不平衡分类作为一项预测建模任务,之所以具有挑战性,主要是因为其类别分布严重倾斜。
这导致传统机器学习模型和假定类别分布平衡的评估指标性能不佳。
然而,分类数据集还有其他特性,这些特性不仅对预测建模构成挑战,而且在对不平衡数据集建模时还会增加或加剧难度。
在本教程中,您将发现加剧不平衡分类挑战的数据特性。
完成本教程后,您将了解:
- 不平衡分类之所以特别困难,是因为类别分布严重倾斜和误分类成本不均。
- 不平衡分类的难度因数据集大小、标签噪声和数据分布等特性而加剧。
- 如何对不同数据集特性对建模难度造成的复合效应形成直觉。
通过我的新书《使用Python进行不平衡分类》启动您的项目,其中包括逐步教程和所有示例的Python源代码文件。
让我们开始吧。

使不平衡分类困难的问题特性
图片由Joshua Damasio提供,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 为什么不平衡分类是难题
- 数据集大小的复合效应
- 标签噪声的复合效应
- 数据分布的复合效应
为什么不平衡分类是难题
不平衡分类的定义是类别分布倾斜的数据集。
这通常以二元(两类)分类任务为例,其中大多数样本属于类别0,而类别1中只有少数样本。分布的严重程度可能从1:2、1:10、1:100甚至1:1000不等。
由于类别分布不平衡,大多数机器学习算法表现不佳,需要修改以避免在所有情况下简单地预测多数类别。此外,像分类这样的度量失去了意义,需要替代方法来评估不平衡样本的预测,例如ROC曲线下面积。
这是不平衡分类的根本挑战。
- 倾斜的类别分布
复杂性来自样本所处的领域。
多数类通常代表领域中的正常情况,而少数类则代表异常情况,例如故障、欺诈、异常值、异常、疾病状态等。因此,误分类错误的解释可能因类别而异。
例如,将多数类中的样本错误分类为少数类中的样本(称为假阳性)通常是不希望发生的,但其严重性低于将少数类中的样本分类为属于多数类(所谓的假阴性)。
这被称为误分类错误的成本敏感性,是不平衡分类的第二个基本挑战。
- 误分类成本不均
这两个方面,即倾斜的类别分布和成本敏感性,通常在描述不平衡分类的难度时被提及。
然而,分类问题还有其他特性,当这些特性与上述属性结合时,会加剧其影响。这些是分类预测建模的一般特性,它们放大了不平衡分类任务的难度。
类不平衡被广泛认为是分类的一个复杂因素。然而,一些研究也认为不平衡比率并不是从不平衡数据学习时性能下降的唯一原因。
——第253页,《从不平衡数据集中学习》,2018年。
有许多这样的特点,但其中三个最常见的可能包括
- 数据集大小。
- 标签噪声。
- 数据分布。
重要的是,不仅要承认这些特性,还要特别培养对它们影响的直觉。这将使您能够在自己的预测建模项目中选择和开发解决这些问题的技术。
理解这些数据内在特性及其与类别不平衡的关系,对于应用现有技术和开发新方法来处理不平衡数据至关重要。
——第253-254页,《从不平衡数据集中学习》,2018年。
在接下来的章节中,我们将仔细研究这些属性及其对不平衡分类的影响。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数据集大小的复合效应
数据集大小仅指从领域收集用于拟合和评估预测模型的样本数量。
通常,更多的数据更好,因为它提供了对领域的更多覆盖,也许会达到收益递减的点。
具体来说,更多的数据能更好地表示特征空间中特征的组合和方差,以及它们与类别标签的映射。由此,模型能够更好地学习和泛化类别边界,以便将来区分新样本。
如果多数类别与少数类别中的样本比例相对固定,那么我们期望随着数据集大小的增加,少数类别中的样本也会增加。
如果我们可以收集更多样本,那将是好事。
这通常是一个问题,因为数据收集困难或昂贵,我们通常收集和使用的数据比我们想要的要少得多。因此,这会极大地影响我们从少数类别中获取足够大或具有代表性的样本的能力。
分类中经常出现的一个问题是训练实例数量很少。这个问题,通常被称为数据稀缺或数据不足,与“密度不足”或“信息不足”有关。
——第261页,《从不平衡数据集中学习》,2018年。
例如,对于一个具有平衡类别分布的适度分类任务,我们可能对数千或数万个样本感到满意,以便开发、评估和选择模型。
一个包含10,000个样本的平衡二元分类将包含5,000个每个类别的样本。一个具有1:100分布且样本数量相同的不平衡数据集将只有100个少数类别的样本。
因此,数据集大小极大地影响了不平衡分类任务,通常认为大型的数据集,在处理不平衡分类问题时,实际上可能不够大。
如果没有足够大的训练集,分类器可能无法泛化数据的特征。此外,分类器也可能过拟合训练数据,导致在样本外测试实例中表现不佳。
——第261页,《从不平衡数据集中学习》,2018年。
为了帮助理解,我们通过一个具体的工作示例来说明这一点。
我们可以使用make_classification() scikit-learn函数来创建一个给定大小的数据集,其中少数类与多数类的样本比例约为1:100(1%到99%)。
|
1 2 3 4 |
... # 创建数据集 X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) |
然后,我们可以创建数据集的散点图,并用不同的颜色标记每个类别的点,以了解样本的空间关系。
|
1 2 3 4 5 6 |
... # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() |
然后可以重复此过程,使用不同大小的数据集来显示类别不平衡如何受到视觉影响。我们将比较包含100、1,000、10,000和100,000个样本的数据集。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 针对1:100不平衡数据集改变数据集大小 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 数据集大小 sizes = [100, 1000, 10000, 100000] # 创建并绘制每种大小的数据集 for i in range(len(sizes)): # 确定数据集大小 n = sizes[i] # 创建数据集 X, y = make_classification(n_samples=n, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # 汇总类别分布 counter = Counter(y) print('Size=%d, Ratio=%s' % (n, counter)) # 定义子图 pyplot.subplot(2, 2, 1+i) pyplot.title('n=%d' % n) pyplot.xticks([]) pyplot.yticks([]) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() # 显示图 pyplot.show() |
运行示例将创建并绘制具有1:100类别分布的相同数据集,使用四种不同大小。
首先,显示每个数据集大小的类别分布。我们可以看到,对于100个样本的小数据集,我们只在少数类别中得到一个样本,正如我们所预期的。即使数据集中有100,000个样本,少数类别中也只有1,000个样本。
|
1 2 3 4 |
大小=100,比例=Counter({0: 99, 1: 1}) 大小=1000,比例=Counter({0: 990, 1: 10}) 大小=10000,比例=Counter({0: 9900, 1: 100}) 大小=100000,比例=Counter({0: 99000, 1: 1000}) |
为每个不同大小的数据集创建散点图。
我们可以看到,直到样本量非常大时,类别分布的潜在结构才变得明显。
这些图强调了数据集大小在不平衡分类中的关键作用。很难看出一个给定990个多数类样本和10个少数类样本的模型,如何能期望在绘制100,000个样本后所描绘的相同问题上表现良好。
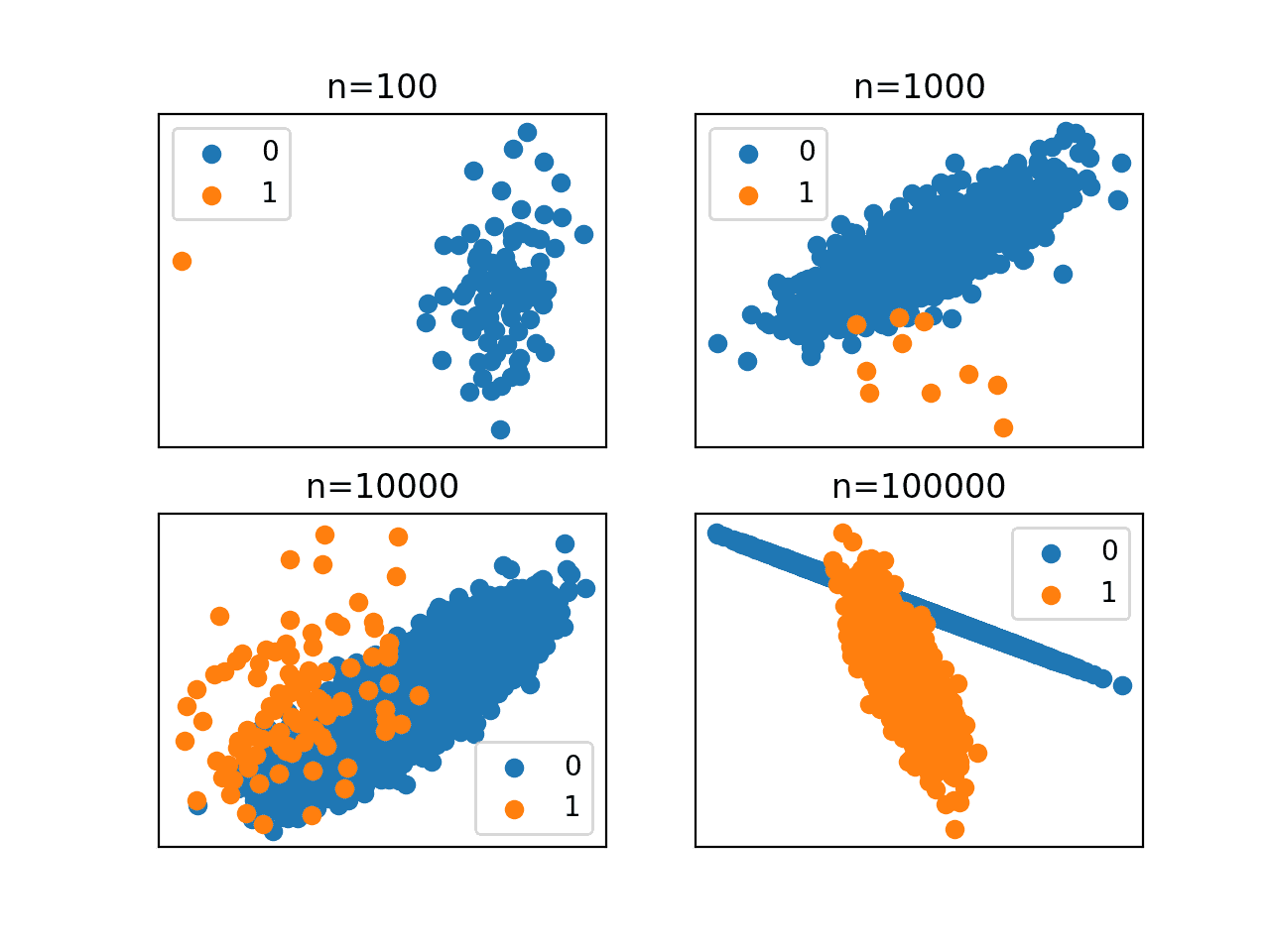
不同数据集大小的不平衡分类数据集散点图
标签噪声的复合效应
标签噪声指的是属于一个类别但被分配到另一个类别的样本。
这使得大多数机器学习算法难以确定特征空间中的类别边界,而且这种难度通常与标签中噪声的百分比成正比。
文献中区分了两种噪声:特征(或属性)噪声和类别噪声。类别噪声通常被认为比属性噪声对机器学习的危害更大……类别噪声以某种方式影响观察到的类别值(例如,通过某种方式将少数类实例的标签翻转为多数类标签)。
——第264页,《从不平衡数据集中学习》,2018年。
原因往往是问题领域固有的,例如类别边界上的模糊观测,甚至数据采集中可能影响特征空间中任何地方观测的错误。
对于不平衡分类,噪声标签的影响更为显著。
鉴于正类中的样本如此之少,一些样本因噪声而丢失,会减少关于少数类的信息量。
此外,多数类中的样本被错误地标记为少数类,可能会导致少数类出现断裂或碎片化,而由于缺乏观测,少数类本身已经很稀疏。
我们可以想象,如果类别边界上存在模糊的样本,我们可以识别、删除或纠正它们。在特征空间中,多数类密度高的区域中被标记为少数类的样本也可能很容易识别、删除或纠正。
当特征空间中两个类别的观测值都稀疏时,这个问题通常变得特别困难,尤其是对于不平衡分类。在这些情况下,未经修改的机器学习算法将倾向于多数类别来定义类别边界,而牺牲少数类别。
被错误标记的少数类实例将导致感知到的不平衡比率增加,并在少数类的类区域内引入错误标记的噪声实例。另一方面,被错误标记的多数类实例可能会导致学习算法或不平衡处理方法将注意力集中在输入空间的错误区域。
——第264页,《从不平衡数据集中学习》,2018年。
我们可以举一个例子来体会这种挑战。
我们可以将数据集大小和1:100的类别比例保持不变,并改变标签噪声量。这可以通过设置`make_classification()`函数的"flip_y"参数来实现,该参数表示每个类别中要更改或翻转标签的样本百分比。
我们将探讨从0%、1%、5%和7%的变化。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 针对1:100不平衡数据集改变标签噪声 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 标签噪声比率 noise = [0, 0.01, 0.05, 0.07] # 创建并绘制具有不同标签噪声的数据集 for i in range(len(noise)): # 确定标签噪声 n = noise[i] # 创建数据集 X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=n, random_state=1) # 汇总类别分布 counter = Counter(y) print('Noise=%d%%, Ratio=%s' % (int(n*100), counter)) # 定义子图 pyplot.subplot(2, 2, 1+i) pyplot.title('noise=%d%%' % int(n*100)) pyplot.xticks([]) pyplot.yticks([]) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() # 显示图 pyplot.show() |
运行示例将创建并绘制具有1:100类别分布的相同数据集,使用四种不同程度的标签噪声。
首先,为每个具有不同标签噪声的数据集打印类别分布。我们可以看到,正如我们所预期的,随着噪声的增加,少数类别中的样本数量也增加了,其中大多数都被错误标记。
我们可能会预期,7%标签噪声下少数类别中额外增加的30个样本,对于试图在特征空间中定义清晰类别边界的模型来说,将具有相当大的破坏性。
|
1 2 3 4 |
噪声=0%,比例=Counter({0: 990, 1: 10}) 噪声=1%,比例=Counter({0: 983, 1: 17}) 噪声=5%,比例=Counter({0: 963, 1: 37}) 噪声=7%,比例=Counter({0: 959, 1: 41}) |
为每个具有不同标签噪声的数据集创建散点图。
在这个具体案例中,我们没有看到许多在类别边界上混淆的例子。相反,我们可以看到,随着标签噪声的增加,少数类别(蓝色区域中的橙色点)的大量样本数量增加,这代表了在建模之前应该识别并从数据集中移除的假阳性。
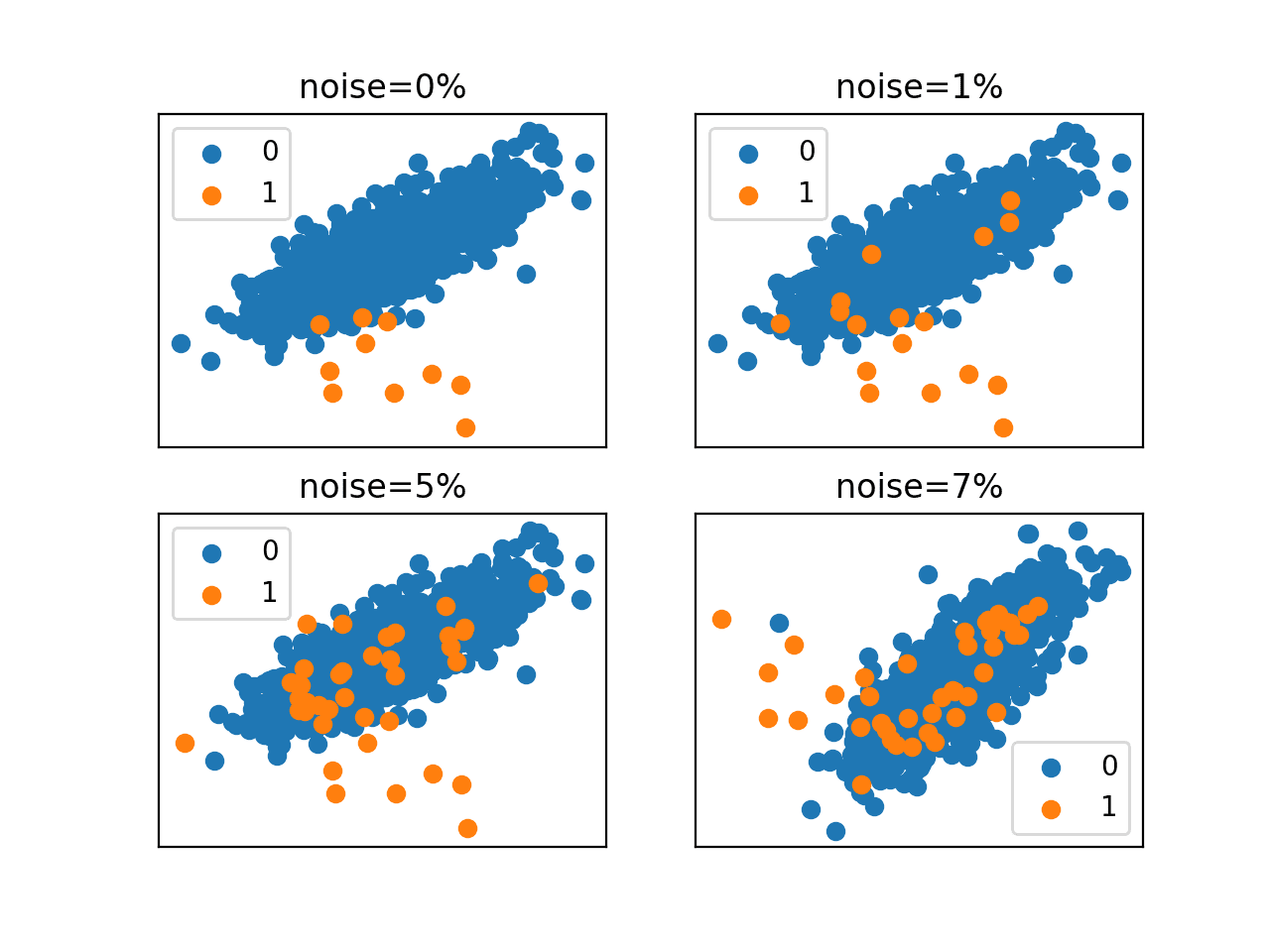
具有不同标签噪声的不平衡分类数据集散点图
数据分布的复合效应
另一个重要的考虑因素是特征空间中样本的分布。
如果我们从空间角度思考特征空间,我们可能希望一个类别中的所有样本都位于空间的一个部分,而另一个类别中的样本则出现在空间的另一个部分。
如果出现这种情况,我们就具有良好的类别可分离性,机器学习模型可以绘制清晰的类别边界并实现良好的分类性能。这对于具有平衡或不平衡类别分布的数据集都适用。
这很少发生,更常见的是每个类别都有多个“概念”,导致特征空间中出现多个不同的样本组或簇。
……通常,一个类别背后的“概念”会分裂成几个子概念,散布在输入空间中。
——第255页,《从不平衡数据集中学习》,2018年。
这些分组在形式上被称为“分离集”,源于规则系统中的一个定义,指覆盖由子概念组成的案例组的规则。一个小的分离集是指在训练数据集中关联或“覆盖”少量样本的分离集。
从示例中学习的系统通常无法为每个概念创建纯粹的合取定义。相反,它们会创建一个由几个析取词组成的定义,其中每个析取词都是原始概念的子概念的合取定义。
——《概念学习与小析取词问题》,1989年。
这种分组使得类别可分离性变得困难,需要识别每个组或簇并将其隐式或显式地包含在类别边界的定义中。
在不平衡数据集的情况下,如果少数类在特征空间中具有多个概念或簇,这是一个特殊问题。这是因为此类样本的密度已经很稀疏,而且在样本很少的情况下很难辨别独立的聚类。它可能看起来像一个大的稀疏聚类。
这种异质性在基于分而治之策略的算法中尤其成问题,其中子概念导致小析取词的创建。
——第255页,《从不平衡数据集中学习》,2018年。
例如,我们可以考虑描述患者健康(多数类别)或患病(少数类别)的数据。该数据可能包含多种不同类型的疾病,并且可能存在相似疾病的组,但如果病例很少,那么类别内的任何分组或概念可能都不明显,并且可能看起来像一组与健康病例混合的扩散集。
为了具体说明这一点,我们可以看一个例子。
我们可以使用数据集中的聚类数量作为“概念”的代理,并比较每个类别有一个聚类样本的数据集和每个类别有两个聚类样本的数据集。
这可以通过修改用于创建数据集的`make_classification()`函数的“n_clusters_per_class”参数来实现。
我们期望在不平衡数据集中,例如1:100的类别分布,聚类数量的增加对多数类别来说是明显的,但对少数类别则不然。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 针对1:100不平衡数据集改变聚类数量 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 聚类数量 clusters = [1, 2] # 创建并绘制具有不同聚类数量的数据集 for i in range(len(clusters)): c = clusters[i] # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=c, weights=[0.99], flip_y=0, random_state=1) counter = Counter(y) # 定义子图 pyplot.subplot(1, 2, 1+i) pyplot.title('Clusters=%d' % c) pyplot.xticks([]) pyplot.yticks([]) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() # 显示图 pyplot.show() |
运行该示例会创建并绘制相同的数据集,该数据集具有 1:100 的类别分布,并使用两种不同数量的簇。
在第一个散点图(左)中,我们可以看到每个类别有一个簇。多数类别(蓝色)很明显有一个簇,而少数类别(橙色)的结构不太明显。在第二个图(右)中,我们再次清楚地看到多数类别有两个簇,而少数类别(橙色)的结构再次是分散的,并且不明显样本是从两个簇中提取的。
这突出了数据集大小与揭示少数类别中示例的潜在密度或分布的能力之间的关系。在示例如此之少的情况下,机器学习模型进行泛化是具有挑战性的,如果不是非常成问题的话。
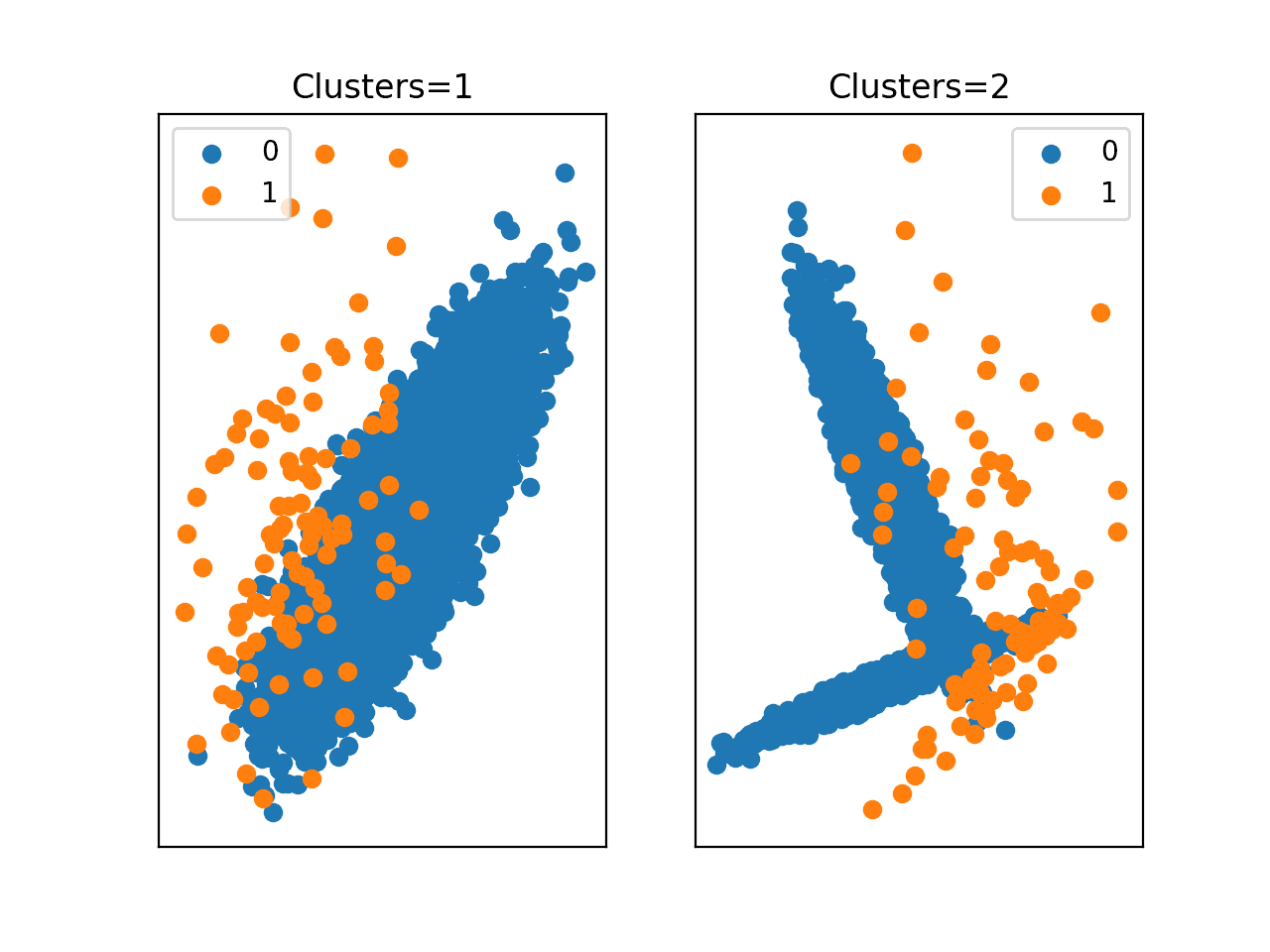
具有不同簇数的非平衡分类数据集的散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 概念学习与小分离问题, 1989.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
总结
在本教程中,您发现了加剧非平衡分类挑战的数据特征。
具体来说,你学到了:
- 不平衡分类之所以特别困难,是因为类别分布严重倾斜和误分类成本不均。
- 不平衡分类的难度因数据集大小、标签噪声和数据分布等特性而加剧。
- 如何对不同数据集特性对建模难度造成的复合效应形成直觉。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






你好 Jason,
我有一个问题,我正在使用时间序列进行预测(使用 FP Prophet)。
使用时间序列的算法是回归吗?是什么类型的回归?
谢谢,
Marco
它是时间序列预测,这是一种特殊的回归类型,其中观测值按时间排序。
谢谢,这篇文章帮了我很多!
谢谢。很高兴你喜欢。
你好 Jason,
给定时间序列,是否有算法可以预测产量(除了 fbprophet – Facebook 的时间序列预测)?
Keras 或 Scikit-Learn 可以做到吗?
谢谢
是的,这里有几十个例子
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,很棒的文章。
您认为不确定性和主动学习是解决这个问题的好方法吗?它允许使用较少数量的训练数据并尝试以逐步迭代的方式平衡数据集。您尝试过吗?
谢谢!
没有万灵药。我们必须针对给定任务测试多种不同的方法才能发现哪种方法效果最好。
谢谢 Jason 的这篇文章,它非常清晰
您对重采样技术有什么看法?
它们是解决这个问题的良好方案吗?
重采样对某些问题可能有效
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
你好 Jason,
我有一个数据集,少数类别的比率为 1003,总样本为 2921
您认为它不平衡吗?
当然可以。
嗨,Jason,
很棒的教程,对许多问题都有即时应用,例如新疾病(例如 Covid-19)的胸部 X 射线图像诊断,其中幸运的是它仍然是一个少数类别,而不是其他经典的肺部疾病分类。
您能否为我们列出或总结您最好的机器学习教程,其中会很好地解释解决这些不平衡数据集的最有效技术?
我会说现在不平衡比例通常在 1:10 到 1:100 之间!
是的,从这里开始
https://machinelearning.org.cn/start-here/#imbalanced
嗨,Jason,
为了计算不平衡比率,我使用香农熵,它给出一个介于 0(高度不平衡数据)- 1(平衡数据)之间的分数。但是,它没有捕捉到数据大小的影响,即 1:10、10:100、100:1000 数据集的影响。
在分数中捕捉它的最佳方法是什么?
谢谢!
没有最好的分数,只有对同一个问题的不同处理方法。
我见过许多不同的评分尝试,也许可以查阅文献。
1. 数据缩放。
2. 使用分层 K 折交叉验证,假设 10 次交叉验证能解决问题吗?
解决什么问题?抱歉,我不明白。也许您可以详细说明您的问题?
尊敬的Jason博士,
我们如何使用散点图来可视化来自 Kaggle 或 UCI 等存储库的真实世界数据集的数据分布?例如,在 pandas 数据帧的一行中,当真实世界数据集具有 Y 值但数据帧的一行中有许多 X 实例时,X 轴和 Y 轴应该是什么?当我们处理整个数据集的多行时怎么办?我们应该如何处理数据集以可视化数据集中存在的不平衡?
您可以使用散点图绘制每对变量,并按类别标签为点着色,但是如果输入变量很多,您可能会有很多图。
更好的方法是将每个类别中的示例数量汇总为计数和占数据集大小的百分比。
尊敬的 Jason 博士,感谢您的回复。我能得到您建议的方法的示例或任何展示此方法的参考资料吗?我希望学习更多,因为我对您建议的方法理解得不太好。对于二元分类,我们有两个类别。您是指我们可以绘制目标变量的积极和消极计数与数据集大小的百分比吗?它是如何工作的?
是的,您可以在博客上找到数百个示例,请使用搜索框。
这里的工作示例和教程可能会有所帮助
https://machinelearning.org.cn/start-here/#imbalanced
你好,
为了处理不平衡分类,我们可以收集来自近期历史的真实少数类别数据吗?
当然可以。