Weka 是学习机器学习的理想平台。
它提供了一个图形用户界面,用于在数据集上探索和实验机器学习算法,而无需您担心数学或编程。
在上一篇文章中,我们探讨了如何设计和运行一个在数据集上运行 3 种算法的实验以及如何分析和报告结果。我们还探讨了如何设计和运行一个实验来调整机器学习算法的配置。
在本篇文章中,您将了解如何使用 Weka Experimenter 通过将多个算法的结果组合到集成模型中来改进您的结果。如果您遵循分步说明,您将在不到五分钟的时间内设计和运行一个集成机器学习实验。
通过我新书 《Weka 机器学习精通》 启动您的项目,书中包含分步教程和所有示例的清晰截图。
1. 下载并安装Weka
访问Weka下载页面,找到适合您电脑的版本(Windows、Mac或Linux)。
Weka 需要 Java。您可能已经安装了 Java,如果没有,下载页面上列出了 Weka 的版本(适用于 Windows),其中包含 Java 并会为您安装。我本人使用的是 Mac,就像 Mac 上的一切一样,Weka 即插即用。
如果您对机器学习感兴趣,那么我知道您一定能弄清楚如何下载和安装软件到自己的电脑。
2. 启动Weka
启动Weka。这可能涉及在程序启动器中找到它,或双击 weka.jar 文件。这将启动 Weka GUI 选择器。
Weka GUI 选择器
Weka GUI 选择器让您可以选择 Explorer、Experimenter、KnowledgeExplorer 和 Simple CLI(命令行界面)中的一个。
点击“Experimenter”按钮启动 Weka Experimenter。
Weka Experimenter允许您设计自己的在数据集上运行算法的实验,运行实验并分析结果。它是一个强大的工具。
3. 设计实验
点击“New”按钮创建一个新的实验配置。
测试选项
Experimenter 会为您配置具有合理默认值的测试选项。该实验被配置为使用 10 折交叉验证。这是一个“分类”类型的问题,每种算法 + 数据集组合会运行 10 次(迭代控制)。
电离层数据集
让我们先选择数据集。
- 在“Datasets”选择中,点击“Add new…”按钮。
- 打开“data”目录并选择“ionosphere.arff”数据集。
这个电离层数据集是一个经典的机器学习数据集。该问题是根据雷达信号预测电离层中自由电子结构的出现(或不出现)。它由 16 对实值雷达信号(34 个属性)和一个具有两个值(良好和不良雷达返回)的单一类属性组成。
您可以在 UCI 机器学习存储库的电离层数据集页面上阅读更多关于此问题的信息。
集成方法
J48(C4.8)是一种强大的决策树方法,在电离层数据集上表现良好。在此实验中,我们将研究是否可以通过集成方法来改进 J48 算法的结果。我们将尝试三种流行的集成方法:Boosting、Bagging 和 Blending。
让我们先将 J48 算法添加到实验中,以便与集成版本的算法进行比较。
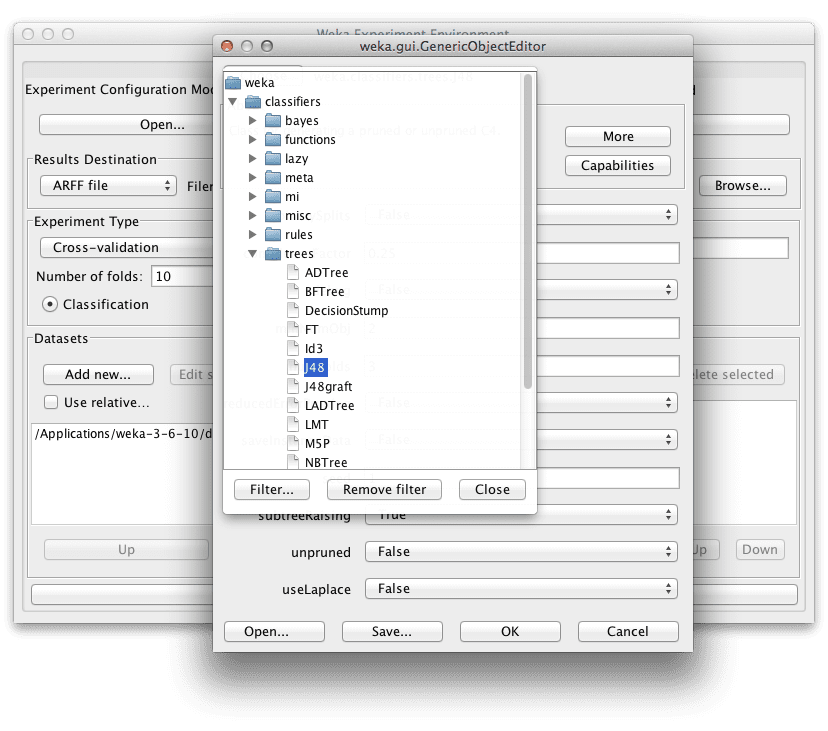
将 J48 算法添加到 Weka Experimenter。
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“tree”选择下点击“J48”。
- 在“AdaBoostM1”配置上点击“OK”按钮。
提升
Boosting 是一种集成方法,它从一个在训练数据上准备好的基础分类器开始。然后在其后面创建一个第二个分类器,以专注于第一个分类器出错的训练数据实例。该过程会继续添加分类器,直到模型数量或准确度达到某个限制。
Weka 中提供的 Boosting 是 AdaBoostM1(自适应增强)算法。
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“meta”选择下点击“AdaBoostM1”。
- 点击“classifier”的“Choose”按钮,在“tree”部分选择“J48”,然后点击“choose”按钮。
- 在“AdaBoostM1”配置上点击“OK”按钮。
Bagging
Bagging(Bootstrap Aggregating)是一种集成方法,它创建训练数据集的独立样本,并为每个样本创建分类器。然后将这些多个分类器的结果组合起来(例如,取平均值或多数投票)。诀窍在于,训练数据集的每个样本都不同,这使得每个训练的分类器在问题上都有微妙不同的重点和视角。
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“meta”选择下点击“Bagging”。
- 点击“classifier”的“Choose”按钮,在“tree”部分选择“J48”,然后点击“choose”按钮。
- 在“Bagging”配置上点击“OK”按钮。
混合
Blending 是一种集成方法,其中在训练数据上准备多个不同的算法,并准备一个元分类器,该元分类器学习如何采用每个分类器的预测,并在看不见的模型上做出准确的预测。
在 Weka 中,Blending 被称为Stacking(得名于 Stacked Generalization 方法)。我们将添加 Stacking,其中包含两个分类器(J48 和 IBk),并使用 Logistic Regression 作为元分类器。
J48 和 IBk(k-最近邻)是截然不同的算法,我们希望在我们的混合模型中包含“好”(可以在问题上做出有意义的预测)和“多样”(对问题有不同的视角,从而做出不同的有用预测)的算法。Logistic Regression 是一种可靠且简单的方法,可以学习如何组合这两种方法的预测,并且由于其本身会产生二元输出,因此非常适合此二元分类问题。
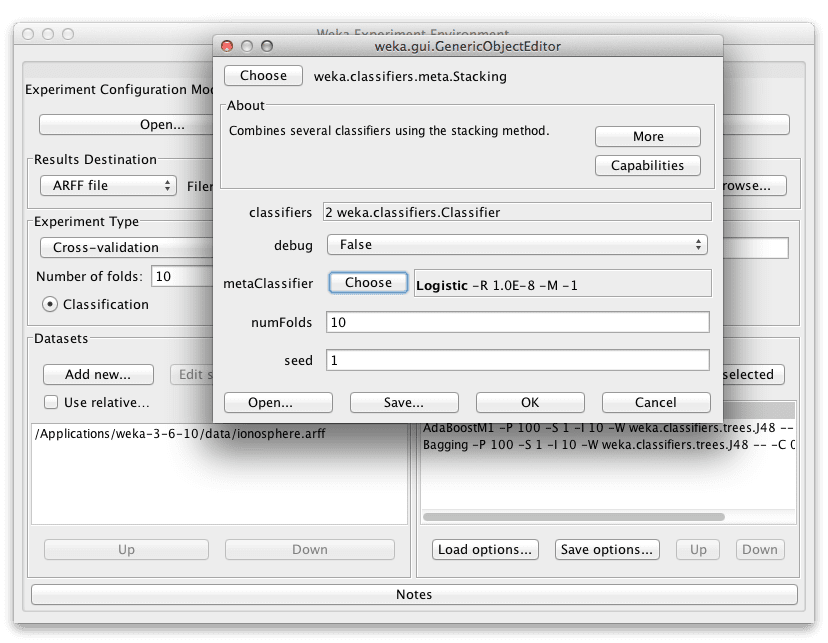
配置并向 Weka Experimenter 添加混合 J48 和 IBk 的 Stacking 算法。
- 在“Algorithms”部分点击“Add new…”。
- 点击“Choose”按钮。
- 在“meta”选择下点击“Stacking”。
- 点击“metaClassifier”的“Choose”按钮,在“function”部分选择“Logistic”,然后点击“choose”按钮。
- 点击“classifiers”的值(算法名称,实际上是一个按钮)。
- 点击“ZeroR”并点击“Delete”按钮。
- 点击“classifier”的“Choose”按钮,在“tree”部分选择“J48”,然后点击“Close”按钮。
- 点击“classifier”的“Choose”按钮,在“lazy”部分选择“IBk”,然后点击“Close”按钮。
- 点击“X”关闭算法选择器。
- 在“Bagging”配置上点击“OK”按钮。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
4. 运行实验
点击屏幕顶部的“Run”选项卡。
此标签页是运行当前配置的实验的控制面板。
点击大的“Start”按钮开始实验,并关注“Log”和“Status”部分,以便随时了解其进度。
5. 审阅结果
点击屏幕顶部的“Analyse”选项卡。
这将打开实验结果分析面板。
算法排名
我们首先想知道哪个算法是最好的。我们可以通过算法击败其他算法的次数来对算法进行排名。
- 点击“Test base”的“Select”按钮,选择“Ranking”。
- 现在点击“Perform test”按钮。
排名表显示了每种算法在数据集中相对于所有其他算法的统计上显著的获胜次数。获胜意味着准确率优于另一种算法,并且差异在统计学上是显著的。
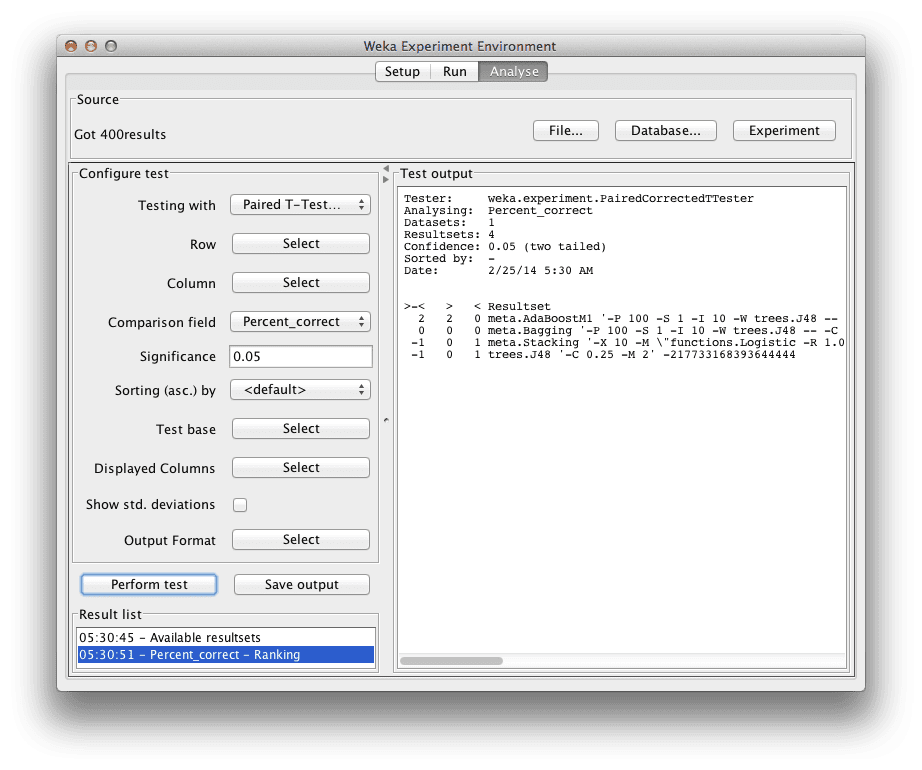
在 Weka Experimenter 中分析结果时的算法排名
我们可以看到 J48 的 AdaBoostM1 版本排名最高,相对于其他算法有 2 次显著获胜。我们还可以看到 Stacking 和普通的 J48 排名最低。J48 排名较低是一个好迹象,这表明至少一些集成方法提高了在该问题上的准确性。
算法准确率
接下来,我们想知道算法取得了什么样的分数。
- 点击“Test base”的“Select”按钮,并在列表中选择“J48”算法,然后点击“Select”按钮。
- 点击“Show std. deviations”旁边的复选框。
- 现在点击“Perform test”按钮。
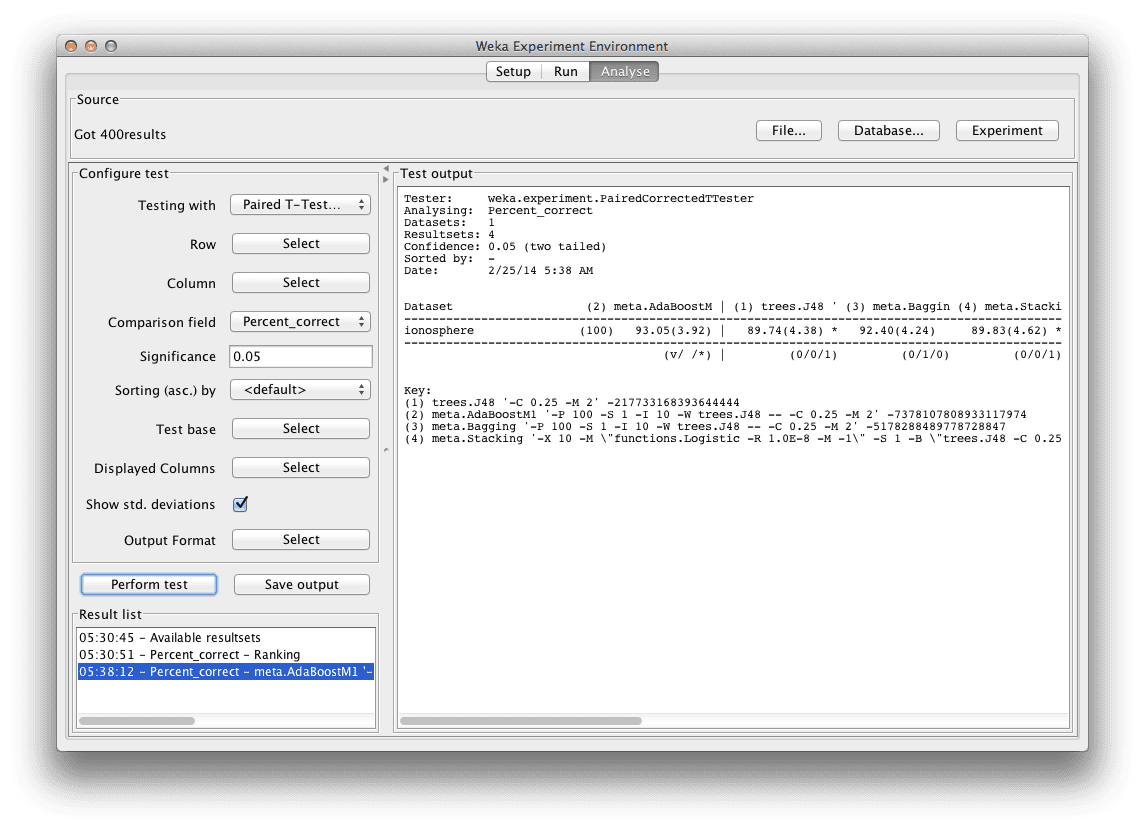
Weka Experimenter 中的算法平均准确率和统计显著性。
我们可以看到 AdaBoostM1 算法的分类准确率为 93.05% (+/- 3.92%)。我们可以看到这个值高于 J48 的 89.74% (+/- 4.38%)。我们在表格中 J48 的准确率旁边看到了一个“*”,这表明增强的 J48 算法与 J48 之间的差异是有意义的(统计显著)。
我们还可以看到 AdaBoostM1 算法的结果值高于 Bagging 的 92.40% (+/- 4.40%),但我们没有看到一个小的“*”,这表明这种差异没有意义(不具有统计显著性)。
总结
在本篇文章中,您了解了如何在 Weka 中配置一个包含一个数据集和三种算法集成的机器学习实验。您了解了如何使用 Weka Experimenter 通过集成方法提高机器学习算法在数据集上的准确性,以及如何分析结果。
如果您看到了这里,为什么不
- 看看您是否可以使用其他集成方法并获得更好的结果。
- 看看您是否可以使用 Bagging、Boosting 或 Blending 算法的不同配置并获得更好的结果。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗨,先生
我很高兴看到您关于集成方法的文章。我是一名研究员,我在数据挖掘领域做我的工作。我发送我的邮件,请回复我的问题。
1. 如何使用 weka 进行 bootstrap:?,请发送执行步骤
2. 我如何仅使用 weka 进行过采样?请发送执行步骤
3. 如何在 weka 中使用 smote+bordeline 和 smote+boosting?请发送执行步骤
4. 如何使用 weka 执行 10 折交叉验证?请发送您的执行步骤。是 weka 在内部执行 10 次吗?它是如何工作的?是否需要通过更改种子值 1 到 10 次来重复 10 折交叉验证并取结果的平均值。weka 是否会自动执行此操作,还是我们需要手动完成?哪个是正确的。
请将宝贵信息发送给我,这将有助于我的论文。
谢谢你
一如既往的简单和信息丰富,谢谢...
注意:请在“Ensemble”部分的第 4 条项目符号中更正“Click the “OK” button on the “AdaBoostM1” configuration。”。
您好,我可以使用 weka 进行基于案例的推理吗?
Weka 不是为此目的而设计的,但如果您使用 Java API,您或许可以对其进行调整。
您好,先生,我希望使用 SVM 作为分类器在 weka 中运行我的数据集,并希望显示 ROC 曲线和其他图形输出作为性能评估。
您能否建议一种方法来完成此操作?
我的数据集可以使用哪些性能评估标准?
先谢谢您了。
哪个算法在聚类方面具有高准确率!?
聚类不用于分类。
你好,
我们如何组合属性,如复合键,并运行集成分类器。请分步演示。
谢谢
感谢您的帮助。
不客气,Seetharam。
您好,先生。首先,感谢您提供如此精彩的教程。我发现它非常有信息量。先生,您能否回答我一个问题?先生,如果我想将一个实验重复 10 次或 100 次,是否可以在 weka experimenter 中完成?
是的。指定“重复次数”。
在这里了解更多
https://machinelearning.org.cn/design-and-run-your-first-experiment-in-weka/
本教程对我帮助很大。我一直在使用 WEKA Explorer 进行集成实验,但现在我将恢复使用 Experimenter。顺便问一下,您认为我可以通过组合 LOF 和 IQR 来创建一个集成异常检测器吗?我知道 WEKA 过滤器显示这是可能的,因为它提供了可用的选项,但我们如何解释距离度量和统计度量的结果?
也许可以尝试一下,看看它对模型技能有什么影响?
感谢教程。非常有用的。
很高兴它有帮助。
尊敬的先生
我有一个由 Bagging 和 MLP 创建的模型。我想知道必须选择哪个 WEKA 分类器来编写代码。
谢谢你
抱歉,我没有使用 Weka API 的教程,或许可以问问 stackoverflow 或 weka 用户组。
我是 WEKA 的多年用户。但我从未用过“experimenter”。我很兴奋它是一个高效的工具。谢谢!
不客气,很高兴听到我为您打开了门!