渐进增长式生成对抗网络(Progressive Growing GAN)是 GAN 训练过程的一种扩展,它允许稳定地训练能够输出大型高质量图像的生成器模型。
它涉及到从一个非常小的图像开始,并逐步添加层块,以增加生成器模型的输出尺寸和判别器模型的输入尺寸,直到达到所需的图像尺寸。
这种方法已被证明在生成令人惊叹的逼真高质量合成人脸方面非常有效。
在这篇文章中,您将了解用于生成大型图像的渐进增长式生成对抗网络。
阅读本文后,你将了解:
- GANs 在生成清晰图像方面很有效,但由于模型稳定性,它们仅限于小尺寸图像。
- 渐进增长式 GAN 是一种稳定训练 GAN 模型以生成大型高质量图像的方法,它涉及在训练过程中逐步增加模型的尺寸。
- 渐进增长式 GAN 模型能够以高分辨率生成逼真的合成人脸和物体,这些图像令人惊叹地真实。
通过我的新书《使用 Python 的生成对抗网络》**启动您的项目**,其中包括**分步教程**和所有示例的**Python 源代码文件**。
让我们开始吧。

渐进增长式生成对抗网络简介
照片由 Sandrine Néel 拍摄,保留部分权利。
概述
本教程分为五个部分;它们是:
- GANs 通常仅限于小尺寸图像
- 通过逐步添加层生成大型图像
- 如何渐进增长 GAN
- 渐进增长式 GAN 生成的图像
- 如何配置渐进增长式 GAN 模型
GANs 通常仅限于小尺寸图像
生成对抗网络,简称 GANs,是训练深度卷积神经网络模型以生成合成图像的有效方法。
训练 GAN 模型涉及两个模型:一个用于输出合成图像的生成器,和一个用于将图像分类为真实或虚假的判别器模型,该判别器模型用于训练生成器模型。这两个模型以对抗方式协同训练,以寻求平衡。
与其他方法相比,它们既快速又能产生清晰的图像。
GANs 的一个问题是它们受限于小数据集大小,通常是几百像素,并且通常小于 100 像素的正方形图像。
GANs 生成清晰的图像,尽管分辨率相当小且变化有限,并且尽管最近取得了进展,训练仍然不稳定。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
对于 GAN 模型来说,生成高分辨率图像被认为具有挑战性,因为生成器必须同时学习如何输出大型结构和精细细节。
高分辨率使得判别器很容易发现生成图像精细细节中的任何问题,从而导致训练过程失败。
生成高分辨率图像很困难,因为分辨率越高,越容易将生成的图像与训练图像区分开来……
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
大型图像,例如 1024 像素的正方形图像,还需要更多的内存,而与主内存相比,现代 GPU 硬件上的内存相对有限。
因此,必须减小定义每次训练迭代中用于更新模型权重的图像数量的批次大小,以确保大型图像适合内存。这反过来又会给训练过程带来进一步的不稳定性。
高分辨率还由于内存限制而需要使用更小的迷你批次,进一步损害了训练的稳定性。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
此外,即使有旨在提高模型训练过程稳定性的经验技术套件,GAN 模型的训练仍然不稳定。
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
通过逐步添加层生成大型图像
解决训练更大图像的稳定 GAN 模型问题的一种方法是在训练过程中逐步增加层数。
这种方法被称为渐进增长式 GAN、渐进式 GAN 或 PGGAN 简称。
该方法由英伟达的 Tero Karras 等人在 2017 年的论文《GANs 的渐进增长以提高质量、稳定性和多样性》中提出,并在 2018 年 ICLR 会议上发表。
我们的主要贡献是一种 GAN 训练方法,我们从低分辨率图像开始,然后通过向网络添加层来逐步提高分辨率。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
渐进增长式 GAN 涉及使用具有相同通用结构的生成器和判别器模型,并从非常小的图像(例如 4×4 像素)开始。
在训练过程中,新的卷积层块系统地添加到生成器模型和判别器模型中。
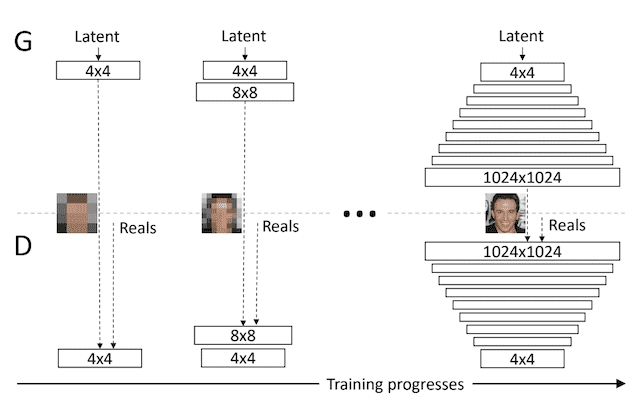
向生成器和判别器模型逐步添加层的示例。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
层的增量添加使模型能够有效地学习粗粒度细节,然后学习越来越精细的细节,这在生成器和判别器侧都适用。
这种增量性质使得训练首先能够发现图像分布的大尺度结构,然后将注意力转移到越来越精细的尺度细节,而不是必须同时学习所有尺度。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
这种方法允许生成大型高质量图像,例如 1024×1024 像素的逼真名人面孔,而这些名人并不真实存在。
如何渐进增长 GAN
渐进增长式 GAN 要求在训练过程中通过添加层来扩展生成器和判别器模型的容量。
这与在 ReLU 和 批量归一化 开发之前常见的用于开发深度学习神经网络的贪婪逐层训练过程非常相似。
例如,请参阅帖子
与贪婪逐层预训练不同,渐进增长式 GAN 涉及添加层块并逐步引入层块的添加,而不是直接添加。
当新的层添加到网络时,我们平滑地淡入它们 […] 这避免了对已经训练良好、分辨率较小的层造成突然冲击。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
此外,在训练过程中,所有层都保持可训练,包括添加新层时的现有层。
两个网络中所有现有层在整个训练过程中都保持可训练。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
新层块的逐步引入涉及使用跳跃连接将新层块连接到判别器的输入或生成器的输出,并将其与现有输入或输出层以加权方式相加。加权控制新层块的影响,并通过参数 alpha (a) 实现,该参数从零或一个非常小的数字开始,并在训练迭代中线性增加到 1.0。
这在下图中有所展示,该图取自论文。
它显示了一个输出 16×16 图像的生成器和一个接收 16×16 像素图像的判别器。模型被增长到 32×32 的大小。
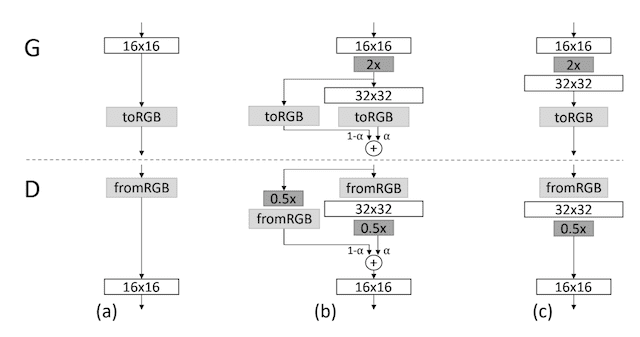
向生成器和判别器模型逐步引入新层的示例。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
让我们仔细看看在从 16×16 到 32×32 像素时如何逐步向生成器和判别器添加层。
增长生成器
对于生成器,这涉及添加一个输出 32×32 图像的新卷积层块。
此新层的输出与使用最近邻插值上采样到 32×32 的 16×16 层的输出相结合。这与许多使用转置卷积层的 GAN 生成器不同。
…使用最近邻滤波将图像分辨率加倍 […]
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
上采样 16×16 层的贡献由 (1 - alpha) 加权,而新的 32×32 层的贡献由 alpha 加权。
Alpha 最初很小,将大部分权重赋予 16×16 图像的放大版本,尽管在训练迭代中会慢慢过渡到将更多权重,然后将所有权重赋予新的 32×32 输出层。
在过渡期间,我们将操作更高分辨率的层视为一个残差块,其权重 alpha 从 0 线性增加到 1。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
增长判别器
对于判别器,这涉及为模型的输入添加一个新的卷积层块,以支持 32×32 像素的图像尺寸。
输入图像通过平均池化下采样到 16×16,以便它可以经过现有的 16×16 卷积层。新的 32×32 层块的输出也通过平均池化下采样,以便可以将其作为输入提供给现有的 16×16 块。这与大多数在卷积层中使用 2×2 步长进行下采样的 GAN 模型不同。
…使用 […] 平均池化将图像分辨率减半
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
输入的两个下采样版本以加权方式组合,从对下采样原始输入的完全加权开始,并线性过渡到对新输入层块的解释输出的完全加权。
渐进增长式 GAN 生成的图像
在本节中,我们可以回顾一下使用论文中描述的渐进增长式 GAN 所取得的一些令人印象深刻的成果。
论文的附录中提供了许多示例图像,我建议您查看。此外,还制作了一个 YouTube 视频,总结了模型的令人印象深刻的成果。
名人面孔的合成照片
渐进增长式 GAN 最令人印象深刻的成就也许是生成了 1024×1024 像素的大尺寸逼真生成面孔。
该模型在高质量的名人面孔数据集 CELEBA-HQ 版本上进行训练。因此,这些面孔看起来很熟悉,因为它们包含许多真实名人面孔的元素,尽管这些名人实际上并不存在。

使用渐进增长式 GAN 生成逼真人脸的示例。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
有趣的是,生成这些面孔所需的模型在 8 个 GPU 上训练了 4 天,这可能超出了大多数开发人员的能力范围。
我们在 8 块 Tesla V100 GPU 上训练了网络 4 天,之后我们没有观察到连续训练迭代结果之间的质量差异。我们的实现根据当前输出分辨率使用自适应迷你批次大小,以便最佳利用可用内存预算。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
合成物体照片
该模型还展示了从 LSUN 数据集生成 256×256 像素的逼真合成物体,例如自行车、公共汽车和教堂。

使用渐进增长式 GAN 生成逼真物体的示例。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
如何配置渐进增长式 GAN 模型
论文描述了用于生成 1024×1024 名人面孔合成照片的模型的配置细节。
具体细节在附录 A 中提供。
尽管我们可能对开发如此大型模型不感兴趣或没有资源,但配置细节在实现渐进增长式 GAN 时可能很有用。
判别器和生成器模型都是通过卷积层块进行增长的,每个块都使用特定数量的 3×3 滤波器和斜率为 0.2 的 LeakyReLU 激活层。上采样通过最近邻采样实现,下采样通过平均池化实现。
两个网络主要由复制的 3 层块组成,我们在训练过程中逐一引入这些块。[…] 我们在两个网络的所有层中都使用泄漏率为 0.2 的 Leaky ReLU,除了最后一层使用线性激活。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
生成器使用一个包含 512 个高斯随机变量的潜在向量。它还使用一个带 1×1 滤波器和线性激活函数的输出层,而不是更常见的双曲正切激活函数 (tanh)。判别器也使用一个带 1×1 滤波器和线性激活函数的输出层。
使用带有梯度惩罚的 Wasserstein GAN 损失,即所谓的 WGAN-GP,如 2017 年论文《改进 Wasserstein GANs 的训练》所述。最小二乘损失经过测试并显示出良好的结果,但不如 WGAN-GP。
模型从 4×4 输入图像开始,并不断增长直到达到 1024×1024 的目标尺寸。
提供了列出生成器和判别器模型中每层使用的层数和滤波器数量的表格,如下所示。
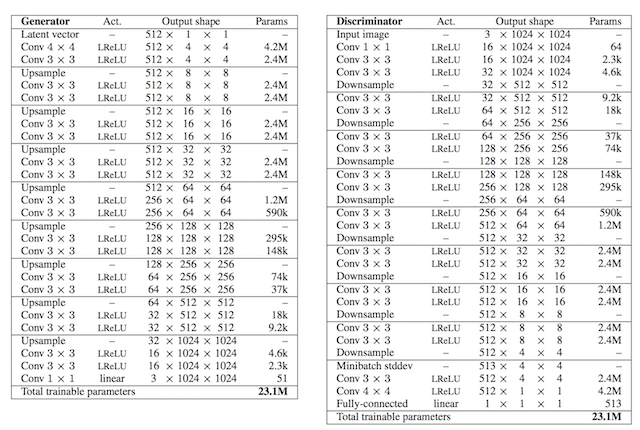
显示渐进增长式 GAN 生成器和判别器配置的表格。
摘自:《GAN 的渐进式增长以提高质量、稳定性和变异性》。
未使用批量归一化;取而代之的是添加了另外两种技术,包括迷你批次标准差像素级归一化。
迷你批次中图像之间激活的标准差在判别器模型中最后一个卷积层块之前作为一个新通道添加。这被称为“*迷你批次标准差*”。
我们在判别器末尾的 4×4 分辨率处注入了跨迷你批次标准差作为额外的特征图
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
在每个卷积层之后,在生成器中执行像素级归一化,该归一化将激活图中的每个像素值在通道上归一化为单位长度。这是一种激活约束类型,更普遍地称为“*局部响应归一化*”。
所有层的偏差都初始化为零,模型权重使用 He 权重初始化方法重新缩放为随机高斯分布。
我们将所有偏差参数初始化为零,所有权重根据单位方差的正态分布初始化。但是,我们在运行时使用层特定常数缩放权重……
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
模型使用 Adam 版本的随机梯度下降进行优化,具有小的学习率和低动量。
我们使用 Adam 训练网络,其中 a = 0.001,B1=0,B2=0.99,eta = 10^-8。
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
图像生成使用先前模型的加权平均,而不是给定的模型快照,这很像一个水平集成。
…在训练过程中的任何给定点可视化生成器输出,我们使用生成器权重的指数移动平均值,衰减率为 0.999
——《GAN 的渐进式增长以提高质量、稳定性和变异性》,2017年。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- GAN 的渐进式增长以提高质量、稳定性和变异性, 2017.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,官方.
- progressive_growing_of_gans 项目(官方),GitHub.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性。开放评论.
- 通过渐进式增长 GAN 提高质量、稳定性和多样性,YouTube.
总结
在这篇文章中,您了解了用于生成大型图像的渐进增长式生成对抗网络。
具体来说,你学到了:
- GANs 在生成清晰图像方面很有效,但由于模型稳定性,它们仅限于小尺寸图像。
- 渐进增长式 GAN 是一种稳定训练 GAN 模型以生成大型高质量图像的方法,它涉及在训练过程中逐步增加模型的尺寸。
- 渐进增长式 GAN 模型能够以高分辨率生成逼真的合成人脸和物体,这些图像令人惊叹地真实。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...


 From Scratch with Keras")



嗨,我喜欢你的教程。它们制作得非常好。我不知道你是否制作 YouTube 视频。但如果你制作了,那真的会很棒,并能吸引更多的观众。
上帝保佑你!
感谢您的支持和建议。
我不打算制作视频,它们太被动了,你不能通过观看学习这些东西,你必须“亲自动手”。
我对判别器的淡入部分有点困惑。
他们似乎为 FromRGB 层使用了 16 个滤波器的卷积层。在下采样之前,他们使用了 32 个滤波器,但这意味 (1-alpha) 将与 16 个滤波器的层相关联,而 alpha 将与 32 个滤波器的层相关联。
我错过了什么?他们是否为两个 FromRGB 层使用了不同数量的滤波器?他们是否将左边的层通过一些卷积层?
好问题,我尝试实现它,也许这会有所帮助
https://machinelearning.org.cn/how-to-implement-progressive-growing-gan-models-in-keras/
我的意思是你的实现方式和我设想的一样。FromRGB 滤波器 = 下采样前一层的滤波器。
论文中的维度仍然很奇怪,但我想我可以接受!
谢谢!
谢谢。
嗨,我有一个关于 alpha 值的问题。它是不是用来生成两个人混合面部的?如果是,我可以在推理时固定 alpha 值吗?
是的,推理时没有 alpha。你只有最终模型。
嗨 Jason,我真的很喜欢你的博客,感谢你的贡献。对于 pggan,我对上采样和下采样感到困惑。为什么他们用最近邻滤波代替转置卷积层,以及用平均池化代替卷积层中的 2×2 步长?他们在论文中证明这更好吗?
谢谢!
是的。我按照论文做了。
谢谢你的回复。
我的意思是,我无法在论文中找到关于所使用的上/下采样优越性的实验证明。我错过了吗?我不知道他们为什么用最近邻滤波代替转置卷积层。最近邻滤波总是比转置卷积层好吗?
我不会那样说。我们能说的最好是作者为这个特定的模型和任务选择了它。
也许可以尝试替代方法并比较结果?
谢谢
不客气。
我猜使用最近邻滤波有助于获得高分辨率图像,同时消除棋盘状伪影。
我看到了您的另外两篇文章,题为《如何在 Keras 中训练渐进增长式 GAN 以合成人脸》和《如何在 Keras 中实现渐进增长式 GAN 模型》。
我对阅读这些文章的顺序有点困惑。
查看每篇论文的发布日期。
这篇,然后是如何实现,然后是如何训练。
谢谢你。
不客气!
嗨,Jason,
这是一个很棒的教程。然而,渐进增长式 GAN 论文中有很多新定义,例如均衡学习率、像素归一化、小批量标准差。
我对均衡学习率感到困惑,请访问 StackOverFlows 上的这个问题 (https://stackoverflow.com/questions/64096461/why-scaling-down-the-parameter-many-times-during-training-will-help-the-learning) 以获取更多详细信息。
我希望你能制作一个关于这些新定义的教程,或者至少回答我的问题。
感谢您的建议。我希望将来能实现。
我正在尝试评估我下一个基于潜在空间探索的艺术项目的可行性。
特别是试图找出哪个部分可以实时完成。
我猜这里的瓶颈(我指的是耗时的 GPU 瓶颈)是训练。
只要我们训练好模型,实时探索和生成图片(我的审美通常不需要超高质量的东西,因为我使用寄生、噪声等)应该可能,对吧?
实际上,我的想法主要是变形图片,将(通过变形)建筑与面孔合并,实时注入生成的视频矩阵等。
推理可以实时完成,训练不能。
每种尺寸的图像需要多少次迭代?
尝试不同次数的迭代,并找出最适合您的数据集的方法。
传递给生成器中 32×32 层的输入是什么?是噪声还是生成器中 16×16 层的输出?
来自 16×16 模型经过放大后的输入。
非常感谢。您使用双线性还是最近邻来上采样图像?
我不记得了。
我们可以在音频数据上训练它吗?训练渐进式 GAN 合成音频需要更改哪些参数?
抱歉,我对音频数据的 GAN 不了解。我建议您查阅 scholar.google.com 上的文献。