难以训练的原因在于,生成器模型和判别器模型在游戏中同时进行训练。这意味着一个模型的改进是以另一个模型的牺牲为代价的。
训练两个模型的目标是找到两个相互竞争的关注点之间的平衡点。
训练GANs包括找到一个双人非合作博弈的纳什均衡。……不幸的是,找到纳什均衡是一个非常困难的问题。对于特定情况存在算法,但我们不知道有任何适用于GAN博弈的算法,因为GAN博弈的目标函数是非凸的、参数是连续的,并且参数空间是极高维的。
——《改进GAN训练技术》,2016。
这也意味着,每次模型参数更新时,正在解决的优化问题的性质都会发生变化。
这会产生一个动态系统。
但对于GAN,每走一步,整个地形都会发生微小的变化。它是一个动态系统,优化过程不是在寻找一个最小值,而是在寻找两个力之间的平衡。
— 第306页,《Python深度学习》,2017年。
在神经网络方面,同时训练两个竞争性神经网络的技术挑战在于它们可能无法收敛。
GAN面临的最大问题,也是研究人员应该努力解决的问题,是**不收敛**的问题。
— NIPS 2016 教程:生成对抗网络, 2016。
GANs可能不会收敛,反而会遭受几种失败模式中的一种。
一种常见的失败模式是,生成器没有找到平衡点,而是在生成领域内的特定示例之间振荡。
在实践中,GANs常常会振荡……这意味着它们从生成一种样本进展到生成另一种样本,但最终未能达到平衡。
— NIPS 2016 教程:生成对抗网络, 2016。
也许最令人头疼的模型失败情况是,多个输入到生成器导致生成相同的输出。
这被称为“模式崩溃”,并且可能是训练GANs时最棘手的挑战之一。
模式崩溃,也称为这种情况,是指生成器学习将多个不同的输入z值映射到同一个输出点的问题。
— NIPS 2016 教程:生成对抗网络, 2016。
最后,没有好的客观指标来评估GAN在训练期间的表现。例如,仅查看损失是不够的。
相反,最好的方法是**视觉检查生成的示例**并使用**主观评估**。
生成对抗网络缺乏客观函数,这使得比较不同模型的性能变得困难。一个直观的性能指标是通过让人工标注者评判样本的视觉质量来获得的。
——《改进GAN训练技术》,2016。
在撰写本文时,关于如何设计和训练GAN模型没有良好的理论基础,但已经有了一个成熟的经验法则或“技巧”的文献,这些方法已被证明在实践中效果很好。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
深度卷积生成对抗网络
也许在设计和训练稳定GAN模型方面最重要的进展之一是Alec Radford等人在2015年发表的题为“使用深度卷积生成对抗网络进行无监督表示学习”的论文。
在论文中,他们描述了深度卷积GAN(DCGAN)这一GAN开发方法,它已成为事实上的标准。
GAN学习的稳定化仍然是一个开放性问题。幸运的是,当模型架构和超参数选择得当,GAN学习效果很好。Radford等人(2015)设计了一个深度卷积GAN(DCGAN),该模型在图像合成任务中表现非常出色……
— 第701页,《深度学习》,2016年。
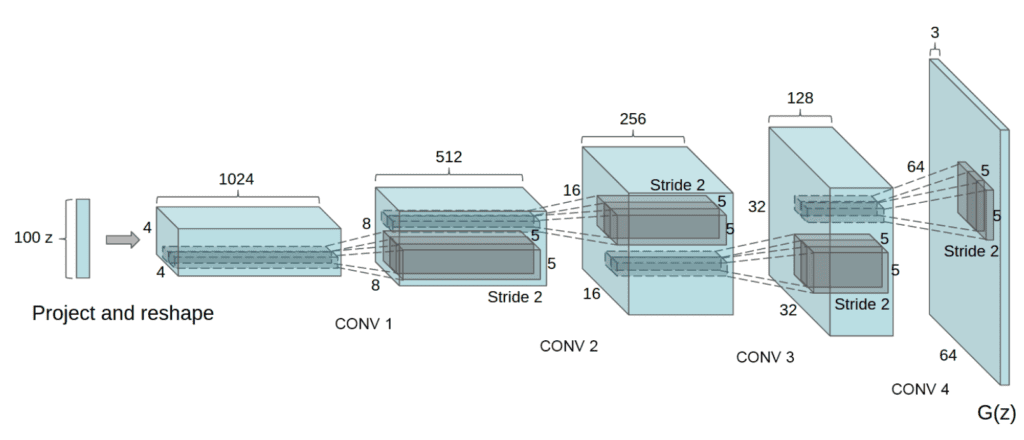
DCGAN生成器模型架构示例。
摘自2015年的《使用深度卷积生成对抗网络进行无监督表示学习》。
这篇论文中的发现来之不易,是通过对不同模型架构、配置和训练方案进行广泛的经验试错而开发的。他们的研究方法仍然强烈推荐作为开发新GANs的起点,至少对于基于图像合成的任务是如此。
……经过广泛的模型探索,我们确定了一系列架构,这些架构在各种数据集上实现了稳定的训练,并允许训练更高分辨率和更深的生成模型。
— 《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
下面总结了论文中关于GAN架构的建议。

训练稳定深度卷积生成对抗网络的架构指南总结。
摘自2015年的《使用深度卷积生成对抗网络进行无监督表示学习》。
让我们仔细看看。
1. 使用**步进卷积**
在卷积神经网络中,通常使用池化层(如最大池化层)进行下采样。
在GANs中,建议**不要使用池化层**,而是使用卷积层中的步长(stride)来在判别器模型中执行下采样。
类似地,在生成器中可以使用**分数步长(反卷积层)**进行上采样。
[替换] 确定性的空间池化函数(如最大池化)用步进卷积代替,使网络能够学习自己的空间下采样。我们在生成器和判别器中都使用了这种方法,这允许它们学习自己的空间上采样。
— 《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
2. **移除全连接层**
在卷积层之后使用全连接层来解释提取的特征,然后输出,这是一种常见的做法。
相反,在GANs中,**不使用全连接层**,判别器的卷积层会被展平并直接传递到输出层。
此外,传递给生成器模型的随机高斯输入向量被直接重塑成一个多维张量,可以传递给第一个卷积层,准备进行上采样。
GAN的第一层,它接受一个均匀噪声分布Z作为输入,可以称为全连接,因为它只是一个矩阵乘法,但结果被重塑成一个4维张量并用作卷积堆栈的起点。对于判别器,最后一层卷积被展平,然后输入到一个单一的sigmoid输出。
— 《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
3. **使用批量归一化**
批量归一化将先前层的激活进行标准化,使其具有零均值和单位方差。这可以稳定训练过程。
批量归一化已成为训练深度卷积神经网络的标准,GAN也不例外。建议在判别器和生成器模型中使用批量归一化层,但**生成器的输出层和判别器的输入层除外**。
然而,直接将批量归一化应用于所有层会导致样本振荡和模型不稳定。这可以通过不将批量归一化应用于生成器输出层和判别器输入层来避免。
——《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
4. **使用ReLU、Leaky ReLU 和 Tanh**
像ReLU这样的激活函数用于解决深度卷积神经网络中的梯度消失问题,并促进稀疏激活(例如,大量的零值)。
**ReLU推荐用于生成器**,但不推荐用于判别器模型。相反,**Leaky ReLU(允许负值通过的ReLU变体)在判别器中更受欢迎**。
生成器中使用ReLU激活,输出层除外,输出层使用Tanh函数……在判别器中,我们发现Leaky ReLU激活效果很好……
——《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
此外,生成器在输出层使用双曲正切(tanh)激活函数,生成器和判别器的输入都缩放到**[-1, 1]**的范围内。
除了将训练图像缩放到tanh激活函数的范围[-1, 1]之外,没有对训练图像进行任何预处理。
— 《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
模型权重被初始化为小的高斯随机值,并且判别器中Leaky ReLU的斜率被初始化为0.2。
所有权重都从一个零均值、标准差为0.02的正态分布中初始化。在LeakyReLU中,所有模型中的泄漏斜率都设置为0.2。
——《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
5. **使用Adam优化器**
生成器和判别器都使用随机梯度下降进行训练,批次大小适中,为128张图像。
所有模型都使用小批量随机梯度下降(SGD)进行训练,小批量大小为128。
——《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
具体来说,使用Adam版的随机梯度下降来训练模型,学习率为0.0002,动量(beta1)为0.5。
我们使用了具有调整后超参数的Adam优化器。我们发现建议的学习率0.001太高,而是使用了0.0002。此外,我们发现将动量项β1保留在建议值0.9会引起训练振荡和不稳定,而将其降低到0.5有助于稳定训练。
——《使用深度卷积生成对抗网络进行无监督表示学习》,2015年。
其他技巧和窍门
DCGAN论文为配置和训练生成器和判别器模型提供了极佳的起点。
此外,还撰写了许多综述性演示文稿和论文,以总结这些以及其他配置和训练GANs的经验法则。
在本节中,我们将介绍其中一些,并重点介绍一些需要考虑的附加技巧和窍门。
Tim Salimans等人(OpenAI)在2016年的论文“改进GANs训练技术”列出了五种据称可以提高GANs训练收敛性的技术。
它们是
- 特征匹配。使用半监督学习来开发GAN。
- 小批量判别。在小批量内的多个样本之间开发特征。
- 历史平均。更新损失函数以包含历史信息。
- 单边标签平滑。将判别器的目标值缩放到远离1.0。
- 虚拟批量归一化。使用真实图像的参考批次计算批量归一化统计。
在2016年NIPS会议上,Ian Goodfellow在关于GAN的教程中详细介绍了其中一些更成功的建议,并记录在随附的论文“教程:生成对抗网络”中。特别是,第四节“技巧与窍门”描述了四种技术。
它们是
1. 使用标签进行训练。利用GANs中的标签可以提高图像质量。
以任何方式、形式或内容使用标签,几乎总能显著提高模型生成的样本的主观质量。
— NIPS 2016 教程:生成对抗网络, 2016。
2. 单边标签平滑。在判别器中使用真实样本的目标值(0.9)或使用随机范围的目标值可以获得更好的结果。
单边标签平滑的想法是将真实样本的目标值替换为略小于1的值,例如0.9……这可以防止判别器出现极端的外插行为……
— NIPS 2016 教程:生成对抗网络, 2016。
3. 虚拟批量归一化。使用真实图像或包含一张生成图像的真实图像来计算批量统计信息效果更好。
……相反,可以使用虚拟批量归一化,其中每个样本的归一化统计是使用该样本和参考批次的并集计算的。
— NIPS 2016 教程:生成对抗网络, 2016。
4. G和D能平衡吗?根据损耗的相对变化来调整生成器或判别器的训练量直观但不可靠。
在实践中,判别器通常比生成器更深,有时每层的过滤器也更多。
— NIPS 2016 教程:生成对抗网络, 2016。
Soumith Chintala,DCGAN论文的合著者之一,在NIPS 2016会议上发表了题为“如何训练GAN?”的演讲,总结了许多技巧和窍门。
视频可在YouTube上观看,强烈推荐。还有一份GitHub存储库提供了技巧摘要,题为“如何训练GAN?让GAN工作的技巧与窍门”。
这些技巧借鉴了DCGAN论文以及其他地方的建议。
下面是一些更具操作性的技巧摘要。
- 将输入归一化到[-1, 1]范围,并在生成器输出中使用tanh。
- 在训练生成器时,翻转标签和损失函数。
- 将高斯随机数作为输入采样到生成器。
- 使用全部真实或全部伪造的小批量来计算批量归一化统计。
- 在生成器和判别器中使用Leaky ReLU。
- 使用平均池化和步长进行下采样;使用ConvTranspose2D和步长进行上采样。
- 在判别器中使用标签平滑,并加入小的随机噪声。
- 在判别器中向标签添加随机噪声。
- 使用DCGAN架构,除非有充分理由不这样做。
- 判别器损失为0.0是一种失败模式。
- 如果生成器损失持续下降,它很可能用垃圾图像欺骗了判别器。
- 如果您有标签,请使用标签。
- 向判别器的输入添加噪声,并随时间衰减噪声。
- 在训练和生成期间使用50%的dropout。
最后,Keras上的《Python深度学习》一书提供了一些在训练GANs时需要考虑的实用技巧,这些技巧主要基于DCGAN论文的建议。
一项额外的技巧建议在生成器模型中使用与步长大小可整除的核大小,以避免所谓的“棋盘格”伪影(错误)。
……我们经常会看到由生成器中像素空间覆盖不均引起的棋盘格伪影。为了解决这个问题,我们在生成器和判别器中使用步进Conv2DTranspose或Conv2D时,都使用核大小可被步长大小整除的参数。
— 第308页,《Python深度学习》,2017年。
这与2016年Distill网站上题为“反卷积和棋盘格伪影”的文章中提出的建议相同。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 第20章。深度生成模型,深度学习,2016年。
- 第8章。生成深度学习,Python深度学习,2017年。
论文
- 生成对抗网络, 2014.
- 教程:生成对抗网络,NIPS, 2016.
- 使用深度卷积生成对抗网络的无监督表征学习, 2015
- 训练 GAN 的改进技术, 2016.
文章
- 如何训练GAN?让GAN生效的技巧
- 反卷积和棋盘格伪影, 2016.
视频
总结
在本篇文章中,您发现了配置和训练稳定的通用对抗网络模型的经验法则。
具体来说,你学到了:
- GANs中生成器和判别器模型的同步训练本质上是不稳定的。
- DCGAN提供的、经过艰苦经验发现的配置,为大多数GAN应用提供了一个强大的起点。
- GANs的稳定训练仍然是一个开放性的问题,许多其他经验发现的技巧和窍门已被提出,并且可以立即采纳。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...
")
")

")

")
精彩的文章,感谢分享。
谢谢Anna!
优秀的文章。
但是,请详细阐述一下提到的以下技巧
“此外,传递给生成器模型的随机高斯输入向量被直接重塑成一个多维张量,可以传递给第一个卷积层,准备进行上采样。”
是的,一个绝佳的问题!
生成器解释输入并产生足够的激活来形成一个具有许多通道的小图像的基础,然后将其输入到第一个CNN层。
这有帮助吗?
非常感谢您的澄清。
不客气。
谢谢!这个博客对我帮助很大。在我的案例中,模型在更改学习率和/beta1后变得稳定:Adam(lr=0.0002, beta_1=0.5)
干得好!
感谢这篇完整的博文,我不确定您想表达什么,但我认为这句话“在训练生成器时翻转标签和损失函数”有错误。
谢谢!已修复。
在您的总结中,您说:“在生成器和判别器中使用Leaky ReLU。”
但在上面的ReLU部分,您说:
“ReLU推荐用于生成器,但不推荐用于判别器模型。相反,Leaky ReLU(允许负值通过的ReLU变体)在判别器中更受欢迎。”
有点不一致。
没有金科玉律,只有来自不同人的许多经验法则。
尝试几种方法,看看哪种最适合您的特定项目。
好的,谢谢🙂
有人知道Keras中实现这些技术的代码吗?
特征匹配。使用半监督学习来开发GAN。
小批量判别。在小批量内的多个样本之间开发特征。
历史平均。更新损失函数以包含历史信息。
我找不到这个。
博客上有很多半监督学习GANs,或许可以从这里开始。
https://machinelearning.org.cn/start-here/#gans
感谢Jason的精彩文章。
您是否为这个DCGAN架构发布了任何Python代码?
你好Ahmed……感谢您的反馈!我已经注意到您对DCGAN相关内容的兴趣。以下资源可能对您有帮助:
https://tensorflowcn.cn/tutorials/generative/dcgan
你好,我们如何使用小批量判别?
你好elhoucine……小批量判别是一种主要用于生成对抗网络(GANs)的技术,旨在帮助判别器检测生成器是否产生了一批非常相似的样本。这项技术有助于防止模式崩溃,即生成器学会只生成几种不同的样本。
以下是小批量判别的工作原理以及如何实现它:
### 概念
在标准的GAN中,判别器单独查看每个样本。然而,小批量判别允许判别器同时查看整个小批量样本。通过比较小批量内的样本,判别器可以学会检测生成器何时产生相似或相同的样本。
### 实现步骤
1. **添加小批量层**:在判别器网络中添加一个小批量判别层。该层计算小批量中样本对之间差异的L1或L2范数,并将这些差异通过一个学习到的矩阵进行传递。
2. **特征向量**:小批量中的每个样本都用一个特征向量进行增强,该向量捕获它与其他小批量样本的差异程度。
3. **连接**:将原始输入特征与小批量判别特征连接起来,然后传递给判别器的后续层。
### 伪代码
以下是使用 TensorFlow/Keras 在 Python 中为 GAN 判别器添加小批量判别功能的简化伪代码
pythonimport tensorflow as tf
from tensorflow.keras import layers, Model
class MinibatchDiscrimination(layers.Layer)
def __init__(self, num_kernels, kernel_dim)
super(MinibatchDiscrimination, self).__init__()
self.num_kernels = num_kernels
self.kernel_dim = kernel_dim
def build(self, input_shape)
self.T = self.add_weight(
shape=(input_shape[-1], self.num_kernels * self.kernel_dim),
initializer='glorot_uniform',
trainable=True,
)
def call(self, inputs)
M = tf.matmul(inputs, self.T)
M = tf.reshape(M, (-1, self.num_kernels, self.kernel_dim))
diffs = tf.expand_dims(M, axis=3) - tf.expand_dims(tf.transpose(M, perm=[1, 2, 0]), axis=0)
abs_diffs = tf.reduce_sum(tf.abs(diffs), axis=2)
minibatch_features = tf.reduce_sum(tf.exp(-abs_diffs), axis=2)
return tf.concat([inputs, minibatch_features], axis=1)
# 判别器模型
def build_discriminator(input_shape, num_kernels=100, kernel_dim=5)
input_layer = layers.Input(shape=input_shape)
x = layers.Dense(128)(input_layer)
x = layers.LeakyReLU(alpha=0.2)(x)
x = MinibatchDiscrimination(num_kernels, kernel_dim)(x)
x = layers.Dense(1, activation='sigmoid')(x)
return Model(input_layer, x)
# 示例用法
input_shape = (784,) # 对于 MNIST 数据集
discriminator = build_discriminator(input_shape)
discriminator.summary()
### 解释
1. **MinibatchDiscrimination 层**
– **初始化**: 定义核的数量及其维度。
– **构建**: 创建一个形状为
(input_dim, num_kernels * kernel_dim)的权重矩阵T。– **调用**: 通过将输入与
T相乘并重塑来计算矩阵M。计算差异,然后通过对负绝对差异指数求和来计算小批量特征。将这些特征与原始输入连接起来。2. **判别器**
– 构建一个简单的判别器网络,其中包含一个密集层,后跟小批量判别层,以及另一个用于最终输出的密集层。
### 用途
通过实现小批量判别,判别器对小批量中的模式更加敏感,从而能够检测生成器何时生成过于相似的输出,并鼓励生成器生成更多样化的样本集。这有助于稳定 GAN 的训练并提高生成样本的质量。