决策树是一种强大的预测方法,并且非常受欢迎。
它们之所以受欢迎,是因为最终模型对于实践者和领域专家来说都非常容易理解。最终的决策树可以精确地解释为什么会做出某个特定的预测,这使得它在实际应用中极具吸引力。
决策树也为更高级的集成方法(如装袋法、随机森林和梯度提升)奠定了基础。
在本教程中,您将学习如何使用Python从零开始实现分类和回归树算法。
完成本教程后,您将了解:
- 如何计算和评估数据中的候选分割点。
- 如何将分割组织成决策树结构。
- 如何将分类和回归树算法应用于实际问题。
启动您的项目,阅读我的新书《从零开始的机器学习算法》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。
- 更新于 2017 年 1 月:更改了 `cross_validation_split()` 中 `fold_size` 的计算,使其始终为整数。修复了 Python 3 的问题。
- 2017 年 2 月更新:修复了 build_tree 中的一个 bug。
- 2017 年 8 月更新:修复了 Gini 计算中的一个 bug,添加了按组大小对组 Gini 分数进行加权的功能(感谢 Michael!)。
- 2018 年 8 月更新:测试并更新以与 Python 3.6 配合使用。

如何用 Python 从零开始实现决策树算法
照片由 Martin Cathrae 拍摄,保留部分权利。
描述
本节简要介绍了分类和回归树算法以及本教程使用的纸币数据集。
分类与回归树
分类和回归树,简称 CART,是 Leo Breiman 提出的一个缩写,用于指代可用于分类或回归预测建模问题的决策树算法。
在本教程中,我们将专注于使用 CART 进行分类。
CART模型的表示是一个二叉树。这与算法和数据结构中的二叉树相同,没有什么特别之处(每个节点可以有零个、一个或两个子节点)。
节点代表一个输入变量(X)以及该变量上的一个分割点,假设该变量是数值型的。树的叶节点(也称为终端节点)包含一个输出变量(y),用于进行预测。
一旦创建,就可以使用新的数据行导航树,沿着每个分支直到做出最终预测。
创建二叉决策树实际上是一个分割输入空间的过程。一种被称为递归二分分割的贪婪方法用于分割空间。这是一个数值过程,所有值都被排列起来,并使用成本函数尝试和测试不同的分割点。
根据成本函数选择成本最低的分割点。所有输入变量和所有可能的分割点都被贪婪地评估和选择,基于成本函数。
- 回归:为了选择分割点而最小化的成本函数是落在矩形内的所有训练样本的总平方误差。
- 分类:使用 Gini 成本函数,它指示了节点的纯度,其中节点纯度是指分配到每个节点的训练数据混合程度。
分割持续进行,直到节点包含最少数量的训练样本或达到最大树深度。
纸币数据集
纸币数据集涉及根据从照片中获取的若干测量值来预测给定纸币是否是真实的。
该数据集包含 1,372 行,具有 5 个数值变量。这是一个二分类问题(二元分类)。
下面列出了数据集中五个变量的列表。
- 小波变换图像的方差(连续)。
- 小波变换图像的偏度(连续)。
- 图像的峰度(连续)。
- 图像的熵(连续)。
- 类别(整数)。
下面是数据集中前 5 行的样本
|
1 2 3 4 5 6 |
3.6216,8.6661,-2.8073,-0.44699,0 4.5459,8.1674,-2.4586,-1.4621,0 3.866,-2.6383,1.9242,0.10645,0 3.4566,9.5228,-4.0112,-3.5944,0 0.32924,-4.4552,4.5718,-0.9888,0 4.3684,9.6718,-3.9606,-3.1625,0 |
使用零规则算法预测最常见的类别值,该问题的基线准确率为 50% 左右。
您可以从 UCI 机器学习库了解更多信息并下载该数据集。
下载数据集并将其保存在当前工作目录中,文件名为 data_banknote_authentication.csv。
教程
本教程分为 5 部分
- Gini 指数。
- 创建分割。
- 构建树。
- 进行预测。
- 纸币案例研究。
这些步骤将为您提供从零开始实现 CART 算法并将其应用于您自己的预测建模问题的基础。
1. Gini 指数
Gini 指数是用于评估数据集中分割的成本函数的名称。
数据集中的分割涉及一个输入属性和一个该属性的值。它可用于将训练样本分成两组行。
Gini 分数通过分割创建的两组类别混合程度来表明分割的好坏。完美分离的结果是 Gini 分数为 0,而最差的分割结果是每组 50/50 类别,则 Gini 分数为 0.5(对于 2 类问题)。
通过示例可以最好地演示 Gini 的计算。
我们有两个数据组,每个组有 2 行。第一组中的行都属于类别 0,第二组中的行都属于类别 1,所以这是一个完美的分割。
我们首先需要计算每个组中类别的比例。
|
1 |
比例 = 计数(类别值)/ 计数(行) |
此示例的比例将是
|
1 2 3 4 |
group_1_class_0 = 2 / 2 = 1 group_1_class_1 = 0 / 2 = 0 group_2_class_0 = 0 / 2 = 0 group_2_class_1 = 2 / 2 = 1 |
然后,Gini 的计算方法如下:
|
1 2 |
gini_index = sum(proportion * (1.0 - proportion)) gini_index = 1.0 - sum(proportion * proportion) |
然后,每个组的 Gini 指数必须按该组的大小相对于父节点中所有样本的比例进行加权,例如,当前正在分组的所有样本。我们可以按如下方式将此加权添加到组的 Gini 计算中:
|
1 |
gini_index = (1.0 - sum(proportion * proportion)) * (group_size/total_samples) |
在此示例中,每个组的 Gini 分数计算如下:
|
1 2 3 4 5 6 |
Gini(group_1) = (1 - (1*1 + 0*0)) * 2/4 Gini(group_1) = 0.0 * 0.5 Gini(group_1) = 0.0 Gini(group_2) = (1 - (0*0 + 1*1)) * 2/4 Gini(group_2) = 0.0 * 0.5 Gini(group_2) = 0.0 |
然后,这些分数按每个子节点在分割点处进行加总,以获得分割点的最终 Gini 分数,该分数可以与其他候选分割点进行比较。
此分割点的 Gini 将为 0.0 + 0.0,即完美的 Gini 分数 0.0。
下面是一个名为 gini_index() 的函数,它计算一组组和一组已知类别值的 Gini 指数。
您可以看到其中有一些安全检查,以避免空组的除以零错误。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 计算分割数据集的基尼指数 def gini_index(groups, classes): # 计算分割点处的所有样本 n_instances = float(sum([len(group) for group in groups])) # 对每个组的加权基尼指数求和 gini = 0.0 for group in groups: size = float(len(group)) # 避免除以零 if size == 0: continue score = 0.0 # 根据每个类别的分数对组进行评分 for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # 根据其相对大小对组分数进行加权 gini += (1.0 - score) * (size / n_instances) return gini |
我们可以用上面计算的例子来测试这个函数。我们也可以测试每个组中 50/50 分割的最坏情况。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 计算分割数据集的基尼指数 def gini_index(groups, classes): # 计算分割点处的所有样本 n_instances = float(sum([len(group) for group in groups])) # 对每个组的加权基尼指数求和 gini = 0.0 for group in groups: size = float(len(group)) # 避免除以零 if size == 0: continue score = 0.0 # 根据每个类别的分数对组进行评分 for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # 根据其相对大小对组分数进行加权 gini += (1.0 - score) * (size / n_instances) return gini # 测试 Gini 值 print(gini_index([[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1])) print(gini_index([[[1, 0], [1, 0]], [[1, 1], [1, 1]]], [0, 1])) |
运行示例将打印两个 Gini 分数,首先是最坏情况下的 0.5,然后是最佳情况下的 0.0。
|
1 2 |
0.5 0.0 |
现在我们知道如何评估分割结果了,让我们看看如何创建分割。
2. 创建分割
分割由数据中的一个属性和一个值组成。
我们可以将其概括为要分割的属性的索引以及用于分割该属性行的值。这只是对数据行进行索引的一种便捷的简写。
创建分割包括三个部分,第一个部分我们已经看过了,那就是计算 Gini 分数。其余两个部分是:
- 分割数据集。
- 评估所有分割。
让我们逐一查看。
2.1. 分割数据集
分割数据集意味着根据属性的索引和该属性的分割值,将数据集分成两行列表。
一旦我们有了这两组,我们就可以使用上面的 Gini 分数来评估分割的成本。
分割数据集包括遍历每一行,检查属性值是否小于或大于分割值,并分别将其分配到左组或右组。
下面是一个名为 test_split() 的函数,它实现了这个过程。
|
1 2 3 4 5 6 7 8 9 |
# 根据属性和属性值分割数据集 def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right = list() return left, right |
没什么特别的。
请注意,右组包含所有在索引处值大于或等于分割值的行。
2.2. 评估所有分割
有了上面的 Gini 函数和测试分割函数,我们现在拥有了评估分割所需的一切。
给定一个数据集,我们必须将属性上的每个值作为候选分割进行检查,评估分割的成本,并找到我们可以进行的最优分割。
一旦找到最佳分割,我们就可以将其作为决策树中的一个节点。
这是一个穷举的贪婪算法。
我们将使用字典来表示决策树中的节点,因为我们可以按名称存储数据。在选择最佳分割并将其用作树的新节点时,我们将存储所选属性的索引、用于分割该属性的值以及通过所选分割点分割的两组数据。
每组数据都是一个小的数据集,只包含通过分割过程分配到左组或右组的那些行。您可以想象我们如何递归地再次分割每个组,同时构建我们的决策树。
下面是一个名为 get_split() 的函数,它实现了这个过程。您可以看到它遍历每个属性(除类别值外),然后遍历该属性的每个值,在遍历过程中进行分割和评估。
最佳分割会被记录下来,并在所有检查完成后返回。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 为数据集选择最佳分割点 def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} |
我们可以构造一个小型数据集来测试这个函数和我们整个数据集的分割过程。
|
1 2 3 4 5 6 7 8 9 10 11 |
X1 X2 Y 2.771244718 1.784783929 0 1.728571309 1.169761413 0 3.678319846 2.81281357 0 3.961043357 2.61995032 0 2.999208922 2.209014212 0 7.497545867 3.162953546 1 9.00220326 3.339047188 1 7.444542326 0.476683375 1 10.12493903 3.234550982 1 6.642287351 3.319983761 1 |
我们可以使用每种类别的不同颜色来绘制此数据集。您可以看到,手动选择 X1 的值(图上的 x 轴)来分割此数据集并不难。
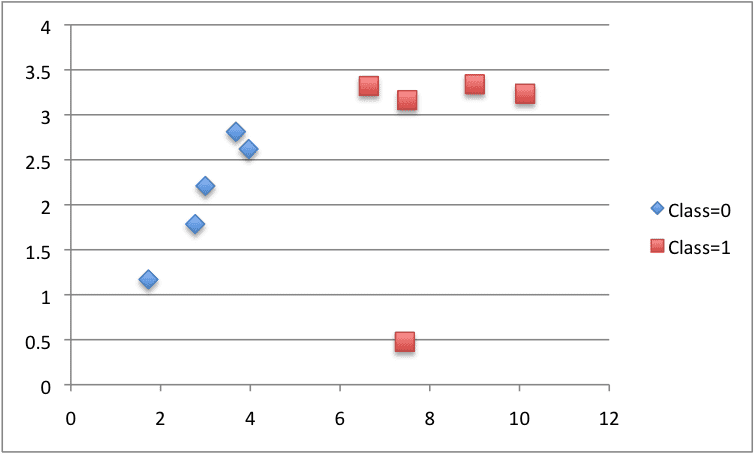
CART 构造的数据集
下面的示例将所有这些内容整合在一起。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# 根据属性和属性值分割数据集 def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right = list() return left, right # 计算分割数据集的基尼指数 def gini_index(groups, classes): # 计算分割点处的所有样本 n_instances = float(sum([len(group) for group in groups])) # 对每个组的加权基尼指数求和 gini = 0.0 for group in groups: size = float(len(group)) # 避免除以零 if size == 0: continue score = 0.0 # 根据每个类别的分数对组进行评分 for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # 根据其相对大小对组分数进行加权 gini += (1.0 - score) * (size / n_instances) return gini # 为数据集选择最佳分割点 def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) print('X%d < %.3f Gini=%.3f' % ((index+1), row[index], gini)) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] split = get_split(dataset) print('Split: [X%d < %.3f]' % ((split['index']+1), split['value'])) |
get_split() 函数已被修改,可以在评估过程中打印每个分割点及其 Gini 指数。
运行示例将打印所有 Gini 分数,然后打印最佳分割分数,即 X1 < 6.642,Gini 指数为 0.0,即完美分割。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
X1 < 2.771 Gini=0.444 X1 < 1.729 Gini=0.500 X1 < 3.678 Gini=0.286 X1 < 3.961 Gini=0.167 X1 < 2.999 Gini=0.375 X1 < 7.498 Gini=0.286 X1 < 9.002 Gini=0.375 X1 < 7.445 Gini=0.167 X1 < 10.125 Gini=0.444 X1 < 6.642 Gini=0.000 X2 < 1.785 Gini=0.500 X2 < 1.170 Gini=0.444 X2 < 2.813 Gini=0.320 X2 < 2.620 Gini=0.417 X2 < 2.209 Gini=0.476 X2 < 3.163 Gini=0.167 X2 < 3.339 Gini=0.444 X2 < 0.477 Gini=0.500 X2 < 3.235 Gini=0.286 X2 < 3.320 Gini=0.375 分割:[X1 < 6.642] |
现在我们知道了如何在数据或行列表中找到最佳分割点,让我们看看如何使用它来构建决策树。
3. 构建树
创建树的根节点很简单。
我们使用上面的 get_split() 函数并传入整个数据集。
向树中添加更多节点更有趣。
构建树可能分为 3 个主要部分:
- 终端节点。
- 递归分割。
- 构建树。
3.1. 终端节点
我们需要决定何时停止生长树。
我们可以通过树的深度和节点在训练数据集中负责的行数来做到这一点。
- 最大树深度。这是从树根节点开始的最大节点数。一旦达到树的最大深度,我们就必须停止分割并添加新节点。更深的树更复杂,并且更有可能过拟合训练数据。
- 最小节点记录数。这是给定节点负责的最少训练样本数。一旦达到或低于此最小值,我们就必须停止分割并添加新节点。负责的训练样本太少的节点预计会过于具体,并且很可能过拟合训练数据。
这两种方法将是我们的树构建过程的用户指定参数。
还有一种情况。有可能选择一个分割,其中所有行都属于一个组。在这种情况下,我们将无法继续分割和添加子节点,因为我们将在某一边或另一边没有记录可供分割。
现在我们对何时停止生长树有了一些想法。当我们停止在给定点生长时,该节点称为终端节点,并用于做出最终预测。
这是通过获取分配给该节点的行组并选择组中最常见的类别值来完成的。这将用于进行预测。
下面是一个名为 to_terminal() 的函数,它将为一组行选择一个类别值。它返回列表中行中最常见的输出值。
|
1 2 3 4 |
# 创建一个终端节点值 def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) |
3.2. 递归分割
我们知道如何以及何时创建终端节点,现在我们可以构建我们的树。
构建决策树涉及反复调用上面开发的 get_split() 函数来处理为每个节点创建的组。
添加到现有节点的新节点称为子节点。一个节点可以有零个子节点(终端节点),一个子节点(一个分支直接进行预测)或两个子节点。在给定节点的字典表示中,我们将子节点称为左节点和右节点。
一旦创建了一个节点,我们就可以通过再次调用相同的函数来递归地在分割产生的每个数据组上创建子节点。
下面是一个实现此递归过程的函数。它将一个节点作为参数,以及最大深度、节点中的最小样本数和节点的当前深度。
您可以想象如何首次调用它,传入根节点和深度 1。这个函数最好分步解释:
- 首先,提取节点分割的两个数据组以供使用,并从节点中删除。在我们处理这些组时,节点不再需要访问这些数据。
- 接下来,我们检查左组或右组是否为空,如果是,我们使用我们拥有的记录来创建终端节点。
- 然后我们检查是否已达到最大深度,如果是,我们创建终端节点。
- 然后,我们处理左子节点,如果行组太小,则创建一个终端节点,否则,以深度优先的方式创建并添加左节点,直到达到该分支的树底。然后以相同的方式处理右侧,当我们重新上升到树的根节点时。
- 然后在构建的树中,我们向上回溯到根节点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 为节点创建子分割或使其成为终端 def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # 检查是否没有分割 if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # 检查是否达到最大深度 if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # 处理左子节点 if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # 处理右子节点 if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) |
3.3. 构建树
现在我们可以将所有部分组合在一起。
构建树的过程包括创建根节点并调用 split() 函数,然后该函数递归地调用自身来构建整棵树。
下面是实现此过程的小型 build_tree() 函数。
|
1 2 3 4 5 |
# 构建决策树 def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root |
我们可以使用上面构造的小数据集来测试整个过程。
下面是完整的示例。
还包含一个小型 print_tree() 函数,该函数递归地打印决策树的节点,每个节点占一行。虽然它不像真正的决策树图那样醒目,但它能让我们了解树的结构和所做的决策。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
# 根据属性和属性值分割数据集 def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right = list() return left, right # 计算分割数据集的基尼指数 def gini_index(groups, classes): # 计算分割点处的所有样本 n_instances = float(sum([len(group) for group in groups])) # 对每个组的加权基尼指数求和 gini = 0.0 for group in groups: size = float(len(group)) # 避免除以零 if size == 0: continue score = 0.0 # 根据每个类别的分数对组进行评分 for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # 根据其相对大小对组分数进行加权 gini += (1.0 - score) * (size / n_instances) return gini # 为数据集选择最佳分割点 def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} # 创建一个终端节点值 def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) # 为节点创建子分割或使其成为终端 def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # 检查是否没有分割 if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # 检查是否达到最大深度 if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # 处理左子节点 if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # 处理右子节点 if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) # 构建决策树 def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root # 打印决策树 def print_tree(node, depth=0): if isinstance(node, dict): print('%s[X%d < %.3f]' % ((depth*' ', (node['index']+1), node['value']))) print_tree(node['left'], depth+1) print_tree(node['right'], depth+1) else: print('%s[%s]' % ((depth*' ', node))) dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] tree = build_tree(dataset, 1, 1) print_tree(tree) |
我们可以通过改变 build_tree() 函数调用的第二个参数(最大深度)来测试此过程,并观察对打印树的影响。
当最大深度为 1 时,我们可以看到树使用了我们在上一节中发现的完美分割。这是一棵只有一个节点的树,也称为决策桩。
|
1 2 3 |
[X1 < 6.642] [0] [1] |
将最大深度增加到 2,我们会强制树进行分割,即使没有必要。根节点的左子节点和右子节点再次使用 X1 属性来分割已经完美混合的类别。
|
1 2 3 4 5 6 7 |
[X1 < 6.642] [X1 < 2.771] [0] [0] [X1 < 7.498] [1] [1] |
最后,也是反常地,我们可以强制再增加一个分割级别,最大深度为 3。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[X1 < 6.642] [X1 < 2.771] [0] [X1 < 2.771] [0] [0] [X1 < 7.498] [X1 < 7.445] [1] [1] [X1 < 7.498] [1] [1] |
这些测试表明,有很大的空间来改进实现,以避免不必要的分割。这留作扩展。
既然我们已经能够创建决策树,让我们看看如何使用它来对新数据进行预测。
4. 进行预测
使用决策树进行预测涉及使用专门提供的行数据来导航树。
同样,我们可以使用递归函数来实现这一点,其中根据分割如何影响提供的数据,将相同的预测例程递归地调用到左子节点或右子节点。
我们必须检查子节点是应作为预测返回的终端值,还是包含要考虑的树的另一个级别的字典节点。
下面是实现此过程的 predict() 函数。您可以看到给定节点中的索引和值
您可以看到给定节点中的索引和值如何用于评估提供的数据行是落在分割的左侧还是右侧。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 使用决策树进行预测 def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] |
我们可以使用我们构造的数据集来测试此函数。下面是一个示例,该示例使用硬编码的决策树,其中包含一个最佳分割数据的节点(决策桩)。
该示例对数据集中每一行都进行预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 使用决策树进行预测 def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] # 使用决策桩进行预测 stump = {'index': 0, 'right': 1, 'value': 6.642287351, 'left': 0} for row in dataset: prediction = predict(stump, row) print('Expected=%d, Got=%d' % (row[-1], prediction)) |
运行示例,结果如预期,对每一行都打印了正确的预测。
|
1 2 3 4 5 6 7 8 9 10 |
Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 |
现在我们知道了如何创建决策树以及如何使用它进行预测。接下来,让我们将其应用于实际数据集。
5. 纸币案例研究
本节将 CART 算法应用于纸币数据集。
第一步是加载数据集,并将加载的数据转换为我们可以用来计算分割点的数字。为此,我们将使用辅助函数 load_csv() 来加载文件,并使用 str_column_to_float() 将字符串数字转换为浮点数。
我们将使用 k 折交叉验证(k=5)来评估该算法。这意味着每折将使用 1372/5 = 274.4,即略多于 270 条记录。我们将使用辅助函数 evaluate_algorithm() 和 accuracy_metric() 来评估交叉验证算法并计算预测的准确性。
开发了一个名为 decision_tree() 的新函数来管理 CART 算法的应用,首先从训练数据集中创建树,然后使用该树对测试数据集进行预测。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 |
# CART 在纸币数据集上的应用 from random import seed from random import randrange from csv import reader # 加载 CSV 文件 def load_csv(filename): file = open(filename, "rt") lines = reader(file) dataset = list(lines) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 将数据集分成 k 折 def cross_validation_split(dataset, n_folds): dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for i in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_split # 计算准确率百分比 def accuracy_metric(actual, predicted): correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0 # 使用交叉验证分割评估算法 def evaluate_algorithm(dataset, algorithm, n_folds, *args): folds = cross_validation_split(dataset, n_folds) scores = list() for fold in folds: train_set = list(folds) train_set.remove(fold) train_set = sum(train_set, []) test_set = list() for row in fold: row_copy = list(row) test_set.append(row_copy) row_copy[-1] = None predicted = algorithm(train_set, test_set, *args) actual = [row[-1] for row in fold] accuracy = accuracy_metric(actual, predicted) scores.append(accuracy) 返回 分数 # 根据属性和属性值分割数据集 def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right = list() return left, right # 计算分割数据集的基尼指数 def gini_index(groups, classes): # 计算分割点处的所有样本 n_instances = float(sum([len(group) for group in groups])) # 对每个组的加权基尼指数求和 gini = 0.0 for group in groups: size = float(len(group)) # 避免除以零 if size == 0: continue score = 0.0 # 根据每个类别的分数对组进行评分 for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # 根据其相对大小对组分数进行加权 gini += (1.0 - score) * (size / n_instances) return gini # 为数据集选择最佳分割点 def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} # 创建一个终端节点值 def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) # 为节点创建子分割或使其成为终端 def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # 检查是否没有分割 if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # 检查是否达到最大深度 if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # 处理左子节点 if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # 处理右子节点 if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) # 构建决策树 def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root # 使用决策树进行预测 def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] # 分类和回归树算法 def decision_tree(train, test, max_depth, min_size): tree = build_tree(train, max_depth, min_size) predictions = list() for row in test: prediction = predict(tree, row) predictions.append(prediction) return(predictions) # 在纸币数据集上测试 CART seed(1) # 加载并准备数据 filename = 'data_banknote_authentication.csv' dataset = load_csv(filename) # 将字符串属性转换为整数 for i in range(len(dataset[0])): str_column_to_float(dataset, i) # 评估算法 n_folds = 5 max_depth = 5 min_size = 10 scores = evaluate_algorithm(dataset, decision_tree, n_folds, max_depth, min_size) print('Scores: %s' % scores) print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores)))) |
该示例使用 5 层最大树深度和每节点最小行数为 10。CART 的这些参数是通过一些实验选择的,但绝非最优。
运行示例将打印出每折的平均分类准确率以及所有折的平均性能。
您可以看到,CART 和所选配置实现了大约 97% 的平均分类准确率,这比仅获得 50% 准确率的零规则算法有了显著提高。
|
1 2 |
Scores: [96.35036496350365, 97.08029197080292, 97.44525547445255, 98.17518248175182, 97.44525547445255] Mean Accuracy: 97.299% |
扩展
本节列出了本教程的扩展内容,您可能希望进行探索。
- 算法调优。CART 在纸币数据集上的应用尚未进行调优。尝试不同的参数值,看看是否可以获得更好的性能。
- 交叉熵。另一个用于评估分割的成本函数是交叉熵(对数损失)。您可以实现并尝试此替代成本函数。
- 树剪枝。减少训练数据集过拟合的重要技术是剪枝树。研究并实现树剪枝方法。
- 分类数据集。该示例专为具有数值或有序输入属性的输入数据而设计,尝试使用分类输入数据和可能使用相等性而不是排秩的分割。
- 回归。使用不同的成本函数和创建终端节点的方法来调整树以用于回归。
- 更多数据集。将算法应用于 UCI 机器学习存储库上的更多数据集。
您是否探索过这些扩展?
在下面的评论中分享您的经验。
回顾
在本教程中,您学习了如何从头开始使用 Python 实现决策树算法。
具体来说,你学到了:
- 如何选择和评估训练数据集中的分割点。
- 如何从多个分割递归地构建决策树。
- 如何将 CART 算法应用于现实世界的分类预测建模问题。
你有什么问题吗?
请在下方评论中提问,我将尽力回答。
了解如何从零开始编写算法!

没有库,只有 Python 代码。
...附带真实世界数据集的逐步教程
在我的新电子书中探索如何实现
从零开始实现机器学习算法
它涵盖了 18 个教程,包含 12 种顶级算法的所有代码,例如
线性回归、k-近邻、随机梯度下降等等……
最后,揭开
机器学习算法的神秘面纱
跳过学术理论。只看结果。






超级好.. 非常感谢分享
很高兴你觉得它有用 steve。
你好,你能解释一下这是什么意思吗?
[X1 < 6.642]
[X1 < 2.771]
[0]
[0]
[X1 < 7.498]
[1]
[1]
这是否意味着如果 X1 <6.642 且 X1 <2.771,则属于类别 0,如果 X1 <6.642 且 X1 < 7.498,则属于类别 1?
谢谢你的帮助。
Mak
是的,[X1 < 6.642] 是根节点,有两个子节点,每个叶节点都有一个分类标签。
你好,你能帮我解决这个问题吗?
该项目要求您编写两个函数。第一个函数将采用包括特征类型的训练数据,并返回最佳模拟分类问题的决策树。这不应进行任何树剪枝。家庭作业的可选部分将需要剪枝步骤。第二个函数将仅将决策树应用于给定的数据点集。
您应该按照以下步骤进行此作业
1. 加载数据并对数据内容和特征进行快速分析。您需要构建一个指示每个特征类型(值)的向量。在这种情况下,您可以假设您具有数值(实数或整数)和分类值。
2. 实现函数“build_dt(X, y, attribute_types, options)”。
a. X:是训练数据的特征/属性矩阵。每一行包含一个数据样本。
b. y:包含 X 行中每个样本的类标签的向量。
c. attribute_types:包含(1:整数/实数)或(2:分类)的向量,指示每个属性(X 的列)的类型。
d. options:您可能要传递给决策树构建器的任何选项。
e. 返回您选择结构的决策树。
3. 实现函数“predict_dt(dt, X, options)”。
a. dt:由“build_dt”函数建模的决策树。
b. X:是测试数据的特征/属性矩阵。
c. 返回预测类标签的向量。
4. 使用适当的 k 折交叉验证和混淆矩阵来报告您的实现性能。
[可选] 实现课堂上讨论的剪枝策略。重复上述步骤 4。指出您可能做出的任何假设。
我认为您应该自己完成家庭作业。
如果您对家庭作业有疑问,请咨询您的老师。这就是您付费的原因。
你好,你能帮我解释我创建的模型吗?谢谢
[X1 < 2.000]
[X10 < 0.538]
[0.0]
[1.0]
[X15 < 10.200]
[X20 < 2.700]
[X10 < 0.574]
[X6 < 14.000]
[1.0]
[X8 < 256.000]
[1.0]
[X16 < 5.700]
[X18 < 0.600]
[X2 < 82.000]
[X15 < 4.100]
[0.0]
[0.0]
[1.0]
[X4 < 112.000]
[X1 < 3.000]
[0.0]
[0.0]
[0.0]
[0.0]
[0.0]
[0.0]
[1.0]
你好,太棒了,我可以用俄语翻译这篇文章并附上此资源的链接吗?
不,谢谢。这是我在这里经常回答的一个问题。
https://machinelearning.org.cn/faq/single-faq/can-i-translate-your-posts-books-into-another-language
你好 Jason,我可以用决策树代替规则引擎吗?
这实际上取决于应用程序的具体细节和利益相关者的要求。
这段代码能用于多项式决策树数据集吗?
通过一些修改可以。
你会推荐什么样的修改?
特别是处理名义值在分割点上的评估和选择。
感谢您的详细描述和代码。
我尝试运行并在第 26 行收到“ValueError: empty range for randrange()”
index = randrange(len(dataset_copy))
如果将 dataset_copy 替换为 list(dataset) 并手动运行此行,则可以正常工作。
听起来像是 Python 3 的问题 Mike。
替换
为
我已经更新了上面示例中的 cross_validation_split() 函数,以解决 Python 3 的问题。
是否可以使用欧氏距离而不是为数据集中的每个元素计算?
你具体是什么意思?你能详细说明一下吗?
非常感谢
不客气。
嗨,Jason,
CART 的优秀教程!
决策树的结果相当依赖于训练数据和测试数据。考虑到这一点,我现在应该如何在代码中设置训练数据与测试数据的比例以改变结果?从我看到的来看,似乎它们是在 evaluate_algorithm 方法中设置的。
//Kind regards
Sokrates
没错 Sokrates。
该示例使用 k 折交叉验证来评估算法在数据集上的性能。
您可以通过设置“n_folds”变量来更改折数。
您可以使用不同的重采样方法,例如训练/测试拆分,请参阅此帖子
https://machinelearning.org.cn/implement-resampling-methods-scratch-python/
好帖子。我想问一下,这个实现是否可以用于只有一个特征的时间序列数据?
是的,可以,但时间序列数据必须重新构建为监督学习问题。
有关更多信息,请参阅此帖子
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
非常有帮助。非常感谢分享。
很高兴您觉得这篇帖子有帮助,vishal。
嗨,Jason,
您的代码中有一个小地方。具体来说,在以下过程中
——
# 构建决策树
def build_tree(train, max_depth, min_size)
root = get_split(dataset)
split(root, max_depth, min_size, 1)
return root
——
我认为应该是 root = get_split(train),尽管您的代码仍然正常运行,因为 dataset 是全局变量。
感谢您发布的好文章。
我非常喜欢您的博客。
我认为你是对的,抓得好!
我会研究并修复这个例子。
非常感谢 Jason,非常有帮助
很高兴听到这个消息。
抱歉,我对您作品中的 get_split 函数感到困惑。实际上,我遇到一个问题,即使我有两个以上的特征,该函数也总是返回一个只有深度为一的树。作为一个新手,我发现解决这个问题有点困难。您能否回答我的问题?给我指个方向就可以了。谢谢。
也许你的数据并不需要不止一个分裂?
也许可以尝试 scikit-learn 库中的决策树?
我正在慢慢地看你的代码,对你 `get_split function` 中的一行感到困惑
groups = test_split(index, row[index], dataset)这是否只返回左边分组?我们需要两组来计算 gini_index?
谢谢你。
你好 Amit,
get_split() 函数评估所有可能的分割点,并返回一个包含找到的最佳分割点、基尼分数和分割数据的字典。
在对代码进行了一些操作后,我意识到该函数在一个变量下返回了两个分组(左和右)。
在 `split` 函数中
if not left or not right
node[‘left’] = node[‘right’] = to_terminal(left + right)
return
你为什么把 (left + right) 加起来?你是把两个分组加到一个分组里吗?
谢谢你。
是的。
另一个问题(第 132 行)
if isinstance(node[‘left’], dict)
return predict(node[‘left’], row)
isinstance 只是检查我们是否已经创建了这样的字典实例?
谢谢你。
它正在检查变量的类型是否是 dict。
我叫 Cynthia,我对机器学习和 Python 都很感兴趣,但我刚开始学习编码。这本书能帮我学习编码吗?我是一名测绘工程师,渴望晋升为环境工程师。
先学习编程会更容易。
或者,您可以使用 Weka 在不进行任何编程的情况下学习机器学习。
https://machinelearning.org.cn/start-here/#weka
你好,
我一直在尝试用这段代码做一些事情,我以为我明白了发生了什么,但当我用一个具有二元值的数据集尝试它时,它似乎不起作用,我找不到原因。你能帮帮我吗?
谢谢。
该示例假定输入是实数值,二进制或分类输入应进行不同的处理。
抱歉,我手头没有例子。
您好,
如果输入是分类的,那么用这种方式拆分输入是否正确?我使用了 `==` 或 `!=` 而不是小于和大于。
谢谢
也许可以尝试一下。
嘿,Hendra
对你来说奏效了吗?当我尝试我的数据集时,准确率下降到 30%。
嗨
你能告诉我如何使用决策树来预测一个未知函数,给定一个样本数据集吗?我的意思是,它是如何用于回归的?
好问题,抱歉,我没有从零开始的决策树回归示例。
如何使用 weka 进行决策树回归?
可以试试博客的搜索功能。
请看这篇文章
https://machinelearning.org.cn/use-regression-machine-learning-algorithms-weka/
很棒的文章,这正是我想要的!
很高兴听到这个消息,Joe!
我是机器学习的新手……成功地用给定的数据集运行了代码
现在我想为我的数据集运行它……算法是否总是将最后一列作为要分类的列?
谢谢
是的,代码就是这么写的。
谢谢!运行得非常好
干得好!
抱歉,如果我占用了太多时间,但我尝试在以下场景中使用此算法,折数设置为 10 折
#
#https://www.youtube.com/watch?v=eKD5gxPPeY0&list=PLBv09BD7ez_4temBw7vLA19p3tdQH6FYO
#
#outlook
#
#1 = sunny
#2 = overcast
#3 = rain
#
#humidity
#
#1 = high
#2 = normal
#
#wind
#
#1 = weak
#2 = strong
#
#play
#
#0 = no
#1 = yes
生成的树不处理 x2、x3 变量(由于某种原因),只为 x1 生成(我哪里做错了?)……准确率已降至 60%。
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 3.000]
[X1 < 1.000]
[1.0]
[1.0]
[0.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
得分:[100.0, 100.0, 0.0, 100.0, 0.0, 100.0, 0.0, 0.0, 100.0, 100.0]
平均准确率:60.000%
确保您正确加载了数据。
是的,现在运行正常了:)
我很想得到一个能以更图形化(可读)格式打印树的脚本。目前的格式有帮助,但有时会让人感到困惑。
非常感谢!
这将生成一个 graphviz dot 文件,您可以使用它来生成 .pnj、jpeg 等文件。
例如
dot -Tpng graph1.dot > graph.png
请注意,它每次调用时都会生成一个新文件——graph1.dot … graphN.dot
# code begin
def graph_node(f, node)
if isinstance(node, dict)
f.write(‘ %d [label=\”[X%d %d;\n’ % ((id(node), id(node[‘left’]))))
f.write(‘ %d -> %d;\n’ % ((id(node), id(node[‘right’]))))
graph_node(f, node[‘left’])
graph_node(f, node[‘right’])
else
f.write(‘ %d [label=\”[%s]\”];\n’ % ((id(node), node)))
def graph_tree(node)
if not hasattr(graph_tree, ‘n’): graph_tree.n = 0
graph_tree.n += 1
fn = ‘graph’ + str(graph_tree.n) + ‘.dot’
f = open(fn, ‘w’)
f.write(‘digraph {\n’)
f.write(‘ node[shape=box];\n’)
graph_node(f, node)
f.write(‘}\n’)
你好,哥们,我只需要把这些代码放在最后部分吗?你只定义了函数……我该如何运行它,在代码的哪个部分运行……谢谢
你好 Greg。我的代码不起作用。你能纠正它吗?
非常感谢您,Brownlee 博士!
我很高兴您觉得它有用。
出色的解释
我很高兴您觉得它有用。
我现在正在从头开始实现 AdaBoost,并且在理解如何将每次迭代中计算的样本权重应用于构建决策树时遇到了困难?我想我应该在这方面修改基尼指数,但我不太确定该怎么做。您能指点一下吗?谢谢!
我的这本书中提供了一个循序渐进的例子
https://machinelearning.org.cn/master-machine-learning-algorithms/
我也推荐这本书,它给出了很好的解释
http://www-bcf.usc.edu/~gareth/ISL/
代码的一部分:predicted = algorithm(train_set, test_set, *args)
TypeError: ‘int’ object is not callable
问题:我收到了这样的错误。请帮帮我。
我很抱歉听到这个消息。
确保您已复制所有代码,没有任何多余的空格。
嘿 Jason
老实说,伙计,这些东西不是开玩笑的。
我获得了数学学士学位和一年数学硕士学位
然后是统计计算和数据挖掘硕士学位
然后是 SAS 认证和大量的 R,伙计,我告诉你,
当我阅读你的作品,看到你对成功应用机器学习所需的各个领域的统一有如此深刻的理解时。
伙计,你真是个杀手。
谢谢。
你好,先生!
首先,非常感谢您提供如此出色的教程。
我想为 get_split() 函数提出一个建议——
在此函数中,与考虑数据集中该属性的每个值来计算基尼指数,我们可以仅使用该属性的平均值作为 test_split 函数的 split_value。
这只是我的想法,如果有错误请纠正我。
谢谢!
试试看吧。
你好先生,
我是一名学生,需要使用 Python 和 R 开发一个算法,用于决策树和集成(最好是随机森林)。我确实需要一本包含一切的“超级套装”的书。
非常感谢这篇帖子和教程。它们非常有帮助。
您可以在这里获取超级套装
https://machinelearning.org.cn/super-bundle/
你好先生,
首先,非常感谢您提供如此出色的教程
我是机器学习和 Python 的新手。我正在慢慢地看你的代码
我对以下部分有一个疑问
# 构建决策树
def build_tree(train, max_depth, min_size)
root = get_split(train)
split(root, max_depth, min_size, 1)
return root
在这个部分,“split”函数返回“none”。那么“split”函数中的更改是如何反映在“root”变量中的?
为了知道“root”变量中存储了什么值,我运行了如下代码:
# 构建决策树
def build_tree(train, max_depth, min_size)
root = get_split(train)
print(root) — 调用 split 函数之前
split(root, max_depth, min_size, 1)
print(root) — 调用 split 函数之后
两种情况下的值都不同。但我对它是如何发生的感到困惑。
有人能帮帮我吗?
谢谢你。
split 函数将子节点添加到传入的根节点以构建树。
你好,先生
感谢这篇教程。
我猜当将子分组的基尼指数相加得到总基尼指数时,应该考虑它们对应的分组大小,也就是说,我认为它应该是加权求和。
我认为我的问题与此类似。上面示例中计算的基尼指数没有按分区大小加权。它们不应该这样吗?我发布了一个详细的示例,但尚未被接受(yet?)。
你好先生,
假设我们已经使用上述算法创建了一个模型。
那么当我们使用这个模型进行预测时,这个模型会处理整个训练数据吗?
谢谢你。
我们不需要在想做预测时评估模型。我们先在所有训练数据上拟合它,然后开始使用它。
请看这篇文章
https://machinelearning.org.cn/train-final-machine-learning-model/
你好先生,
假设我有 100 万个训练数据,我创建并保存了一个模型来预测患者是否患有糖尿病。模型一切正常,并且已部署到客户端(医院)。请考虑以下情况:
1. 如果新患者来了,那么根据患者的一些输入,模型将预测患者是否患有糖尿病。
2. 如果另一位患者来了,我们的模型也会预测。
我的疑问是,在这两种情况下,模型都会处理一百万个训练数据吗?
也就是说,如果 100 位患者在不同时间到来,这个模型是否会处理 100 次,每次都处理一百万条数据(训练数据)?
谢谢你
不,拟合模型后,您会保存它。稍后加载它并进行预测。
请参阅此关于创建最终模型以进行预测的帖子。
https://machinelearning.org.cn/train-final-machine-learning-model/
太棒了,感谢分享!
是否有工具可以在完全不编码的情况下做到这一点?
我的意思是拖放/右键单击选项。
在很多情况下,理解幕后原理非常有用,但使用某种 UI 会更快。
您会推荐什么?
谢谢你,
Michael
是的,Weka
https://machinelearning.org.cn/start-here/#weka
你好,
非常棒的帖子。它对我帮助很大!
是否有关于 C4.5 算法的类似文章/教程?
在 R 中有实现吗?
谢谢你,
Ali。
请参阅 R 示例
https://machinelearning.org.cn/non-linear-classification-in-r-with-decision-trees/
dataset = list(lines)
错误:迭代器应该返回字符串,而不是字节(您是否以文本模式打开文件?)
如何解决这个问题?
这可能是一个 Python 版本问题。
尝试将文件加载更改为“rt”格式。
你好 Jason,感谢您分享这个算法,
我的最终任务是使用像决策树这样的分类模型来填充数据集中的缺失值,这可能吗?
谢谢你
是的,请参阅此帖以获取想法
https://machinelearning.org.cn/handle-missing-data-python/
嗨,Jason,
我尝试运行修改后的版本,添加了数据的标签
#添加标签,但不是训练的一部分
data = pd.read_csv(r’H:\Python\Tree\data_banknote_authentication.txt’, header = None )
dataset = pd.DataFrame(data)
dataset.columns = [‘var’, ‘skew’, ‘curt’, ‘ent’, ‘bin’]
所以最后一步,我只运行了
n_folds = 5
max_depth = 5
min_size = 10
scores = evaluate_algorithm(dataset, decision_tree, n_folds, max_depth, min_size)
print(‘Scores: %s’ % scores)
print(‘Mean Accuracy: %.3f%%’ % (sum(scores)/float(len(scores))))
我收到了错误消息,说
ValueError: randrange() 的范围为空
你能解释一下为什么吗?
另外,在加载 CSV 文件的这一部分
# 加载 CSV 文件
def load_csv(filename)
file = open(filename, “rb”)
lines = reader(file)
dataset = list(lines)
return dataset
你能解释一下如果文件在本地驱动器上,如何添加文件的位置吗?
非常感谢,
您建议我对以下问题进行哪些更改
一位保费支付者希望通过机器学习改善医疗保健。他们希望预测即将发生的诊断、手术或治疗。他们提供了使用 ICD9 编码的患者旅程信息。
您必须预测患者在 2014 年按发生顺序报告的未来 10 个事件。
数据描述
提供了三个文件供下载:train.csv、test.csv 和 sample_submission.csv
训练数据包括 2011 年 1 月至 2013 年 12 月的患者信息。测试数据包括 2014 年的患者 ID。
变量描述
ID 患者 ID
Date 诊断周期
Event 事件 ID (ICD9 格式) – 目标变量
听起来像是家庭作业。
如果不是,我建议按此过程处理新的预测建模问题
https://machinelearning.org.cn/start-here/#process
Jason,
感谢您提供的精彩示例。我重写了您的代码,与您写的一模一样,但无法复制您的分数和平均准确率。我得到的是
Scores: [28.467153284671532, 37.591240875912405, 76.64233576642336, 68.97810218978103, 70.43795620437956]
Mean Accuracy: 56.42335766423357
作为另一个运行,我将 nFolds 改为 7,maxDepth 改为 4,minSize 改为 4,得到了
Scores: [40.30612244897959, 38.775510204081634, 37.755102040816325, 71.42857142857143, 70.91836734693877, 70.91836734693877, 69.89795918367348]
Mean Accuracy: 57.142857142857146
我尝试了 nFolds、minSize 和 maxDepth 的所有组合,甚至尝试停止随机化数据实例到 Folds。然而,我的分数没有改变,我的平均准确率从未超过 60%,实际上一直保持在 55% 以上的范围内。奇怪的是,我的前两个分数很低,然后才提高,但没有达到 80%。我快要抓狂了,为什么我无法复制您的高(80%以上)分数/准确率。
有什么可能发生这种情况的吗?感谢您花时间阅读我的评论,再次感谢您精彩的演示。
Ikib
这很奇怪。
也许是某些地方复制粘贴错误?那将是我的最佳猜测。
嗨 Jason
对大小为 1 的组进行拆分(就像您现在对大小为 0 的组那样)没有用,您可以直接将它们设为终端节点。
此致
感谢 Jason 提供的这个非常完善的教程!
我阅读了这里所有的回复,看看是否有人问了我同样的问题。我认为 Xinglong Li 在 2017 年 6 月 24 日提出的问题与我的问题相同,但没有得到回答,所以我将重新表述一下。
基尼指数的计算不应该按每个组的计数加权吗?
例如,在“3. 构建树”部分前面的表格中,第 15 行的输出列出了
X2 < 2.209 Gini=0.934
当我手动计算时,如果我不按分区大小加权计算,就能得到这个确切的值。当我按我认为应该计算的方式(按分区大小加权)计算时,我得到 Gini=0.4762。这是我的计算方法
1) 从按 X1 排序的测试数据开始,以便我们轻松进行拆分(以 csv 格式表示)
X1,X2,Y
7.444542326,0.476683375,1
1.728571309,1.169761413,0
2.771244718,1.784783929,0
— 此行上方为第一组,此行下方为第二组 —
2.999208922,2.209014212,0
3.961043357,2.61995032,0
3.678319846,2.81281357,0
7.497545867,3.162953546,1
10.12493903,3.234550982,1
6.642287351,3.319983761,1
9.00220326,3.339047188,1
2) 计算比例(计算到 9 位小数,显示 4 位)
P(1, 0) = 第 1 组(上方),类别 0 = 0.6667
P(1, 1) = 第 1 组(上方),类别 1 = 0.3333
P(2, 0) = 第 2 组(下方),类别 0 = 0.4286
P(2, 1) = 第 2 组(下方),类别 1 = 0.5714
3) 计算不加权 (计算到 9 位小数,显示 4 位) 的 Gini 分数
Gini Score =
[P(1, 0) x (1 – P(1, 0))] +
[P(1, 1) x (1 – P(1, 1))] +
[P(2, 0) x (1 – P(2, 0))] +
[P(2, 1) x (1 – P(2, 1))] =
0.2222 + 0.2222 + 0.2449 + 0.2449 = 0.934(正如您所得到的)
4) 计算加权 (计算到 9 位小数,显示 4 位) 的 Gini 分数
[(3/10) x (0.2222 + 0.2222)] + [(7/10) x (0.2449 + 0.2449)] = 0.4762
您能解释一下为什么在计算 Gini 指数时不按分区大小加权吗?
谢谢!
你好 Michael,我相信计数是加权的。
请参阅算法描述中的“proportion”,以及 gini 的代码计算每个类别组。
请参阅“an introduction to statistical learning with applications in r”第 311 页 onwards 的方程。
这有帮助吗?
你好 Jason,谢谢回复。在仔细阅读了 ISL 的第 311 和 312 页多次之后,我觉得 ISL 中的方程 (8.6) 应该有一个下标 m 在 G 上,因为它计算的是某个区域的基尼分数。请注意,在该方程中:1)求和是对 K(总类别数)进行的,2)p hat 上的 mk 下标。这表明比例(p hat sub mk)和 G 都是相对于特定区域 m 的。
ISL 中的 Eqn. (8.6) 是正确的,但它不是用于确定拆分质量的最终数量。还有一个额外的步骤(ISL 中未描述):按所示示例中建议的拆分区域大小对基尼分数进行加权
https://www.researchgate.net/post/How_to_compute_impurity_using_Gini_Index
我认为 gini_index 函数应该类似于下面显示的内容。这个版本给了我预期的值,并且与上面示例中计算 gini 分数的方式一致。
有什么想法?
抱歉,代码缩进丢失了。似乎网络应用在发布前解析掉了它们。
我已经为您添加了一些 pre 标签。
我会看看的,谢谢分享。
感谢您的关注。我最初提出的代码有效,但包含一些不必要的代码。这是一个更简洁(行数更少)的实现(希望我插入的 pre 标签能生效……)
谢谢。已添加到我的 Trello 以便审查。
更新:是的,您 100% 正确。非常感谢您指出这一点并帮助我看到错误 Michael!我非常感激!
我做了一些关于计算的功课(查阅了一些教科书并阅读了 sklearn 的源代码),并从头开始编写了一个新的 gini 计算函数版本。然后我更新了教程。
我认为现在可以了,但如果您发现任何问题,请告诉我。
你好 Jason,在您的代码中
print(gini_index([[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1]))
零和一的数量(类别在组中的分布)应该如何解释?我对这个很陌生……
很好的问题!
不,每个数组是一个模式,每个数组的最后一个值是类别值。最后一个数组是有效类别。
我没有注意到使用旧的 Gini 代码和修改后的 Gini 代码在拆分点和预测方面有任何区别。
如何将其应用于离散值?
您推荐此决策树模型用于基于二进制文件的数据吗?
我不推荐任何一种算法。我建议测试一系列算法,看看哪种效果最好。
请看这篇文章
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
先生您好!
我想问一下,我的代码为什么需要大约 30-46 分钟才能得到平均准确率?我正在处理大约 24100 行数据,有 3 列。这正常吗?非常感谢!
是的,因为这只是一个演示。
为了更高效的实现,请使用 scikit-learn 中的实现。
关于为什么应该仅出于学习目的从头开始编写机器学习算法,请参阅此帖
https://machinelearning.org.cn/dont-implement-machine-learning-algorithms/
您能否提供一个带有 2 甚至 3 个阶段的较大硬编码决策树的示例?
我似乎无法正确使用语法来处理更大的决策树。
谢谢您的建议。请注意,代码可以开发这样的树。
是的,我自己刚发现,最好还是不要给例子,让我们自己思考一段时间。
我想问一下,是否有办法存储已经学习到的决策树?这样当为单个测试数据调用 predict 函数时,可以以更快的速度运行。非常感谢!
嘿 Maria,你可以把它保存到一个 .txt 文件,然后读取回来用于预测。我就是这么做的,而且效果非常好!
哦,好的。我会将 build_tree 的结果保存到文本文件吗?非常感谢这些信息!😀
Jarich,很棒的建议。
是的,我建议使用 sklearn 库,然后使用 pickle 保存拟合的模型。
我的博客上有一些这方面的例子,请使用搜索功能。
Jason:感谢您的精彩文章。您能否提供生成树的代码?我已获得分数和准确率,并希望查看决策树。请提供与生成树相关的代码。
我需要使用 graphviz 编写代码。
感谢您的建议。
我想知道这个树除了 0 或 1 之外,是否也能处理多个分类?例如,我需要分类为 1、2、3、4、5。非常感谢!
可以将其扩展到多个类别。抱歉,我没有示例。
我无法开始。
我使用 Python 3.5,Spyder 3.0.0。
您的代码无法读取数据集,并出现错误。
错误:迭代器应该返回字符串,而不是字节(您是否以文本模式打开文件?)
我是 Python 和 ML 的初学者。
你能帮忙吗?
谢谢,Leo
该代码是为 Python 2.7 开发的。我将在未来更新它以适应 Python 3。
也许可以先从 Weka 开始,它不需要编程。
https://machinelearning.org.cn/start-here/#weka
你好,我是一个初学者,也有同样的问题。为什么 Python 2 和 3 的代码不同?如果我使用您的代码,应该将文件保存为文本还是 csv?我现在应该怎么做?谢谢。
Python 2 和 3 是不同的编程语言。此示例是为 Python2 设计的,需要修改才能在 Python3 中运行。
我将在未来几个月内进行这些更改。
我的数据集在两个轴上都有标题(稍后将发布示例),它们有 1 和 0,表示该特征是否存在。您建议我从修改您的代码开始以适应此数据集吗?我现在收到一个关于将字符串转换为浮点数的错误。
white blue tall
ch1 0 1 1
ch2 1 0 0
ch3 1 0 1
我不确定我是否理解您的问题,抱歉。
也许这个过程可以帮助您端到端地定义和解决您的问题。
https://machinelearning.org.cn/start-here/#process
这太棒了!
请问您计划引入 CART 的成本复杂度剪枝吗?
非常感谢!
目前还没有。也许您可以发布一些链接?
先生您好,我尝试在我的数据上使用您的代码,但是遇到了一个问题,错误信息是 ValueError: invalid literal for float(): 1;0.766126609;45;2;0.802982129;9120;13;0;6;0;2 。我该如何修复这个问题?
你好先生,
感谢您的教程。它非常清晰简洁。但是,您如何最好地建议修改它以适应以下数据集
my_data=[[‘slashdot’,’USA’,’yes’,18,’None’], [‘google’,’France’,’yes’,23,’Premium’], [‘digg’,’USA’,’yes’,24,’Basic’], [‘kiwitobes’,’France’,’yes’,23,’Basic’], [‘google’,’UK’,’no’,21,’Premium’], [‘(direct)’,’New Zealand’,’no’,12,’None’], [‘(direct)’,’UK’,’no’,21,’Basic’], [‘google’,’USA’,’no’,24,’Premium’], [‘slashdot’,’France’,’yes’,19,’None’], [‘digg’,’USA’,’no’,18,’None’], [‘google’,’UK’,’no’,18,’None’], [‘kiwitobes’,’UK’,’no’,19,’None’], [‘digg’,’New Zealand’,’yes’,12,’Basic’], [‘slashdot’,’UK’,’no’,21,’None’], [‘google’,’UK’,’yes’,18,’Basic’], [‘kiwitobes’,’France’,’yes’,19,’Basic’]
本教程比较高级。
也许您更适合从 Weka 开始。
https://machinelearning.org.cn/start-here/#weka
或者 Python 中的 scikit-learn 库。
https://machinelearning.org.cn/start-here/#python
Jason,
非常感谢您的代码。我能够为我的应用程序进行改编,但您能否建议如何在 build tree 代码中替换为绘制树图?
谢谢
约翰
抱歉 John,我没有绘制树的代码。
嗨,Jason,
非常感谢您的教程。它对我的理解决策树非常有帮助。我有一个需要澄清的问题。在‘def split (node, max_depth, min_size, depth)’方法中,我看到您递归地拆分左节点,直到达到最大深度或最小尺寸条件。当您执行拆分时,您会增加当前深度 1,但当您移动到下一个 if 语句来处理第一个右子节点/分区时,没有函数可以重置深度。
这是因为在递归函数中,您为每次迭代保存新的深度值吗?意味着每次递归都保存了唯一的深度值?
深度是在递归的每一行中传递的。
另外,build tree的返回值是如何读取的?
即
in
tree = build_tree(dataset, 10, 1)
print tree
输出
{‘index’: 0, ‘right’: {‘index’: 0, ‘right’: {‘index’: 0, ‘right’: 1, ‘value’: 7.497545867, ‘left’: 1}, ‘value’: 7.497545867, ‘left’: {‘index’: 0, ‘right’: 1, ‘value’: 7.444542326, ‘left’: 1}}, ‘value’: 6.642287351, ‘left’: {‘index’: 0, ‘right’: {‘index’: 0, ‘right’: 0, ‘value’: 2.771244718, ‘left’: 0}, ‘value’: 2.771244718, ‘left’: 0}}
每个节点都有指向左节点和右节点的引用。
嗨,
我有一个包含数值和类别值的混合数据集,所以我修改了load_csv和main中的一些代码来将类别值转换为数值。
#load_csv
def load_csv(filename)
#file = open(filename, “r”)
headers = [“location”,”w”,”final_margin”,”shot_number”,”period”,”game_clock”,”shot_clock”,”dribbles”,”touch_time”,
“shot_dist”,”pts_type”,”close_def_dist”,”target”]
df = pd.read_csv(filename, header=None, names=headers, na_values=”?”)
cleanup_nums = {“location”: {“H”: 1, “A”: 0},
“w”: {“W”: 1, “L”: 0},
“target”: {“made”: 1, “missed”: 0}}
df.replace(cleanup_nums, inplace=True)
df.head()
obj_df=list(df.values.flatten())
return obj_df
#main
# Test CART on Basketball dataset
seed(1)
# 加载并准备数据
filename=’data/basketball.train.csv’
dataset = load_csv(filename)
i=0
new_list=[]
while i<len(dataset)
new_list.append(dataset[i:i+13])
i+=13
n_folds = 5
max_depth = 5
min_size = 10
scores = evaluate_algorithm(new_list, decision_tree, n_folds, max_depth, min_size)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
程序仍然可以处理您的数据集,但当我尝试在自己的数据集上运行时,程序在gini_index方法中的listcomp行 p = [row[-1] for row in group].count(class_val) / size 处冻结。
您有什么办法能打破这个无限循环吗?
谢谢
也许先尝试用sklearn让它工作,并更好地理解你的数据。
https://machinelearning.org.cn/start-here/#python
谢谢,很有帮助!
不客气。
我不明白row [-1] for row in group这一部分。请解释一下这里发生了什么?
您可以在这篇文章中了解更多关于Python数组索引的知识。
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
谢谢 <3
不客气。
非常有帮助,非常感谢!
谢谢,听到这个我很高兴。
易于理解,无需任何背景知识。优秀的文章
谢谢,
很棒的教程,你能帮我用熵作为分裂标准,而不是基尼指数吗?有什么例子吗?我试过了,但没有成功。
抱歉,我没有例子。
你好 Nandit,
我尝试了 Jason 的算法以及熵作为成本函数。也许能帮到你。
@Kevin Sequeira
嗨,凯文,
我尝试使用熵-信息增益标准在 Jason 的算法中,但它对我不起作用。请问您能提供一个实现示例吗?
你好先生,
可以可视化上面的树吗?可以使用Graphviz实现吗?你能否提供一个可视化这个决策树的示例?
当然可以。抱歉,我没有例子。
也许你可以使用内置可视化功能的第三方CART库,例如R或Weka。
你好。看看这个
https://github.com/Aarhi/MLAlgorithms/blob/main/DecisionTreeImplementationVisualization.py
我从头开始实现了决策树并使用决策树对其进行了可视化。
做得好,谢谢分享!
你好 –
我注意到
to_terminal基本上就是零规则算法。这仅仅是巧合(也就是说,对于小数据集,这似乎是最好的做法)?还是有一个更深层的想法,即当你将树剪枝到任何最小数据大小时,你可能想对剩余的子集应用其他预测算法(有点像使用决策树来预过滤其他方法的输入)?(如果只是巧合,那我承认我可能过度拟合了……🙂)
谢谢。
只是巧合,你注意到了,很棒!
我正在尝试分类iris.csv数据集,您建议如何修改代码以加载属性和非数字类别?
将数据加载为混合numpy数组,然后通过标签编码将字符串转换为整数。
我的博客上有很多例子。
我加载数据集时遇到了问题,出现了以下错误:“iterator应该返回字符串,而不是字节(您是否以文本模式打开文件?”
您能否确认您使用的是Python 2.7?
在“纸币数据集”的副标题下有一个错别字…
{The dataset contains 1,372 with 5 numeric variables.} 应该改为
{The dataset contains 1,372 rows with 5 numeric variables.}
谢谢,已修正。
outcomes = [row[-1] for row in group]
这段代码有什么作用?
对于回归树,to_terminal(group)函数应该返回目标属性值的平均值,但我得到的group变量包含所有NaN值。
请提供建议。
收集所有输出值。
也许这篇文章能帮助你理解Python中的列表和数组索引。
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
该示例是为Python 2.7编写的,请确认您使用的是此版本。
谢谢,这非常有帮助。
我们正试图根据Web页面上的WebElement中的属性来做决策,以生成动态测试用例。
例如,我们想输入一些属性,如 type = “text” 和 name =”email” 等,然后做出它是文本字段的决策,并生成适用于文本字段的测试用例。一个读取属性的例子
有什么指针,如何开始?任何帮助都将不胜感激。基本上如何开始准备链接、图像和其他元素类型的训练数据集?
也许这篇文章有助于定义模型的输入和输出。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
嗨,Jason,
我一定是瞎了。一旦一个属性在分裂中使用,我就看不见你在下次递归分裂/分支中移除它了。
谢谢!
如果它能增加价值,就可以重用它,但请注意,下一层的数据子集将是不同的——例如,已经被分裂了。
你好 Jason,
感谢这篇很棒的教程。
我对基尼指数的定义有点困惑。
gini_index = sum(proportion * (1.0 – proportion)) 只是 2*p*q,其中 p 是群组中一个类的比例,q 是另一个类的比例,即
gini_index = sum(proportion * (1.0 – proportion)) == 2p*(1-p)
对吗?
你为什么这么说?
不错的教程,先生。我真的很享受您的作品,先生。它帮助我更好地理解了幕后发生的事情。如何有人可以为本教程绘制logloss图?
谢谢。
对于决策树,logloss图是如何工作的呢?在它构建过程中?它可能不合适。
嗨,Jason,
谢谢你的教程,我想把你的文章翻译成中文,不是为了商业目的,只是为了分享。
可以吗?
如果可以,有什么需要注意的吗?
请不要翻译和重新发布我的内容。
好的,谢谢您的回复。
我建议在递归分裂的解释中,可以加上关于Python在每次递归调用时创建“node”字典副本的说明。对于没有丰富编程经验的人来说,这并不容易知道,如果他们尝试手动评估小“dataset”的表达式,可能会使他们感到困惑。除此之外,感谢您写了这么好的文章。
感谢您的建议。
不客气。我亲自过了一遍小数据集的整个递归代码,以便掌握流程。为每个深度级别使用了不同的变量名来表示“node”。如果对任何人有帮助,这里是代码。
root = get_split(dataset)
max_depth = 3
min_size = 1
depth = 1
node = root.copy()
left, right = node[‘groups’]
del(node[‘groups’])
node[‘left’] = l1 = get_split(left)
depth = depth + 1
l1left, l1right = l1[‘groups’]
del(l1[‘groups’])
len(l1left) <= min_size
l1['left'] = to_terminal(l1left)
l1['right'] = l1r2 = get_split(l1right)
depth = depth + 1
l1r2left, l1r2right = l1r2['groups']
del(l1r2['groups'])
not l1r2left or not l1r2right
l1r2['left'] = l1r2['right'] = to_terminal(l1r2left + l1r2right)
depth = depth – 1
node['right'] = r1 = get_split(right)
r1left, r1right = r1['groups']
del(r1['groups'])
r1['left'] = r1l2 = get_split(r1left)
depth = depth + 1
r1l2left, r1l2right = r1l2['groups']
del(r1l2['groups'])
r1l2['left'], r1l2['right'] = to_terminal(r1l2left), to_terminal(r1l2right)
depth = depth – 1
r1['right'] = r1r2 = get_split(r1right)
depth = depth + 1
r1r2left, r1r2right = r1r2['groups']
del(r1r2['groups'])
not r1r2left or not r1r2right
r1r2['left'] = r1r2['right'] = to_terminal(r1r2left + r1r2right)
干得好!
X后面的数字是什么意思?(X1, X2, 等)在print_tree函数中,它代表node[‘index’]。这是基尼指数吗?
为什么在你的示例数据周围只有两个索引?
我尝试了其他一些数据集,结果如下:
[X4 < 23.570]
[X1 < 1143.631]
[X1 < 1096.228]
[X1 < 905.490]
[X1 < 714.853]
[X1 < 524.248]
[0]
[0]
[0]
[0]
[0]
[X1 < 1143.631]
[0]
[0]
[X1 < 1373.940]
[X1 < 1292.075]
[X1 < 1276.251]
[X1 < 1141.360]
[X1 < 912.083]
[1]
[1]
[1]
[1]
[1]
[X1 < 1373.940]
[1]
[1]
Xn是变量编号,后面的浮点数值是该变量选择的分割点。
另一个问题
如何修改您的python代码来解决n维问题与决策树?
这是否会是对本页的一个很好的更新?🙂
我将非常乐意并感激。
无论如何,非常感谢您的工作。
这段代码是为了教你算法是如何工作的。
要解决实际问题,我建议使用sklearn库。我有很多示例,请搜索博客。
写得真好!我能知道这些“groups”具体是什么吗?我知道它们是包含2组数据的3d数组,但它们包含什么?谢谢!
谢谢。哪些groups?
我指的是“groups”数据,但在阅读了代码后,我明白了它们是什么。感谢您的时间!
不客气。
你好,
我正在研究决策树分类器。你能分享一下SLIQ – 决策树分类器在python语言中的代码吗?
什么是SLIQ?
你好,
SLIQ是数据挖掘中的一个决策树分类器。我把SLIQ的文件发给你。请检查一下,如果可能的话,请分享一下它的Python代码。
http://sci2s.ugr.es/keel/pdf/algorithm/congreso/SLIQ.pdf
谢谢,先生。
谢谢。抱歉,我对此一无所知。
我强烈建议将此代码发布到github上,因为这使得贡献非常容易。然后我建议一个简单的修剪函数。您在文本中已经建议了其他改进/功能。此外:您作为所有者可以更深入地了解克隆/使用情况等。您怎么看?
谢谢您的建议,但我更愿意不将我的代码放在github上。
为什么?
因为我控制着这个博客和所有的体验,所以我对github没有任何控制权,那是别人的平台。
我写代码教程,我不是简单地把源代码在线上倾倒。上下文是至关重要的。
我也卖书,这让我能够继续写更多的教程。
非常感谢!!
它真的很有帮助!!!
您的书和您的网站内容也很棒
我是ML的初学者,我在阅读这些资料时遇到了一些语言上的问题,但不是太难。
Q1:我想知道如何正确地结合使用您的书和您的网站教程?
Q2:您的教程有63页,它们是按随机顺序排序的吗?还是您的博客是按顺序排列的,例如,这篇博文之后紧跟着的文章是关于决策树的,那么下一篇就会更高级?最后,我想问的是,如果我想系统地学习ML,我应该逐一阅读这些资料,还是应该先读您的书,读完后再回头看这个网站?
博客的组织性不是很强。您可以使用搜索功能。
对于特定主题的更多帮助,我建议您购买一本书或使用这里的指南。
https://machinelearning.org.cn/start-here/
Hi, train_set.remove(fold) 这行会引发一个错误。
ValueError:包含多个元素的数组的真值不明确。请使用 a.any() 或 a.all()
我通过参考这个笔记解决了这个问题。
https://stackoverflow.com/questions/3157374/how-do-you-remove-a-numpy-array-from-a-list-of-numpy-arrays
removearray(train_set,fold)
希望这能帮助到其他人。
代码是为 Python 2.7 编写的。您使用的是这个版本的 Python 吗?
嗨,Jason!
首先,这是一篇很棒的文章,非常感谢您写了它。我想问您关于训练感知器决策树的问题,如您所知,每个节点都是一个感知器。要构建这样的树,理想情况下我应该单独训练每个节点,并根据输出(例如,如果是一个二分类问题,y = 0 或 1),我会将数据集分成两个子节点,前提是纯度大于阈值。
由于每个节点的拆分取决于用于感知器的权重,因此整个树的结构也取决于权重。因此,在训练期间,我将不断改变树的结构(这可能在计算上非常密集)。或者我应该从根节点开始单独训练每个感知器,然后对后续节点执行相同的操作?
谢谢!
抱歉,我没有这方面的示例算法。
先生,我必须从头开始实现决策树和线性svc,针对从 Twitter 获取的评论(字符串)数据集,csd 将包含在标签 #student #refugee 和 #trip 下的评论……。
也许可以使用 scikit-learn 这样的库,会容易得多!
先生,我实现了这个决策树,但是我想可视化这棵树,该怎么做?
使用 sklearn 我可以使用 pydotplus.graph_from_dot_data,但我不知道如何通过这个教程来做。
抱歉,我没有可视化决策树的示例。
我如何连接 mysql 数据库来获取数据集?
我看不出为什么不。
你得到代码了吗?
先生,
我正在做一个项目,它将图像作为数据并进行处理,以便做出“是”或“否”的决定……。假设我给的数据是蓝天图像……它只能在是蓝天时打印是,否则打印否……这需要通过机器学习来完成……您能告诉我代码,或任何来源……请帮帮我。
听起来是个大项目。
可以考虑使用 CNN 模型,并可能利用预训练模型。也可以试试这个教程。
https://machinelearning.org.cn/develop-a-deep-learning-caption-generation-model-in-python/
嗨 Jason,您发布的这篇文章非常棒。对我帮助很大。
您是否有关于此教程扩展的链接——交叉熵和树剪枝?
非常感谢!
抱歉,我没有。
感谢您的文章。这对我的作业非常有帮助。在您的案例中,“类”已经被生成;要么是 0,要么是 1。如果您还没有生成类,您会如何生成类?是否有关于生成“类”的参考资料?感谢您的详细解释。
这是我们的目标。用我们有类的模型来训练模型,然后使用训练好的模型对我们没有类的模型进行预测。
我建议从这里开始
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
我正处于一个需要自定义拆分函数的情况下,该函数根据不同人口统计组的流失率差异来拆分数据,分为两个节点,一个差异较低,另一个差异较高。
我设计了那个函数,但现在的问题在于拆分。如果我有 300 万行数据,那么我将不得不计算我的度量 300 万减 1 次:针对每一行组合。是否有更有效的方法来选择要评估的拆分?
任何想法都将不胜感激。谢谢,
这个问题听起来很具体,取决于你的数据集,我不太确定我能否明智地回答,抱歉。
在 n x m 数据集中:get_split(dataset) 函数在选择最佳拆分之前,会为该列的 n-1 种可能的行值组合计算基尼指数。这意味着要评估 m x (n-1) 次 gini_index()。
我曾设法将这些基尼指数评估减少到该列的唯一行值数量,但仍然非常低。有没有更有效的方法?我不知道 sklearn 或 rpart 是如何做到这么快的。
我猜是的,我建议使用像 sklearn 这样的健壮库中的实现。这段代码是为了学习算法的工作原理,而不是用于实际操作。
嗨 Jason,很棒的教程!我在小型数据集上运行了您的代码,然后在 Excel 中手动复制了这个过程,以获得更深入的理解。最后,我尝试在 sklearn 中使用相同的数据,但未能获得相同的结果。您的代码与 sklearn 中的 DecisionTreeClassifier 有何不同/额外之处?谢谢!!!
sklearn 库将做很多事情,以确保结果是稳健的,并且实现使用了最佳实践。这些差异加起来会给出稍微不同的结果树。
嗨。有人能告诉我“predicted = algorithm(train_set, test_set, *args)”这一行中的“algorithm”是什么吗?非常感谢。
它正在执行作为参数传递的算法函数名。
如果这对您来说有挑战,也许可以从 sklearn 开始。
https://machinelearning.org.cn/start-here/#python
嗨,Jason,
我根据类似的代码为我的项目案例研究构建了一个 CART 模型。但是当我运行时,它会抛出错误 p=[row[-1] for row in group].count(class_val)/size ;invalid index to scalar variable(标量变量的无效索引)。
由于在整个代码中数据集进行了多次相互转换,group 最终变成了一个列表而不是 ndarray,所以 group 中的 row 变成了一个标量变量,我们正在尝试访问它的 [-1] 索引,从而导致该错误。但我无法找出如何修复它。你能帮我吗?
确保您的数据已按预期加载。
嗨,Jason,
我正在根据您的代码构建一棵树,但当我尝试可视化树时,我被卡住了。你能告诉我怎么做吗??谢谢
我展示了如何用简单的 ASCII 输出进行可视化。
嗨 Jason!感谢您提供的精彩教程。
我有一个关于决策树的问题。我可以使用标签编码器来处理名义上的分类变量吗?我在网上找到了关于此问题的各种答案,但没有明确的答案。
你可以,但决策树不需要。
我也推荐使用 sklearn 的实现。
精彩的解释!非常有帮助
非常感谢您 🙂
很高兴它有帮助。
你好,
非常感谢您提供的精彩解释。
我想知道是否可以在代码中某处添加一个关于测试数据的整体约束。
例如,根据一个实例被分配到哪个组,它有一个特定参数值。对于所有测试数据,这些参数的总和必须等于某个值。
这是否可能?
抱歉,我不太明白,您能否详细说明一下您的意思?
嘿 Dr. Brownlee,
感谢您的教程!
一些评论:我需要将 rb 改为 rt,并且我删除了浮点数转换函数,因为我的数据集有超过 400,000 个观测值(它们已经是浮点数)。我知道您不是为这么大的数据集设计的,但目前这只是为了好玩!如果我的计算是正确的,这将在我的机器上花费大约 200 分钟。
仅供参考,它仍然可以与 Python 3.7 一起工作 :)
祝好,
谢谢。
你好,有没有办法修改这个以适应大型数据集?我不想等这么久。
谢谢你
是的,我建议您使用 sklearn 中更快的实现,这篇帖子只是为了学习算法。
嗨 Jason,感谢您的资料。在决策树中,每次拆分后都应该删除拆分器列,但您的代码没有这样做,您能否提供一些示例代码?
不,我们在这个算法中不删除用于拆分的列。
谢谢。这对于理解算法非常有帮助。
谢谢,很高兴对您有帮助。
太棒了 Jason!非常清晰的解释和编写良好的代码。我非常感谢您免费提供这些内容!
谢谢。希望它有所帮助。
嗨,Jason,
首先,我必须说这个网站在没有经验的情况下学习 ML 方面真是救命稻草——您创建和维护这些文章做得太棒了!
我是一名三年级学生,我的毕业设计项目是把 ML 应用到一个负担得起的嵌入式系统中来识别人类活动——对我来说,首先是步行和跑步——这个项目主要是概念验证。直到我发现这篇文章,我一直非常卡住,但当我运行时,我在我收集的数据(来自板载加速度计)上进行了标记,并在我的 PC 上获得了惊人的 93-96% 的准确率。
我使用的微控制器运行 MicroPython——如果您有兴趣,我使用的是 Pycom 的 LoPy,因此将其改编到它上面运行一个非常小且修改过的数据集相当直接。但是,我对 ML 还是新手,还在学习 Python,我想知道根据上面的例子,您建议我尝试什么来获得用于训练的标记数据集和用于测试的未标记数据集,这是否可以轻松完成?
我尝试研究了您的交叉验证函数,它似乎需要标签才能正常工作(我查看了您关于它的帖子——https://machinelearning.org.cn/implement-resampling-methods-scratch-python/)。当然,如果您错了请纠正我。您有什么建议吗?再次感谢您所做的一切!
谢谢。
干得好!
未标记的数据集意味着您没有在测试,而是意味着您正在对新数据进行预测。无法进行重采样。
谁有 CART 算法的分步描述???请帮帮我……。
试试这个
https://machinelearning.org.cn/classification-and-regression-trees-for-machine-learning/
伙计,我只能说你真是太棒了。你真的“帮助像你一样的开发者取得成果”。
很棒的教程,与其他许多教程不同,它是实际可用且开箱即用的。
我最诚挚的感谢。
谢谢,很高兴它有帮助!
嘿 Jason,我知道 C++ 中的 ML 不是您教授的内容,但我想在 C++ 中实现决策树,您能提供一些 C++ 代码吗?
抱歉,我没有能力为您编写 cpp 代码。
非常感谢!我对算法是新手。您的博客帮助我很多,让我理解并更重要的是在实现方面。再次感谢 :)
很高兴听到这个!
谢谢,伙计。这给了我实现 c45 算法的启示。
我很高兴它能帮到你。
有一件事我觉得有点奇怪
在“gini_index”中,您有
p=[row[-1] for row in groups].count(label)
这只是计算标签作为特征向量的最后一个值出现了多少次(我假设 group 中的每一行都是一个特征向量——如果我错了请纠正我)——我不知道那有什么用?
组根据每个类的比例进行评分。纯度越高(混合越少)越好。
是的,我发现了一样的事情。例如,如果您将以下内容传递给 gini 函数,您将得到相同的结果
gini_index([[[10, 1], [‘c’,’b’, 0]], [[‘e’, 1], [1, 0]]], [0, 1]))
您得到相同的结果。换句话说,列表中的第一个元素不重要。那么这个数据到底代表什么呢?
确实如此。这里有同样的疑问。
gini_index函数似乎接受多维数据,但计算仅基于数据的最后一个维度进行,有点令人费解……我一直在考虑改进实现以避免不必要的拆分,正如文章中所建议的那样。
看起来 get_split 函数正在测试列中的每一个值。在所有标签都相同但预测变量不同的情况下,如果它只测试唯一(排序后)的值,那么该列中的最小值将被测试并设置为最佳 gini 分数,并且由于 test_split 检查 < ,所有行将被分配到右侧,而 split 函数中的“if not left or not right:”检查将由于左侧为空而终止。
假设我没有在检查拆分点之前进行唯一值+排序,我的另一个想法是也将最佳 gini 分数添加到节点字典中,并添加另一个终止条件“if node['gini'] == 0: node['left'], node['right'] = to_terminal(left), to_terminal(right)”。
比较上述两种策略,基尼检查(第二种)策略将允许树比“空左侧”检查早一个级别终止。然而,如果数据集的列中有很多重复值,例如来自分类数据的标签编码值(通常会重复),那么进行唯一值+排序将大大减少计算量。
还有其他方法可以缩短它/减少计算吗?
我也一直在考虑剪枝。我需要编辑哪些考虑因素/函数?需要跟踪哪些变量?
是的,我鼓励您查看sklearn中的实现,它在设计上要快得多。
感谢您的帖子、代码和所有后续更新!我也想知道如何避免树底部的某些不必要的分裂。万一其他人好奇,可以在代码中添加一个简短的附加项:
if len(class_values) == 1: return to_terminal(dataset)
作为get_split的第二行,然后
if not isinstance(node, dict): return
在split的开头。
这似乎可以避免在给定的示例和其他一些数据集中进行不必要的分裂。
再次感谢!
做得好!
我想用python从头开始实现c4.5。有链接吗?
抱歉,我没有。
我对处理分类变量进行了一些修改,
我在另一个数据集(贷款预测)上运行了该程序,它运行良好,准确率约为79%。
干得好!
嗨,Jason,
感谢您提供如此出色的资源!
在评估所有可能的分割时,如果纯度度量返回多个局部最小值(假设这可能发生?),您应该如何进行?例如,如果多个特征的基尼指数为零,或者一个特征在不同的分割点处具有等效的最小基尼指数?
您应该测试所有可能的分割组合吗?
另外,就像示例一样,不应用终止节点的条件(如果纯净)的原因是什么?
它应该(也可能,我不记得了)。很棒的评论!
如果所有分割都相同(得分相同),则可以选择随机分割。
是的,我们作为算法的一部分来测试所有分割。
你好,我可以在个人项目中使用你的一些代码吗?我正在尝试实现一个略有不同的决策树。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-i-use-your-code-in-my-own-project
嗨,Jason,
我发现这个例子非常有帮助。而且,在我们想要构建决策树的大多数情况下,我们需要定义自己的问题,并使用这些问题来创建和构建决策树。现在,您已经创建了自己的函数来完成这项工作。
根据您的经验,您是否发现您最常需要从头开始构建自己的决策树,而不是使用XGBoost、Sklearn等模型来完成底层工作?我想我也在问,您是否可以使用XGBoost或Sklearn或其他增强的开源工具等开源库来完成您所做的事情?科学家能否使用开源工具提出自己的问题并提供自己的分割值,还是您需要构建自己的决策树、预测机制和准确性计算函数,或者这些都可以使用开源工具创建?希望你能理解我的意思。
顺便说一句 - 如果您之前回答过这个问题,请原谅我。
我读过您的许多帖子,例如https://machinelearning.org.cn/visualize-gradient-boosting-decision-trees-xgboost-python/
并且认为这最有趣,因为您是从头开始构建的。
谢谢,很高兴听到这个。
不,我很少从头开始编写代码——很容易引入错误和编写慢代码。我使用库是因为它们经过测试并且速度很快。
是的,我几乎在所有情况下都推荐使用开源库。
“完美分离的基尼得分为0,而导致每组50/50类别的最差分割得分为0.5(对于2类问题)。”等等,你不觉得这是错的吗?0.5表示完美分离。
不,在这种情况下,它表示最坏情况,即类别在每组中混合。
代码行
file = open(filename, “rb”)
与数据文件不兼容,应改为
file = open(filename, “rt”)
谢谢,已修正。
你好 Jason,我对基尼指数不太熟悉,所以如果我说错了请忽略我。但是根据《统计学习要素》这本书,基尼指数的定义是
gini = 1-sum(p_k * (1-p_k))
我觉得这个也更容易理解。
但是,您的实现使用了
gini = (1-sum(p_k **2)) * sum(p_k **2)
我明白损失函数可以有多种形式,只要它们具有相同的极值点。我可以看到它们实际上在 k = 2 时产生了相同的结果,我无法在数学上证明它们始终等效。请问这只是使用基尼指数的另一种方法吗?非常感谢。
这个可能会有帮助
https://en.wikipedia.org/wiki/Gini_coefficient
谢谢回复。但我认为您可能指的是“决策树学习”中的基尼不纯度https://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity?您提供的链接实际上是一个经济学术语。
是的,抱歉,搜索-复制-粘贴太快了。
谢谢 Jason,我也意识到我太笨了,因为展开公式和重新排列后它们是完全等价的……谢谢您的帖子,这是我见过的最好的教程。
谢谢。
我很高兴它能帮助您完成项目!
这是一个很棒的教程。谢谢写这个。看到从头开始的实现对于理解涉及的所有问题非常有用。
谢谢,我很高兴它有用!
嗨,Jason,
感谢精彩的教程。
我有一个具有挑战性的问题
我需要实现一个“交互式决策树”,其中用户决定在哪个特征上进行分割,而不是使用基尼指数。
例如,在 banknote_authentication 数据集中,我需要允许用户指定节点在树中的顺序,例如,偏度作为根节点,然后是峰度,然后是方差,然后是图像的熵。
如何修改代码以允许这样做?
非常感谢
听起来您需要构建一个界面。例如,工程,而不是机器学习。
TypeError: 'list' object cannot be interpreted as an integer
你好 Jason 谢谢你的代码,在我运行和学习代码的时候。
出现了这个错误,你能帮帮我吗?
很抱歉听到这个,请看这个
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好。
我分析了您的代码,我对交叉验证有一个疑问。
如果我有 k 折,我的代码产生 k 个不同的树是正常的吗?
如果我有一个训练集(可以分成 k 折),但有一个不同的测试集呢?预测阶段是在哪个树中进行的?非常感谢。
正确。
如果您想使用训练/测试集,您需要准备一个不同的测试框架来评估您的模型。
你好,谢谢这个教程。
我亲自实现了这个代码,使用了信息熵(这里解释信息熵:https://victorzhou.com/blog/information-gain/)而不是基尼得分。以下是我从上面的代码更改/添加的唯一函数,但它是一种粗略的实现,假设它是一个二维数据集(+类)。
感谢分享。
又是我,再次感谢您的教程。我有一个问题,就是指定一个过大的 max_depth 会导致代码崩溃。我导入了自己的数据集,当指定 max_depth 为 2、3、4 时,代码可以正常运行,但当指定 max_depth=5 时,我遇到了这个错误。
看起来“node[‘groups’]”是“None”,我弄不清楚哪里出了问题。也许应该有一个方法来捕获这个错误?我认为代码应该在此之前终止,但它没有生效。
我不确定,抱歉。也许可以试试调试器?
确实需要调试一下,但我已经解决了。我使用了额外的“if/else”语句来检查 NoneType。我还使用了“is None”而不是“if not”来检查 NoneType,因为不知何故“if not”不起作用。
干得好。
嗨 Jason,教程很棒!
我想知道是否有其他从头开始实现的分类树算法?
我搜索了很久,只找到了 CART 方法和随机森林方法。
还有其他的分类方法吗?
感谢您的分享!
谢谢!
是的,我有一些。也许可以从这里开始
https://machinelearning.org.cn/start-here/#code_algorithms
当所有行具有相同标签时,您是如何处理这种情况的?这里我们也应该停止分割。分割函数是通过检查:左侧为空或右侧为空来处理它吗?
当分割值是解释变量的最大值或最小值时,左侧或右侧会为空。这种情况什么时候发生?
是的。基尼指数将显示完美的分割。
嗨,我认为此代码在检测哪些索引的数据(如 x0,x1,x2)是重要的可选项时存在一个小问题。在默认情况下,它选择 x1,并且在 x0 是可选项时也不会改变。
谢谢
很抱歉听到您遇到了麻烦,也许这会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您的意思是我的代码有问题,还是您认为我可以在此案例中指出您网站代码的问题?
我不认为实现中有问题。
嗨 Jason!感谢您的精彩教程。
但我想知道您是否有关于基于此模型实现回归树的教程?另外,您有关于树剪枝的代码吗?
非常感谢!
嗨 Jason!感谢您的精彩教程。
但我想知道您是否有关于基于此模型实现回归树的教程?另外,您有关于树剪枝的代码吗?
非常感谢!
目前还没有。
嗨,Jason,
感谢您发布此模型。例如,除了分类之外,您建议如何使用此技术(回归)来根据类型和地块大小预测房价?
也许可以使用标准实现
https://scikit-learn.cn/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
感谢 Jason,我的兴趣在于拔掉 Gini 函数并插入一个不同的成本函数,除非我遗漏了什么,否则应该不会有任何影响。对于赛马数据,评估基于利润的分割,看看是否能比 Gini 提高模型,Gini 旨在提高准确性,这会很有趣。
听起来很棒!
此算法是否容易修改以预测概率?
它可以预测概率,但需要进行校准。
https://machinelearning.org.cn/calibrated-classification-model-in-scikit-learn/
我的意思是“从头开始”,而不是使用 sklearn 库。
是的,您可以对其进行改编,同样,您仍然需要校准预测的概率。
抱歉,我没有一个实际的例子,我建议您查阅关于该主题的优秀综述文章或教科书。
感谢您提供的精彩教程。是否存在基于您的树的 dict 结构计算特征重要性的扩展?
这将有助于您了解特征重要性
https://machinelearning.org.cn/calculate-feature-importance-with-python/
我也看过这篇文章,并使用了 sklearn 库。下一步是深入研究并扩展您的决策树分类器。
是的,扩展决策树实现是一个不错的下一步。抱歉,我没有能力指导您。
嗨,Jason
我认为,这不是基尼指数,而是基尼不纯度。基尼指数这个术语来自经济学。
谢谢。
你好,你是 Nirma 大学(Nirma Uni.)的吗?
不,我来自澳大利亚墨尔本。
非常棒的教程,感谢您创建 Machine Learning Mastery。
您能帮我理解一点吗?
“添加到现有节点的新节点称为子节点。一个节点可以有零个子节点(终端节点)、一个子节点(一侧直接进行预测)或两个子节点。”
我看不出如何可能只有一个子节点。如果没有要进行的分割,那么节点不应该就是终端节点吗?
我也为可能有相同问题但可能弄错了的人添加这个(请纠正我)。在这一部分
“然后将分数加到每个子节点在分割点上,以获得分割点的最终基尼分数,该分数可以与其他候选分割点进行比较。”
之所以这是一个简单的加法而不是加权加法,是因为不平衡类别的权重已经在基尼指数的计算中考虑过了。例如,Scikit-learn 计算基尼指数为 sum(p*(1-p)),然后稍后考虑权重。
谢谢。
好问题,是的,这听起来像一个终端节点。您可能需要将其设置为在分割的一侧进行“无预测”。
非常有用的信息性文章。我感谢作者提供了这样一篇有用的文章,特别是与基尼指数相关的文章。
谢谢!
嗨,Jason。
感谢您发表这篇文章!您能否告诉我如何或如何用您的代码来获取构建树的决策规则?我的意思是,我想明确地打印树的 IF-THEN 规则。
抱歉,我没有这方面的例子。
我比较了您的代码和 sklearn 的准确率结果,存在巨大差异。此代码给出 97% 的准确率,而 sklearn 返回 57% 的准确率。您能解释一下原因吗?
谢谢
也许是比较了不同的数据或同一数据的不同样本?
也许您的 sklearn 代码中存在错误或拼写错误?
也许您复制的代码有错误或拼写错误?
也许您需要调整 sklearn 的实现?
也许上面的实现已经进行了调整?
嗨,Jason,
对所有主题的解释都很好,而且很容易理解…
不客气。
嗨 Jason,您能解释一下这个部分吗
Gini(group_1) = 0.0 * 0.5
是的,我建议阅读有关“基尼指数”的部分。
嗨 Jason,抱歉,这两个部分。我有点困惑。我们只有两个组,难道不应该从每个组中找到两个基尼不纯度吗?但在这里我们计算了每个组的三个基尼不纯度,以及我们如何得到下面的数字。您能为我澄清一下吗?谢谢。
Gini(group_1) = 0.0 * 0.5
Gini(group_1) = 0.0
是的,我们正在通过计算进行计算——计算项。
我需要这个代码用 Java 语言,您能帮忙吗?
不行。
我需要开发一个基于方面的句子分析算法。但我不打算使用任何深度学习方法。如何定制一个标准的分类算法,使其可以用于 ABSA。
也许可以使用词袋模型表示,然后测试一套标准的机器学习算法。
size = float(len(group)) on [[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1]
给出的是组的每一侧的数量,而不是基尼指数所需的数量。
我错过了什么?
您好,非常感谢您写了这么棒的文章。
我认为您的 print_tree 函数需要稍作修改,因为您在格式化打印 ([X%d < %.3f]) 中似乎只考虑了小于分割值的左子节点,这就是为什么在运行您提到的示例代码后,我们会得到以下结果:
[X1 < 6.642]
[X1 < 2.771]
[0]
[0]
[X1 7.498] for class [1] not “<"
def print_tree(node, depth=0)
if isinstance(node, dict)
print('%s[X%d < %.3f]' % ((depth*' ', (node['index']+1), node['value'])))
print_tree(node['left'], depth+1)
print_tree(node['right'], depth+1)
你说得对。正如引述的,“虽然不像真正的决策树图那样引人注目,但它能让人了解树的结构和整个过程中做出的决策。”该函数只是为了说明。
你能帮我解释一下第 5 步,“当我们返回到构建的树的根节点时”是如何工作的吗?我看不出代码中的后退到根节点是如何工作的。谢谢
不,那段代码并没有回到根节点。这句话的意思是,从根节点到叶节点,我们始终定义左节点和右节点。如果检查为真,则为左,如果为假,则为右,反之亦然。你不能做的是,有时检查为真则向左,有时则向右。
你好 Adrian,感谢你的回复。我尝试复现了你的代码,还有另一个问题。
以下字典是通过 split 函数的第一次递归生成的。
‘index’: 0, ‘value’: 6.642287351, ‘groups’: ([[2.771244718, 1.784783929, 0], [1.728571309, 1.169761413, 0], [3.678319846, 2.81281357, 0], [3.961043357, 2.61995032, 0], [2.999208922, 2.209014212, 0]], [[7.497545867, 3.162953546, 1], [9.00220326, 3.339047188, 1], [7.444542326, 0.476683375, 1], [10.12493903, 3.234550982, 1], [6.642287351, 3.319983761, 1]])
我认为在此步骤之后,所有节点都是纯的(左组全部为 0 标签,右组全部为 1 标签)。您能否告诉我为什么在第一步之后继续拆分树?
如果尚未达到所需的树深度,则应继续拆分。
你好 Jason,这是我的用于回归的损失函数和 to_Terminal。但是当我用它们来预测波士顿的房价时,效果不太好。你能帮帮我吗?
我认为你的第二个“for row in group”是错误的。
我该如何纠正?
“temp = avg-x”这一行在循环中反复覆盖“temp”而没有使用它。这是你想要做的吗?
谢谢,是我的错。损失应该在循环中。
清晰易懂。
感谢您的这篇文章。
对于扩展*(在扩展 3 的末尾)
要求:- 如果满足以下条件,则停止进一步分割节点:
1)。当前深度 min_size
2)。组是纯的(每个组只有一个唯一的类)。
# changing the split() function {refer ‘—>’ marker for new lines added}:-
def split(node, max_depth, min_size, depth)
left, right = node[‘groups’]
del(node[‘groups’])
# check for a no split
if not left or not right
node[‘left’] = node[‘right’] = to_terminal(left + right)
return
# check for max depth
if depth >= max_depth
node[‘left’], node[‘right’] = to_terminal(left), to_terminal(right)
return
# process left child
if len(left) if (len(set([row[-1] for row in left])) == 1)
—> node[‘left’] = to_terminal(left)
—> else
node[‘left’] = get_split(left)
split(node[‘left’], max_depth, min_size, depth+1)
# process right child
if len(right) if (len(set([row[-1] for row in right])) == 1)
—> node[‘right’] = to_terminal(right)
—> else
node[‘right’] = get_split(right)
split(node[‘right’], max_depth, min_size, depth+1)
你好,首先,这是一篇非常棒的文章。我也想从头开始实现决策树。我需要一个详细的来源,但不是像这个来源那样现成的实现。我可以在哪里找到关于决策树的详细来源?到目前为止,我看了深度学习的书(例如 Goodfellow 的书),但它们没有深入到实现细节。
你好 Onat…以下是一个很好的起点
https://www.hackerearth.com/practice/machine-learning/machine-learning-algorithms/ml-decision-tree/tutorial/
一如既往,Jason,当你寻找复杂主题的 Python 实现时,你的网站总会出现。在阅读了代码并更深入地理解了这个实现之后,它也引发了更多问题。
如何在训练数据集中选择和评估分割点 = 这一部分很有意义,因为它会提供统计反馈来评估,然后提供一个数据分割建议,同时训练模型?
如何从多个分割点递归构建决策树。 = 这一部分不太清楚,在你其他的帖子中 - https://machinelearning.org.cn/use-classification-machine-learning-algorithms-weka/ - 你明确地展示了一个决策树。对于这篇决策树的帖子,我不太明白它是如何构建树的。在你《统计机器学习方法》一书的第 10 页(这本书太棒了)中,你简要提到了决策树,但你在书中提到了 9 次“决策”,而这篇帖子提供了更多细节,所以我认为应该问一下。
如何将 CART 算法应用于现实世界的分类预测建模问题。 = 大部分内容都很有意义,我需要多加练习,但你为我节省了大量时间。当我接近完成时,我想购买相关的机器学习书籍,你的哪本书与决策科学或决策树最相关? https://machinelearning.org.cn/products/
不错的网站和示例!
一个令我疑惑的问题:难道不应该是
def to_terminal_(group):
outcomes = [row[-1] for row in group]
return max(outcomes, key=outcomes.count)
而不是
def to_terminal_(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
我本以为将 `set(outcomes)` 用作 `max` 的第一个参数而不是 `outcome` 会导致结果出错。我说得对吗,还是我遗漏了什么?
你好,首先非常感谢您的解释!
虽然我理解了决策树,但我不知道
如何实际实现它们。这是我找到的最好的解释
🙂
我有一个关于树是如何构建的问题。
虽然我理解了 split 函数,但我不知道它返回什么,
或者它如何改变根节点?
谁能解释一下?:)
你好 Myrthe…以下资源应该能提供一些清晰度
https://www.analyticsvidhya.com/blog/2020/06/4-ways-split-decision-tree/#:~:text=Steps%20to%20split%20a%20decision%20tree%20using%20Information%20Gain%3A,entropy%20or%20highest%20information%20gain
嗨 Jason
“groups”的含义是什么?您如何将输入特征属性与这种“groups”的概念联系起来?这令人困惑。请帮忙!
你好 Tarun…以下资源可能符合你的兴趣
https://scikit-learn.cn/stable/modules/tree.html