池化可用于对特征图内容进行下采样,在保持其显著特征的同时,减少其宽度和高度。
深度卷积神经网络的一个问题是,特征图的数量通常随网络深度的增加而增加。当使用较大的滤波器尺寸(如 5x5 和 7x7)时,此问题可能导致参数数量和所需计算量急剧增加。
为了解决这个问题,可以使用 1x1 卷积层,它提供通道式池化,通常称为特征图池化或投影层。这种简单的技术可用于降维,减少特征图的数量,同时保留其显著特征。它也可以直接用于创建特征图的一对一投影,以跨通道池化特征,或增加特征图的数量,例如在传统池化层之后。
在本教程中,您将学习如何使用 1x1 滤波器来控制卷积神经网络中特征图的数量。
完成本教程后,您将了解:
- 1x1 滤波器可用于创建特征图堆栈的线性投影。
- 1x1 创建的投影可以充当通道式池化,并用于降维。
- 1x1 创建的投影也可以直接使用,或用于增加模型中特征图的数量。
通过我的新书《计算机视觉深度学习》**启动您的项目**,其中包括*分步教程*和所有示例的 *Python 源代码*文件。
让我们开始吧。

1x1 卷积简介:减少卷积神经网络的复杂性
照片版权,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 跨通道卷积
- 特征图过多问题
- 使用 1x1 滤波器对特征图进行下采样
- 如何使用 1x1 卷积的示例
- CNN 模型架构中 1x1 滤波器的示例
跨通道卷积
回想一下,卷积操作是较小的滤波器对较大输入的线性应用,从而产生输出特征图。
应用于输入图像或输入特征图的滤波器总是产生一个数字。滤波器对输入进行系统地从左到右、从上到下的应用,从而产生二维特征图。一个滤波器创建一个对应的特征图。
滤波器的深度或通道数必须与输入相同,然而,无论输入和滤波器的深度如何,结果输出都是一个数字,一个滤波器创建一个具有单个通道的特征图。
让我们通过一些例子来具体说明这一点。
- 如果输入有一个通道,例如灰度图像,则将以 3x3x1 的块应用 3x3 滤波器。
- 如果输入图像有红色、绿色和蓝色的三个通道,则将以 3x3x3 的块应用 3x3 滤波器。
- 如果输入是来自另一个卷积或池化层的特征图块,深度为 64,则将以 3x3x64 的块应用 3x3 滤波器,以创建构成单个输出特征图的单个值。
一个卷积层的输出深度仅由应用于输入的并行滤波器数量定义。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
特征图过多问题
卷积层中使用的输入深度或滤波器数量通常随网络深度的增加而增加,导致结果特征图的数量增加。这是一种常见的模型设计模式。
此外,某些网络架构(例如 Inception 架构)也可能连接多个卷积层的输出特征图,这可能还会急剧增加后续卷积层的输入深度。
卷积神经网络中大量的特征图可能会导致问题,因为卷积操作必须沿着输入深度向下执行。如果执行的卷积操作相对较大,例如 5x5 或 7x7 像素,则这是一个特殊问题,因为它可能导致参数(权重)和执行卷积操作所需的计算量(大的空间和时间复杂度)显著增加。
池化层旨在缩小特征图,并系统地将网络中特征图的宽度和高度减半。然而,池化层不会改变模型中滤波器、深度或通道的数量。
深度卷积神经网络需要一种相应的池化类型层,该层可以对深度或特征图的数量进行下采样或减少。
使用 1x1 滤波器对特征图进行下采样
解决方案是使用 1x1 滤波器对深度或特征图的数量进行下采样。
一个 1x1 滤波器在输入中的每个通道将只有一个参数或权重,并且像任何滤波器的应用一样,会产生一个输出值。这种结构允许 1x1 滤波器像单个神经元一样工作,其输入来自输入中每个特征图的相同位置。然后,这个单个神经元可以系统地以步幅为一的方式,从左到右、从上到下进行应用,无需填充,从而产生一个与输入宽度和高度相同的特征图。
1x1 滤波器非常简单,不涉及输入中的任何相邻像素;它可能不被视为卷积操作。相反,它是对输入的线性加权或投影。此外,与其它卷积层一样,也使用了非线性,从而允许投影对输入特征图执行非平凡的计算。
这个简单的 1x1 滤波器提供了一种有效总结输入特征图的方法。反过来,使用多个 1x1 滤波器允许调整要创建的输入特征图总结的数量,从而有效地根据需要增加或减少特征图的深度。
因此,带有 1x1 滤波器的卷积层可以在卷积神经网络中的任何位置用于控制特征图的数量。因此,它通常被称为投影操作或投影层,甚至特征图或通道池化层。
现在我们知道可以使用 1x1 滤波器控制特征图的数量,让我们通过一些例子来具体说明。
如何使用 1x1 卷积的示例
我们可以通过一些例子来具体说明 1x1 滤波器的使用。
假设我们有一个卷积神经网络,它期望输入颜色图像的方形形状为 256x256x3 像素。
然后,这些图像通过第一个隐藏层,该层有 512 个滤波器,每个滤波器尺寸为 3x3,采用相同填充,然后是ReLU 激活函数。
下面的示例演示了这个简单的模型。
|
1 2 3 4 5 6 7 8 |
# 简单 CNN 模型示例 from keras.models import Sequential from keras.layers import Conv2D # 创建模型 model = Sequential() model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3))) # 总结模型 model.summary() |
运行示例将创建模型并总结模型架构。
不出所料;第一个隐藏层的输出是一个形状为 256x256x512 的三维特征图块。
|
1 2 3 4 5 6 7 8 9 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 512) 14336 ================================================================= 总参数:14,336 可训练参数:14,336 不可训练参数: 0 _________________________________________________________________ |
投影特征图示例
1x1 滤波器可用于创建特征图的投影。
创建的特征图数量将相同,并且效果可能是对已提取特征的细化。这通常被称为通道式池化,而不是每个通道上的传统特征式池化。它可以按以下方式实现:
|
1 |
model.add(Conv2D(512, (1,1), activation='relu')) |
我们可以看到,我们使用了相同数量的特征,并且仍然在滤波器应用后使用了修正线性激活函数。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 |
# 1x1 滤波器用于投影的示例 from keras.models import Sequential from keras.layers import Conv2D # 创建模型 model = Sequential() model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3))) model.add(Conv2D(512, (1,1), activation='relu')) # 总结模型 model.summary() |
运行示例将创建模型并总结其架构。
我们可以看到,特征图的宽度或高度没有改变,并且通过设计,特征图的数量通过简单的投影操作保持不变。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 512) 14336 _________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 512) 262656 ================================================================= 总参数:276,992 可训练参数:276,992 不可训练参数: 0 _________________________________________________________________ |
减少特征图的例子
1x1 滤波器可用于减少特征图的数量。
这是这种类型滤波器最常见的应用,因此该层通常被称为特征图池化层。
在这个例子中,我们可以将深度(或通道)从 512 减少到 64。如果我们要添加到模型中的后续层是另一个具有 7x7 滤波器的卷积层,这可能会很有用。这些滤波器将只应用于 64 的深度,而不是 512。
|
1 |
model.add(Conv2D(64, (1,1), activation='relu')) |
64 个特征图的构成与原始的 512 个不同,但包含一个有用的降维总结,它捕获了显著特征,因此 7x7 操作对 64 个特征图可能与对原始 512 个特征图具有相似的效果。
此外,一个具有 64 个滤波器的 7x7 卷积层,如果应用于第一个隐藏层输出的 512 个特征图,将产生大约一百万个参数(权重)。如果首先使用 1x1 滤波器将特征图的数量减少到 64,那么 7x7 层所需的参数数量大约只有 200,000,这是一个巨大的差异。
使用 1x1 滤波器进行降维的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 |
# 1x1 滤波器用于降维的示例 from keras.models import Sequential from keras.layers import Conv2D # 创建模型 model = Sequential() model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3))) model.add(Conv2D(64, (1,1), activation='relu')) # 总结模型 model.summary() |
运行示例将创建模型并总结其结构。
我们可以看到特征图的宽度和高度没有改变,但特征图的数量从 512 减少到 64。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 512) 14336 _________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 64) 32832 ================================================================= 总参数:47,168 可训练参数:47,168 不可训练参数: 0 _________________________________________________________________ |
增加特征图的示例
1x1 滤波器可用于增加特征图的数量。
这是在池化层之后、应用另一个卷积层之前使用的常见操作。
滤波器的投影效果可以根据需要多次应用于输入,允许特征图的数量按比例增加,并且其组成仍能捕获原始图像的显著特征。
我们可以将第一个隐藏层输入的特征图数量从 512 增加到 1,024,即两倍。
|
1 |
model.add(Conv2D(1024, (1,1), activation='relu')) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 |
# 1x1 滤波器用于增加维度示例 from keras.models import Sequential from keras.layers import Conv2D # 创建模型 model = Sequential() model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3))) model.add(Conv2D(1024, (1,1), activation='relu')) # 总结模型 model.summary() |
运行示例将创建模型并总结其结构。
我们可以看到,特征图的宽度和高度没有改变,并且特征图的数量从 512 增加到 1,024,即两倍。
|
1 2 3 4 5 6 7 8 9 10 11 |
_________________________________________________________________ 层(类型) 输出形状 参数数量 ================================================================= conv2d_1 (Conv2D) (None, 256, 256, 512) 14336 _________________________________________________________________ conv2d_2 (Conv2D) (None, 256, 256, 1024) 525312 ================================================================= 总参数:539,648 可训练参数:539,648 不可训练参数: 0 _________________________________________________________________ |
现在我们已经熟悉了如何使用 1x1 滤波器,接下来让我们看看一些在卷积神经网络模型架构中使用了 1x1 滤波器的示例。
CNN 模型架构中 1x1 滤波器的示例
在本节中,我们将重点介绍一些重要的示例,其中 1x1 滤波器已成为现代卷积神经网络模型架构的关键元素。
网络中的网络
1x1 滤波器可能最早由 Min Lin 等人在 2013 年发表的论文《Network In Network》中描述和推广。
在论文中,作者提出了对 MLP 卷积层和跨通道池化的需求,以促进跨通道学习。
这种级联的跨通道参数池化结构允许复杂的、可学习的跨通道信息交互。
— 《Network In Network》,2013 年。
他们将 1x1 卷积层描述为跨通道参数池化的一种特定实现,而这正是 1x1 滤波器所实现的。
每个池化层对输入特征图执行加权线性重组,然后通过整流线性单元。 […] 跨通道参数池化层也等同于使用 1x1 卷积核的卷积层。
— 《Network In Network》,2013 年。
Inception 架构
1x1 滤波器被明确用于降维和在池化后增加特征图维度,这在 Christian Szegedy 等人在其 2014 年论文《Going Deeper with Convolutions》中描述的 GoogLeNet 模型中使用的 Inception 模块设计中。
该论文描述了一个“Inception 模块”,其中输入特征图块由不同的卷积层并行处理,每个卷积层使用不同大小的滤波器,其中 1x1 大小滤波器是使用的层之一。
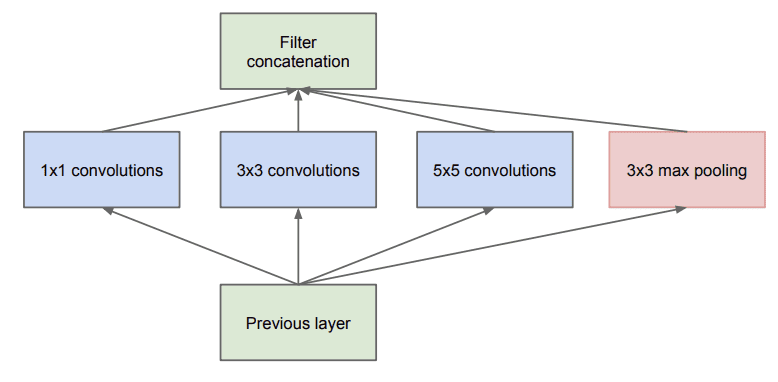
朴素 Inception 模块示例
摘自《Going Deeper with Convolutions》,2014 年。
并行层的输出然后按通道堆叠,导致非常深的卷积层堆栈,由随后的 Inception 模块处理。
池化层输出与卷积层输出的合并将导致阶段之间的输出数量不可避免地增加。即使这种架构可能覆盖最优的稀疏结构,它也会非常低效地实现,导致在几个阶段内计算量爆炸式增长。
— Going Deeper with Convolutions,2014。
然后重新设计 Inception 模块,使用 1x1 滤波器减少特征图数量,然后使用 5x5 和 7x7 大小滤波器的并行卷积层。
这导致了所提出架构的第二个思想:在计算需求过高时,明智地应用降维和投影。 […] 也就是说,在昂贵的 3x3 和 5x5 卷积之前,使用 1x1 卷积进行降维。除了用作降维之外,它们还包括使用整流线性激活,这使它们具有双重目的。
— Going Deeper with Convolutions,2014。
1x1 滤波器还用于在池化后增加特征图的数量,人工创建更多降采样特征图内容的投影。
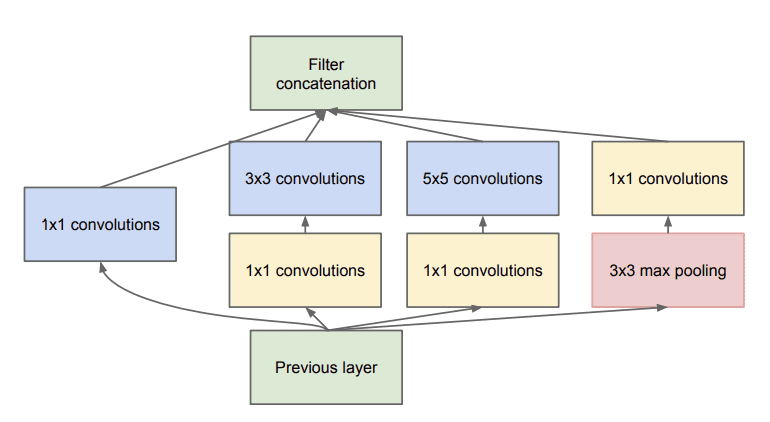
带有降维的 Inception 模块示例
摘自《Going Deeper with Convolutions》,2014 年。
残差架构
1x1 滤波器被用作一种投影技术,以匹配输入滤波器数量与残差模块输出,这在 Kaiming He 等人在其 2015 年论文《Deep Residual Learning for Image Recognition》中设计的残差网络中。
作者描述了一种由“残差模块”组成的架构,其中模块的输入被添加到模块的输出中,这被称为快捷连接。
由于输入被添加到模块的输出中,因此维度必须在宽度、高度和深度方面匹配。宽度和高度可以通过填充来保持,尽管 1x1 滤波器用于根据需要改变输入的深度,以便它可以与模块的输出相加。这种连接被称为投影快捷连接。
此外,残差模块采用瓶颈设计,使用 1x1 滤波器减少特征图数量,以提高计算效率。
这三层是 1x1、3x3 和 1x1 卷积,其中 1x1 层负责减少和增加(恢复)维度,使 3x3 层成为具有较小输入/输出维度的瓶颈。
— 用于图像识别的深度残差学习,2015年。
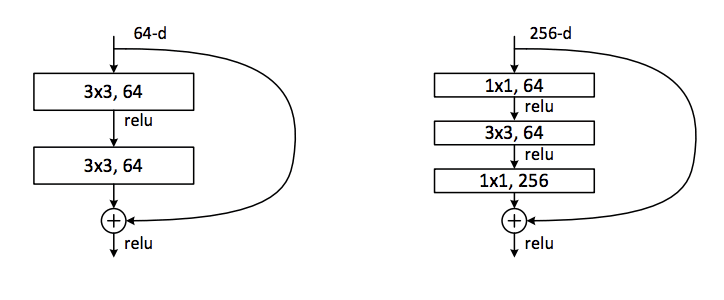
带有快捷连接的普通和瓶颈残差模块示例
摘自《Deep Residual Learning for Image Recognition》,2015 年。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 网络中的网络, 2013.
- 使用卷积网络更深入, 2014.
- 用于图像识别的深度残差学习, 2015.
文章
- 1x1 卷积——反直觉的有用, 2016.
- Yann LeCun 关于 CNN 中没有全连接层, 2015.
- Networks in Networks and 1x1 Convolutions,YouTube.
总结
在本教程中,您学习了如何使用 1x1 滤波器来控制卷积神经网络中特征图的数量。
具体来说,你学到了:
- 1x1 滤波器可用于创建特征图堆栈的线性投影。
- 1x1 创建的投影可以充当通道式池化,并用于降维。
- 1x1 创建的投影也可以直接使用,或用于增加模型中特征图的数量。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






你好 Jason,你知道如何实现时间卷积网络 (TCN) 进行多元时间序列预测吗?我不知道怎么写代码。
抱歉,我没有关于该主题的教程,我希望将来能涵盖它。
谢谢您!您的教程帮了我很多!期待您的 TCN 教程。
谢谢。
太棒了,先生,这种方法我们可以用于语义分割吗?用于解码器
通常,Mask RCNN 等方法用于图像的语义分割。
好文章,
如果我们想在动态池化层中实现呢?
等待建议。
谢谢你
什么是动态池化层?
Jason,
如果我有您正在训练的模型
比如说
model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3)))
model.add(Conv2D(1024, (1,1), activation='relu'))
我将如何考虑特征图的块
如果您总结模型,您可以看到每一层的输出形状。
Jason,
我尝试了 CNN 模型的特征图并得到了输出,现在我想尝试显示相同模型的不同块
假设
model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3)))
model.add(Conv2D(1024, (1,1), activation='relu'))
我如何考虑这些块
你具体指的是什么?
亲爱的 Jason,您说的“
1- 输入中每个通道的单个参数或权重。
2- 像一个单神经元一样工作,其输入来自每个特征图的相同位置。
谢谢您的好文章。
1. 每个滤波器都有权重或可学习参数。
2. 单个权重用于解释整个输入或创建整个输出特征图。
这有帮助吗?讲得通吗?
您愿意分享您的 PyTorch 版本作品吗?
PyTorch 很受欢迎,如果您能添加您的代码的 PyTorch 版本,我们将非常感谢您。
感谢您的建议。
嗨,Jason,
我想知道 Conv2D(512, (1,1), activation='relu') 层和 Dense(512, activation='relu') 层之间有什么区别?我是一个初学者(几个月的神经网络经验),可能遗漏了一些东西,但从我的角度来看,kernel_size=(1,1) 的 Conv2D 层等同于 Dense 层中的权重,并且 Dense 层和 Conv2D 层都有偏差,那么我是否遗漏了其他差异?或者 Conv2D 带有 kernel_size=(1,1) 而不是 Dense 有什么好处?
提前感谢,这篇文章非常有帮助!
差别很小。
实际上,我认为在处理输入方面可能存在差异,例如,卷积在通道缩减方面做得很好,不确定全连接层是否会做同样的事情。
需要进行分析才能给出有帮助/真实的答案。
谢谢!我正在训练一些模型来对其进行真实世界分析,并且它似乎给出了可比较的结果,但我只是想确认这些结果并非特定于我的应用程序。
干得好!
非常有帮助。
谢谢。
关于1x1卷积,您说过“这些滤波器仅应用于64深度而不是512深度”,但根据吴恩达的说法,每个滤波器的大小都是1x1x前一个通道大小,因此单个滤波器将是1x1x512——如果您需要将通道从512减少到64,只能通过添加64个这样的滤波器来减少。您的说法和他的说法是矛盾的。
很抱歉造成困惑。
您有关于单图像SRCNN的教程吗?
目前还没有。
在瓶颈残差块中,3x3卷积之前的1x1卷积有什么影响?
好问题,来自教程
嗨,Jason,
不确定这对所有人来说是否显而易见,至少对我来说不是。在第一个简单示例中,您说“第一个隐藏层的输出是……256x256x512。” 我想知道如何计算模型中显示的总参数数量14336,您可以通过计算3x3x3x512+512=14336来获得。
也许您在另一个教程中涵盖了这个问题?
根据指定的模型架构,有标准的权重数量和输出数量计算方法。抱歉,我没有关于这个主题的教程——至少我不认为我有。
我不太明白“用1x1卷积减少特征图”是什么意思。
在您的示例中,一个512个滤波器的3x3 conv2d后面跟着一个64个滤波器的1x1 conv2d“减少”了特征图
model.add( Conv2D(512, (3,3), …
model.add( Conv2D(64, (1,1), …
第一行的结果是512个通道的特征图。在1x1层之后,结果变成64个512通道的特征图。数据量是增加而不是减少。为什么您认为使用1x1卷积可以简化复杂性?
我太困惑了
好问题。
将其视为另一个卷积层输出的变换。它让我们对将输入转换为多少个映射有精细的控制。如果你看看增加和减少映射数量的示例代码,这就有意义了。
你好,
我正在尝试实现一篇论文,现在我被卡住了。您能帮我解决问题吗?
https://stackoverflow.com/q/65676671/14922100
此致,
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-comment-on-my-stackoverflow-question
这是第一个真正解释滤波器深度的指南!我到目前为止看过/读过的所有其他关于卷积神经网络的指南都忽略了滤波器/核与输入层深度相同的事实,并且进行ReLU计算一个核宽度 x 核高度 x 核深度值(3D!)块的一个输出标量,从而将深度减少到1(并用核数量再次增加)。
非常感谢您在这里正确解释了这一点!
谢谢!
我有一个关于Bernd评论的问题。
假设我有一个深奥的特征图深度,我想用1x1卷积来减少它
model.add(Conv2D(512, (3,3), padding='same', activation='relu', input_shape=(256, 256, 3)))
model.add(Conv2D(42, (1,1), activation=’relu’))
这在底层是如何工作的(如果它工作的话)?
根据评论,我假设一个1x1x1卷积得到深度为1的特征图,然后
42个重复投影将深度增加到42。当减少特征图时,它总是这样工作吗?
而且,这是对1x1卷积作用和工作原理的最佳解释。
非常感谢。
你好Thomas……以下资源可能会有帮助
https://machinelearning.org.cn/how-to-visualize-filters-and-feature-maps-in-convolutional-neural-networks/
嗨,Jason,您能解释一下您是如何通过1x1卷积获得262656个参数的吗?
256x256的输入只是一个示例,它并没有什么特别之处。
嘿,谢谢你的教程
你知道计算1*1卷积的算法是什么吗?
您是在询问上面某个示例代码的解释吗?
你说的以下内容究竟是什么意思?
“它也可以直接用于创建特征图的一对一投影,以在通道上汇集特征或增加特征图的数量,例如在传统池化层之后。”
什么是一对一投影?如果我们正在减少特征图的数量,事情如何能一对一?或者你只是想表达不同的意思?
一对一投影是一个数学术语,意思是转换。它只是指我们以不同的方式看待特征,而不是组合/分离特征。减少特征的数量是网络中其他层(例如池化层)的工作。
有没有替代1x1卷积的方法?有没有更简单的方法来对所有通道进行求和?
也许是 tensor.sum(axis)