我们已经看到了如何在英语和德语句子对的数据集上训练 Transformer 模型,以及如何绘制训练和验证损失曲线来诊断模型的学习性能,并决定在哪个 epoch 上对训练好的模型进行推理。现在,我们准备在训练好的 Transformer 模型上运行推理,以翻译输入句子。
在本教程中,您将了解如何为神经机器翻译在训练好的 Transformer 模型上运行推理。
完成本教程后,您将了解:
- 如何在训练好的 Transformer 模型上运行推理
- 如何生成文本翻译
通过我的书《Building Transformer Models with Attention》来启动您的项目。它提供了自学教程和可运行的代码,指导您构建一个功能齐全的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

Transformer 模型推理
照片由 Karsten Würth 拍摄,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- Transformer 架构回顾
- Transformer 模型推理
- 测试代码
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
回想一下,Transformer 架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射到一系列连续表示;右侧的解码器接收编码器的输出以及前一时间步的解码器输出,以生成输出序列。
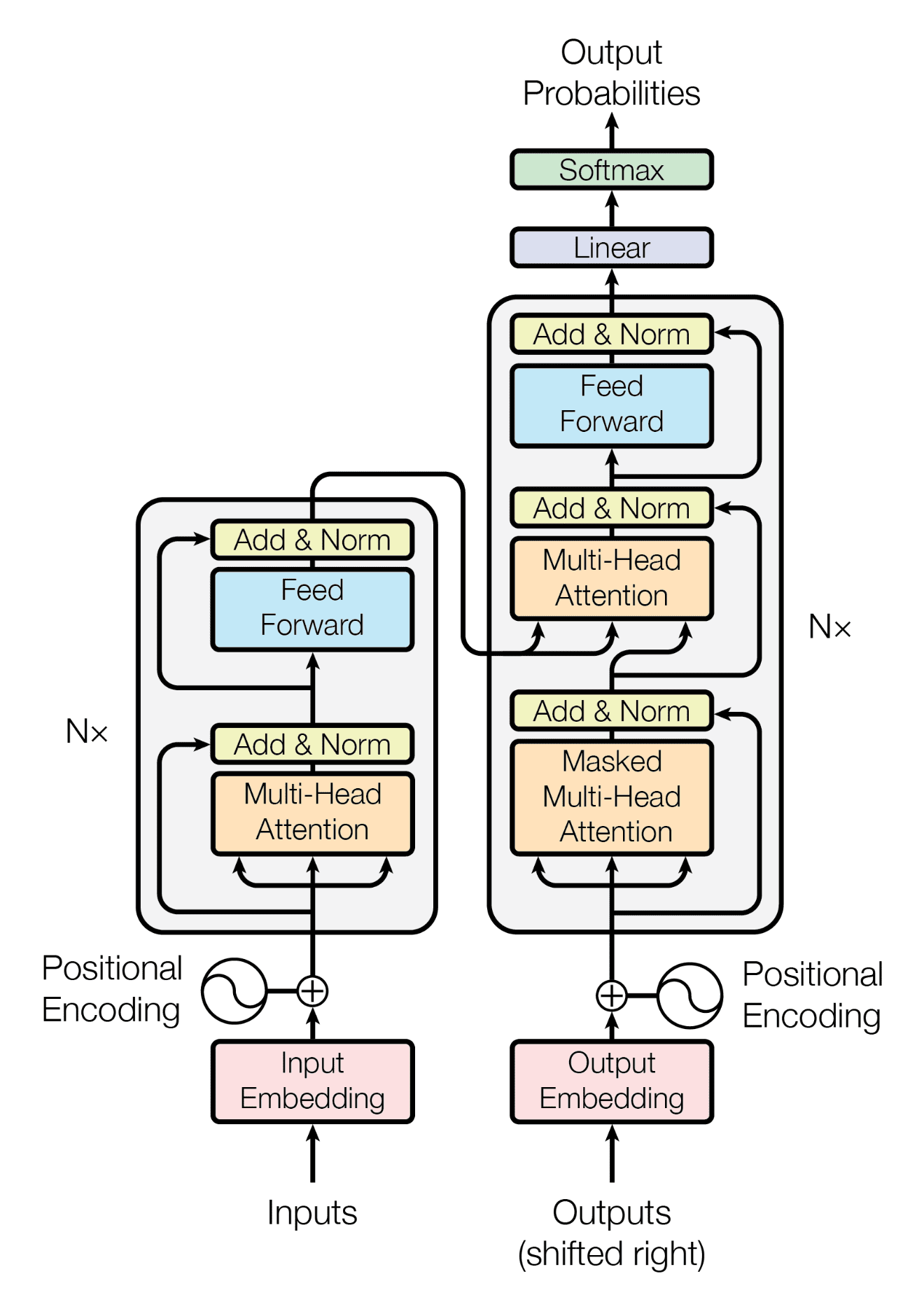
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经了解了如何实现完整的 Transformer 模型,并随后在英语和德语句子对的数据集上进行训练。现在,让我们继续为神经机器翻译在训练好的模型上运行推理。
Transformer 模型推理
让我们开始创建一个 `TransformerModel` 类的新实例,该类已在本教程中实现。
您将向其中输入相关参数,如 Vaswani 等人 (2017) 的论文中所述,以及有关正在使用的数据集的相关信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 定义模型参数 h = 8 # 自注意力头数 d_k = 64 # 线性投影查询和键的维度 d_v = 64 # 线性投影值的维度 d_model = 512 # 模型层输出的维度 d_ff = 2048 # 内部全连接层的维度 n = 6 # 编码器堆栈中的层数 # 定义数据集参数 enc_seq_length = 7 # 编码器序列长度 dec_seq_length = 12 # 解码器序列长度 enc_vocab_size = 2405 # 编码器词汇量大小 dec_vocab_size = 3858 # 解码器词汇量大小 # 创建模型 inferencing_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, 0) |
在此,请注意,最后输入到 `TransformerModel` 的是 Transformer 模型中每个 `Dropout` 层的 dropout 率。在模型推理期间将不使用这些 `Dropout` 层(您最终会将 `training` 参数设置为 `False`),因此您可以安全地将 dropout 率设置为 0。
此外,`TransformerModel` 类已保存到名为 `model.py` 的单独脚本中。因此,要使用 `TransformerModel` 类,您需要包含 `from model import TransformerModel`。
接下来,让我们创建一个继承自 Keras 中 `Module` 基类的 `Translate` 类,并将初始化好的推理模型赋值给变量 `transformer`。
|
1 2 3 4 5 |
class Translate(Module): def __init__(self, inferencing_model, **kwargs): super(Translate, self).__init__(**kwargs) self.transformer = inferencing_model ... |
在训练 Transformer 模型时,您需要先对要输入到编码器和解码器的文本序列进行分词。您通过创建词汇表并将每个单词替换为其对应的词汇表索引来实现这一点。
在推理阶段,在将要翻译的文本序列输入到 Transformer 模型之前,您需要实现一个类似的过程。
为此,您将在类中包含以下 `load_tokenizer` 方法,该方法将用于加载您“在训练阶段生成并保存的”编码器和解码器分词器。
|
1 2 3 |
def load_tokenizer(self, name): with open(name, 'rb') as handle: return load(handle) |
重要的是,您需要在推理阶段使用在 Transformer 模型训练阶段生成的相同分词器来分词输入文本,因为这些分词器已经过训练,能够处理与您的测试数据相似的文本序列。
下一步是创建 `call()` 类方法,该方法将负责
- 将开始 (<START>) 和字符串结束 (<EOS>) 标记附加到输入句子
|
1 2 |
def __call__(self, sentence): sentence[0] = "<START> " + sentence[0] + " <EOS>" |
- 加载编码器和解码器分词器(在本例中,它们分别保存在 `enc_tokenizer.pkl` 和 `dec_tokenizer.pkl` 的 pickle 文件中)
|
1 2 |
enc_tokenizer = self.load_tokenizer('enc_tokenizer.pkl') dec_tokenizer = self.load_tokenizer('dec_tokenizer.pkl') |
- 通过先分词,然后填充到最大短语长度,最后转换为张量来准备输入句子
|
1 2 3 |
encoder_input = enc_tokenizer.texts_to_sequences(sentence) encoder_input = pad_sequences(encoder_input, maxlen=enc_seq_length, padding='post') encoder_input = convert_to_tensor(encoder_input, dtype=int64) |
- 对输出的 <START> 和 <EOS> 标记重复类似的分词和张量转换过程
|
1 2 3 4 5 |
output_start = dec_tokenizer.texts_to_sequences(["<START>"]) output_start = convert_to_tensor(output_start[0], dtype=int64) output_end = dec_tokenizer.texts_to_sequences(["<EOS>"]) output_end = convert_to_tensor(output_end[0], dtype=int64) |
- 准备包含翻译文本的输出数组。由于无法提前知道翻译句子的长度,因此将输出数组的大小初始化为 0,但将其 `dynamic_size` 参数设置为 `True`,使其可以超过初始大小。然后,您将此输出数组的第一个值设置为 <START> 标记。
|
1 2 |
decoder_output = TensorArray(dtype=int64, size=0, dynamic_size=True) decoder_output = decoder_output.write(0, output_start) |
- 在解码器序列长度的范围内进行迭代,每次调用 Transformer 模型来预测一个输出标记。在这里,`training` 输入被设置为 `False`,然后传递给 Transformer 的每个 `Dropout` 层,以便在推理期间不丢弃任何值。然后选择得分最高的预测,并写入输出数组的下一个可用索引。一旦预测到 <EOS> 标记,`for` 循环就用 `break` 语句终止。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
for i in range(dec_seq_length): prediction = self.transformer(encoder_input, transpose(decoder_output.stack()), training=False) prediction = prediction[:, -1, :] predicted_id = argmax(prediction, axis=-1) predicted_id = predicted_id[0][newaxis] decoder_output = decoder_output.write(i + 1, predicted_id) if predicted_id == output_end: break |
- 将预测的标记解码为输出列表并返回
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
output = transpose(decoder_output.stack())[0] output = output.numpy() output_str = [] # 将预测的标记解码为输出列表 for i in range(output.shape[0]): key = output[i] translation = dec_tokenizer.index_word[key] output_str.append(translation) return output_str |
到目前为止,完整的代码清单如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
从 pickle 导入 加载 from tensorflow import Module from keras.preprocessing.sequence import pad_sequences from tensorflow import convert_to_tensor, int64, TensorArray, argmax, newaxis, transpose from model import TransformerModel # 定义模型参数 h = 8 # 自注意力头数 d_k = 64 # 线性投影查询和键的维度 d_v = 64 # 线性投影值的维度 d_model = 512 # 模型层输出的维度 d_ff = 2048 # 内部全连接层的维度 n = 6 # 编码器堆栈中的层数 # 定义数据集参数 enc_seq_length = 7 # 编码器序列长度 dec_seq_length = 12 # 解码器序列长度 enc_vocab_size = 2405 # 编码器词汇量大小 dec_vocab_size = 3858 # 解码器词汇量大小 # 创建模型 inferencing_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, 0) class Translate(Module): def __init__(self, inferencing_model, **kwargs): super(Translate, self).__init__(**kwargs) self.transformer = inferencing_model def load_tokenizer(self, name): with open(name, 'rb') as handle: return load(handle) def __call__(self, sentence): # 将开始和结束标记附加到输入句子 sentence[0] = "<START> " + sentence[0] + " <EOS>" # 加载编码器和解码器分词器 enc_tokenizer = self.load_tokenizer('enc_tokenizer.pkl') dec_tokenizer = self.load_tokenizer('dec_tokenizer.pkl') # 通过分词、填充并转换为张量来准备输入句子 encoder_input = enc_tokenizer.texts_to_sequences(sentence) encoder_input = pad_sequences(encoder_input, maxlen=enc_seq_length, padding='post') encoder_input = convert_to_tensor(encoder_input, dtype=int64) # 通过分词并转换为张量来准备输出 <START> 标记 output_start = dec_tokenizer.texts_to_sequences(["<START>"]) output_start = convert_to_tensor(output_start[0], dtype=int64) # 通过分词并转换为张量来准备输出 <EOS> 标记 output_end = dec_tokenizer.texts_to_sequences(["<EOS>"]) output_end = convert_to_tensor(output_end[0], dtype=int64) # 准备动态大小的输出数组 decoder_output = TensorArray(dtype=int64, size=0, dynamic_size=True) decoder_output = decoder_output.write(0, output_start) for i in range(dec_seq_length): # 预测一个输出 token prediction = self.transformer(encoder_input, transpose(decoder_output.stack()), training=False) prediction = prediction[:, -1, :] # 选择得分最高的预测 predicted_id = argmax(prediction, axis=-1) predicted_id = predicted_id[0][newaxis] # 将选定的预测写入输出数组的下一个可用索引 decoder_output = decoder_output.write(i + 1, predicted_id) # 如果预测到 <EOS> token,则中断 if predicted_id == output_end: break output = transpose(decoder_output.stack())[0] output = output.numpy() output_str = [] # 将预测的 tokens 解码为输出字符串 for i in range(output.shape[0]): key = output[i] print(dec_tokenizer.index_word[key]) return output_str |
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
测试代码
为了测试代码,我们来看一下您在准备训练数据集时保存的test_dataset.txt文件。这个文本文件包含一组已预留用于测试的英德句子对,您可以从中选择几个句子进行测试。
让我们从第一个句子开始
|
1 2 |
# 要翻译的句子 sentence = ['im thirsty'] |
这个句子的德语真实翻译,包括 <START> 和 <EOS> 解码器 token,应该是:<START> ich bin durstig <EOS>。
如果您查看此模型的绘制的训练和验证损失曲线(这里,您训练了 20 个 epoch),您可能会注意到验证损失曲线在第 16 个 epoch 左右显著减慢并开始趋于平稳。
因此,让我们加载第 16 个 epoch 保存的模型权重,并查看模型生成的预测
|
1 2 3 4 5 6 7 8 |
# 加载指定 epoch 的训练模型权重 inferencing_model.load_weights('weights/wghts16.ckpt') # 创建“Translate”类的新实例 translator = Translate(inferencing_model) # 翻译输入句子 print(translator(sentence)) |
运行上面的代码行会产生以下翻译的单词列表
|
1 |
['start', 'ich', 'bin', 'durstig', ‘eos’] |
这相当于预期的德语真实句子(请始终记住,由于您是从头开始训练 Transformer 模型,因此根据模型的随机初始化权重,您可能会得到不同的结果)。
让我们看看如果您加载一个对应于更早 epoch 的权重集(例如第 4 个 epoch)会发生什么。在这种情况下,生成的翻译是:
|
1 |
['start', 'ich', 'bin', 'nicht', 'nicht', 'eos'] |
用英语来说,这意味着:“I in not not”,这显然与输入的英语句子相去甚远,但这是可以预期的,因为在这个 epoch,Transformer 模型的学习过程仍处于早期阶段。
让我们用测试数据集中的第二个句子再试一次
|
1 2 |
# 要翻译的句子 sentence = ['are we done'] |
这个句子的德语真实翻译,包括 <START> 和 <EOS> 解码器 token,应该是:<START> sind wir dann durch <EOS>。
使用第 16 个 epoch 保存的权重,模型对该句子的翻译是:
|
1 |
['start', 'ich', 'war', 'fertig', 'eos'] |
这翻译成:“I was ready”。虽然这也不等于真实翻译,但它“接近”其含义。
然而,最后一个测试表明,Transformer 模型可能需要更多的数据样本才能有效训练。验证损失曲线在趋于平稳时相对较高,也证实了这一点。
事实上,Transformer 模型以非常消耗数据而闻名。例如,Vaswani 等人 (2017) 使用包含约 450 万个句子对的数据集训练了他们的英德翻译模型。
我们使用了标准的 WMT 2014 英德数据集,包含约 450 万个句子对……对于英法,我们使用了显著更大的 WMT 2014 英法数据集,包含 3600 万个句子……
—— 《Attention Is All You Need》,2017。
他们报告说,他们花了 3.5 天在 8 个 P100 GPU 上训练了英德翻译模型。
相比之下,您在这里仅使用了包含 10,000 个数据样本的数据集进行训练,这些数据样本在训练、验证和测试集之间进行了划分。
所以,下一个任务其实是给您的。如果您有计算资源,可以尝试在更大范围的句子对上训练 Transformer 模型,看看是否能获得比这里有限数据量更好的翻译结果。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
总结
在本教程中,您了解了如何对训练好的 Transformer 模型进行神经机器翻译的推理。
具体来说,你学到了:
- 如何在训练好的 Transformer 模型上运行推理
- 如何生成文本翻译
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






@ Jason Brownlee 和 @ Stefania Cristina 你们是否计划发布关于 Transformer 的书籍?
Jerzy 的建议很棒!感谢您的推荐。
感谢这个很棒的教程!
运行代码时出现了一些错误。 traceback 如下:
我仍在努力查找 bug。我没有在此教程中更改任何参数。
回溯(最近一次调用)
File “E:\code\transformer\inference_trans.py”, line 101, in
print(translator(sentence))
File “E:\code\transformer\inference_trans.py”, line 45, in __call__
prediction = self.transformer(encoder_input, transpose(decoder_output.stack()), training=False)
File “C:\Anaconda3\envs\ML\lib\site-packages\keras\utils\traceback_utils.py”, line 70, in error_handler
raise e.with_traceback(filtered_tb) from None
File “E:\code\transformer\transformer.py”, line 198, in call
decoder_output = self.decoder(decoder_input, encoder_output, dec_in_lookahead_mask, enc_padding_mask, training)
File “E:\code\transformer\transformer.py”, line 158, in call
pos_encoding_output = self.pos_encoding(output_target)
File “E:\code\transformer\positional_encoding.py”, line 47, in call
embedded_words = self.word_embedding_layer(inputs)
ValueError: Exception encountered when calling layer “position_embedding_fixed_weights_1″ ” f”(type PositionEmbeddingFixedWeights).
In this
tf.Variablecreation, the initial value’s shape ((2404, 512)) is not compatible with the explicitly suppliedshapeargument ((2405, 512)).Call arguments received by layer “position_embedding_fixed_weights” ” f”(type PositionEmbeddingFixedWeights)
\u2022 inputs=tf.Tensor(shape=(1, 7), dtype=int64)
你好 Helen,谢谢你的留言!
在推理 Transformer 模型时,你需要确保这些参数值与训练阶段准备数据集时的方式一致。
# 定义数据集参数enc_seq_length = 7 # Encoder sequence length
dec_seq_length = 12 # Decoder sequence length
enc_vocab_size = 2405 # Encoder vocabulary size
dec_vocab_size = 3858 # Decoder vocabulary size
从你的错误来看,我怀疑(至少)enc_vocab_size 的值需要改为 2404。请检查你的错误是否由此引起?
谢谢你的帮助!
结果是 enc_vocab_size 和 dec_vocab_size 都设置错了。
你好!这篇文章写得太棒了,感谢您的努力!
我有一个疑问:在推理过程中,解码器输入了“START” token,然后预测了“dec_seq_length”(在本例中为 12)。因此,解码器的形状将是 [batch_size, 12, d_model],其中只取最后一个预测(prediction = prediction[:, -1, :])。
我的问题是,剩下的 11 个预测有意义吗?由于 Transformer 是以向右移动一个单位的值进行训练的,所以我理解这 11 个是训练期间的先前词,但在推理时,我很难理解它在预测什么,或者这些值是否应该被忽略,因为它们没有任何意义。从预测的角度来看,我认为您可以直接忽略它们,但我只是好奇。
提前感谢!
你好 Alex……不客气!以下资源可能会有所帮助
https://towardsdatascience.com/how-to-use-transformer-networks-to-build-a-forecasting-model-297f9270e630
你好,
解释得很好。我使用 Transformer 在 Keras 中创建了一个印地语到英语的音译模型。模型效果很好。我遇到的问题是推理时间。您是否有任何建议可以减少推理时间?
你好 Lokesh……使用带有 GPU 选项的 Google Colab 可能会对您有所帮助。
你好,
一如既往地精彩解释和干净的代码!非常感谢您提供如此好的学习平台。
在实现 Decision Transformers (DT) 时,我注意到作者在推理时不对输入进行填充,就像您在这里做的那样。
这让我想知道为什么推理时没有填充。这仅仅是因为只有解码器吗?如果我们不在推理时使用填充会发生什么?
你好 Gabriel……不客气!这是一个很棒的问题。你能尝试一下,这样我们就可以从你的结果中学习吗?
你好,
在之前的教程中,用于保存模型每个 epoch 权重的那个方法,TensorFlow 会引发一个异常,即权重必须保存为“__.weights.h5”。现在在推理时,我先加载了模型实例,如本教程所示,并且参数 [enc_vocab_size = 2189 和 dec_vocab_size=3447],我已经用 10000 个数据集训练了模型。
但是加载权重时,出现了以下错误:
回溯(最近一次调用)
File “”, line 1, in
training_model.load_weights(“wght0.weights.h5”)
File “C:\Users\ABC\AppData\Local\Programs\Python\Python310\lib\site-packages\keras\src\utils\traceback_utils.py”, line 122, in error_handler
raise e.with_traceback(filtered_tb) from None
File “C:\Users\ABC\AppData\Local\Programs\Python\Python310\lib\site-packages\keras\src\saving\saving_lib.py”, line 456, in _raise_loading_failure
raise ValueError(msg)
ValueError: A total of 1 objects could not be loaded. Example error message for object
Layer ’embedding_2′ expected 1 variables, but received 0 variables during loading. Expected: [’embeddings’]
List of objects that could not be loaded
[]
你好 Raja……看来在加载模型权重时,保存的模型权重与模型架构之间可能存在不匹配。如果模型结构在保存和加载之间发生变化,或者权重与模型层没有正确对齐,就可能发生这种情况。
以下是解决此问题的一步一步方法
### 正确加载模型权重的步骤指南
#### 1. **确保模型架构一致**
– 确保在加载权重时,模型架构与保存时完全相同。模型结构的任何更改都可能导致权重加载问题。
#### 2. **正确保存模型权重**
– 使用一致的命名约定,并确保文件路径正确。
– 示例
python
# 保存每个 epoch 的权重
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath='model_weights_epoch_{epoch:02d}.weights.h5',
save_weights_only=True,
save_freq='epoch'
)
#### 3. **加载模型和权重**
– 在加载权重之前定义模型架构。
– 使用正确的方法加载权重。
– 示例
python# 定义模型架构
model = create_model(enc_vocab_size=2189, dec_vocab_size=3447) # 确保这与训练模型架构一致
# 加载权重
model.load_weights('model_weights_epoch_10.weights.h5')
#### 4. **代码示例**
这是一个完整的示例,展示了如何定义、保存和加载模型权重
pythonimport tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
def create_model(enc_vocab_size, dec_vocab_size, embedding_dim=256, units=512)
# 定义模型架构
encoder_inputs = Input(shape=(None,), name='encoder_inputs')
encoder_embedding = Embedding(input_dim=enc_vocab_size, output_dim=embedding_dim, name='encoder_embedding')(encoder_inputs)
encoder_lstm = LSTM(units, return_state=True, name='encoder_lstm')
encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(None,), name='decoder_inputs')
decoder_embedding = Embedding(input_dim=dec_vocab_size, output_dim=embedding_dim, name='decoder_embedding')(decoder_inputs)
decoder_lstm = LSTM(units, return_sequences=True, return_state=True, name='decoder_lstm')
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(dec_vocab_size, activation='softmax', name='decoder_dense')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
return model
# 实例化模型
model = create_model(enc_vocab_size=2189, dec_vocab_size=3447)
# 编译模型(如果需要)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 训练模型并保存权重
# 假设 training_data 和 validation_data 已定义
# model.fit(training_data, epochs=10, validation_data=validation_data, callbacks=[checkpoint_callback])
# 加载权重
try:
model.load_weights('model_weights_epoch_10.weights.h5')
print("Weights loaded successfully.")
except ValueError as e:
print("Error loading weights:", e)
### 关键点
1. **模型架构一致**: 确保保存和加载权重时模型架构相同。
2. **文件名和路径**: 仔细检查文件路径和名称,确保它们与保存时匹配。
3. **模型编译**: 有时,在加载权重之前编译模型可以解决问题。
通过遵循这些步骤,您应该能够正确加载模型权重并避免与变量不匹配相关的
ValueError。如果您继续遇到问题,请确保模型架构和权重文件兼容且正确对齐。感谢这个指南,我已经解决了这个问题,因为我在创建 Transformer 实例时提供了错误的参数,这导致了上述错误。
现在在推理时,模型只预测“eos” token 而不是翻译句子。在此方面任何帮助都将不胜感激。
谢谢
嗨,
在训练模型时,我为每个 epoch 添加了交叉检查,以查看训练模型对输入句子的预测。对于每个 epoch 迭代,我都会调用 Translator,并将训练模型实例传递给它的参数以初始化 translator 实例,然后将输入句子传递给该实例,但对于每个 epoch,模型的预测都是“”。token
Translator 的输入和输出
1. tokenized input sentence
[[1, 3, 151, 1336, 2]]
2. padded tokens
tf.Tensor([[ 1 3 151 1336 2 0 0]], shape=(1, 7), dtype=int64)
3. Decoder output PREDICTION scores for each tokens in the vocabulary
tf.Tensor([[-12.633082 -12.154094 5.066319 … -3.5435305 -3.546515
-3.5011318]], shape=(1, 3474), dtype=float32)
4. get the token with maximum score using tensorflow argmax
tf.Tensor([2], shape=(1,), dtype=int64)
5. Decoder output stack: tf.Tensor([1 2], shape=(2,), dtype=int64)
Input sentence: [” i made cookies “]
结果
translation: [‘start’, ‘eos’]
我遇到了完全相同的问题。您是否找到了导致此问题的原因?
感谢本教程,完成了从英语到德语的 seq2seq 翻译……