许多二元分类任务的每种类别的样本数量并不相等,例如类别分布是倾斜或不平衡的。
一个流行的例子是成人收入数据集,该数据集涉及根据个人详细信息(如关系和教育程度)来预测个人收入水平是高于还是低于50,000美元/年。收入低于50,000美元的案例比收入高于50,000美元的案例要多得多,尽管倾斜程度并不严重。
这意味着不平衡分类技术可以被使用,同时模型性能仍然可以使用分类准确率来报告,正如在平衡分类问题中所使用的那样。
在本教程中,您将了解如何开发和评估用于不平衡成人收入分类数据集的模型。
完成本教程后,您将了解:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何使用稳健的测试框架系统地评估一套机器学习模型。
- 如何拟合最终模型并使用它来预测特定案例的类别标签。
通过我的新书 Python 中的不平衡分类 开启您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

开发用于预测收入的不平衡分类模型
照片由 Kirt Edblom 拍摄,部分权利保留。
教程概述
本教程分为五个部分;它们是:
- 成人收入数据集
- 探索数据集
- 模型测试和基线结果
- 评估模型
- 对新数据进行预测
成人收入数据集
在这个项目中,我们将使用一个标准的机器学习数据集,称为“成人收入”或简称为“adult”数据集。
该数据集归功于 Ronny Kohavi 和 Barry Becker,摘自 1994 年 美国人口普查局的数据,涉及使用教育程度等个人详细信息来预测个人年收入是高于还是低于 50,000 美元。
成人数据集来自人口普查局,任务是根据教育、每周工作时间等属性来预测给定成年人年收入是否超过 50,000 美元。
— Scaling Up The Accuracy Of Naive-bayes Classifiers: A Decision-tree Hybrid, 1996。
该数据集提供了 14 个输入变量,它们是分类、有序和数值数据类型的混合。变量的完整列表如下
- 年龄。
- 工作类别。
- 最终权重。
- 教育。
- 教育年限。
- 婚姻状况。
- 职业。
- 关系。
- 种族。
- 性别。
- 资本收益。
- 资本损失。
- 每周工作时间。
- 国籍。
数据集中包含用问号字符(?)标记的缺失值。
数据共有 48,842 行,其中 3,620 行包含缺失值,留下 45,222 行完整。
有两个类值“>50K”和“<=50K”,这意味着这是一个二元分类任务。类别是不平衡的,偏向于“<=50K”类别标签。
- “>50K”:多数类,约占 25%。
- “<=50K”:少数类,约占 75%。
鉴于类别不平衡并不严重,并且两个类别标签同样重要,因此通常使用分类准确率或分类错误来报告此数据集上的模型性能。
使用预定义的训练集和测试集,报告的良好分类错误约为 14%,即分类准确率约为 86%。在处理此数据集时,这可以作为目标。
接下来,我们仔细看看数据。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
探索数据集
成人数据集是一个广泛使用的标准机器学习数据集,用于探索和演示许多机器学习算法,包括一般算法和专门为不平衡分类设计的算法。
首先,下载数据集并将其保存在当前工作目录中,文件名为“adult-all.csv”。
查看文件内容。
文件的前几行应如下所示
|
1 2 3 4 5 6 |
39,State-gov,77516,Bachelors,13,Never-married,Adm-clerical,Not-in-family,White,Male,2174,0,40,United-States,<=50K 50,Self-emp-not-inc,83311,Bachelors,13,Married-civ-spouse,Exec-managerial,Husband,White,Male,0,0,13,United-States,<=50K 38,Private,215646,HS-grad,9,Divorced,Handlers-cleaners,Not-in-family,White,Male,0,0,40,United-States,<=50K 53,Private,234721,11th,7,Married-civ-spouse,Handlers-cleaners,Husband,Black,Male,0,0,40,United-States,<=50K 28,Private,338409,Bachelors,13,Married-civ-spouse,Prof-specialty,Wife,Black,Female,0,0,40,Cuba,<=50K ... |
我们可以看到输入变量是数值和分类或有序数据类型的混合,其中非数值列用字符串表示。至少,分类变量需要进行顺序编码或独热编码。
我们还可以看到目标变量是用字符串表示的。此列需要进行标签编码,将多数类编码为 0,将少数类编码为 1,这对于二元不平衡分类任务是惯例。
缺失值用“?”字符标记。这些值需要被插补,或者考虑到样本数量较少,这些行可以从数据集中删除。
可以使用 read_csv() Pandas 函数将数据集加载为 DataFrame,指定文件名、没有标题行,并且像‘ ?‘ 这样的字符串应被解析为 NaN(缺失)值。
|
1 2 3 4 5 |
... # 定义数据集位置 filename = 'adult-all.csv' # 将csv文件加载为数据框 dataframe = read_csv(filename, header=None, na_values='?') |
加载后,我们可以删除包含一个或多个缺失值的行。
|
1 2 3 |
... # 删除含有缺失值的行 dataframe = dataframe.dropna() |
我们可以通过打印 DataFrame 的形状来总结行数和列数。
|
1 2 3 |
... # 总结数据集的形状 print(dataframe.shape) |
我们还可以使用 Counter 对象来总结每个类别的示例数量。
|
1 2 3 4 5 6 7 |
... # 总结类别分布 target = dataframe.values[:,-1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
总而言之,下面列出了加载和汇总数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 加载并汇总数据集 from pandas import read_csv from collections import Counter # 定义数据集位置 filename = 'adult-all.csv' # 将csv文件加载为数据框 dataframe = read_csv(filename, header=None, na_values='?') # 删除含有缺失值的行 dataframe = dataframe.dropna() # 总结数据集的形状 print(dataframe.shape) # 总结类别分布 target = dataframe.values[:,-1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
运行该示例首先加载数据集并确认行数和列数,即 45,222 行无缺失值,14 个输入变量和一个目标变量。
然后总结类别分布,确认中等程度的类别不平衡,多数类(<=50K)约为 75%,少数类(>50K)约为 25%。
|
1 2 3 |
(45222, 15) Class= <=50K, Count=34014, Percentage=75.216% Class= >50K, Count=11208, Percentage=24.784% |
我们还可以通过为每个数值输入变量创建直方图来查看其分布。
首先,我们可以通过在 DataFrame 上调用 select_dtypes() 函数来选择具有数值数据类型的列。然后,我们可以仅从 DataFrame 中选择这些列。
|
1 2 3 4 5 |
... # 选择具有数值数据类型的列 num_ix = df.select_dtypes(include=['int64', 'float64']).columns # 选择具有选定列的 DataFrame 的子集 subset = df[num_ix] |
然后,我们可以为每个数值输入变量创建直方图。完整的示例列在下方。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 创建数值输入变量的直方图 from pandas import read_csv from matplotlib import pyplot # 定义数据集位置 filename = 'adult-all.csv' # 将csv文件加载为数据框 df = read_csv(filename, header=None, na_values='?') # 删除含有缺失值的行 df = df.dropna() # 选择具有数值数据类型的列 num_ix = df.select_dtypes(include=['int64', 'float64']).columns # 选择具有选定列的 DataFrame 的子集 subset = df[num_ix] # 为每个数值变量创建直方图 subset.hist() pyplot.show() |
运行该示例会创建图形,其中包含数据集中每个数值输入变量的一个直方图子图。每个子图的标题表示 DataFrame 中的列号(例如,零偏移)。
我们可以看到许多不同的分布,有些呈高斯状分布,有些呈指数状或离散状分布。我们还可以看到它们似乎都具有非常不同的尺度。
根据建模算法的选择,我们预计将分布缩放到相同的范围将是有用的,并且可能需要使用一些幂变换。
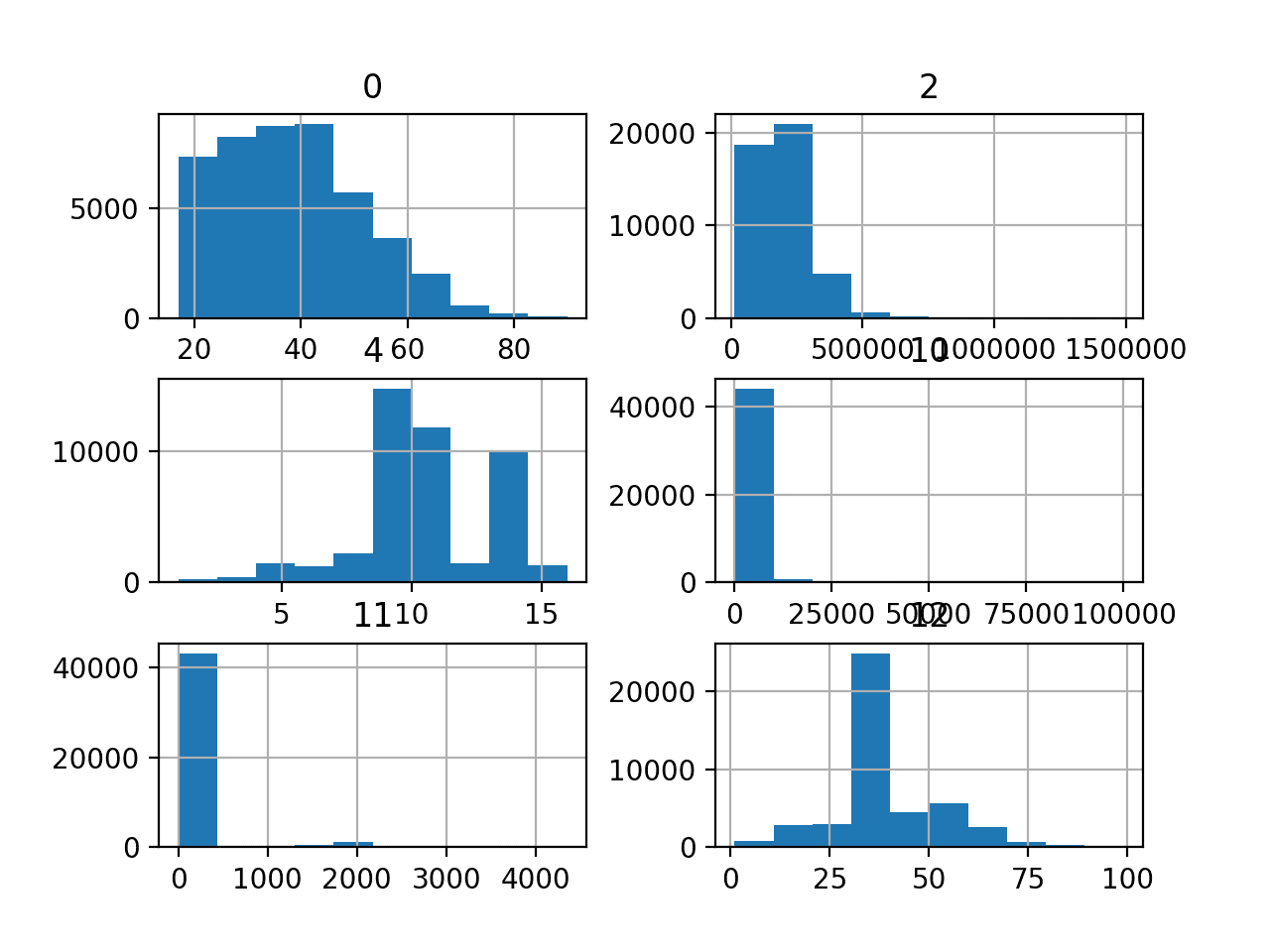
成人不平衡分类数据集中的数值变量直方图
现在我们已经审阅了数据集,接下来我们将开发一个测试工具来评估候选模型。
模型测试和基线结果
我们将使用重复分层 k 折交叉验证来评估候选模型。
k 折交叉验证过程提供了模型性能的良好通用估计,该估计不太可能过于乐观地倾向,至少与单一的训练-测试拆分相比是如此。我们将使用 k=10,这意味着每个折叠将包含约 45,222/10,即约 4,522 个示例。
分层意味着每个折叠将包含相同的类别示例混合,即多数类和少数类分别约占 75% 和 25%。重复意味着将多次执行评估过程,以帮助避免偶然结果并更好地捕捉所选模型的方差。我们将使用三次重复。
这意味着一个模型将被拟合和评估10 * 3或30次,并将报告这些运行的均值和标准差。
这可以使用 scikit-learn 的 RepeatedStratifiedKFold 类来实现。
我们将为每个示例预测一个类别标签,并使用分类准确率来衡量模型性能。
下面的 `evaluate_model()` 函数将接受加载的数据集和定义的模型,并使用重复分层 k 折交叉验证对其进行评估,然后返回准确率分数列表,稍后可以对其进行汇总。
|
1 2 3 4 5 6 7 |
# 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores |
我们可以定义一个函数来加载数据集并对目标列进行标签编码。
我们还将返回一个类别列和数值列的列表,以防我们稍后在拟合模型时决定转换它们。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 dataframe = read_csv(full_path, header=None, na_values='?') # 删除含有缺失值的行 dataframe = dataframe.dropna() # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix |
最后,我们可以使用这个测试工具评估数据集上的基线模型。
在使用分类准确率时,一个朴素的模型将为所有案例预测多数类。这提供了一个模型性能基线,所有其他模型都可以与之比较。
这可以通过 scikit-learn 库中的 DummyClassifier 类来实现,并将“strategy”参数设置为“most_frequent”。
|
1 2 3 |
... # 定义参考模型 model = DummyClassifier(strategy='most_frequent') |
模型评估完成后,我们可以直接报告准确率分数的平均值和标准差。
|
1 2 3 4 5 |
... # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
综合来看,加载成人数据集、评估基线模型并报告性能的完整示例将在下面列出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# 成人数据集的测试框架和基线模型评估 from collections import Counter from numpy import mean from numpy import std from numpy import hstack from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.dummy import DummyClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 dataframe = read_csv(full_path, header=None, na_values='?') # 删除含有缺失值的行 dataframe = dataframe.dropna() # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'adult-all.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 总结已加载的数据集 print(X.shape, y.shape, Counter(y)) # 定义参考模型 model = DummyClassifier(strategy='most_frequent') # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例首先加载并总结数据集。
我们可以看到已加载正确的行数。重要的是,我们可以看到类别标签已正确映射到整数,其中 0 代表多数类,1 代表少数类,这是不平衡二元分类数据集的惯例。
接下来,报告平均分类准确率分数。
在这种情况下,我们可以看到基线算法的准确率为 75.2% 左右。该分数提供了模型技能的下限;任何平均准确率高于 75.2% 的模型都具有技能,而分数低于此值的模型在此数据集上不具备技能。
|
1 2 |
(45222, 14) (45222,) Counter({0: 34014, 1: 11208}) Mean Accuracy: 0.752 (0.000) |
现在我们有了测试工具和性能基线,我们可以开始评估该数据集上的一些模型。
评估模型
在本节中,我们将使用上一节中开发的测试工具,评估数据集上的一系列不同技术。
目标是演示如何系统地解决问题,并展示一些针对不平衡分类问题设计的技术的能力。
报告的性能良好,但尚未高度优化(例如,超参数未进行调整)。
你能做得更好吗? 如果您可以使用相同的测试框架获得更好的分类准确率性能,我很乐意听到。请在下面的评论中告诉我。
评估机器学习算法
让我们开始在数据集上评估一系列机器学习模型。
在数据集上尝试一系列不同的非线性算法是一个好主意,这样可以快速找出哪些有效并值得进一步关注,哪些无效。
我们将评估成人数据集上的以下机器学习模型
- 决策树 (CART)
- 支持向量机 (SVM)
- 装袋决策树(BAG)
- 随机森林 (RF)
- 梯度提升机 (GBM)
我们将使用大部分默认模型超参数,除了集成算法中的树的数量,我们将将其设置为合理的默认值 100。
我们将依次定义每个模型并将它们添加到一个列表中,以便我们可以按顺序评估它们。下面的 get_models() 函数定义了要评估的模型列表,以及用于稍后绘制结果的模型简称列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义要测试的模型 定义 获取_模型(): models, names = list(), list() # CART models.append(DecisionTreeClassifier()) names.append('CART') # SVM models.append(SVC(gamma='scale')) names.append('SVM') # Bagging models.append(BaggingClassifier(n_estimators=100)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=100)) names.append('RF') # GBM models.append(GradientBoostingClassifier(n_estimators=100)) names.append('GBM') return models, names |
然后我们可以依次枚举模型列表并评估每个模型,存储分数以供后续评估。
我们将使用 OneHotEncoder 对分类输入变量进行独热编码,并使用 MinMaxScaler 对数值输入变量进行标准化。这些操作必须在交叉验证过程中的每个训练/测试拆分中执行,其中编码和缩放操作在训练集上拟合,并应用于训练集和测试集。
实现这一点的简单方法是使用 Pipeline,其中第一个步骤是 ColumnTransformer,它仅将 OneHotEncoder 应用于分类变量,将 MinMaxScaler 应用于数值输入变量。要实现这一点,我们需要分类和数值输入变量的列索引列表。
我们在上一节中定义的 `load_dataset()` 函数加载并返回数据集以及具有分类和数值数据类型的列列表。这可以用于准备一个 Pipeline 来包装每个模型,然后再进行评估。首先,定义 `ColumnTransformer`,它指定要应用于每种列类型的转换,然后将其用作 `Pipeline` 的第一步,最后是需要拟合和评估的特定模型。
|
1 2 3 4 5 6 7 8 9 |
... # 定义步骤 steps = [('c',OneHotEncoder(handle_unknown='ignore'),cat_ix), ('n',MinMaxScaler(),num_ix)] # 对分类变量进行独热编码,对数值变量进行标准化 ct = ColumnTransformer(steps) # 将模型包装在管道中 pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) |
我们可以为每个算法总结平均分类准确率,这将有助于直接比较算法。
|
1 2 3 |
... # 总结性能 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) |
在运行结束时,我们将为每个算法的采样结果创建单独的箱线图。这些图将使用相同的 y 轴比例,以便我们可以直接比较结果的分布。
|
1 2 3 4 |
... # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
综合起来,在成人不平衡数据集上评估一系列机器学习算法的完整示例将在下面列出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
# 在成人不平衡数据集上进行机器学习算法的抽样检查 from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import BaggingClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 dataframe = read_csv(full_path, header=None, na_values='?') # 删除含有缺失值的行 dataframe = dataframe.dropna() # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义要测试的模型 定义 获取_模型(): models, names = list(), list() # CART models.append(DecisionTreeClassifier()) names.append('CART') # SVM models.append(SVC(gamma='scale')) names.append('SVM') # Bagging models.append(BaggingClassifier(n_estimators=100)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=100)) names.append('RF') # GBM models.append(GradientBoostingClassifier(n_estimators=100)) names.append('GBM') return models, names # 定义数据集位置 full_path = 'adult-all.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义模型 models, names = get_models() results = list() # 评估每个模型 for i in range(len(models)): # 定义步骤 steps = [('c',OneHotEncoder(handle_unknown='ignore'),cat_ix), ('n',MinMaxScaler(),num_ix)] # 对分类变量进行独热编码,对数值变量进行标准化 ct = ColumnTransformer(steps) # 将模型包装在管道中 pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # 评估模型并存储结果 scores = evaluate_model(X, y, pipeline) results.append(scores) # 总结性能 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例将依次评估每个算法,并报告分类准确率的平均值和标准差。
注意:鉴于算法或评估程序的随机性质,或数值精度的差异,您的结果可能有所不同。请考虑多次运行示例并比较平均结果。
您得到了什么分数?
请在下方评论区发布你的结果。
在这种情况下,我们可以看到所有选定的算法都很有技巧,分类准确率均高于 75.2%。我们可以看到集成决策树算法表现最好,其中随机梯度增强的分类准确率约为 86.3%。
这略好于原始论文中报道的结果,尽管使用了不同的模型评估程序。
|
1 2 3 4 5 |
CART 0.812 (0.005) SVM 0.837 (0.005) BAG 0.852 (0.004) RF 0.849 (0.004) GBM 0.863 (0.004) |
创建一个图,显示每个算法结果样本的一个箱须图。箱子显示数据的前 50%,每个箱子中间的橙色线显示样本的中位数,每个箱子中的绿色三角形显示样本的平均值。
我们可以看到,每个算法的分数分布似乎都高于大约 75% 的基线,可能有一些异常值(图上的圆圈)。每个算法的分布似乎都很紧凑,中位数和平均值对齐,这表明模型在此数据集上相当稳定,分数不会形成倾斜分布。
这突显了模型性能的中心趋势、分布和最坏情况的结果都很重要,尤其是在少数类样本数量有限的情况下。
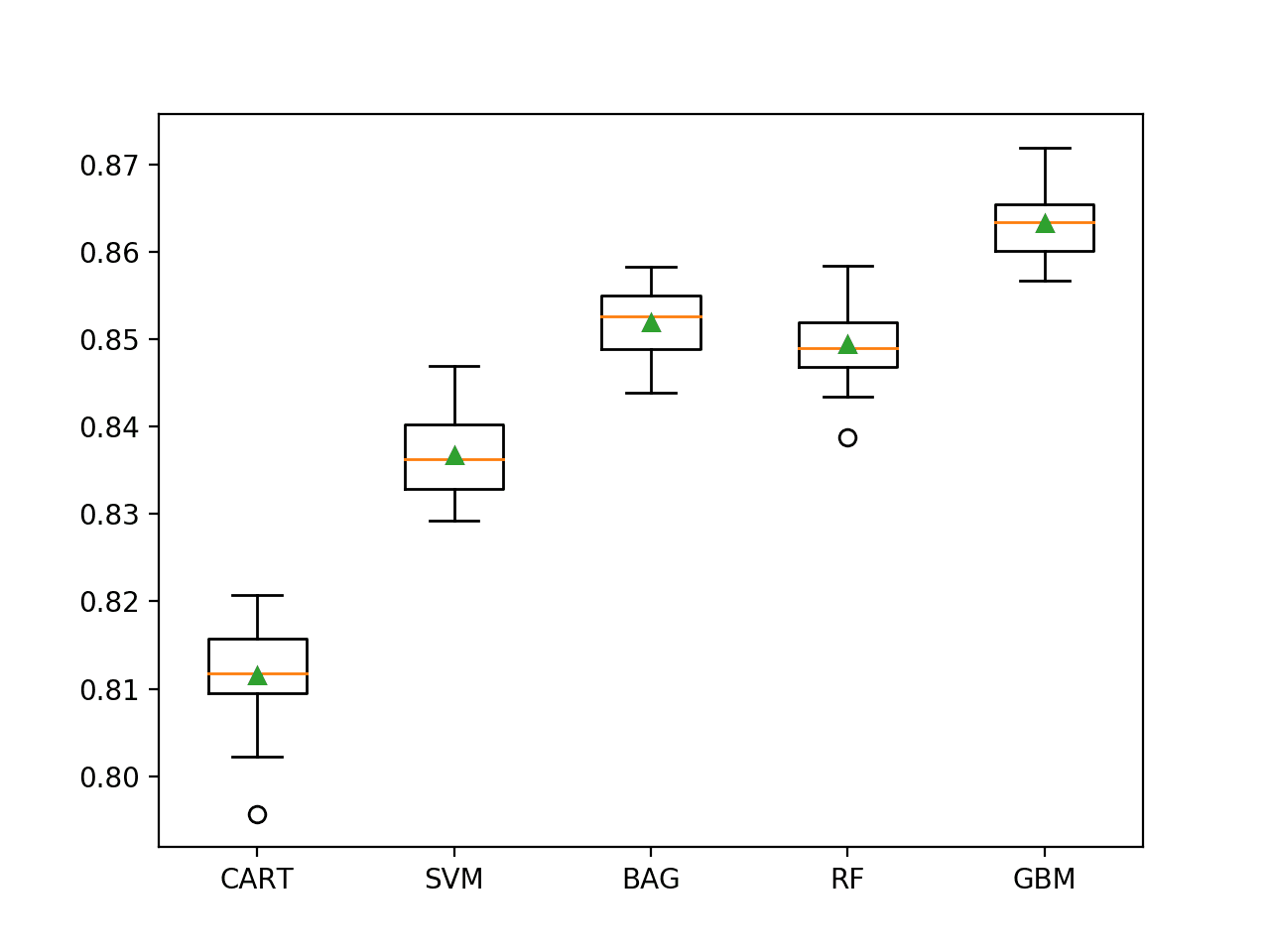
不平衡成人数据集上机器学习模型箱须图
对新数据进行预测
在本节中,我们可以拟合最终模型并使用它来预测单行数据。
我们将使用分类准确率约为 86.3% 的GradientBoostingClassifier模型作为我们的最终模型。拟合最终模型涉及定义ColumnTransformer来对分类变量进行编码并对数值变量进行缩放,然后构建一个Pipeline以在拟合模型之前对训练集执行这些转换。
然后,可以使用该Pipeline直接在新数据上进行预测,并会自动使用与训练数据集相同的操作来编码和缩放新数据。
首先,我们可以将模型定义为管道。
|
1 2 3 4 5 6 7 |
... # 定义要评估的模型 model = GradientBoostingClassifier(n_estimators=100) # 对分类变量进行独热编码,对数值变量进行标准化 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 定义管道 pipeline = Pipeline(steps=[('t',ct), ('m',model)]) |
定义好后,我们就可以在整个训练数据集上对其进行拟合。
|
1 2 3 |
... # 拟合模型 pipeline.fit(X, y) |
拟合后,我们可以通过调用predict()函数来使用它对新数据进行预测。这将返回“<=50K”的类别标签 0,或“>50K”的类别标签 1。
重要的是,我们必须在Pipeline中使用ColumnTransformer来使用相同的转换正确准备新数据。
例如
|
1 2 3 4 5 |
... # 定义一行数据 row = [...] # 进行预测 yhat = pipeline.predict([row]) |
为了演示这一点,我们可以使用已训练好的模型来预测一些已知结果的案例的标签。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
# 拟合模型并对成人数据集进行预测 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.ensemble import GradientBoostingClassifier from imblearn.pipeline import Pipeline # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 dataframe = read_csv(full_path, header=None, na_values='?') # 删除含有缺失值的行 dataframe = dataframe.dropna() # 分割为输入和输出 last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # 选择分类和数值特征 cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # 定义数据集位置 full_path = 'adult-all.csv' # 加载数据集 X, y, cat_ix, num_ix = load_dataset(full_path) # 定义要评估的模型 model = GradientBoostingClassifier(n_estimators=100) # 对分类变量进行独热编码,对数值变量进行标准化 ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # 定义管道 pipeline = Pipeline(steps=[('t',ct), ('m',model)]) # 拟合模型 pipeline.fit(X, y) # 评估一些 <=50K 的案例(已知类别为 0) print('<=50K cases:') data = [[24, 'Private', 161198, 'Bachelors', 13, 'Never-married', 'Prof-specialty', 'Not-in-family', 'White', 'Male', 0, 0, 25, 'United-States'], [23, 'Private', 214542, 'Some-college', 10, 'Never-married', 'Farming-fishing', 'Own-child', 'White', 'Male', 0, 0, 40, 'United-States'], [38, 'Private', 309122, '10th', 6, 'Divorced', 'Machine-op-inspct', 'Not-in-family', 'White', 'Female', 0, 0, 40, 'United-States']] for row in data: # 进行预测 yhat = pipeline.predict([row]) # 获取标签 label = yhat[0] # 总结 print('+Predicted=%d (expected 0)' % (label)) # 评估一些 >50K 的案例(已知类别为 1) print('+>50K cases:') data = [[55, 'Local-gov', 107308, 'Masters', 14, 'Married-civ-spouse', 'Prof-specialty', 'Husband', 'White', 'Male', 0, 0, 40, 'United-States'], [53, 'Self-emp-not-inc', 145419, '1st-4th', 2, 'Married-civ-spouse', 'Exec-managerial', 'Husband', 'White', 'Male', 7688, 0, 67, 'Italy'], [44, 'Local-gov', 193425, 'Masters', 14, 'Married-civ-spouse', 'Prof-specialty', 'Wife', 'White', 'Female', 4386, 0, 40, 'United-States']] for row in data: # 进行预测 yhat = pipeline.predict([row]) # 获取标签 label = yhat[0] # 总结 print('+Predicted=%d (expected 1)' % (label)) |
首先运行示例,在整个训练数据集上拟合模型。
然后,使用从数据集中选择的用于预测 <=50K 案例标签的拟合模型。我们可以看到所有案例都得到了正确预测。然后,将一些 >50K 案例作为输入提供给模型并预测标签。正如我们所希望的,预测结果是正确的标签。
|
1 2 3 4 5 6 7 8 |
<=50K cases >预测值=0(期望值 0) >预测值=0(期望值 0) >预测值=0(期望值 0) >50K cases >预测值=1(期望值 1) >预测值=1(期望值 1) >预测值=1(期望值 1) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 提高朴素贝叶斯分类器的准确性:一种决策树混合方法, 1996.
API
- pandas.DataFrame.select_dtypes API.
- sklearn.model_selection.RepeatedStratifiedKFold API.
- sklearn.dummy.DummyClassifier API.
数据集 (Dataset)
总结
在本教程中,您学习了如何开发和评估用于不平衡成人收入分类数据集的模型。
具体来说,你学到了:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何使用稳健的测试框架系统地评估一套机器学习模型。
- 如何拟合最终模型并使用它来预测特定案例的类别标签。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






你好,
当我运行模型评估代码时,我收到“ValueError: could not convert string to float: ‘United-States'”错误。找不到解决方案。您能帮忙吗?
ANwar
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
感谢本教程。我遇到了和 Anwar 一样的问题,我认为这是因为您没有对分类变量进行编码。因此,您直接将 cat_ix 列输入到您的模型中。
希望您能对此进行研究并加以澄清。
谢谢。
很抱歉听到您遇到了麻烦。
我们确实准备了两种变量类型,请参阅“评估机器学习算法”部分,我们在那里第一次这样做了。
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
哦,明白了,谢谢!
显然,在“评估机器学习算法”之前的代码块会引发错误。因此,使用那里的代码,我们无法获得基线性能,因为那时还没有进行准备。
它前面的块使用了一个不查看输入的虚拟模型。
在这种情况下,不需要数据准备,代码会直接执行。也许请确认您使用的是最新版本的 scikit-learn。
请忽略我上一条消息。
我刷新了我的内核并在新笔记本中运行,它奏效了。
感谢您所做的一切,Jason
没问题。很高兴听到这个消息,干得好!
嗨 Jason
非常棒的成人数据集教程,实际上是数据科学项目的好例子,尤其是您干净的代码。但我有一个困惑之处。
与大多数在线数据科学教程不同,您的示例没有太多特征工程。老实说,有时阅读其他数据科学家的特征工程部分教程确实令人头疼,他们会玩弄每个特征与目标之间的相关性,他们还会通过一些数学转换创建一些虚构的特征。
您对特征工程有何看法?您是否介意分享一些您的经验?样本或教程?
谢谢。
如果你有时间,我认为这是一个好主意。
这可能有助于作为第一步
https://machinelearning.org.cn/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
嗨,伙计,谢谢分享。
在浏览 sklearn 的
RepeatedStratifiedKFold文档时有点困惑,想知道您的技术是否包含任何形式的训练和测试分割?还是训练在前 9 折中完成,最后 1 折用于获取指标?否则,您如何确保模型没有仅仅完美地学习表示?
它执行简单的交叉验证
https://machinelearning.org.cn/k-fold-cross-validation/
它只是确保分割是分层的。它还会重复几次过程,以便我们在均值中获得更少的标准误差。
你好,
您能否解释一下为什么选择“最频繁”作为虚拟分类器的策略?我们应该根据什么来选择策略?
是的,请看这个
https://machinelearning.org.cn/naive-classifiers-imbalanced-classification-metrics/
我为这个数据集获得了 0.9 的中位数 AUC。我使用了 Primeclue,一个开源数据挖掘工具(可在 github 上找到)。
干得好!
嗨,Jason,
您在上面的代码中提到您正在过采样,但我看不出您是如何做到的。您能解释一下吗?
谢谢!
看起来像一个笔误,谢谢。已修复。
感谢您的快速回复。
在您看来,过采样少数类会有什么改进吗?
此外,是否需要处理一些倾斜的特征,例如种族和国籍(可能还有其他),其中白种人和美国在样本总数中所占的比例占主导地位?
谢谢!
我认为我尝试过,但没有看到任何好处。也许您自己试试确认一下。
嗨,我正在尝试您的代码,但不知何故,在评估部分,我对不同模型的均值和标准差得到 NaN。您能建议我可能做错了什么吗?
谢谢你
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
谢谢(一如既往)的快速分析。我为一次面试得到了完全相同的数据集作为案例研究,并且有一个问题。在评估部分,当我想检测模型是否过拟合时,仅仅绘制 Logloss 曲线和 Error 曲线是否足够?您会如何进行?提前感谢!
马龙
不客气。
过拟合确实是您只能针对迭代学习的模型进行查看的内容,也许可以看看这个
https://machinelearning.org.cn/overfitting-machine-learning-models/
那么您的意思是,没有办法可视化任何曲线来检测 xgb 的过拟合/欠拟合吗?
我感到很困惑。您在这里不是这样做的吗:https://machinelearning.org.cn/avoid-overfitting-by-early-stopping-with-xgboost-in-python/
是的。
您可以,在添加每个树之后,您可以评估在训练集和验证集上的性能,然后绘制曲线。它只是无助于模型选择——它有助于模型诊断。
请看这个例子
https://machinelearning.org.cn/avoid-overfitting-by-early-stopping-with-xgboost-in-python/
啊,抱歉!那么我回答我的问题的方式可能会被误解。感谢您一如既往的快速回复 😉
不客气。
嗨,Jason
我尝试了上面的代码,直到尝试不同分类模型的部分。出于某种原因,我的计算机只显示 CART 结果。我已经等待了大约 15 分钟,但其他模型的结果还没有出来。
您是否知道原因?我不认为这是由于繁重的编程,您的代码看起来很轻量
在此先感谢您
嗨,又是我
最终结果出来了,我得到了
CART 0.811 (0.006)
SVM 0.837 (0.005)
BAG 0.853 (0.005)
RF 0.850 (0.005)
GBM 0.863 (0.005)
我的电脑花了大约 2 小时才运行完成。我使用的是 Anaconda 的 Spyder,我的配置是:Win 10 64 位,Intel(R) Core(TM) i3-6006U CPU @ 2.00GHz 2.00 GHz,RAM 4GB
我不能确定原因,但我听说有人抱怨 Spyder 拖慢了执行速度。
如果您尝试在控制台(即非 jupyter notebook)中运行它,请按 Ctrl-C 终止它。它会告诉您它在哪里停止。不过,我看不出为什么需要这么长时间才能运行。如果您仍然不确定,请尝试在代码中添加一些 print() 语句来跟踪程序去了哪里。这些只是学习更多关于正在发生的事情的初步步骤。