循环神经网络的编码器-解码器架构在自然语言处理领域的许多序列到序列预测问题中都显示出强大的能力。
注意力机制是一种解决编码器-解码器架构在长序列上的局限性的方法,它通常可以加速学习并提升模型在序列到序列预测问题上的技能。
在本帖中,您将了解实现带注意力机制和不带注意力机制的编码器-解码器模型的模式。
阅读本文后,你将了解:
- 编码器-解码器循环神经网络的直接实现模式与递归实现模式。
- 注意力机制如何融入编码器-解码器模型的直接实现模式。
- 注意力机制如何与编码器-解码器模型的递归实现模式一起实现。
快速开始您的项目,阅读我的新书 《Python长短期记忆网络》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

带注意力机制的RNN编码器-解码器架构的实现模式
照片由 Philip McErlean 拍摄,部分权利保留。
带注意力的编码器-解码器
循环神经网络的编码器-解码器模型是一种用于序列到序列预测问题的架构,其中输入序列的长度与输出序列的长度不同。
顾名思义,它由两个子模型组成:
- 编码器:编码器负责遍历输入时间步,并将整个序列编码成一个固定长度的向量,称为上下文向量。
- 解码器:解码器负责遍历输出时间步,同时读取上下文向量。
该架构的一个问题是,在长输入或输出序列上性能较差。据信原因是编码器使用了固定大小的内部表示。
注意力机制是对该架构的扩展,它解决了这一局限性。它的工作原理是首先为解码器提供来自编码器的更丰富的上下文,并提供一种学习机制,使解码器能够学习在生成输出序列的每个时间步时,在更丰富的编码中应关注何处。
有关编码器-解码器架构的更多信息,请参阅帖子
直接编码器-解码器实现
有多种方法可以实现编码器-解码器架构作为系统。
一种方法是由解码器根据编码器的输入来完全生成输出。模型通常如此描述。
……我们提出了一种新颖的神经网络架构,它能够学习将可变长度序列编码为固定长度向量表示,并将给定固定长度向量表示解码回可变长度序列。
— 《使用循环神经网络编码器-解码器进行统计机器翻译的学习短语表示》,2014。
为了便于理解,我们将这种模型称为直接编码器-解码器实现。
为了使这一点更清楚,让我们通过一个法语到英语的神经机器翻译的示例来进行说明。
- 模型接收一个法语句子作为输入。
- 编码器逐词读取句子,并将序列编码为一个固定长度的向量。
- 解码器读取编码后的输入,并逐词输出英语。
下图为此实现的示意图。
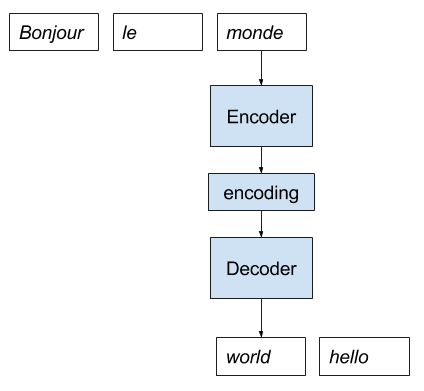
用于神经机器翻译的直接编码器-解码器模型实现
递归编码器-解码器实现
另一种实现方式是这样构建模型:它只生成一个词,然后递归调用模型来生成整个输出序列。
为了与上述描述区分开,我们将此称为递归实现(暂无更好的名称)。
在其关于图像描述生成模型《Where to put the Image in an Image Caption
Generator》的论文中,Marc Tanti等人将直接方法称为“连续视图”。
传统上,神经网络语言模型被描绘成……字符串被认为是连续生成的。每个时间步生成一个新词,将RNN的状态与最后一个生成的词结合起来生成下一个词。我们称之为“连续视图”。
— 《Where to put the Image in an Image Caption Generator》,2017。
他们将递归实现称为“离散视图”。
我们建议从一系列离散快照的角度来看待RNN,每个词都是从先前所有词的前缀生成的,并且RNN的状态在每次生成后都会被重新初始化。我们称之为“离散视图”。
— 《Where to put the Image in an Image Caption Generator》,2017。
我们可以使用递归实现来逐步分析相同的法语到英语神经机器翻译示例。
- 模型接收一个法语句子作为输入。
- 编码器逐词读取句子,并将序列编码为一个固定长度的向量。
- 解码器读取编码后的输入,并输出一个英语单词。
- 将输出作为输入,与编码的法语句子一起,进入步骤3。
下图为此实现的示意图。
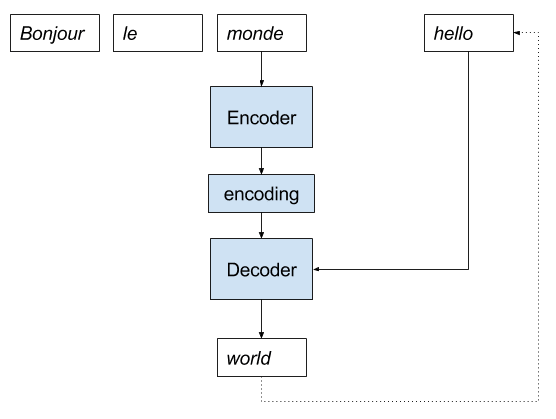
用于神经机器翻译的递归编码器-解码器模型实现
为了开始这个过程,可能需要向模型提供一个“序列开始”标记作为已生成输出序列的输入。
可以将迄今为止生成的整个输出序列作为输入重新提供给解码器,可以包含或不包含编码的输入序列,以便解码器在预测下一个单词之前达到与在上一节中一次性生成整个输出序列时相同的内部状态。
合并编码器-解码器实现
递归实现可以模拟一次性输出整个序列,就像在第一个模型中一样。
递归实现还允许您更改模型,并尝试更简单的或更有效的模型。
一个例子是,还可以编码输入序列,并使用解码器模型来学习如何最好地组合编码的输入序列和迄今为止生成的输出序列。Marc Tanti等人在其论文《What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?》中称之为“合并模型”。
……在给定的时间步长,合并架构通过将迄今为止生成的字符串的RNN编码前缀(生成过程的“过去”)与非语言信息(生成过程的“指导”)结合起来,来预测接下来要生成什么。
— 《What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?》,2017
模型仍然是递归调用的,只是模型的内部结构发生了变化。我们可以通过图示来清晰说明这一点。
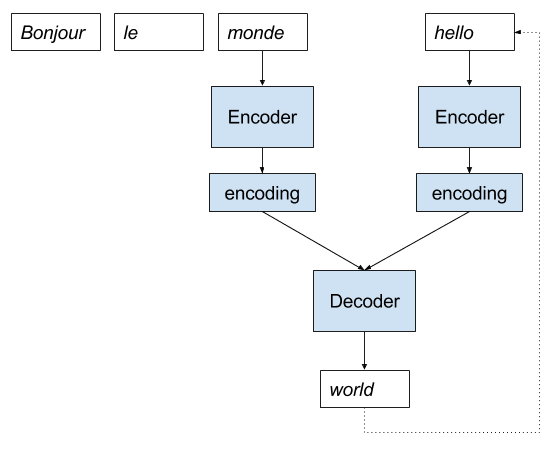
用于神经机器翻译的合并编码器-解码器模型实现
带注意力的直接编码器-解码器实现
现在我们可以结合这些不同的编码器-解码器循环神经网络架构的实现模式来考虑注意力机制。
Bahdanau等人提出的标准注意力机制,在其论文《《通过联合学习对齐和翻译的神经机器翻译》》中,包含以下几个要素:
- 更丰富的编码。编码器的输出被扩展,以提供输入序列中所有词的信息,而不仅仅是最后一个词的最终输出。
- 对齐模型。使用一个新的小型神经网络模型,通过前一个时间步解码器的注意力输出,来对齐或关联扩展后的编码。
- 加权编码。对齐的权重,可用作输入序列的概率分布。
- 加权上下文向量。应用于编码输入序列的权重,然后可用于解码下一个单词。
请注意,在所有这些编码器-解码器模型中,模型输出(下一个预测的单词)与解码器输出(内部表示)之间存在差异。解码器不直接输出单词;通常会有一个全连接层连接到解码器,该层输出词汇表中单词的概率分布,然后通过诸如束搜索之类的启发式方法进一步搜索。
有关如何在编码器-解码器模型中计算注意力的更多详细信息,请参阅帖子
我们可以为带注意力的直接编码器-解码器模型创建一个卡通图,如下所示。
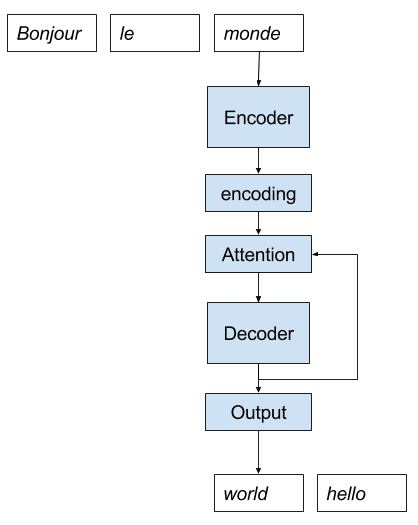
用于神经机器翻译的直接编码器-解码器带注意力模型实现
在直接编码器-解码器模型中实现注意力可能具有挑战性。这是因为高效的神经网络库需要向量化方程,这些方程要求在计算之前所有信息都可用。
模型需要访问解码器为每个预测生成的注意力输出,这破坏了这种需求。
带注意力的递归编码器-解码器实现
注意力机制很适合进行递归描述和实现。
递归实现注意力机制要求,除了将已生成输出序列提供给解码器之外,前一个时间步解码器生成的输出还可以提供给注意力机制,以预测下一个单词。
我们可以用一个卡通图来更清楚地说明这一点。
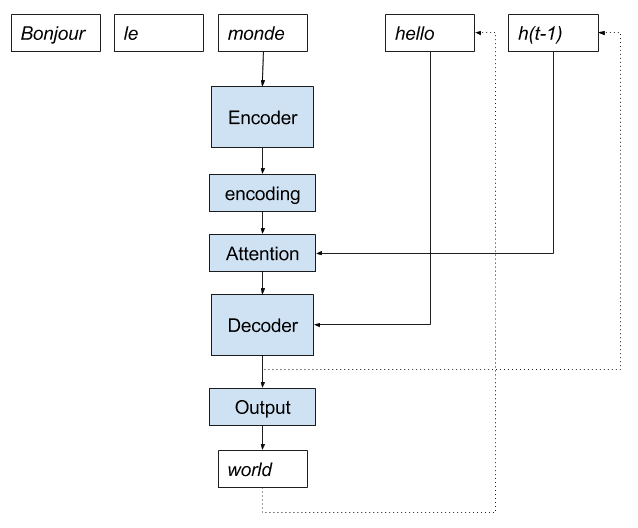
用于神经机器翻译的递归编码器-解码器带注意力模型实现
递归方法还为尝试新设计提供了额外的灵活性。
例如,Luong等人(在其论文《《基于注意力的神经机器翻译的有效方法》》中)更进一步,提出可以将前一个时间步的解码器输出(h(t-1))作为输入提供给解码器,而不是用于注意力计算。他们称之为“输入馈送”模型。
具有此类连接的影响是双重的:(a)我们希望使模型完全了解先前的对齐选择,并且(b)我们创建了一个跨越水平和垂直方向的非常深的网络。
— Effective Approaches to Attention-based Neural Machine Translation, 2015。
有趣的是,这种输入馈送与他们的局部注意力相结合,在撰写本文时,在标准的机器翻译任务上取得了最先进的性能。
输入馈送方法与合并模型有关。合并模型提供的是所有先前生成时间步的编码,而不是仅提供最后一个时间步的解码输出。
人们可以想象解码器中的注意力机制利用这种编码来帮助解码编码的输入序列,或者可能在两种编码上都使用注意力。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
论文
- 《使用循环神经网络编码器-解码器进行统计机器翻译的学习短语表示》, 2014.
- 通过联合学习对齐和翻译的神经机器翻译, 2015.
- 如何在图像标题生成器中放置图像, 2017.
- 循环神经网络 (RNN) 在图像描述生成器中的作用是什么?, 2017
- 基于注意力的神经机器翻译的有效方法, 2015.
总结
在本帖中,您了解了实现带注意力机制和不带注意力机制的编码器-解码器模型的模式。
具体来说,你学到了:
- 编码器-解码器循环神经网络的直接实现模式与递归实现模式。
- 注意力机制如何融入编码器-解码器模型的直接实现模式。
- 注意力机制如何与编码器-解码器模型的递归实现模式一起实现。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






您在哪里有这个教程?
Tom,您指的是什么?
抱歉,我没说清楚,Jason。
我的问题是——您在《Python长短期记忆网络》这本书中有这篇文章吗?
我不知道您是否在书中涵盖了“注意力”主题。
谢谢
没有。这本书没有涵盖这篇帖子和注意力主题。
我正在等待Keras API正式发布注意力机制,到时候我可能会将注意力机制添加到书中。
您有计划在这本书中添加“注意力”主题吗?我认为这是一个非常重要的主题。
我希望如此。当Keras实现最终确定后,我将开始进行。