深度学习神经网络通常是不透明的,这意味着虽然它们可以做出有用且熟练的预测,但尚不清楚如何或为何做出给定的预测。
卷积神经网络具有旨在处理二维图像数据的内部结构,因此能够保留模型所学内容的空间关系。具体来说,可以检查和可视化模型学习到的二维滤波器,以发现模型将检测到的特征类型;可以检查卷积层输出的激活图,以确切了解给定输入图像检测到了哪些特征。
在本教程中,您将学习如何在卷积神经网络中开发滤波器和特征图的简单可视化。
完成本教程后,您将了解:
- 如何在卷积神经网络中开发特定滤波器的可视化。
- 如何在卷积神经网络中开发特定特征图的可视化。
- 如何在深度卷积神经网络的每个块中系统地可视化特征图。
开始您的项目,阅读我的新书 《深度学习计算机视觉》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何可视化卷积神经网络中的过滤器和特征图
照片由 Mark Kent 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 可视化卷积层
- 预训练的 VGG 模型
- 如何可视化滤波器
- 如何可视化特征图
可视化卷积层
神经网络模型通常被称为不透明的。这意味着它们很难解释为什么会做出特定的决策或预测。
卷积神经网络旨在处理图像数据,其结构和功能表明它们应该比其他类型的神经网络更易于理解。
具体来说,模型由小的线性滤波器组成,滤波器的应用结果称为激活图,或更通用地称为特征图。
滤波器和特征图都可以可视化。
例如,我们可以设计和理解小的滤波器,例如边缘检测器。也许可视化学习到的卷积神经网络中的滤波器可以提供对模型工作方式的洞察。
将滤波器应用于输入图像以及 prior 层输出的特征图所产生的特征图可以提供对模型在模型中特定点上对特定输入的内部表示的洞察。
在本教程中,我们将探讨这两种可视化卷积神经网络的方法。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
预训练的 VGG 模型
我们需要一个模型来可视化。
我们不必从头开始训练模型,而是可以使用预先训练的最先进图像分类模型。
Keras 提供了许多示例,这些示例是为 ImageNet 大型视觉识别挑战(ILSVRC)开发的表现出色的图像分类模型。其中一个例子是 VGG-16 模型,该模型在 2014 年的比赛中取得了优异的成绩。
这是一个用于可视化的好模型,因为它具有简单的统一结构,由顺序排列的卷积层和池化层组成;它很深,有 16 个学习层;并且表现出色,这意味着滤波器和由此产生的特征图将捕获有用的特征。有关此模型的更多信息,请参阅 2015 年的论文《用于大规模图像识别的超深卷积网络》.
我们可以用几行代码加载和总结 VGG16 模型;例如
|
1 2 3 4 5 6 |
# 加载 vgg 模型 from keras.applications.vgg16 import VGG16 # 加载模型 model = VGG16() # 总结模型 model.summary() |
运行示例会将模型权重加载到内存中,并打印加载模型的摘要。
如果这是您第一次加载模型,权重将从互联网下载并存储在您的主目录中。这些权重大约为 500MB,下载可能需要一些时间,具体取决于您的互联网连接速度。
我们可以看到层名称清晰,按块组织,并在每个块内用整数索引命名。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= 总参数:138,357,544 可训练参数:138,357,544 不可训练参数: 0 _________________________________________________________________ |
现在我们有了一个预训练模型,可以将其作为可视化的基础。
如何可视化滤波器
也许最简单的可视化方法是直接绘制学习到的滤波器。
在神经网络术语中,学习到的滤波器就是权重,但由于滤波器的特殊二维结构,权重值之间存在空间关系,将每个滤波器绘制成二维图像是有意义的(或者可能是有意义的)。
第一步是查看模型中的滤波器,看看我们有什么可以处理的。
上一节打印的模型摘要总结了每个层的输出形状,例如,结果特征图的形状。它没有提供有关网络中滤波器(权重)形状的任何信息,只提供了每层的总权重数。
我们可以通过 model.layers 属性访问模型的所有层。
每个层都有一个 layer.name 属性,卷积层的命名方式类似于 block#_conv#,其中“#”是整数。因此,我们可以检查每个层的名称,并跳过任何不包含“conv”字符串的层。
|
1 2 3 4 5 |
# 汇总滤波器形状 for layer in model.layers: # 检查是否为卷积层 if 'conv' not in layer.name: continue |
每个卷积层都有两组权重。
一个是滤波器块,另一个是偏置值块。这些可以通过 layer.get_weights() 函数访问。我们可以检索这些权重,然后汇总它们的形状。
|
1 2 3 |
# 获取滤波器权重 filters, biases = layer.get_weights() print(layer.name, filters.shape) |
将所有内容整合在一起,总结模型滤波器的完整示例代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 总结每个卷积层的滤波器 from keras.applications.vgg16 import VGG16 from matplotlib import pyplot # 加载模型 model = VGG16() # 汇总滤波器形状 for layer in model.layers: # 检查是否为卷积层 if 'conv' not in layer.name: continue # 获取滤波器权重 filters, biases = layer.get_weights() print(layer.name, filters.shape) |
运行该示例将打印出层详细信息列表,包括层名称和层中滤波器的形状。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
block1_conv1 (3, 3, 3, 64) block1_conv2 (3, 3, 64, 64) block2_conv1 (3, 3, 64, 128) block2_conv2 (3, 3, 128, 128) block3_conv1 (3, 3, 128, 256) block3_conv2 (3, 3, 256, 256) block3_conv3 (3, 3, 256, 256) block4_conv1 (3, 3, 256, 512) block4_conv2 (3, 3, 512, 512) block4_conv3 (3, 3, 512, 512) block5_conv1 (3, 3, 512, 512) block5_conv2 (3, 3, 512, 512) block5_conv3 (3, 3, 512, 512) |
我们可以看到所有卷积层都使用 3x3 的滤波器,它们很小,可能易于解释。
卷积神经网络的一个架构问题是滤波器的深度必须与滤波器的输入深度匹配(例如,通道数)。
我们可以看到,对于具有三个通道(红、绿、蓝)的输入图像,每个滤波器的深度为三个(这里我们处理的是通道优先格式)。我们可以将一个滤波器可视化为包含三个图像的图,每个通道一个图像;或者将所有三个图像压缩成一个彩色图像;甚至只查看第一个通道并假设其他通道看起来相同。问题是,我们还有 63 个其他滤波器可能也想可视化。
我们可以按如下方式检索第一层的滤波器:
|
1 2 |
# 检索第二隐藏层的权重 filters, biases = model.layers[1].get_weights() |
权重值可能很小,是围绕 0.0 的正负值。
我们可以将它们的值归一化到 0-1 的范围,以便于可视化。
|
1 2 3 |
# 将滤波器值归一化到 0-1,以便我们可视化它们 f_min, f_max = filters.min(), filters.max() filters = (filters - f_min) / (f_max - f_min) |
现在我们可以枚举块中的前六个滤波器(共 64 个),并绘制每个滤波器的三个通道。
我们使用 matplotlib 库,并将每个滤波器绘制成新的子图行,将每个滤波器通道或深度绘制成新的列。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制前几个滤波器 n_filters, ix = 6, 1 for i in range(n_filters): # 获取滤波器 f = filters[:, :, :, i] # 分别绘制每个通道 for j in range(3): # 指定子图并关闭轴 ax = pyplot.subplot(n_filters, 3, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(f[:, :, j], cmap='gray') ix += 1 # 显示图 pyplot.show() |
将所有内容整合在一起,从 VGG16 模型的第一隐藏卷积层中绘制前六个滤波器的完整示例代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 较低层的滤波器不易可视化 from keras.applications.vgg16 import VGG16 from matplotlib import pyplot # 加载模型 model = VGG16() # 检索第二隐藏层的权重 filters, biases = model.layers[1].get_weights() # 将滤波器值归一化到 0-1,以便我们可视化它们 f_min, f_max = filters.min(), filters.max() filters = (filters - f_min) / (f_max - f_min) # 绘制前几个滤波器 n_filters, ix = 6, 1 for i in range(n_filters): # 获取滤波器 f = filters[:, :, :, i] # 分别绘制每个通道 for j in range(3): # 指定子图并关闭轴 ax = pyplot.subplot(n_filters, 3, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(f[:, :, j], cmap='gray') ix += 1 # 显示图 pyplot.show() |
运行示例将创建一个包含六行三张图像(即 18 张图像)的图形,每行代表一个滤波器,每列代表一个通道。
我们可以看到,在某些情况下,滤波器在通道之间是相同的(第一行),而在其他情况下,滤波器是不同的(最后一行)。
暗方块表示小或抑制性权重,亮方块表示大或兴奋性权重。根据这个直觉,我们可以看到第一行的滤波器检测到了从左上角的亮色到右下角的暗色梯度。
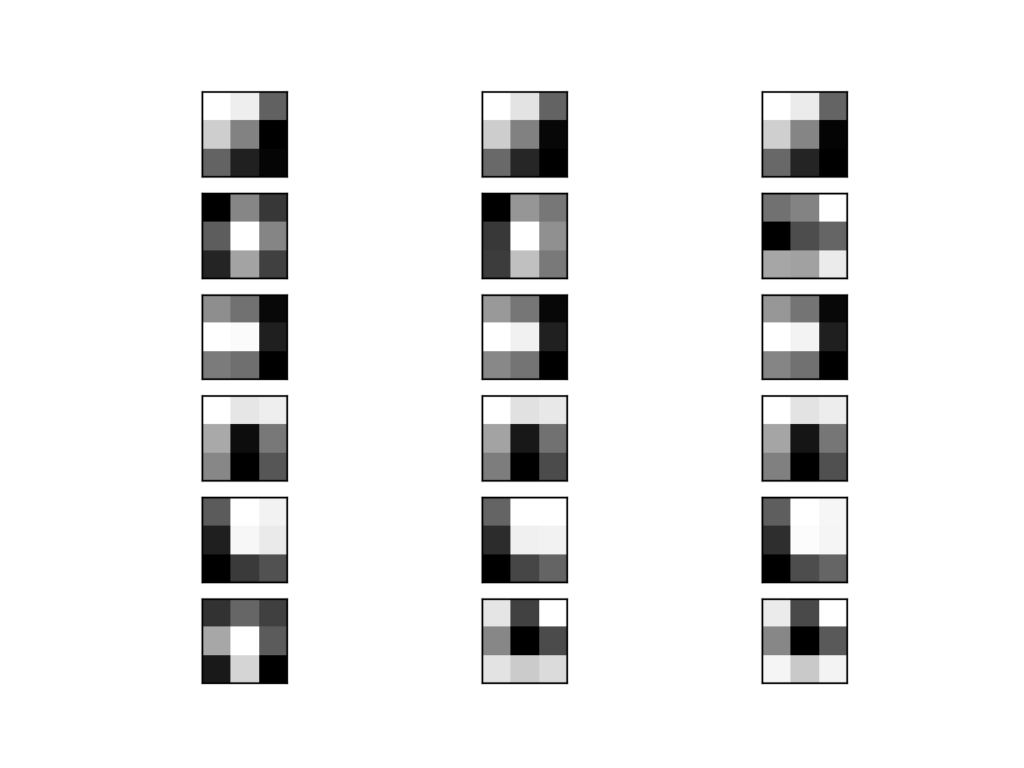
VGG16 滤波器(每个通道一个子图)的前 6 个滤波器的绘制图
虽然我们有可视化,但我们只看到了第一个卷积层中 64 个滤波器中的前六个。可视化所有 64 个滤波器在一张图像中是可行的。
可惜的是,这并不能规模化;如果我们想开始查看第二个卷积层中的滤波器,我们可以看到同样有 64 个滤波器,但每个滤波器有 64 个通道以匹配输入特征图。要查看所有 64 个滤波器的所有 64 个通道,需要 (64x64) 4,096 个子图,在其中可能很难看到任何细节。
如何可视化特征图
称为特征图的激活图捕获了将滤波器应用于输入(如输入图像或其他特征图)的结果。
可视化特定输入图像的特征图的想法是理解输入图像的哪些特征在特征图中被检测到或保留。期望是,靠近输入的特征图会检测到小或细粒度的细节,而靠近模型输出的特征图则捕获更通用的特征。
为了探索特征图的可视化,我们需要 VGG16 模型所需的输入,用于创建激活。我们将使用一张简单的鸟的照片。具体来说,是一只知更鸟,由 Chris Heald 拍摄,并根据许可发布。
下载照片并将其放在当前工作目录中,文件名为 'bird.jpg'。

知更鸟,作者 Chris Heald
接下来,我们需要更清楚地了解每个卷积层输出的特征图的形状以及层索引号,以便我们能够检索相应的层输出。
下面的示例将枚举模型中的所有层,并打印每个卷积层的输出大小或特征图大小以及模型中的层索引。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 总结每个卷积层的特征图大小 from keras.applications.vgg16 import VGG16 from matplotlib import pyplot # 加载模型 model = VGG16() # 总结特征图形状 for i in range(len(model.layers)): layer = model.layers[i] # 检查是否为卷积层 if 'conv' not in layer.name: continue # 总结输出形状 print(i, layer.name, layer.output.shape) |
运行示例,我们看到与模型摘要中看到的输出形状相同,但在这种情况下仅针对卷积层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
1 block1_conv1 (?, 224, 224, 64) 2 block1_conv2 (?, 224, 224, 64) 4 block2_conv1 (?, 112, 112, 128) 5 block2_conv2 (?, 112, 112, 128) 7 block3_conv1 (?, 56, 56, 256) 8 block3_conv2 (?, 56, 56, 256) 9 block3_conv3 (?, 56, 56, 256) 11 block4_conv1 (?, 28, 28, 512) 12 block4_conv2 (?, 28, 28, 512) 13 block4_conv3 (?, 28, 28, 512) 15 block5_conv1 (?, 14, 14, 512) 16 block5_conv2 (?, 14, 14, 512) 17 block5_conv3 (?, 14, 14, 512) |
我们可以利用这些信息设计一个新模型,该模型是 VGG16 模型层的一个子集。该模型将与原始模型具有相同的输入层,但输出将是给定卷积层的输出,我们知道这将是该层的激活或特征图。
例如,在加载 VGG 模型后,我们可以定义一个新模型,该模型从第一个卷积层(索引 1)输出特征图,如下所示。
|
1 2 |
# 重新定义模型,使其在第一个隐藏层之后输出 model = Model(inputs=model.inputs, outputs=model.layers[1].output) |
使用此模型进行预测将为给定的输入图像生成第一个卷积层的特征图。让我们来实现这一点。
定义模型后,我们需要加载大小与模型期望大小(在本例中为 224x224)相同的鸟图像。
|
1 2 |
# 加载具有所需形状的图像 img = load_img('bird.jpg', target_size=(224, 224)) |
接下来,需要将 PIL 图像对象转换为像素数据的 NumPy 数组,并从 3D 数组扩展到 4D 数组,维度为 [样本,行,列,通道],其中我们只有一个样本。
|
1 2 3 4 |
# 将图像转换为数组 img = img_to_array(img) # 扩展维度,使其代表单个“样本” img = expand_dims(img, axis=0) |
然后需要将像素值缩放到适合 VGG 模型的适当比例。
|
1 2 |
# 准备图像(例如,缩放 VGG 的像素值) img = preprocess_input(img) |
现在我们可以获取特征图了。可以通过调用 model.predict() 函数并传入准备好的单个图像来轻松完成。
|
1 2 |
# 获取第一个隐藏层的特征图 feature_maps = model.predict(img) |
我们知道结果将是一个 224x224x64 的特征图。我们可以将所有 64 个二维图像绘制成 8x8 的图像方格。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 以 8x8 方格绘制所有 64 张图 square = 8 ix = 1 for _ in range(square): for _ in range(square): # 指定子图并关闭轴 ax = pyplot.subplot(square, square, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(feature_maps[0, :, :, ix-1], cmap='gray') ix += 1 # 显示图 pyplot.show() |
将所有这些内容整合在一起,用于可视化 VGG16 模型中第一个卷积层的特征图,针对鸟输入图像的完整代码示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 以给定图像可视化第一个卷积层的特征图 from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.models import Model from matplotlib import pyplot from numpy importexpand_dims # 加载模型 model = VGG16() # 重新定义模型,使其在第一个隐藏层之后输出 model = Model(inputs=model.inputs, outputs=model.layers[1].output) model.summary() # 加载具有所需形状的图像 img = load_img('bird.jpg', target_size=(224, 224)) # 将图像转换为数组 img = img_to_array(img) # 扩展维度,使其代表单个“样本” img = expand_dims(img, axis=0) # 准备图像(例如,缩放 VGG 的像素值) img = preprocess_input(img) # 获取第一个隐藏层的特征图 feature_maps = model.predict(img) # 以 8x8 方格绘制所有 64 张图 square = 8 ix = 1 for _ in range(square): for _ in range(square): # 指定子图并关闭轴 ax = pyplot.subplot(square, square, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(feature_maps[0, :, :, ix-1], cmap='gray') ix += 1 # 显示图 pyplot.show() |
运行示例将首先总结新的、更小的模型,该模型接受图像并输出特征图。
请记住:这个模型比 VGG16 模型小得多,但它仍然使用 VGG16 模型第一个卷积层中的相同权重(滤波器)。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 ================================================================= 总参数:1,792 可训练参数:1,792 不可训练参数: 0 _________________________________________________________________ |
接下来,将创建一个图形,显示所有 64 个特征图作为子图。
我们可以看到,第一个卷积层中滤波器的应用结果是许多经过不同特征高亮显示的鸟的图像版本。
例如,有些高亮显示边缘,有些则聚焦于背景或前景。

VGG16 模型第一个卷积层提取的特征图可视化
这是一个有趣的结果,总体上符合我们的预期。我们可以更新示例以绘制 VGG16 模型中其他特定卷积层的输出特征图。
另一种方法是收集模型每个块的特征图并在一次通过中完成,然后为每个块创建一个图像。
图像中有五个主要块(例如,block1、block2 等),它们以池化层结束。每个块的最后一个卷积层的层索引是 [2, 5, 9, 13, 17]。
我们可以定义一个具有多个输出的新模型,每个输出对应每个块的最后一个卷积层的特征图输出;例如
|
1 2 3 4 5 |
# 重新定义模型,使其在第一个隐藏层之后输出 ixs = [2, 5, 9, 13, 17] outputs = [model.layers[i+1].output for i in ixs] model = Model(inputs=model.inputs, outputs=outputs) model.summary() |
使用这个新模型进行预测将产生一个特征图列表。
我们知道,更深层的特征图的数量(例如,深度或通道数)远超 64,例如 256 或 512。尽管如此,为了保持一致性,我们可以将可视化的特征图数量限制为 64。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 绘制每个块的输出 square = 8 for fmap in feature_maps: # 以 8x8 方格绘制所有 64 张图 ix = 1 for _ in range(square): for _ in range(square): # 指定子图并关闭轴 ax = pyplot.subplot(square, square, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(fmap[0, :, :, ix-1], cmap='gray') ix += 1 # 显示图形 pyplot.show() |
将这些更改整合在一起,我们现在可以为 VGG16 模型中的五个块中的每个块创建五个单独的图,用于我们的鸟类照片。完整列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 可视化 VGG 模型中每个块的特征图输出 from keras.applications.vgg16 import VGG16 from keras.applications.vgg16 import preprocess_input from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.models import Model from matplotlib import pyplot from numpy importexpand_dims # 加载模型 model = VGG16() # 重新定义模型,使其在第一个隐藏层之后输出 ixs = [2, 5, 9, 13, 17] outputs = [model.layers[i].output for i in ixs] model = Model(inputs=model.inputs, outputs=outputs) # 加载具有所需形状的图像 img = load_img('bird.jpg', target_size=(224, 224)) # 将图像转换为数组 img = img_to_array(img) # 扩展维度,使其代表单个“样本” img = expand_dims(img, axis=0) # 准备图像(例如,缩放 VGG 的像素值) img = preprocess_input(img) # 获取第一个隐藏层的特征图 feature_maps = model.predict(img) # 绘制每个块的输出 square = 8 for fmap in feature_maps: # 以 8x8 方格绘制所有 64 张图 ix = 1 for _ in range(square): for _ in range(square): # 指定子图并关闭轴 ax = pyplot.subplot(square, square, ix) ax.set_xticks([]) ax.set_yticks([]) # 以灰度绘制滤波器通道 pyplot.imshow(fmap[0, :, :, ix-1], cmap='gray') ix += 1 # 显示图形 pyplot.show() |
运行示例将生成五个图,显示 VGG16 模型五个主要块的特征图。
我们可以看到,更接近模型输入的特征图捕获了图像中的大量细节,并且随着我们深入模型,特征图显示的细节越来越少。
这是可以预期的模式,因为模型将图像的特征抽象为更通用的概念,可用于进行分类。虽然从最终图像看不出模型看到了鸟,但我们通常会失去解释这些更深层特征图的能力。

VGG16 模型中从 Block 1 提取的特征图可视化

VGG16 模型中从 Block 2 提取的特征图可视化

VGG16 模型中从 Block 3 提取的特征图可视化

VGG16 模型中从 Block 4 提取的特征图可视化

VGG16 模型中从 Block 5 提取的特征图可视化
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 第9章:卷积网络,深度学习,2016年。
- 第5章:深度学习计算机视觉,Python 深度学习,2017年。
API
文章
- 第 12 讲 | 可视化与理解,CS231n:用于视觉识别的卷积神经网络,(幻灯片)2017。
- 可视化卷积神经网络的学习内容,CS231n:用于视觉识别的卷积神经网络.
- 卷积神经网络如何看待世界, 2016.
总结
在本教程中,您学习了如何为卷积神经网络中的滤波器和特征图开发简单的可视化。
具体来说,你学到了:
- 如何在卷积神经网络中开发特定滤波器的可视化。
- 如何在卷积神经网络中开发特定特征图的可视化。
- 如何在深度卷积神经网络的每个块中系统地可视化特征图。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。




")
")
非常感谢您,先生!它帮助我的论文手稿找到我模型中每一层的特征图。顺便问一下,先生,关于如何在我的 CNN 模型中显示每个卷积层的滤波器和偏差的值(而不是图像)?
很高兴听到这个消息。
您可以打印数组并检查值。
好的,先生,谢谢 🙂
先生,我可以提个请求吗?我想显示我模型中每个卷积层的每个特征图,并且我的代码在访问每个特征图时遇到问题。有什么建议吗,先生?我希望您能回复,谢谢。
先生,解释得非常棒。
index = [0, 1, 6, 9, 14, 17]
outputs = [self.model.layers[i].output for i in index]
self.model = Model(inputs=self.model.inputs, outputs=outputs)
featureMaps = self.model.predict(self.testImage)
print((np.shape(featureMaps[0][0])))
print(“FeatureMapsLen: “+str(np.shape(featureMaps[0]))[2])
numOfFeaturemaps = (np.shape(featureMaps[0][0]))[2]
print(“numOfFeatureMaps: “+str(numOfFeaturemaps)
fig=plt.figure(figsize=(16,16))
subplotNum=int(np.ceil(np.sqrt(numOfFeaturemaps)))
for i in range(int(numOfFeaturemaps))
idx = fig.add_subplot(subplotNum, subplotNum, i+1)
idx.imshow(featureMaps[0, :, :, i], cmap=’viridis’) #我在这里卡了很久,杰森先生!!
plt.xticks(np.array([]))
plt.yticks(np.array([]))
plt.tight_layout()
plt.savefig(“featureMaps/featuremaps@Layer{}”.format(self.layerNum) + ‘.png’)
outputImg = QtGui.QPixmap(“featureMaps/featuremaps@Layer{}”.format(self.layerNum) + ‘.png’)
self.userInterface.labelImageContainer.setScaledContents(False)#固定显示
self.userInterface.labelImageContainer.setPixmap(outputImg)
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
LiME 以“解释”分类问题的结果而闻名。我们能否使用您解释的滤波器来解释分割问题的结果?
也许吧。我还没有看到过关于这个主题的研究。
也许可以尝试在 scholar.google.com 上搜索。
很棒的解释。最好的部分是分步解释和代码。真的很有帮助 🙂
谢谢。
出于任何明显的原因,我的 Keras 是通过 TensorFlow 使用的,所以 I have to modify,例如,这一行代码
“from keras.applications.vgg16 import VGG16”
推广到
“from tensordlow.keras.applications.vgg16 import VGG16”
当我第一次加载它时,它显示正在从 Github 下载,但现在它正在训练!这正常吗?
谢谢!
第一次下载是正常的。
好的!但我下载时遇到了困难,在下载了 33Mb 后出现连接到远程服务器错误,所以我打开了位于我的 tensorflow/python/keras/applications 中的 vgg16.py 文件,获取了链接,手动下载并更改了默认设置,从 'imagenet' 改为手动下载文件所在的路径(我将其传输到了 'applications' 文件夹,但它仍然需要整个路径而不是仅文件名:“vgg16_weights_tf_dim_ordering_tf_kernels.h5”),所以对我来说是有效的。您介意 kindly 告诉我为什么它需要完整的路径吗?它应该识别它正在运行的当前路径。
我不知道它为什么需要完整路径,抱歉。
嗨 Hamed,我只想指出 TensorFlow 更新非常快,昨天关于 TensorFlow 实现的具体细节可能明天就不再是真的了。有时唯一可用的文档是您特定版本的源代码。如果值得,您可以阅读源代码,或者在 stackoverflow.com 或 github.com/tensorflow 上寻求帮助,但这通常不值得,因为更新 TF 版本将解决当前的问题。
同意!感谢分享。
感谢这节课!!
我很想看到创建类激活图的详细描述。
我一直在使用您书籍中的一些代码来训练一个 CNN 以识别前交叉韧带撕裂。我很想看看我的模型用来做决策的图像的哪些部分。
是前交叉韧带,没错。
不错,听起来像是 X 光扫描或类似的东西。
很好的建议,谢谢。
干得好,Mike!
谢谢,您真是太客气了。
你好 Jason,
谢谢您的代码……非常有帮助。
我有一个疑问。
1. 我们在本模型中使用单个图像,是否可以使用图像批次来可视化它们?
2. 我是新手。请不要介意我的愚蠢问题。是否可以像我们在这里对卷积层所做的那样,查看全连接层的输出?
3. 密集层中使用的神经元数量是否有任何限制?
如果您只查看激活图,则一次处理一张图像。
您可以查看任何层的激活,但密集层不会形成图像,它们会是噪声。
唯一的限制是您的内存大小。
如何将特征图保存为 png 或 pdf?
如果绘制它们,您可以将绘图保存到文件。
在 matplotlib 中有一个 savefig() 函数
https://matplotlib.net.cn/3.1.0/api/_as_gen/matplotlib.pyplot.savefig.html
嘿,喜欢详细的描述!
我试图复制同样的操作,但用于 pytorch 模型。
所以模型看起来不同,我无法使用相同的函数来创建特征图。
您是否为 pytorch 模型做了同样的操作,或者能否给我一些如何做的建议?
目前我完全卡住了。
抱歉,我没有 pytorch 示例,无法给您好的现成建议。
嗨,Jason,
如何解决以下问题?
NameError: name ‘Model’ is not defined
执行后
model = Model(inputs=model.inputs, outputs=model.layers[1].output)
谢谢。
错误提示您尚未导入 Model 类。
我明白了。
非常感谢!
您好,我遇到了同样的错误,我是一名新的编码员。我该如何解决这个错误?
也许这些提示会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason,您的又一篇精彩帖子。
我有一个愚蠢的问题:我明白离输入层越近的层学习局部特征,而离输出层越近的层学习全局特征。例如:我有一张人脸图像,然后将其输入我的 VGG16 网络。当我可视化滤波器时,我期望早期的滤波器绘制“眉毛”、“鼻子”,而最后一层描述“脸”,但我完全错了。
所以,我曾认为局部特征=“眉毛”、“鼻子”,但第一个滤波器的激活图描述了“脸”(全局特征)。
您能解释一下这件事吗?谢谢。
这真的取决于具体的模型。
另一个问题,模型如何推断出物体是猫或狗,如果最后一个卷积层的细节模糊甚至对人类来说也是如此?谢谢。
模型在输出层有一个分类器层来解释高阶特征。
嗨 Jason
我正在使用 ResNet50 而不是 VGG16,但在执行以下代码时遇到错误
ValueError: not enough values to unpack (expected 2, got 0)
from keras.applications.resnet50 import ResNet50
from matplotlib import pyplot
model = ResNet50()
`for layer in model.layers`
if ‘conv’ not in layer.name
continue
# 获取滤波器权重
filters, biases = layer.get_weights()
print(layer.name, filters.shape)
错误与该行有关:filters, biases = layer.get_weights()
resnet 架构更复杂,您需要调试此更改。
谢谢,Jason。最终解决了。
很高兴听到这个消息。
您能分享您的代码吗?
请问,您能分享您是如何解决的吗?谢谢。
你太棒了。你让概念变得清晰。非常感谢!
谢谢,很高兴它帮到了你!
感谢您提供的精彩文章。我经常通过“随机”的 Google 搜索阅读您的博客。
你太棒了!
谢谢 Simone!
最困难和最热门的主题之一,却以一种非常简单和信息丰富的方式进行了阐释。我非常欣赏您的解释方式。我最喜欢的博客之一。谢谢 Jason!
谢谢,很高兴它帮到了你!
在处理时间序列时可以这样做吗?我一直在看这些示例(https://machinelearning.org.cn/how-to-develop-rnn-models-for-human-activity-recognition-time-series-classification/),我想尝试解释模型正在理解的内容。我外插了卷积层的输出,并为每个不同的类进行了可视化,但我想知道您对此的看法。
这可能是可能的,我没有尝试过。
这是为初学者提供的最好的教程之一,“谢谢您,先生”。
先生,我有一个疑问,在 cov2d 函数的“filter”参数中,它会接受什么值作为矩阵值,该值与卷积图像进行矩阵乘法(我在 vgg16() 函数中看到了这个),它是否采用标记的矩阵值(如果它是监督的)?
谢谢,很高兴对您有帮助。
权重或滤波器将在训练过程中学习权重。
谢谢您,先生,我还想知道权重是如何为每一层更新的,是否有任何方法可以更新它?
注意:我正在尝试理解架构模型 https://arxiv.org/pdf/1511.00561 segnet 以及每个函数,谢谢您,先生。
权重通过反向传播进行更新。
抱歉,我对那篇论文不熟悉,也许可以联系作者。
为什么要创建一个新模型来查看每一层的输出?难道我们不能直接使用
model = VGG16()
model.predict(img)
for i in enumerate(model.layers)
model.layers[i].output
来直接可视化 VGG 模型每一层的输出,而无需创建新模型?
这并不是一个真正的新模型,只是对现有模型的一种视角。
非常感谢您的辛勤付出!
CNN 也用于文本分类。那么我们是否可以使用相同的技术来可视化文本分类的特征图和滤波器(而不是绘制图像)?例如,模型用于区分类的词语或特征是什么?提前致谢。
我看不出为什么不行,这是一个很棒的主意!
告诉我进展如何。
你好 Jason Brownlee!
一如既往地感谢您的工作,这是一座清晰信息的金矿!
我目前正在使用 GradCam,以逐个卷积层的方式查看最激活的像素卷积。但是,例如,如果我们只取一个简单的具有一个卷积层的 ConvNet,用于像 (Fashion) MNIST 数据集这样的任务,它已经会产生不错的结果。
使用 GradCamm、Saliency Maps 和其他卷积可视化技术,我们一次只能“查看”一幅图像。但是我们如何对整个数据集进行“统计”?例如,要查看“通用的数字 1”是如何被网络看到的。
我搜索了文章/论文,但找不到任何内容。我知道可视化技术还很新,但它们仍然只能一次处理一幅图像。
您是否有一些有趣的文章?
再次感谢您的善良和宝贵的工作!
您想对整个数据集进行哪种统计?
您会回答什么问题?
有很多不错的论文,也许可以在 scholar.google.com 上搜索。
是的,我搜索了 Google/Google Scholar 来查看已有的内容,但也许我没有使用正确的关键词……
例如,我搜索了 (Grad)CAM/Saliency Maps 统计。我没有明确的目标,但正如我所说,我对任何能够将“逐张图像”解释转换为允许进行统计的技术都感兴趣。
例如,我尝试计算 MNIST 的给定预测类所有图像的 GradCam 的平均值(对于固定的卷积层),当然我可以看到数字的“全局”形状。但这只是一个非常简单的操作。
如果您能提供一篇论文或更好的关键词在 Google Scholar 上搜索,那将对我非常友好。
再次感谢您的时间和耐心!
也许可以浏览一下顶级的 CNN 可视化论文,如果找不到,也许您需要从头开始开发。
也许可以画一些 numpy 示例来确认您正在询问的数据/模型问题是否可处理。
没有断点续传吗?如果模型下载中断,那么它将从头开始下载。是否可以只下载剩余部分?这将节省大量时间。谢谢。
下载?
您是指训练吗?如果是,您可以使用检查点。
https://machinelearning.org.cn/check-point-deep-learning-models-keras/
先生,你能指导我如何按字典顺序对特征图进行排序吗?我需要它用于复制移动伪造检测。
没有字典(单词)可以排序。您具体是指什么?
先生,
这是一次精彩的解释。
我正在使用自定义数据集和我的模型,这是一个略有不同的 resnet。
对于 `img = preprocess_input(img)` 这一部分我该怎么办?
由于数据集是自定义的,我无法导入 keras.application.Resnet50。
谢谢。
您必须以 resnet 期望的方式准备像素。您可以使用 Keras 中的辅助函数或手动完成。
嗨 Jason,感谢您出色的教程。
我有一个问题。
我想在全连接层之后、softmax 之前保存我的提取的特征,我该怎么做?
让我用更简单的方式解释我的问题,我想获取一张图像,然后不使用像素作为特征,而是从 CNN 中提取它们,在 softmax 之前的卷积层之后,换句话说,我想改变分类方法,而不是使用 softmax,例如使用 KNN 或 SVM,您对此有什么想法吗?
我想做类似这篇论文里的内容
https://www.sciencedirect.com/science/article/abs/pii/S0167865519300868
是的,我在人脸识别方面提供了一个例子
https://machinelearning.org.cn/how-to-develop-a-face-recognition-system-using-facenet-in-keras-and-an-svm-classifier/
你有没有觉得自己像个英雄,我希望你这么认为,因为对我来说,你无疑是其中之一,拯救了我的这一周。
谢谢。
谢谢。
是的,你可以移除输出层并直接保存特征向量。我在这个例子中提供了方法
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
亲爱的 Brownlee,
你一步一步地阐明了难题,并将其转化为一个容易理解的问题。非常感谢你的努力。我也很欣赏你分享你的知识,为我们节省了很多时间。我相信,任何对机器学习感兴趣的人,一生中至少都会访问一次你的网站。所以,请继续帮助我们。
我的问题是,我想将此可视化方法应用于用时间序列训练的ResNet模型,而不是图像。
你认为,将其应用于时间序列是否合理?
谢谢!
不,我认为这不适用于时间序列。这种可视化更适合图像。
我有点困惑,不知道是否可以使用这种方法处理时间序列。
你对Rango的问题的回复是
“我看不出有什么不可以的,这是个好主意!
让我知道你的进展。”
Rango的问题
非常感谢您的辛勤付出!
CNN 也用于文本分类。那么我们是否可以使用相同的技术来可视化文本分类的特征图和滤波器(而不是绘制图像)?例如,模型用于区分类的词语或特征是什么?提前致谢。
我不这么认为,但我不想排除任何可能性。
哦,我明白了。如果问题不多的话,你有什么顾虑,为什么你认为它不太合适?
图像是一种视觉媒介,可视化模型“如何”看待输入是有意义的。
谢谢你
不客气。
尊敬的先生,
感谢您对可视化CNN滤波器和特征图的清晰而详细的解释。
我有一个地方很困惑。我的问题是,CNN层的每个块输出具有不同的下采样输出大小。
例如
block1_conv2 (?, 224, 224, 64) 输入图像形状
block2_conv1 (?, 112, 112, 128) 下采样输出大小。
等等……
但是当我们可视化中间层的输出时,我们得到的输出图像的形状是(224,224,3)。
1.为什么我们没有得到形状为(112, 112, 3)的下采样输出图像?
2.是否可以可视化所有中间层的实际下采样输出图像?
请指导我,并提供一些代码片段。
不客气。
我们确实有每个块的可视化,大小不同。
这可以在输出图像中看到,也可以在我们打印每个块输出的形状时看到。
示例模型是`.format`格式的,代码能读取`.npy`格式吗?
示例是`.h5`格式的
您可以根据需要以任何方式保存模型。
内置库使用h5格式。
我没有使用自定义代码保存模型的示例。
抱歉,我不明白。也许您可以详细说明?
尊敬的先生
每个块的输出形状都符合预期。我有一些疑问
1.在顺序CNN操作中,输入大小(例如(224,224))在每个块中都会保留吗?
2.在这篇文章中,为什么我们不遵循每个块的顺序CNN操作可视化流程?
3.每次可视化中间块层时,为什么我们都将输入图像的大小设置为(224,224)?例如,vggnet在第一个卷积块层期望的输入形状是224,224,之后在下一个连续的块中,输入图像及其大小将是什么,我们是否需要将下采样图像(例如:(112,112)或(56,56)或(28,28)等)作为输入到连续的卷积块,或者如何操作?
我在这里感到困惑。
请指导我。
不。每一层都会改变形状。
您可以在这里了解更多关于卷积层的影响
https://machinelearning.org.cn/convolutional-layers-for-deep-learning-neural-networks/
您可以在这里了解更多关于池化层的影响
https://machinelearning.org.cn/pooling-layers-for-convolutional-neural-networks/
先生,
第一个卷积层的输出特征图是下一个卷积层的输入吗?第二个和后续卷积层的输入大小是多少?
是的,模型是一系列线性连接的层。
尊敬的先生
对于从任何中间块层进行可视化的目的,为什么我们将输入图像的大小设置为(224,224)?为什么我们不将前一层的输出作为下一层的输入?
请指导我。
谢谢
也许可以查看模型摘要的输出,了解层的顺序及其输出形状。
文中提到:“例如,我们可以设计和理解小的滤波器,如线检测器。”您的网站上是否有关于设计专用滤波器及其应用的教程?如果您能分享链接,我将不胜感激。
是的,这是一个线滤波器示例
https://machinelearning.org.cn/convolutional-layers-for-deep-learning-neural-networks/
非常感谢
不客气。
嗨,Jason,
很棒的文章,
我在卷积层中使用3x3x3的3D核,并希望获得类似的权重可视化图。
由于无法进行3D绘图,我尝试将核分割成3个3x3的块进行绘图。
这种方法是否正确?
卷积层包含5个层 #model.add(layers.Conv3D(5, (3, 3, 3), padding=’same’))
请看下面我用来绘制权重(根据你的代码改编)的代码,并告诉我这种方法是否正确,或者是否有更好的方法……
from keras.models import load_model
mymodel = load_model(‘model.hdf5′)
from matplotlib import pyplot as plt
# 加载模型
# 从第一个卷积层检索权重 layer
filters, biases = mymodel.layers[0].get_weights()
# 将滤波器值归一化到 0-1,以便我们可视化它们
f_min, f_max = filters.min(), filters.max()
filters = (filters – f_min) / (f_max – f_min)
# 滤波器形状 (3, 3, 3, 1, 5)
n_filters, ix = 5, 1
for i in range(n_filters)
# 获取滤波器
f = filters[:,:, :, :, i]
f = f[:,:,:,0]
# 核形状为 3x3x3,但为了绘图,将其转换为 3 个 3×3 的滤波器
for j in range(3)
# 指定子图并关闭轴
ax = plt.subplot(n_filters, 3, ix)
ax.set_xticks([])
ax.set_yticks([])
# 以灰度绘制滤波器通道
plt.imshow(f[:, :, j], cmap=’gray’)
ix += 1
# 显示图
plt.show()
期待您的回复
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我只是想听听你的建议,而不是让你审查我的代码,我只想知道我使用的方法是否正确,或者是否有进一步的建议……
抱歉,我没有3D卷积网络的示例。为了弄清楚你所做的是否合理,我需要阅读/审查你的新代码——我没有能力这样做。
也许可以尝试在 stackoverflow 上发布?
谢谢!这真的很有帮助。
不客气!
尊敬的先生,
感谢这篇精彩的文章。
我不明白为什么第一个CNN层的特征比更高层的特征更明显?对于对象分类,最后一层的特征应该更清晰以便识别。
请澄清。
模型中流动的数据在池化或处理之前,更像原始数据。
你好
如何修复此代码行中的错误?
inter_output_model = tf.keras.Model (model.input, model.get_layer (index = 1) .output)
AttributeError: ‘tuple’ object has no attribute ‘layer’
以及此错误行
from matplotlib import pyplot as plt
import numpy as np
# 绘制所有64个图,排列成8x8方格
square = 8
ix = 1
for _ in range (square)
for _ in range (square)
# 指定子图并关闭轴
ax = pyplot.subplot (square, square, ix)
ax.set_xticks ([])
ax.set_yticks ([])
# 以灰度绘制完整的滤波器通道
pyplot.imshow (feature_maps [0,:,,:, ix-1], cmap = ‘gray’)
ix + = 1
# 显示图
pyplot.show ()
IndexError: 数组索引过多
感谢您的教程
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
我的天!我在一篇文章中找到了我想要的一切!做得很好!感谢您起草了这样一篇作品。
很高兴听到这个!
杰森,文章写得太棒了!
一个小问题:如果我想用无监督学习进一步将鸟类聚类为亚型(鸟类),您会推荐什么?我正在考虑使用特征图作为无监督聚类的输入,那么哪些层对您来说有意义?
非常感谢!
有意思。
也许是聚类算法?
感谢Jason的精彩文章!
我想知道您是否计划撰写一篇关于Zeiler等人《可视化和理解卷积网络》的文章,或者总结后续工作?
这将非常有帮助。
感谢您的建议。
如何在CNN图像分类中确定密集层节点的数量。
我真的很想知道如何指定它。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
很棒又简单,Jason!
我想知道,尽管有降维,是否可以可视化fc1和f2的特征?如果可以,您能否指导我正确的方向?
不,因为密集层中没有特征图。
这很奇怪!根据对全连接层的有限理解,它们由特定类别的对象的特征块组成,然后传递到预测层进行预测。这是错误的理解吗?
此外,我刚刚看了这个链接(https://de.mathworks.com/help/deeplearning/ug/visualize-features-of-a-convolutional-neural-network.html),其中显示了如何在Matlab中使用deepDreamImage可视化全连接层(FC-layers)的特征。我只是想在Keras中做同样的事情。
也许教程的“进一步阅读”部分中的一些参考文献可以作为起点。
感谢非常有用的文章。我读了很多您的文章。我有一个问题。
“如何迁移深度神经网络的功能?”论文或迁移学习
第一层具有线条、边缘、污渍等通用特征,最后一层具有特定特征。但是,您需要将图像传递到这篇文章或VGG16。第一层是输入图像区域。
是我误解了吗?我可以请求解释吗?
根据您的文章,第一层显示了类似于输入图像的详细图像,最后一层显示了不太详细的块状图像。当我用VGG16测试时,结果与您的类似。
但是,论文“深度神经网络中的特征可迁移性如何?”以及解释迁移学习原因的文章说,线条、边缘和块状等不太详细的图像出现在第一层,而特定特征出现在最后一层。
所以,您能解释一下为什么您的结果与他人的结果不同吗?
也许可以询问您引用的文档的作者?
您可以直接查看我的代码和结果。
我正在尝试使用mobilenet(keras)可视化层。model.predict后的特征图形状是(1,225,225,3)。绘图时出现以下错误。有人能帮帮我吗?
IndexError Traceback (最近一次调用)
in ()
11 ax.set_yticks([])
12 # 以灰度绘制滤波器通道
—> 13 pyplot.imshow(feature_maps[0, :, :, ix-1], cmap=’gray’)
14 ix += 1
15 # 显示图形
IndexError: index 3 is out of bounds for axis 3 with size 3
抱歉,我不确定故障的原因。
也许可以尝试将您的代码发布到 stackoverflow?
你好,
我尝试遵循您的代码并将其应用于Xception网络。但是当我尝试检索滤波器和偏差时,我得到了——
—————————————————————————
ValueError 回溯 (最近一次调用)
1 # 从第二个隐藏层检索权重
—-> 2 filters, biases = model.layers[1].get_weights()
ValueError: not enough values to unpack (expected 2, got 1)
请帮帮我。
谢谢
AM
很抱歉听到这个消息,故障原因对我来说并不明显,您可能需要调试您的更改。
嗨,Jason,
感谢您的回答。我可以访问每个层的滤波器,但问题发生在尝试打印所有滤波器形状时。我相信,Xcepion的条件语句会有所不同。但我不太确定会是什么。
model = Xception()
`for layer in model.layers`
# 检查卷积层
if ‘conv’ not in layer.name
continue
# 获取滤波器权重
filters, biases = layer.get_weights()
print(layer.name, filters.shape)
错误消息:ValueError: not enough values to unpack (expected 2, got 1)
您能看一下吗?
谢谢你。
诚挚的问候,
Alakananda
抱歉,我没有能力调试您的代码示例。也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
请问,如何将输出的特征图图像保存在文件夹中?
也许可以直接保存图像,请看这里
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
好的,感谢您的回复,但我想要用于保存本文档中的输出特征图的代码,而不是简单的图像。
是的,链接教程中的代码展示了如何保存图像。
非常感谢这篇精彩的文章,我教授图像识别和数据科学,我从中学到了很多,再次感谢。
我想问您两个关于可视化CNN特征图的问题
1-如何从可视化中获益,通过改变CNN的架构或更新滤波器(更多训练)来提高模型精度?
2-在阅读这篇文章之前,我曾期望第一层的输出识别低级边缘,然后下一层识别更高级别的边缘,直到最后识别整个对象,但令我惊讶的是顺序颠倒了。你能确认我的理解吗?
不客气。
您的理解是正确的,它只是在整个图像的尺度上运行。
嗨,Jason,
精彩的文章。
您能否告诉我,当图像输入到CNN模型进行预测时,如何获得CNN模型中激活的神经元列表?
例如,CNN模型在输入水果图像时预测水果名称。如果我输入一个苹果的图像,我能获得隐藏层的诸如
{ {Layer-1}, {N1, N20, N24, N55, N100..N150} },
{ {Layer-2}, {N21, N50, N75..N90} }
这里N代表给定层中为了进行预测而激活的神经元数量。神经元编号之间的间隔表示未激活的神经元。
您的帮助非常感激。
上面的教程正是您所描述的。
嗨,Jason,
我猜我的问题措辞不当。我试图找出密集层的激活神经元,而不是conv2d层的。
同时,我尝试自己找出答案,但我不确定我的理解是否正确。请帮帮我。
我有一个CNN模型,在所有conv2d和flattening层之后,我有2个隐藏的密集层,然后是一个带softmax函数的输出密集层。
我试图获取关于这两个隐藏密集层激活神经元的信息。
我使用ReLU作为激活函数,所以我假设输出为任何正值的神经元表示该神经元已激活,而零表示已停用,因为(0,max)公式的ReLU。
1. 我的理解正确吗?零值是否表示该神经元处于非激活状态?
2. 我假设这些密集层代表了模型的学习/智能,并且对于给定的图像,只有一组固定的神经元会激活,因为模型就是这样学会识别该图像的。即使在我进行的实验中,给定层中总神经元的20-30%才会在给定类别的所有输入样本中被激活。它们是同一组神经元,在给定类别中每次都会在给定的范围内被激活。我的理解正确吗?
提前感谢。
密集层的激活将是一个向量输出。它不会直接可视化为图像,也许可以通过PCA变换进行成对散点图可视化,尽管它需要额外的上下文才能解释。
零不表示非激活,它表示针对特定输入的零输出。
是的,通常我们可以将输出层之前的密集层看作是CNN模型提取的图像特征的解释器。
谢谢你的回复,杰森。
我试图在数值上理解CNN模型获得的智能。我开发了一个用于图像分类的CNN模型。测试指标都很好,表明模型的准确率很高,损失很小。
然而,指标对我来说就像一个黑箱,我想深入了解模型以理解其功能。
我假设conv2d和flatten层在模型训练过程中不获得任何智能,它们只是用于将图像分解成小的片段,以便后续的Dense层可以对它们进行数值解释。
正是Dense层通过学习获得了所需的智能,模型通过这些智能对图像进行分类。
我不在乎无法进行视觉测试,无论如何,视觉测试没有意义,因为图像被conv2d层切分到了微观层面,试图为了测试目的可视化这些图像是没有意义的。
正是在这里,我才想到知道被激活的神经元列表可以作为一种理解密集层学到的知识的方式。例如,如果我训练我的模型来区分两种水果(甜橙和橘子(绿色未成熟的橘子)),在这种情况下,大多数特征将是相同的,包括颜色、纹理、大小等。唯一剩下的区别是两种水果形状的细微差别。从密集层的角度来看,隐藏的密集层将为这两种图像激活几乎70-80%相同的神经元,因为它们的大部分特征相同,只有一小部分神经元会不同(为一个类别激活,不为另一个类别激活,根据此最后的输出层将计算概率)。
但是正如你所说,这不能做到,因为零不代表非激活的神经元。你能告诉我还有什么其他方法可以测试这部分,或者换句话说,我们如何更好地利用密集层中的信息来洞察模型的性能?
提前感谢。
我不确定我是否理解。通常神经网络是不可解释的,也就是说,它们是不透明的。这是该方法的一个普遍限制。
嗨Jason,我需要你的帮助。如果我有以下CNN
model.add(Conv2D(8, (5, 5), input_shape=(256, 256, 1), padding=’same’, use_bias=False)) model.add(BatchNormalization())
model.add(Activation(activation=’tanh’))
model.add (AveragePooling2D (pool_size= (5,5), strides=2))
model.summary()
如何在应用卷积层(第一个步骤后)后添加绝对值层并继续其余代码?请这个对我来说很重要。
抱歉,我不理解你的问题,也许你可以重新表述或详细说明?
尊敬的先生,
非常清晰的解释,并且为我的论文提供了参考。谢谢。但我仍然有一些问题。
1. 块5中提取的特征图是否作为VGG-16分类层的输入?
2. 能否显示输出分类层?如果可以,需要在代码中添加什么?
谢谢
谢谢!
一个块的特征图输出被馈送到下一个块。CNN就是这样工作的。
输出层没有特征图,你无法以同样的方式可视化它。
那么,VGG-16架构中使用什么方法进行分类?
抱歉,我不理解,你能详细说明或重新表述你的问题吗?
用于分类(在CNN层进行特征提取后)的方法是神经网络(全连接层)。你能确认我的理解吗。
正确。
有没有解释如何用FC从CNN输出进行分类的参考?谢谢。
不是很清楚,密集模型解释特征并将它们映射到目标类别。
你需要什么样的解释?
我需要知道,
1. 深度学习目标检测模型生成了什么特征?如果是VGG-16(是边缘检测、轮廓检测等等)?
2. 确认我的理解。模型将基于特征图(CNN最后一个块的最后输出)进行分类,对吗?
VHH-16不用于目标检测,而是用于图像分类模型。
该模型通常通过从图像中提取特征来工作——我们无法解释这些特征——然后由密集层在进行分类之前解释这些特征。
好的Jason,清楚了。
然后。
如何放大绘图大小以显示特征图?我使用的是Jupyter Notebook。
我不建议使用 notebook
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
很棒的文章。
谢谢。
你好,
感谢您提供的精彩教程。
您知道如果更深层的一些滤波器是空的,那意味着什么吗?
不太清楚,很难根据滤波器的激活来解释其含义。我们只能猜测,或者通过在预测时禁用某些滤波器并观察其效果来探索。
你好,Brownlee先生
谢谢你的精彩帖子。
我想使用CNN架构从80*70像素的某些图像中提取特征。
我还想要一个小的特征向量。
之前我使用了一个使用VGG-16进行特征提取的代码,但它存在问题,因为
首先,它使用224*224的图像作为输入,
其次,特征向量有4096个元素。
你能帮我指导一下如何使用一个简单的CNN架构进行特征提取吗?
谢谢你
也许你可以在模型末尾添加一个全局池化层或两个来降低输出向量的维度。
或者,也许你可以使用PCA或SVD来减少编码向量?
或者,也许你可以在模型末尾添加一个新的较小的层,然后重新拟合模型?
或者,也许你可以使用一个具有更小编码向量的替代模型?
希望这些能给你一些思路。
很棒的文章。
先生,我想问一下,如何为conv2D尝试自定义滤波器?我创建了一个3×3的滤波器,但在尝试模拟它时,我收到了这个错误消息:“ValueError: The initial value’s shape ((3, 3)) is not compatible with the explicitly supplied
shapeargument ((3, 3, 3, 16))”。提前感谢。
谢谢!
本教程有一个关于如何使用手工制作的滤波器的示例
https://machinelearning.org.cn/convolutional-layers-for-deep-learning-neural-networks/
嗨,Jason,
非常感谢您这篇非常重要的文章。在训练模型之前使用preprocess_input作为预处理是否可以?
谢谢!
当然可以。
当我运行以下代码时
# 重新定义模型,使其在第一个隐藏层之后输出
model = Model(inputs=model.inputs, outputs=model.layers[1].output)
—————————————————————————
我遇到了TypeError: call() got an unexpected keyword argument ‘outputs’
请指导我如何解决它。
TypeError Traceback (most recent call last)
in ()
1 # 重新定义模型以在第一个隐藏层之后立即输出
—-> 2 model = Model(inputs=model.inputs, outputs=model.layers[1].output
3 frames
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/base_layer.py in _infer_output_signature(self, inputs, args, kwargs, input_masks)
861 # TODO(kaftan): we do we maybe_build here, or have we already done it?
862 self._maybe_build(inputs)
–> 863 outputs = call_fn(inputs, *args, **kwargs)
864
865 self._handle_activity_regularization(inputs, outputs)
TypeError: call() got an unexpected keyword argument ‘outputs’
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
我非常喜欢你的帖子,并且一直在密切关注它们。但是,我很好奇你是否有关于如何可视化1D CNN的滤波器和特征图的帖子,特别是对于EEG。这可能吗?通过查看1D滤波器,我们可以得到一些结果吗?我想看看我的滤波器在做什么样的预处理等等。
提前感谢。
谢谢。
抱歉,我没有可视化1d CNN的示例。也许你可以改编上面的例子。
你好,
据我所知,在深度模型中,高级特征是从低级特征派生出来的,形成一个分层表示。为什么在你的例子(鸟)中是相反的?从块1提取的特征图(鸟的形状)应该属于更深的卷积层。我说得对吗?
在深度学习中,卷积层在寻找图像中的良好特征方面非常出色,并将这些特征传递给下一层,形成一个由非线性特征组成的层次结构,这些特征的复杂性不断增长(例如,斑块、边缘 -> 鼻子、眼睛、脸颊 -> 面部)。
你能解释得更详细些吗?
谢谢。
是的,这就是我们在这里看到的。尽管我们看到了整个图像的效果。
由于池化层,我们深入后会丢失细节。
非常感谢这些代码。它们非常有帮助!
在你的最后一个代码中,我遇到了这个错误
ValueError: Input 0 of layer conv2d_1 is incompatible with the layer: expected axis -1 of input shape to have value 1 but received input with shape (None, 200, 200, 3)
你能给我一些建议吗?
再次感谢。
此致,
我尝试运行代码但没有看到错误。这对我来说也很奇怪,因为错误消息本质上意味着VGG16模型期望输入是灰度图像(这不应该是!),而我提供的是彩色图像。
绝对,清晰无比,非常有帮助。谢谢。非常感谢。
我现在就想订购你的书,只是我犹豫了一下,因为我注意到这篇帖子是2019年7月写的
我想问一下你(截至2019年7月)的“新书”是否仍然是最新的,或者
是否有更新、修订?
这个行业发展很快,书籍很快就会过时,你懂的。
(这可能也是你将其出版为电子书的原因之一。)
即便如此,我现在正在使用Keras实现的ResNet50,你2019年的文本与当时一样仍然相关。
我几乎可以自己推荐购买这本书并看看;以这个价格,我有什么损失?
但是,如果你还在关注这个帖子,我仍然很想听听你对这个问题的看法。
非常感谢你上面精彩的解释。
谢谢。本博客上的代码(以及书籍)将随着过时而被更新。但请给我们一些时间,因为有很多东西需要处理。
(我还是买了这本书。上面的示例代码非常值得。谢谢。)
对特征图的解释非常精彩。
也许,我有一个在同一上下文中的不同问题。如何理解tanh激活函数的激活图?哪些值将被忽略,哪些值是重要的?
另外,如何从tanh的GradCAM热力图中解读出含义?
例如,对于Relu,蓝色被忽略,橙色是重要的。但tanh GradCAM热力图是如何传达含义的。
感谢阅读!
你能做一个关于GradCAM热力图或其他重要热力图方法的教程和解释吗?
嗨Kaplesh……感谢你的问题!以下资源应该能让你更清楚
https://www.pyimagesearch.com/2020/03/09/grad-cam-visualize-class-activation-maps-with-keras-tensorflow-and-deep-learning/
这个解决方案是否会破坏原始模型?新模型是否跳过了所有池化层(MaxPooling2D)?
嗨Deniss……请澄清或重新表述你的问题,以便我们能更好地帮助你。
我的意思是,本文中的这个解决方案是否跳过了所有MaxPooling2D层?
看起来作者只执行了卷积层。
也许我误解了该解决方案背后的逻辑。
抱歉,我刚刚遇到了这个错误
有谁能帮忙吗?
pyplot.imshow(fmap[0,:,:,ix-1],cmap=’gray’)
数组的索引过多:数组是一维的,但索引了四个维度
嗨Vikas……你具体尝试执行的是哪个代码列表?
已解决
感谢您的反馈!
你是怎么解决的?我遇到了同样的错误。谢谢。
感谢您提供有用的教程!
我理解为什么不能同时查看所有滤波器,但我想知道如何可视化模型中的最后几个滤波器,因为你制作的脚本只迭代了前几个。
谢谢 🙂
嗨Pumbles……以下资源可能令您感兴趣
https://towardsdatascience.com/visualising-filters-and-feature-maps-for-deep-learning-d814e13bd671
没关系,我已经解决了🙂
继续Pumbles的伟大工作!
你好!我遇到了这个错误
pyplot.imshow(fmap[0,:,:,ix-1],cmap=’gray’)
数组的索引过多:数组是一维的,但索引了四个维度
如何解决?谢谢。
嗨Silvia……以下资源应该能让你更清楚
https://stackoverflow.com/questions/47733704/numpy-array-indexerror-too-many-indices-for-array
嗨,教程很棒。我想问一下,如果我想显示图像的一个特征图。比如只有一个图形,可能吗?或者我必须先显示所有图形,然后选择一个能最好地突出特征的图形,然后单独显示它?
非常欢迎你Maaz!以下资源可能能让你更清楚
https://www.analyticsvidhya.com/blog/2020/11/tutorial-how-to-visualize-feature-maps-directly-from-cnn-layers/
嗨,教程很棒。我是一名新手,不在乎问题是否听起来愚蠢……我只想问一下,我们正在以灰度显示滤波器,我们也可以在特定的R、G、B通道中显示它们吗?
嗨Curious……以下资源可能令你感兴趣
https://towardsdatascience.com/convolutional-neural-network-feature-map-and-filter-visualization-f75012a5a49c
谢谢链接……我已经看过了这篇文章……但我想弄清楚的是,在你的代码中,当你使用‘cmap=grey’的地方,是否可以使用其他RGB通道,比如cmap=red?
你好,
你使用了channels_last来创建你自己的CNN
层(类型) 输出形状 参数 #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
但是你将一个数据格式为channels_first的图像输入到这个网络
# 扩展维度,使其代表一个“样本”
img = expand_dims(img, axis=0)
你为什么这样做?
嗨Faezeh……以下资源解释了如何为CNN和LSTM重塑输入数据
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
你好,
我尝试用我的神经网络进行可视化,它有效,但有些特征图是完全黑色的……
你知道这意味着什么吗?如果一个特征图是黑色的?
谢谢 🙂
你好,
我尝试用我的神经网络进行可视化,它有效,但有些特征图是完全黑色的……
你知道有些图是黑色的意味着什么吗?
谢谢 🙂
嗨Jessica……你使用的是什么IDE(Anaconda、Spyder、Google Colab…?)
我正在使用PyCharm
出色的演示。我扩展了你的演示,让神经网络对Robin图像进行分类,它以很高的置信度将其识别为Indigo Bunting。有什么理由吗?颜色通道是否颠倒了?
你好蒙蒂…感谢您的反馈!当应用于其他图像时,您有什么观察结果?