图像修复(Inpainting)和图像外绘(Outpainting)长期以来一直是流行且经过充分研究的图像处理领域。这些问题的传统方法通常依赖于复杂的算法和深度学习技术,但仍然会产生不一致的结果。然而,Stable Diffusion 的最新进展已经重塑了这些领域。Stable Diffusion 现在在图像修复和外绘方面提供了更高的效率,同时保持了令人惊讶的轻量级特性。
在这篇文章中,您将探索图像修复和外绘的概念,并了解如何使用 Stable Diffusion Web UI 来实现它们。
通过我的书 《使用 Stable Diffusion 精通数字艺术》 来启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

使用 Stable Diffusion 进行图像修复和外绘
照片由 Kelly Sikkema 拍摄。保留部分权利。
概述
本文共五部分,分别是:
- 图像修复原理
- Stable Diffusion Web UI 中的图像修复
- 使用 Inpaint Anything 扩展
- 图像外绘原理
- Stable Diffusion Web UI 中的图像外绘
图像修复原理
Stable Diffusion 是一种最先进的 Text2Image 生成模型。
它是由 Robin Robmach 等人提出的潜在扩散模型(LDM)的一个类别。该 LDM 最初在 LAION-5B 数据集的一个 512×512 图像子集上进行训练,在各种图像生成任务中表现出具有竞争力的结果,包括条件图像合成、图像修复、图像外绘、图像到图像转换、超分辨率等等!
与先前在像素空间(原始图像)中运行的扩散模型不同,Stable Diffusion 在潜在空间(压缩图像)中运行,需要更少的计算资源,同时保留细节;这意味着您可以在本地系统上轻松运行它!
Stable Diffusion 主要基于三个组件:
1. 文本编码器
文本编码器将文本提示转换为嵌入空间,然后将其用于指导去噪过程(我们稍后会讲到)。Stable Diffusion 最初使用了一个固定的、预训练的 CLIP ViT-L/14 来创建嵌入;然而,改进的版本切换到 OpenCLIP,它包含参数大小为 354M+ 的文本模型,而前者 CLIP 的参数量为 63M。这使得文本提示能够更准确地描述图像。
2. U-Net
U-Net 将有缺陷的图像反复转换为更干净的形式。它接收两种类型的输入:噪声潜在表示(代表不完整或失真的图像数据)和文本嵌入(来自输入文本)。这些文本嵌入包含文本信息,用于指导 U-Net 理解最终图像理想上应该是什么样子。U-Net 的主要工作是预测输入中的噪声并将其减去以生成去噪后的潜在表示。与典型的 U-Net 架构不同,它还包含注意力层,这些层根据文本信息专注于图像的特定部分,从而增强了去噪过程。
3. 变分自编码器(VAE)
自编码器的解码器将 U-Net 的预测(去噪后的潜在表示)转换回原始像素空间,以创建最终图像。然而,仅在训练期间,自编码器的编码器会将高维图像(原始图像)压缩成低维潜在表示,作为去噪过程后输入到 U-Net。这种压缩创建了更紧凑的形式,并忽略了感知上无关紧要的细节,从而实现了计算上有效的训练。
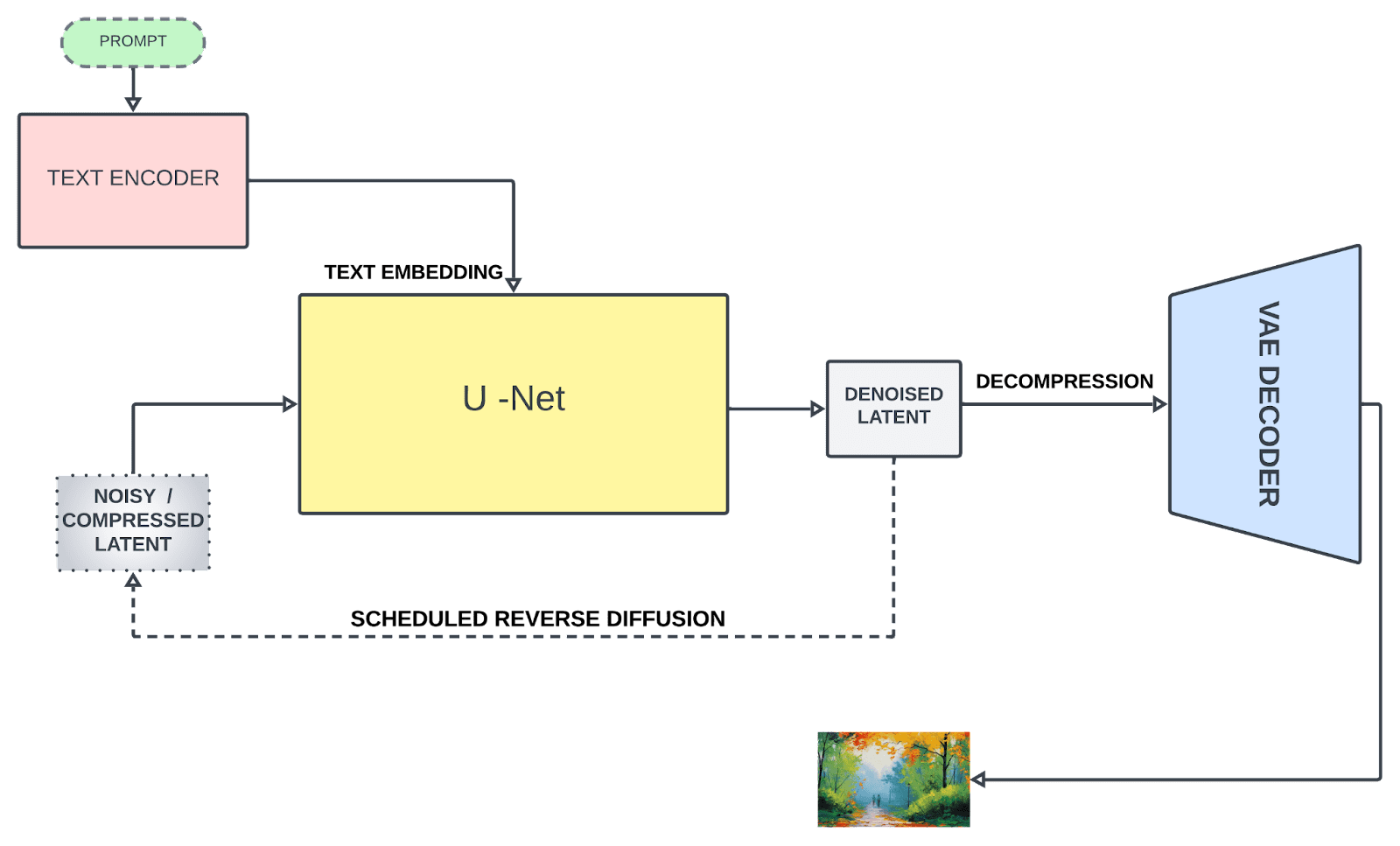
Stable Diffusion 架构
图像修复是一种流行的图像处理技术,用于修复图像中丢失的像素,甚至可以在遵循周围上下文(健康的像素有助于修复损坏的像素)的情况下重建图像的某个区域。这是扩散模型的一个惊人功能。典型的图像修复过程包括:
- 识别需要重建/修复的区域。可以通过掩码(用二值图像)来识别这些区域,以便算法识别它们。
- 然后,算法分析周围像素的模式和纹理,以修复在语义上合理且一致的区域。
让我们讨论一些重要的图像修复技术:
1. 纹理合成
该方法将图像分解成小块,分析它们的结构和纹理,并在图像内识别相似的块来填充缺失的区域。然而,它需要大量的计算资源,并且适用于具有均匀和一致纹理的图像。
2. 基于示例的方法
该方法涉及评估每个块的优先级,选择最佳匹配的块,然后根据预定义的优先级利用这些块来填充缺失的区域。它对于具有简单纹理和结构的缺失区域效果更好。
3. 基于扩散的方法
它使用偏微分方程(PDE)将图像数据从周围像素扩散到缺失的区域。这是一种快速有效的方法,但由于信息从周围区域扩散,它可能会导致锐度或细节丢失,导致重建区域出现模糊的外观,尤其是对于较大的缺失区域。
Stable Diffusion Web UI 中的图像修复
默认情况下,Stable Diffusion Web UI 中不仅有 txt2img,还有 img2img 功能。请记住,Stable Diffusion 是通过一个随机过程来生成图像的,该过程逐渐将噪声转化为可识别的图像。在此过程中,您可以根据提示施加条件。提示是 txt2img 中的文本,而在 img2img 中,它可以是图像 **和** 文本提示的组合。
一种进行图像修复的方法是使用 Web UI 中的 img2img 选项卡。在开始之前,您需要准备一个 **图像修复模型**,这与普通的 Stable Diffusion 模型不同。例如,您可以从 Hugging Face 下载 Stable Diffusion 2 图像修复模型
您可以直接下载 safetensors 文件(请注意,它的大小为 5.2GB),并将其放入 models/Stable-diffusion 目录。您可能还会发现另一个有用的模型(且更小,仅 2GB),即 epiCRealism Inpainting 模型
正如您已经了解了执行图像修复的原理一样,您需要一种方法来遮罩需要重建的图像区域,以及一个能够填充缺失像素的强大模型。在 img2img 选项卡中,您可以找到“inpaint”子选项卡,您可以在其中上传图像。

在 Stable Diffusion Web UI 中,您可以将图像上传到“img2img”选项卡下的“inpaint”子选项卡。
让我们用下面的狗的图片来试试:

用于图像修复的狗的图片
上传此图像后,您可以使用鼠标在图像中“绘制”狗以创建掩码。您可以使用右上角的图标来设置更大的画笔。如果您无法在图像中精确标记狗的边界,请不要担心,更大的掩码也没问题。例如,您可能会创建这样的效果:
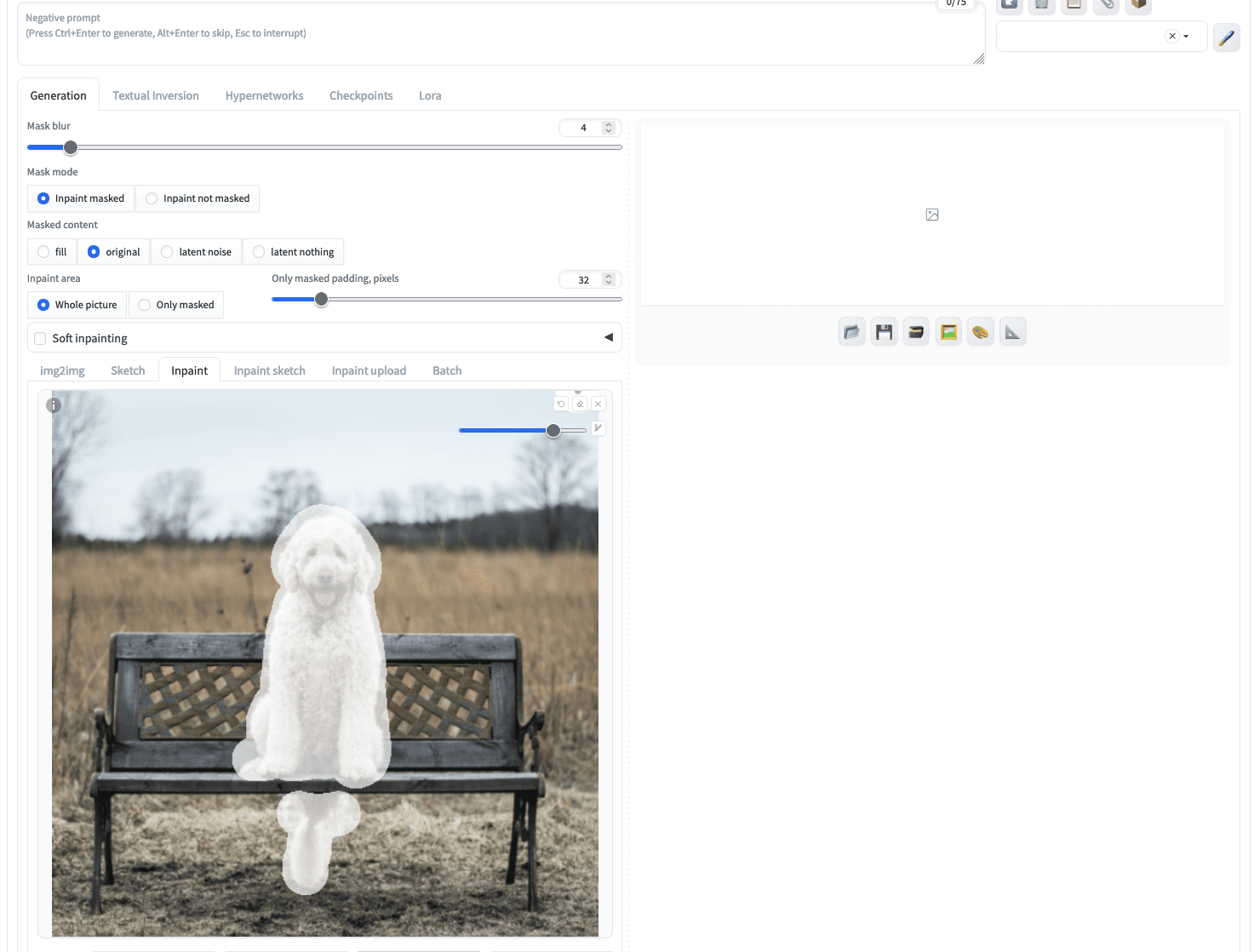
为图像修复创建的掩码
如果您立即点击生成,您将给予图像修复模型完全的自由来创建图像以填充被遮罩的区域。但是,让我们输入以下文本提示:
一只坐着的灰色猫,高分辨率
这不是最复杂的提示,但足以告诉模型您想要什么。然后,您应该从左上角的“Stable Diffusion checkpoint”下拉菜单中选择一个图像修复模型。之后,点击“Generate”按钮将得到您描述的确切内容:
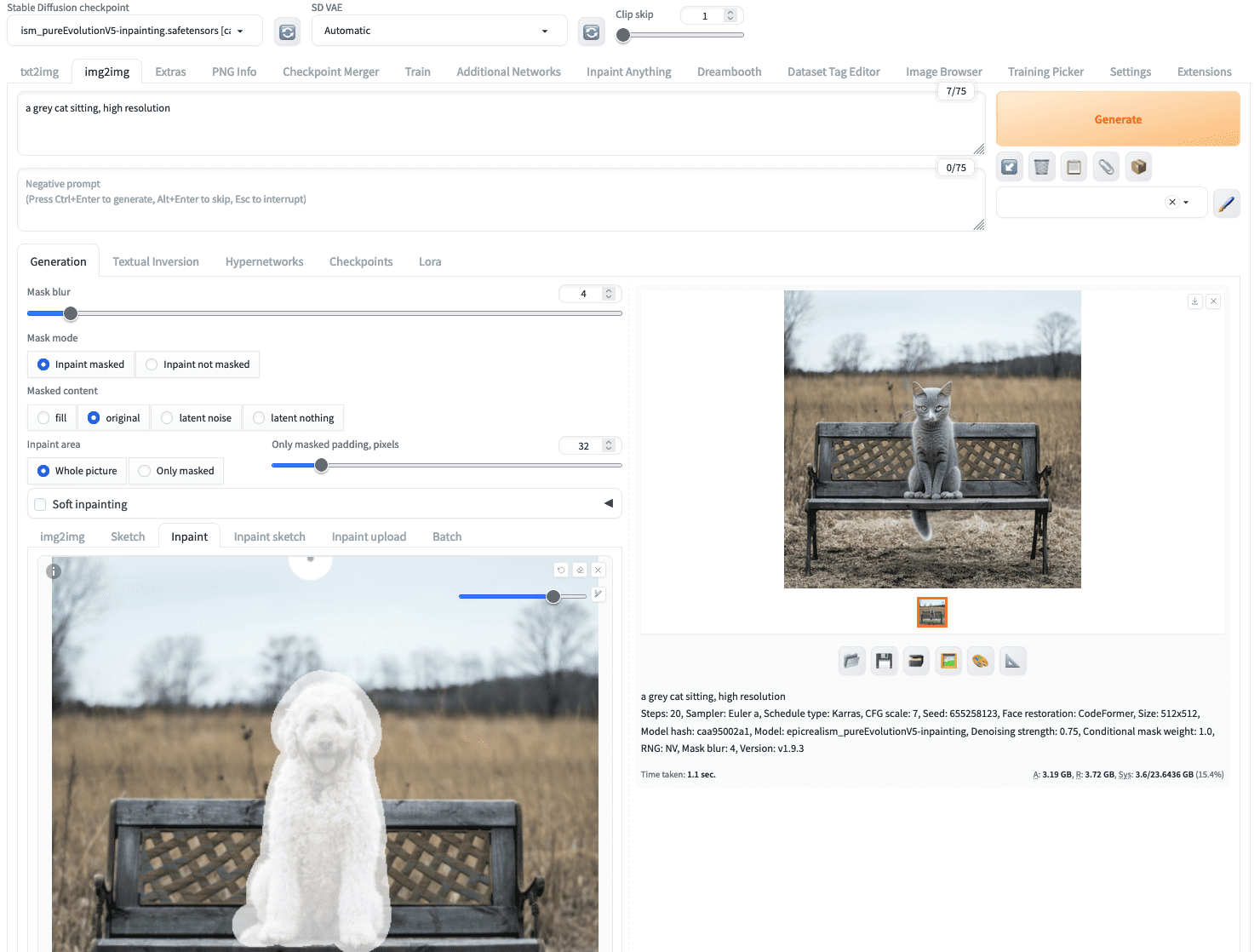
一张从狗的图片修复成猫的图片的照片
由于图像生成过程是随机的,您可能会看到不同的结果。
图像生成参数在这里同样适用,包括采样方法(例如 Euler)和采样步数。但有几个额外的参数您需要注意:
- 输入图像和生成图像的纵横比可能不同。如果需要调整大小,这会影响输出质量。您可以选择调整大小方法(例如,“仅调整大小”或“裁剪并调整大小”)。选择“仅调整大小”可能会扭曲纵横比。
- 被遮罩的图像是 Stable Diffusion 模型的起点。您可以选择用“潜在噪声”(latent noise)填充被遮罩的区域,“原始”(original)保留原始像素内容,或者简单地用相同颜色填充被遮罩的区域(“填充”)。这由“Masked content”选项控制。
- 您的输出图像在多大程度上与输入图像相似是由“Denoising strength”(去噪强度)控制的。值为 0 将保留输入,值为 1 将给予图像修复模型最大的自由度。如果您为“Masked content”选项选择了“original”,此选项的效果最为显著。
使用 Inpaint Anything 扩展
在图像上创建用于图像修复的掩码可能很耗时,具体取决于掩码的复杂程度。您可能会注意到“img2img”下有一个“Inpaint upload”子选项卡,您可以在其中将图像和掩码作为两个图像文件上传。如果您使用了 Photoshop 等其他应用程序来创建掩码,这会很有帮助。
但是,还有一种更高级的创建掩码的方法,即使用“Inpaint Anything”扩展。这是利用 Meta AI 的 SAM(Segment Anything Model),一个非常强大的图像分割模型,来为输入图像生成掩码。
要开始,请转到 Web UI 的“Extensions”选项卡。然后在“Available”子选项卡下,单击“Load from”按钮,并在表格上方的搜索栏中键入“inpaint anything”。应该只有一个扩展名与此名称匹配,您可以通过单击“Install”按钮来安装它。安装后,您需要重新启动 Web UI。

安装“Inpaint Anything”扩展
Inpaint Anything 扩展将创建一个同名的新的顶级选项卡。首先,您需要选择一个 SAM 模型,例如,本例中使用的是 sam_hq_vit_l.pth。您需要在第一次运行时下载该模型。
要开始创建图像修复,您可以像在 img2img 选项卡中一样上传您的图像。然后,您应该单击“Run Segment Anything”按钮,它将在右侧生成一个分段图,如下所示:
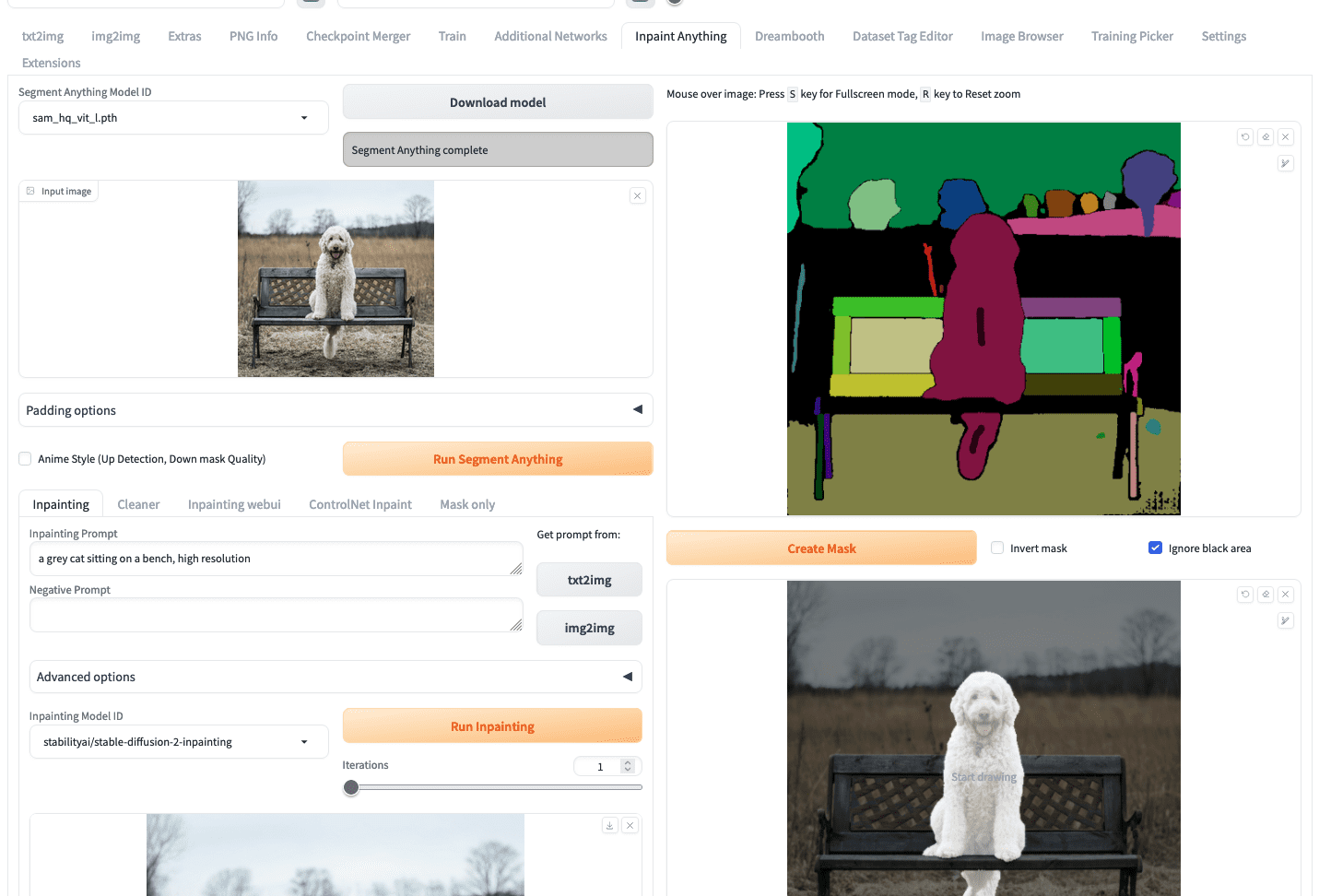
使用 Inpaint Anything 创建掩码
接下来,您需要使用鼠标在对应于狗的分段区域上绘制一个小划痕(如上面的截图所示,狗的胸部和尾部的短黑线)。然后单击“create mask”按钮将在其下方生成掩码。这样创建掩码比仔细勾勒图像中的狗的区域要容易得多。
要运行图像修复,您可以回到屏幕的左半部分,输入提示,然后单击“Run inpainting”。

来自“Inpaint Anything”的图像修复结果
但是,您应该注意到,在这种情况下,下拉菜单“Inpainting Model ID”中只有几个模型可供选择。上面示例中使用了 stable-diffusion-2-inpainting 模型。这些模型不依赖于您放入 models/Stable-diffusion 目录中的模型文件,而是首次使用时从 Hugging Face Hub 下载的。这是使用 Inpaint Anything 扩展的一个限制。如果您坚持使用您准备的图像修复模型,您可以从“Mask only”子选项卡中检索掩码,并在“img2img”选项卡中重新使用它。
图像外绘原理
虽然图像修复可以修复或重建图像的内部像素,但图像外绘是一种外插技术,它通过生成新的(外部)像素来扩展图像的视觉叙事,这些像素与原始图像在上下文上是一致的。现在您可以将图像扩展到其边界之外了!
图像外绘虽然不如图像修复受到关注,但仍有一些基于 CNN 和 GAN 的方法。斯坦福大学研究人员的一种方法非常有趣。他们采用了 DCGAN 作为其生成器网络。他们保持了编码器-解码器结构,并增加了扩张卷积,通过增加神经元的局部感受野(神经元可访问的信息)来提高真实感,因为增加扩张因子会增强感受野,而判别器网络由局部判别器组成,每个判别器在图像的特定区域上运行,并有一个连接层将所有局部输组合起来以产生最终输出。如需更多了解,请参阅此资源 感受野。
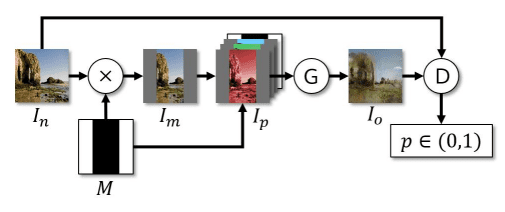
Radford 等人(2016)的训练流程
Stable Diffusion 的图像外绘
图像外绘意味着您提供一个输入图像,并生成一个输出,其中输入是输出的一个子图像。例如,您可以从一个头肩照生成一个半身照。
让我们使用 Stable Diffusion Web UI 来尝试一下。您可以像在前面的工作流程中一样,从 img2img 选项卡开始您的项目。但您也可以从 txt2img 生成图像,然后转移到 img2img。让我们尝试使用提示来生成一个头肩照:
一位公园里站着的女性的详细肖像,细节精美
使用合适的 Stable Diffusion 模型和其他参数,您将在 txt2img 选项卡中得到您的输出。在生成的图片下方,您可以找到一个看起来像相框的按钮,表示“将图像和生成参数发送到 img2img 选项卡”。点击它,您将把生成的图片带到 img2img 选项卡,如下所示:

将 txt2img 结果加载到 img2img 选项卡
此时,这与您在 img2img 选项卡中上传图像的情况相同。
您可以通过提示来描述外绘的预期输出,如果需要,还可以通过顶部的两个文本字段提供负面提示。您需要在 img2img 选项卡中设置输出大小。例如,如果输入图像是 512×512 像素,您可以将输出设置为 512×768 像素。
然后,最重要的一步是滚动到页面底部,在“script”部分,选择 Poor Man’s Outpainting 或任何外绘脚本。
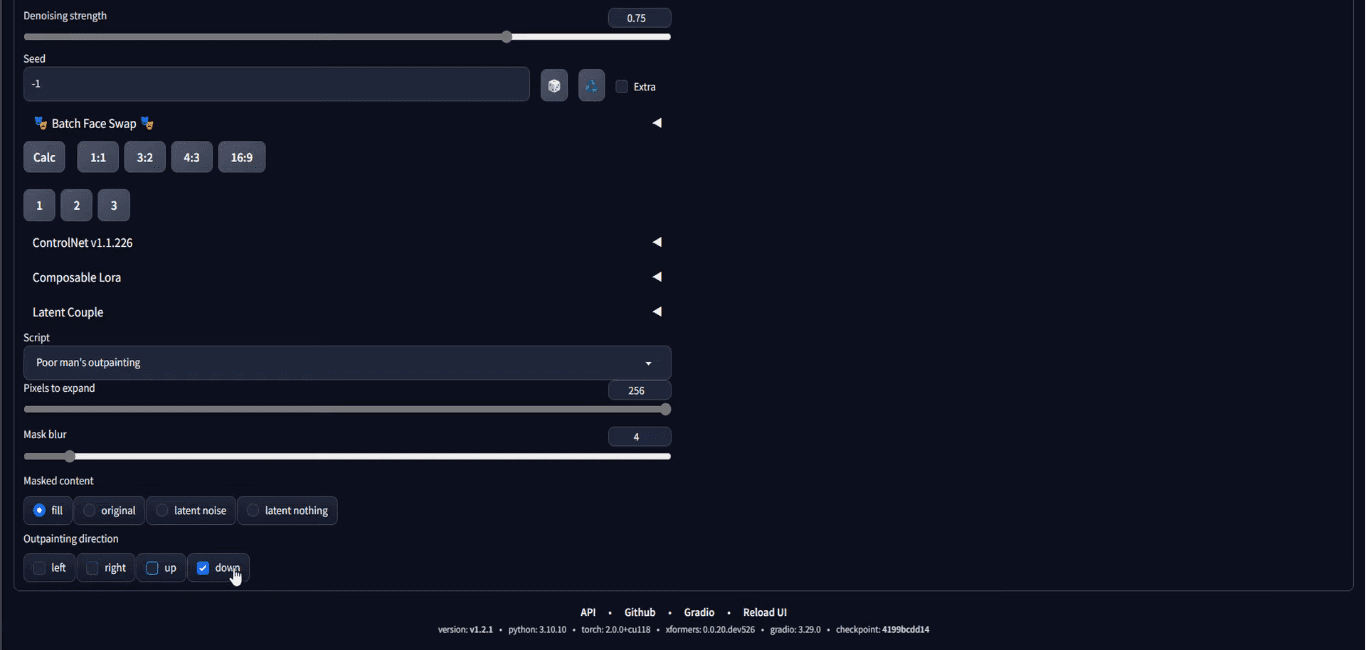
在“Script”下拉菜单中选择“Poor man’s outpainting”
您需要设置要绘制在输入图像边界之外的像素数量。您还需要设置要扩展图像的方向。在上面的截图中,它被设置为仅在向下方向外绘 256 像素。请注意,由于输入是 512×512 像素,并且外绘将在底部添加 256 像素,因此输出将是 512×768 像素,这就是为什么我们将输出大小设置为这样的原因。
完成所有参数设置后,您可以单击“Generate”来获取您的输出。由于生成过程中涉及随机性,您可能需要多次生成输出,直到您对结果满意为止。您可能会得到这样的结果:

外绘结果
您的输出可能与原始图像无法自然融合。您应该调整去噪强度,找出最适合您的方法。
这是您的最终输出。但没有任何东西阻止您再次运行它。(注意输出下方的“Send to img2img”按钮?)您可以重复此过程来创建全身照,但请记住,您需要使输出“更长”以适应输出。
外绘的替代方案
Stable Diffusion 展现了令人印象深刻的外绘结果,但在当前的生成式 AI 浪潮中,在我们完成这篇帖子之前,值得一提的是其他两个竞争对手。但是,只有 Stable Diffusion 是免费的!
Dall-E
Dall-E 由 OpenAI 开发,它们也是 text2img 模型,根据输入提示生成图像,目前有三个变体 Dall-E 1、Dall-E 2 和 Dall-E 3。 Dall-E 的外绘 通过考虑图像的阴影、反射和纹理来保持图像的上下文。
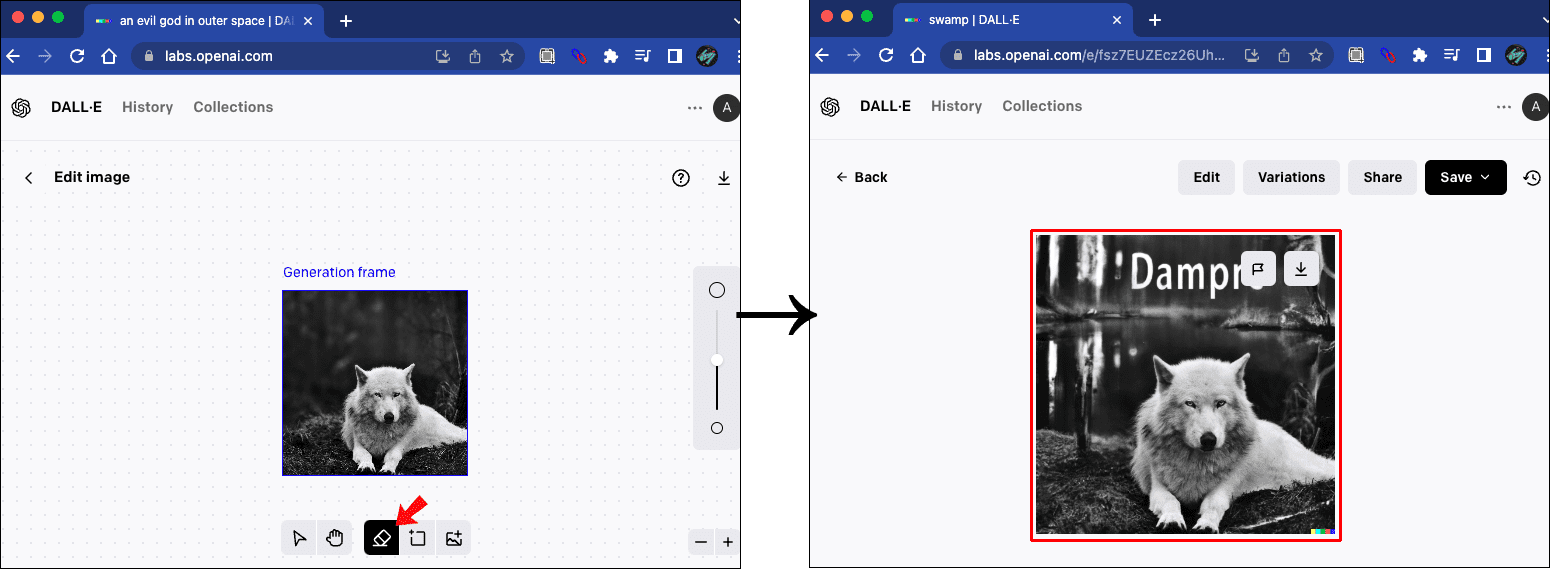
图片来自 Alphr
Midjourney
Midjourney bot 是由独立研究实验室 Midjourney 发布的主要图像生成器之一,您可以通过其 discord 服务器 访问它。它在 V5.2 中引入了名为 Zoom-out 功能 的外绘。

图片来自 Midjourney
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 高分辨率图像合成与潜在扩散模型,作者:Rombach 等人(2022)
- LAION-5B 数据集
- 无监督表示学习与深度卷积生成对抗网络,作者:Redford 等人(2016)
- 理解深度卷积网络的感受野
总结
在这篇文章中,您学习了 Stable Diffusion 的基本架构及其构建模块,特别是它们如何应用于图像修复和外绘任务。Stable Diffusion 已被证明是生成式 AI 领域的强大工具。除了 txt2img 生成,它也因图像修复和外绘而广受欢迎。automatic1111 的 Web UI 是 Stable Diffusion 的首选工具,您可以使用 img2img 选项卡通过它进行图像修复或外绘。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,包含所有 Python 工作代码,指导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都将帮助您创建令人惊叹的数字艺术。






暂无评论。