使用神经网络和深度学习模型时需要进行数据准备。越来越多地,在更复杂的物体识别任务中也需要进行数据增强。
在这篇文章中,您将学习如何在使用 Keras 的 Python 中开发和评估深度学习模型时,对图像数据集进行数据准备和数据增强。
阅读本文后,你将了解:
- 关于 Keras 提供的图像增强 API 以及如何将其与您的模型一起使用
- 如何执行特征标准化
- 如何对图像进行 ZCA 白化
- 如何使用随机旋转、平移和翻转来增强数据
- 如何将增强的图像数据保存到磁盘
通过我的新书《使用 Python 进行深度学习》启动您的项目,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2016 年 6 月:首次发布
- 更新于 2016 年 8 月:此文章中的示例已更新以适应最新的 Keras API。datagen.next() 函数已被移除
- 2016 年 10 月更新:更新至 Keras 1.1.0、TensorFlow 0.10.0 和 scikit-learn v0.18
- 更新于 2017 年 1 月:更新以适应 Keras 1.2.0 和 TensorFlow 0.12.1
- 2017 年 3 月更新:更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 2019 年 9 月更新:更新至 Keras 2.2.5 API
- 更新于 2022 年 7 月:更新以适应 TensorFlow 2.x API,并解决了特征标准化问题
有关用于图像数据增强的 ImageDataGenerator 的详细教程,请参阅
Keras 图像增强 API
与 Keras 的其余部分一样,图像增强 API 简单而强大。
Keras 提供了 ImageDataGenerator 类,该类定义了图像数据准备和增强的配置。这包括以下功能:
- 样本级标准化
- 特征级标准化
- ZCA 白化
- 随机旋转、平移、剪切和翻转
- 维度重排
- 将增强图像保存到磁盘
可以按如下方式创建增强图像生成器
|
1 2 |
from tensorflow.keras.preprocessing.image import ImageDataGenerator datagen = ImageDataGenerator() |
与在内存中对整个图像数据集执行操作不同,该 API 被设计为由深度学习模型拟合过程迭代,及时为您创建增强的图像数据。这减少了您的内存开销,但在模型训练期间增加了一些额外的时间成本。
创建并配置好 ImageDataGenerator 后,您必须将其拟合到您的数据上。这将计算实际对图像数据执行转换所需的任何统计量。您可以通过调用数据生成器上的 fit() 函数并将其传递给您的训练数据集来完成此操作。
|
1 |
datagen.fit(train) |
数据生成器本身实际上是一个迭代器,当请求时返回批量的图像样本。您可以通过调用 flow() 函数来配置批量大小,并准备数据生成器并获取批量图像。
|
1 |
X_batch, y_batch = datagen.flow(train, train, batch_size=32) |
最后,您可以使用数据生成器。您必须调用 fit_generator() 函数,而不是在模型上调用 fit() 函数,并传入数据生成器、所需的 epoch 长度以及要训练的总 epoch 数。
|
1 |
fit_generator(datagen, samples_per_epoch=len(train), epochs=100) |
您可以在 Keras 文档中了解有关 Keras 图像数据生成器 API 的更多信息。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
图像增强的比较点
现在您已经了解了 Keras 中图像增强 API 的工作原理,接下来我们看一些示例。
我们将在这些示例中使用 MNIST 手写数字识别任务。首先,让我们看一下训练数据集中的前九张图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 绘制图像 from tensorflow.keras.datasets import mnist import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_train[i*3+j], cmap=plt.get_cmap("gray")) # 显示绘图 plt.show() |
运行此示例会生成以下图像,您可以将其与下面示例中的图像准备和增强进行比较。

MNIST 图像示例
特征标准化
还可以对整个数据集的像素值进行标准化。这称为特征标准化,反映了通常对表格数据集中的每一列执行的标准化类型。
您可以通过将 ImageDataGenerator 类上的 featurewise_center 和 featurewise_std_normalization 参数设置为 True 来执行特征标准化。这些参数默认设置为 False。但是,最新版本的 Keras 在特征标准化方面存在一个错误,即均值和标准差是针对所有像素计算的。如果您使用 ImageDataGenerator 类中的 fit() 函数,您将看到与上面类似的图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 对整个数据集的图像进行标准化,均值=0,标准差=1 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True) # 根据数据拟合参数 datagen.fit(X_train) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False): print(X_batch.min(), X_batch.mean(), X_batch.max()) # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j], cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
例如,上面打印的批次中的最小值、均值和最大值是
|
1 |
-0.42407447 -0.04093817 2.8215446 |
显示图像如下:

特征标准化图像
解决方法是手动计算特征标准化。每个像素应具有单独的均值和标准差,并且应在不同样本之间计算,但独立于同一样本中的其他像素。您只需要用自己的计算替换 fit() 函数即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 对整个数据集的图像进行标准化,每个像素的均值=0,标准差=1 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True) # 根据数据拟合参数 datagen.mean = X_train.mean(axis=0) datagen.std = X_train.std(axis=0) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False): print(X_batch.min(), X_batch.mean(), X_batch.max()) # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j], cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
现在打印的最小值、平均值和最大值范围更广
|
1 |
-1.2742625 -0.028436039 17.46127 |
运行此示例,您可以看到效果不同,似乎使不同的数字变暗和变亮。

标准化特征 MNIST 图像
ZCA 白化
图像的白化变换是一种线性代数运算,可减少像素图像矩阵中的冗余。
图像中较少的冗余旨在更好地向学习算法突出显示图像中的结构和特征。
通常,图像白化是使用主成分分析(PCA)技术执行的。最近,一种称为 ZCA(在此技术报告附录 A 中了解更多)的替代方法在变换图像中显示出更好的结果,该图像保留了所有原始维度。与 PCA 不同,所得的变换图像仍然看起来像原始图像。确切地说,白化将每个图像转换为白噪声向量,即向量中的每个元素都具有零均值和单位标准差,并且彼此统计独立。
您可以通过将 zca_whitening 参数设置为 True 来执行 ZCA 白化变换。但由于与特征标准化相同的问题,您必须首先单独将输入数据归零居中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# ZCA 白化 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True, zca_whitening=True) # 根据数据拟合参数 X_mean = X_train.mean(axis=0) datagen.fit(X_train - X_mean) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train - X_mean, y_train, batch_size=9, shuffle=False): print(X_batch.min(), X_batch.mean(), X_batch.max()) # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
运行该示例,您可以看到图像中相同的整体结构,以及每个数字的轮廓如何被突出显示。
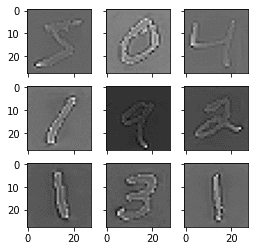
ZCA 白化 MNIST 图像
随机旋转
有时,样本数据中的图像可能在场景中具有不同且变化的旋转。
您可以通过在训练期间人为地随机旋转数据集中的图像来训练模型以更好地处理图像旋转。
下面的示例通过设置 rotation_range 参数创建 MNIST 数字的随机旋转,最大可达 90 度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 随机旋转 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(rotation_range=90) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False): # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
运行该示例,您可以看到图像已左右旋转,最大旋转角度为 90 度。这对于此问题没有帮助,因为 MNIST 数字具有标准化方向,但此变换在从物体可能具有不同方向的照片中学习时可能会有所帮助。

MNIST 图像的随机旋转
随机平移
图像中的物体可能不在框架中心。它们可能以各种不同的方式偏离中心。
您可以通过人工创建训练数据的平移版本来训练深度学习网络以期望并正确处理偏离中心的物体。Keras 支持通过 width_shift_range 和 height_shift_range 参数对训练数据进行单独的水平和垂直随机平移。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 随机平移 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 shift = 0.2 datagen = ImageDataGenerator(width_shift_range=shift, height_shift_range=shift) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False): # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
运行此示例会创建数字的平移版本。同样,这对于 MNIST 来说不是必需的,因为手写数字已经居中,但您可以看到这对于更复杂的问题领域可能有多大用处。

随机平移的 MNIST 图像
随机翻转
图像数据的另一个增强方法,可以提高处理大型复杂问题的性能,是在训练数据中创建图像的随机翻转。
Keras 支持使用 vertical_flip 和 horizontal_flip 参数沿垂直和水平轴进行随机翻转。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 随机翻转 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False): # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
运行此示例,您可以看到翻转的数字。翻转数字没有用,因为它们将始终具有正确的左右方向,但这对于场景中物体具有不同方向的照片问题可能有用。

随机翻转的 MNIST 图像
将增强图像保存到文件
数据准备和增强由 Keras 及时执行。
这在内存方面是高效的,但您可能需要训练期间使用的确切图像。例如,您可能希望稍后将它们与不同的软件包一起使用,或者只生成一次并将它们用于多个不同的深度学习模型或配置。
Keras 允许您保存训练期间生成的图像。在训练之前,可以在 flow() 函数中指定目录、文件名前缀和图像文件类型。然后,在训练期间,生成的图像将写入文件。
下面的示例演示了这一点,并将九张图像写入“images”子目录,前缀为“aug”,文件类型为 PNG。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 将增强图像保存到文件 from tensorflow.keras.datasets import mnist from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt # 加载数据 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 重塑为 [样本][宽度][高度][通道] X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)) # 将 int 转换为 float X_train = X_train.astype('float32') X_test = X_test.astype('float32') # 定义数据准备 datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True) # 配置批量大小并检索一批图像 for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False, save_to_dir='images', save_prefix='aug', save_format='png'): # 创建 3x3 图像网格 fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4)) for i in range(3): for j in range(3): ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray")) # 显示图表 plt.show() break |
运行该示例,您可以看到图像仅在生成时才写入。
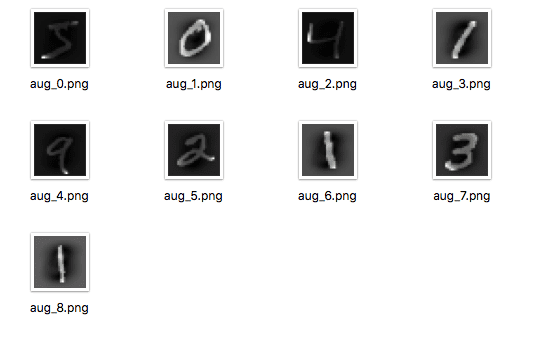
保存到文件的增强 MNIST 图像
使用 Keras 增强图像数据的技巧
图像数据是独一无二的,您可以查看数据和数据转换后的副本,并快速了解模型可能如何感知它。
以下是一些充分利用深度学习图像数据准备和增强的技巧。
- 审查数据集。花一些时间详细审查您的数据集。查看图像。记录可能有助于模型训练过程的图像准备和增强,例如需要处理场景中物体的不同平移、旋转或翻转。
- 审查增强。在执行增强后审查样本图像。智力上了解您正在使用的图像变换是一回事;查看示例则完全不同。审查您正在使用的单个增强以及您计划使用的完整增强集。您可能会发现简化或进一步增强模型训练过程的方法。
- 评估一套转换。尝试多种图像数据准备和增强方案。通常,您可能会对您认为没有益处的数据准备方案的结果感到惊讶。
总结
在这篇文章中,您了解了图像数据准备和增强。
您发现了一系列可以在 Python 中使用 Keras 轻松用于深度学习模型的技术。您学习了:
- Keras 中的 ImageDataGenerator API 用于即时生成转换图像
- 样本级和特征级像素标准化
- ZCA 白化变换
- 图像的随机旋转、平移和翻转
- 如何将转换后的图像保存到文件以供以后重用
您对图像数据增强或此文章有任何疑问吗?在评论中提出您的问题,我将尽力回答。






有趣的教程。
我正在进行跨数据集图像标准化的步骤,遇到了以下错误:
AttributeError Traceback (最近一次调用)
in ()
18 datagen.flow(X_train, y_train, batch_size=9)
19 # 检索一批图像
—> 20 X_batch, y_batch = datagen.next()
21 # 创建 3×3 图像网格
22 for i in range(0, 9)
AttributeError: ‘ImageDataGenerator’ object has no attribute ‘next’
我查阅了 Keras 文档,没有发现 next 属性的提及。
也许我遗漏了什么。
感谢您提供出色的教程!
是的,API 已经更改。请参阅
https://keras.org.cn/preprocessing/image/
我会尽快更新所有示例。
更新:我已更新此文章中的所有示例以使用新的 API。如果您有任何问题,请告诉我。
完美运行!谢谢
很高兴听到这个消息,安迪。
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9)
文件 “/usr/local/lib/python2.7/dist-packages/keras/preprocessing/image.py”,第 475 行,in next
x = self.image_data_generator.random_transform(x.astype(‘float32’))
文件 “/usr/local/lib/python2.7/dist-packages/keras/preprocessing/image.py”,第 346 行,in random_transform
fill_mode=self.fill_mode, cval=self.cval)
文件 “/usr/local/lib/python2.7/dist-packages/keras/preprocessing/image.py”,第 109 行,in apply_transform
x = np.stack(channel_images, axis=0)
AttributeError: ‘module’ object has no attribute ‘stack’
如何解决此错误…?
我以前从未见过这样的错误。也许您的环境有问题?
考虑重新安装 Theano 和/或 Keras。
我通过更新 numpy 版本解决了这个错误…以前是 1.8.0…现在是 1.11.1…这意味着它应该大于 1.9.0
太好了,很高兴听到这个消息,narayan。
现在我有一个问题,如何决定这个参数的值,以便获得良好的测试准确性…我有一个包含 110 个类别和 32000 张图像的训练数据集…
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode=’nearest’,
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
dim_ordering=K.image_dim_ordering()
期待您的积极回复…
我的建议是尝试一套不同的配置,看看哪种配置最适合您的问题。
非常感谢。
除了最后一个保存图像到文件的代码外,一切都运行正常,我收到了以下异常:
Walids-MacBook-Pro:DataAugmentation walidahmed$ python augment_save_to_file.py
使用 TensorFlow 后端。
回溯(最近一次调用)
文件 “augment_save_to_file.py”,第 20 行,in
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, save_to_dir=’images’, save_prefix=’aug’, save_format=’png’)
文件 “/usr/local/lib/python2.7/site-packages/keras/preprocessing/image.py”,第 490 行,in next
img = array_to_img(batch_x[i], self.dim_ordering, scale=True)
文件 “/usr/local/lib/python2.7/site-packages/keras/preprocessing/image.py”,第 140 行,in array_to_img
raise Exception(‘不支持的通道数:’,x.shape[2])
Exception: (‘不支持的通道数:’,28)
有什么建议吗?
再次感谢
再次检查您的 Keras 版本是否为 1.1.0,TensorFlow 是否为 0.10。
你好 Jason,
非常感谢您的教程。它在很多方面帮助了我。
我有一个关于训练图像 X 的掩码图像或目标 Y 的问题。
我也可以将 Y 与 X 一起转换吗?这有助于分割训练。
我成功做到了。
datagen = ImageDataGenerator(shear_range=0.02,dim_ordering=K._image_dim_ordering,rotation_range=5,width_shift_range=0.05, height_shift_range=0.05,zoom_range=0.3,fill_mode=’constant’, cval=0)
for samples in range(0,100)
seed = rd.randint(low=10,high=100000)
for imags_batch in datagen.flow(imgs_train,batch_size=batch_size,save_to_dir=’augmented’,save_prefix=’aug’,seed=seed,save_format=’tif’)
print(‘-‘)
break
for imgs_mask_batch in datagen.flow(imgs_mask_train, batch_size=batch_size, save_to_dir=’augmented’,seed=seed, save_prefix=’mask_aug’,save_format=’tif’)
print(‘|’)
break
print((samples+1)*batch_size)
这很棒,但我想知道您是否可以提供一个带有三个通道的 RGB 图像的示例?我个人在使用这个 ImageGenerator 时遇到了一些非常糟糕的结果。
好建议,谢谢 Addie。
我想知道
channel_shift_range是什么意思。文档说“每个通道的偏移范围”,但这实际上意味着什么?它是给每个通道添加一个随机值还是做其他事情?抱歉 Lucas,我还没有用过这个。
您可以尝试进行实验,或者深入研究源代码以了解其全部内容。
你好,
感谢您的文章。我有一个问题,即我们在训练集中进行特征标准化,那么在测试时,我们需要那些标准化值来应用于测试图像吗?
是的,Indra,在建模之前对数据执行的任何转换(例如标准化)也需要在新数据进行测试或预测时执行。
在标准化的情况下,我们需要跟踪均值和标准差。
再次感谢 Jason。我们为什么要子图 330+1+i?谢谢
这是 matplotlab 语法。
33 创建一个 3x3 的图像网格。后面的数字 (1-9) 表示在该网格中放置下一张图像的位置(从左到右,从上到下排序)。
希望这能有所帮助。
我如何将增强的图像保存到带有类别标签前缀的目录中,甚至更好地保存到类别名称的子目录中?
好问题,Vineeth,
您可以在调用 flow() 时指定任何目录和文件名前缀。
我们可以增强特定类别的数据吗?我的意思是,图像较少的类别,以解决类别不平衡问题。
好主意。
是的,但您可能需要单独准备每个类别的数据。
嗨,Jason,
感谢您的帖子!
我有一个问题:这是否适用于每个像素都有 RGBXYZ 的图像数据?
我的每个输入图像都有六个通道,包括 RGB 和 XYZ(世界坐标),这些图像是从 PCL(点云库)组织的点云中获取的。我想知道是否有正确的方法来对我的图像进行数据增强。
我认为 ImageDataGenerator 可能只对 RGB 图像正确?因为当您平移/旋转/翻转 RGB 图像时,它确实意味着相机移动,XYZ 坐标也应该随之改变。
谢谢。
你好 Lebron,我相信这个特定的 API 是为 3D 像素数据设计的。您可能可以为自己的数据设计自己的类似领域特定的转换。
谢谢 Jason!
确认一下,“3D 像素数据”是指仅包含 RGB 的图像吗?如果我有更多通道,我是否必须自己完成所有增强,而不是使用 Keras API?
是的,我相信情况就是这样,但我可能错了。
当我使用 0.2 的
zoom_range并检查输出图像时,它似乎独立地缩放 h 轴和 v 轴。但是我希望在保留图像纵横比的同时进行少量缩放变化。另外,当我指定
rotation_range时,旋转后的图像会出现锯齿状伪影。有没有办法指定带有抗锯齿的旋转?我暂时不确定。
您认为这些问题会影响模型的性能吗?
谢谢 Jason,
图像的纵横比在面部识别设置中很重要。旋转图像的抗锯齿我不确定,但由于它们是小图像(244 x 244),进一步降级它们没有意义。
我可以修改我自己的 Keras 代码副本以保持缩放的纵横比,并且应该能够用 PIL 的旋转功能(它执行抗锯齿)替换 Keras 中使用的功能。
保持良好的工作状态,您的文章确实帮助我快速掌握了 Keras
很好,Brian。
告诉我进展如何。
你好,布莱恩。
ImageGenerator 中的变换是使用 [scipy.ndimage.interpolation.affine_transform](https://docs.scipy.org.cn/doc/scipy-0.14.0/reference/generated/scipy.ndimage.interpolation.affine_transform.html) 应用的,其中“order”(用于插值的样条阶数)设置为零。
将其更改为 1 用于线性插值,或更改为更高的阶数用于更高阶插值。
嗨,Jason,
感谢您的文章!非常清楚!
我正在尝试使用 ImageDataGenerator。但是,如果我将来想对未见过的数据应用特征标准化,我需要将 ImageDataGenerator 保存到磁盘,对吗?有什么建议吗?非常感谢。
没错,或者您可以手动标准化并仅保存使用的系数。
嗨 Jason
我正在使用 Keras 2.x 的 'tf' 设置。
为什么我不能使用
X_batch, y_batch = datagen.flow(train, train, batch_size=32)
例如
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 重塑为 [样本][像素][宽度][高度]
X_train = X_train.reshape(X_train.shape[0], 28, 28,1)
X_test = X_test.reshape(X_test.shape[0], 28, 28,1)
# 将 int 转换为 float
X_train = X_train.astype(‘float32’)
X_test = X_test.astype(‘float32’)
# 定义数据准备
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# 根据数据拟合参数
datagen.fit(X_train)
# 配置批量大小并检索一批图像
X_batch, y_batch = datagen.flow(X_train, y_train, batch_size=9)
能告诉我为什么吗?
谢谢!
您具体收到什么错误?
你好,Hason
错误消息是
要解包的值太多 (预期 2)
很抱歉,我以前从未见过这个错误,我没有任何好的建议。
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
我认为这应该在没有 train 和 test 对的括号的情况下完成。
# 加载数据
X_train, y_train, X_test, y_test = mnist.load_data()
它返回四个值,但您只接受了两个元组。
嗨,Jason,
我的训练数据形状为 (2000,4,100,100),这意味着 2000 个大小为 100x100 且有 4 个通道的样本,dtype=uint8,存储为 '.npy' 文件。我可以使用图像增强技术处理此类数据吗?
您可以尝试一下。
嗨,Jason,
因为我使用了 fit_generator 方法而不是 fit(),所以我需要使用 evaluate_generator 来正确评估模型吗?predict_generator 也是如此吗?我有点困惑。
嗨,Jason,
我有一个关于图像增强的快速问题。我正在尝试通过数据增强大幅增加训练数据集的大小,以提高我的分割精度。图像生成器是向模型提供同一图像的多个增强版本,还是只返回单个增强版本而不是原始版本?图像数据生成器似乎无法修改实际返回的增强图像数量。
没关系,我在 Keras 文档中找到了答案。
很高兴听到这个消息。
很好的问题。
来自文档:“数据将无限期地循环(批量)。”
https://keras.org.cn/preprocessing/image/
另外,如果我在数据增强生成器中设置了多个选项。它会创建很多不同的数据组合吗?例如
– 原始数据;
– 平移数据;
– 旋转数据;
– 噪声数据;
– 平移 + 旋转数据;
– 平移 + 噪声数据;
– 平移 + 旋转 + 噪声数据,等等。
还是只创建一组所有转换的组合,即
– 仅平移 + 旋转 + 噪声数据;
如果是后者,您对如何组合不同的输出结果有什么建议吗?也许将它们附加到列表中或其他什么?
祝好,
一个非常好的教程
它在创建增强数据时应用所有指定的变换。
你好 Jason,
我用您的书做了练习,我觉得它非常棒!!!
问题是:它应用于随机选择的图像,而不是应用于“比较点”子章节中相同的图像。而且总是不同的样本。
我该如何解决这个问题?
我必须说我不明白“i”如何应用于 pyplot.subplot 和 X-batch[]。
谢谢你!!
Alice
将增强图像视为训练数据集的随机修改版本。您有一个新数据集,其中包含您提供的数据的许多变体。您无需将它们与原始示例联系起来。
或者,也许我误解了您的问题?
我认为爱丽丝的问题和我的一样,每次修改后绘制的数据都不同,这很难进行比较,因为它们每次都会变化。
例如
-第一个图表给我:5 6 3, 0 1 9, 2 3 1
– ZCA 白化后我有:2 3 8, 3 2 5, 0 1 7
是的,根据设计,每次调用时,增强都会创建图像的不同增强版本。
这正是我们想要的,以便模型更好地泛化。
到底是什么问题,您能帮我理解一下吗?
你好 Jason,
我和爱丽丝有同样的问题。我想她说的意思是,随机修改后绘制的图片从来都不是一样的。
似乎每次绘制的 9 张图片都是随机选择的。
如果你能回答我的这个问题,那就太好了。
谢谢!
是的,这是设计好的。这正是我们从图像增强中想要得到的。
如果要保留原始数据集的顺序,请在 flow 方法中使用 shuffle 参数
…
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False)
…
你好,
当我运行上述脚本时,出现此错误:
使用 TensorFlow 后端。
C:\Users\sacheu\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\preprocessing\image.py:653: UserWarning: 预期的输入是图像(Numpy 数组),遵循数据格式约定“channels_first”(通道在轴 1 上),即预期轴 1 上有 1、3 或 4 个通道。然而,传入的数组形状为 (60000, 1, 28, 28)(1 个通道)。
‘ (‘ + str(x.shape[self.channel_axis]) + ‘ channels).’)
你能告诉我怎么解决吗?
我想我安装的是最新版本的库。我正在使用 python 3.5。
谢谢你。
您可以尝试更改代码中或 Keras 配置文件中通道的顺序。
例如,在代码中
或者如果这是原因,请将其注释掉。
我也有同样的问题。什么都不管用。
消息是一个警告,我仍然得到输出图像,但是例如特征标准化是黑白的,而不是灰度。所以我猜它不起作用?
当我尝试注释掉它或将顺序从“th”更改为“tf”时,它完全中断了。消息是:…(28 个通道)
我是新手,欢迎任何评论。
也许再次检查您是否安装了最新版本的 Keras?2.0.8 或 2.0.9?
(C:\ProgramData\Anaconda3) C:\ProgramData\Anaconda3\etc\conda\activate.d>set “KERAS_BACKEND=theano”
(C:\ProgramData\Anaconda3) C:\Users\Tom>conda install -c conda-forge keras Fetching package metadata ……………
Solving package specifications: .
# 所有请求的包都已安装。
# 环境中的包在 C:\ProgramData\Anaconda3
#
keras 2.0.6 py36_0 conda-forge
看起来是最新的。但是…
我使用了这个教程:https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/,然后输入
import keras
print(‘keras: %s’ % keras.__version__)
给了我
使用 Theano 后端。
keras: 2.0.6
但根据教程应该如此
使用 TensorFlow 后端。
keras: 1.2.1
您可以在 ~/.keras/keras.json 配置文件中更改 Keras 使用的后端。
好的,目前我可以说:
– 这些警告消息只是警告。它们出现在每个示例中。我不知道如何让它们消失,但事实证明它们是无害的。
– 示例特征标准化是黑白的,而不是灰度。脚本中可能有错误?我太新手了,看不出来。
– 其他示例似乎工作正常,尽管有警告消息。(所以我只是看到了警告,看到了不同的输出,发现了带有类似问题的评论就停了下来。我的错)。
– 我可以写 set “KERAS_BACKEND=tensorflow” 来更改后端(我不知道它是什么意思,但没关系 🙂 )。
– 您制作这些教程真是太棒了。谢谢!
谢谢。
您好,感谢您的分享。当我尝试在更大的数据上使用 zca-whitening 和 feature-wised centering 时,我发现很难获得足够的内存来执行 fit() 函数。由于数据集有大约 10000 张图片和 224*224 像素,即使生成一个流迭代器也会用完我 16GB 的内存。当尝试使用 fit() 进行 zca-whitening、centering、normalization 时(文档说必须使用 fit() 函数),我从未成功过。您能为更大的数据准备提供一些建议吗?非常感谢!
您能使用 flow_from_directory 而不是将所有内容加载到内存中吗?
https://keras.org.cn/preprocessing/image/
我在 MS-COCO 和 NUS-WIDE 数据集上遇到了同样的问题,我有 128GB 内存。flow_from_directory() 要求您的数据采用特定的目录结构。
根据 Keras v2.1.2 文档…
directory: 目标目录的路径。它应该包含每个类别的一个子目录。
MS-COCO 和 NUS-WIDE 本身并非以这种方式结构化。
此外,Xiaojie 特别提到了 fit() 函数,该函数在 flow(或 flow_from_directory)函数之前调用。
嗨,Jason,
感谢这篇精彩的文章。我有一个快速问题。我有一个大型数据集,我正在使用自定义数据生成器将其加载到模型中。我正在 model.fit_generator() 中使用它。现在我想使用数据增强。所以我的问题是,我可以在哪里/如何使用 keras ImageDataGenerator?非常感谢。
我相信这个教程会有所帮助
https://blog.keras.org.cn/building-powerful-image-classification-models-using-very-little-data.html
嗨
我们应该分别使用原始图像集和增强图像集运行 fit_transform 吗?或者我们将它们组合成一个。后者我们如何组合它们?
谢谢。
Steve
只用增强图像。
谢谢 Jason。买了你所有的机器学习书籍,非常喜欢!你会写一本关于迁移学习的深度书籍,涵盖 ImageNet 和其他一些内容,以便我们能够将预训练的模型用于我们自己的目的吗?
谢谢。
再次感谢您的支持,Steve。
是的,我有一个关于重复使用 VGG 模型的帖子。它应该很快就会出现在博客上。
感谢这篇精彩的文章!
在随机平移部分,我们可以控制文件名吗?
是否可以将文件保存为
“aug”+原始文件名+“png”?
谢谢。
是的,您可以控制文件名。也许API会使其更清晰
https://keras.org.cn/preprocessing/image/
感谢您的教程。当我尝试使用
pred = model.predict_generator(data_gen.flow_from_directory("../input/valid_img", target_size=(input_size, input_size)))
时,我无法获取与预测概率对应的图像文件名。有什么解决方案吗?
我期望预测的顺序与目录中文件的顺序匹配。
我检查过了,然而情况并非如此,因为我的准确率与val_acc相比非常低。我发现有人通过在使用predict_generator和ImageDataGenerator.flow_from_directory时将batch_size设置为1来解决这个问题,但这并不是我想要的。
嗨,Jason,
您对如何将相同的想法应用于信号有什么想法吗?我是指用于深度学习的信号增强?谢谢
暂时没有。考虑如何将转换应用于您的特定数据以创建新的模式。例如,即使只是添加随机噪声也是一个好的开始。
一旦特征居中,在keras.preprocessing.image.ImageDataGenerator()中使用featurewise_center=True,我如何检索这些统计数据以便在evaluate_generator()等预测/测试期间预处理图像
好问题,我暂时不确定,也许可以发布到Keras群组或slack频道
https://machinelearning.org.cn/get-help-with-keras/
嗨,Jason,
非常感谢您分享的所有帖子,它们非常有用,帮助很大。
我想问一下您是否有关于时间序列数据(例如加速度、交流电压等)的数据增强算法的实现想法
谢谢你
目前没有,谢谢您的建议。
嗨,Jason,我有一个问题,假设我们有语义分割任务,我们想旋转和翻转图像和输出图像标签,我们如何应用这些变换?我应该将图像和标签连接成一个同构数组,然后应用适当的变换吗?
好问题,您可能需要更多的控制,一次应用一对增强。
嗨,Jason,
感谢您的精彩帖子!我如何将增强应用于磁盘上的数据?我看到您导入了mnist,但我无法理解如何为我的目的更改它。
您可以通过增强API加载数据,并使用它创建数据集的增强版本。此增强可以直接使用,也可以保存到文件。
嗨,Jason,
快速问题:图像增强后,您的脚本将它们保存到更小的文件中。如果我想将这些增强文件拼接成一个文件,类似于原始的mnist文件,以便我可以使用nmist.load_data()函数将它们加载到,比如说,一个CNN引擎中,该怎么做?以下方法可行吗?
nmist_new = []
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9)
# 创建一个3x3的图像网格
for i in range(0, 9)
nmist_new.append(array(X_batch, y_batch))
我不确定应该使用什么格式。
好问题,我认为需要一些实验。
也许可以使用numpy的hstack和vstack从图像数组创建更大的数组?
是的,我认为需要一些调整,或者研究Keras的mnist_load()函数在写回数据时的数据格式。这个链接有原始数据格式
http://yann.lecun.com/exdb/mnist/
向下滚动到底部查看训练和测试数据集结构。他们为每个图像使用了一些头部信息。我认为hstack和vstack是可行的方法,但需要处理这些头部(我认为应该很容易)。我仍然不确定那些“xxxx”是什么意思。我认为文件只是由28x28的小图像数据填充的。
编写自己的渐进式加载函数可能会更容易。实际上简单得多。
亲爱的 Jason,
我使用代码生成了特征标准化样本,但没有得到网页上显示的结果。
天
有什么不同?
你好,Jason
我有一个图像数据集(jpg文件而非csv文件),这些图像的每个类别都分别在一个文件夹中,例如“汽车”在一个名为“car”的文件夹中,“猫”在一个名为“cat”的文件夹中,“狗”在一个名为“dog”的文件夹中,那么我如何将深度学习模型应用于这些数据?我需要图像数据生成器吗?
谢谢你
我想这个教程会有帮助
https://blog.keras.org.cn/building-powerful-image-classification-models-using-very-little-data.html
您的博客太棒了。非常感谢。
谢谢。
你好 Jason,
我对“图像增强”的理解有点困惑
假设:-
总训练图像:- 10 (#X_train 图像)
ImageDataGenerator(rotation_range=90) #随机旋转
model.fit_generator(datagen.flow(x_train, y_train, batch_size=1),
steps_per_epoch=len(x_train) / 1, epochs=epochs)
这是否意味着我们正在训练10张随机旋转图像的模型?
或者我们是在使用fit_generator()训练10张原始图像+10张随机旋转图像的模型?
我假设我们正在用10张随机旋转的图像训练模型。
Q.1 我说对了吗?
在这里,我在CIFAR10(彩色图像,图像[10])上尝试了数据增强
但我没有得到适当的增强后输出图像
https://pasteboard.co/HkvZLT1.png
这是代码:-
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
x1=x_train[10:11,:,:,:]
y1=y_train[10:11,]
datagen = ImageDataGenerator(rotation_range=90)
print (x1.shape) #形状 (1, 32, 32, 3)
print (y1.shape) #形状 (1, 10)
plt.imshow(x1[0]) #图像 1
plt.show()
for x_batch,y_batch in datagen.flow(x1,y1, batch_size=1)
for i in range(0, 1)
plt.imshow(x_batch[i].reshape(32,32,3)) #图像 2
plt.show()
print (y_batch)
break
Jason,能帮我一下吗?
谢谢你
10张不同图像的10个随机修改版本。
知道了。
我尝试旋转一张图片。但是当我执行plt.show()时,图片没有正确显示。
这是图片
https://pasteboard.co/HkvZLT1.png
这是代码:-
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
x1=x_train[10:11,:,:,:]
y1=y_train[10:11,]
datagen = ImageDataGenerator(rotation_range=90)
print (x1.shape) #形状 (1, 32, 32, 3)
print (y1.shape) #形状 (1, 10)
plt.imshow(x1[0]) #图像 1
plt.show()
for x_batch,y_batch in datagen.flow(x1,y1, batch_size=1)
for i in range(0, 1)
plt.imshow(x_batch[i].reshape(32,32,3)) #图像 2
plt.show()
print (y_batch)
break
谢谢你,Jason。
抱歉,我没有什么好的建议。也许您可以将您的代码和错误发布到StackOverflow上?
您好。感谢您的教程。它非常有帮助。实际上,我有3个问题
1. 当我使用您的代码时,Mnist图像从一种数据增强方法变为另一种。我的意思是,它每次都在不同的9个数字样本上执行。您知道如何解决这个问题吗?因为它们需要相同才能进行比较。
2. 第一个技术(标准化)对我不起作用。我得到的数字亮度相同:没有变暗或变亮。这是为什么?我只是复制粘贴了代码。
3. 我需要在3D医学图像(DICOM格式)上进行数据增强。是否可以使用Keras的ImageDataGenerator来完成?或者有没有更简单的方法?
再次感谢。
抱歉,我没理解第一个问题。
也许代码已经改变了?
抱歉,我不了解3D图像。
亲爱的 Jason,
我想知道如何将包含多张图像(即一个文件中有多张图像)的图像文件上传到python中。感谢您的宝贵时间。
抱歉,我没有这方面的具体例子。
好的,谢谢您的时间。
不客气。
你好。
我在 Jupyter Notebook 中运行这些示例,但没有看到本博客“特征标准化”部分中出现的变暗和变白效果。在本节中,每次运行都会看到不同的数字。我仔细检查了代码,确保没有遗漏任何东西。
有人在这里得到相同的结果吗?
也许API已经改变了?
也许从命令行运行结果会不同,我推荐这样做?
嗨,Jason!
感谢您的所有教程,您在向渴望学习的人们推广概念方面做得非常出色!
我有一个关于数据整理的问题。我一直编写自己的小脚本来处理数据加载。但实际上我想做的是以类似于 MNIST 或 CIFAR 数据集在 Keras 中存储的方式准备数据。我研究过文件的格式等,但我想知道,肯定有人为自己的数据编写过一些代码,而且他们肯定会将其公开。我到处搜索都找不到。
基本上,我正在寻找一个脚本,它以某种结构(例如数据/训练和数据/验证子文件夹)获取数据,并将其以 MNIST 和 CIFAR 附带的腌制批次形式准备,以便可以轻松共享和重用。
您对此有什么线索吗?
好主意。
据我所知,没有。我预计您需要为此编写一些自定义代码。
小更新
根据文档 (https://keras.org.cn/preprocessing/image/#imagedatagenerator-class),
featurewise_center 和 featurewise_std_normalization 默认设置为 False。
谢谢,也许API已经改变了。
嗨 Jason,
如何将图像精确旋转90度。ImageDataGenerator生成的图像是随机旋转的。我希望图像精确旋转90度。如何做到这一点
也许编写代码预旋转并保存旋转后的图像?
嗨,Jason,我正在学习分类器。我使用序列类来生成数据批次并使用多进程函数来训练模型。
我的问题是:如何将这个增强生成器和我创建的生成器拟合?我的意思是这个增强生成器可以这样训练
还有我的批次生成器
我能混合这个,做一些像
history = model.fit_generator(train_datagen.flow(batcg_train)….吗?
谢谢你
我在这篇文章中有一个使用生成器的例子,可能会提供一个有用的指导
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
嗨,Jason,感谢您的精彩教程。
我有一个问题,当我在本地计算机上尝试您的特征标准化示例时,我没有看到任何与变暗或变亮相关的变化,结果图像似乎相同。我无法弄清楚原因。顺便说一句,为了比较前9张图像,我们必须在使用flow()函数获取批次时将shuffle设置为False。
这是代码
也许API已经改变了?
嗨,duliqiang(以及嗨,Jason,再次感谢这些精彩的教程)
我遇到了同样的问题(没有变亮或变暗)。查看了API,但找不到任何可以尝试的东西。这方面有什么更新吗?
谢谢!
我将就此主题撰写一篇更新的教程。
嗨,Jason,
我有个问题
为什么在进一步处理数据之前将其转换为浮点数?
这是必要的吗?如果省略会导致错误结果吗?
谢谢你
当时我认为这是必需的。
嗨,Jason!
一如既往的精彩帖子!
我想我错过了一些东西,我查阅了之前的回复,但没有找到我问题的明确答案,所以让我问一下,如果已经回答过,请原谅。
当您使用fit_generator()方法时,模型只用转换后的图像进行训练吗?它不是用原始图像+转换后的图像进行训练,对吗?
ImageGenerator允许生成转换后的数据来增强数据集。
但是,只用转换后的图像而不是原始图像加上转换后的图像来训练模型有什么意义呢?
我觉得增强的意义就是增强:D所以如果我们的数据集没有变大,那就没有增强。
我这里错过了什么?如果keras是这样实现的,那么只用转换后的图像进行训练可能很好,但为什么呢?我以为这样做的全部目的是增加用于训练的图像数量。
是否有可能,使用相同的方法,生成多种类型的转换图像(例如旋转、平移和白化),并用所有转换图像和原始图像一起训练模型?
那样会更有意义,那才是真正意义上的原始数据集的增强。
它只在增强图像上进行训练。增强图像集包含了未增强图像——它已经扩展了训练数据集。
嗨,Jason,
我需要预测125000张图像的值,为此我使用了以下代码片段
———————————————————————————————————
test_datagen=ImageDataGenerator(rescale=1/255)
test_generator = test_datagen.flow(x,batch_size=10,seed=42,shuffle=False)
y_pred = model.predict_generator(test_generator,steps=n_pred//10,verbose=1)
———————————————————————————————————
但我遇到了内存错误。
您能给些建议吗?如何处理
也许可以尝试使用flow_from_directory()来逐步加载数据,而不是将所有数据加载到内存中?
由于我正在从只读目录中读取数据,并且没有子文件夹来标识标签,因此我无法使用flow_from_directory。而且,我认为将所有图像复制到单独的目录会是一个成本高昂的过程。
您可以从只读目录流式传输,只需禁用任何图像保存(默认设置)。
当没有子文件夹时,它无法读取。
我使用了
# 定义数据预处理
test_image_gen = ImageDataGenerator(rescale=1/255)
test_generator = test_image_gen.flow_from_directory(test_dir,target_size=(Image_width,Image_height),batch_size=batch_size,seed=42,class_mode = None,classes=None)
============================================================
找到0张图片,属于0个类别。
我明白了,是的,从目录流式传输时,每个类都必须有一个子目录。
嗨,Jason,
我有一个疑问,我用数据增强训练了一个卷积神经网络模型。现在我需要实时解释并从训练好的模型中获取新输入的分类。我使用了ImageDataGenerator与flow_from_directory和fit_generator… 我需要使用哪种方法来预测结果?您能详细说明一下吗?
您使用predict_generator(),您可能还需要创建一个新的生成器,该生成器只具有相同的缩放(在训练数据集上拟合),但没有增强。
嗨,Jason,
我希望将增强数据(cifar10测试数据集)转换为npz格式的0-1值。
不确定我的脚本是否正确,如下所示
然而,当我使用npz文件作为输入图像(它使用
npz值作为泊松率)运行CNN模型时,它抱怨泊松生成器
的泊松率不能为负。
ImageDataGenerator()中是否还有其他设置需要设置才能获得
0到1之间的值?
此致
德尔
.
for x_batch, y_batch in test
抱歉,我不确定我是否理解数据保存与泊松分布之间的关系?
嗨,Jason,
抱歉,我实际上正在尝试将ANN CNN网络转换为脉冲神经网络,图像像素
密度值被视为泊松生成器的泊松率,
抱歉,我对此不熟悉。我能够生成0-1值范围的数据集。
从我之前的帖子来看,我能够保存x_test.npz,我该如何保存相应的
y_test.npz?
您可以使用savez_compressed()保存.npz文件
https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.savez_compressed.html
你好,
我检查了用旋转和缩放(ImageDataGenerator)生成的输入图像
但是图像改变后,出现了黑色的空白。
所有图像最初都有白色背景。
如何去除这些黑色空白?
我相信您可以指定“fill_mode”和/或“cval”来指示填充的像素值,并将其设置为255或1,具体取决于像素比例。
更多细节在此
https://keras.org.cn/preprocessing/image/
嗨,Jason,
我在“将增强图像保存到文件”示例中遇到了错误
回溯(最近一次调用)
File “”, line 1, in
文件“C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\keras_preprocessing\image\iterator.py”,第100行,在__next__中
return self.next(*args, **kwargs)
文件“C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\keras_preprocessing\image\iterator.py”,第112行,在next中
return self._get_batches_of_transformed_samples(index_array)
文件“C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\keras_preprocessing\image\numpy_array_iterator.py”,第159行,在_get_batches_of_transformed_samples中
img = array_to_img(batch_x[i], self.data_format, scale=True)
文件“C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\keras_preprocessing\image\utils.py”,第228行,在array_to_img中
raise ImportError('Could not import PIL.Image. '
ImportError: 无法导入PIL.Image。使用array_to_img需要PIL。
错误提示您需要安装Pillow,您可以在此处了解如何安装
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
如果我对训练和测试数据集都使用 featurewise_center 和 featurewise_std_normalization,这段代码是否正确?
test_datagen = ImageDataGenerator(
rescale=1./255,
featurewise_center=True,
featurewise_std_normalization=True)
train_datagen = ImageDataGenerator(
rescale=1./255,
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
os.path.join(args.data_dir , 'train/'),
target_size=(args.fixed_width, args.fixed_width),
batch_size=args.batch_size,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
os.path.join(args.data_dir, 'val/'),
target_size=(args.fixed_width, args.fixed_width),
batch_size=args.batch_size,
class_mode='categorical')
sgd = SGD(lr=args.learning_rate, decay=0.005, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
也许可以查看这个教程
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
先生,我在保存图像时遇到了麻烦。数据增强之后,我们如何将所有这些新图像保存到本地机器?有什么想法吗?
调用flow时设置“save_to_dir”。
在这里了解更多
https://keras.org.cn/preprocessing/image/
我的数据集训练集有4532个样本,验证集有698个样本,测试集有599个样本。我正在尝试使用以下代码对VGG16进行数据增强训练
# 数据预处理和数据增强
train_datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
rescale=1. / 255,
fill_mode='nearest'
)
vald_datagen = ImageDataGenerator()
test_datagen = ImageDataGenerator()
train_datagen.fit(train_data, augment=True)
…
tr_bs = train_data.shape[0]//batch_size
vl_bs = vald_data.shape[0]//batch_size
for e in range(epoch)
print('Epoch', e)
batches = 0
for (x_batch, y_batch), (val_x, val_y) in zip(
train_datagen.flow(train_data, train_labels_one_hot_coded,
batch_size=tr_bs),
vald_datagen.flow(vald_data, vald_labels_one_hot_coded,
batch_size=vl_bs))
model.fit(x_batch, y_batch, validation_data=(val_x, val_y))
batches += 1
if batches >= len(train_data) / tr_bs
# 我们需要手动打破循环,因为
# 生成器无限循环
break
在训练过程开始时,keras显示此信息
找到4532张图片,属于7个类别。
找到698张图片,属于7个类别。
找到599张图片,属于7个类别。
这与我数据集中的数字兼容。然而,这让我感到困惑。我以为当我们执行增强时,训练集中至少应该有实际样本数量的8倍。您能告诉我如何检查增强数据样本的数量吗?(我没有在任何地方保存增强图像,这是必须的吗,还是我可以在训练时在线使用?!)
摘要只是作为起点找到的内容,增强是在此基础上执行的。
你好,
杰森,帖子很棒!
我有这个问题
在模型训练过程中,它只考虑增强数据吗?还是也考虑初始数据?
我猜考虑初始数据会有助于更好地拟合。
这有关系吗?
谢谢你
训练只使用了增强数据,这是初始数据的超集(包括)。
嗨,Jason,
首先,衷心感谢您制作如此详细的教程。我无法用言语表达我的感激之情。
运行图像标准化脚本时,我得到的图像网格图在任何数字上都没有变暗或变亮的效果。此外,最终脚本的结果图完全不同,没有明显的数据增强。Keras版本(2.3.1)
也许可以试试这个教程
https://machinelearning.org.cn/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
嗨,Jason,
感谢您的所有文章。它们非常有帮助。:)
如果模型有多个输入,您对如何使用 fit_generator() 方法有什么想法/提示吗?
您可能需要创建一个自定义生成器。
如果我有另一个数据集,比如 malimg 数据集,如何获取 X_train、X_test、y_train、y_test 值,我的数据集中有 25 个文件夹中的灰度图像。
我的所有数据集都是 png 格式。
请帮助我
如果25个文件夹对应25个类别,那么您可以直接使用ImageDataGenerator。据我了解,它支持灰度图像。
请看这个教程
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
我如何知道目录与其类别之间的映射?例如,如果我为模型使用softmax,我如何知道它检测到哪个类别?
好问题,请看这个
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
一如既往的精彩教程,非常感谢
我正在尝试在彩色图像上使用它,我得到的图像颜色不同,如何保持颜色并只进行增强?
缩放和翻转等操作不会影响颜色。
也许确认您的图像是否正确加载?
嗨,Jason,
您的教程太棒了。感谢您为准备这些材料所付出的努力。
数据增强用于增加训练数据的大小,但您将number_of_step = training_size / number of batches。换句话说,训练数据的大小保持不变,而我们的目的是增加训练数据的大小!我是不是遗漏了什么?
谢谢!
您可以随心所欲地训练。
先生,我是个新手。我想问您如何对同一九张图片进行一系列操作
在imagedatagenerator配置中指定所有您想要的操作。
先生,问题已经解决了,但是我使用flow from directory方法读取本地图像进行zca操作,但是没有效果
干得好。
也许仔细检查一下您的ZCA配置?
感谢您的精彩教程
我的问题是关于在数据生成器中使用“zca_whitening”。
实际上,在使用数据生成器时,我们没有以 numpy 数组的形式获取训练数据,以便将其传递给以下代码中的“fit”方法
train_datagen.fit(x_train)
这里应该怎么做?
抱歉,我不太明白。也许您能重新表达您的问题?
在这行代码中:“train_datagen.fit(x_train)”
x_train指的是我们的训练数据集,以numpy数组的形式。对吗?
但是当我们使用imagedatagenerator从目录中读取图像时,实际上没有以numpy数组形式存在的x_train。
当我们使用imagedatagenerator时,“fit”方法的参数应该传递什么?
当使用图像数据生成器时,我们不调用 fit()。
我们调用 fit_generator() 并将准备好的生成器传递给它。
也许这会有帮助。
https://machinelearning.org.cn/how-to-load-large-datasets-from-directories-for-deep-learning-with-keras/
如何对dicom(.dcm)图像执行图像增强?
抱歉,我不了解“dicom”图像。
我如何指定要生成的增强图像的数量?
通常,增强图像是根据模型需要即时生成的,例如,一批接一批。
如果您想预先生成它们,您可以循环图像生成过程,直到您的项目有足够的数量。
感谢您的帖子。当我们使用imagegenerator和keras中的flow_directory加载图像时,是否有一种方法可以对不平衡类别进行上采样?
感谢您的帮助
我暂时不这么认为。您可能需要编写一个自定义数据生成器。
杰森,很棒的教程。
有没有一种方法可以以固定角度进行随机旋转?例如,旋转-90、0或90度,即不是旋转范围内的任意角度,而是精确地旋转-90、0或90度。
恕我直言,我认为没有。创建一个您自己的生成器,对增强有更多控制,可能会更容易。
你好,杰森
我的项目是关于使用 OPG 图像通过神经网络 danet(基于年龄)和 dasnet(基于年龄和辅助性别)估计年龄。这是一个在 gitlab 上的原始项目,用于一篇有 2000 多张图像的文章的实现。但我尝试用 112 张图像运行它,其中 72 张教程,20 张验证和 20 张测试,只做了一点改动,danet 运行了,但 dasnet 没有。请指导我…
这是我的 Google Drive 项目链接
https://drive.google.com/file/d/12omJoMgXckE4zGyN4w-BRI02iHW22DvS/view?usp=sharing
git lab 中的链接
https://gitlab.citius.usc.es/nicolas.vila.blanco/chronological-age-estimation-opg-images/-/blob/317d4c9b3ead35e930b70a14779e7cbf0635a730/train_dasnet.py
文章链接在 git lab 中。
我真的很需要您的帮助,谢谢
我用粤语给您发了一条消息,但因为不知道在哪里查看,所以把我的消息回复也写在了这里
我很乐意回答问题,但我没有能力审查代码/数据。
感谢Jason的帮助。
我有一个问题,当我们应用数据增强时(我正在使用imgaug包中的Sequential augmenter只进行翻转操作),它会替换原始图像吗?在生成批处理数据时,我们也应该连接原始数据吗?
嘿,Jason,很棒的帖子,我正在尝试使用,但第一个示例后一直报错
/usr/local/lib/python3.7/dist-packages/matplotlib/image.py 中的 set_data(self, A)
697 或 self._A.ndim == 3 且 self._A.shape[-1] 在 [3, 4] 中)
698 raise TypeError(“图像数据形状无效 {}”
--> 699 .format(self._A.shape))
700
701 如果 self._A.ndim == 3
TypeError: 图像数据形状 (28, 28, 1) 无效
在google colab上有什么解决办法吗
嗨,Matt……你是复制粘贴代码还是手动输入的?
更新:搞定了,你只需要先挤压图片:D)
img = X_batch[i*3+j]
img = np.squeeze(img)
ax[i][j].imshow(img, cmap=plt.get_cmap(“gray”))
谢谢Matt的反馈!继续努力!
詹姆斯·卡迈克尔博士您好
我是来自台湾的学生
感谢您的文章总是给我带来很多启发。
我想请问您,如何连接输入数据,例如将(均值1,标准差1)这两个相关值作为单个输入数据?
谢谢
嗨,Ray……不客气!我建议使用Pandas来执行此功能
https://pandas.ac.cn/docs/user_guide/merging.html
嗨,Jason,
您的文章对我学习帮助巨大。我想知道您是否会制作一个使用 Keras 新的、推荐的图像数据生成器版本的教程。应用它时,会返回弃用警告。一个推论性的问题是,就使用新类更新代码而言,您如何找到项目中所有使用它的实例?
嗨,Angelique……非常欢迎!感谢您的建议!我们将考虑在未来采纳。
除了您提到的警告,您是否发现当前版本性能方面有任何问题可以分享?