为了构建一个能够准确分类数据样本并在测试数据上表现良好的分类器,你需要以模型能够良好收敛的方式初始化权重。通常我们会随机化权重。但当我们使用均方误差(MSE)作为逻辑回归模型的损失进行训练时,有时可能会遇到一些问题。在深入细节之前,请注意,这里使用的方法也适用于逻辑回归以外的分类模型,并且将在后续的教程中使用。
如果权重以适当的区域初始化,我们的模型就可以很好地收敛。但是,如果我们从一个不利的区域开始模型的权重,我们可能会看到模型难以收敛或收敛速度非常慢。在本教程中,你将学习到,如果你使用 MSE 损失并且模型权重被不利地初始化,模型训练会发生什么。特别是,你将学到
- 不良的初始化如何影响逻辑回归模型的训练。
- 如何使用 PyTorch 训练逻辑回归模型。
- 具有 MSE 损失的糟糕初始化权重如何显著降低模型的准确性。
- 那么,让我们开始吧。
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

深度学习模型初始化权重。
图片来源:Priscilla Serneo。保留部分权利。
概述
本教程分为三个部分;它们是
- 准备数据和构建模型
- 模型权重初始值的影响
- 合适的权重初始化
准备数据和构建模型
首先,让我们准备一些合成数据用于训练和评估模型。
数据将基于单个变量预测值为 0 或 1。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import torch from torch.utils.data import Dataset class Data(Dataset): def __init__(self): self.x = torch.arange(-2, 2, 0.1).view(-1, 1) self.y = torch.zeros(self.x.shape[0], 1) self.y[self.x[:, 0] > 0.2] = 1 self.len = self.x.shape[0] def __getitem__(self, idx): return self.x[idx], self.y[idx] def __len__(self): "获取数据长度" return self.len |
有了这个Dataset类,我们可以创建一个数据集对象。
|
1 2 |
# 创建数据集对象 data_set = Data() |
现在,让我们使用nn.Module为我们的逻辑回归模型构建一个自定义模块。正如我们在之前的教程中所解释的,你将使用nn.Module包中的方法和属性来构建自定义模块。
|
1 2 3 4 5 6 7 8 9 10 |
# 为逻辑回归构建自定义模块 class LogisticRegression(torch.nn.Module): # 构建构造函数 def __init__(self, n_inputs): super().__init__() self.linear = torch.nn.Linear(n_inputs, 1) # 进行预测 def forward(self, x): y_pred = torch.sigmoid(self.linear(x)) return y_pred |
我们将创建一个逻辑回归模型对象,如下所示。
|
1 |
log_regr = LogisticRegression(1) |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型权重初始值的影响
为了证明这一点,让我们将随机初始化的模型权重替换为其他值(或预设的糟糕值),这些值将不允许模型收敛。
|
1 2 3 4 |
# 将随机初始化的权重替换为我们自己的值 log_regr.state_dict() ['linear.weight'].data[0] = torch.tensor([[-5]]) log_regr.state_dict() ['linear.bias'].data[0] = torch.tensor([[-10]]) print("检查权重: ", log_regr.state_dict()) |
输出结果为:
|
1 |
检查权重: OrderedDict([('linear.weight', tensor([[-5.]])), ('linear.bias', tensor([-10.]))]) |
如你所见,随机初始化的参数已被替换。
你将使用随机梯度下降来训练这个模型,并将学习率设置为 2。由于你要检查带有 MSE 损失的糟糕初始化值可能对模型性能产生的影响,你将设置此标准来检查模型损失。在训练中,数据由具有 2 个批次大小的数据加载器提供。
|
1 2 3 4 5 6 7 8 |
... from torch.utils.data import DataLoader # 定义优化器和损失 optimizer = torch.optim.SGD(log_regr.parameters(), lr=2) criterion = torch.nn.MSELoss() # 创建数据加载器 train_loader = DataLoader(dataset=data_set, batch_size=2) |
现在,让我们为模型训练 50 个 epoch。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... # 训练模型 Loss = [] epochs = 50 for epoch in range(epochs): for x,y in train_loader: y_pred = log_regr(x) loss = criterion(y_pred, y) Loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print(f"epoch = {epoch}, loss = {loss}") print("完成!") |
在模型训练期间,您将看到每个 epoch 的进度
|
1 2 3 |
[参数包含 tensor([[0.7645]], requires_grad=True), 参数包含 tensor([0.8300], requires_grad=True)] |
正如你所看到的,训练过程中的损失保持不变,没有任何改进。这表明模型没有在学习,并且在测试数据上的表现不会很好。
我们还将可视化模型训练的图表。
|
1 2 3 4 5 6 |
import matplotlib.pyplot as plt plt.plot(Loss) plt.xlabel("迭代次数") plt.ylabel("总损失") plt.show() |
您应该看到以下内容: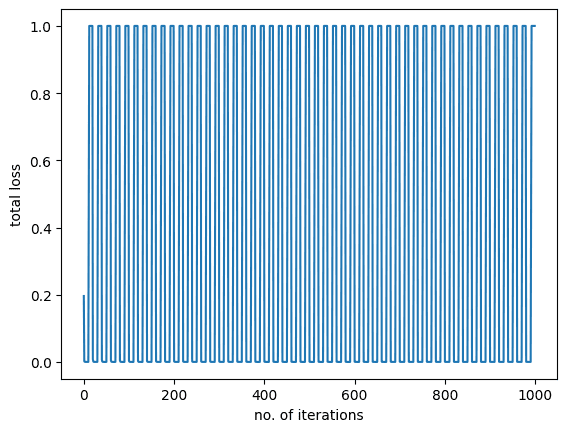 图表也告诉我们同样的故事,即在训练过程中模型损失没有发生任何变化或减少。
图表也告诉我们同样的故事,即在训练过程中模型损失没有发生任何变化或减少。
虽然我们的模型在训练中表现不佳,但让我们获取测试数据的预测并衡量模型的总体准确性。
|
1 2 3 4 5 |
# 获取模型在测试数据上的预测 y_pred = log_regr(data_set.x) label = y_pred > 0.5 # 设置分类阈值 print("模型在测试数据上的准确率: ", torch.mean((label == data_set.y.type(torch.ByteTensor)).type(torch.float))) |
这给出
|
1 |
模型在测试数据上的准确率: tensor(0.5750) |
模型的准确率仅为 57% 左右,这并不符合你的预期。这就是带有 MSE 损失的糟糕初始化权重可能对模型准确率产生的影响。为了减少这个错误,我们应用最大似然估计和交叉熵损失,这将在下一个教程中介绍。
把所有东西放在一起,下面是完整的代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
导入 matplotlib.pyplot 为 plt import torch from torch.utils.data import Dataset, DataLoader torch.manual_seed(0) class Data(Dataset): def __init__(self): self.x = torch.arange(-2, 2, 0.1).view(-1, 1) self.y = torch.zeros(self.x.shape[0], 1) self.y[self.x[:, 0] > 0.2] = 1 self.len = self.x.shape[0] def __getitem__(self, idx): return self.x[idx], self.y[idx] def __len__(self): "获取数据长度" return self.len # 创建数据集对象 data_set = Data() # 为逻辑回归构建自定义模块 class LogisticRegression(torch.nn.Module): # 构建构造函数 def __init__(self, n_inputs): super().__init__() self.linear = torch.nn.Linear(n_inputs, 1) # 进行预测 def forward(self, x): y_pred = torch.sigmoid(self.linear(x)) return y_pred log_regr = LogisticRegression(1) # 将随机初始化的权重替换为我们自己的值 log_regr.state_dict() ['linear.weight'].data[0] = torch.tensor([[-5]]) log_regr.state_dict() ['linear.bias'].data[0] = torch.tensor([[-10]]) print("检查权重: ", log_regr.state_dict()) # 定义优化器和损失 optimizer = torch.optim.SGD(log_regr.parameters(), lr=2) criterion = torch.nn.MSELoss() # 创建数据加载器 train_loader = DataLoader(dataset=data_set, batch_size=2) # 训练模型 Loss = [] epochs = 50 for epoch in range(epochs): for x,y in train_loader: y_pred = log_regr(x) loss = criterion(y_pred, y) Loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print(f"epoch = {epoch}, loss = {loss}") print("完成!") plt.plot(Loss) plt.xlabel("迭代次数") plt.ylabel("总损失") plt.show() # 获取模型在测试数据上的预测 y_pred = log_regr(data_set.x) label = y_pred > 0.5 # 设置零和一之间的阈值。 print("模型在测试数据上的准确率: ", torch.mean((label == data_set.y.type(torch.ByteTensor)).type(torch.float))) |
合适的权重初始化
默认情况下,PyTorch 的初始化权重应该能让模型正常工作。如果你修改上面的代码,注释掉训练前覆盖模型权重的两行并重新运行,你应该会看到结果效果相当好。上面它之所以工作得很糟糕,是因为权重离最优权重太远,并且在逻辑回归问题中使用了 MSE 作为损失函数。
像随机梯度下降这样的优化算法的性质并不能保证它在所有情况下都能工作。为了让优化算法找到解决方案,即模型收敛,最好使模型权重位于解决方案的邻近区域。当然,在模型收敛之前我们不知道邻近区域在哪里。但研究发现,我们应该优先设置权重,使得在样本数据的批次中,
- 激活的平均值为零
- 激活的方差与层输入的方差相当
一种流行的方法是使用 Xavier 初始化来初始化模型权重,即根据均匀分布 $U[-\frac{1}{\sqrt{n}}, \frac{1}{\sqrt{n}}]$ 随机设置权重,其中 $n$ 是层输入的数量(在本例中为 1)。
另一种方法是标准化 Xavier 初始化,即使用分布 $U[-\sqrt{\frac{6}{n+m}}, \sqrt{\frac{6}{n+m}}]$,其中 $n$ 和 $m$ 是层输入和输出的数量。在本例中,两者都为 1。
如果我们希望不使用均匀分布,He 初始化建议使用均值为 0、方差为 $\sqrt{2/n}$ 的高斯分布。
您可以在这篇博文中了解更多关于权重初始化的信息:深度学习神经网络的权重初始化。
总结
在本教程中,您了解了糟糕的权重如何降低模型性能。特别是,您了解了
- 不良的初始化如何影响逻辑回归模型的训练。
- 如何使用 PyTorch 训练逻辑回归模型。
- 带有 MSE 损失的糟糕初始化权重值如何显著降低模型的准确性。
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...

")

")


你好 Muhammad
教程很好,非常清晰。
只是有一个问题。训练之后你说
“虽然我们的模型在训练中表现不佳,但让我们获取测试数据的预测并衡量模型的总体准确性。”
但看起来你又预测了训练数据(data_set.x),因为我在示例中看不到测试数据。
是我有什么地方没理解吗?
祝好
你好 Edu…最佳实践可以在以下资源中找到,用于训练/测试分割
https://machinelearning.org.cn/training-validation-test-split-and-cross-validation-done-right/