从提示到图片,Stable Diffusion 是一个包含许多组件和参数的流程。所有这些组件协同工作以生成输出。如果某个组件的行为不同,输出也会改变。因此,不当的设置很容易毁掉你的图片。在这篇文章中,你将看到
- Stable Diffusion 流程中的不同组件如何影响你的输出
- 如何找到最佳配置来帮助你生成高质量的图片
通过我的书 《用 Stable Diffusion 精通数字艺术》 来启动你的项目。它提供了带有工作代码的自学教程。
让我们开始吧。

如何有效使用 Stable Diffusion。
照片作者:Kam Idris。部分权利保留。
概述
这篇文章分为三个部分;它们是
- 模型的重要性
- 选择采样器和调度器
- 尺寸和 CFG 比例
模型的重要性
如果流程中有一个组件影响最大,那一定是模型。在 Web UI 中,它被称为“检查点”(checkpoint),以我们在训练深度学习模型时保存模型的方式命名。
Web UI 支持多种 Stable Diffusion 模型架构。如今最常见的架构是 1.5 版本 (SD 1.5)。事实上,所有 1.x 版本都具有相似的架构(每个模型有 8.6 亿个参数),但训练或微调的策略不同。
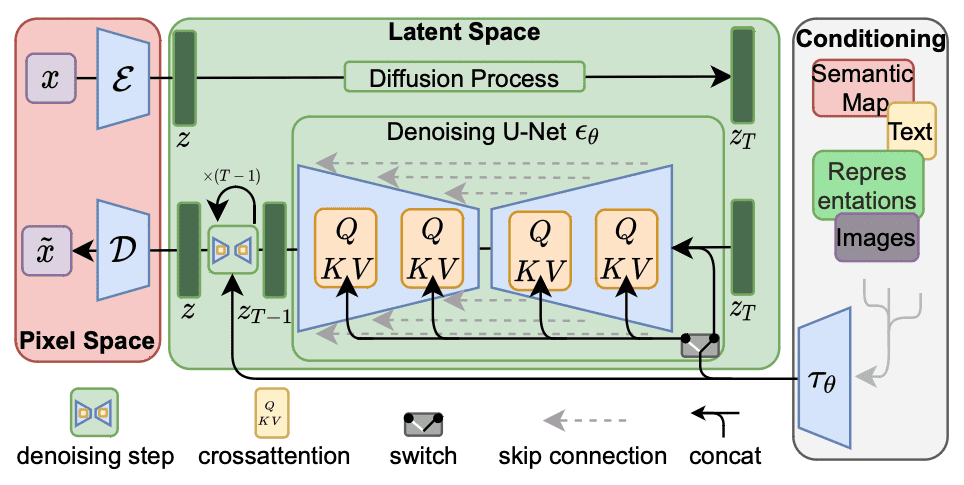
Stable Diffusion 1.x 的架构。图片来自 Rombach 等人 (2022)
还有 Stable Diffusion 2.0 (SD 2.0) 及其更新版本 2.1。这并不是 1.5 版本的“修订版”,而是从头开始训练的模型。它使用了不同的文本编码器(OpenCLIP 而不是 CLIP);因此,它们对关键字的理解不同。一个明显的区别是 OpenCLIP 知道的明星和艺术家名字更少。因此,来自 Stable Diffusion 1.5 的提示在 2.1 中可能已过时。由于编码器不同,SD2.x 和 SD1.x 不兼容,尽管它们具有相似的架构。
接下来是 Stable Diffusion XL (SDXL)。虽然 1.5 版本的原生分辨率是 512×512,2.0 版本将其提高到 768×768,但 SDXL 的分辨率是 1024×1024。不建议使用与原生分辨率相差很大的尺寸。SDXL 是不同的架构,拥有大得多的 66 亿参数流程。最值得注意的是,模型有两个部分:基础模型 (Base model) 和精炼模型 (Refiner model)。它们成对出现,但你可以用兼容的部件替换其中一个,或者根据需要跳过精炼模型。使用的文本编码器结合了 CLIP 和 OpenCLIP。因此,它应该比任何旧架构更能理解你的提示。运行 SDXL 更慢,需要更多内存,但通常质量更好。
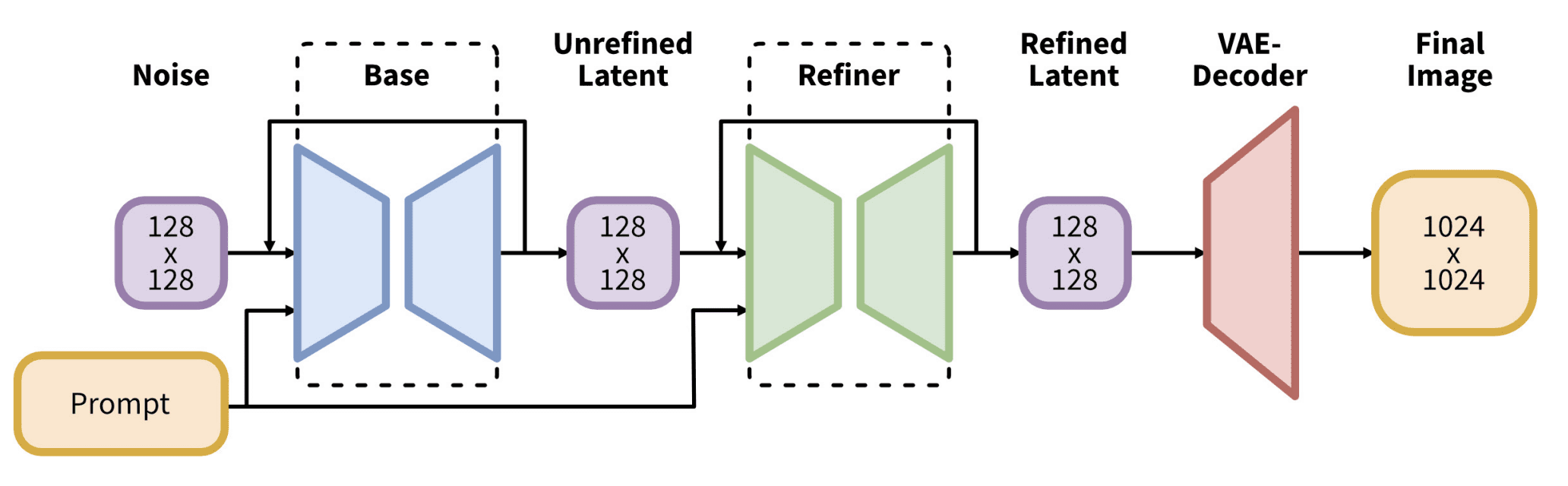
SDXL 的架构。图片来自 Podell 等人 (2023)
对你来说重要的是,你应该将你的模型分为三个不兼容的家族:SD1.5、SD2.x 和 SDXL。它们与你的提示的行为不同。你还会发现,SD1.5 和 SD2.x 需要负面提示才能生成好图,但在 SDXL 中这不太重要。如果你使用 SD2.x 模型,你还会注意到可以在 Web UI 中选择精炼模型。

使用提示“一个沙漠中的快餐店,名字叫‘Sandy Burger’”生成的图片,使用 SD 1.5 和不同的随机种子。请注意,没有一张图片正确拼写了名字。

使用提示“一个沙漠中的快餐店,名字叫‘Sandy Burger’”生成的图片,使用 SD 2.0 和不同的随机种子。请注意,并非所有图片都正确拼写了名字。

使用提示“一个沙漠中的快餐店,名字叫‘Sandy Burger’”生成的图片,使用 SDXL 和不同的随机种子。请注意,其中三张图片正确拼写了名字,最后一张只少了一个字母。
Stable Diffusion 的一个特点是,原始模型能力较弱但适应性强。因此,产生了许多第三方微调模型。最重要的是专注于特定风格的模型,例如日式动漫、欧美卡通、皮克斯风格的 2.5D 图形或逼真照片。
你可以在 Civitai.com 或 Hugging Face Hub 上找到模型。搜索关键词如“photorealistic”或“2D”并按评分排序通常会有帮助。
选择采样器和调度器
图像扩散是从噪声开始,然后战略性地用像素替换噪声,直到生成最终图片。后来发现这个过程可以表示为一个随机微分方程。数值求解该方程是可能的,并且有不同的算法,准确度各异。
最常用的采样器是 Euler。它很传统但仍然有用。然后是 DPM 采样器家族。最近还引入了一些新的采样器,如 UniPC 和 LCM。每个采样器都是一个算法。它会运行多个步长,并且每一步使用不同的参数。参数使用调度器设置,例如 Karras 或 exponential。一些采样器有替代的“祖先”模式,这会在每一步增加随机性。如果你想要更有创意的输出,这很有用。这些采样器通常在其名称中带有“a”后缀,例如“Euler a”而不是“Euler”。非祖先采样器会收敛,也就是说,它们在达到一定步数后会停止改变输出。祖先采样器如果增加步数,会产生不同的输出。
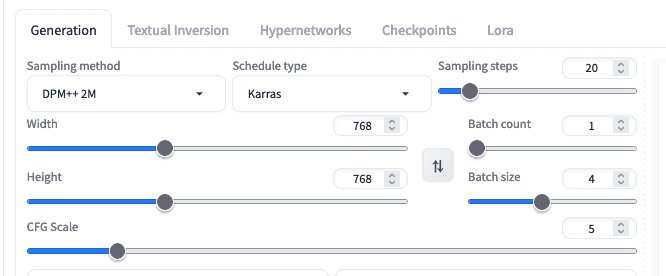
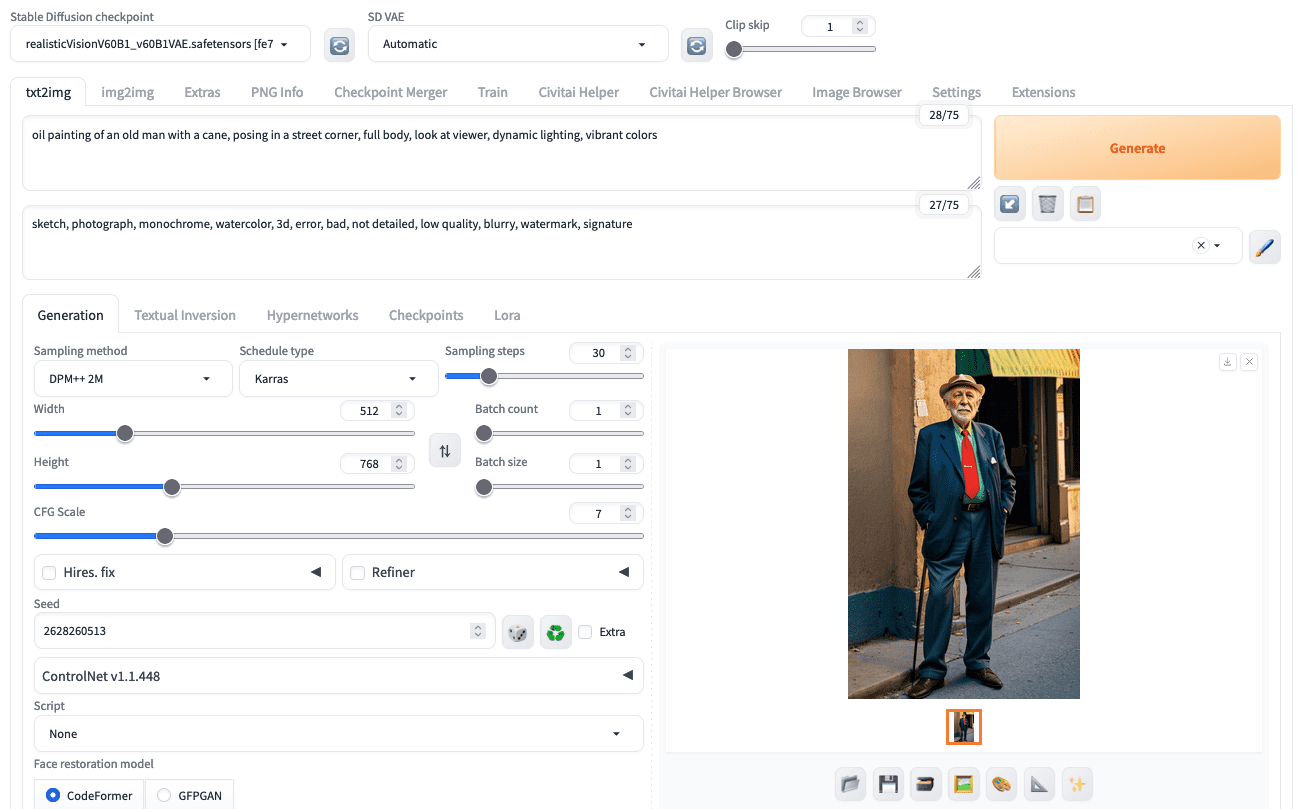
在 Stable Diffusion Web UI 中选择采样器、调度器、步数和其他参数
作为用户,你可以假设 Karras 是所有情况下的调度器。然而,调度器和步数还需要一些实验。Euler 或 DPM++2M 应该被选中,因为它们在质量和速度之间取得了最佳平衡。你可以从大约 20 到 30 步开始;你选择的步数越多,输出的细节和准确性就越好,但速度会按比例下降。
尺寸和 CFG 比例
回想一下,图像扩散过程是从一张带噪图片的开始,根据提示逐渐放置像素。提示对扩散过程的影响程度由 CFG 比例(classifier-free guidance scale,分类器无关引导比例)参数控制。
不幸的是,CFG 比例的最佳值取决于模型。有些模型在 CFG 比例为 1 到 2 时效果最好,而有些模型则针对 7 到 9 进行了优化。Web UI 中的默认值为 7.5。但总的来说,CFG 比例越高,输出图像越能符合你的提示。
如果你的 CFG 比例太低,输出图像可能不是你想要的。然而,你没有得到想要结果的另一个原因是你设置的输出尺寸。例如,如果你提示要一张男人站立的图片,你可能会得到一个半身照,除非你将图像高度设置为远大于宽度。扩散过程在早期步骤中就确定了图片的构图。在一个更高的画布上更容易设计一个站立的男人。
在提供方形画布时生成半身照。
使用相同的提示、相同的种子,只更改画布尺寸,生成全身照。
同样,如果你给图像中一小部分的东西太多细节,这些细节就会被忽略,因为没有足够的像素来渲染这些细节。这就是为什么 SDXL 通常比 SD 1.5 更好,因为你通常会使用更大的像素尺寸。
最后一点,使用图像扩散模型生成图片涉及随机性。请始终从一批图片开始,以确保不好的输出不是仅仅由于随机种子。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- 使用潜在扩散模型进行高分辨率图像合成,作者 Rombach 等人 (2022)
- SDXL:改进用于高分辨率图像合成的潜在扩散模型,作者 Podell 等人 (2023)
- 维基百科上的 Stable Diffusion 页面
总结
在这篇文章中,你了解了影响 Stable Diffusion 图像生成的几个微妙细节。具体来说,你学习了
- 不同版本的 Stable Diffusion 之间的区别
- 调度器和采样器如何影响图像扩散过程
- 画布尺寸如何影响输出
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,包含所有 Python工作代码,指导你从新手成长为图像生成专家。它教你如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都将帮助你创作出令人惊叹的数字艺术。






请注意,SDXL 输出图中最右下角的图片中,“Sandy Burger”的拼写有误——拼写成了“Sandy Buger”,而该图的说明中说所有输出都正确拼写了文本。
感谢 Lachlan 的反馈!