逻辑回归是用于二分类问题的首选线性分类算法。
它易于实现,易于理解,并且在各种问题上都能获得出色的结果,即使该方法对数据的期望被违反。
在本教程中,您将学习如何使用 Python 从零开始实现随机梯度下降的逻辑回归。
完成本教程后,您将了解:
- 如何使用逻辑回归模型进行预测。
- 如何使用随机梯度下降估计系数。
- 如何将逻辑回归应用于实际预测问题。
通过我的新书《从零开始的机器学习算法》启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2017 年 1 月:更改了 `cross_validation_split()` 中 `fold_size` 的计算,使其始终为整数。修复了 Python 3 的问题。
- **2018 年 3 月更新**:添加了下载数据集的备用链接,因为原始链接似乎已被删除。
- 2018 年 8 月更新:测试并更新以与 Python 3.6 配合使用。

如何使用 Python 从零开始实现随机梯度下降的逻辑回归
图片来自Ian Sane,保留部分权利。
描述
本节将简要介绍逻辑回归技术、随机梯度下降以及我们将在本教程中使用的 Pima 印第安人糖尿病数据集。
逻辑回归
逻辑回归以该方法核心使用的函数(逻辑函数)命名。
逻辑回归使用一个方程作为表示,非常类似于线性回归。输入值 (X) 使用权重或系数值线性组合以预测输出值 (y)。
与线性回归的一个关键区别在于,建模的输出值是二元值(0 或 1),而不是数值。
|
1 |
yhat = e^(b0 + b1 * x1) / (1 + e^(b0 + b1 * x1)) |
这可以简化为
|
1 |
yhat = 1.0 / (1.0 + e^(-(b0 + b1 * x1))) |
其中 e 是自然对数的底(欧拉数),yhat 是预测输出,b0 是偏差或截距项,b1 是单个输入值 (x1) 的系数。
yhat 预测是一个介于 0 和 1 之间的实值,需要将其四舍五入为整数值并映射到预测的类别值。
输入数据中的每一列都有一个相关的 b 系数(一个常数实值),必须从训练数据中学习。您将存储在内存中或文件中的模型实际表示是方程中的系数(beta 值或 b)。
逻辑回归算法的系数必须从训练数据中估计。
随机梯度下降
梯度下降是通过沿着成本函数的梯度来最小化函数的过程。
这涉及知道成本的形式以及其导数,以便从给定点知道梯度并可以朝该方向移动,例如朝向最小值向下移动。
在机器学习中,我们可以使用一种技术,即随机梯度下降,它在每次迭代中评估和更新系数,以最小化模型在训练数据上的误差。
这种优化算法的工作方式是,每个训练实例都逐一展示给模型。模型对训练实例进行预测,计算误差,并更新模型以减少下一个预测的误差。
此过程可用于查找模型中导致模型在训练数据上误差最小的系数集。每次迭代,机器学习语言中的系数 (b) 都使用以下方程更新
|
1 |
b = b + learning_rate * (y - yhat) * yhat * (1 - yhat) * x |
其中 b 是正在优化的系数或权重,learning_rate 是您必须配置的学习率(例如 0.01),(y – yhat) 是归因于权重的模型在训练数据上的预测误差,yhat 是系数做出的预测,x 是输入值。
Pima 印第安人糖尿病数据集
Pima 印第安人数据集涉及根据基本医疗详细信息预测 Pima 印第安人五年内糖尿病的发作。
这是一个二分类问题,预测结果为 0(无糖尿病)或 1(有糖尿病)。
它包含 768 行和 9 列。文件中的所有值都是数值,特别是浮点值。以下是问题前几行的一个小样本。
|
1 2 3 4 5 6 |
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1 ... |
预测多数类(零规则算法),此问题的基准性能为 65.098% 的分类准确率。
下载数据集并将其保存到当前工作目录,文件名为 pima-indians-diabetes.csv。
教程
本教程分为 3 部分。
- 进行预测。
- 系数估计。
- 糖尿病预测。
这将为您提供在自己的预测建模问题中实现和应用带随机梯度下降的逻辑回归所需的基础。
1. 进行预测
第一步是开发一个能够进行预测的函数。
这在随机梯度下降中评估候选系数值以及模型最终确定后我们希望开始对测试数据或新数据进行预测时都需要。
下面是一个名为 predict() 的函数,它根据给定的一组系数预测行的输出值。
第一个系数始终是截距,也称为偏差或 b0,因为它独立存在,不负责特定的输入值。
|
1 2 3 4 5 6 |
# 用系数进行预测 def predict(row, coefficients): yhat = coefficients[0] for i in range(len(row)-1): yhat += coefficients[i + 1] * row[i] return 1.0 / (1.0 + exp(-yhat)) |
我们可以设计一个小型数据集来测试我们的 predict() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 |
X1 X2 Y 2.7810836 2.550537003 0 1.465489372 2.362125076 0 3.396561688 4.400293529 0 1.38807019 1.850220317 0 3.06407232 3.005305973 0 7.627531214 2.759262235 1 5.332441248 2.088626775 1 6.922596716 1.77106367 1 8.675418651 -0.242068655 1 7.673756466 3.508563011 1 |
下面是数据集的图表,使用不同的颜色表示每个点的不同类别。
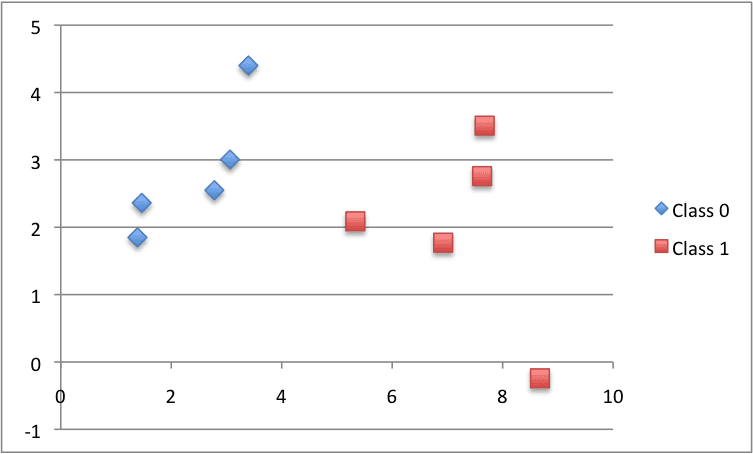
小型人工分类数据集
我们还可以使用预先准备好的系数对该数据集进行预测。
将所有内容放在一起,我们可以在下面测试我们的 predict() 函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 进行预测 from math import exp # 用系数进行预测 def predict(row, coefficients): yhat = coefficients[0] for i in range(len(row)-1): yhat += coefficients[i + 1] * row[i] return 1.0 / (1.0 + exp(-yhat)) # 测试预测 dataset = [[2.7810836,2.550537003,0], [1.465489372,2.362125076,0], [3.396561688,4.400293529,0], [1.38807019,1.850220317,0], [3.06407232,3.005305973,0], [7.627531214,2.759262235,1], [5.332441248,2.088626775,1], [6.922596716,1.77106367,1], [8.675418651,-0.242068655,1], [7.673756466,3.508563011,1]] coef = [-0.406605464, 0.852573316, -1.104746259] for row in dataset: yhat = predict(row, coef) print("Expected=%.3f, Predicted=%.3f [%d]" % (row[-1], yhat, round(yhat))) |
有两个输入值(X1 和 X2)和三个系数值(b0、b1 和 b2)。我们为这个问题建模的预测方程是
|
1 |
y = 1.0 / (1.0 + e^(-(b0 + b1 * X1 + b2 * X2))) |
或者,使用我们手动选择的特定系数值为
|
1 |
y = 1.0 / (1.0 + e^(-(-0.406605464 + 0.852573316 * X1 + -1.104746259 * X2))) |
运行此函数,我们得到与预期输出 (y) 值相当接近的预测,并且在四舍五入后能正确预测类别。
|
1 2 3 4 5 6 7 8 9 10 |
预期=0.000,预测=0.299 [0] 预期=0.000,预测=0.146 [0] 预期=0.000,预测=0.085 [0] 预期=0.000,预测=0.220 [0] 预期=0.000,预测=0.247 [0] 预期=1.000,预测=0.955 [1] 预期=1.000,预测=0.862 [1] 预期=1.000,预测=0.972 [1] 预期=1.000,预测=0.999 [1] 预期=1.000,预测=0.905 [1] |
现在我们准备实现随机梯度下降来优化我们的系数值。
2. 系数估计
我们可以使用随机梯度下降来估计训练数据的系数值。
随机梯度下降需要两个参数
- 学习率:用于限制每次更新时每个系数的修正量。
- 纪元:在更新系数的同时遍历训练数据的次数。
这些参数以及训练数据将是函数的参数。
函数中需要进行 3 次循环
- 遍历每个周期。
- 遍历训练数据中的每一行以进行一个周期。
- 在每个纪元中,遍历每个系数并为一行更新它。
如您所见,我们在每个纪元中为训练数据中的每一行更新每个系数。
系数根据模型产生的误差进行更新。误差计算为预期输出值与使用候选系数进行的预测之间的差值。
每个输入属性都有一个权重系数,这些系数以一致的方式更新,例如
|
1 |
b1(t+1) = b1(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t)) * x1(t) |
列表开头的特殊系数,也称为截距,以类似的方式更新,只是没有输入,因为它不与特定输入值相关联
|
1 |
b0(t+1) = b0(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t)) |
现在我们可以将所有这些整合在一起。下面是一个名为 coefficients_sgd() 的函数,它使用随机梯度下降计算训练数据集的系数值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 使用随机梯度下降估计逻辑回归系数 def coefficients_sgd(train, l_rate, n_epoch): coef = [0.0 for i in range(len(train[0]))] for epoch in range(n_epoch): sum_error = 0 for row in train: yhat = predict(row, coef) error = row[-1] - yhat sum_error += error**2 coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat) for i in range(len(row)-1): coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i] print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error)) return coef |
您可以看到,此外,我们还记录了每个纪元的平方误差之和(一个正值),以便我们可以在每个外部循环中打印一条友好的消息。
我们可以对上面相同的、经过设计的示例数据集进行测试。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from math import exp # 用系数进行预测 def predict(row, coefficients): yhat = coefficients[0] for i in range(len(row)-1): yhat += coefficients[i + 1] * row[i] return 1.0 / (1.0 + exp(-yhat)) # 使用随机梯度下降估计逻辑回归系数 def coefficients_sgd(train, l_rate, n_epoch): coef = [0.0 for i in range(len(train[0]))] for epoch in range(n_epoch): sum_error = 0 for row in train: yhat = predict(row, coef) error = row[-1] - yhat sum_error += error**2 coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat) for i in range(len(row)-1): coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i] print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error)) return coef # 计算系数 dataset = [[2.7810836,2.550537003,0], [1.465489372,2.362125076,0], [3.396561688,4.400293529,0], [1.38807019,1.850220317,0], [3.06407232,3.005305973,0], [7.627531214,2.759262235,1], [5.332441248,2.088626775,1], [6.922596716,1.77106367,1], [8.675418651,-0.242068655,1], [7.673756466,3.508563011,1]] l_rate = 0.3 n_epoch = 100 coef = coefficients_sgd(dataset, l_rate, n_epoch) print(coef) |
我们使用较大的学习率 0.3,并训练模型 100 个纪元,或将系数暴露给整个训练数据集 100 次。
运行示例会在每个纪元打印一条消息,其中包含该纪元的平方误差总和以及最终的系数组。
|
1 2 3 4 5 6 |
>epoch=95, lrate=0.300, error=0.023 >epoch=96, lrate=0.300, error=0.023 >epoch=97, lrate=0.300, error=0.023 >epoch=98, lrate=0.300, error=0.023 >epoch=99, lrate=0.300, error=0.022 [-0.8596443546618897, 1.5223825112460005, -2.218700210565016] |
您可以看到,即使在最后一个纪元,误差仍在继续下降。我们可能可以训练更长时间(更多纪元)或增加每个纪元更新系数的量(更高的学习率)。
尝试一下,看看您会得到什么结果。
现在,让我们将此算法应用于真实数据集。
3. 糖尿病预测
在本节中,我们将使用随机梯度下降在糖尿病数据集上训练逻辑回归模型。
该示例假设数据集的 CSV 副本位于当前工作目录中,文件名为 pima-indians-diabetes.csv。
首先加载数据集,将字符串值转换为数字,并将每列规范化为 0 到 1 范围内的值。这通过辅助函数 load_csv() 和 str_column_to_float() 来加载和准备数据集,以及 dataset_minmax() 和 normalize_dataset() 来规范化它。
我们将使用 k 折交叉验证来估计学习模型在未见数据上的性能。这意味着我们将构建和评估 k 个模型,并将性能估计为平均模型性能。分类准确率将用于评估每个模型。这些行为由 cross_validation_split()、accuracy_metric() 和 evaluate_algorithm() 辅助函数提供。
我们将使用上面创建的 predict()、coefficients_sgd() 函数和新的 logistic_regression() 函数来训练模型。
下面是完整的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 |
# 糖尿病数据集上的逻辑回归 from random import seed from random import randrange from csv import reader from math import exp # 加载 CSV 文件 def load_csv(filename): dataset = list() with open(filename, 'r') as file: csv_reader = reader(file) for row in csv_reader: if not row: continue dataset.append(row) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 查找每列的最小值和最大值 def dataset_minmax(dataset): minmax = list() for i in range(len(dataset[0])): col_values = [row[i] for row in dataset] value_min = min(col_values) value_max = max(col_values) minmax.append([value_min, value_max]) return minmax # 将数据集列重新缩放到 0-1 范围 def normalize_dataset(dataset, minmax): for row in dataset: for i in range(len(row)): row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0]) # 将数据集分成 k 折 def cross_validation_split(dataset, n_folds): dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for i in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_split # 计算准确率百分比 def accuracy_metric(actual, predicted): correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0 # 使用交叉验证分割评估算法 def evaluate_algorithm(dataset, algorithm, n_folds, *args): folds = cross_validation_split(dataset, n_folds) scores = list() 对于 在 折叠中 进行折叠: 训练集 = 列表(折叠) train_set.remove(fold) 训练集 = 求和(训练集, []) 测试集 = 列表() 对于 行 在 折叠中: 行副本 = 列表(行) test_set.append(row_copy) 行副本[-1] = 无 预测值 = 算法(训练集, 测试集, *参数) 实际值 = [行[-1] 对于 行 在 折叠中] 准确率 = 准确率指标(实际值, 预测值) scores.append(accuracy) 返回 分数 # 用系数进行预测 def predict(row, coefficients): yhat = coefficients[0] for i in range(len(row)-1): yhat += coefficients[i + 1] * row[i] return 1.0 / (1.0 + exp(-yhat)) # 使用随机梯度下降估计逻辑回归系数 def coefficients_sgd(train, l_rate, n_epoch): coef = [0.0 for i in range(len(train[0]))] for epoch in range(n_epoch): for row in train: yhat = predict(row, coef) error = row[-1] - yhat 系数[0] = 系数[0] + 学习率 * 误差 * yhat * (1.0 - yhat) for i in range(len(row)-1): coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i] return coef # 具有随机梯度下降的线性回归算法 def 逻辑回归(训练, 测试, 学习率, 迭代次数): 预测值 = 列表() 系数 = 系数_sgd(训练, 学习率, 迭代次数) 对于 行 在 测试中: yhat = predict(row, coef) yhat = 四舍五入(yhat) predictions.append(yhat) return(predictions) # 在糖尿病数据集上测试逻辑回归算法 seed(1) # 加载并准备数据 filename = 'pima-indians-diabetes.csv' 数据集 = 加载_csv(文件名) 对于 i 在 范围(长度(数据集[0])): 字符串列转浮点数(数据集, i) # 归一化 最小最大值 = 数据集_最小最大值(数据集) normalize_dataset(dataset, minmax) # 评估算法 n_folds = 5 学习率 = 0.1 n_epoch = 100 分数 = 评估算法(数据集, 逻辑回归, 折叠数, 学习率, 迭代次数) 打印('分数: %s' % 分数) 打印('平均准确率: %.3f%%' % (求和(分数)/浮点数(长度(分数)))) |
交叉验证使用k值为5,使得每次迭代每个折叠有768/5 = 153.6条记录,即略多于150条记录进行评估。经过少量实验,选择了0.1的学习率和100个训练周期。
You can try your own configurations and see if you can beat my score.
运行此示例将打印5个交叉验证折叠的每个分数,然后打印平均分类准确率。
我们可以看到准确率约为77%,高于我们仅使用零规则算法预测多数类时的基准值65%。
|
1 2 |
分数:[73.8562091503268, 78.43137254901961, 81.69934640522875, 75.81699346405229, 75.81699346405229] 平均准确率:77.124% |
扩展
本节列出了您可能希望探索的一些本教程的扩展。
- 调整示例。调整学习率、迭代次数甚至数据准备方法,以在数据集上获得更高的分数。
- 批量随机梯度下降。将随机梯度下降算法更改为在每个时期累积更新,并仅在时期结束时批量更新系数。
- 额外的分类问题。将该技术应用于UCI机器学习存储库中的其他二元(2类)分类问题。
您是否探索过这些扩展?
Let me know about it in the comments below.
回顾
在本教程中,您学习了如何使用Python从零开始实现带有随机梯度下降的逻辑回归。
You learned.
- 如何对多元分类问题进行预测。
- 如何使用随机梯度下降优化一组系数。
- 如何将该技术应用于实际的分类预测建模问题。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
了解如何从零开始编写算法!

没有库,只有 Python 代码。
...附带真实世界数据集的逐步教程
在我的新电子书中探索如何实现
从零开始实现机器学习算法
它涵盖了 18 个教程,包含 12 种顶级算法的所有代码,例如
线性回归、k-近邻、随机梯度下降等等……
最后,揭开
机器学习算法的神秘面纱
跳过学术理论。只看结果。






这是一篇描述逻辑回归所有不同变体的好论文
http://research.microsoft.com/en-us/um/people/minka/papers/logreg/
太棒了,谢谢Phil的链接。
上面的链接似乎已损坏。正确的链接现在似乎是
https://tminka.github.io/papers/logreg/minka-logreg.pdf
谢谢Michael。
嗨,Jason,
3.糖尿病预测中的代码抛出“ValueError: randrange()的空范围”错误。
我发现它只发生在fold_size不是整数时,因为那样“while len(fold) < fold_size”循环会在每个n_folds中多迭代一次,最终导致len(dataset_copy)为0,从而导致randrange()出错(第47行)。将n_folds更改为6后,它运行正常。是我做错了什么,还是自此发布以来数据集发生了变化,或者还有其他原因?
谢谢!
PS:我使用的是Anaconda的Spyder 3.0.0(Python 3.5)
谢谢Pencho,我想在使用Python 3时需要进行类型转换。我会创建一个任务,并尽快更新示例。
在cross_validation函数下,将“fold_size = len(dataset) // n_folds”中的第二个斜杠添加到“fold_size = len(dataset) // n_folds”。
我已经更新了上面示例中的 cross_validation_split() 函数,以解决 Python 3 的问题。
你好,
我很好奇为什么系数会使用
coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 – yhat) * row[i]
而不是简单地
coef[i + 1] = coef[i + 1] + l_rate * error * row[i]
谢谢
嗨Habo,
我从《人工智能:一种现代方法》第727页的公式(18.8)中获取了该方程。
嗨,Jason,
在优化系数之前进行初始预测时,您是如何精确选择初始系数的?这仅仅是反复试验吗?此外,如果我们选择非常差的系数(无论出于何种原因),我们是否可以运行随机梯度算法来获得最佳(足够好)的系数?
谢谢
嗨Kristopher,通常我们可以从零或随机系数开始。
好的做法是多次重新运行像梯度下降这样的随机过程,并保留最佳结果。
谢谢你,
不幸的是,我是在问第二个问题之后才看到您的回复的,所以如果写得似乎忽略了上下文,我深表歉意,我以为我最初的问题未能提交。
再次感谢
没问题,这是一个学习的地方。
嗨,Jason,
为什么我们要使用第i个系数更新第i+1个系数?为什么我们不直接更新当前所在的系数?换句话说,为什么我们这样做
coef[i + 1] = coef[i+1]…. 等等
而不是这样做
coef[i] = coef[i]…. 等等
好问题 Kristopher。
因为位置0的系数是偏差(截距)系数,它会将索引向下移动一位,使其与输入数据中的索引不匹配。
这有道理吗?
嗨,Jason,
感谢这篇很棒的文章!我最初和Habo有同样的想法。我不确定为什么会这样写:coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 – yhat) * row[i]。我确实有你之前提到的AI书。我仔细看了一下,对我来说,作者正在使用线性回归的成本函数,并将逻辑函数代入h。
另一方面,我认为大多数逻辑回归成本/损失函数都写成最大对数似然,它与(y – h(x))^2的写法不同。这是否解释了您在这篇文章中使用的梯度?区别在于对最大对数似然求导与对y和估计y的平方差求导?再次感谢!
嗨Habo,
我相信项 yhat * (1.0 – yhat) 之所以包含在估计中,是由于 sigmoid 函数及其一阶导数的性质,以及试图将其最小化。更新的系数在每次迭代中使用这些项进行新的估计。设想 yhat = 1 和 yhat = 0。此项将消失。因此 coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 – yhat) * row[i] 变为 coef[i + 1] = coef[i + 1]。这个实验估计与实际值匹配。
我正在将上述代码应用于我的轴承分类问题数据集。
在第2步寻找系数时,我的误差没有减少,而且值很高。我尝试了不同的epcon和学习率值。
考虑对您的数据进行归一化,并确认它具有高斯分布。
考虑使用此过程系统地解决您的问题
https://machinelearning.org.cn/start-here/#process
非常感谢这篇很棒的文章。在这里的两个例子中(无论是使用假数据还是真实数据),我都使用coefficients_sgd()拟合了逻辑回归。我还使用scikit learn拟合了逻辑回归。令人惊讶的是,两种方法估计的系数非常不同。您认为是什么原因造成的?
实现上的微小差异会导致系数的差异。
在应用机器学习中没有“最佳”模型,只有许多不同的模型,我们必须从中选择。
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
感谢您的回答,Jason。我实际上模拟了具有已知系数的数据。然后我一次使用scikit-learn拟合逻辑回归,另一次使用这里提出的SGD方法。scikit-learn的系数估计值与真实系数非常接近(我知道真实值,因为是我自己模拟的)。但是,SGD的系数估计值却非常不同。这可能是梯度公式中的错误吗?
为了仔细检查教程中使用的梯度公式,我写下了损失函数并求导。我的系数(包括截距)的导数是
– X_i (Y_i – \hat{Y_i}) = – X_i (error)
对于截距,X_i 将是 1.0!
您的系数公式中包含额外的元素。我的推导有什么错误吗?我修改了函数,得到了很好的输出。您怎么看?
非常感谢您的帮助。
错误将来自SGD过程本身和随机初始条件。
我认为正则化是这里的关键。scikit-learn库默认进行L2正则化,而这里没有进行。
我有几个基本问题
1) 随机梯度下降是确定权重/参数的唯一方法吗?还有其他方法吗?请提供相关的好资源。
2) 当我们对数据集进行归一化或标准化并在重新缩放的数据上构建模型时,当有新的(未见过的)数据时会发生什么?我们如何使用模型进行预测?因为想象一下在线流数据,我们无法确定最小值/最大值,所以新数据无法重新缩放。那么,我们是在重新缩放/归一化数据上构建模型,并在原始数据上进行预测吗?
不,SGD不是唯一的方法,您可以使用线性代数。
我们必须估计用于缩放的最小值/最大值,这些值需要考虑未来所有新数据。
一个好的替代方法是使用标准化,它需要估计均值和标准差,而不是最小值/最大值。
嗨,Jason。我来自毛里求斯,非常感谢您的信息丰富的博客。我有一个关于您用于更新系数的公式的问题
b1(t+1) = b1(t) + delta,其中delta=学习率 * (y(t) – yhat(t)) * yhat(t) * (1 – yhat(t)) * x1(t)
我正在尝试将相同的公式用于在线(而不是批量)过程,但我遇到了以下问题
如果 y(t)=0 且 yhat(t)=1,则 delta 为 0。
如果 y(t)=1 且 yhat(t)=0,则 delta 为 0。
这些不正确的预测被忽略,而不是更新系数以尝试纠正它们。
所以我的问题是,相同的算法是否可以用于在线学习(即每次预测后更新)?
如果是,我是不是错过了算法的某些功能,或者算法真的会忽略大错误?
嗨,Jason,
当我尝试在自己的数据集上运行系数时,部分 (exp(-(yhat))) 返回错误 'OverflowError: math range error.' 我正在使用 Python 3。有没有关于这可能来自哪里的想法?
另外,还有一个问题。
看起来您正在计算 exp(-yhat),yhat 不是一个实数,而是一个列表吗?Python 如何处理 e^(数字列表)?
yhat 是 a+bx(或 X 和系数的点积)的结果,它始终是一个数字,不可能是列表
很抱歉听到这个消息,这个示例是用Python 2开发的,也许这是Python 3的问题?
你好,
您能给我提供这个方程的推导吗?
b = b + learning_rate * (y – yhat) * yhat * (1 – yhat) * x
那会非常有帮助。
谢谢。
我想我是从《人工智能:一种现代方法》第三版教科书中引用的。
嗨 Jason,
我已经在自己的演示数据集上实现了上述方法。
然而,当我这样做时,经过10个数据周期的SGD模型产生的系数与使用IRLS方法在同一演示数据集上构建的传统逻辑模型产生的系数相去甚远。我希望SGD模型的系数至少会收敛到传统IRLS模型的“真实”系数。
您有什么想法,为什么会这样?是因为我使用的数据集是有序的吗?目前,我所有的“好账户”(Y=1)都排在前面,然后所有的“坏账户”(Y=0)都排在后面。我是否应该在应用SGD之前随机化数据集?
另外——经过10个周期的SGD模型的最终系数似乎完全取决于“学习率”,而且据我所知,这里没有“正确”的值可以使用。您能帮助我吗?
嗨Alex,SGD可能陷入局部最优,对于小问题,使用线性代数解决方案更高效和准确。SGD需要调优。
嗨,Jason,
感谢您的回复。如果您不介意,我还有几个问题
1) 什么是线性代数解决方案?
2) 我还在数据集的一个小样本上建立了一个传统的逻辑模型(IRLS),然后用剩余的数据训练了这个模型。我原以为这意味着SGD的“起点”已经接近全局最优,因此效果会更好,但我仍然没有成功——这个SGD模型仍然与在整个数据集上建立的传统IRLS模型相去甚远——您能告诉我这可能是为什么吗?
再次感谢您的帮助
我说的线性代数是指直接使用矩阵运算(分析地)估计解,而不是搜索解(优化)。
一些想法
– 也许SGD需要针对您的问题进行调整。
– 也许分析解最适合您的问题。
– 也许代码中有错误。
您好 Jason,您关于逻辑回归中 SGD 的文章非常有帮助。我正在尝试实现 SGD 算法,但我有一个问题。我应该如何处理本质上是分类的变量?我应该简单地将它们视为数值变量,让 SGD 算法为它们估计系数吗?
提前感谢!
一般来说,我建议将它们转换为数字或二进制向量(独热编码)。
感谢您的快速回复!我问完不久,就在这个博客中找到了答案。
我在我的机器上使用糖尿病数据集运行了示例,并且正如预期的那样,它给出了约 77% 的精度。当我在 Weka 中使用“Logistic”分类器运行它时,它给出了相似的结果,但系数与我运行上面发布的后得到的系数大相径庭。Weka 给出的系数保持不变,无论我给 useConjugateGradientDescent 选项什么布尔值。
然后我这次使用 SGD 限定符(带和不带归一化)重新运行它,结果又得到一组不同的系数,尽管精度相同。
根据我们使用的算法不同,系数有所不同是正常的吗?
是的。
嗨,Jason
第 72 行的“row_copy[-1] = None”是必要的吗?它有什么用?
非常感谢!
为了清除结果,以便算法不能故意或因错误而“作弊”。
太棒了!
最好往前移一行?
不需要,我们仍然有一个对列表的引用,这样我们就可以更改其中的值。
您好 Jason,帖子不错。在学习参数向量 theta 时,是否没有设置收敛准则,因此无需遍历所有 epoch?
谢谢,
Dan
为了保持示例的简单性。请修改它以添加您希望的任何准则。
嗨,Jason,
感谢您发布这篇非常棒的帖子。我有一个问题,为什么您选择 MSE 成本函数而不是交叉熵,因为预测函数由于 Sigmoid 变换而呈现非线性。
谢谢,
Sanchit
也许可以尝试使用对数损失,看看效果如何。
谢谢。还有一个问题,这种方法是否受限于数据集中的特征数量?
例如,我的数据集中有超过 20 个特征。
同样的方法应该可行,对吗?
我相信它会的。更多特征意味着更多复杂性。
20个特征并不多。试试看吧。
感谢 Jason 分享这份精彩的知识。
我不知道为什么以及在哪里,但在 Python 3 上运行此代码给了我
得分:[9.15032679738562, 4.57516339869281, 11.76470588235294, 8.49673202614379, 7.18954248366013]
平均准确率:8.235%
正在努力寻找原因……
该代码是为 Py2.7 编写的。
忘了 Jason 吧,
我弄清楚了发生了什么。
类别列在第一位而不是最后一位。
谢谢
很高兴听到这个消息。
嗨,Jason,
假设我有一个单独的标签数组,我的数据看起来像 [12, 136, 34],标签是 [1]。我可以直接使用 b0 第一个系数吗?还是我必须忽略它?因为我从您的数据中可以看到,如果我没弄错的话,最后一列是标签。
抱歉,我没听懂你的问题。你能详细说明一下吗?
嗨,Jason,
感谢您的优秀文章!我有一个关于实现小批量反向传播和优化的疑问。
我们基本上会得到每个示例的损失,L_i。大多数工具包似乎返回一个平均损失,即 (1/n)*sum(L_i's),其中 n 是小批量中的样本数量。但是,我们仍然需要计算每个示例的系数梯度,对吗(我们称之为 G_i)?
那么我们是否平均所有梯度(跨样本)并进行更新?即 coef = coef – lr * average(G_i's)
上述方法与每项 G_i 都用自己的 L_i(而不是 average(L_i's))计算,并使用平均梯度(average(G_i's))进行更新的方法有什么区别?
是的,我们对许多样本的损失进行平均。如果我们不这样做,我们会得到一个非常嘈杂的梯度估计,进而导致权重更新出现噪声。
如果我们对损失进行平均,我们仍然会为小批量中的每个输入得到一组梯度 G_i,对吗?(因为梯度本身可能取决于输入)。
那么在执行参数更新时,我们是否再次平均梯度 G_i?如果是,为什么我们需要在两个步骤(损失和梯度)都进行平均,而不是只对梯度进行一次平均?
您好,我注意到您的代码中(在进行随机梯度下降时)对于线性回归,您有这个
coef[i + 1] = coef[i + 1] – l_rate * error * row[i]
但是对于逻辑回归,您有这个
coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 – yhat) * row[i]
yhat * (1.0 – yhat) 部分是否等价于 ln(y / (1-y))?
好问题,我暂时不确定,我手头没有推导过程。
谁能帮我用 R 语言实现随机梯度下降,我将不胜感激。
我建议使用库而不是自己编写代码。
我们如何使用 Python 代码获取独立变量的系数?
我在上面的教程中展示了如何计算并打印它们。
您遇到哪部分问题?
你好,Jason!
您的又一篇精彩文章。谢谢。
我尝试“聪明”(或懒惰)地使用 Scikit-learn API 进行 SGD 逻辑回归。
进行同类比较,API 获得了 63% 的准确率,而使用您的代码,我获得了 77% 的准确率。
奇怪且有趣……
干得好!
是的,实现上的微小差异可能会对性能产生巨大影响。
谢谢 Jason!
您好 Jason,感谢您有趣的教程。我有一个问题。为了提高准确率和 AUC,使用 SGD 还是 Xgboost 更好?
两种都试试,看看哪种最适合您的特定数据集。
您好 Jason,我很喜欢您的实现。
有趣的是,我们的课程通常使用梯度上升来寻找系数 W,该系数 W 最大化 P(Y|X, W) 的条件似然对数。
而且我相信在此实现中,我们改为使用梯度下降来最小化成本函数。我假设成本函数是 Y_true – P(Y|X, W),您能确认一下吗?
条件似然的对数可以在以下笔记的第 11 页找到
http://www.cs.cmu.edu/~tom/mlbook/NBayesLogReg.pdf
嗨,Jason!
我们必须对数据进行缩放和归一化吗?据我所知,在逻辑回归模型中这不是必须的。
如果必须,为什么?
非常感谢!
这取决于数据,如果输入变量的单位不同,那么是的,建议将输入缩放到相同的范围。
尝试缩放和不缩放,然后比较性能。
谢谢你的回答,Jason!
实际上,我做到了,对我的分数来说是一样的。
但我从现在开始会记下这一点。
谢谢你,杰森,这篇文章信息量很大。
谢谢,很高兴它有帮助。
你好,先生,
我有一个疑问
从 sklearn.linear_model 的 LinearRegression() 获得的系数也是更好的系数,对吧?这些系数是通过最小化 OLS 获得的。
那么我们为什么要再次应用随机梯度下降来获得相同的系数呢?
机器学习模型中的系数值是否准确?
还是说随机梯度下降是为了获得更好的系数值?
解决线性回归的方法有很多种。
当所有数据都适合内存时,linalg 方法很好。
当您有大量数据时,sgd 方法很好。
两者都可能准确或不准确,sgd 的结果可能噪声更大,但更健壮。linalg 对数据有严格的假设。
您好 Jason,在 SGD 中您使用了平方损失,这是线性回归。您能发布逻辑损失的对数损失方法吗?
感谢您的建议。
嗨,Jason,
又是一篇很棒的博客和很棒的文章。
小问题是,您提供的链接中,文件名为“pima-indians-diabetes.data.csv”,而代码中是“pima-indians-diabetes.csv”,因此解释器找不到它。
对于遇到此错误的读者,只需更改名称使其匹配即可。
谢谢
谢谢提示。
请注意,教程中写道:
嗨,Jason,
作为后续,有几个问题
1- 为什么这被称为“随机”梯度下降?我印象中,当我查看 coefficients_sgd() 的代码时,它是一个确定性算法,用相同的参数运行几次会得到相同的结果。您能澄清一下在这种情况下“随机”是什么意思吗?
2- 您曾向 Manuela 提到,使用 xgboost 实现是可行的。那仍然是逻辑回归的一种形式,还是会被认为是决策树算法?
再次感谢您的网站和您分享的所有优质材料!
因为每个样本后权重的更新是嘈杂的——例如,梯度的随机估计。
XGBoost 不使用 SGD,但它可以对特征和行进行随机采样,这被称为随机梯度提升。
嗨,Jason,
您能告诉我您是如何选择这里的初始系数的吗?
y = 1.0 / (1.0 + e^(-(-0.406605464 + 0.852573316 * X1 + -1.104746259 * X2))) 1 y = 1.0 / (1.0 + e^(-(-0.406605464 + 0.852573316 * X1 + -1.104746259 * X2)))
谢谢,
马哈茂德
在这种情况下,我认为它们对于那段代码的测试是任意的。
训练逻辑回归模型的整个思想就是找到那些系数。
您好 Jason:
首先,非常感谢您的分享;您写的每一篇文章都很棒。
我有一个小问题想请教您:我注意到您的文章中关于 b0, b1, b2 … 的迭代更新公式是应用了 [教科书 AI a modern approah 第3版] 中的,我查阅了这本书并阅读了相关部分,然后我发现这部分使用的损失函数是 loss (x) = y-yhat;然后我又搜索了逻辑回归随机梯度下降实现中使用的其他最大似然函数是 (pi ^ y (1-pi) 1-y)。那么这两种思想是不同的吗?最大似然函数使用的思想是最大似然的思想,而您文章中使用的思想是直接最小化误差吗?
期待您的回复。谢谢。
不客气。
是的,有很多方法。在这里,我们学习模型的结构以及如何使用优化算法来解决它,而不是解决逻辑回归的最佳方法。
此外,更多关于 LR 的 MLE 信息在这里:
https://machinelearning.org.cn/logistic-regression-with-maximum-likelihood-estimation/
您好 Jason:
首先,非常感谢您分享您的文章,它对所有机器学习工程师都非常有帮助。我真的对您的文章印象深刻,无言以表。
您的所有文章都很棒,真正帮助了数据科学界。我非常感谢您为整个数据科学界所做的努力和贡献。
如果您能从头到尾发布一些真实世界项目的文章,那将更有帮助。或者,如果您已经发布过任何内容,请告诉我任何链接。或者给我一些我可以找到的链接。
期待您的回复。再次感谢,并祝您新年快乐。
不客气。
是的,博客上有很多项目,您可以使用搜索功能找到它们。
嗨,Jason,
我在 XL 表格中执行了这些步骤,
但是,我得到了不正确的结果。
我多次交叉检查。
我到底哪里出错了。
我遵循了《掌握机器学习算法》一书第 14.3 章给出的示例。
https://drive.google.com/file/d/1jQgn4yy9DYrMWmyKyxY3VECQ1hDLsfE2/view?usp=sharing
找到 Excel 表格。
谢谢你
请参阅书中提供的电子表格并比较结果。
如果您丢失了书中提供的电子表格,请给我发电子邮件,我可以重新发送您的购买收据以及更新的下载链接。
https://machinelearning.org.cn/contact/
如果您盗版了这本书,那么我帮助您是不道德的。
嗨,Jason,
有没有关于通过多进程进行梯度计算的提示?
是的,使用支持多线程的现有实现。
此外,逻辑回归并不是一个真正可并行化的算法,除非您将其更改为使用 SGD,然后您可以通过批处理进行系数更新。
亲爱的同事!
b = b + learning_rate * (y – yhat) * x
因为损失函数(交叉熵函数)不同
L = – sum(yhat * ln(y) + (1 – yhat) * (1 – ln(y)))
嗨,Jason,
我只是想补充我之前的评论。我认为我们应该注意到,帖子中使用的梯度是 L2 损失函数的导数,它是用于计算误差的众多损失/成本函数之一。
另一方面,如果采用对数似然的梯度(导数),我们将得到 b = b + learning_rate * (y – yhat) * x 之类的值。因此,该梯度将用于最大化对数似然并通过梯度下降法确定最合适的系数。请告诉我您的想法。谢谢!
我很抱歉……我应该写成通过“梯度上升”来获得最合适的系数,因为我们正在最大化对数似然。我们正朝着梯度的方向迈出小步,达到局部最大值。
机器学习大师 Andrew Ng 在计算逻辑回归的随机梯度下降时使用了对数损失函数的导数。我不确定为什么本章没有实现这一点,以及本章的梯度方法与对数损失导数方法相比有什么意义。
我也有同样的问题:对我来说,这与 Jason 另一个例子中的线性回归示例之间唯一的区别应该是函数 h_theta,这里称为“predict”。因此,我认为损失函数应该是:coef[i + 1] = coef[i + 1] + l_rate * error * row[i],但我很想知道我是否理解错误
你似乎在使用平方损失
J = (y-y^)**2
dJ/db1 = dJ/dy * dy/db1
= – 2 * (y-y^) * (y^) (1-y^)* x
在这种情况下,你漏掉了“2”,Jason 我对吗??
正确,但你是否看到从梯度下降的角度来看没有区别?
你好,
我不明白在方程 b = b + learning_rate * (y – yhat) * yhat * (1 – yhat) * x 中,这是哪个 x?x1 还是 x2?
你好 Andrew……在这种情况下应该是 X1。
你好 Jason,我不明白 normalize_dataset() 函数的含义
你好 cylon……以下内容可能对你感兴趣
https://machinelearning.org.cn/batch-normalization-for-training-of-deep-neural-networks/
为什么这样计算 row[i] = (row[i] – minmax[i][0]) / (minmax[i][1] – minmax[i][0]),不能直接使用数据集本身吗?
你好 cylon……是的,还有其他选择。你会如何以不同的方式处理它?
嗨,Jason,
我有一个基本问题。
对于真实数据集的最终输出,我们只得到平均准确率:77.124%,但没有打印最优参数。
请问如何打印与平均准确率:77.124% 相关的系数集?