你可以使用的20个技巧、窍门和技术
对抗过拟合,获得更好的泛化能力
如何让你的深度学习模型表现得更好?
这是我被问到的最常见的问题之一。
它可能会被问成:
我该如何提高准确率?
...或者反过来问:
如果我的神经网络表现不佳,我能做些什么?
我通常会回答:“我不知道具体该怎么做,但我有很多想法。”
然后我就会列出所有我能想到的可能提升性能的方法。
与其每次都重新写一遍这个列表,我决定把所有想法都写在这篇文章里。
这些想法不仅能帮助你处理深度学习,实际上对任何机器学习算法都有用。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
这是一篇很长的文章,你可能需要收藏一下。

如何提升深度学习性能
照片由 Pedro Ribeiro Simões 拍摄,保留部分权利。
提升算法性能的想法
这个想法列表并不完整,但它是一个很好的起点。
我的目标是给你提供很多可以尝试的想法,希望其中有一两个是你没有想过的。
通常你只需要一个好主意就能获得提升。
如果你通过其中一个想法取得了成果,请在评论中告诉我。
我很乐意听到!
如果你还有一个新想法,或是对所列想法的延伸,也请告诉我,我和所有读者都会受益!它可能正是帮助别人取得突破的那个想法。
我将列表分成了4个子主题:
- 通过数据提升性能。
- 通过算法提升性能。
- 通过算法调优提升性能。
- 通过集成方法提升性能。
通常,越往下,收益会越小。例如,重新构建问题或增加数据,通常会比调整表现最佳算法的参数带来更大的回报。虽然不总是这样,但大体上是如此。
我加入了许多来自博客的教程链接、相关网站的问题,以及经典的神经网络常见问题解答中的问题。
有些想法是针对人工神经网络的,但很多都相当通用。通用到你可以用它们来启发如何在其他技术上提升性能。
让我们开始吧。
1. 通过数据提升性能
通过改变训练数据和问题定义,你可以获得巨大的收益。甚至可能是最大的收益。
以下是我们将要涵盖的简短列表:
- 获取更多数据。
- 创造更多数据。
- 重缩放你的数据。
- 转换你的数据。
- 特征选择。
1) 获取更多数据
你能获得更多的训练数据吗?
你的模型质量通常受限于训练数据的质量。你需要为你的问题获取最好的数据。
你也需要大量的数据。
深度学习和其他现代非线性机器学习技术会随着数据量的增加而变得更好。尤其是深度学习。这是让深度学习如此激动人心的主要原因之一。
看看下面的漫画:
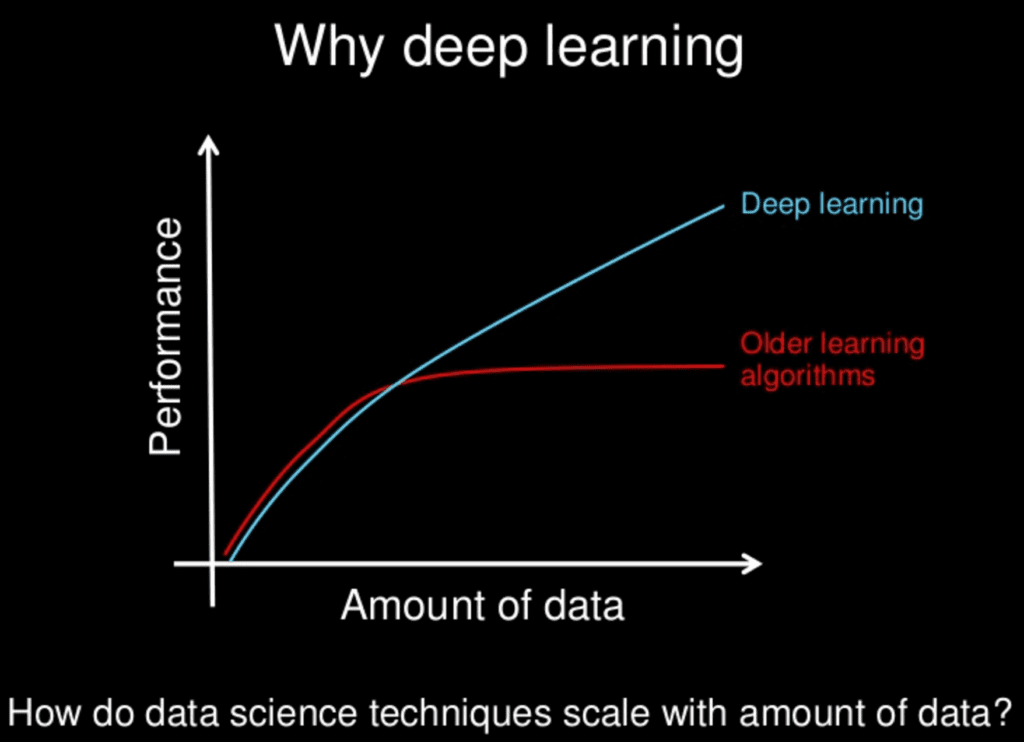
为什么是深度学习?
幻灯片由 Andrew Ng 提供,保留所有权利。
更多数据并不总是有帮助,但它可能会。如果让我选择,我会获取更多数据,因为它提供了更多的可能性。
相关
2) 创造更多数据
深度学习算法通常在数据更多时表现更好。
我们在上一节提到了这一点。
如果你无法合理地获取更多数据,你可以创造更多数据。
- 如果你的数据是数字向量,可以创建现有向量的随机修改版本。
- 如果你的数据是图像,可以创建现有图像的随机修改版本。
- 如果你的数据是文本,你懂的……
这通常被称为数据增强或数据生成。
你可以使用生成模型。你也可以使用简单的技巧。
例如,对于照片图像数据,通过随机平移和旋转现有图像可以获得巨大的收益。如果新数据中预期会出现这类变换,这样做可以提高模型对这些变换的泛化能力。
这也与添加噪声有关,我们过去称之为添加抖动(jitter)。它可以像一种正则化方法一样,抑制对训练集的过拟合。
相关
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
3) 重缩放你的数据
这是一个快速见效的方法。
在处理神经网络时,一个传统的经验法则是:
将你的数据重缩放到激活函数的边界范围内。
如果你使用 sigmoid 激活函数,将数据重缩放到 0 到 1 之间。如果你使用双曲正切函数(tanh),则重缩放到 -1 到 1 之间。
这适用于输入(x)和输出(y)。例如,如果你在输出层使用 sigmoid 来预测二元值,那么将你的 y 值归一化为二元值。如果你使用 softmax,归一化 y 值仍然可以带来好处。
这仍然是一个很好的经验法则,但我会更进一步。
我建议你创建几个不同版本的训练数据集,如下所示:
- 归一化到 0 到 1。
- 重缩放到 -1 到 1。
- 标准化。
然后在每个数据集上评估你的模型性能。选择一个,然后加倍投入。
如果你改变了激活函数,重复这个小实验。
网络中累积的大数值是不好的。此外,还有其他方法可以保持网络中的数值较小,例如归一化激活值和权重,但我们稍后会讨论这些技术。
相关
4) 转换你的数据
与上面建议的重缩放相关,但需要更多工作。
你必须真正了解你的数据。将其可视化。寻找异常值。
估算每一列的单变量分布。
- 如果一列看起来像偏态高斯分布,可以考虑使用 Box-Cox 变换来调整偏度。
- 如果一列看起来像指数分布,可以考虑进行对数变换。
- 如果一列看起来有一些特征,但它们被一些明显的东西掩盖了,可以尝试平方或开方。
- 你能否以某种方式将特征离散化或分箱,以更好地强调某些特征?
依靠你的直觉。多做尝试。
- 你能用 PCA 这样的投影方法来预处理数据吗?
- 你能将多个属性聚合成一个单一的值吗?
- 你能通过一个新的布尔标志来揭示问题的某些有趣方面吗?
- 你能以其他方式探索时间或其他结构吗?
神经网络会进行特征学习。它们可以做这些事情。
但是,如果你能更好地将问题的结构暴露给网络进行学习,它们学习问题的速度会快得多。
快速检查你的数据或特定属性的许多不同变换,看看哪些有效,哪些无效。
相关
5) 特征选择
神经网络通常对不相关的数据具有鲁棒性。
它们会使用一个接近于零的权重,并将非预测性属性的贡献边缘化。
尽管如此,这些数据、权重、训练周期还是用在了不需要进行良好预测的数据上。
你能从你的数据中移除一些属性吗?
有很多特征选择方法和特征重要性方法可以给你提供关于保留哪些特征和剔除哪些特征的想法。
尝试一些。全部都试试。目的是获得想法。
同样,如果你有时间,我建议用同一个网络评估几个不同的问题“视图”,看看它们的表现如何。
- 也许你可以用更少的特征做得同样好甚至更好。太好了,速度更快!
- 也许所有的特征选择方法都剔除了相同的特定特征子集。太好了,对无用特征达成了共识。
- 也许一个选定的子集能给你一些关于可以进行的进一步特征工程的想法。太好了,更多的想法。
相关
6) 重新构建你的问题
退一步审视你的问题。
你收集到的观察数据是构建问题的唯一方式吗?
也许还有其他方式。也许问题的其他构建方式能更好地将问题的结构暴露给学习过程。
我真的很喜欢这个练习,因为它迫使你敞开心扉。这很难。尤其是在你已经对当前方法投入了很多(自尊心!!!、时间、金钱)的情况下。
即使你只是列出3到5个备选框架然后否定它们,至少你也在建立对自己所选方法的信心。
- 也许你可以将时间元素纳入一个窗口或一个允许时间步长的方法中。
- 也许你的分类问题可以变成回归问题,反之亦然。
- 也许你的二元输出可以变成一个 softmax 输出?
- 也许你可以转而对一个子问题建模。
在拿起工具之前,仔细思考问题及其可能的框架是一个好主意,因为你对解决方案的投入较少。
尽管如此,如果你陷入困境,这个简单的练习可以带来一股思想的清泉。
另外,你不需要扔掉任何之前的工作。请看后面的集成方法部分。
相关
2. 通过算法提升性能
机器学习是关于算法的。
所有的理论和数学都描述了从数据中学习决策过程的不同方法(如果我们把自己限制在预测建模的范畴内)。
你为你的问题选择了深度学习。它真的是你能选择的最佳技术吗?
在这一节中,我们将简单谈谈算法选择的一些想法,然后再深入探讨如何从你选择的深度学习方法中获得最大收益。
以下是简短列表:
- 抽查算法。
- 借鉴文献。
- 重采样方法。
我们开始吧。
1) 抽查算法
做好心理准备。
你无法事先知道哪种算法在你的问题上表现最好。
如果你知道,你可能就不需要机器学习了。
你收集了什么证据表明你选择的方法是个好选择?
让我们反过来看这个难题。
当性能在所有可能问题上取平均时,没有单一算法能比其他算法更好。所有算法都是平等的。这是对“没有免费午餐”定理的发现的总结。
也许你选择的算法并不是最适合你的问题的。
现在,我们不是要解决所有可能的问题,但算法领域的新热点可能并非在你特定的数据集上是最佳选择。
我的建议是收集证据。接受这样一个想法:还有其他好的算法,并给它们一个在你的问题上公平竞争的机会。
抽查一套顶级方法,看看哪些表现好,哪些不好。
- 评估一些线性方法,如逻辑回归和线性判别分析。
- 评估一些树方法,如CART、随机森林和梯度提升。
- 评估一些实例方法,如SVM和kNN。
- 评估一些其他的神经网络方法,如LVQ、MLP、CNN、LSTM、混合模型等。
对表现最好的方法加倍投入,通过进一步的调优或数据准备来提高它们的机会。
将结果与你选择的深度学习方法进行排名比较,它们表现如何?
也许你可以放弃深度学习模型,使用一些更简单、训练更快、甚至更容易理解的方法。
相关
2) 借鉴文献
选择一个好方法的捷径,就是借鉴文献中的想法。
还有谁处理过类似你的问题,他们用了什么方法?
查阅论文、书籍、博客文章、问答网站、教程,所有谷歌能给你的东西。
写下所有的想法,然后逐一尝试。
这不是要复制研究,而是要获得你没有想到的新想法,这些想法可能会给你带来性能上的提升。
已发表的研究是高度优化的.
有很多聪明的人写了很多有趣的东西。从这个巨大的图书馆中挖掘你需要的宝藏。
相关
3) 重采样方法
你必须知道你的模型有多好。
你对模型性能的估计可靠吗?
深度学习方法的训练速度很慢。
这通常意味着我们无法使用像k折交叉验证这样的黄金标准方法来估计模型性能。
- 也许你正在使用简单的训练/测试集划分,这很常见。如果是这样,你需要确保划分能够代表整个问题。单变量统计和可视化是一个好的开始。
- 也许你可以利用硬件来改进估计。例如,如果你有一个集群或亚马逊云服务账户,我们可以并行训练 *n* 个模型,然后取结果的均值和标准差来获得更稳健的估计。
- 也许你可以使用一个验证集来了解模型在训练过程中的性能(对提前停止很有用,见后文)。
- 也许你可以保留一个完全独立的验证集,只在完成模型选择后使用。
反过来,也许你可以把数据集变小,使用更强的重采样方法。
- 也许你发现在训练数据集的一个样本上训练的模型的性能与在整个数据集上训练的模型的性能有很强的相关性。或许你可以在较小的数据集上进行模型选择和调优,然后在最后将最终的技术扩展到完整的数据集上。
- 也许你可以无论如何都限制数据集,取一个样本,并用它来进行所有的模型开发。
你必须对你的模型性能评估有完全的信心。
相关
3. 通过算法调优提升性能
这才是重点所在。
你通常可以通过抽查快速发现一两个表现良好的算法。而要从这些算法中获得最大收益,可能需要几天、几周甚至几个月的时间。
以下是一些关于调优你的神经网络算法以获得更好性能的想法。
- 诊断。
- 权重初始化。
- 学习率。
- 激活函数。
- 网络拓扑。
- 批次和周期。
- 正则化。
- 优化和损失函数。
- 提前停止。
你可能需要多次(3-10次或更多)训练一个给定的网络“配置”,才能得到该配置性能的一个良好估计。这可能适用于本节中你可以调整的所有方面。
关于超参数优化的一篇好文章,请看:
1) 诊断
如果你知道为什么性能不再提高,你就能获得更好的性能。
你的模型是过拟合还是欠拟合?
始终牢记这个问题。始终。
它总是在这两者之间,只是程度不同。
一个快速了解模型学习行为的方法是,在每个周期(epoch)后,在训练集和验证集上评估它,并绘制结果图。
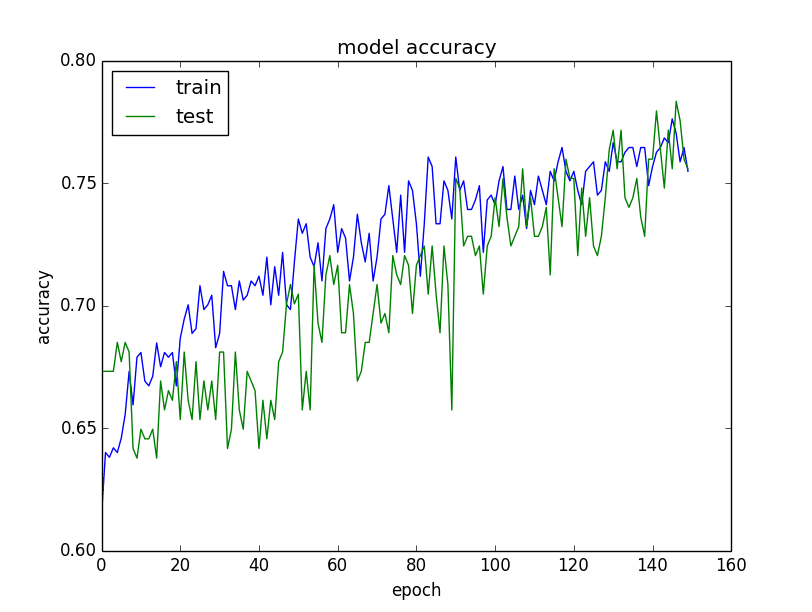
训练集和验证集上模型准确率的图
- 如果训练集上的表现远好于验证集,你很可能在过拟合,可以使用正则化等技术。
- 如果训练集和验证集的表现都很低,你很可能在欠拟合,你或许可以增加网络的容量并进行更多或更长时间的训练。
- 如果训练曲线超过验证曲线时出现拐点,你也许可以使用提前停止。
经常创建这些图表,并研究它们,以洞察可以用来提高性能的不同技术。
这些图表可能是你能创建的最有价值的诊断工具。
另一个有用的诊断方法是研究网络预测正确和错误的观察样本。
在某些问题上,这可以给你一些尝试的想法。
- 也许你需要更多或增强版的难以训练的样本。
- 也许你可以移除训练数据集中大量容易建模的样本。
- 也许你可以使用专门的模型,专注于输入空间中不同的清晰区域。
相关
2) 权重初始化
过去的经验法则是:
使用小的随机数进行初始化。
在实践中,这可能仍然足够好。但对你的网络来说,这是最好的吗?
对于不同的激活函数,也有一些启发式方法,但我记得在实践中没看到太大区别。
保持你的网络固定,尝试每一种初始化方案。
记住,权重是你要寻找的模型的实际参数。有很多组权重能提供良好的性能,但你想要的是更好的性能。
- 在其他一切保持不变的情况下,尝试所有不同的初始化方法,看看哪一种更好。
- 尝试使用像自编码器这样的无监督方法进行预学习。
- 尝试使用一个现有的模型,并为你的问题重新训练一个新的输入和输出层(迁移学习)。
记住,改变权重初始化方法与激活函数甚至优化函数密切相关。
相关
3) 学习率
调整学习率通常会有回报。
以下是一些可以探索的想法:
- 尝试非常大和非常小的学习率。
- 对文献中常见的学习率值进行网格搜索,看看能把网络推到多远。
- 尝试一个随周期(epochs)递减的学习率。
- 尝试一个每隔固定周期数就按百分比下降的学习率。
- 尝试添加一个动量项,然后对学习率和动量一起进行网格搜索。
更大的网络需要更多的训练,反之亦然。如果你增加了更多的神经元或更多的层,就增加你的学习率。
学习率与训练周期数、批次大小和优化方法相关联。
相关
4) 激活函数
你可能应该使用修正线性单元(ReLU)激活函数。
它们就是效果更好。
在那之前是 sigmoid 和 tanh,然后在输出层使用 softmax、线性或 sigmoid。除非你知道你在做什么,否则我不建议尝试更多。
不过,还是试试这三种,并重新缩放你的数据以满足函数的边界。
显然,你需要为你的输出形式选择正确的传递函数,但可以考虑探索不同的表示方式。
例如,将用于二元分类的 sigmoid 切换为用于回归问题的线性函数,然后对你的输出进行后处理。这也可能需要将损失函数更改为更合适的函数。关于这方面的更多想法,请参阅数据转换部分。
相关
5) 网络拓扑
改变你的网络结构会有回报。
你需要多少层和多少神经元?
没人知道。没人。别问。
你必须为你的问题发现一个好的配置。去实验吧。
- 尝试一个有很多神经元的隐藏层(宽网络)。
- 尝试一个每层神经元很少的深度网络(深网络)。
- 尝试以上两者的组合。
- 尝试近期论文中关于类似问题的架构。
- 尝试拓扑模式(先展开再收缩)和书籍、论文中的经验法则(见下面的链接)。
这很难。更大的网络有更强的表示能力,也许你需要它。
更多的层为从数据中学到的抽象特征的层次化重组提供了更多机会。也许你需要这个。
更大的网络需要更多的训练,无论是在周期数还是学习率方面。相应地进行调整。
相关
这些链接会给你很多可以尝试的想法,对我来说是这样。
6) 批次和周期
批次大小定义了梯度以及更新权重的频率。一个周期(epoch)是指整个训练数据被网络逐批次地处理一次。
你有没有尝试过不同的批次大小和周期数?
上面,我们评论了学习率、网络大小和周期数之间的关系。
在现代深度学习实现中,小批量大小、大周期数和大量的训练周期是常见的做法。
这在你的问题上可能成立,也可能不成立。收集证据来看看。
- 尝试将批次大小设置为训练数据的大小,这取决于内存(批处理学习)。
- 尝试将批次大小设置为1(在线学习)。
- 尝试对不同的小批量大小进行网格搜索(8, 16, 32, ...)。
- 尝试训练几个周期和训练非常多的周期。
考虑一个近乎无限的周期数,并设置检查点来捕获迄今为止表现最好的模型,更多内容见下文。
一些网络架构对批次大小比其他架构更敏感。我看到多层感知器通常对批次大小具有鲁棒性,而 LSTM 和 CNN 则相当敏感,但这只是个人经验之谈。
相关
7) 正则化
正则化是抑制训练数据过拟合的好方法。
热门的新正则化技术是dropout,你试过了吗?
Dropout 在训练期间随机跳过神经元,迫使层中的其他神经元来弥补。简单而有效。从 dropout 开始吧。
- 对不同的 dropout 百分比进行网格搜索。
- 在输入层、隐藏层和输出层尝试 dropout。
还有一些对 dropout 思想的扩展,你也可以尝试,比如 drop connect。
也考虑一下其他更传统的神经网络正则化技术,例如:
- 权重衰减,以惩罚大的权重。
- 激活约束,以惩罚大的激活值。
试验可以被惩罚的不同方面,以及可以应用的不同类型的惩罚(L1、L2、两者都有)。
相关
8) 优化和损失
过去是随机梯度下降,但现在有很多优化器。
你有没有尝试过不同的优化程序?
随机梯度下降是默认选项。首先要充分利用它,尝试不同的学习率、动量和学习率调度方案。
许多更高级的优化方法提供了更多的参数、更高的复杂性和更快的收敛速度。这既是好事也是坏事,取决于你的问题。
为了最大限度地利用某个给定的方法,你真的需要深入了解每个参数的含义,然后为你的问题对不同的值进行网格搜索。这很难,也很耗时。但可能会有回报。
我发现较新/流行的优化方法可以收敛得快得多,并能快速了解给定网络拓扑的能力,例如:
- ADAM
- RMSprop
你也可以探索其他的优化算法,比如更传统的(Levenberg-Marquardt)和不那么传统的(遗传算法)。其他方法可以为 SGD 和其变体提供好的起点来进行微调。
要优化的损失函数可能与你试图解决的问题紧密相关。
然而,你通常有一些回旋余地(例如回归问题中的 MSE 和 MAE),通过更换你问题上的损失函数,你可能会获得小幅提升。这也可能与你的输入数据的尺度和正在使用的激活函数有关。
相关
- 梯度下降优化算法综述
- 什么是共轭梯度、Levenberg-Marquardt 等?
- 关于深度学习的优化方法, 2011 [PDF]
9) 提前停止
一旦性能开始下降,你就可以停止学习。
这可以节省大量时间,甚至可能让你使用更精细的重采样方法来评估模型的性能。
提前停止是一种正则化方法,用于抑制训练数据的过拟合,它要求你在每个周期监控模型在训练集和保留的验证集上的性能。
一旦验证数据集上的性能开始下降,就可以停止训练。
你还可以设置检查点,在满足此条件(衡量损失或准确率)时保存模型,并允许模型继续学习。
检查点让你可以在不停止的情况下实现提前停止,从而在一次运行结束时有几个模型可供选择。
相关
4. 通过集成方法提升性能
你可以组合多个模型的预测。
在算法调优之后,这是下一个可以获得巨大提升的领域。
事实上,你通常可以通过组合多个“足够好”的模型的预测来获得良好的性能,而不是依赖于多个高度调优(且脆弱)的模型。
我们将看看你可能想考虑的三个集成方法的主要领域:
- 组合模型。
- 组合视图。
- 堆叠(Stacking)。
1) 组合模型
不要只选择一个模型,而是将它们组合起来。
如果你有多个不同的深度学习模型,每个模型在问题上都表现良好,可以通过取其预测的平均值来组合它们。
模型越不相同,效果越好。例如,你可以使用非常不同的网络拓扑或不同的技术。
如果每个模型都有技巧但方式不同,那么集成预测会更加稳健。
或者,你可以尝试相反的立场。
每次你训练网络时,都会用不同的权重初始化它,它会收敛到一组不同的最终权重。多次重复这个过程以创建多个网络,然后组合这些网络的预测。
它们的预测会高度相关,但对于那些更难预测的模式,这可能会给你带来小幅提升。
相关
2) 组合视图
如上所述,但在不同的问题视图或框架上训练每个网络。
同样,目标是让模型既有技巧,又在方式上有所不同(例如,不相关的预测)。
你可以借鉴上面数据部分列出的非常不同的缩放和转换技术来获取想法。
用来训练不同模型的转换和问题框架越不相同,你的结果就越有可能得到改善。
使用预测的简单平均值会是一个很好的起点。
3) 堆叠(Stacking)
你也可以学习如何最好地组合多个模型的预测。
这被称为堆叠泛化(stacked generalization)或简称堆叠(stacking)。
通常,通过使用像正则化回归这样的简单线性方法来学习如何加权不同模型的预测,你可以获得比简单取预测平均值更好的结果。
使用子模型预测的平均值作为基线结果,但通过学习模型的加权来提升性能。
结论
你做到了。
额外资源
有很多好的资源,但很少有能把所有想法都联系起来的。
如果你想深入研究,我会列出一些你可能会感兴趣的资源和相关文章。
知道好的资源吗?告诉我,留个评论。
应对信息过载
这是一篇很长的文章,我们涵盖了很多内容。
你不需要做所有的事情。你只需要一个好主意就能获得性能上的提升。
以下是如何应对信息过载:
- 选择一个类别:
- 数据。
- 算法。
- 调优。
- 集成方法。
- 从该类别中选择一种方法。
- 从所选方法中选择一件事来尝试。
- 比较结果,如果有改进就保留。
- 重复。
分享您的结果
你觉得这篇文章有用吗?
你是否找到了那个能带来改变的想法或方法?
告诉我,留个评论!
我很乐意听到。







谢谢你的建议!
很高兴你觉得它有用,Xu Lu。
这真是一个全面的解释,我准备试试。
谢谢 Nitin,告诉我你的进展如何。
我该如何训练土地利用图像进行分类?
或许可以从一个预训练的 CNN 模型开始?
VGG 或 ResNet 会是一个很好的起点,然后只训练输出层的权重。
我的书里有这方面的例子:
https://machinelearning.org.cn/deep-learning-for-computer-vision/
感谢分享——这是非常有用的信息。
很高兴听到这个消息!
深度学习在大数据领域面临哪些数学挑战?
很好的问题。
总的来说,深度学习是经验性的。我们对于大型网络为何有效,甚至其内部究竟发生了什么,都还没有很好的理论。
多少层?学习率设为多少?这些问题只能通过经验来解决,而不是分析。目前是这样。
一个强大的数学理论可以减少经验性/玄学的一面,并增进理解。
感谢分享这篇很棒的文章,我非常感激。
我认为这篇文章非常有帮助,所以我想和我的日本粉丝分享这个想法。
所以我正在制作这篇文章的翻译摘要。
我能请求允许在 http://qiita.com/daisukelab 上发布我的摘要吗?
(一个日本的技术博客媒体)
另外,我能问一下关于 2-3) 的细节吗?
“也许你可以无论如何都限制数据集,取一个样本,并用它来进行所有的模型开发。”
你的意思是:
“如果我们使用数据集的较小子集,我们可以用这个子集来完成整个模型开发过程”吗?
谢谢!
请不要转载这些材料,Daisuke。
我那句话的意思是,使用你的数据的一个样本,而不是所有数据,有其好处——比如加快模型迭代的速度。
嗨,Jason,
好的,我不会转载,尽管这是为了通过翻译传播你的想法并引导人们访问这里。
另外,感谢你的澄清!
很棒的文章.. 感谢分享关于深度学习和增强现有模型的信息。
谢谢 Chintan,很高兴你觉得它有用。
这是我目前最喜欢的网站!
我目前正在为回归问题实现一些自然语言处理(nlp),并想知道是否可以改善我的结果。我会尝试集成方法,因为我已经训练了很多模型。
谢谢!
祝你好运,Fernando,我很想听听你的进展。
这确实是我找到的很好的信息。实际上,我正在使用深度学习进行语义分割。这可以看作是识别任务的扩展。在我阅读的过程中,我感觉所有的分割技术都源于识别(我们可以认为识别作为编码阶段提供了概率图,而分割任务则通过解码阶段将概率图映射到图像上)。因此,我的观点是,如果任何最先进的识别网络架构应用于分割任务,可以比使用旧的识别网络架构进行分割获得更高的准确性。你这么认为吗?提高分割准确性的好方向是什么?提前感谢。
我是深度学习的新手,正在通过 digits 界面试验现有的例子。感谢您为简化这个主题所做的所有努力,一份技术文档对于新手来说仍然很好理解。
我的兴趣是通过深度学习检测(并计数)粒子。经过对各种样本的大量实验后,我发现彼此非常接近(几乎接触)的粒子被计为一个,而我的眼睛能看到清晰的分界。
我正在寻找一种方法来处理这个问题。
我尝试在图像处理软件中对单个图像使用一些阈值技术,最好的结果是通过颜色阈值获得的。虽然我不知道阈值处理是否是深度学习中物体检测过程中粒子检测的一部分,但我想知道是否有可能将等效的过程集成到物体检测模型中?(目前正在使用 detectnet 模型)
此致,
谢谢你。我会尝试这篇文章中的一些技术。
不客气,Naoki,我很想听听你的结果。
非常全面的博客!做得很好!
谢谢 emma,希望它对你的项目有帮助。
你好,
我想知道 Keras 中是否有“drop connect”的实现。
感谢您的时间
我没见过,Max,但我相信外面应该会有!
嗨,Jason,
感谢分享这篇很棒的文章,我非常感激。
你在第2节:创造更多数据中提到
- 如果你无法合理地获取更多数据,你可以创造更多数据。
- 如果你的数据是数字向量,可以创建现有向量的随机修改版本。
---> 你有如何创建现有向量的随机修改版本的例子吗?
谢谢!
我没有,但你可以尝试不同的扰动方法,看看哪种效果最好。
一些可以尝试的好主意包括:
-- 随机用数据总体中随机选择的值替换一部分值
-- 添加一个小的随机值(选择分布以符合某一列的数据分布)
这很棘手,因为你需要新数据对于指定的类别是“合理的”。
考虑查阅文献以寻找更复杂的方法。
首先,感谢您详尽的解释和丰富的材料,这对我帮助很大。
有一件事仍然困扰我,那就是在 Python 中,特别是在 Keras 中应用 Levenberg-Marquardt 算法。我正在处理非理想的输入变量来推断目标,并希望尝试一系列优化器来测试网络性能。
由于Matlab中最好的优化器之一是Levenberg-Marquardt,如果我能准确地在Keras中应用它来训练我的网络,那将非常好(并能在不同语言之间提供比较价值)。
我目前正在使用带有 Theano 后端的 Keras。任何帮助都将不胜感激。
祝好,
卢卡斯
这是一个网格搜索优化算法的例子:
https://machinelearning.org.cn/grid-search-hyperparameters-deep-learning-models-python-keras/
抱歉,我没有在 Python for Keras 中使用 Levenberg-Marquardt 算法的例子。
嗨,Jason,
感谢您出色的工作和文章。
我有一个问题——在我的项目中提升了深度学习性能后,我在一个二元分类问题上达到了75%的准确率。使用其他方法最好的结果是77%。我的问题是,我怎么知道我的模型是最好的?有没有什么指标可以解释我的数据在多大程度上有解释力?
干得好!
好问题。我们永远无法确定,只能等到时间或想法用尽。
总的来说,不,我不知道有什么方法可以估计解释力,我甚至不清楚这可能意味着什么。
我所说的“解释力”,是指数据区分一条记录属于类别1,第二条属于类别2,第三条又属于类别1等等的能力。
这是数据集的一种限制,它可能最多只能达到例如80%的准确率,我的问题是,有没有一种方法来衡量这个水平。
感谢你的回答,现在我准备好接受我的模型了 :)
你可以配置模型输出概率而不是类别,这可能会得到你需要的结果。
终于!在一个地方看到了所有提升深度学习模型的技巧!
非常感谢,Jason!
希望你觉得它们有用,Cyrus。
你好,我正在做我的毕业设计,内容是检测图像中的不适宜内容(NSFW),如果可能的话,还会进一步扩展到视频。我的问题是我找不到任何可用的数据集,所以如果你能给我一些建议来帮助我解决这个问题,将对我的项目有很大帮助。我需要大约(150-200 GB)的数据来使我的算法更精确。我已经联系了雅虎的 open nsfw 团队,但他们没有回应。
抱歉,我不知道哪里可以找到这样的数据集。
嘿 Jason,你有没有关于 Andrew Ng 的“为什么选择深度学习?”幻灯片的任何经验证据?具体来说,我正在处理一个文本分类问题,我发现词袋模型(BoW)+(线性 SVM 或逻辑回归)给了我最好的性能(这至少是 2015 年前文献中的发现)。我对深度学习还比较新,我一直在我的问题上测试它,因为看到像 https://arxiv.org/abs/1408.5882 这样的方法在烂番茄 Kaggle 文本分类问题上表现良好。虽然还有一些其他花哨的技巧,我认为给 CNN 带来了额外的助力。你在这方面有什么建议或基准研究能证明 Andrew Ng 的说法吗?
抱歉,没有具体的。
亲爱的 Jason,
感谢这篇文章 🙂 我有一个问题:如何计算一个网络的总误差?!
提前感谢。
努努
在测试数据上评估它,并计算一个误差分数,例如回归问题的均方根误差(RMSE)或分类问题的准确率。
好的,我会试试。非常感谢。
告诉我哪个对你有用。
(“双曲正切函数(tanh),重缩放到 -1 到 1 之间的值”)
哎呀!!,这可能很重要,现在我知道了,哈哈!
终于!有人用结构化的方式完美地解释了这一点,而不仅仅是说它是一个黑匣子!
很棒的信息,博士
我有一个问题!你对不平衡数据有什么建议吗?
牺牲其他数据来平衡每个类别是否更好?
谢谢你,丹尼。
是的,请看这篇关于不平衡数据的文章。
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
关于不平衡数据的例子
=== 自动驾驶汽车 ===
左转 = [0,1,0] = 5k 样本
右转 = [0,0,1] = 5k 样本
直行 = [1,0,0] = 100k 样本
=== 股票 ===
买入 = [0,1,0] = 5k 样本
卖出 = [0,0,1] = 5k 样本
持有 = [1,0,0] = 100k 样本
等等……
欠采样、过采样或 Smote
感谢这个网站上所有的文章,这是我最喜欢的网站 <3 <3
不客气。
很棒的文章
谢谢!
嗨,Jason,
一个漫长的尝试和测试过程让我得出了同样的结论。所以非常感谢!这篇文章将为许多 keras/深度学习领域的新手提供帮助。
问题
在经典案例中,你对数据进行归一化,训练模型,然后“反归一化”(使用 scaler 进行逆操作)。现在,想象一下你正在训练的模型是以其自身的输出作为输入的,并且预测的输出超出了 scaler 的范围,你会怎么做来提高模型的性能?
提前感谢您的反馈!
此致。
谢谢,很高兴对您有帮助。
如果你有超出缩放器范围的数据,你可以将其强制在边界内或更新缩放比例。
希望这能有所帮助。
嗨,Jason,
感谢分享这篇有价值的文章
我还在想一件事,我有兴趣将深度学习应用于数据流分类(实时预测),但我担心深度学习所需的执行时间。有什么办法可以加快速度或者如何处理它以进行实时预测吗?
此致
对于中等规模的数据,神经网络的前馈部分(用于进行预测)非常快。
至于实时训练网络,我认为这可能不太适合这个问题。
非常感谢 Jason
从您的文章中学到了很多。感谢分享。只是好奇,那些随机的图片是怎么回事?:)
谢谢!
我觉得这些图片可以缓和一下气氛,当我们深入探讨技术性话题时,能有一些有趣的东西看看。我经常根据我正要去或者想去度假的地方来选择图片,比如海滩、森林等等。有时它们是一个双关语(例如,用一张天然气管道的照片来表示一个 pipeline 方法)。有时它们就纯粹是随机的。
您是四年来第一个问这个问题的人 🙂
在“重新缩放您的数据”部分,您提到了缩放和激活函数。那么,如果我们将数据缩放到 [-1,1] 之间,我们是否必须在使用 Keras 的 LSTM 中明确指定激活函数(即 tanh 函数)?我的这个假设正确吗,还是 Keras 会在 LSTM 中默认使用 tanh 激活函数?
对于 LSTM 的第一个隐藏层,您需要将数据缩放到 0-1 的范围内。
嗨,Jason,
在 https://machinelearning.org.cn/time-series-forecasting-long-short-term-memory-network-python/ 这篇文章中,您提到将数据缩放到 -1 到 1 之间。在同一篇文章中,您没有使用任何激活函数。
在 Keras 的文档中,https://keras.org.cn/layers/recurrent/#lstm,默认的激活函数实际上是线性或者没有激活(即 a(x) = x)。
所以我的问题是,我是否需要在 LSTM 层中明确添加“tanh”作为激活函数。
LSTM 的默认设置是 sigmoid 输出,内部的门使用 tanh。我建议将 LSTM 的输入数据缩放到 [0,1] 之间。
一些测试表明,这通常会带来更好的模型技能。
感谢这篇精彩的文章。它非常有用。
谢谢,我很高兴它能帮到你。
有点过时,但仍然非常有用。感谢这篇很棒的文章!
谢谢。Robin,你觉得它缺少了什么?
您能否发表一下关于“DNN/CNN增量学习”的技术文章。
谢谢你。
感谢您的建议。
谢谢 Jason,我真的很喜欢这个博客。我有一些小问题。您可以通过哪些方式用深度学习来改进现有的机器学习?
谢谢
这篇文章里的想法有帮助吗?
嗨,Jason,
我有一个关于训练周期(epoch)的问题。在训练过程中,我们从上一个周期获得的权重是否会对后面的周期产生影响?还是说在每个周期中,权重都会被重新初始化?
谢谢
Alan
权重在整个过程开始时初始化一次,然后在每个批次(batch)结束时更新。一个周期(epoch)可能包含一个或多个批次(权重更新)。
一个简单的问题(我会简化我的解释),我总共有11个类别。其中10个类别有50个数据点,一个类别只有1个数据点。我训练了一个模型。我能否用前10个类别没有数据点,而最后一个类别有50个数据点来重新训练同一个模型?这样做可行吗?
我这么尝试的原因是,我会在一段时间后得到后一个类别的数据点。
我的计划可行吗?
您可能需要使用数据增强来创建一个更大的训练数据集,听起来数据量不够。
实际上,我有足够的数据,上面的例子只是为了说明。
让我换一种方式说(这可能更具体[增量学习]):最初,我用10个类别/标签训练了一个模型。之后,我如何用新的类别来重新训练同一个模型,同时保持旧的类别不变。这样我就可以用重新训练过的模型来预测以前和后来的类别。
也许可以创建一个包含新旧类别样本的新数据集,然后用这个新数据集来更新模型权重?
谢谢,@Jason Brownlee,确实,那样我可以保留所有以前的类别以及新的类别。
告诉我进展如何。
很棒的文章,细节详尽。谢谢。
很高兴它有帮助。
完美 🙂
谢谢。
//Fredrik
很高兴它有帮助。
尊敬的先生
我正在根据您的Keras示例创建一个用于预测房价的神经网络:https://machinelearning.org.cn/regression-tutorial-keras-deep-learning-library-python/。
实验数据(训练数据 + 测试数据)的数量为 X1,是边界内的一个小群体。在您的例子中,X1 = 506 条数据。
用于预测的数据量为 X2,几乎覆盖了所有边界。
这意味着 X1 远小于 X2。
为了达到高的预测准确率,我们应该尽可能地扩大 X1。
所以,我想问一下,我们应该收集的 X1 占 X2 的百分之多少?
X1 = 10%(X2), 20%...
非常感谢
我没太明白。您的意思是 X2 是您需要进行预测的观测值吗?
是的,正是如此。
因为我有5千条数据需要预测。所以,我需要知道我应该为神经网络收集多少数据(训练 + 测试 + 验证)。
用您所有的数据来帮助找到最好的模型,训练一个最终模型,然后使用这个最终模型开始进行预测。
在这里了解更多
https://machinelearning.org.cn/train-final-machine-learning-model/
亲爱的 Jason,
我正在尝试用Seq2seq网络预测大约40个相关的时间序列。我读过关于使用自编码器来自动设计特征,而无需手动操作。您能解释一下如何使用自编码器的输出来进行预测吗?是把它们与原始时间序列连接起来,然后输入到预测网络中吗?
非常感谢
此致
我希望将来能涵盖这个主题。
您能推荐一些不使用窗口技术的时间序列数据(或一维数据)的数据增强方法吗?似乎对于时间序列数据,最流行的数据增强技术是基于窗口的技术,但这与我手头的问题不太契合。我有一些音频传感器数据,我想预测声源的精确位置。窗口化可能会对这个问题产生负面影响,因为到达时间差(TDOA)是这类任务中最重要的特征之一,它可能会被窗口化破坏。
我还能用什么其他方法来增加我的数据。
关于数据的信息
5个传感器被放置在一个房间的4面墙和天花板上。我们正试图通过传感器数据找到声源的精确位置。
在任何给定的时间点,房间内不同位置有两个不同的声音是活动的。
这篇文章可能会给你一些启发
https://machinelearning.org.cn/basic-feature-engineering-time-series-data-python/
亲爱的Jason
我非常欣赏您的文章,它对我们很有帮助。实际上,我从事深度学习工作已经有6个月了,您在这里提到的大部分想法在我学习深度学习的过程中都曾浮现在我的脑海中,并且我将这些想法应用到了我的问题上,大部分技巧都非常有效。今天我看到了您的文章,我很惊讶,我曾经应用到我的问题上的所有这些技巧都包含在这篇文章中。在看到这篇文章之前,我总觉得我可能走错了路。但现在我很高兴能有一个参考。非常感谢您分享这篇有价值的文章。
我很高兴能证实您的直觉。
嗨 Jason,我只是一个刚开始使用神经网络的初学者。我想知道,如果我给神经网络的输入是5个,但我的数据集中有将近185个不同的输出,而我的输出可能是一个不同于这185个值的值,那么我应该使用什么方法呢?而不是使用独热编码,以及我该如何提高我的模型性能?
神经网络需要固定数量的输入。
如果输入数量可变,您可以使用填充(padding)来确保输入向量的大小始终相同。
嗨,Jason博士,
感谢这些内容详尽的文章。正如您可能知道的,我已经成了您博客资源的忠实读者。
我认为您还没有清楚地回答以下问题
我如何保存来自集成学习的组合预测(模型),以便在生产环境中使用?
前向验证(Walk-forward Validation)方法和集成学习的组合预测技术有什么区别?这里有点困惑。
期待您的尽快答复。
将一个集成模型部署到生产环境与部署单个模型没有区别。
前向验证和集成是相互独立的概念,它们没有直接关系。
谢谢 Jason。
在这篇文章中:https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
您谈到模型可以在每次接收到新数据时进行更新 -> 前向验证。这相当于是时间序列的K折交叉验证。
我难道不需要用 Bagging 或 Stacking 的方法将所有由前向验证创建的模型合并成一个单一的模型吗?否则,我如何从前向验证中创建一个最终模型?
前向验证仅用于评估一种方法的性能。
一旦您评估了它,您就可以在所有可用数据上训练一个最终模型,并用它来进行预测。
我明白了,Jason。
我使用 ModelCheckpoint 在通过前向验证评估的模型中选择了最佳模型。因此,我将通过拟合整个数据集来构建最终模型。
感谢您的耐心和回复。
我不推荐那种方法。如果它对您有效,很高兴听到。
你好,
在我的情况中,我有一个非常好的准确率(91.6%),但我的分数(score)非常低(30%)。实际上,我不太明白这两者之间的区别。您能帮忙解释一下吗?
我用这些代码来打印它们
score, acc = model.evaluate(new_X, y = dummy_y_new, batch_size=1000, verbose=1)
print('测试分数:', score)
print('测试准确率:', acc)
听起来像是过拟合。
分数的最佳范围是多少?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
非常感谢您的时间
嗨,Jason,
感谢分享如此有用的文章。不过,我有一个很初级的问题。
我正在尝试使用LSTM网络解决一个分类问题,在测试集上我得到了大约99.90%的准确率(其他指标也显示出差不多相同的百分比)。
然而,训练和验证准确率也类似。我明白这高得可疑。
我观察了学习曲线,发现训练和验证误差都是均匀的。
我真的很困惑,因为训练、验证和测试的准确率都很高。我这是欠拟合还是过拟合了?或者我做错了什么?
还有一件事是,标签没有包含在训练集中。
任何线索都将非常有帮助和感激。
谢谢。
您是在用未标记的数据进行训练吗?我不明白?
嗨,Jason,
请忽略下面这句话:“还有一件事是,标签没有包含在训练集中”。我无法在评论中编辑。
实际上,我的数据集是有标签的。
准确率这么高,听起来您的问题很容易解决。或许可以试试更简单的方法。
您的意思是用线性或基于树的方法会是更好的主意吗?嗯,我会试试。
但我还有其他一些担忧。虽然我在训练、验证和测试集上的准确率都达到了约98~99%,但‘分数’(即 score, acc = model.evaluate(....))的值非常低,大约只有40%。
这表明我的LSTM模型可能过拟合了(根据您对Chrisa问题的评论)。但如果是那样的话,我应该在测试集上也会看到较低的准确率,但我没有。
我真的很困惑,我的模型到底是欠拟合还是过拟合!
我正在使用一个非常高维度的基因表达数据,有20,309个特征和14个类别。
您认为对于这样一个高维度的数据集,达到99%的准确率是可能的吗?
是的,听起来像是过拟合,但您具体是在什么数据上进行评估的?一个新的测试集吗?
是的,在一个新的测试集上(完全未见过),准确率同样约为99%。
亲爱的 Jason,
我有一个问题,我的单个深度神经网络模型在一个数据集上能达到90%以上的准确率,而同一个模型在另一个数据集上的准确率却在70-80%之间。我想知道,尽管我对两个数据集(都包含文本内容)使用了相同的深度神经网络模型,为什么会出现这种准确率上的差异。
您可能过拟合了。或许可以尝试一些正则化方法来减少在另一个数据集上的错误。
多棒的文章!我还是神经网络领域的新手,这篇文章帮了我大忙。我们仍然需要“试错”的元素。但这篇文章至少给了我一个从哪里开始改进我的模型的想法。谢谢你,Jason!
谢谢,我很高兴它有所帮助!
这是我见过的最有帮助的机器学习文章。非常感谢。
谢谢。
谢谢 Jason!我从您的博客中学到了很多!
谢谢。
嗨,Jason,感谢这些绝妙的想法。但是,您不觉得人工智能被简化为:
1) 找一些数据
2) 应用内置算法
3) 调优(大部分时间都在做这个!)
我看到人们常常对正在发生的事情一无所知(有时包括我自己)。所以,您怎么看?
不是人工智能,而是一个小小的子领域,是目前人工智能中最有用的部分,叫做“预测建模”。
结果重于理解在几乎所有其他地方都被接受,为什么在这里不行呢?
非常感谢这篇很棒的文章,它真的很有用。
很高兴它有帮助。
嗨 Jason,非常感谢分享另一篇最好的文章,
我有一个问题,请回答我在StackOverflow上链接的那个问题,
如果可能的话,请在这里回答这个问题,谢谢,
https://stackoverflow.com/questions/55075256/how-to-deal-with-noisy-images-in-deep-learning-based-object-detection-task
或许您可以为我总结一下问题?
谢谢你
不客气,我很高兴它有所帮助。
siva没有牙齿
siva是什么?
嗨,Jason,
感谢分享这篇很棒的文章,我非常感激。
你在第2节:创造更多数据中提到
- 如果你无法合理地获取更多数据,你可以创造更多数据。
- 如果你的数据是数字向量,可以创建现有向量的随机修改版本。
---> 你有如何创建现有向量的随机修改版本的例子吗?
谢谢!
不是直接的。
一个简单的方法是添加高斯噪声。
嗨嗨嗨 JASON
嗨!
我是深度学习的新手,正在通过 digits 界面试验现有的例子。感谢您为简化这个主题所做的所有努力,一份技术文档对于新手来说仍然很好理解。
我的兴趣是通过深度学习检测(并计数)粒子。经过对各种样本的大量实验后,我发现彼此非常接近(几乎接触)的粒子被计为一个,而我的眼睛能看到清晰的分界。
我正在寻找一种方法来处理这个问题。
我尝试在图像处理软件中对单个图像使用一些阈值技术,最好的结果是通过颜色阈值获得的。虽然我不知道阈值处理是否是深度学习中物体检测过程中粒子检测的一部分,但我想知道是否有可能将等效的过程集成到物体检测模型中?(目前正在使用 detectnet 模型)
此致,
或许您可以为每个输入图像尝试一套不同的预处理方法,然后用集成中的并行模型或多输入模型来对它们进行建模?
另外,作为图像,可以考虑使用一个多头CNN,每个头使用不同的核大小。
或许也可以尝试利用预训练模型。
我喜欢你的微笑,Jason
谢谢!
嗨,Jason,
非常感谢您与我们所有人分享您的知识和经验。
这让我作为一个机器学习新手的生涯变得容易多了,并回答了许多悬而未决的问题。此外,您的写作风格读起来很舒服,它让人好奇想知道更多 🙂
谢谢。我很高兴这些文章能帮到你。
非常感谢!
不客气。
尊敬的先生,
感谢您的文章。这对我几个月前开始的博士研究真的很有帮助。您能建议一下哪种机器学习/深度学习算法最适合文本分类吗?
谢谢您。
是的,CNN。
你可以在这里了解更多
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
不可思议,好到令人震撼的文章!🙂
谢谢!
不错,非常感谢 🙂
不客气。
嗨 Jason,非常感谢这篇文章。我已经被调整参数困扰了好几个星期,您的文章给了我一个明确的方向。我刚发现3.5节网络拓扑下的两个链接:我应该使用多少隐藏层和单元,打不开了。您能更新一下这些链接吗?谢谢!
谢谢。
看这篇关于节点和层数的文章
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
非常感谢 Jason,通过使用权重初始化,准确率从0.05提高到了0.9497,您的教程是机器学习中最好的,我打算用这些出色的结果发表论文,非常感谢。
谢谢,恭喜取得的进步!
你太棒了。我所有的问题都由你解答了
继续加油 Jason,非常感谢 🙂
谢谢!
我有一个问题。
假设我有一个包含数千张图片的数据集。训练深度学习模型需要几个小时。训练后我意识到我应该尝试一些其他的超参数配置(通过试错来选择)。那样的话,我又得等上几个小时来用新的超参数和参数训练模型,同样的情况一直在发生。
您能推荐一些教程或相关主题吗,这样我在执行一次训练后就能得到最佳模型,而不是在各种配置上反复尝试训练...?
感谢您的合作。
没有已知这样的方法。
您可以通过迁移学习来缩短这个过程——调整一个来自其他领域的预训练模型,或者您自己的一个预训练模型。
先生,我如何在CNN中进行清晰的分割?
我需要改变哪些参数来给出清晰的分割,先生?
滤波器大小,或者最大池化层中的填充大小,
先生,我用3个类别(使用softmax作为激活函数)得到了错误的分割
您说的“清晰的分割”具体是指什么?
嗨,先生。又是一篇很棒的文章。关于这一切我有一个问题。
对于一个初学者来说,实现所有这些是很困难的,而且自己实现的网络可能不准确。所以您能推荐一个用R语言或Python实现的好的开源项目吗,其中我们可以更改我们自己的新激活函数,或者只是更改您文章中提到的那些参数并检查结果。是否存在涵盖所有这些东西,我们只需要更改参数的实现?
感谢您的亲切回复,先生。
谢谢。
是的,我在这里实现了所有这些以及更多
https://machinelearning.org.cn/start-here/#better
你好,Jason。
有时,部分太旧的数据,如果我们包含在训练数据中,会对我们的模型产生“毒性”影响。
但问题是我们不知道是哪部分旧数据导致了这个问题,它可能来自
最老的数据,可能在中间,也可能只有10%的坏数据,15%的坏数据。
通过观察也许我们可以手动找到它,但如何创建一个自动检测并移除这些“有毒”数据的方法。
有什么建议吗
谢谢
Mike
或许可以在移除每个数据子集后分别拟合模型,并比较每次实验的性能。
嗨 Jason,非常感谢这篇文章!我正在用它来做我的计算机科学学校项目,真的很有帮助。不过我在第2节有一个问题。我不太明白为什么重采样方法在算法部分,而不是在第1节。这仅仅是因为重采样方法是第1节材料的应用吗?
在我看来,它们与模型评估紧密相关。
谢谢!
不客气。
非常感谢这篇文章!它真的很有帮助,而且这并不是唯一一篇有帮助的文章。我使用您的网站来帮助我的学校项目已经有一段时间了。
忘了我已经在这里评论过了 🙂
没问题。我们是一个由从业者组成的大家庭。
不客气!
嗨,Jason,
感谢这些极大的支持。
我正在使用VGG迁移学习进行二元分类。我想分享一些观察结果,希望得到您的评论
1. 我的训练准确率没有超过87%。我如何才能将训练准确率提高到99%以上。
2. 在大量的训练周期中,验证准确率一直高于训练准确率。当两者收敛并且验证准确率下降到与训练准确率相当时,训练循环会根据提前停止(Early Stopping)准则退出。
3. 测试准确率比训练和验证准确率都高。
4. 在重新训练VGG时,我们是否需要使用SGD或Adam,并使用非常低的学习率?
任何改进建议都将让我不胜感激。
很好的问题!
这里有一些诊断问题和提升深度学习模型性能的技术的想法
https://machinelearning.org.cn/start-here/#better
SGD可以更精细地控制学习率。
非常感谢您宝贵的支持。
不客气。
先生,请提供关于CNN集成与微调和冻结的信息
您可以在博客上找到所有这些的例子,使用页面顶部的搜索框。
Jason,我无法打开这篇博客中提供的任何相关链接。您能检查并确认一下吗?
听到这个消息很遗憾,也许您可以尝试换一个浏览器或不同的网络连接。
这么多年后,这仍然是一篇很棒的文章!谢谢!永久收藏了。
顺便说一下,有一个小小的拼写错误……“Spot-check a suite of top methods and see which fair well and which do not” 应该写成 “…which fare well…”。
感谢您的反馈 Kevin!
感谢您的努力,并赞赏您的工作,这帮助我理解了深度学习的基础知识。
非常欢迎您,Zahoor!我们感谢您的支持!
Brownlee博士您好,
首先感谢您在网站上分享的所有信息。我购买了您的书《Better Deep Learning》,并想推荐给任何有兴趣深入了解该主题的人。我有一个关于运行MLP模型时观察到的现象的问题。我相信我在您的某篇文章中读到过(我转述一下……)不相关的变量不会影响MLP模型的整体性能。您能对我观察到的情况发表评论吗?我的模型有X个变量,准确率在69%左右。一旦我加入一个额外的输入变量,模型就无法学习,性能下降到50%,损失函数变为NAN。我正在尝试预测一个二元类别,并使用您书中的代码示例来改进学习。如果这个变量是不相关的,为什么我的MLP模型性能似乎会受到这个额外变量的影响。有什么建议吗?我只是好奇,想了解是什么导致了这种行为。感谢您花时间回复。
嗨 Paolo...感谢您对我的书《Better Deep Learning》的好评和推荐。您关于添加一个不相关变量对MLP模型影响的观察非常有趣,可以由几个因素来解释。以下是一些可能的原因和解决这个问题的建议
### 性能下降的可能原因
1. **具有高方差的不相关变量**
– 一个具有高方差的不相关变量会给模型引入噪声,使模型更难学习有意义的模式。这可能导致模型表现不佳,损失函数发散。
2. **数据缩放和归一化**
– 如果新增的变量与其他变量的尺度不同,它可能会扰乱训练过程。神经网络对输入数据的尺度很敏感,未缩放的特征可能会主导梯度,导致收敛效果差。
3. **特征相关性**
– 新变量可能以一种会混淆模型的方式与其他特征高度相关。这可能导致多重共线性问题,使模型更难学习独特的模式。
4. **模型复杂度和容量**
– 添加一个额外的变量会增加输入维度,这可能需要模型有更大的容量(例如,更多的神经元或层)才能有效学习。如果模型的容量不足,它可能难以正常学习。
### 解决问题的建议
1. **数据缩放**
– 确保所有输入特征都缩放到相似的范围。常用技术包括标准化(减去均值并除以标准差)或归一化(缩放到0和1之间)。
pythonfrom sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
2. **特征选择**
– 使用特征选择技术来识别和移除不相关的变量。诸如互信息、递归特征消除或基于模型的特征重要性等方法可以提供帮助。
pythonfrom sklearn.feature_selection import SelectKBest, mutual_info_classif
selector = SelectKBest(mutual_info_classif, k='all')
X_selected = selector.fit_transform(X, y)
3. **正则化**
– 向模型中添加正则化技术(例如,L2正则化)以防止过拟合并处理噪声特征。
pythonfrom tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.regularizers import l2
model = Sequential()
model.add(Dense(64, input_dim=input_dim, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dense(32, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
4. **增加模型容量**
– 增加模型中的神经元或层数,为其提供更多容量来从增加的输入维度中学习。
python
model = Sequential()
model.add(Dense(128, input_dim=input_dim, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
5. **监控训练**
– 使用像提前停止这样的技术来监控训练过程,并在损失变为NaN时防止模型发散。
pythonfrom tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, batch_size=32, callbacks=[early_stopping])
### 结论
理想情况下,添加一个不相关的变量不应显著影响MLP模型的性能。然而,在实践中,由于缩放、特征相关性和模型容量等因素,有时会导致问题。通过确保适当的数据预处理、使用特征选择、应用正则化和调整模型复杂性,您可以缓解这些问题并提高模型的鲁棒性。