机器学习模型是根据它们的平均性能选择的,通常使用 k 折交叉验证计算。
平均性能最佳的算法预计会优于平均性能较差的算法。但如果平均性能的差异是由统计上的偶然因素造成的呢?
解决方案是使用 **统计假设检验** 来评估任意两个算法之间的平均性能差异是真实的还是虚假的。
在本教程中,您将了解如何使用统计假设检验来比较机器学习算法。
完成本教程后,您将了解:
- 基于平均模型性能进行模型选择可能会产生误导。
- 对修改后的 Student's t-Test 进行五次重复的两次交叉验证是比较机器学习算法的一个好方法。
- 如何使用 MLxtend 机器学习通过统计假设检验来比较算法。
开始您的项目,阅读我的新书《机器学习统计学》,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

用于比较机器学习算法的假设检验
照片由 Frank Shepherd 拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 比较算法的假设检验
- 5×2 程序配合 MLxtend
- 比较分类器算法
比较算法的假设检验
模型选择涉及评估一套不同的机器学习算法或建模流程,并根据它们的性能进行比较。
然后,根据您的性能指标选择达到最佳性能的模型或建模流程,作为您可以用于在新数据上进行预测的最终模型。
这适用于经典的机器学习算法和深度学习的回归和分类预测建模任务。过程始终相同。
问题是,您如何知道两个模型之间的差异是真实的,而不仅仅是统计上的偶然因素?
这个问题可以通过 统计假设检验 来解决。
一种方法是在数据的同一 k 折交叉验证 分割上评估每个模型(例如,在每种情况下使用相同的随机数种子来分割数据),并为每个分割计算一个分数。这会得到 10 折交叉验证的一个分数样本。然后可以使用配对统计假设检验来比较这些分数,因为每种算法用于得出每个分数的处理(数据行)是相同的。可以使用 配对 Student's t-Test。
在这种情况下,使用配对 Student's t-Test 的一个问题是,每个模型的评估都不是独立的。这是因为相同的数据行被多次用于训练数据——实际上,除了数据行用于保留测试折之外,每次都使用。这种评估中的非独立性意味着配对 Student's t-Test 存在乐观偏差。
可以调整此统计检验以考虑非独立性。此外,还可以配置折数和程序重复次数,以实现对模型性能的良好采样,使其能够很好地推广到各种问题和算法。具体来说,是五次重复的两次交叉验证,即所谓的 5×2 折交叉验证。
这种方法由 Thomas Dietterich 在他 1998 年的论文《Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms》中提出。
欲了解更多关于此主题的信息,请参阅教程
幸运的是,我们无需自己实现此过程。
5×2 程序配合 MLxtend
由 Sebastian Raschka 开发的 MLxtend 库 通过 `paired_ttest_5x2cv()` 函数提供了实现。
首先,您必须安装 mlxtend 库,例如
|
1 |
sudo pip install mlxtend |
要使用该评估,您必须先加载数据集,然后定义要比较的两个模型。
|
1 2 3 4 5 6 |
... # 加载数据 X, y = .... # 定义模型 model1 = ... model2 = ... |
然后,您可以调用 `paired_ttest_5x2cv()` 函数,传入您的数据和模型,它将报告 t 统计量值和 p 值,以确定两个算法的性能差异是否具有统计学意义。
|
1 2 3 |
... # 比较算法 t, p = paired_ttest_5x2cv(estimator1=model1, estimator2=model2, X=X, y=y) |
p 值必须使用 alpha 值来解释,alpha 是您愿意接受的显著性水平。
如果 p 值小于或等于选定的 alpha,我们就拒绝原假设(即模型具有相同的平均性能),这意味着差异很可能是真实的。如果 p 值大于 alpha,我们就无法拒绝原假设(即模型具有相同的平均性能),任何观察到的平均准确度差异都可能是统计上的偶然因素。
alpha 值越小越好,通常的值是 5% (0.05)。
|
1 2 3 4 5 6 |
... # 解释结果 if p <= 0.05: print('平均性能差异可能真实存在') else: print('算法可能具有相同的性能') |
现在我们熟悉了如何使用假设检验来比较算法,让我们看一些例子。
比较分类器算法
在本节中,我们将比较两个机器学习算法在二分类任务上的性能,然后检查观察到的差异是否具有统计学意义。
首先,我们可以使用 make_classification() 函数 创建一个具有 1000 个样本和 20 个输入变量的合成数据集。
下面的示例创建了数据集并总结了其形状。
|
1 2 3 4 5 6 |
# 创建分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=10, n_redundant=0, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结行数和列数,确认了我们的预期。
我们可以使用此数据作为比较两个算法的基础。
|
1 |
(1000, 10) (1000,) |
我们将在此数据集上比较两种线性算法的性能。具体来说,是 逻辑回归 算法和 线性判别分析 (LDA) 算法。
我喜欢的方法是使用重复分层 k 折交叉验证,10 折,3 次重复。我们将使用此过程来评估每个算法,并返回和报告平均分类准确度。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 比较逻辑回归和 LDA 进行二分类 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=10, n_redundant=0, random_state=1) # 评估模型 1 model1 = LogisticRegression() cv1 = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores1 = cross_val_score(model1, X, y, scoring='accuracy', cv=cv1, n_jobs=-1) print('逻辑回归平均准确率: %.3f (%.3f)' % (mean(scores1), std(scores1))) # 评估模型 2 model2 = LinearDiscriminantAnalysis() cv2 = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores2 = cross_val_score(model2, X, y, scoring='accuracy', cv=cv2, n_jobs=-1) print('线性判别分析平均准确率: %.3f (%.3f)' % (mean(scores2), std(scores2))) # 绘制结果图 pyplot.boxplot([scores1, scores2], labels=['LR', 'LDA'], showmeans=True) pyplot.show() |
运行示例首先报告了每个算法的平均分类准确率。
注意:您的 结果可能有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑多次运行示例并比较平均结果。
在这种情况下,如果我们仅查看平均分数:逻辑回归为 89.2%,LDA 为 89.3%,结果表明 LDA 具有更好的性能。
|
1 2 |
逻辑回归平均准确率: 0.892 (0.036) 线性判别分析平均准确率: 0.893 (0.033) |
还创建了一个箱线图,总结了准确度分数的分布。
这个图表支持我选择 LDA 而不是 LR 的决定。
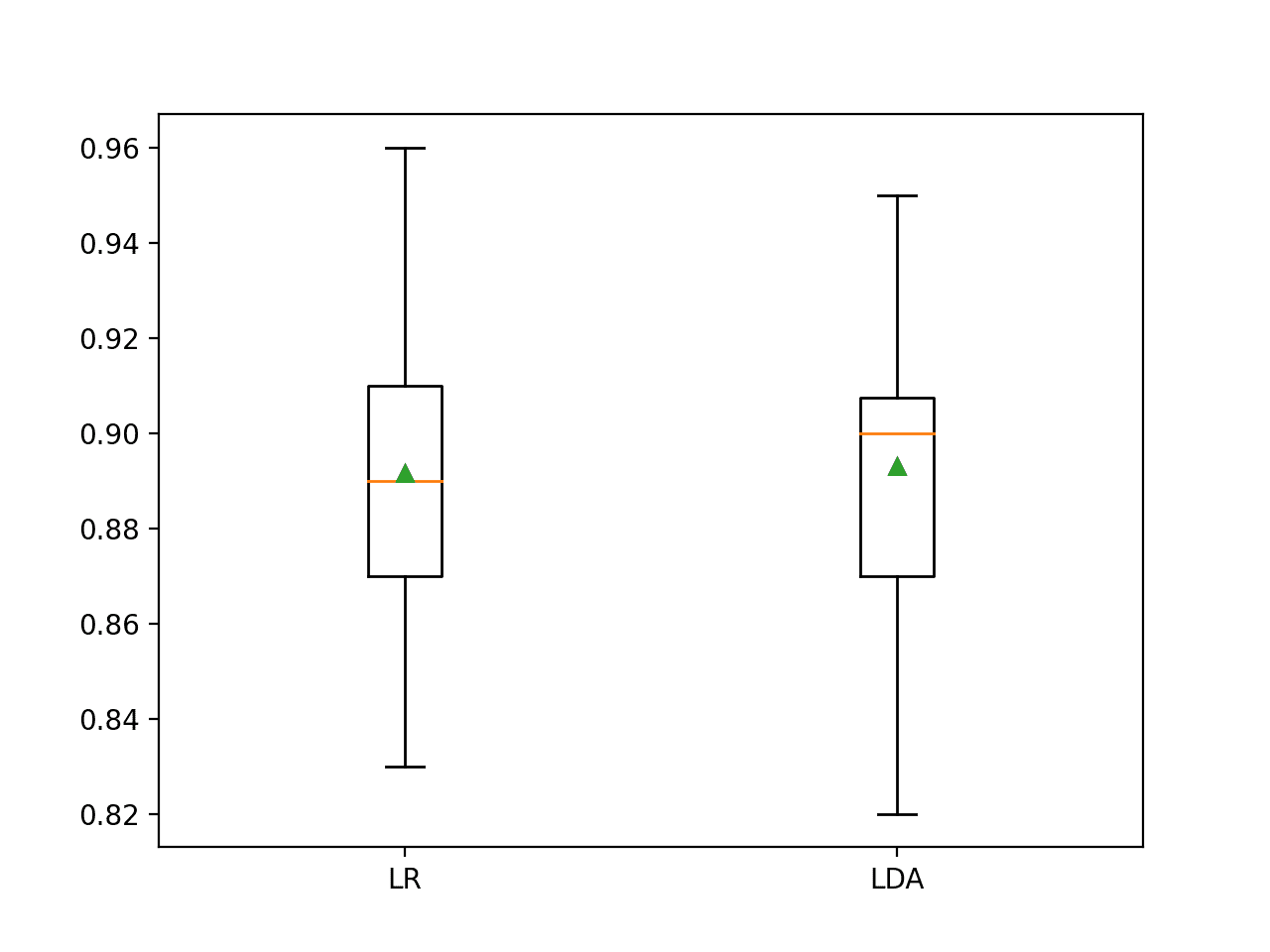
两个算法的分类准确度分数的箱线图
现在我们可以使用假设检验来查看观察到的结果是否具有统计学意义。
首先,我们将使用 5×2 程序来评估算法,并计算 p 值和检验统计量值。
|
1 2 3 4 5 |
... # 检查算法之间的差异是否真实 t, p = paired_ttest_5x2cv(estimator1=model1, estimator2=model2, X=X, y=y, scoring='accuracy', random_seed=1) # 总结 print('P值: %.3f, t统计量: %.3f' % (p, t)) |
然后,我们可以使用 5% 的 alpha 值来解释 p 值。
|
1 2 3 4 5 6 |
... # 解释结果 if p <= 0.05: print('平均性能差异可能真实存在') else: print('算法可能具有相同的性能') |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 使用 5x2 统计假设检验程序比较两个机器学习算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from mlxtend.evaluate import paired_ttest_5x2cv # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=10, n_redundant=0, random_state=1) # 评估模型 1 model1 = LogisticRegression() cv1 = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores1 = cross_val_score(model1, X, y, scoring='accuracy', cv=cv1, n_jobs=-1) print('逻辑回归平均准确率: %.3f (%.3f)' % (mean(scores1), std(scores1))) # 评估模型 2 model2 = LinearDiscriminantAnalysis() cv2 = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores2 = cross_val_score(model2, X, y, scoring='accuracy', cv=cv2, n_jobs=-1) print('线性判别分析平均准确率: %.3f (%.3f)' % (mean(scores2), std(scores2))) # 检查算法之间的差异是否真实 t, p = paired_ttest_5x2cv(estimator1=model1, estimator2=model2, X=X, y=y, scoring='accuracy', random_seed=1) # 总结 print('P值: %.3f, t统计量: %.3f' % (p, t)) # 解释结果 if p <= 0.05: print('平均性能差异可能真实存在') else: print('算法可能具有相同的性能') |
运行示例,我们首先评估算法,然后报告统计假设检验的结果。
注意:您的 结果可能有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 p 值约为 0.3,远大于 0.05。这导致我们无法拒绝原假设,表明算法之间观察到的任何差异可能都不是真实的。
我们可以选择逻辑回归或 LDA,平均而言,两者表现都差不多。
这凸显了仅基于平均性能进行模型选择可能不足够。
|
1 2 3 4 |
逻辑回归平均准确率: 0.892 (0.036) 线性判别分析平均准确率: 0.893 (0.033) P值: 0.328, t统计量: 1.085 算法可能具有相同的性能 |
回想一下,我们使用与用于估计统计检验中性能的过程(5×2 CV)不同的过程(3×10 CV)来报告性能。也许如果我们查看使用五次重复的两次交叉验证的分数,结果会有所不同?
下面的示例已更新,使用 5×2 CV 为两种算法报告分类准确度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 使用 5x2 统计假设检验程序比较两个机器学习算法 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from mlxtend.evaluate import paired_ttest_5x2cv # 定义数据集 X, y = make_classification(n_samples=1000, n_features=10, n_informative=10, n_redundant=0, random_state=1) # 评估模型 1 model1 = LogisticRegression() cv1 = RepeatedStratifiedKFold(n_splits=2, n_repeats=5, random_state=1) scores1 = cross_val_score(model1, X, y, scoring='accuracy', cv=cv1, n_jobs=-1) print('逻辑回归平均准确率: %.3f (%.3f)' % (mean(scores1), std(scores1))) # 评估模型 2 model2 = LinearDiscriminantAnalysis() cv2 = RepeatedStratifiedKFold(n_splits=2, n_repeats=5, random_state=1) scores2 = cross_val_score(model2, X, y, scoring='accuracy', cv=cv2, n_jobs=-1) print('线性判别分析平均准确率: %.3f (%.3f)' % (mean(scores2), std(scores2))) # 检查算法之间的差异是否真实 t, p = paired_ttest_5x2cv(estimator1=model1, estimator2=model2, X=X, y=y, scoring='accuracy', random_seed=1) # 总结 print('P值: %.3f, t统计量: %.3f' % (p, t)) # 解释结果 if p <= 0.05: print('平均性能差异可能真实存在') else: print('算法可能具有相同的性能') |
运行示例报告了两种算法的平均准确率以及统计检验的结果。
注意:您的 结果可能有所不同,因为算法或评估过程的随机性,或数值精度的差异。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到两种算法的平均性能差异更大,逻辑回归为 89.4%,LDA 为 89.0%,这与 3×10 CV 的情况相反。
|
1 2 3 4 |
逻辑回归平均准确率: 0.894 (0.012) 线性判别分析平均准确率: 0.890 (0.013) P值: 0.328, t统计量: 1.085 算法可能具有相同的性能 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
论文
- 用于比较监督分类学习算法的近似统计检验, 1998.
API
总结
在本教程中,您了解了如何使用统计假设检验来比较机器学习算法。
具体来说,你学到了:
- 基于平均模型性能进行模型选择可能会产生误导。
- 对修改后的 Student's t-Test 进行五次重复的两次交叉验证是比较机器学习算法的一个好方法。
- 如何使用 MLxtend 机器学习通过统计假设检验来比较算法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。



")



谢谢分享!!
另一个可能的选择是通过 BEST 进行贝叶斯方法
https://best.readthedocs.io/en/latest/
感谢分享!
真的很好……对于那些没有 proper 知识的人来说很容易理解。我是一名统计学副教授,在一家享有盛誉的理学院工作。
谢谢!
尊敬的Jason博士,
我已将上述准确率扩展到 https://machinelearning.org.cn/calculate-the-bias-variance-trade-off/#comment-550512 中使用的模型。也就是说,我已经将该网站和本网站的模型进行了成对组合,并产生了以下结果。
这包含统计上显著和不显著的比较
统计学上显著的模型是
结论
在统计学上显著的模型中,SVC的准确率为0.952,高于LDA的0.894。P值为0.003。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
抱歉,我忘记考虑SVC和KNeighborsClassifier的比较,它们的平均值为0.952和0.942,P值为0.028,是显著的。
进一步结论
尽管SVC和KNeighborsClassifier之间的准确率差异很小,但对于由X和y组成的特定数据集,SVC似乎是最适合的方法。
因此,如果有人要为给定的数据集X、y做预测,SVC很可能是首选模型。
谢谢你,
悉尼的Anthony
很好,谢谢分享。
干得好!
展示成对假设检验的一个好方法是使用一个矩阵,算法沿着两个轴排列,并在矩阵的每个单元格中显示显著的真/假值。
尊敬的Jason博士,
谢谢你的回复。
当你说“展示成对假设检验的一个好方法是使用一个矩阵”时,你能详细说明一下吗?你是指成对箱线图,还是散点图对?
是否存在一个散点图矩阵,可以让你从散点图切换到成对箱线图的比较?
谢谢你,
悉尼的Anthony
不,不是图,而是一个矩阵或表格,其中包含指示每对算法之间是否存在显著差异的真/假值。
然后可以查看每种算法的实际平均值,并忽略其余部分。
也可以使用一对列表。
尊敬的Jason博士,
谢谢你。
你是指这样的表格吗
请指教。
谢谢你,
悉尼的Anthony
我不这么认为。那是我博士时期做的事情。
尊敬的Jason博士,
请扩大上述“表格”的显示范围,它显示了
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
对程序的一项修改产生了以下列表
你的意思是像上面那样的东西吗?
如果是这样,有没有办法以一种美观的方式显示文本,使文本对齐得很好?
谢谢你,
悉尼的Anthony
干得好!
尊敬的Jason博士,
这是使用“prettyable”包的文本图输出,来自https://pypi.ac.cn/project/PrettyTable/
一些演示实现的示例代码
输出 – 将鼠标悬停在此输出的顶部以查看完整视图,从而扩展页面宽度。
谢谢你,
悉尼的Anthony
太棒了。
Weka 似乎也这样做,并为主平均值添加了一个*,以使表格更容易扫描。
尊敬的Jason博士,
上面的表格是ASCII文本表格。下面的两个是使用plotly和matplotlib实现的图形。
谢谢你,
悉尼的Anthony
太棒了!
尊敬的Jason博士,
你提到“……我相信Weka也是这样做的,并且会在较大的数字旁边添加一个*,使表格更容易扫描。”
我花了两分钟额外修改了python中的代码。
这是结果
谢谢你,
悉尼的Anthony
Anthony,这真是太棒了!
尊敬的Jason博士,
上面的表格使用了prettytable包。
不幸的是,你无法使用prettytable包添加标题。
如果你想添加一个标题,就像下面的表格一样
使用pytable包。首先卸载prettytable,然后安装pytable。
在你的python程序中,像导入prettytable一样导入ptable包。
在这个例子中,你添加了另一行
代码如下:
谢谢你,
悉尼的Anthony
干得不错。
尊敬的Jason博士,
从我对你关于比较模型得分的教程的改进中,我展示了如何制作一个表格,列出一模型与另一模型之间存在显著关系的列表。
本教程展示了比较模型时的得分箱线图。
在不展示完整代码的情况下,我将重点介绍使用matplotlib、matplotlib和seaborn(它使用matplotlib)绘制箱线图数据的核心内容。请注意,我没有意外地写两次matplotlib。有两种方法。
我将把这个与教程联系起来。
假设包已在程序顶部声明。
这被呈现为一种“概念性”方法,但没有细节。
首先是matplotlib,其中subplots使用行数和列数进行实例化。
这使用了matplotlib:比较这两个示例中subplots的实例化差异。
本示例使用seaborn和matplotlib。
seaborn中的箱线图需要 (i) 一个DataFrame,以及 (ii) 将model1和model2这两个变量重塑为一个数组。seaborn中的箱线图做到了这一点,但不是。
Seaborn 的 boxplot 需要两个变量:一个用于识别 model1 和 model2 的分类变量,以及另一个包含 model1 和 model2 值堆叠的数组。
单独的分类变量和值数组的生成是通过 pandas 的 melt 和 DataFrame 函数自动完成的。
一个加分项。
您可以结合使用 DataFrame 和 melt 方法来生成一个与另一“数组”数据关联的分类变量数组。
分类变量是在初始化 DataFrame 时派生的。
谢谢你,
悉尼的Anthony
干得好,感谢分享!
嗨,Jason,
这是一篇非常有意思的文章,对我的博士论文工作帮助很大,非常感谢。
我想请教一下,如果我想在多个数据集上测试多个机器学习算法,您会给出什么建议?
我正在考虑通过交叉验证来测试每个数据集,然后得到每个机器学习算法的结果表,以便进行假设检验。下面是一个示例表格,展示了各种机器学习算法的标准RMSE。
数据集 | GP1 | GP2 | ANN | 线性回归
Ishigami | 0.21 | 0.16 | 0.19 | 0.32
Sobol | blah | blah | blah | blah
....
....
等等。
那么,在这种情况下,是否有推荐的假设检验方法来比较回归技术?您是否推荐任何文献让我进一步研究?您对此类分析有什么看法?
我的问题是,我发现的大部分文献都是将两种机器学习技术作为最佳,但只针对一个数据集。而我想为多个数据集找到一个总体上更好的技术。
谢谢,
Aaron
也许是所有情况之间的成对检验。
你好 Aaron,我希望你现在已经找到了答案,但我可以分享一本非常棒的书,它深入探讨了这个领域,那就是:“Evaluating Learning Algorithms A Classification Perspective”,作者是“NATHALIE JAPKOWICZ, University of Ottawa”和“MOHAK SHAH, McGill University”。
希望这个参考能帮助你和其他人解决这些问题。
有人知道如何计算这种检验的功效吗?🙂
这篇教程中的参考文献或许能帮到你
https://machinelearning.org.cn/statistical-power-and-power-analysis-in-python/
嗨,Jason,
感谢您的文章!确实非常有帮助!
我能问一下,在使用大型数据集时,您建议使用什么方法?交叉验证会非常耗时,所以也许有什么其他方法可以考虑?
谢谢,
Laura
对于非常大的数据集,也许可以采用 train/test split 和 McNemar 检验
https://machinelearning.org.cn/mcnemars-test-for-machine-learning/
当模型在同一个 train/test split 上训练了 k(例如 5)次时(这是一个基准测试),是否有推荐的检验方法?这不完全是交叉验证(数据分割没有变异性),而是由于模型本身的随机性而产生的多次运行。
当我进行这个测试时,我应该在测试之前对数据进行预处理,还是没有必要?
没必要。
如果我比较 ML 和 DL 分类器,DL 中的 cross val score 是如何编写的?
也许你可以使用标准的测试框架,如交叉验证。
https://machinelearning.org.cn/repeated-k-fold-cross-validation-with-python/
你好,我偶然发现了这篇论文,它似乎与你的文章非常相似。我不知道它是否是抄袭的,但想提请你注意。
https://www.spu.edu.iq/kjar/index.php/kjar/article/view/630/333
感谢 Shruti 的反馈!
你好 Jason。只有一个小问题。你为什么定义 cv 和 cv2?这是否意味着这两个模型将在不同的数据分割中进行训练和评估?如果只使用一个 cv 是否是错误的?
我也只用了一个。
你好 Jason,感谢你这篇精彩的文章。我想问一个关于比较两个深度学习模型(如 u-net 和 attention u-net)的问题。是否可以将数据集固定(添加 10% 的数据用于测试,其余用于训练),然后在固定数据集上使用一组相同的超参数训练这两个模型?然后,对获得的结果使用假设检验?
你好 Carol…非常欢迎!你的理解是正确的!你也可以尝试在新的数据上运行各种模型,并比较它们各自的均方根误差。
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
这里还提供了其他想法
https://machinelearning.org.cn/evaluate-performance-deep-learning-models-keras/