多类别分类问题是指必须预测一个标签,但可能预测的标签不止两个。
这些是具有挑战性的预测建模问题,因为模型需要足够具有代表性的每个类别的样本数才能学习问题。当每个类别的样本数量不平衡,或偏向于某个类别或少数几个类别,而其他类别只有很少样本时,问题就会变得更具挑战性。
这类问题被称为不平衡多类别分类问题,它们需要仔细设计评估指标和测试框架,以及选择机器学习模型。玻璃识别数据集是探索不平衡多类别分类挑战的标准数据集。
在本教程中,您将发现如何为不平衡的多类别玻璃识别数据集开发和评估模型。
完成本教程后,您将了解:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何使用稳健的测试框架系统地评估一套机器学习模型。
- 如何拟合最终模型并使用它来预测特定样本的类别标签。
开启您的项目,阅读我的新书 《Python不平衡分类》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2020年6月:添加了一个实现更好性能的示例。

评估不平衡多类别玻璃识别数据集的模型
照片来源: Sarah Nichols,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 玻璃识别数据集
- 探索数据集
- 模型测试和基线结果
- 评估模型
- 评估机器学习算法
- 改进模型(新)
- 在新数据上进行预测
玻璃识别数据集
在此项目中,我们将使用一个标准的机器学习数据集,称为“玻璃识别”数据集,或简称为“glass”。
该数据集描述了玻璃的化学性质,涉及使用其化学性质将玻璃样本分类为六个类别之一。该数据集于1987年由Vina Spiehler提供。
忽略样本标识号,有九个输入变量总结了玻璃数据集的属性;它们是:
- RI:折射率
- Na:钠
- Mg:镁
- Al:铝
- Si:硅
- K:钾
- Ca:钙
- Ba:钡
- Fe:铁
化学成分以相应氧化物的重量百分比衡量。
列出了七种玻璃类型;它们是:
- 类别 1:建筑玻璃(浮法处理)
- 类别 2:建筑玻璃(非浮法处理)
- 类别 3:车辆玻璃(浮法处理)
- 类别 4:车辆玻璃(非浮法处理)
- 类别 5:容器
- 类别 6:餐具
- 类别 7:车头灯
浮法玻璃是指制造玻璃的工艺。
数据集中有214个观测值,每个类别中的观测值数量不平衡。请注意,数据集中没有类别4(非浮法处理的车辆玻璃)的样本。
- 类别 1:70个样本
- 类别 2:76个样本
- 类别 3:17个样本
- 类别 4:0个样本
- 类别 5:13个样本
- 类别 6:9个样本
- 类别 7:29个样本
尽管存在少数类别,但在本次预测问题中,所有类别同等重要。
该数据集可以分为窗玻璃(类别1-4)和非窗玻璃(类别5-7)。有163个窗玻璃样本和51个非窗玻璃样本。
- 窗玻璃:163个样本
- 非窗玻璃:51个样本
另一个划分方式是根据浮法处理的玻璃和非浮法处理的玻璃,仅针对窗玻璃。这种划分更为平衡。
- 浮法玻璃:87个样本
- 非浮法玻璃:76个样本
接下来,我们仔细看看数据。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
探索数据集
首先,下载数据集并将其保存在当前工作目录中,名为“glass.csv”。
请注意,此版本的数据集已删除第一列(行)编号,因为它不包含可泛化的建模信息。
查看文件内容。
文件的前几行应如下所示
|
1 2 3 4 5 6 |
1.52101,13.64,4.49,1.10,71.78,0.06,8.75,0.00,0.00,1 1.51761,13.89,3.60,1.36,72.73,0.48,7.83,0.00,0.00,1 1.51618,13.53,3.55,1.54,72.99,0.39,7.78,0.00,0.00,1 1.51766,13.21,3.69,1.29,72.61,0.57,8.22,0.00,0.00,1 1.51742,13.27,3.62,1.24,73.08,0.55,8.07,0.00,0.00,1 ... |
我们可以看到输入变量是数值型的,类别标签是整数,位于最后一列。
所有化学输入变量具有相同的单位,尽管第一个变量,即折射率,具有不同的单位。因此,某些建模算法可能需要数据缩放。
可以使用 read_csv() Pandas 函数将数据集加载为 DataFrame,并指定数据集的位置以及没有标题行的事实。
|
1 2 3 4 5 |
... # 定义数据集位置 filename = 'glass.csv' # 将csv文件加载为数据框 dataframe = read_csv(filename, header=None) |
加载后,我们可以通过打印 DataFrame 的形状来总结行数和列数。
|
1 2 3 |
... # 总结数据集的形状 print(dataframe.shape) |
我们还可以使用Counter对象总结每个类别的示例数量。
|
1 2 3 4 5 6 7 |
... # 总结类别分布 target = dataframe.values[:, -1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%d, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
总而言之,下面列出了加载和汇总数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 加载并汇总数据集 from pandas import read_csv from collections import Counter # 定义数据集位置 filename = 'glass.csv' # 将csv文件加载为数据框 dataframe = read_csv(filename, header=None) # 总结数据集的形状 print(dataframe.shape) # 总结类别分布 target = dataframe.values[:, -1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%d, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
运行该示例首先加载数据集,并确认行数和列数,即214行,9个输入变量和1个目标变量。
然后总结类别分布,证实了每个类别观测值的严重偏斜。
|
1 2 3 4 5 6 7 |
(214, 10) Class=1, Count=70, Percentage=32.710% Class=2, Count=76, Percentage=35.514% Class=3, Count=17, Percentage=7.944% Class=5, Count=13, Percentage=6.075% Class=6, Count=9, Percentage=4.206% Class=7, Count=29, Percentage=13.551% |
我们还可以通过为每个变量创建直方图来查看输入变量的分布。
以下是创建所有变量直方图的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 创建所有变量的直方图 from pandas import read_csv from matplotlib import pyplot # 定义数据集位置 filename = 'glass.csv' # 将csv文件加载为数据框 df = read_csv(filename, header=None) # 创建每个变量的直方图 df.hist() # 显示绘图 pyplot.show() |
我们可以看到,一些变量具有 类似高斯分布,而其他变量则呈现指数分布甚至双峰分布。
根据算法的选择,数据可能受益于某些变量的标准化,以及可能进行的幂变换。
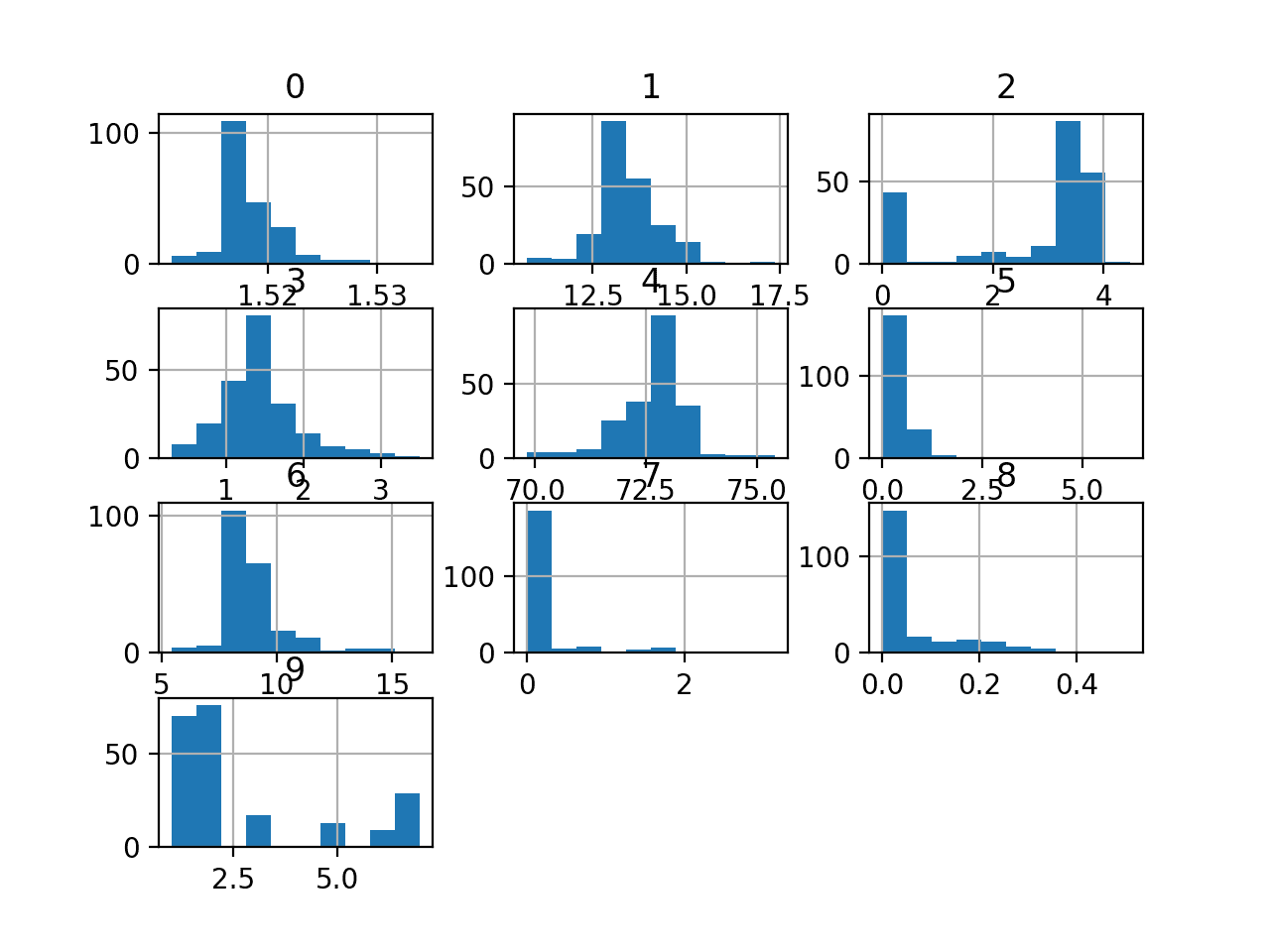
玻璃识别数据集变量的直方图
现在我们已经审阅了数据集,接下来我们将开发一个测试工具来评估候选模型。
模型测试和基线结果
我们将使用重复分层 k 折交叉验证来评估候选模型。
k折交叉验证程序可以提供对模型性能的良好总体估计,至少与单个训练-测试分割相比,它不会过于乐观地产生偏差。我们将使用 k=5,这意味着每折将包含大约 214/5,即约42个样本。
分层意味着每折将尝试包含与整个训练数据集相同的类别样本组合。重复意味着将执行多次评估过程,以帮助避免偶然结果并更好地捕捉所选模型的方差。我们将使用三次重复。
这意味着将对单个模型进行15次(5 * 3)拟合和评估,并将报告这些运行的平均值和标准差。
这可以使用 scikit-learn 的 RepeatedStratifiedKFold 类来实现。
所有类别同等重要。存在仅占数据4%或6%的少数类别,但没有类别占数据集的35%以上。
因此,在这种情况下,我们将使用分类准确率来评估模型。
首先,我们可以定义一个函数来加载数据集,将输入变量分为输入和输出变量,并使用标签编码器确保类别标签从0到5按顺序编号。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) return X, y |
我们可以定义一个函数来使用分层重复5折交叉验证来评估候选模型,然后返回模型在每个折叠和重复中计算出的分数列表。下面的 evaluate_model() 函数实现了这一点。
|
1 2 3 4 5 6 7 |
# 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores |
然后,我们可以调用 load_dataset() 函数来加载和确认玻璃识别数据集。
|
1 2 3 4 5 6 7 |
... # 定义数据集位置 full_path = 'glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 总结已加载的数据集 print(X.shape, y.shape, Counter(y)) |
在这种情况下,我们将评估预测所有情况下的多数类别这一基线策略。
这可以使用 DummyClassifier 类自动实现,并将“strategy”设置为“most_frequent”,该选项将预测训练数据集中最常见的类别(例如类别2)。
因此,考虑到这是训练数据集中最常见类别的分布,我们预计该模型将达到约35%的分类准确率。
|
1 2 3 |
... # 定义参考模型 model = DummyClassifier(strategy='most_frequent') |
然后,我们可以通过调用我们的 evaluate_model() 函数来评估模型,并报告结果的平均值和标准差。
|
1 2 3 4 5 |
... # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
总而言之,评估基线模型在玻璃识别数据集上的分类准确率的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 玻璃识别数据集的基线模型和测试框架 from collections import Counter from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.dummy import DummyClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 总结已加载的数据集 print(X.shape, y.shape, Counter(y)) # 定义参考模型 model = DummyClassifier(strategy='most_frequent') # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行该示例首先加载数据集,并按预期报告正确案例数214和类别标签的分布。
然后使用重复分层k折交叉验证评估具有默认策略的 DummyClassifier,并报告分类准确率的平均值和标准差,约为35.5%。
该分数提供了此数据集的基线,所有其他分类算法都可以与此基线进行比较。得分高于约35.5%表示模型在此数据集上具有技能,而得分等于或低于此值表示模型在此数据集上不具有技能。
|
1 2 |
(214, 9) (214,) Counter({1: 76, 0: 70, 5: 29, 2: 17, 3: 13, 4: 9}) Mean Accuracy: 0.355 (0.011) |
现在我们有了测试工具和性能基线,我们可以开始评估该数据集上的一些模型。
评估模型
在本节中,我们将使用上一节中开发的测试工具,评估数据集上的一系列不同技术。
报告的性能良好,但尚未高度优化(例如,超参数未进行调整)。
能做得更好吗? 如果您可以使用相同的测试框架获得更好的分类准确率,我很想听听。请在下面的评论中告诉我!
评估机器学习算法
让我们在数据上评估一组机器学习模型。
最好能够对数据集进行一系列不同的非线性算法的抽样检查,以快速找出哪些效果好并值得进一步关注,哪些效果不好。
我们将对玻璃数据集评估以下机器学习模型:
- 支持向量机 (SVM)
- k-近邻(KNN)
- 装袋决策树(BAG)
- 随机森林 (RF)
- 极端随机树(ET)
我们将使用大多数默认模型超参数,除了集成算法中的树的数量,我们将将其设置为合理的默认值1000。
我们将依次定义每个模型并将它们添加到一个列表中,以便我们可以按顺序评估它们。下面的 get_models() 函数定义了要评估的模型列表,以及用于稍后绘制结果的模型简称列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义要测试的模型 定义 获取_模型(): models, names = list(), list() # SVM models.append(SVC(gamma='auto')) names.append('SVM') # KNN models.append(KNeighborsClassifier()) names.append('KNN') # Bagging models.append(BaggingClassifier(n_estimators=1000)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=1000)) names.append('RF') # ET models.append(ExtraTreesClassifier(n_estimators=1000)) names.append('ET') return models, names |
然后我们可以依次枚举模型列表并评估每个模型,存储分数以供后续评估。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 定义模型 models, names = get_models() results = list() # 评估每个模型 for i in range(len(models)): # 评估模型并存储结果 scores = evaluate_model(X, y, models[i]) results.append(scores) # 总结性能 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) |
在运行结束时,我们可以将每个样本的分数绘制成箱须图,并具有相同的比例,以便直接比较其分布。
|
1 2 3 4 |
... # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
总而言之,在玻璃识别数据集上评估一系列机器学习算法的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# 对玻璃识别数据集进行机器学习算法抽样检查 from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.svm import SVC from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import BaggingClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义要测试的模型 定义 获取_模型(): models, names = list(), list() # SVM models.append(SVC(gamma='auto')) names.append('SVM') # KNN models.append(KNeighborsClassifier()) names.append('KNN') # Bagging models.append(BaggingClassifier(n_estimators=1000)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=1000)) names.append('RF') # ET models.append(ExtraTreesClassifier(n_estimators=1000)) names.append('ET') return models, names # 定义数据集位置 full_path = 'glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义模型 models, names = get_models() results = list() # 评估每个模型 for i in range(len(models)): # 评估模型并存储结果 scores = evaluate_model(X, y, models[i]) results.append(scores) # 总结性能 print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) # 绘制结果图 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行该示例将依次评估每个算法,并报告分类准确率的平均值和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到所有被测试的算法都具有技能,其准确率都高于默认值35.5%。
结果表明,决策树集成模型在此数据集上表现良好,其中随机森林可能是整体表现最好的,分类准确率约为79.6%。
|
1 2 3 4 5 |
>SVM 0.669 (0.057) >KNN 0.647 (0.055) >BAG 0.767 (0.070) >RF 0.796 (0.062) >ET 0.776 (0.057) |
将创建一张图,其中包含每个算法结果样本的一个箱须图。箱子显示了数据的中位数50%,每个箱子中间的橙色线显示了样本的中位数,每个箱子中的绿色三角形显示了样本的平均值。
我们可以看到,决策树集成模型的得分分布聚在一起,与其他测试算法分开。在大多数情况下,平均值和中位数在图上接近,这表明得分分布可能相对对称,这可能表明模型是稳定的。
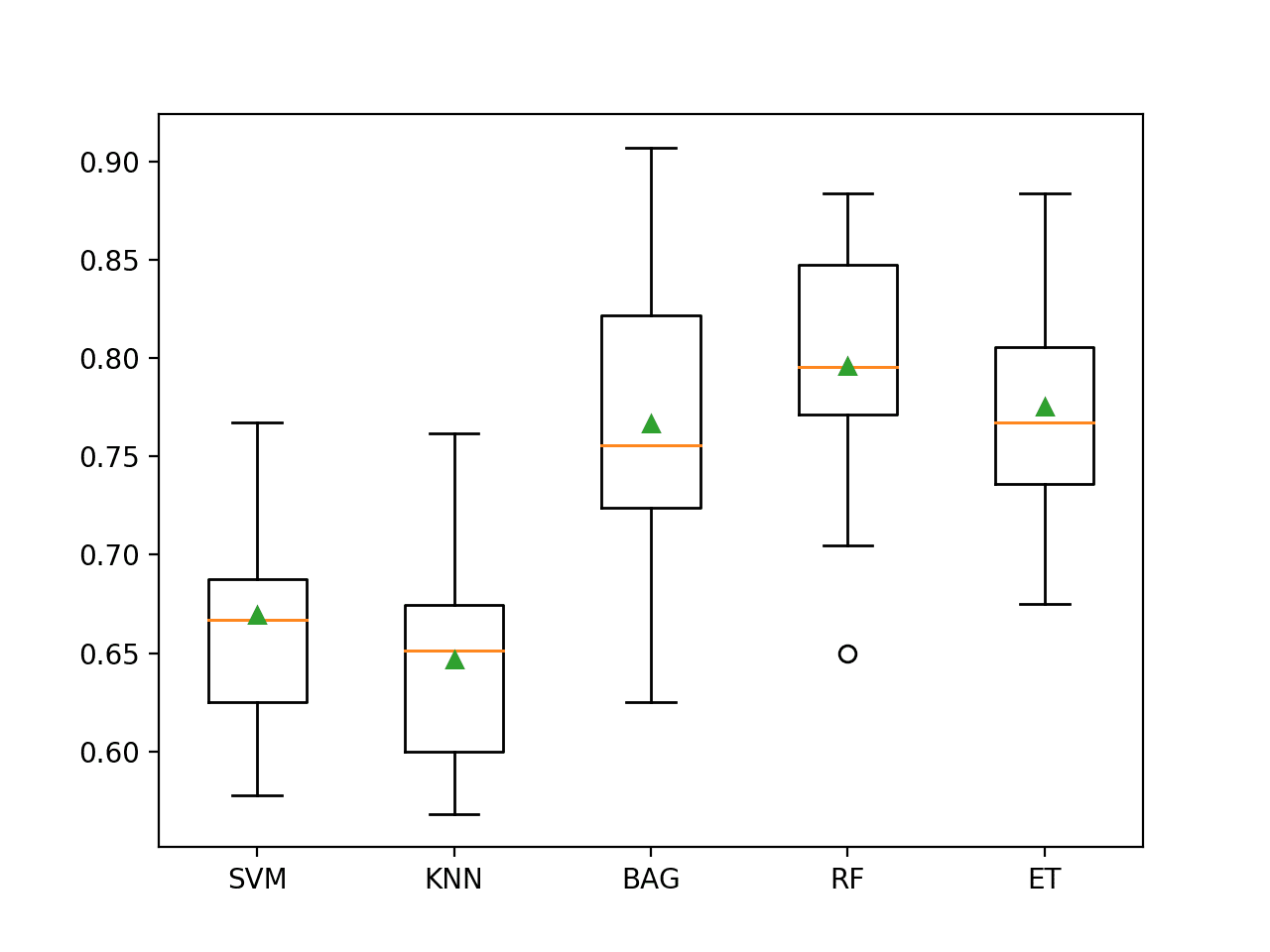
不平衡玻璃识别数据集上机器学习模型的箱须图
现在我们已经了解了如何在此数据集上评估模型,接下来看看如何使用最终模型进行预测。
改进模型
本节列出了发现性能优于上述模型的模型,这些模型是在教程发布后添加的。
成本敏感随机森林(80.8%)
发现具有自定义类别权重的成本敏感随机森林模型实现了更好的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 带有自定义类别权重的成本敏感随机森林 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义模型 weights = {0:1.0, 1:1.0, 2:2.0, 3:2.0, 4:2.0, 5:2.0} model = RandomForestClassifier(n_estimators=1000, class_weight=weights) # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行该示例评估算法,并报告平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能有所不同。请考虑多次运行示例并比较平均结果。
在这种情况下,该模型实现了约80.8%的准确率。
|
1 |
Mean Accuracy: 0.808 (0.059) |
能做得更好吗?
请在下面的评论中告诉我,如果我能使用相同的测试框架复现结果,我会将您的模型添加到此处。
在新数据上进行预测
在本节中,我们可以拟合最终模型并使用它来预测单行数据。
我们将使用随机森林模型作为我们的最终模型,该模型实现了约79%的分类准确率。
首先,我们可以定义模型。
|
1 2 3 |
... # 定义要评估的模型 model = RandomForestClassifier(n_estimators=1000) |
定义好后,我们就可以在整个训练数据集上对其进行拟合。
|
1 2 3 |
... # 拟合模型 model.fit(X, y) |
训练完成后,我们可以通过调用 `predict()` 函数来为新数据进行预测。
这将为每个样本返回类别标签。
例如
|
1 2 3 4 5 |
... # 定义一行数据 row = [...] # 预测类别标签 yhat = model.predict([row]) |
为了演示这一点,我们可以使用已训练好的模型来预测一些已知结果的案例的标签。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 训练模型并在玻璃识别数据集上进行预测 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.ensemble import RandomForestClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) 返回 X, y # 定义数据集位置 full_path = 'glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义要评估的模型 model = RandomForestClassifier(n_estimators=1000) # 拟合模型 model.fit(X, y) # 已知类别 0 (数据集中为类别 1) row = [1.52101,13.64,4.49,1.10,71.78,0.06,8.75,0.00,0.00] print('>预测=%d (实际为 0)' % (model.predict([row]))) # 已知类别 1 (数据集中为类别 2) row = [1.51574,14.86,3.67,1.74,71.87,0.16,7.36,0.00,0.12] print('>预测=%d (实际为 1)' % (model.predict([row]))) # 已知类别 2 (数据集中为类别 3) row = [1.51769,13.65,3.66,1.11,72.77,0.11,8.60,0.00,0.00] print('>预测=%d (实际为 2)' % (model.predict([row]))) # 已知类别 3 (数据集中为类别 5) row = [1.51915,12.73,1.85,1.86,72.69,0.60,10.09,0.00,0.00] print('>预测=%d (实际为 3)' % (model.predict([row]))) # 已知类别 4 (数据集中为类别 6) row = [1.51115,17.38,0.00,0.34,75.41,0.00,6.65,0.00,0.00] print('>预测=%d (实际为 4)' % (model.predict([row]))) # 已知类别 5 (数据集中为类别 7) row = [1.51556,13.87,0.00,2.54,73.23,0.14,9.41,0.81,0.01] print('>预测=%d (实际为 5)' % (model.predict([row]))) |
首先运行示例,在整个训练数据集上拟合模型。
然后使用训练好的模型来预测从六个类别中各选一个样本的标签。
我们可以看到,对于选定的每个样本,都正确预测了类别标签。尽管如此,平均而言,我们预计 5 次预测中会有 1 次是错误的,而且这些错误可能不会在各个类别之间平均分配。
|
1 2 3 4 5 6 |
>预测值=0(期望值 0) >预测值=1(期望值 1) >预测=2 (实际为 2) >预测=3 (实际为 3) >预测=4 (实际为 4) >预测=5 (实际为 5) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
- pandas.read_csv API.
- sklearn.dummy.DummyClassifier API.
- sklearn.ensemble.RandomForestClassifier API.
数据集 (Dataset)
总结
在本教程中,您学习了如何为不平衡的多类别玻璃识别数据集开发和评估模型。
具体来说,你学到了:
- 如何加载和探索数据集,并为数据准备和模型选择提供思路。
- 如何使用稳健的测试框架系统地评估一套机器学习模型。
- 如何拟合最终模型并使用它来预测特定样本的类别标签。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






很棒的文章。对学习者和从业者都有很大的帮助。
谢谢!
很棒的文章。
您没有说明如何处理不平衡情况?
最常用的包是什么?
集成模型默认情况下是否适合处理不平衡数据?
最重要的是,我应该先做什么:特征选择还是数据平衡?
谢谢你。
好问题,请看这个框架
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
感谢分享,对于初学者了解您如何开始以及如何进行每个项目非常有帮助。在许多项目中,我看到类似的步骤,但这就是现实。谢谢!
很高兴它有帮助。
你好,感谢你精彩的教程。
在多类别分类中,对于不平衡数据集,准确率不是一个有效的指标,我们还应该计算精确率、召回率和 F1 分数。
我训练了一个多类别和多任务的二元网络来处理 35 个人类属性。在预测时,对于大多数类别,它总是返回 0 或 1。准确率很高,但其他指标非常糟糕。你知道可能是什么问题吗?我更改了损失函数并向 resnet50 添加了一些层,但问题仍然存在。
它可以是。
我建议选择最能体现您项目目标的指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
Jason,你有没有办法对这个不平衡分类进行多行预测?🙁
是的,调用 `model.predict()` 可以对一行或多行进行预测。
线性可分性适用于多类别分类吗?
如果适用,我该如何检查多类别数据集的线性可分性?
如果我将逻辑回归拟合到整个数据集并测试到整个数据集,然后如果我获得接近 100% 的分数,假设类别是线性可分的,这是否正确?
是的。
或许可以绘制按类别标签着色的数据对。
不,要评估性能,请在一个数据集上拟合,并在另一个数据集上评估,或者使用 k 折交叉验证。
谢谢。实际上,我以为只用逻辑回归来检查线性可分性,而不是为了生成预测。那么在这种情况下,上述方法是否适用?
根据我在堆栈溢出上找到的内容
首先,要检查数据是否线性可分,请*不要*使用交叉验证。只需将模型拟合到所有数据并检查错误,无需训练/验证/测试拆分,训练所有数据——测试所有数据。
从
谢谢
San
也许可以。
如果线性模型在分类数据集上表现良好,则提供了该数据集线性可分的弱证据。
要计算零准确率,我们应该使用训练集和测试集中的哪个集合?
谢谢
San
什么是零准确率?
根据我在博客上找到的内容,它是:
• 总是预测最常见类别可以达到的准确率。
• 这意味着一个总是预测 0/1 的哑模型将有 “null_accuracy”% 的时间是正确的。
在您的文章中,您称之为“基线性能”。我希望零准确率和基线性能是相同的。
要计算这个,我们应该使用训练集和测试集中的哪个集合?
谢谢,我从未听说过。
不同的指标使用不同的朴素分类器,本教程将建议为每个指标使用哪个朴素分类器
https://machinelearning.org.cn/naive-classifiers-imbalanced-classification-metrics/
假设我有一个训练集和测试集,如 X_train, y_train, X_test, y_test。
我有一个多类别分类问题,如果我像这样计算训练和测试错误,是否正确?
print(“训练误差 “, 1 – accuracy_score( y_train, model.predict( X_train )))
print(“测试误差 “, 1 – accuracy_score( y_test, model.predict( X_test )))
当然,但准确率对于不平衡分类来说是一个非常糟糕的指标
https://machinelearning.org.cn/failure-of-accuracy-for-imbalanced-class-distributions/
如果我使用 f1_score 作为指标,像这样计算训练误差和测试误差是否合理
print(“训练误差 “, 1 – f1_score( y_train, model.predict( X_train )))
print(“测试误差 “, 1 – f1_score( y_test, model.predict( X_test )))
谢谢
San
不,那是不正确的。误差是准确率的倒数,正如你之前所说,它只是一个评估不平衡数据集的糟糕指标。
在应用独热编码之前,我的特征是分类的,在应用 OHE 之后,其中一些变量变成了整数。
那么,找到特征之间相关性的正确方法是在应用独热编码之前还是之后?
谢谢
San
相关性是在原始数据上计算的,而不是在独热编码数据上。
分类数据使用分类相关性,数值数据使用数值相关性
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
Jason你好。我的数据集总数据量达到 3000。数据集被划分为几个类别。
类别 A:455
类别 B:540
类别 C:566
类别 D:491
类别 E:399
类别 F:248
类别 G:450
类别 H:295
我想问的是,我的数据集是否是数据集不平衡的?
感谢您的帮助
有点不平衡。试试这个框架
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
Jason 你好。我是机器学习新手。我的不平衡数据集被分为四个类别,总共 3000 个实例
类别 A:0
类别 B:1802
类别 C:1198
类别 D:0
在这个数据集中,我该如何精确地预测类别?如果您能指导我,我将不胜感激。
本教程将向您展示如何为多类别分类配置精确率
https://machinelearning.org.cn/precision-recall-and-f-measure-for-imbalanced-classification/
你好,先生,
这篇博客太棒了。
有一件事我没弄明白,你是如何选择随机森林的权重的?
有什么规则吗?
谢谢你
谢谢。
设置为“balanced”,它将根据数据集为您设置权重。