Weka是学习机器学习的理想平台。
它提供了一个图形用户界面,用于在数据集上探索和试验机器学习算法,而无需您担心数学或编程。
在上一篇文章中,我们研究了如何设计和运行一个实验,其中包含3种算法在数据集上的应用,以及如何分析和报告结果。

曼哈顿天际线,因为我们将使用曼哈顿距离与k近邻算法。
照片作者:Tim Pearce, Los Gatos,部分权利保留。
在这篇文章中,您将发现如何使用Weka Experimenter来改进您的结果并充分利用机器学习算法。如果您遵循分步说明,您将在不到五分钟的时间内设计并运行一个算法调优的机器学习实验。
开始您的项目,阅读我的新书《Weka机器学习精通》,其中包含分步教程和所有示例的清晰屏幕截图。
1. 下载并安装Weka
访问Weka下载页面,找到适合您电脑的版本(Windows、Mac或Linux)。
Weka需要Java。您可能已经安装了Java,如果还没有,下载页面上列出的Weka版本(适用于Windows)包含Java并且会为您安装。我自己使用的是Mac,就像Mac上的一切一样,Weka开箱即用。
如果您对机器学习感兴趣,那么我知道您一定能弄清楚如何下载和安装软件到自己的电脑。
2. 启动Weka
启动Weka。这可能涉及在程序启动器中找到它,或双击 weka.jar 文件。这将启动 Weka GUI 选择器。
Weka GUI 选择器
Weka GUI 选择器让您可以选择 Explorer、Experimenter、KnowledgeExplorer 和 Simple CLI(命令行界面)中的一个。
点击“Experimenter”按钮启动Weka Experimenter。
Weka Experimenter允许您设计自己的在数据集上运行算法的实验,运行实验并分析结果。它是一个强大的工具。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
3. 设计实验
点击“New”按钮创建一个新的实验配置。
测试选项
Experimenter会为您配置合理的默认测试选项。该实验配置为使用10折交叉验证。这是一个“分类”类型的问题,每个算法+数据集组合运行10次(迭代控制)。
电离层数据集
让我们先选择数据集。
- 在“Datasets”选择中,点击“Add new…”按钮。
- 打开“data”目录并选择“ionosphere.arff”数据集。
该电离层数据集是一个经典的机器学习数据集。问题是根据雷达信号预测电离层中自由电子结构的存在(或不存在)。它由16对实值雷达信号(34个属性)和一个具有两个值(good和bad雷达回波)的单一类属性组成。
您可以在UCI机器学习数据库的电离层数据集页面上阅读更多关于此问题的信息。
调整k近邻
在这个实验中,我们对在数据集上调整k近邻算法(kNN)感兴趣。在Weka中,这个算法称为IBk(Instance Based Learner)。
IBk算法不构建模型,而是即时为测试实例生成预测。IBk算法使用距离度量来定位每个测试实例在训练数据中的k个“接近”实例,并使用这些选定的实例来做出预测。
在这个实验中,我们希望确定在IBk算法中,对于电离层数据集,应该使用哪种距离度量。我们将把该算法的3个版本添加到我们的实验中。
欧几里得距离
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“lazy”选择下点击“IBk”。
- 在“IBk”配置中点击“OK”按钮。
这将添加IBk算法,并使用欧几里得距离作为默认距离度量。
曼哈顿距离
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“lazy”选择下点击“IBk”。
- 在IBk配置中点击“nearestNeighborSearchAlgorithm”的名称。
- 点击“distanceFunction”的“Choose”按钮,然后选择“ManhattanDistance”。
- 在“nearestNeighborSearchAlgorithm”配置中点击“OK”按钮。
- 在“IBk”配置中点击“OK”按钮。
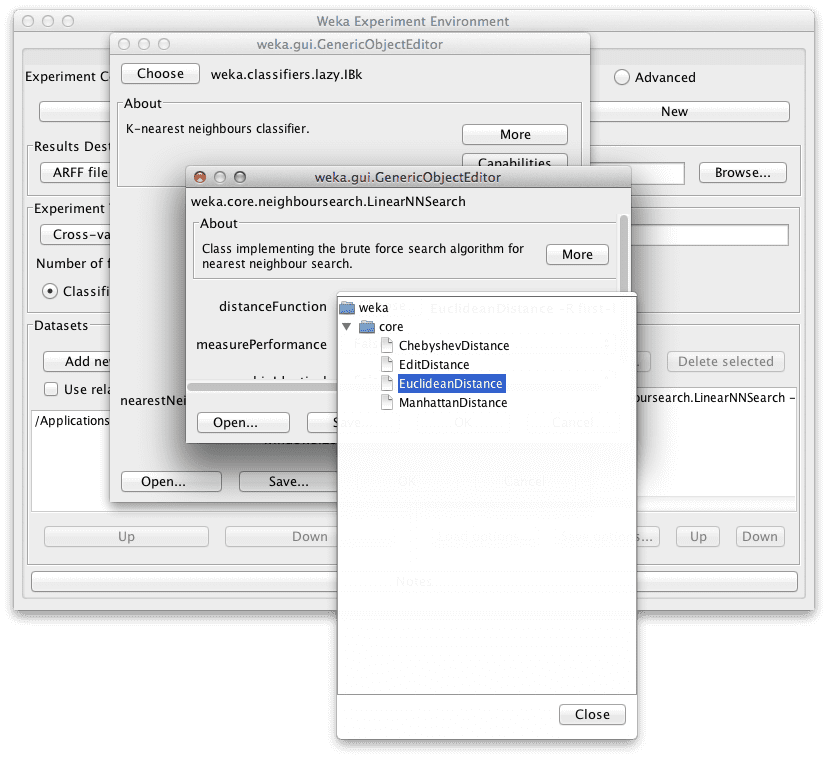
为IBk选择距离度量
这将添加IBk算法,并使用曼哈顿距离(也称为城市街区距离)。
切比雪夫距离
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“lazy”选择下点击“IBk”。
- 在IBk配置中点击“nearestNeighborSearchAlgorithm”的名称。
- 点击“distanceFunction”的“Choose”按钮,然后选择“ChebyshevDistance”。
- 在“nearestNeighborSearchAlgorithm”配置中点击“OK”按钮。
- 在“IBk”配置中点击“OK”按钮。
这将添加IBk算法,并使用切比雪夫距离(也称为城市棋盘距离)。
4. 运行实验
点击屏幕顶部的“Run”标签页。
此标签页是运行当前配置的实验的控制面板。
点击大的“Start”按钮开始实验,并观察“Log”和“Status”部分以了解其进度。
5. 审阅结果
点击屏幕顶部的“Analyse”标签页。
这将打开实验结果分析面板。
算法排名
我们首先想知道哪个算法是最好的。我们可以通过算法击败其他算法的次数来对算法进行排名。
- 点击“Test base”的“Select”按钮,然后选择“Ranking”。
- 现在点击“Perform test”按钮。
排名表显示了每种算法在数据集上相对于所有其他算法的统计学显著获胜次数。获胜是指准确率优于另一算法的准确率,并且差异在统计学上是显著的。
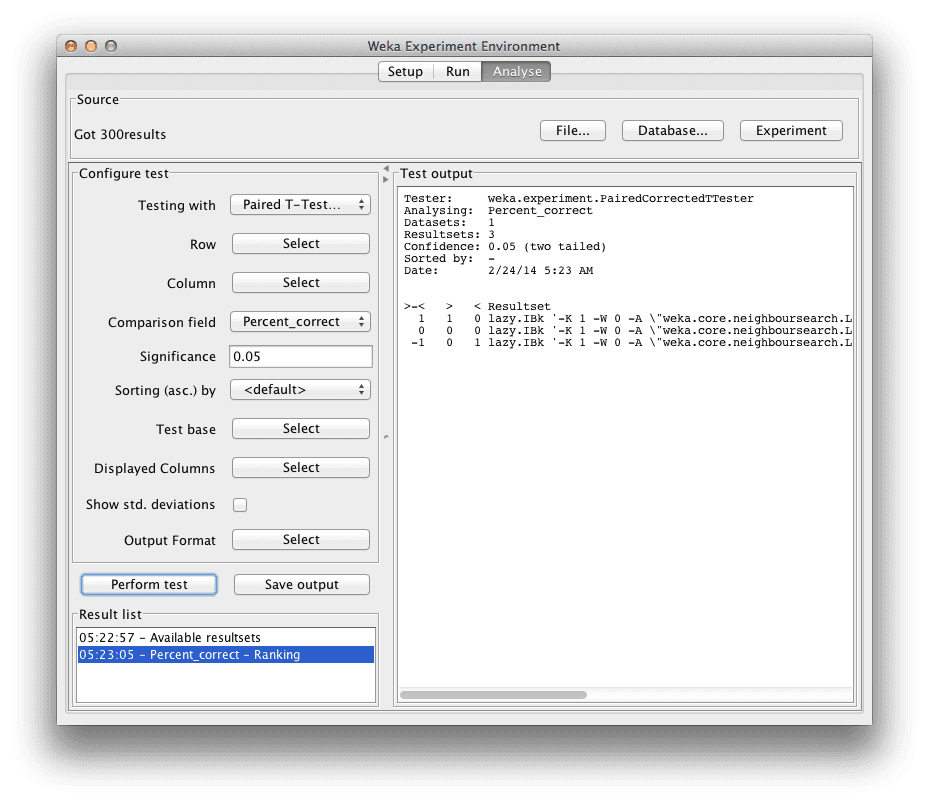
Weka Explorer中电离层数据集的算法排名
我们可以看到曼哈顿距离变体排名最高,而欧几里得距离变体排名最低。这令人鼓舞,看起来我们找到了一个比该问题默认算法配置更好的配置。
算法准确率
接下来,我们想知道算法取得了什么样的分数。
- 点击“Test base”的“Select”按钮,然后从列表中选择“Manhattan Distance”的“IBk”算法,然后点击“Select”按钮。
- 勾选“Show std. deviations”旁边的复选框。
- 现在点击“Perform test”按钮。
在“Test output”中,我们可以看到一个表格,其中包含IBk算法3个变体的结果。每种算法在数据集上运行了10次,报告的准确率是这10次运行的平均值和标准差。
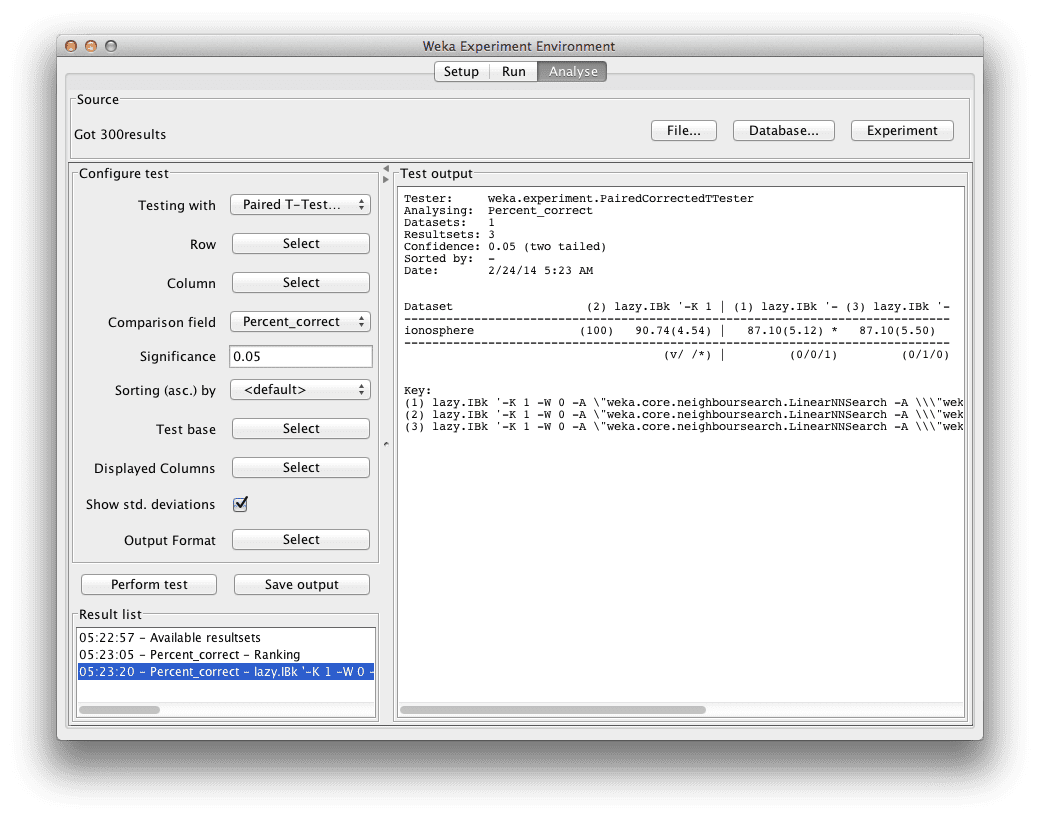
Weka Explorer中电离层数据集上的算法分类准确率表
我们可以看到,曼哈顿距离的IBk算法达到了90.74%(+/- 4.57%)的准确率,优于默认的欧几里得距离算法,后者准确率为87.10%(+/- 5.12%)。
IBk与欧几里得距离的结果旁边的小“*”符号告诉我们,曼哈顿距离和欧几里得距离变体的IBk算法的准确率结果来自于不同的总体,结果的差异在统计学上是显著的。
我们还可以看到,IBk与切比雪夫距离的结果没有“*”符号,这表明曼哈顿距离和切比雪夫距离变体IBk算法的结果差异在统计学上不显著。
总结
在这篇文章中,您学会了如何在Weka中使用一个数据集和三种算法变体配置机器学习实验。您还发现如何使用Weka Experimenter来调整数据集上机器学习算法的参数并分析结果。
如果您看到了这里,为什么不
- 看看您是否可以进一步调整IBk并获得更好的结果(并在评论中告诉我们)
- 设计并运行一个实验来调整IBk的k参数。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。


")



非常感谢网站创建者
非常欢迎。
你好,我尝试了多个选项K=1(如提及的)、3、5、10。也尝试了加权距离,很难找到比曼哈顿距离更好的准确率。
感谢关于调整机器学习算法的教程,它确实提供了如何修改参数和比较测试选项的完整见解。
我很高兴您觉得它有用,Jayesh。
现在我尝试与SMO函数(即SVM算法)进行比较,使用RBF核和gamma为1,它给出了更好的结果,准确率为94.53%。
比较/排名这两个算法(KNN和SVM)有效吗?
是的,对所有算法进行排名,看看哪个在问题上效果最好。结果/性能衡量所有算法。
排名是如何在内部工作的?当你有N个受试者和每个受试者有m个模型时,如何比较算法的性能?如果我能访问每个模型的混淆矩阵,是否有方法可以在Python/MATLAB中编程实现排名部分?
你说的受试者是什么意思?数据集?
很好的教程。令人惊讶的是,一个好的相似性或距离函数选择会对结果产生如此大的影响。
这是一个很好的提醒,要调整模型。
你好,
在这个数据集中没有显示KNN的图吗?可以使用Weka实现吗?
是的,我认为有一个决策边界图。