计算学习理论,或称统计学习理论,是指用于量化学习任务和算法的数学框架。
这些是机器学习的子领域,机器学习从业者不必深入了解它们,就可以在广泛的问题上取得良好的成果。尽管如此,它仍然是一个子领域,对其中一些更突出的方法有高层次的了解,可以为从数据中学习的更广泛任务提供见解。
在本篇文章中,您将了解计算学习理论在机器学习中的初步介绍。
阅读本文后,你将了解:
- 计算学习理论使用形式化方法来研究学习任务和学习算法。
- PAC学习提供了一种量化机器学习任务计算难度的方法。
- VC维度提供了一种量化机器学习算法计算能力的方法。
开始您的项目,阅读我的新书《机器学习概率》,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

计算学习理论简明入门
照片由someone10x拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 计算学习理论
- PAC学习(学习问题理论)
- VC维度(学习算法理论)
计算学习理论
计算学习理论,简称CoLT,是一个研究领域,涉及将形式化数学方法应用于学习系统。
它试图利用理论计算机科学的工具来量化学习问题。这包括描述特定学习任务的难度。
计算学习理论可以被认为是统计学习理论(简称SLT)的扩展或姊妹领域,它使用形式化方法来量化学习算法。
- 计算学习理论(CoLT):学习任务的形式化研究。
- 统计学习理论(SLT):学习算法的形式化研究。
学习任务与学习算法的这种划分是任意的,在实践中,这两个领域之间存在很大的重叠。
通过考虑学习者的计算复杂性,可以扩展统计学习理论。这个领域被称为计算学习理论或COLT。
— 第 210 页,《机器学习:概率视角》,2012年。
在现代用法中,它们可能被认为是同义词。
… 一个称为计算学习理论的理论框架,有时也称为统计学习理论。
— 第 344 页,《模式识别与机器学习》,2006年。
计算学习理论的重点通常是监督学习任务。对实际问题和实际算法进行形式化分析非常具有挑战性。因此,通常通过关注二元分类任务甚至简单的基于规则的二元系统来简化分析的复杂性。因此,这些定理的实际应用可能有限,或者对于实际问题和算法来说难以解释。
学习中未解决的主要问题是:我们如何确定我们的学习算法产生了一个能够正确预测以前未见过输入的假设?
— 第 713 页,《人工智能:现代方法》第3版,2009年。
计算学习理论中探讨的问题可能包括:
- 我们如何知道模型对目标函数有很好的近似?
- 应该使用哪个假设空间?
- 我们如何知道我们得到的是局部最优还是全局最优解?
- 如何避免过拟合?
- 需要多少数据样本?
作为一名机器学习从业者,了解计算学习理论及其一些主要研究领域可能会有所帮助。该领域为我们在数据上拟合模型时所要实现的目标提供了有用的基础,并且可能为这些方法提供见解。
有许多子研究领域,尽管计算学习理论中最广泛讨论的两个研究领域可能是:
- PAC学习。
- VC维度。
简而言之,我们可以说PAC学习是机器学习问题理论,VC维度是机器学习算法理论。
作为从业者,您可能会遇到这些主题,了解它们是很有用的。让我们仔细看看每一个。
如果您想深入了解计算学习理论领域,我推荐这本书:
- 计算学习理论导论, 1994.
PAC学习(学习问题理论)
概率近似正确学习,或PAC学习,是指由Leslie Valiant开发的理论机器学习框架。
PAC学习旨在量化学习任务的难度,并可被视为计算学习理论的首要子领域。
考虑在监督学习中,我们试图近似一个未知的底层输入到输出的映射函数。我们不知道这个映射函数是什么样子的,但我们怀疑它的存在,并且我们有来自该函数产生的数据的例子。
PAC学习关注的是找到一个与未知目标函数非常匹配的假设(拟合模型)所需的计算工作量。
有关在机器学习中使用“假设”来指代拟合模型的更多信息,请参阅教程:
其思想是,一个坏的假设会根据它在新数据上的预测被发现,例如基于它的泛化误差。
一个能正确预测大部分或大量预测的假设,例如具有较低的泛化误差,很可能就是目标函数的一个很好的近似。
基本原理是,任何严重错误的假设几乎肯定会在少量样本后以高概率被“揭穿”,因为它会做出错误的预测。因此,任何与足够大的训练样本集一致的假设都不太可能是严重错误的:也就是说,它必须是概率近似正确的。
— 第 714 页,《人工智能:现代方法》第3版,2009年。
这种概率语言赋予了该定理其名称:“概率近似正确”。也就是说,一个假设试图“近似”一个目标函数,并且如果它具有较低的泛化误差,它“可能”是好的。
PAC学习算法是指返回一个PAC假设的算法。
使用形式化方法,可以为监督学习任务指定最小泛化误差。然后,该定理可用于估计确定一个假设是否为PAC所需的该问题域的预期样本数量。也就是说,它提供了一种估计找到PAC假设所需的样本数量的方法。
PAC框架的目标是了解数据集需要多大才能提供良好的泛化。它还给出了学习的计算成本的界限……
— 第 344 页,《模式识别与机器学习》,2006年。
此外,在PAC框架下,一个假设空间(机器学习算法)是有效的,如果一个算法能在多项式时间内找到一个PAC假设(拟合模型)。
如果存在一个多项式时间算法可以识别出PAC函数,那么一个假设空间就被称为是有效的PAC可学习的。
— 第 210 页,《机器学习:概率视角》,2012年。
有关PAC学习的更多信息,请参阅该主题的开创性著作,题为:
- 概率近似正确:自然界在复杂世界中学习和繁荣的算法, 2013.
VC维度(学习算法理论)
Vapnik–Chervonenkis理论,简称VC理论,是指由Vladimir Vapnik和Alexey Chervonenkis开发的理论机器学习框架。
VC理论学习旨在量化学习算法的能力,并可被视为统计学习理论的首要子领域。
VC理论包含许多要素,其中最著名的是VC维度。
VC维度量化了假设空间的复杂性,例如,给定表示和学习算法可以拟合的模型。
一种考虑假设空间(可以拟合的模型空间)复杂性的方法是基于它包含的不同的假设数量,以及可能如何导航该空间。VC维度是一种巧妙的方法,它反而衡量了目标问题中的样本数量,这些样本可以被该空间中的假设区分开来。
VC维度通过H所能完全区分的X的最大有限子集的大小来衡量假设空间的复杂性……
— 第 214 页,《机器学习》,1997年。
VC维度估计了分类机器学习算法在特定数据集(样本数量和维度)上的能力或容量。
形式上,VC维度是训练数据集中的最大样本数,算法的假设空间(或特定的拟合模型)可以“打散”它。
定义在实例空间X上的假设空间H的Vapnik-Chervonenkis维度,VC(H),是H能够“打散”的X的最大有限子集的大小。
— 第 215 页,《机器学习》,1997年。
打散或打散集,就数据集而言,意味着特征空间中的点可以被空间中的假设选择或分离,使得分离组中的样本标签是正确的(无论它们碰巧是什么)。
一组点是否能被算法打散取决于假设空间和点的数量。
例如,一条直线(假设空间)可以用来打散三个点,但不能打散四个点。
在二维平面上的任何三个点,无论其类别标签是0还是1,都可以被直线“正确”地按标签分割,例如被打散。但是,在平面上存在四个点,无论其二元类别标签如何,都无法被直线正确地按标签分割,例如无法被打散。相反,必须使用另一种“算法”,例如椭圆。
下图清楚地说明了这一点。
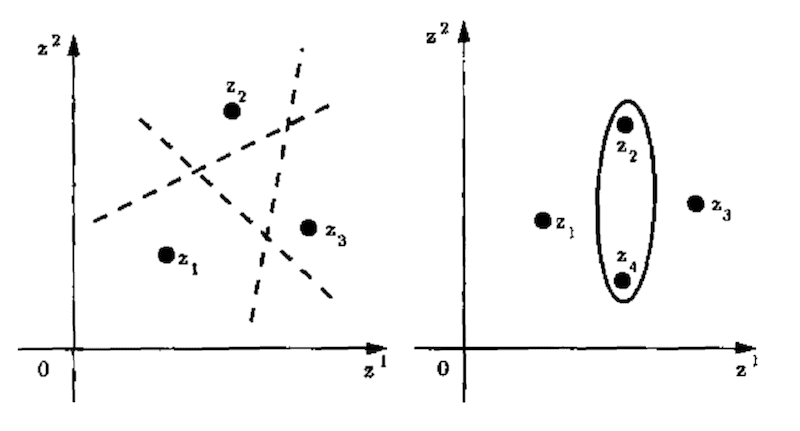
直线假设打散3个点和椭圆假设打散4个点的示例
摘自第81页,《统计学习理论的本质》,1999年。
因此,机器学习算法的VC维度是特定算法配置(超参数)或特定拟合模型能够打散的数据集中的最大数据点数。
一个在所有情况下都预测相同值的分类器,其VC维度为0,即没有点。较大的VC维度表明算法非常灵活,尽管这种灵活性可能伴随着过拟合的额外风险。
VC维度被用作PAC学习框架的一部分。
PAC学习中的一个关键量是Vapnik-Chervonenkis维度,或简称VC维度,它提供了函数空间的复杂性度量,并允许PAC框架扩展到包含无限数量函数的空间。
— 第 344 页,《模式识别与机器学习》,2006年。
有关PCA学习的更多信息,请参阅该主题的开创性著作,题为:
- 统计学习理论的本质, 1999.
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 概率近似正确:自然界在复杂世界中学习和繁荣的算法, 2013.
- 人工智能:现代方法,第3版, 2009.
- 计算学习理论导论, 1994.
- 机器学习:概率视角, 2012.
- 统计学习理论的本质, 1999.
- 模式识别与机器学习, 2006.
- 机器学习, 1997.
文章
总结
在本篇文章中,您了解了计算学习理论在机器学习中的初步介绍。
具体来说,你学到了:
- 计算学习理论使用形式化方法来研究学习任务和学习算法。
- PAC学习提供了一种量化机器学习任务计算难度的方法。
- VC维度提供了一种量化机器学习算法计算能力的方法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。


")
")
")


有可能解释强化学习吗?
是的,请看这个
https://machinelearning.org.cn/faq/single-faq/do-you-have-tutorials-on-deep-reinforcement-learning
亲爱的 Jason,
计算学习理论能否帮助我们确定算法需要多少样本才能显示出有用的结果?您能否在文章中添加一个关于它是如何应用的例子?我不是在要代码。一个案例研究,就像你想根据相机显示的图像将水果分为香蕉、苹果和橙子。然后,如果你应用计算学习理论,将会发生什么。
有人说可以,实践中说不可以。
R^2 中的线性分类器是否应该具有 2 个 VC 维度而不是 3 个?
我不确定,抱歉。
我非常确定您对此不再感兴趣,但也许对于其他看到您评论的人来说:它是 VC 3,因为它很容易用直线分隔 3 个点。实际上,本文中的图已经很好地解释了这一点。
您的陈述“二维平面上的任何三个点,无论其类别标签是0还是1,都可以被直线“正确”地按标签分割,例如被打散。”是错误的。假设空间VC维度的定义是存在一种点的配置,而不是适用于所有配置。在您的解释中,这意味着您只需要一种配置/放置3个点的方式,对于所有这些点的标记,直线都可以对它们进行分类。如果不存在一种配置4个点的方式,对于所有标记,直线都无法正确分类,那么直线集合的VC维度就是3。事实上,如果你把3个点放在一条线上,那么你就无法对它们进行分类,对于所有标记,都用一条直线!请参阅这个问题https://ai.stackexchange.com/q/27854/2444。
感谢您的分析和反馈!
干得好。
谢谢你,Aniket!