在您的机器学习之旅的开端,公开可用的数据集可以减轻您自行创建数据集的担忧,让您专注于学习使用机器学习算法。如果数据集大小适中,并且不需要过多的预处理,也可以帮助您更快地练习使用算法,然后再转向更具挑战性的问题。
我们将关注两个数据集:OpenCV 提供的更简单的数字数据集和更具挑战性但广泛使用的 CIFAR-10 数据集。在学习 OpenCV 机器学习算法的过程中,我们将使用这两个数据集中的任何一个。
在本教程中,您将学习如何下载和提取 OpenCV 数字数据集和 CIFAR-10 数据集,以便在 OpenCV 中实践机器学习。
完成本教程后,您将了解:
- 如何下载和提取 OpenCV 数字数据集。
- 如何在不依赖其他 Python 包(例如 TensorFlow)的情况下下载和提取 CIFAR-10 数据集。
通过我的书《OpenCV 机器学习》启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

用于在 OpenCV 中实践机器学习的图像数据集
照片由 OC Gonzalez 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 数字数据集
- CIFAR-10 数据集
- 加载数据集
数字数据集
OpenCV 提供了一张名为 digits.png 的图像,它由 20x20 像素的子图像“拼贴”而成,其中每个子图像都包含一个从 0 到 9 的数字,并且可以拆分以创建数据集。总共,digits 图像包含 5,000 个手写数字。
OpenCV 提供的数字数据集不一定能代表更复杂数据集带来的现实挑战,主要是因为其图像内容变化非常有限。然而,它的简单性和易用性将使我们能够以较低的预处理和计算成本快速测试几种机器学习算法。
为了能够从完整的数字图像中提取数据集,我们的第一步是将其拆分成构成它的许多子图像。为此,让我们创建以下 split_images 函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
从 cv2 导入 imread, IMREAD_GRAYSCALE 从 numpy 导入 hsplit, vsplit, 数组 def split_images(img_name, img_size): # 从指定文件中加载完整图像 img = imread(img_name, IMREAD_GRAYSCALE) # 根据子图像的大小查找每行和每列的子图像数量 num_rows = img.shape[0] / img_size num_cols = img.shape[1] / img_size # 将完整图像水平和垂直分割成子图像 sub_imgs = [hsplit(row, num_cols) for row in vsplit(img, num_rows)] 返回 img, 数组(sub_imgs) |
split_images 函数将完整图像的路径以及子图像的像素大小作为输入。由于我们使用的是正方形子图像,因此我们将它们的尺寸表示为单个维度,即 20。
该函数随后应用 OpenCV imread 方法将图像的灰度版本加载到 NumPy 数组中。然后使用 hsplit 和 vsplit 方法分别水平和垂直分割 NumPy 数组。
split_images 函数返回的子图像数组的大小为 (50, 100, 20, 20)。
一旦我们提取了子图像数组,我们将它分成训练集和测试集。我们还需要为这两部分数据创建地面真实标签,以便在训练过程中使用并评估测试结果。
以下 split_data 函数用于这些目的
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
从 numpy 导入 float32, arange, repeat, newaxis def split_data(img_size, sub_imgs, ratio): # 计算训练数据和测试数据之间的分区 partition = int(sub_imgs.shape[1] * ratio) # 将数据集分成训练集和测试集 train = sub_imgs[:, :partition, :, :] 测试 = sub_imgs[:, partition:sub_imgs.shape[1], :, :] # 将每个图像展平为一维向量 train_imgs = train.reshape(-1, img_size ** 2) test_imgs = 测试.reshape(-1, img_size ** 2) # 创建地面真实标签 labels = arange(10) train_labels = repeat(labels, train_imgs.shape[0] / labels.shape[0])[:, newaxis] test_labels = repeat(labels, test_imgs.shape[0] / labels.shape[0])[:, newaxis] 返回 train_imgs, train_labels, test_imgs, test_labels |
split_data 函数接收子图像数组作为输入,以及数据集训练部分的分割比例。然后,该函数计算 partition 值,该值沿其列将子图像数组分割成训练集和测试集。此 partition 值随后用于将第一组列分配给训练数据,将剩余的列分配给测试数据。
为了在 digits.png 图像上可视化这种分区,它将如下所示
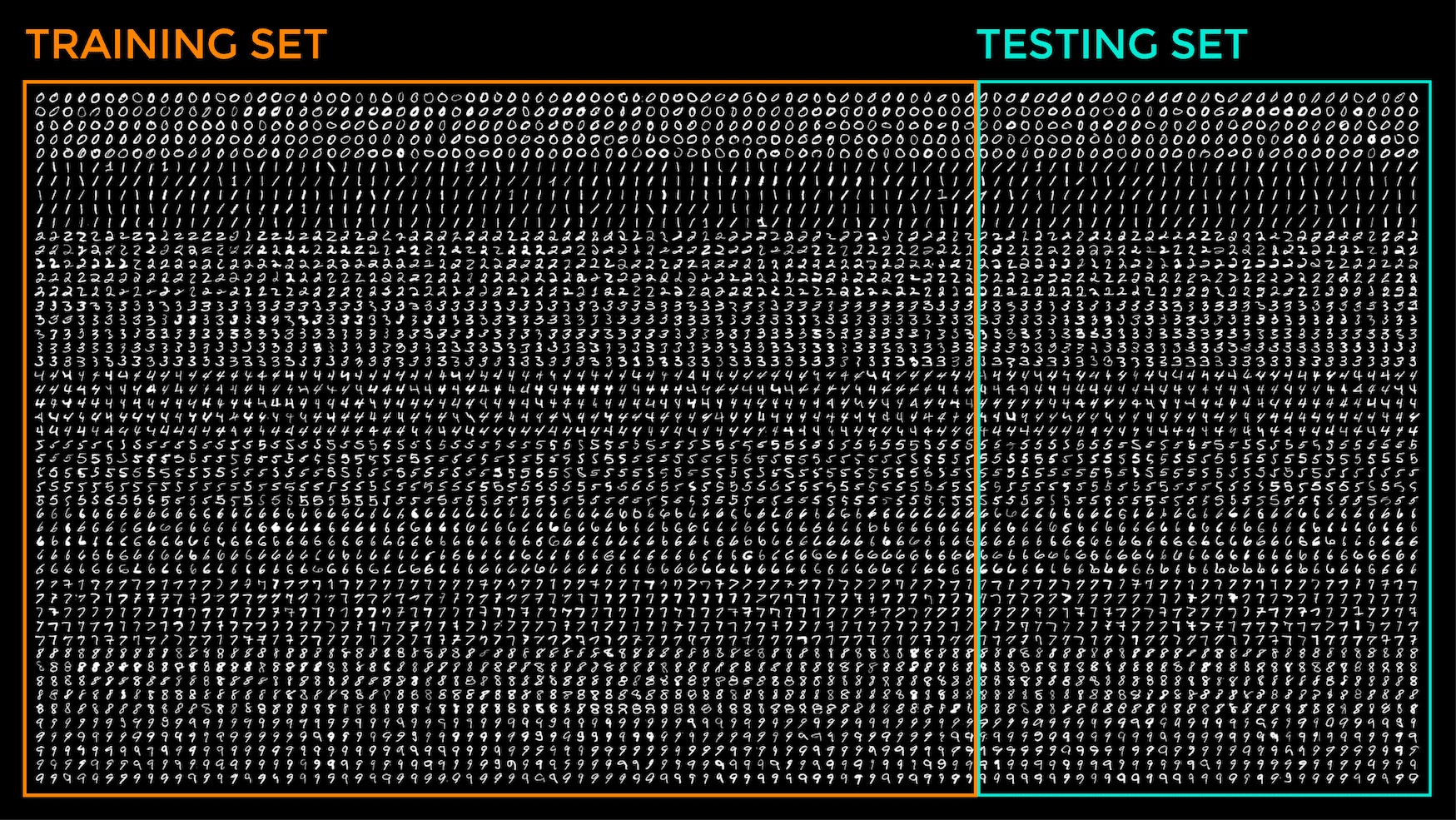
将子图像划分为训练数据集和测试数据集
您可能还会注意到,我们将每个 20x20 的子图像展平为一个长度为 400 像素的一维向量,因此,在包含训练和测试图像的数组中,每一行现在都存储着 20x20 像素图像的展平版本。
split_data 函数的最后一部分创建了介于 0 到 9 之间的地面真实标签,并根据我们可用的训练和测试图像数量重复这些值。
CIFAR-10 数据集
CIFAR-10 数据集不是 OpenCV 提供的,但我们会考虑它,因为它比 OpenCV 的数字数据集更能代表现实世界的挑战。
CIFAR-10 数据集总共包含 60,000 张 32x32 RGB 图像。它包含各种属于 10 个不同类别的图像,例如飞机、猫和船。数据集文件已拆分为 5 个 pickle 文件,包含 1,000 张训练图像和标签,以及一个包含 1,000 张测试图像和标签的额外文件。
我们来下载 Python 版的 CIFAR-10 数据集,请访问此链接(注意:不使用 TensorFlow/Keras 的原因是展示在需要时如何不依赖额外的 Python 包)。请记下您保存和提取数据集的硬盘路径。
以下代码加载数据集文件并返回训练和测试图像以及标签
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
从 pickle 导入 加载 从 numpy 导入 数组, newaxis def load_images(路径): # 创建空列表来存储图像和标签 imgs = [] labels = [] # 遍历数据集文件 for 批次 in 范围(5): # 指定训练数据的路径 train_path_batch = path + 'data_batch_' + str(batch + 1) # 从数据集文件中提取训练图像和标签 train_imgs_batch, train_labels_batch = extract_data(train_path_batch) # 存储训练图像 imgs.append(train_imgs_batch) train_imgs = 数组(imgs).reshape(-1, 3072) # 存储训练标签 labels.append(train_labels_batch) train_labels = 数组(labels).reshape(-1, 1) # 指定测试数据的路径 test_path_batch = path + 'test_batch' # 从数据集文件中提取测试图像和标签 test_imgs, test_labels = extract_data(test_path_batch) test_labels = 数组(test_labels)[:, newaxis] 返回 train_imgs, train_labels, test_imgs, test_labels def extract_data(路径): # 打开 pickle 文件并返回一个字典 with open(path, 'rb') as fo: dict = load(fo, encoding='bytes') # 提取字典值 dict_values = 列表(dict.values()) # 提取图像和标签 imgs = dict_values[2] labels = dict_values[1] 返回 imgs, labels |
重要的是要记住,使用更大、更多样化的数据集(如 CIFAR-10)而不是更简单的数据集(如数字数据集)来测试不同模型的折衷方案是,前者上的训练可能更耗时。
加载数据集
让我们尝试调用上面创建的函数。
我将属于数字数据集的代码与属于 CIFAR-10 数据集的代码分成了两个不同的 Python 脚本,分别命名为 digits_dataset.py 和 cifar_dataset.py
|
1 2 3 4 5 6 7 8 9 10 11 |
从 digits_dataset 导入 split_images, split_data 从 cifar_dataset 导入 加载_图像 # 加载数字图像 img, sub_imgs = split_images('Images/digits.png', 20) # 从数字图像获取训练和测试数据集 digits_train_imgs, digits_train_labels, digits_test_imgs, digits_test_labels = split_data(20, sub_imgs, 0.8) # 从 CIFAR-10 数据集获取训练和测试数据集 cifar_train_imgs, cifar_train_labels, cifar_test_imgs, cifar_test_labels = load_images('Images/cifar-10-batches-py/') |
注意:不要忘记将上述代码中的路径更改为您保存您的数据文件的位置。
在后续的教程中,我们将看到如何将这些数据集与不同的机器学习技术结合使用,首先了解如何将数据集图像转换为特征向量,作为用于机器学习的预处理步骤之一。
想开始学习 OpenCV 机器学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
书籍
- 使用 Python 精通 OpenCV 4, 2019.
网站
- OpenCV,https://opencv.ac.cn/
总结
在本教程中,您学习了如何下载和提取 OpenCV 数字数据集和 CIFAR-10 数据集,以便在 OpenCV 中实践机器学习。
具体来说,你学到了:
- 如何下载和提取 OpenCV 数字数据集。
- 如何在不依赖其他 Python 包(例如 TensorFlow)的情况下下载和提取 CIFAR-10 数据集。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块

")




暂无评论。