本质上,Stable Diffusion 是一个可以生成图片的深度学习模型。结合一些其他模型和用户界面,你可以将其视为一个工具,帮助你以新的维度创建图片,你不仅可以提供图片样式的指示,还可以让生成模型为你构思未明确指定的部分。
在这个为期 7 天的速成课程中,你将通过示例学习如何利用 Stable Diffusion 完成一个绘画项目。本迷你课程侧重于生成式 AI 模型的使用,而非其内部机制。因此,你不必担心它如何产生如此惊人结果的复杂理论。然而,由于无法一步到位,你应该期望了解众多扩展和参数如何协同工作以完成图像生成项目。让我们开始吧。

使用 Stable Diffusion 进行室内设计(7 天迷你课程)
照片由 Arno Smit 拍摄。保留部分权利。
本迷你课程适合谁?
在开始之前,让我们确保你找对了地方。下表提供了一些关于本课程设计受众的一般性指导。如果你不完全符合这些要点,请不要担心;你可能只需要复习一个或另一个领域就能跟上。
- 你知道什么是生成模型。你不是在期待奇迹。你将看到的一切都是一些复杂算法的结果。因此,所有结果都可以解释,并且一旦你知道了幕后原理,这些步骤都是可复用的。
- 你不是艺术家。你不是在数字画布上绘画。事实上,你无需绘画即可创作图片。生成模型不允许你控制过多细节,但你可以提供一些高级指令。这意味着你不应期望能够精确控制输出。而且,你也不需要学习绘画技巧来创作一张好图片。
- 你有耐心去完成一个项目。与用画笔创作图片一样,你需要耐心,完成一个项目需要时间。与绘画不同的是,你花费的时间是用来尝试生成流程中的不同旋钮。根据你的项目性质,你需要检查最佳参数是什么才能获得最佳结果。
本迷你课程不是一本关于 stable diffusion 的教科书。但你将看到许多组件如何工作以及它们如何帮助最终的图像生成结果。关键在于了解每个组件和参数的作用,以便你能决定如何在下一个项目中使用它们。
迷你课程概述
本迷你课程分为八个部分。
每节课的设计时长约为 30 分钟。你可能会比预计更快完成一些课程,而在其他课程中,你可能选择深入研究并花费更多时间。
你可以按自己的节奏完成每个部分。一个舒适的计划可能是连续八天每天完成一节课。强烈推荐。
在接下来的 8 节课中,你将学习以下主题:
- 第一课:创建你的 Stable Diffusion 环境
- 第二课:为自己创造空间
- 第三课:试错
- 第四课:提示语法
- 第五课:更多试错
- 第六课:ControlNet
- 第七课:LoRA
- 第八课:更好的脸部
这将非常有趣。
你需要做一些工作:阅读、研究和实验。你想学会如何完成一个 stable diffusion 项目,对吧?
在评论中发布您的结果;我会为您加油!
坚持下去;不要放弃。
第一课:创建你的 Stable Diffusion 环境
Stable Diffusion 是一个模拟扩散过程来生成图片的深度学习模型。你需要了解扩散的物理学才能欣赏一个看似没有想象力的计算机算法如何能创作艺术品。然而,作为用户,你可以将其视为一个黑箱,它可以将你的输入(例如文字描述)转化为图片。
Stable Diffusion 是一个基础模型,社区还会生产许多重新训练或微调的衍生模型。但归根结底,它是一个需要大量计算能力的深度学习模型。要运行该模型,建议你拥有一台配备不错 GPU 的电脑。如果你的电脑没有 GPU,可以考虑使用 AWS 等云提供商的 GPU。
你可能希望有一个用户界面来使你的工作流程更顺畅。它能帮助你更快地迭代,并避免在你需要编写代码时可能犯的许多错误。Stable Diffusion 有多种用户界面。ComfyUI 非常灵活且功能强大。然而,GitHub 上 Automatic1111 创建的 Web UI 是最容易使用的。在本课程中,我们将使用这个 Web UI。
要开始,你需要一个现代版本的 Python,例如 Python 3.10 或更高版本。Linux 机器是首选,因为过程会更顺畅,但 Windows 或 Mac 也可以。首先,从 GitHub 下载 Web UI。在 Linux 中,你可以运行 git 命令
|
1 |
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui |
然后,你需要下载 Stable Diffusion 模型。Civitai 是提供用户生成模型的最著名的社区。例如,你可以从这个位置获取“Realistic Vision v6”模型
选择“safetensors”格式,然后点击下载按钮。然后将下载的模型文件移动到 stable-diffusion-webui/models/Stable-diffusion 目录。
你还可以从 Hugging Face 找到模型。你可以在那里搜索关键词“stable diffusion”来找到它们。例如,你可以在这里找到 Deliberate 模型以及原始的 Stable Diffusion v1.5 模型
- https://hugging-face.cn/XpucT/Deliberate
- https://hugging-face.cn/models?pipeline_tag=text-to-image&sort=downloads
转到这些页面的“files”标签页获取模型文件。下载后,同样将它们移动到 stable-diffusion-webui/models/Stable-diffusion 目录。
下载完模型后,你可以进入 Web UI 目录并启动它
|
1 2 |
cd stable-diffusion-web-ui ./webui.sh |
这将自动创建一个 Python 虚拟环境,安装必要的包(如 PyTorch),并启动 Web UI。如果你在自己的电脑上启动,你应该会看到一个浏览器启动到 URL
- https://:7860
但是,如果你在远程运行,例如在云端的远程计算机上,你应该让 Web UI“监听”公共 IP
|
1 |
./webui.sh --listen |
然后在浏览器中你会看到如下内容

你的任务
尝试按照上述步骤启动你的 Web UI。确保你没有遇到任何错误,并且在左上角的下拉菜单中看到了你的 checkpoint。
第二课:为自己创造空间
想象一下,你是一名室内设计师,你的项目是设计一个卧室。你想向其他人展示你的想法。你可以在纸上画出来。但你也可以让你的电脑帮你画。
要让 Stable Diffusion 画一张图片,你可以提供一个文本提示,并期望得到一张图片作为回报。这就是 Web UI 中的“text2img”功能。你可以在正向提示框中输入以下内容:
卧室,现代风格,一面墙上有一个窗户,写实照片
确保你选择了一个“checkpoint”,即你正在使用的 Stable Diffusion 模型。将宽度和高度设置为 768 和 512。然后点击“Generate”(生成)并等待图片。这就是你用 Stable Diffusion 创建的第一件艺术品。
正如你在屏幕上看到的,在生成图片之前,你还可以调整很多其他设置。你使用了正向提示,但也有负向提示。正向提示用于描述输出,而负向提示则告诉图片应该避免什么。既然你要求的是“写实照片”,你可以在负向提示中加入其他风格,例如:
素描,黑白,绘画
你可以添加更多内容,例如“户外”,因为显然,你的输出应该是室内场景。如果你想要不同风格的房间,你也可以尝试调整一些关键词,例如“砖墙”或“小屋内部”。

仅使用文本提示生成房间图像
任何提示(即使是非英语提示)都可以使用标准算法转换为嵌入向量。但是,不同的模型可能对提示的理解不同。模型不认识的关键词可能会被忽略或被错误地解释。这就是为什么你应该尝试不同的模型。
你的任务
在 Web UI 中,你可以看到许多其他选项。尝试上述操作并多次生成。每次你应该会看到不同的图片。然后,找到随机种子(random seed)的框,输入一个固定的正整数,然后再次生成。图片是否始终保持不变?如果固定随机种子但更改采样器(sampler)呢?
要重新创建相同的图片,你需要固定提示、模型和选项(包括种子、采样器和步数)。
第三课:试错
不幸的是,扩散过程的性质涉及许多随机性,并且有很多参数,很难判断你的设置是否正确。检查的 easiest 方法是保持设置(包括提示、模型、调度器等)不变,但调整随机种子。如果多个随机种子始终产生错误的结果,你就知道你需要更改其他东西。
在 Web UI 中,你可以在保持随机种子为 $-1$ 的同时调整批次大小(batch size)和批次计数(batch count),从而通过一次点击生成按钮来生成多张图片。
与许多深度学习模型一样,数据是分批处理的,批次大小告诉 Stable Diffusion 模型同时处理多少张图片,每张图片都有一个不同的随机种子。这只有在你的 GPU 内存足够的情况下才有效。否则,你可以增加批次计数,即你想要生成的批次数。每个批次都会运行一次生成(因此速度会成比例地变慢)。
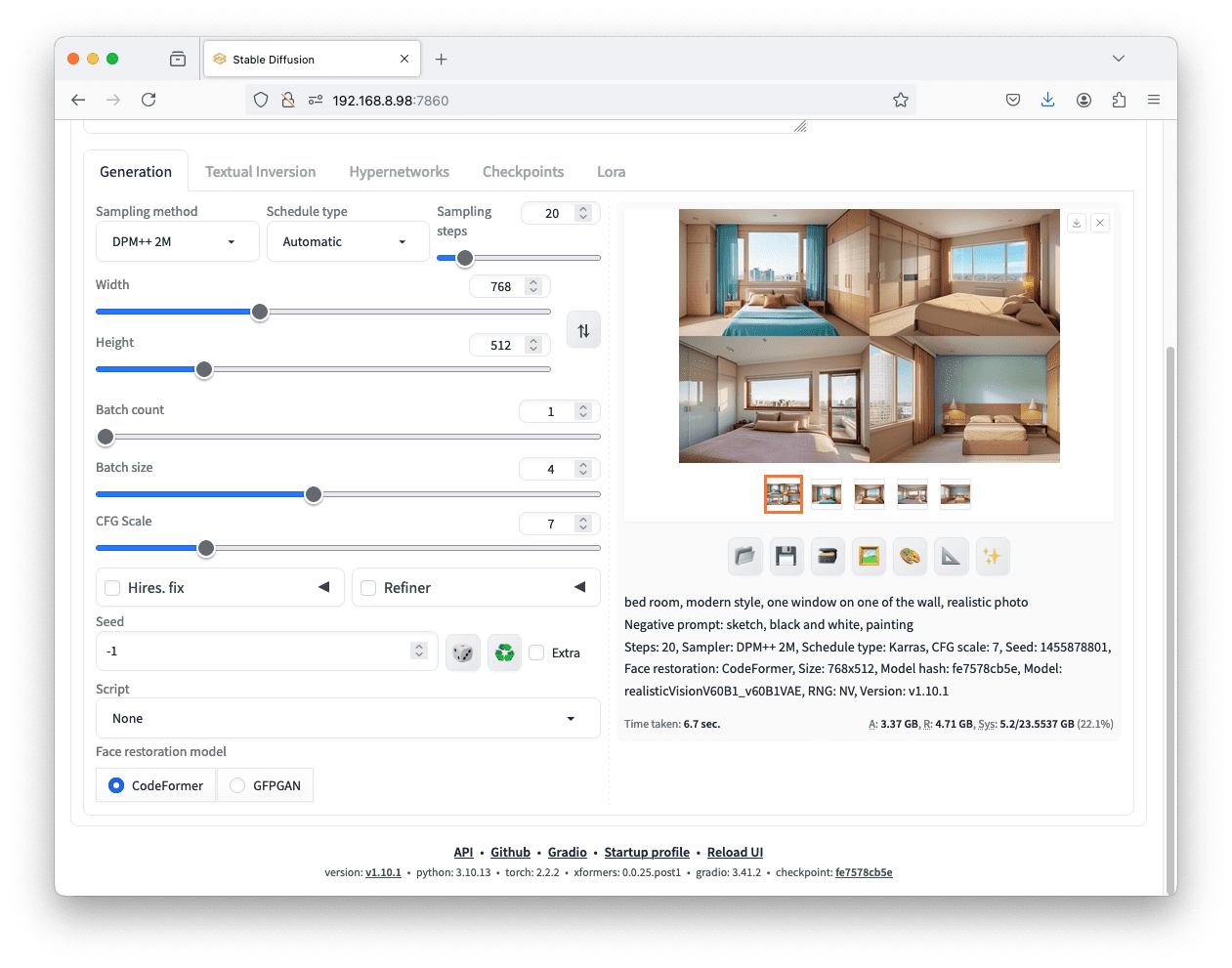
将“batch size”设置为 4 将一次生成四张图像。设置“batch count”将产生类似的效果。
通过多个批次大小或批次计数,你将一次性在 Web UI 中看到所有输出,并有一个“联系表”(contact sheet)显示所有内容。你可以点击每张单独的图片来查看生成该图片的参数(包括使用的随机种子)。

多个图像在同一批次中生成,使用相同的提示和设置,但随机种子不同。
你的任务
尝试使用多个批次大小或批次计数生成图片。调整你的提示或其他设置,然后重试。你能找到下载屏幕上显示的图片的按钮吗?你知道如何找到你之前生成的所有图片的记录吗?Web UI 中有一个用于此的标签页。你能找到磁盘上存储之前生成的图片的目录吗?
第四课:提示语法
你向 Stable Diffusion 提供了一个提示,然后有一个预处理器将你的文本提示转换为数值嵌入向量。提示将被分解为关键词,你可以让每个关键词对图片生成过程产生不同的影响。
考虑这样一个提示:
卧室,现代风格,一面墙上有一个窗户,灰色床单,木制床头柜,吊灯,墙上的画,(一只猫睡在地板上:1.1),写实照片
在此提示中,你看到片段“(一只猫睡在地板上:1.1)”被括在括号中,并且具有“(文本:权重)”的样式。这使得引号中的文本对最终的嵌入向量具有不同的权重,默认权重为 1.0。你可以在 Web UI 的正向提示和负向提示框中使用此提示语法。
你不应该尝试非常极端的权重,因为模型不是为此设计的。通常,你的权重应在 0.5 到 1.5 之间。如果你需要非常极端的权重,那可能意味着你的模型没有经过训练来理解该关键词。
你的任务
查看 https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki,了解支持哪些提示语法。这由 Web UI 中的提示处理器处理,不属于 Stable Diffusion 模型的一部分。有一种语法允许你使用一个提示在前一半的生成步骤中,在剩余步骤中使用另一个提示。如何编写这样的提示?
第五课:更多试错
使用相同的参数集,你可以使用批次大小一次性生成多张图片,每张图片具有不同的随机种子。这通常有效,并能帮助你找到一个好的图片所对应的好的种子。
然而,有时你需要尝试不同的参数,因为你不确定哪个参数能产生正确的效果。这可能是在不同模型上尝试相同的提示,或者替换提示中的某个关键词。
默认情况下,Web UI 中有一个“scripts”(脚本)部分,其中有一个“X/Y/Z plot”(X/Y/Z 图)。这个名称意味着创建“轴”,其中轴上的每个点都是一个选项,这样你就可以通过一次点击按钮尝试所有组合。
让我们尝试以下操作:将正向提示设置为:
卧室,现代风格,一面墙上有一个窗户,写实照片
负向提示设置为:
素描,黑白,绘画
然后在脚本部分选择“X/Y/Z plot”,为“X type”选择“Prompt S/R”,然后在此处输入“X values”:
现代,皇家,中世纪,日本

使用“X/Y/Z plot”脚本和“Prompt S/R”类型生成具有提示变化的多个图像。
X/Y/Z plot 部分的所有值都用逗号分隔。第一个值“modern”是要搜索(S)的内容,其余的是要替换(R)的内容。这就是 Prompt S/R 如何帮助你构建组合。当你点击“generate”时,你会看到类似上图的图片。例如,现代风格的卧室具有极简主义的装饰风格,而日式卧室则没有床,而是榻榻米。
你的任务
脚本中还有一个“prompt matrix”(提示矩阵),但“Prompt S/R”更容易使用。尝试使用“X/Y/Z plot”和其他“types”和“values”。你最多可以同时使用三个轴。你是否找到了允许你尝试多个模型的“type”?你认为不同的模型会产生不同的房间吗?尝试使用提示在图片中生成一个人。你应该会看到不同模型如何生成人脸。X/Y/Z plot 是一个强大的功能,可以让你探索选项以生成你喜欢的图片。
第六课:ControlNet
在后台,Stable Diffusion 模型是从一个随机数矩阵开始,然后缓慢地将其转换为一个像素矩阵,你可以在其中识别出你的提示所描述的图片。这个过程涉及多个迭代(调度器步骤),去除的随机量取决于你在 Web UI 中设置的参数。
由于存在多个迭代,你可以有意识地调整每次迭代的输出,然后再将其反馈给 Stable Diffusion 模型。这就是 ControlNet 的概念。要使用 ControlNet,请在 Web UI 的“Extensions”(扩展)选项卡中勾选并安装 ControlNet 插件。然后,你还需要按照 ControlNet 扩展的 wiki 页上的说明,从 Hugging Face 下载并安装 ControlNet 模型:
安装 ControlNet 后,你可能需要重启 Web UI(扩展选项卡中有一个按钮)并刷新浏览器以加载它。
让我们尝试解决这个提示:如果你多次生成房间,你会发现每次的视角都不同。很难写一个提示来描述你想要的视角,但很容易通过图片来展示。让我们下载并使用这张“空房间”图片:

动漫风格的空房间图片。由作者使用 Stable Diffusion 生成。
你像之前一样设置提示和其他设置。但这次,展开并启用 ControlNet 部分。在“Single Image”(单张图片)标签页中,上传这张图片。然后选择“MLSD”作为“Control Type”(控制类型)。最重要的是,将“Starting Control Step”(控制起始步数)设置为 0,将“Ending Control Step”(控制结束步数)设置为 0.3。这意味着你只在步骤的前 30% 使用此 ControlNet。例如,如果你选择的采样步数为 40,ControlNet 将在第 0 到第 12 步干预图像。
设置批次大小并生成。你会发现生成的图像都具有相同的视角。这是因为“MLSD”是一种边缘检测 ControlNet,它将你上传的图片转换为线条艺术,并将线条应用于图片。你可以尝试将 Control Type 改为“Canny”,它应该具有类似的效果,因为它也是一种边缘检测算法。
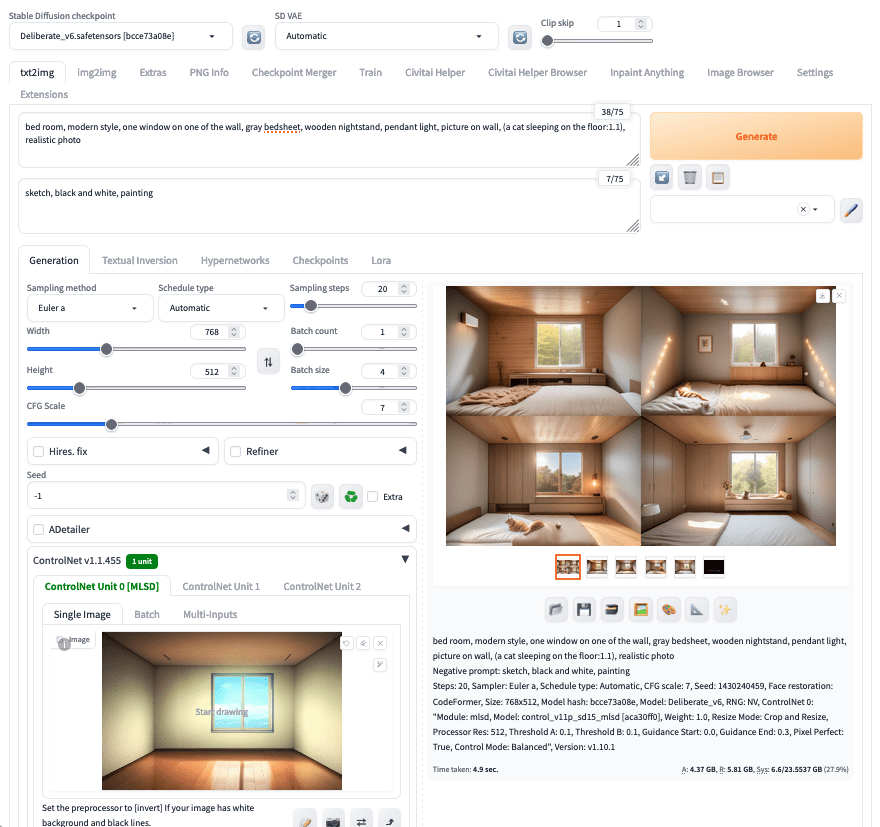
使用 MLSD ControlNet 生成相同视角下的房间图片。
你的任务
按照上面的说明生成图片后,你是否看到了查看边缘检测结果外观的方法?你是否看到了控制边缘检测算法灵敏度的一些参数?还有一种名为“Scribble”(涂鸦)的 Control Type。这不需要你上传图片,而是允许你用鼠标绘制。试试这个,看看效果。
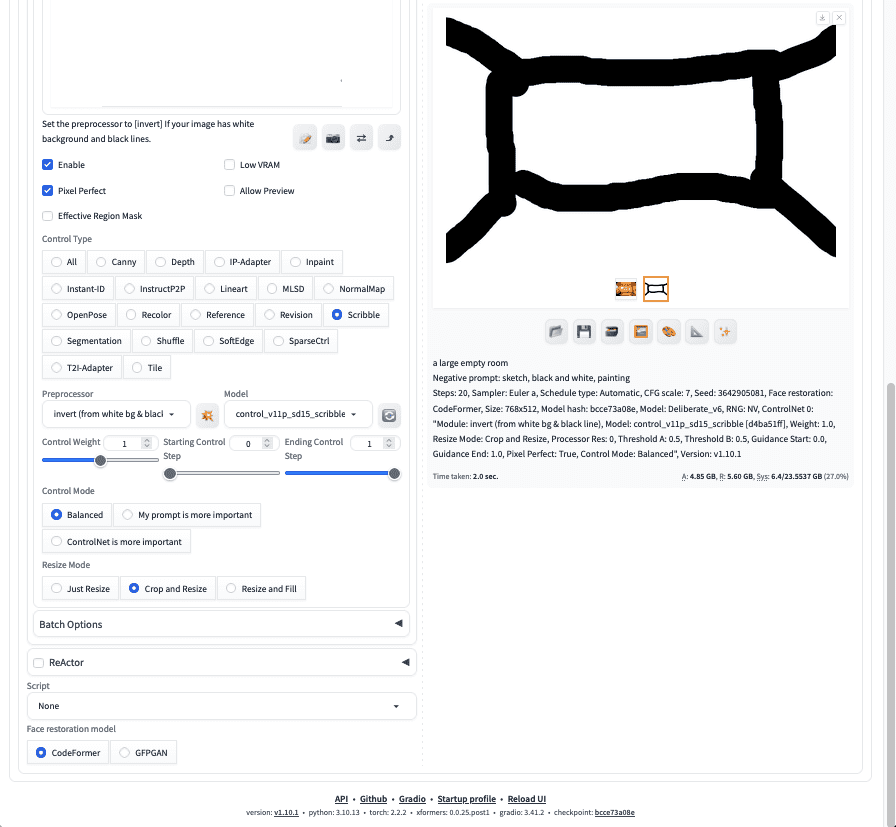
使用“scribble”ControlNet。
第七课:LoRA
ControlNet 不是唯一可以干预生成图片的扩散过程的方法。LoRA 也是一个可以对输出应用效果的插件。首先,让我们下载并使用一个 Stable Diffusion XL 模型(SDXL),例如这个:
- https://civitai.com/models/312530 (CyberRealistic XL 模型)
然后你可以从 Civitai 下载“Better Picture, More Details LoRA”:
并将其保存到路径(stable-diffusion-webui/models/Lora)。请注意,LoRA 需要匹配的 Stable Diffusion 架构。这个需要 SDXL。一些其他的 LoRA 可能需要 SD1 或 SD2。你不能混合使用它们。
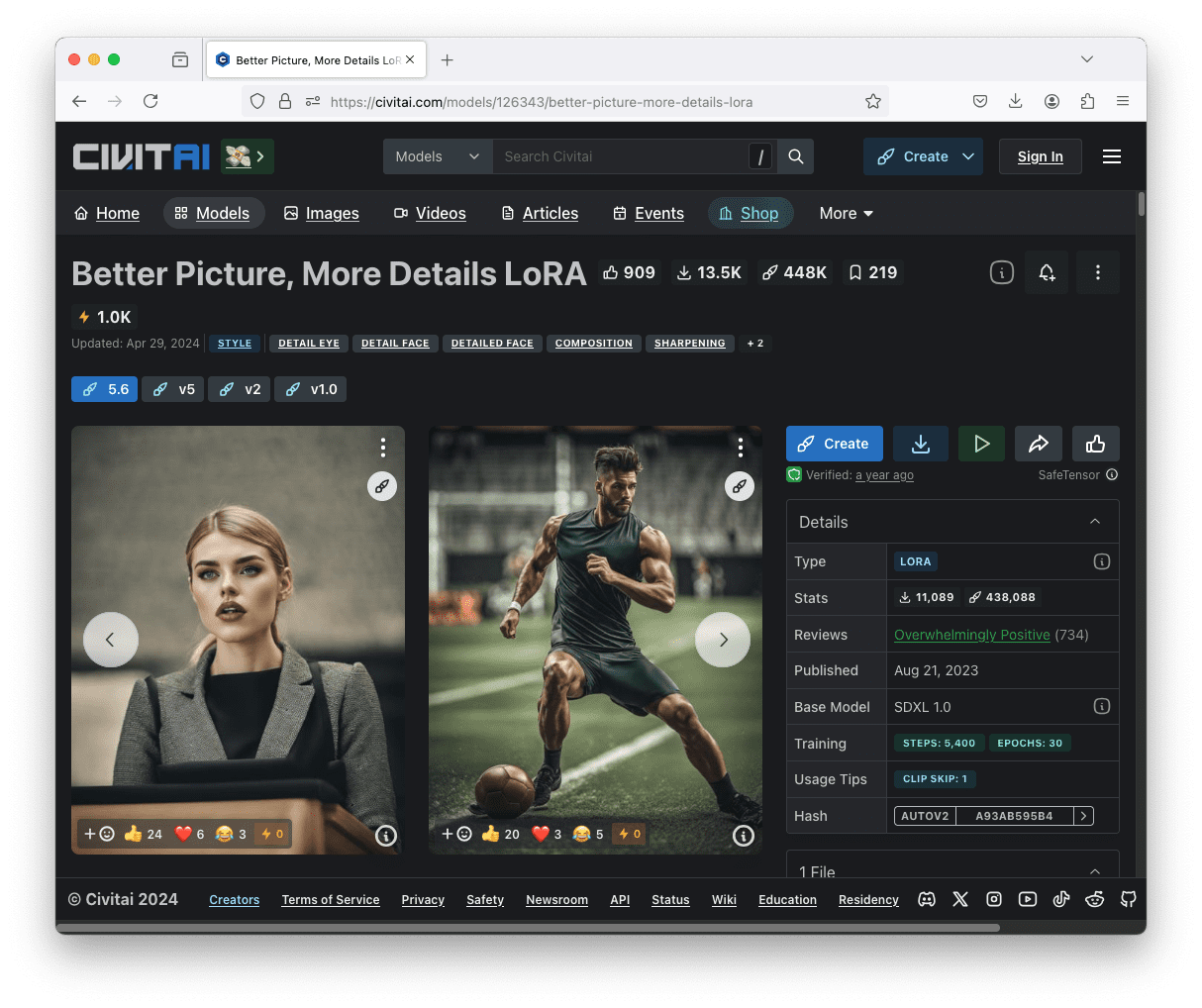
LoRA 模型可以从 Civitai.com 下载。请注意,这个特定的 LoRA 需要使用基于 SDXL 的模型。
下载 LoRA 后,尝试使用以下提示:
卧室,现代风格,一面墙上有一个窗户,灰色床单,木制床头柜,吊灯,墙上的画,(一个女孩坐在地上抱着一只猫:1.2),写实照片,<lora:SDXLHighDetail_v5:1.1>
带有尖括号的部分是如何在 Web UI 中使用 LoRA 的。你需要指定 LoRA 的文件名以及你想要使用的 LoRA 权重。一些 LoRA 可能允许你使用负权重,但你必须检查。如果你省略“:1.1”部分,则假定默认权重为 1.0。
这个特定的 LoRA 会为你的图片添加细节,例如纹理。例如,你应该会看到更逼真的织物和头发。
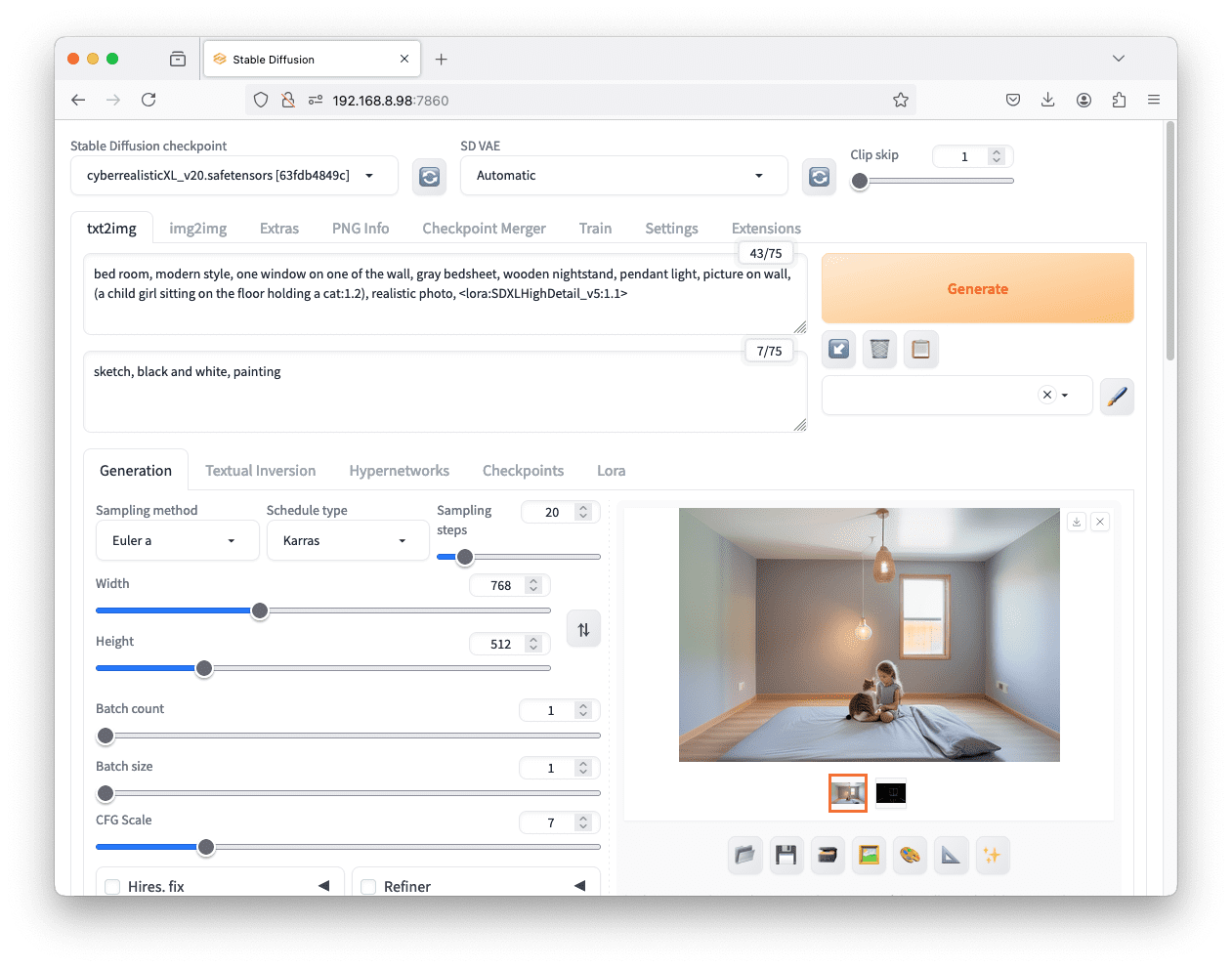
在生成流程中使用 LoRA
你的任务
在 Hugging Face 和 Civitai 上探索 LoRA 模型。你是否知道如何检查 LoRA 是用于 SD1、SD2 还是 SDXL?你是否看到如何使用它们的示例(尤其是在 Civitai 上)?你是否可以在使用 SD 1.5 的 ControlNet 的同时使用 SDXL 的 LoRA?
第八课:更好的脸部
在前一课中,你看到了提示中添加了“一个女孩坐在地上抱着一只猫”。这使得图片更复杂,你应该更容易看到不同模型之间的差异。但是,你也应该会发现,人脸有时看起来不自然。如果你不是生成肖像,而是人类只占图片的一小部分,这一点尤其明显。
有一种方法可以解决这个问题。首先,转到“Extensions”选项卡并安装名为“ADetailer”的插件。安装后你可能需要重新加载 Stable Diffusion Web UI。然后,像之前一样设置提示和其他选项。
之后,你可以展开“ADetailer”部分,选择“face_yolov8n.pt”作为人脸检测器。你可以跳过提示或设置一个像“sleepy face”(困倦的脸)这样的提示。ADetailer 的作用是在扩散过程完成后检测生成图片中的人脸,然后使用你的提示重新生成人脸。这有助于使人脸更逼真,或更精确地调整面部表情。
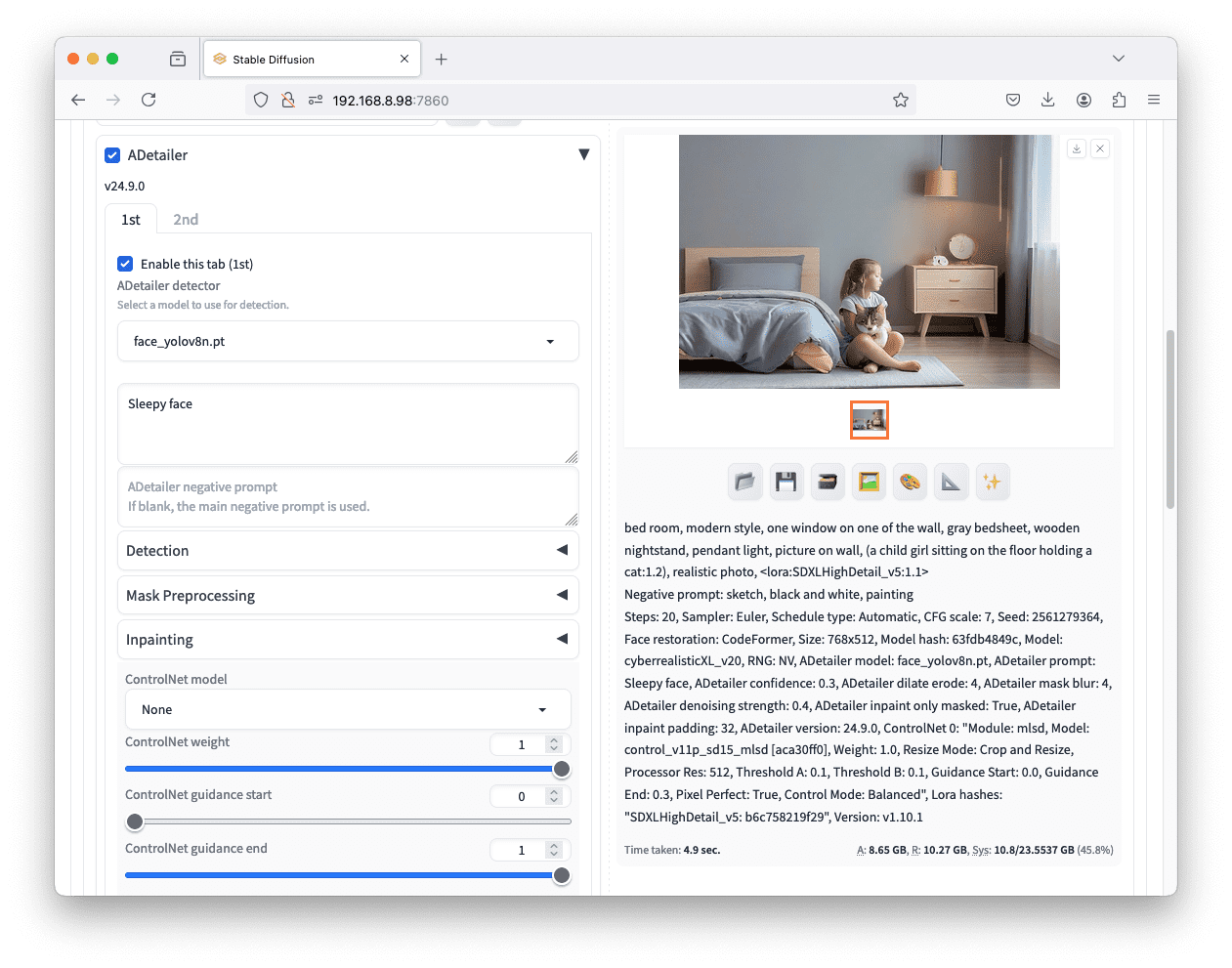
使用 ADetailer 创建逼真的人脸
ADetailer 可以不仅可以润饰人脸,还可以润饰手。你能找到它的检测器吗?在 ReActor 中,你可以提供一个人脸图片,并选择不同的人脸来使用。你如何控制这一点?

照片由 Kune Chan 拍摄。保留部分权利。
为了获得最佳效果,你选择的图片应该正面且清晰,以便能看到更多面部特征。只需上传图片并生成,你应该会看到生成的所有图片都类似于你上传图片中的人物。

使用 ReActor 扩展来生成参考他人肖像的图片
你的任务
在 ADetailer 中,你可以润饰的不仅仅是人脸,还有手。你能找到手部检测器吗?在 ReActor 中,你可以提供一个人脸图片,并选择不同的人脸来使用。你如何控制这一点?
这是最后一课。
结束!(看看你已经走了多远)
您做到了。干得好!
你现在是一位室内设计师,拥有一个名为 Stable Diffusion 的助手。你可以轻松地让计算机构思不同的设计,并为你生成设计草图。这就是如何利用生成式 AI 的力量来节省你的时间,让你更专注于想法,而不是细节。
花点时间回顾一下您已经走了多远。
- 你学会了如何快速设置和运行 Stable Diffusion。
- 你学会了如何使用提示和各种提示语法来控制图像生成。
- 你了解了一些 Web UI 的扩展,它们可以帮助你生成更好的图片。
- 你学会了如何有效地进行生成过程的实验。
不要轻视这一点,你在短时间内取得了长足的进步。这仅仅是你生成式 AI 之旅的开始。继续练习并发展你的技能。
总结
您对这个迷你课程的学习情况如何?
您喜欢这个速成课程吗?
您有任何问题吗?有没有遇到什么难点?
告诉我。在下面留言。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,包含所有可工作的 Python 代码,将你从新手引导到图像生成专家。它教你如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数以及更多……所有这些都旨在帮助你创作令人惊叹的数字艺术。






暂无评论。