对于某些不平衡分类任务,少数类上的误分类错误比其他类型的预测错误更重要。
一个例子是银行客户分类问题,即他们是否应该获得贷款。将贷款发放给被标记为良好客户的不良客户,给银行带来的成本要高于拒绝向被标记为不良客户的良好客户发放贷款的成本。
这需要仔细选择一个性能指标,该指标既能促进总体上最小化误分类错误,又能在不同类型的误分类错误中优先最小化某一种。
德国信贷数据集是一个标准的不平衡分类数据集,它具有不同的误分类错误成本特性。在此数据集上评估的模型可以使用Fbeta-Measure进行评估,该指标提供了一种量化模型总体性能的方法,并捕捉了某种误分类错误比另一种成本更高这一要求。
在本教程中,您将学习如何针对不平衡的德国信贷分类数据集开发和评估模型。
完成本教程后,您将了解:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何评估一系列机器学习模型,并使用数据欠采样技术提高其性能。
- 如何拟合最终模型并使用它来预测特定案例的类别标签。
通过我的新书《使用 Python 进行不平衡分类》启动您的项目,其中包括逐步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2020年2月更新:增加了关于进一步模型改进的部分。
- 2021年1月更新:更新了API文档链接。

开发不平衡分类模型以预测信贷良好和不良
图片来源:AL Nieves,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 德国信贷数据集
- 探索数据集
- 模型测试和基线结果
- 评估模型
- 评估机器学习算法
- 评估欠采样
- 进一步的模型改进
- 对新数据进行预测
德国信贷数据集
在此项目中,我们将使用一个标准的不平衡机器学习数据集,称为“德国信贷”数据集或简称“德国”。
该数据集是Statlog项目的一部分,该项目是20世纪90年代在欧洲发起的一项倡议,旨在评估和比较大量(当时)机器学习算法在各种不同分类任务上的表现。该数据集的作者是Hans Hofmann。
不同学科之间的碎片化几乎肯定阻碍了交流和进步。StatLog项目旨在通过选择不考虑历史渊源的分类程序,在大规模和商业上重要的问题上进行测试,从而确定各种技术在多大程度上满足了行业需求,来打破这些隔阂。
— 第4页,《机器学习、神经网络和统计分类》,1994年。
德国信用数据集描述了客户的财务和银行详细信息,任务是确定客户是良好还是不良。假设该任务涉及预测客户是否会偿还贷款或信用。
该数据集包含1,000个示例和20个输入变量,其中7个是数值型(整数),13个是类别型。
- 现有活期账户状况
- 持续时间(月)
- 信用记录
- 目的
- 信用额度
- 储蓄账户
- 当前就业情况
- 可支配收入的百分比分期付款率
- 个人状况和性别
- 其他债务人
- 现住址自何时起
- 财产
- 年龄(岁)
- 其他分期付款计划
- 住房
- 在该银行现有信用卡的数量
- 职业
- 受抚养人数量
- 电话
- 外籍工人
一些分类变量具有序数关系,例如“储蓄账户”,尽管大多数没有。
有两个类别,1代表良好客户,2代表不良客户。良好客户是默认或负类,而不良客户是例外或正类。总共有70%的示例是良好客户,而其余30%的示例是不良客户。
- 良好客户:负类或多数类 (70%)。
- 不良客户:正类或少数类 (30%)。
数据集中提供了一个成本矩阵,对正类的每个误分类错误给予不同的惩罚。具体来说,对假阴性(将不良客户标记为良好)施加五倍的成本,对假阳性(将良好客户标记为不良)施加一倍的成本。
- 假阴性成本: 5
- 假阳性成本: 1
这表明预测任务的重点是正类,并且对银行或金融机构来说,将资金提供给不良客户比不将资金提供给良好客户的成本更高。在选择性能指标时必须考虑到这一点。
接下来,我们仔细看看数据。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
探索数据集
首先,下载数据集并将其保存到当前工作目录,文件名为“german.csv”。
查看文件内容。
文件的前几行应如下所示
|
1 2 3 4 5 6 |
A11,6,A34,A43,1169,A65,A75,4,A93,A101,4,A121,67,A143,A152,2,A173,1,A192,A201,1 A12,48,A32,A43,5951,A61,A73,2,A92,A101,2,A121,22,A143,A152,1,A173,1,A191,A201,2 A14,12,A34,A46,2096,A61,A74,2,A93,A101,3,A121,49,A143,A152,1,A172,2,A191,A201,1 A11,42,A32,A42,7882,A61,A74,2,A93,A103,4,A122,45,A143,A153,1,A173,2,A191,A201,1 A11,24,A33,A40,4870,A61,A73,3,A93,A101,4,A124,53,A143,A153,2,A173,2,A191,A201,2 ... |
我们可以看到分类列以 Axxx 格式编码,其中“x”是不同标签的整数。这将需要对分类变量进行一次性热编码。
我们还可以看到数值变量具有不同的尺度,例如第二列中的6、48和12,以及第五列中的1169、5951等。这表明对于那些对尺度敏感的算法,需要对整数列进行尺度缩放。
目标变量或类别是最后一列,包含值1和2。这些值需要分别编码为0和1,以满足不平衡二元分类任务的一般期望,即0表示负例,1表示正例。
可以使用read_csv() Pandas 函数将数据集加载为 DataFrame,指定位置和没有标题行。
|
1 2 3 4 5 |
... # 定义数据集位置 文件名 = 'german.csv' # 将csv文件加载为数据框 数据框 = read_csv(文件名, header=None) |
加载后,我们可以通过打印DataFrame的形状来总结行数和列数。
|
1 2 3 |
... # 总结数据集的形状 print(dataframe.shape) |
我们还可以使用Counter对象总结每个类别的示例数量。
|
1 2 3 4 5 6 7 |
... # 总结类别分布 目标 = dataframe.values[:,-1] 计数器 = Counter(目标) 对于 k,v 在 计数器.items(): per = v / len(目标) * 100 print('类别=%d, 计数=%d, 百分比=%.3f%%' % (k, v, per)) |
总而言之,下面列出了加载和汇总数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 加载并汇总数据集 from pandas import read_csv from collections import Counter # 定义数据集位置 文件名 = 'german.csv' # 将csv文件加载为数据框 数据框 = read_csv(文件名, header=None) # 总结数据集的形状 print(dataframe.shape) # 总结类别分布 目标 = dataframe.values[:,-1] 计数器 = Counter(目标) 对于 k,v 在 计数器.items(): per = v / len(目标) * 100 print('类别=%d, 计数=%d, 百分比=%.3f%%' % (k, v, per)) |
运行示例首先加载数据集并确认行数和列数,即1,000行、20个输入变量和1个目标变量。
然后总结了类别分布,确认了良好客户和不良客户的数量以及少数类别和多数类别的案例百分比。
|
1 2 3 |
(1000, 21) 类别=1,计数=700,百分比=70.000% 类别=2,计数=300,百分比=30.000% |
我们还可以通过为每个数值输入变量创建直方图来查看它们的分布。
首先,我们可以通过对 DataFrame 调用select_dtypes() 函数来选择具有数值数据类型的列。然后我们可以从 DataFrame 中只选择这些列。我们期望有七个,加上数值类别标签。
|
1 2 3 4 5 |
... # 选择数值数据类型的列 num_ix = df.select_dtypes(包含=['int64', 'float64']).columns # 选择包含选定列的数据框子集 子集 = df[num_ix] |
然后,我们可以为每个数值输入变量创建直方图。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 创建数值输入变量的直方图 from pandas import read_csv from matplotlib import pyplot # 定义数据集位置 文件名 = 'german.csv' # 将csv文件加载为数据框 df = read_csv(文件名, header=None) # 选择数值数据类型的列 num_ix = df.select_dtypes(包含=['int64', 'float64']).columns # 选择包含选定列的数据框子集 子集 = df[num_ix] # 为每个数值变量创建直方图 ax = 子集.hist() # 禁用轴标签以避免混乱 对于 轴 在 ax.flatten(): axis.set_xticklabels([]) axis.set_yticklabels([]) # 显示绘图 pyplot.show() |
运行该示例将创建一个图形,其中包含数据集中七个输入变量和1个类标签的直方图子图。每个子图的标题表示 DataFrame 中的列号(例如,从0到20的零偏移)。
我们可以看到许多不同的分布,有些是高斯分布,另一些似乎是指数分布或离散分布。
根据建模算法的选择,我们预计将分布缩放到相同的范围将是有用的,并且可能需要使用一些幂变换。
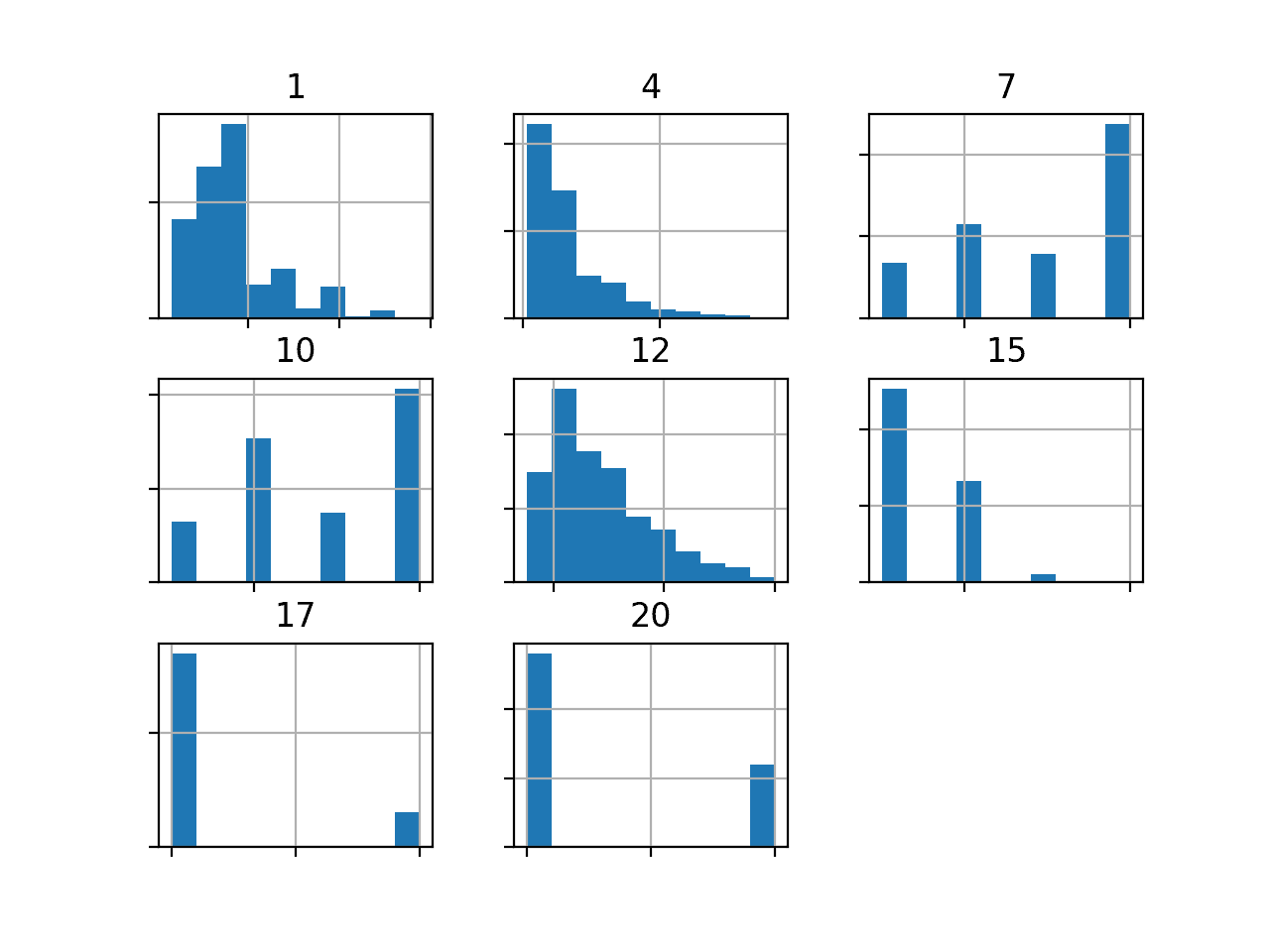
德国信用数据集中数值变量的直方图
现在我们已经审阅了数据集,接下来我们将开发一个测试工具来评估候选模型。
模型测试和基线结果
我们将使用重复分层 k 折交叉验证来评估候选模型。
k折交叉验证过程提供了一个很好的模型性能一般估计,它不会过于乐观偏倚,至少与单次训练-测试分割相比是这样。我们将使用k=10,这意味着每个折叠将包含大约1000/10或100个示例。
分层意味着每个折叠将包含相同比例的样本,即良好客户与不良客户的比例约为70%到30%。重复意味着评估过程将执行多次,以帮助避免偶然结果并更好地捕捉所选模型的方差。我们将使用三次重复。
这意味着一个模型将被拟合和评估10 * 3或30次,并将报告这些运行的均值和标准差。
这可以通过使用RepeatedStratifiedKFold scikit-learn 类来实现。
我们将预测客户是否良好的类别标签。因此,我们需要一个适合评估预测类别标签的指标。
该任务的重点是正类(不良客户)。精确度和召回率是一个很好的起点。最大化精确度将最小化假阳性,最大化召回率将最小化模型预测中的假阴性。
- 精确率 = 真阳性 / (真阳性 + 假阳性)
- 召回率 = 真阳性 / (真阳性 + 假阴性)
使用 F-Measure 将计算精确度和召回率的调和平均值。这是一个很好的单一数字,可以用于比较和选择该问题上的模型。问题是假阴性比假阳性造成的损害更大。
- F 值 = (2 * 精确率 * 召回率) / (精确率 + 召回率)
请记住,此数据集上的假阴性是指不良客户被标记为良好客户并获得贷款的情况。假阳性是指良好客户被标记为不良客户并被拒绝贷款的情况。
- 假阴性:不良客户(类别1)被预测为良好客户(类别0)。
- 假阳性:良好客户(类别0)被预测为不良客户(类别1)。
假阴性对银行造成的成本高于假阳性。
- 成本(假阴性)> 成本(假阳性)
换句话说,我们对 F-measure 感兴趣,它将总结模型最小化正类误分类错误的能力,但我们希望模型在最小化假阴性方面优于最小化假阳性。
这可以通过使用 F-measure 的一个版本来实现,该版本计算精确度和召回率的加权调和平均值,但更偏向于高召回率而不是高精确率。这被称为Fbeta-measure,是 F-measure 的泛化,其中“beta”是一个参数,定义了两个分数的权重。
- Fbeta-Measure = ((1 + beta^2) * 精确率 * 召回率) / (beta^2 * 精确率 + 召回率)
Beta 值为 2 将更多地关注召回率而非精确率,并被称为 F2-measure。
- F2-Measure = ((1 + 2^2) * 精确率 * 召回率) / (2^2 * 精确率 + 召回率)
我们将使用此度量来评估德国信用数据集上的模型。这可以通过使用fbeta_score() scikit-learn 函数来实现。
我们可以定义一个函数来加载数据集并将列分为输入和输出变量。我们将对分类变量进行独热编码,并对目标变量进行标签编码。您可能还记得,独热编码用一个新列替换分类变量,该新列对应变量的每个值,并在该值对应的列中标记为1。
首先,我们必须将 DataFrame 拆分为输入和输出变量。
|
1 2 3 4 |
... # 分割输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] |
接下来,我们需要选择所有分类输入变量,然后应用独热编码,并保持数值变量不变。
这可以通过使用ColumnTransformer并定义将OneHotEncoder仅应用于分类变量的列索引来实现。
|
1 2 3 4 5 6 |
... # 选择分类特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns # 仅对分类特征进行独热编码 ct = ColumnTransformer([('o',OneHotEncoder(),cat_ix)], remainder='passthrough') X = ct.fit_transform(X) |
然后我们可以对目标变量进行标签编码。
|
1 2 3 |
... # 将目标变量标签编码为类别0和1 y = LabelEncoder().fit_transform(y) |
下面的 load_dataset() 函数将所有这些组合在一起,并加载和准备数据集以进行建模。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns # 仅对分类特征进行独热编码 ct = ColumnTransformer([('o',OneHotEncoder(),cat_ix)], remainder='passthrough') X = ct.fit_transform(X) # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X, y |
接下来,我们需要一个函数,它将使用 fbeta_score() 函数(beta 设置为 2)来评估一组预测。
|
1 2 3 |
# 计算f2分数 def f2(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) |
然后我们可以定义一个函数,该函数将评估数据集上的给定模型,并返回每个折叠和重复的 F2-Measure 分数列表。
下面的 evaluate_model() 函数实现了这一点,它将数据集和模型作为参数,并返回分数列表。
|
1 2 3 4 5 6 7 8 9 |
# 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) return scores |
最后,我们可以使用这个测试工具评估数据集上的基线模型。
预测少数类别的模型将获得最大召回率分数和基线精确率分数。这为该问题上的模型性能提供了一个基线,所有其他模型都可以与此进行比较。
这可以通过使用 scikit-learn 库中的DummyClassifier 类,并将“strategy”参数设置为“constant”,将“constant”参数设置为少数类别的“1”来实现。
|
1 2 3 |
... # 定义参考模型 模型 = DummyClassifier(策略='constant', 常数=1) |
一旦模型被评估,我们可以直接报告 F2-Measure 分数的均值和标准差。
|
1 2 3 4 5 |
... # 评估模型 分数 = evaluate_model(X, y, model) # 总结性能 print('平均 F2: %.3f (%.3f)' % (mean(scores), std(scores))) |
综合起来,加载德国信用数据集、评估基线模型并报告性能的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# 德国信用数据集的测试工具和基线模型评估 from collections import Counter from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from sklearn.dummy import DummyClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns # 仅对分类特征进行独热编码 ct = ColumnTransformer([('o',OneHotEncoder(),cat_ix)], remainder='passthrough') X = ct.fit_transform(X) # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) 返回 X, y # 计算f2分数 def f2(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y = load_dataset(full_path) # 总结已加载的数据集 print(X.shape, y.shape, Counter(y)) # 定义参考模型 模型 = DummyClassifier(策略='constant', 常数=1) # 评估模型 分数 = evaluate_model(X, y, model) # 总结性能 print('平均 F2: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例首先加载并总结数据集。
我们可以看到加载了正确的行数,并且通过对分类输入变量进行独热编码,我们将输入变量的数量从20个增加到61个。这表明13个分类变量被编码成了总共54列。
重要的是,我们可以看到类标签具有正确的整数映射,0代表多数类,1代表少数类,这符合不平衡二元分类数据集的惯例。
接下来,报告了 F2-Measure 分数的平均值。
在这种情况下,我们可以看到基线算法的 F2-Measure 约为 0.682。这个分数提供了模型技能的下限;任何达到平均 F2-Measure 高于 0.682 的模型都具有技能,而分数低于此值的模型在此数据集上不具有技能。
|
1 2 |
(1000, 61) (1000,) Counter({0: 700, 1: 300}) 平均 F2:0.682 (0.000) |
现在我们有了测试工具和性能基线,我们可以开始评估该数据集上的一些模型。
评估模型
在本节中,我们将使用上一节中开发的测试工具,评估数据集上的一系列不同技术。
目标是演示如何系统地解决问题,并展示一些针对不平衡分类问题设计的技术的能力。
报告的性能良好,但尚未高度优化(例如,超参数未进行调整)。
你能做得更好吗?如果你能使用相同的测试工具实现更好的 F2-Measure 性能,我很乐意听到。请在下面的评论中告诉我。
评估机器学习算法
我们首先评估数据集上混合的概率机器学习模型。
在数据集上对一系列不同的线性和非线性算法进行快速检查,可以很快地发现哪些效果好值得进一步关注,哪些效果不好。
我们将评估以下机器学习模型在德国信用数据集上的表现:
- 逻辑回归 (LR)
- 线性判别分析 (LDA)
- 朴素贝叶斯 (NB)
- 高斯过程分类器 (GPC)
- 支持向量机 (SVM)
我们将主要使用默认的模型超参数。
我们将依次定义每个模型并将它们添加到一个列表中,以便我们可以按顺序评估它们。下面的 get_models() 函数定义了要评估的模型列表,以及用于稍后绘制结果的模型简称列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义要测试的模型 定义 获取_模型(): 模型, 名称 = list(), list() # LR models.append(LogisticRegression(solver='liblinear')) names.append('LR') # LDA models.append(LinearDiscriminantAnalysis()) names.append('LDA') # NB models.append(GaussianNB()) names.append('NB') # GPC models.append(GaussianProcessClassifier()) names.append('GPC') # SVM models.append(SVC(gamma='scale')) names.append('SVM') return models, names |
然后我们可以依次枚举模型列表并评估每个模型,存储分数以供后续评估。
我们将对分类输入变量进行独热编码,就像上一节中那样,在这种情况下,我们将对数值输入变量进行归一化。这最好在交叉验证评估过程的每个折叠中,使用MinMaxScaler来执行。
实现此功能的一种简单方法是使用管道(Pipeline),其中第一步是列转换器(ColumnTransformer),它仅对分类变量应用独热编码器(OneHotEncoder),并仅对数值输入变量应用最小-最大缩放器(MinMaxScaler)。为此,我们需要分类和数值输入变量的列索引列表。
我们可以更新 load_dataset() 函数,使其除了返回数据集的输入和输出元素外,还返回列索引。此函数的更新版本如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix |
然后我们可以调用此函数以获取数据以及分类和数值变量的列表。
|
1 2 3 4 5 |
... # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) |
这可以用来准备一个 Pipeline,在评估每个模型之前将其包装起来。
首先,定义 ColumnTransformer,它指定对每种类型的列应用什么转换,然后将其作为 Pipeline 的第一步,Pipeline 的最后一步是将被拟合和评估的特定模型。.
|
1 2 3 4 5 6 7 8 9 |
... # 评估每个模型 对于 i 在 range(len(models)): # 独热编码分类变量,归一化数值变量 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 将模型包装在一个管道中 pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) |
我们可以总结每个算法的平均 F2-Measure;这将有助于直接比较算法。
|
1 2 3 |
... # 总结并存储 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) |
在运行结束时,我们将为每个算法的结果样本创建一个单独的箱线图。
这些图将使用相同的 y 轴刻度,以便我们可以直接比较结果的分布。
|
1 2 3 4 |
... # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
综合起来,在德国信用数据集上评估一系列机器学习算法的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
# 在德国信用数据集上进行机器学习算法的抽查 from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.svm import SVC # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 计算f2-measure def f2_measure(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2_measure) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义要测试的模型 定义 获取_模型(): 模型, 名称 = list(), list() # LR models.append(LogisticRegression(solver='liblinear')) names.append('LR') # LDA models.append(LinearDiscriminantAnalysis()) names.append('LDA') # NB models.append(GaussianNB()) names.append('NB') # GPC models.append(GaussianProcessClassifier()) names.append('GPC') # SVM models.append(SVC(gamma='scale')) names.append('SVM') return models, names # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义模型 模型, 名称 = get_models() results = list() # 评估每个模型 对于 i 在 range(len(models)): # 独热编码分类变量,归一化数值变量 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 将模型包装在一个管道中 pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) results.append(scores) # 总结并存储 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例将依次评估每个算法并报告其平均F2-Measure和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到所测试的模型中没有一个的 F2-measure 高于在所有情况下预测多数类的默认值(0.682)。所有模型都没有技能。这令人惊讶,尽管这表明两个类别之间的决策边界可能存在噪声。
|
1 2 3 4 5 |
>LR 0.497 (0.072) >LDA 0.519 (0.072) >NB 0.639 (0.049) >GPC 0.219 (0.061) >SVM 0.436 (0.077) |
创建了一个图,为每个算法的结果样本显示了一个箱线图。箱形显示了数据的中间50%,每个箱形中间的橙色线显示了样本的中位数,每个箱形中的绿色三角形显示了样本的平均值。
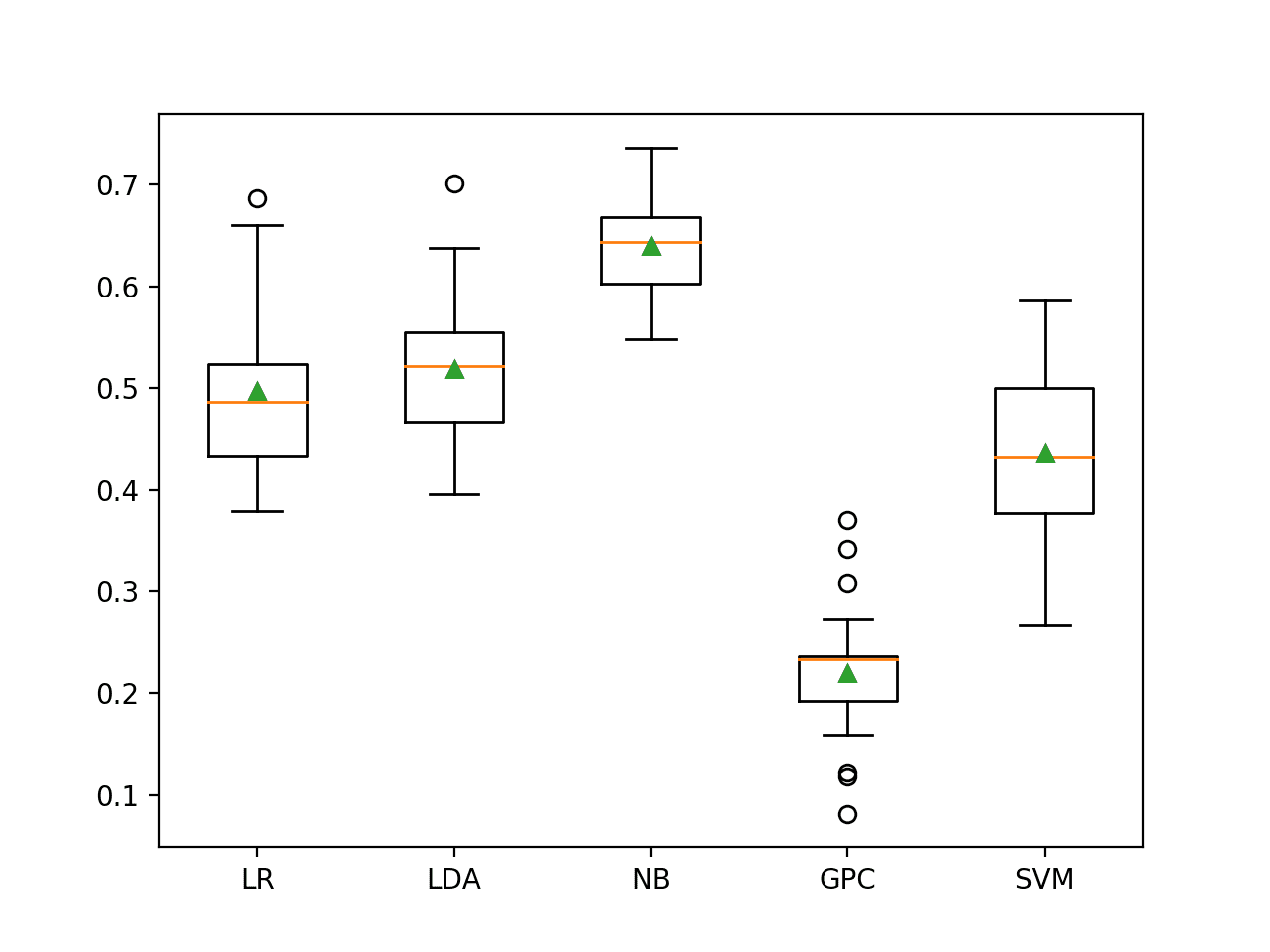
机器学习模型在不平衡德国信用数据集上的箱线图
现在我们有了一些结果,让我们看看是否可以通过欠采样来改进它们。
评估欠采样
在解决不平衡分类任务时,欠采样可能是使用最少的技术,因为大多数焦点都放在使用 SMOTE 对多数类进行过采样。
欠采样可以帮助从决策边界沿线的多数类中移除样本,这些样本会使分类算法面临挑战。
在这个实验中,我们将测试以下欠采样算法:
- Tomek链接 (TL)
- 编辑最近邻 (ENN)
- 重复编辑最近邻 (RENN)
- 单边选择 (OSS)
- 邻域清理规则 (NCR)
Tomek Links 和 ENN 方法选择从多数类中删除的样本,而 OSS 和 NCR 都选择要保留和删除的样本。为了保持简单,我们将使用逻辑回归算法的平衡版本来测试每种欠采样方法。
可以更新上一节中的 get_models() 函数,以返回与逻辑回归算法一起测试的欠采样技术列表。我们使用 imbalanced-learn 库中这些算法的实现。
下面列出了定义欠采样方法的 get_models() 函数的更新版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义要测试的欠采样模型 定义 获取_模型(): 模型, 名称 = list(), list() # TL models.append(TomekLinks()) names.append('TL') # ENN models.append(EditedNearestNeighbours()) names.append('ENN') # RENN models.append(RepeatedEditedNearestNeighbours()) names.append('RENN') # OSS models.append(OneSidedSelection()) names.append('OSS') # NCR models.append(NeighbourhoodCleaningRule()) names.append('NCR') return models, names |
scikit-learn 提供的Pipeline不了解欠采样算法。因此,我们必须使用imbalanced-learn 库提供的Pipeline实现。
与上一节一样,管道的第一步将是对分类变量进行独热编码和对数值变量进行归一化,最后一步将是拟合模型。这里,中间一步将是欠采样技术,仅在训练数据集上交叉验证评估中正确应用。
|
1 2 3 4 5 6 7 8 9 |
... # 定义要评估的模型 模型 = LogisticRegression(求解器='liblinear', class_weight='balanced') # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后欠采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', models[i]), ('m',model)]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) |
综合起来,以下是使用不同欠采样方法对德国信用数据集上的逻辑回归进行评估的完整示例。
我们期望欠采样能提高逻辑回归的技能,理想情况下高于在所有情况下预测少数类别的基线性能。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
# 使用逻辑回归在不平衡德国信用数据集上评估欠采样 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from matplotlib import pyplot from sklearn.linear_model import LogisticRegression from imblearn.pipeline import Pipeline from imblearn.under_sampling import TomekLinks from imblearn.under_sampling import EditedNearestNeighbours from imblearn.under_sampling import RepeatedEditedNearestNeighbours from imblearn.under_sampling import NeighbourhoodCleaningRule from imblearn.under_sampling import OneSidedSelection # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 计算f2-measure def f2_measure(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2_measure) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义要测试的欠采样模型 定义 获取_模型(): 模型, 名称 = list(), list() # TL models.append(TomekLinks()) names.append('TL') # ENN models.append(EditedNearestNeighbours()) names.append('ENN') # RENN models.append(RepeatedEditedNearestNeighbours()) names.append('RENN') # OSS models.append(OneSidedSelection()) names.append('OSS') # NCR models.append(NeighbourhoodCleaningRule()) names.append('NCR') return models, names # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义模型 模型, 名称 = get_models() results = list() # 评估每个模型 对于 i 在 range(len(models)): # 定义要评估的模型 model = LogisticRegression(solver='liblinear', class_weight='balanced') # 独热编码分类变量,归一化数值变量 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后欠采样,然后拟合模型 pipeline = Pipeline(steps=[('t',ct), ('s', models[i]), ('m',model)]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) results.append(scores) # 总结并存储 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例会使用五种不同的欠采样技术评估逻辑回归算法。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到五种欠采样技术中有三种的F2-measure比基线0.682有所改进。具体来说是ENN、RENN和NCR,其中重复编辑最近邻表现最佳,F2-measure约为0.716。
结果表明,SMOTE 取得了最佳分数,F2-Measure 为 0.604。
|
1 2 3 4 5 |
>TL 0.669 (0.057) >ENN 0.706 (0.048) >RENN 0.714 (0.041) >OSS 0.670 (0.054) >NCR 0.693 (0.052) |
为每种评估过的欠采样技术创建了箱线图,显示它们通常具有相同的扩散。
令人鼓舞的是,对于表现良好的方法,盒子向上延伸到0.8左右,并且所有三种方法的均值和中位数都在0.7左右。这突出表明分布呈高偏斜,偶尔会被一些不好的评估拉低。
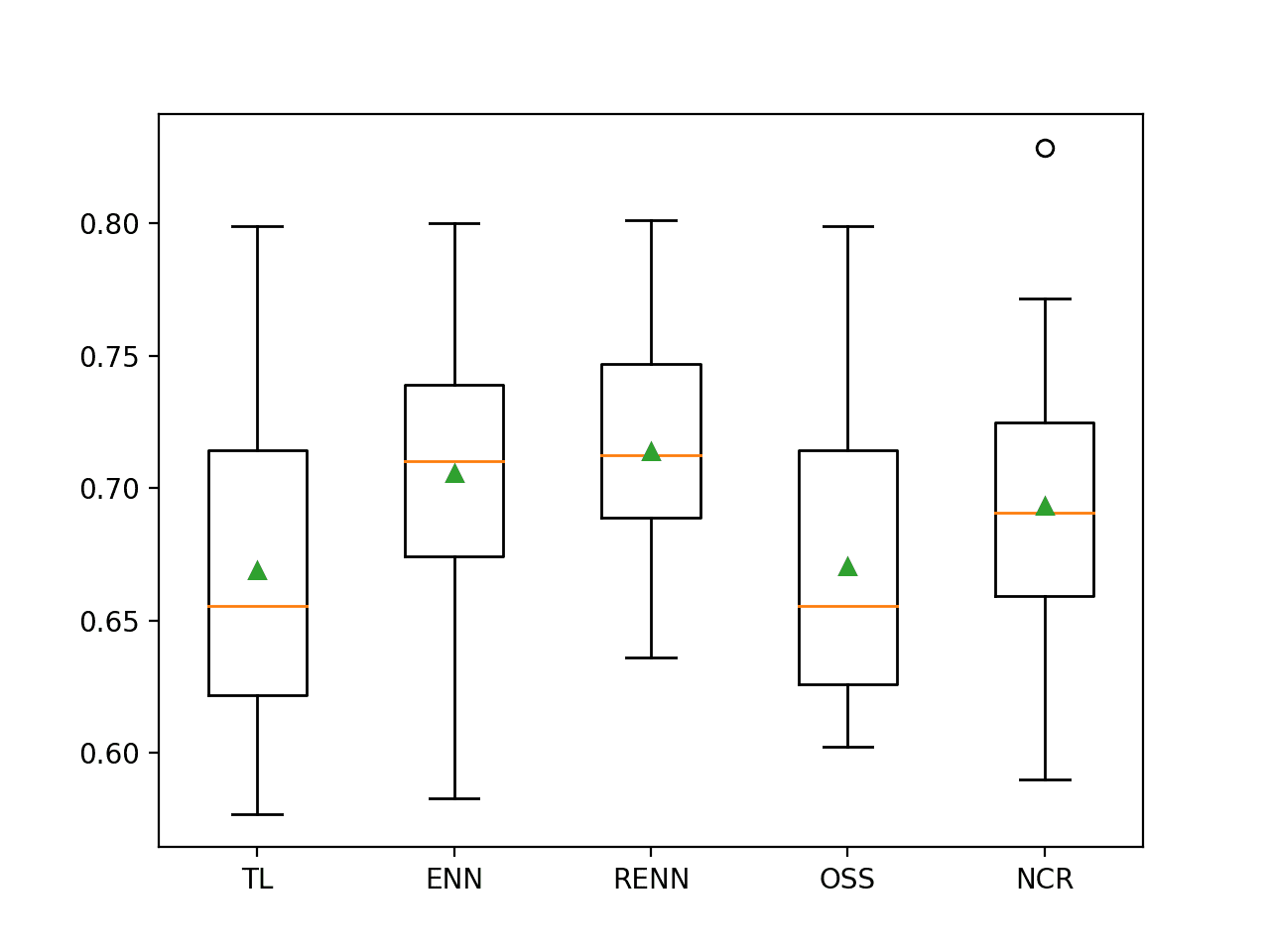
逻辑回归与欠采样在不平衡德国信用数据集上的箱线图
接下来,让我们看看如何使用最终模型对新数据进行预测。
进一步的模型改进
这是一个新部分,与上一节略有不同。在这里,我们将测试导致F2-measure性能进一步提升的特定模型,我将随着新模型被报告/发现而更新本节。
改进 #1:实例硬度阈值
使用平衡逻辑回归和InstanceHardnessThreshold欠采样,可以实现约 0.727 的 F2-measure。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
# 提高不平衡德国信用数据集的性能 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from sklearn.linear_model import LogisticRegression from imblearn.pipeline import Pipeline from imblearn.under_sampling import InstanceHardnessThreshold # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 计算f2-measure def f2_measure(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2_measure) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义要评估的模型 模型 = LogisticRegression(求解器='liblinear', class_weight='balanced') # 定义数据采样 采样 = InstanceHardnessThreshold() # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', sampling), ('m',model)]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) print('%.3f (%.3f)' % (mean(scores), std(scores))) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行示例将得到以下结果。
|
1 |
0.727 (0.033) |
改进 #2:SMOTEENN
通过 LDA 和SMOTEENN,其中 ENN 参数设置为采样策略为多数的 ENN 实例,可以实现约 0.730 的 F2-measure。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# 提高不平衡德国信用数据集的性能 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from imblearn.pipeline import Pipeline from imblearn.combine import SMOTEENN from imblearn.under_sampling import EditedNearestNeighbours # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 计算f2-measure def f2_measure(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2_measure) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义要评估的模型 model = LinearDiscriminantAnalysis() # 定义数据采样 采样 = SMOTEENN(enn=EditedNearestNeighbours(sampling_strategy='majority')) # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', sampling), ('m',model)]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) print('%.3f (%.3f)' % (mean(scores), std(scores))) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行示例将得到以下结果。
|
1 |
0.730 (0.046) |
改进 #3:SMOTEENN 结合 StandardScaler 和 RidgeClassifier
通过将 RidgeClassifier 替换 LDA,并使用 StandardScaler 代替 MinMaxScaler 对数值输入进行处理,SMOTEENN 可以进一步改进,F2-measure 达到约 0.741。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# 提高不平衡德国信用数据集的性能 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder from sklearn.preprocessing import StandardScaler from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.metrics import fbeta_score from sklearn.metrics import make_scorer from sklearn.linear_model import RidgeClassifier from imblearn.pipeline import Pipeline from imblearn.combine import SMOTEENN from imblearn.under_sampling import EditedNearestNeighbours # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 计算f2-measure def f2_measure(y_true, y_pred): return fbeta_score(y_true, y_pred, beta=2) # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义模型评估指标 metric = make_scorer(f2_measure) # 评估模型 scores = cross_val_score(model, X, y, scoring=metric, cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义要评估的模型 model = RidgeClassifier() # 定义数据采样 采样 = SMOTEENN(enn=EditedNearestNeighbours(sampling_strategy='majority')) # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',StandardScaler(),num_ix)]) # 缩放,然后采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', sampling), ('m',model)]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) print('%.3f (%.3f)' % (mean(scores), std(scores))) |
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行示例将得到以下结果。
|
1 |
0.741 (0.034) |
你能做得更好吗?
在下面的评论中告诉我。
对新数据进行预测
鉴于结果的差异,选择任何欠采样方法可能都足够了。在这种情况下,我们将选择带有 Repeated ENN 的逻辑回归。
此模型在我们的测试工具上获得了约 0.716 的 F2-measure。
我们将以此作为我们的最终模型,并用它来预测新数据。
首先,我们可以将模型定义为管道。
|
1 2 3 4 5 6 7 |
... # 定义要评估的模型 模型 = LogisticRegression(求解器='liblinear', class_weight='balanced') # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后欠采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', RepeatedEditedNearestNeighbours(), ('m',model)]) |
定义好后,我们就可以在整个训练数据集上对其进行拟合。
|
1 2 3 |
... # 拟合模型 管道.fit(X, y) |
拟合后,我们可以通过调用 predict() 函数来使用它对新数据进行预测。这将返回“良好客户”的类标签0,或“不良客户”的类标签1。
重要的是,我们必须使用在 Pipeline 中拟合的 ColumnTransformer 来正确地使用相同的转换准备新数据。
例如
|
1 2 3 4 5 |
... # 定义一行数据 行 = [...] # 进行预测 yhat = pipeline.predict([行]) |
为了证明这一点,我们可以使用拟合模型对一些已知是良好客户或不良客户的案例进行标签预测。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# 拟合模型并对德国信用数据集进行预测 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.linear_model import LogisticRegression from imblearn.pipeline import Pipeline from imblearn.under_sampling import RepeatedEditedNearestNeighbours # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 数据框 = read_csv(full_path, header=None) # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 定义数据集位置 full_path = 'german.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义要评估的模型 模型 = LogisticRegression(求解器='liblinear', class_weight='balanced') # 独热编码分类,归一化数值 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 缩放,然后欠采样,然后拟合模型 管道 = Pipeline(steps=[('t',ct), ('s', RepeatedEditedNearestNeighbours(), ('m',model)]) # 拟合模型 管道.fit(X, y) # 评估一些良好客户案例(已知类别 0) print('良好客户:') 数据 = [['A11', 6, 'A34', 'A43', 1169, 'A65', 'A75', 4, 'A93', 'A101' 4, 'A121', 67, 'A143', 'A152' 2, 'A173' 1, 'A192', 'A201'], ['A14', 12, 'A34', 'A46', 2096, 'A61', 'A74', 2, 'A93', 'A101' 3, 'A121' 49, 'A143', 'A152' 1, 'A172' 2, 'A191', 'A201'], ['A11', 42, 'A32', 'A42', 7882, 'A61', 'A74', 2, 'A93', 'A103', 4, 'A122', 45, 'A143', 'A153', 1, 'A173', 2, 'A191', 'A201']] for row in data: # 进行预测 yhat = pipeline.predict([row]) # 获取标签 label = yhat[0] # 总结 print('>预测值=%d (期望值 0)' % (label)) # 评估一些不良客户(已知类别 1) print('不良客户:') data = [['A13', 18, 'A32', 'A43', 2100, 'A61', 'A73', 4, 'A93', 'A102', 2, 'A121', 37, 'A142', 'A152', 1, 'A173', 1, 'A191', 'A201'], ['A11', 24, 'A33', 'A40', 4870, 'A61', 'A73', 3, 'A93', 'A101', 4, 'A124', 53, 'A143', 'A153', 2, 'A173', 2, 'A191', 'A201'], ['A11', 24, 'A32', 'A43', 1282, 'A62', 'A73', 4, 'A92', 'A101', 2, 'A123', 32, 'A143', 'A152', 1, 'A172', 1, 'A191', 'A201']] for row in data: # 进行预测 yhat = pipeline.predict([row]) # 获取标签 label = yhat[0] # 总结 print('>预测值=%d (期望值 1)' % (label)) |
首先运行示例,在整个训练数据集上拟合模型。
然后,使用拟合模型来预测从数据集文件中选择的良好客户的标签。我们可以看到大多数案例都得到了正确预测。这突出表明,尽管我们选择了好的模型,但它并不完美。
然后,将一些实际不良客户的案例用作模型的输入,并预测标签。正如我们所希望的,所有案例都预测出了正确的标签。
|
1 2 3 4 5 6 7 8 |
良好客户 >预测值=0(期望值 0) >预测值=0(期望值 0) >预测值=0(期望值 0) 不良客户 >预测值=0(期望值 1) >预测值=1(期望值 1) >预测值=1(期望值 1) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 机器学习、神经网络和统计分类, 1994.
API
- pandas.DataFrame.select_dtypes API.
- sklearn.metrics.fbeta_score API.
- sklearn.compose.ColumnTransformer API.
- sklearn.preprocessing.OneHotEncoder API.
- imblearn.pipeline.Pipeline API.
数据集 (Dataset)
总结
在本教程中,您学习了如何为不平衡的德国信用分类数据集开发和评估模型。
具体来说,你学到了:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何评估一系列机器学习模型,并使用数据欠采样技术提高其性能。
- 如何拟合最终模型并使用它来预测特定案例的类别标签。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






非常好的带代码教程。
谢谢!
精彩的笔记
谢谢。
Jason
采用 60/40 的训练-测试方法,将各种模型/抽样组合拟合到训练数据集,然后在测试数据集上进行预测,最佳 f2 分数似乎是 RC RENN(min-max 归一化)的 0.738 和 LDA RENN(min-max 归一化)的 0.737。使用 RC SMOTEENN 返回的 f2 分数为 0.732(min-max 归一化)和 0.707(均值标准化)。当然,这些分数会因拆分中的随机性而异。在采用交叉验证来识别有希望的模型之后,我喜欢在训练-测试中应用它们来生成混淆矩阵。混淆矩阵热图有助于可视化整体准确性(在这种情况下,通常在 0.6 到 0.7 之间)与减少假阴性(并将错误分类错误转移到假阳性)之间的权衡,以基于 f2 度量进行优化。例如,在 RC SMOTEENN(min-max 归一化)的情况下,在测试集中的 400 个样本中,252 个被正确分类(整体准确性 = 0.63),但在 148 个错误分类的样本中,只有 13 个是假阴性,135 个是假阳性。
干得好,Ron!
Jason,出色的工作……
谢谢!
嗨,Jason,
感谢您的教程!
我了解到 SMOTE 技术(用于少数类过采样改进)不适用于图像数据。因为它只适用于表格数据,而且我们有类似数据增强的技术用于图像数据……好的。
但是欠采样技术(如 TL、ENN、RENN、OSS、NCR)呢,它们也不能用于图像数据吗?图像数据有没有类似数据增强的反向对应物?
致敬
大多数方法都基于 kNN,这在像素数据上会很混乱。也许人们正在探索这种背景下的相似性度量,我不知道。
你可以通过精心设计的数据增强实现来达到类似的再平衡效果——控制每个批次中产生的样本平衡。这是我将关注的重点。
嗨,Jason,
感谢您的精彩文章。这些对我帮助很大。我有一个疑问。
我定义了以下指令
num_pipeline = make_pipeline(SimpleImputer(strategy=’median’), MinMaxScaler())
cat_pipeline = make_pipeline(OneHotEncoder())
column_transformer = make_column_transformer((num_pipeline, num_cols),
(cat_pipeline, cat_cols))
from imblearn.combine import SMOTEENN
# 定义数据采样
sampling = SMOTEENN(enn=EditedNearestNeighbours(sampling_strategy=’majority’, random_state=42))
当我逐步转换数据时,即首先使用列转换器转换数据,然后使用 SMOTEEN 进行重采样。
c_train_feature_df = column_transformer.fit_transform(train_feature_df)
# 下一行中重采样的数据
s_train_feature_df, s_train_target_df= sampling.fit_resample(c_train_feature_df, train_target_df)
在这种情况下,哑模型的得分是(’dummy = DummyClassifier(strategy=’constant’, constant=1)’)
哑模型的得分:-
平均 F2:- 0.876,标准差:- 0.000
现在,当我在新管道中结合所有上述管道和列转换器时,如下所示,
model_pipeline = Pipeline(steps=[(‘ct’, column_transformer), \
(‘s’, sampling), (‘m’, dummy)])
我得到了以下哑模型的得分。
哑模型的得分:-
平均 F2:- 0.58,标准差:- 0.000
通常,当我没有重采样训练数据时,我会得到这个分数。我很困惑,为什么结合所有管道和列转换器没有得到相同的结果。您能在这方面帮助我吗?
做得好,抱歉我无法调试你的代码示例
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨,Jason,
感谢您的笔记本。
我将成本敏感算法与欠采样技术结合,然后使用启发式方法来提高分数。具体来说,我使用带权重的岭分类器和编辑最近邻居,邻居的数量也是启发式方法中的一个参数。F2-measure 的最佳结果是 0.7503。
干得好!
嗨 Jason
非常感谢您分享您的知识。我发现本教程很有启发性,并且能够澄清我在使用不平衡训练数据集进行二元分类方面存在的许多问题。
为了尝试改进您的结果并获得更好的 F2-Measure,我首先使用 CalibratedClassifierCV 类来包装模型。我将 SVM 和 LR 的方法参数设置为“isotonic”,并将 class_weight 设置为“balanced”。由此,我获得了以下值
>LR 0.460 (0.069)
>LDA 0.476 (0.083)
>NB 0.374 (0.087)
>GPC 0.354 (0.063)
>SVM 0.485 (0.072
我只注意到 SVM 和 GPC 略有改进。LR、LDA 和 NB 的值很差。
我保留了“isotonic”作为方法,并删除了 SVM 和 LR 的 class_weight 参数,结果如下
>LR 0.463 (0.072)
>LDA 0.476 (0.083)
>NB 0.374 (0.087)
>GPC 0.354 (0.063)
>SVM 0.442 (0.081)
显然,SVM 以及前三个模型的结果都较差。
我通过欠采样在平衡校准 SVM 的技能方面取得了最显著的改进。使用五种不同欠采样技术评估 SVM 算法的结果如下。
>TL 0.516 (0.079)
>ENN 0.683 (0.044)
>RENN 0.714 (0.035)
>OSS 0.517 (0.078)
>NCR 0.674 (0.062)
RENN 和 ENN 使 SVM 相对于基线 0.682 大幅改进。我发现这非常了不起,因为如果没有概率校准和 SVM 的欠采样,SVM 的结果是 0.436(完全没有技能)。
我正在使用用户的手机元数据进行二元分类项目(信用评分)。有什么需要注意或考虑的提示吗?
再次感谢您的分享。
Gideon Aswani
干得好!
请注意,我们在教程中 F2 达到了 0.741 (0.034)。
这个框架将帮助您尝试一系列不同的技术,并从数据集中获得最佳效果
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
嗨 Jason
再次感谢。是的,我注意到在教程中您实现了 0.741(0.034)。那很棒。我将使用该框架来改进我的工作
非常感谢本教程,它非常有帮助。我只想问一件事。为什么我们不使用“DummyClassifier”模型和欠采样方法,并将相应的 f2 分数作为基础模型来超越呢?如果进行欠采样并使用“DummyClassifier”模型,我们应该会得到大约 0.83 的 F-2 分数。因此,无技能模型(预测所有为 1)应该具有更高的 f 分数。
我们使用哑分类器来建立基线。任何比它做得更好的模型都具有解决问题的“技能”。
重要的是哑分类器要尽可能简单。
你好,
我们为什么需要“evaluate_model”函数,特别是里面的 cross_val_score?我们不能直接使用 fbeta_score(y_true, y_pred, beta=2) 来计算 f2 分数吗?谢谢。
Ulas
如果你在保留数据上进行预测,你可以直接计算得分。
我需要编写满足以下 3 点的代码
1) 开发一个预测模型将客户分类为好或坏;
2) 将客户聚类成各种群组;
3) 提供一些关于如何利用频繁模式挖掘来发现数据中的模式和/或增强分类的想法;
非常感谢帮助。
也许这个过程会有所帮助
https://machinelearning.org.cn/start-here/#process
嗨,Jason,
非常感谢这篇文章。
我刚开始学习机器学习,您的文章非常善于简单地解释复杂主题。再次感谢。
关于这个问题,我设法在训练和测试数据上获得了 91-92% 之间的分数,参数如下所示的逻辑回归。这没有进行任何欠采样。下面是方法。如果您能指出我做错了什么,那将非常棒,因为我对如此高的结果持怀疑态度。
唯一的区别在于预处理中,我删除了数据集中分类特征周围的所有引号。
再次感谢。
干得好!
这个分数很高,我安排一些时间检查一下。
我无法用该模型重现您的结果,我能得到的最好结果是
我相信您不小心通过调用 grid.score() 报告了准确度而不是 F2-Measure。这可能是您“91-92%”结果的原因。
您可以在下面看到我完整的网格搜索代码
嗨,Jason,
感谢本教程。干得好!我有 2 个问题
1. 我在您的模型中没有观察到任何特征选择。您使用了我没有意识到的任何特征选择吗?如果没有,您认为选择特征可以改进模型吗?
2. 我正在开发一个只有 300 行数据集的不平衡分类模型。在这种情况下,由于数据量较少,使用过采样而不是欠采样会更好吗?
提前感谢!
嗨,Igor……特征选择绝对是您在这种情况下可以实现的改进。此外,以下内容可能对您有帮助
https://www.kaggle.com/code/rafjaa/dealing-with-very-small-datasets/notebook
嗨 James,
您分享的笔记本将非常有用。谢谢!
嗨,Jason,
我看到您对分类数据进行了独热编码,对数值数据应用了缩放器,然后应用了像 SMOTE() 这样的合成技术来过采样数据。
在独热编码字段上生成了哪种数据点?它们仍然是二进制性质的,还是会在编码特征中创建合成点?
如果是后者,那么对于一个模型来说,学习一个永远不会真正看到合成点或浮点数据类型(对于只能是二进制的字段)的字段,这有意义吗?
嗨,Vivek……以下资源可能对您有用
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/