scikit-learn 库是日常机器学习和数据科学中最受欢迎的平台之一。其原因在于它建立在 Python 这个功能齐全的编程语言之上。
但是,如何开始使用 scikit-learn 进行机器学习呢?
Kevin Markham 是一位数据科学培训师,他创建了一系列 9 个视频,向您展示了如何开始使用 scikit-learn 进行机器学习。
在本文中,您将逐步了解该系列视频及其涵盖的内容,以帮助您判断这些材料是否对您有用。
使用我的新书《Python 机器学习精通》启动您的项目,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
视频系列概述
Kevin Markham 是一位数据科学培训师,曾任职于计算机编程编码训练营 General Assembly。
Kevin 创立了他自己的培训网站 Data School,并分享数据科学和机器学习方面的培训。他在机器学习方面知识渊博,并且是视频格式的清晰讲解者。
2015 年,Mark 与机器学习竞赛网站 Kaggle 合作,创建了一个包含 9 个视频和博客文章的系列,使用 scikit-learn 对机器学习进行了一个温和的介绍。
这 9 个视频的主题是:
- 什么是机器学习,它是如何工作的?
- 为机器学习设置 Python:scikit-learn 和 IPython Notebook
- 使用著名的 iris 数据集开始使用 scikit-learn
- 使用 scikit-learn 训练机器学习模型
- 比较 scikit-learn 中的机器学习模型
- Python 数据科学:pandas、seaborn、scikit-learn
- 使用交叉验证在 scikit-learn 中选择最佳模型
- 如何在 scikit-learn 中找到最佳模型参数
- 如何在 scikit-learn 中评估分类器
您可以查看 每个视频在 Kaggle 上的博客文章。还有一个 YouTube 播放列表,您可以在其中一个接一个地观看所有 9 个视频。您还可以访问 IPython notebooks,其中包含这 9 个视频中每个视频使用的代码和演示材料。
接下来,我们将回顾该系列中的 9 个视频。
需要 Python 机器学习方面的帮助吗?
参加我为期 2 周的免费电子邮件课程,探索数据准备、算法等等(附带代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
视频 1:计算机如何从数据中学习?
在第一个视频中,Mark 指出该系列的重点是面向 Python 程序员的 scikit-learn。它也不假定您事先了解或熟悉机器学习,但他很快指出,如果不了解机器学习,就无法有效地使用 scikit-learn。
本视频涵盖:
- 什么是机器学习?
- 机器学习的两个主要类别是什么?(监督学习和无监督学习)
- 机器学习有哪些示例?(泰坦尼克号沉没中的乘客生存率)
- 机器学习是如何工作的?(从示例中学习以对新数据进行预测)
他将机器学习定义为:
机器学习是从数据中半自动化地提取知识。
他提供了应用机器学习过程的精美图像概述。

Data School 机器学习流程(取自此处)
视频 2:为机器学习设置 Python
第二个视频主要是一个关于如何使用 IPython notebooks(现在可能已被 Jupyter notebooks 超越)的教程。
涵盖的主题是:
- scikit-learn 的优点和缺点是什么?
- 如何安装 scikit-learn?
- 如何使用 IPython Notebook?
- 有哪些学习 Python 的好资源?
Mark 花了一些时间讨论 scikit-learn 的优点,建议:
- 它为机器学习算法提供了统一的接口。
- 它为每个算法提供了许多调优参数,并使用合理的默认值。
- 它拥有出色的文档。
- 它具有与机器学习相关的丰富功能。
- 它拥有活跃的开发者社区(在 StackOverflow 和邮件列表中)。
在比较 scikit-learn 和 R 时,他认为 R 在机器学习初期更容易上手,但从长远来看,使用 scikit-learn 可以更深入。
他还建议 R 侧重于统计学习,并注重模型的可解释性,而 scikit-learn 则侧重于机器学习,并注重预测准确性。
我认为 R 中的 caret 是一个强大且可能无与伦比的工具。
视频 3:使用 scikit-learn 进行机器学习入门
此视频侧重于机器学习的“Hello World”,即 iris 数据集。这包括加载数据和审查数据。
此视频涵盖的主题是:
- 著名的 iris 数据集是什么,它与机器学习有什么关系?
- 如何将 iris 数据集加载到 scikit-learn 中?
- 如何使用机器学习术语描述数据集?
- scikit-learn 在处理数据时的四个关键要求是什么?
Mark 总结了您希望使用 scikit-learn 处理数据的 4 个要求:
- 输入和响应变量必须是独立的(X 和 y)。
- 输入和响应变量必须是数值型的。
- 输入和响应变量必须是 numpy 数组 (ndarray)。
- 输入和响应变量必须具有一致的形状(行和列)。
视频 4:使用 scikit-learn 进行预测
此视频侧重于在 scikit-learn 中构建第一个机器学习模型,即 K-最近邻模型。
涵盖的主题包括:
- 什么是 K-最近邻分类模型?
- 在 scikit-learn 中进行模型训练和预测的四个步骤是什么?
- 如何将此模式应用于其他机器学习模型?
Mark 总结了在使用 scikit-learn 中的任何模型(API 中称为“估计器”)时必须遵循的 4 个步骤:
- 导入您计划使用的类。
- 实例化估计器(模型就是估计器)。
- 通过调用 .fit() 函数,用数据拟合模型(训练模型)。
- 通过调用 .predict() 函数,为新的观测值(样本外)预测响应。
视频 5:选择机器学习模型
此视频侧重于比较 scikit-learn 中的机器学习模型。
Mark 指出,构建监督学习模型的目标是泛化到样本外数据,即在未来对新数据进行准确预测。
涵盖的主题包括:
- 如何为我的监督学习任务选择模型?
- 如何选择该模型的最佳调优参数?
- 如何估计我的模型在样本外数据的可能性能?
此视频开始研究使用单个数据集估计模型性能的方法,从测试准确性开始,然后介绍使用训练/测试拆分并查看测试准确性。
视频 6:Python 数据科学:pandas 和 scikit-learn
此视频介绍与 scikit-learn 一起使用的相关库,特别是用于加载和处理数据的 pandas 库,以及用于简单清晰数据可视化的 seaborn 库。
此视频还从分类转向回归问题,即对实值数据的预测。构建线性回归模型并审查不同的性能指标来评估构建的模型。
以下是此较长视频中涵盖的主题列表:
- 如何使用 pandas 库将数据读入 Python?
- 如何使用 seaborn 库可视化数据?
- 什么是线性回归,它是如何工作的?
- 如何在 scikit-learn 中训练和解释线性回归模型?
- 回归问题有哪些评估指标?
- 如何选择要在模型中包含哪些特征?
视频 7:交叉验证简介
此视频深入探讨了通过使用 k-折交叉验证来评估机器学习算法在未见过数据上性能的标准方法。
Mark 指出,仅使用训练准确性会过度拟合已知数据,模型将无法很好地泛化。仅使用测试数据进行训练/测试拆分会导致高方差,这意味着它对训练集和测试集的具体内容很敏感。他认为交叉验证在这些问题之间提供了良好的平衡。
本视频涵盖以下主题:
- 使用训练/测试拆分程序进行模型评估的缺点是什么?
- K-折交叉验证如何克服此限制?
- 如何使用交叉验证来选择调优参数、在模型之间进行选择以及选择特征?
- 交叉验证有哪些可能的改进?
演示了用于模型选择、调优模型参数和特征选择的交叉验证。
Mark 列出了从交叉验证中获得最大收益的三个技巧:
- 使用重复的 10 折交叉验证,以进一步降低估计性能的方差。
- 使用一个保留的验证数据集来确认从交叉验证中看到的估计,并捕获任何数据泄露错误。
- 在交叉验证折叠内执行所有特征选择和工程,以避免数据泄露错误。
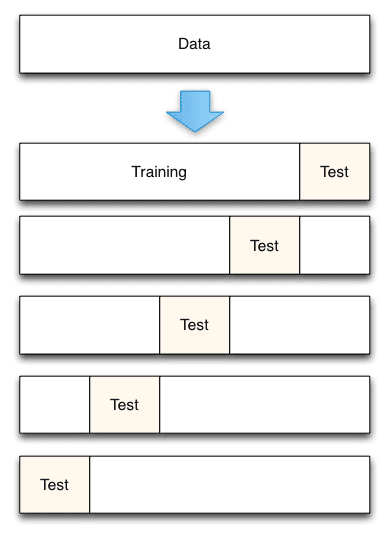
Data School K-折交叉验证(来自此处)
视频 8:寻找最佳模型参数
此视频侧重于您可用于调整机器学习算法参数(称为超参数)的技术。
Mark 介绍了用于算法调优的交叉验证,如何使用网格搜索尝试参数组合,以及随机搜索参数组合以提高效率。
本视频涵盖以下主题:
- 如何使用 K-折交叉验证来搜索最佳调优参数?
- 如何更有效地进行此过程?
- 如何同时搜索多个调优参数?
- 在进行实际预测之前,您需要对这些调优参数做什么?
- 如何降低此过程的计算成本?
视频 9:如何在 scikit-learn 中评估分类器
这是本系列的最后一个视频,也是最长的视频。
在本视频中,Mark 涵盖了大量内容,重点介绍可用于评估分类问题上的机器学习模型的技术。
此视频涵盖的主题是:
- 模型评估的目的是什么?有哪些常见的评估程序?
- 分类准确性的用法是什么?它的局限性是什么?
- 混淆矩阵如何描述分类器的性能?
- 可以从混淆矩阵计算出哪些指标?
- 如何通过更改分类阈值来调整分类器性能?
- ROC 曲线的目的是什么?
- 曲线下面积 (AUC) 与分类准确性有何不同?
Mark 花时间仔细描述了混淆矩阵、灵敏度和特异性的详细信息以及 ROC 曲线。
总结
在本帖中,您了解了 Kevin Markham 的视频系列,标题为“使用 scikit-learn 进行机器学习入门”。
您了解到它包含 9 个视频。
- 什么是机器学习,它是如何工作的?
- 为机器学习设置 Python:scikit-learn 和 IPython Notebook
- 使用著名的 iris 数据集开始使用 scikit-learn
- 使用 scikit-learn 训练机器学习模型
- 比较 scikit-learn 中的机器学习模型
- Python 数据科学:pandas、seaborn、scikit-learn
- 使用交叉验证在 scikit-learn 中选择最佳模型
- 如何在 scikit-learn 中找到最佳模型参数
- 如何在 scikit-learn 中评估分类器
Mark 制作了一个出色的视频系列,向您介绍了 scikit-learn 机器学习。我强烈推荐观看全部内容。
您是否观看过这些视频的部分或全部内容?您觉得怎么样?在评论中分享您的想法。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






{kind=link}
{kind=link}
暂无评论。