深度学习神经网络技术之所以兴起并被广泛使用,可以追溯到卷积神经网络在图像分类任务中的创新应用。
其中一些最重要的创新源于学术界和行业领袖向“ImageNet 大规模视觉识别挑战赛”(或简称 ILSVRC)提交的成果。ILSVRC 是一个年度计算机视觉竞赛,它基于一个公开的计算机视觉数据集 ImageNet 的子集开发。因此,这些任务乃至挑战赛本身通常也被称为 ImageNet 竞赛。
在这篇文章中,您将了解 ImageNet 数据集、ILSVRC 以及竞赛中产生的图像分类关键里程碑。
阅读本文后,你将了解:
- ImageNet 数据集是一个由学术界设计的大型人工标注照片集合,旨在开发计算机视觉算法。
- ImageNet 大规模视觉识别挑战赛(ILSVRC)是一个年度竞赛,它使用 ImageNet 数据集的子集,旨在促进最先进算法的开发和基准测试。
- ILSVRC 任务催生了计算机视觉和深度学习交叉领域中的里程碑式模型架构和技术。
通过我的新书《计算机视觉深度学习》启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧。

ImageNet 和大规模视觉识别挑战赛(ILSVRC)简介
图片来源:Tom Hall,保留部分权利。
概述
本教程分为三个部分;它们是:
- ImageNet 数据集
- ImageNet 大规模视觉识别挑战赛
- ILSVRC 带来的深度学习里程碑
ImageNet 数据集
ImageNet 是一个包含大量带标注照片的数据集,旨在用于计算机视觉研究。
开发该数据集的目标是提供一个资源,以促进计算机视觉领域改进方法的研究和开发。
我们相信,一个大规模的图像本体论是开发先进、大规模基于内容的图像搜索和图像理解算法的关键资源,同时也为这些算法提供了关键的训练和基准测试数据。
—— ImageNet:一个大规模分层图像数据库,2009 年。
根据ImageNet 主页上记录的数据集统计数据,该数据集中有略多于 1400 万张图像,略多于 2.1 万个组或类别(synsets),以及略多于 100 万张带有边界框注释(例如,图像中识别出的对象周围的框)的图像。
这些照片由人类通过众包平台(如亚马逊的 Mechanical Turk)进行标注。
开发和维护该项目的团队由普林斯顿大学、斯坦福大学和其他美国大学的学者们协作组成。
该项目不拥有构成图像的照片;相反,它们属于版权所有者。因此,数据集不直接分发;提供了数据集中包含的图像的 URL。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
ImageNet 大规模视觉识别挑战赛 (ILSVRC)
ImageNet 大规模视觉识别挑战赛,简称 ILSVRC,是一项在 2010 年至 2017 年间举办的年度竞赛,挑战任务使用了 ImageNet 数据集的子集。
挑战赛的目标是促进更好的计算机视觉技术的发展,并对现有最先进的技术进行基准测试。
年度挑战赛侧重于“图像分类”的多个任务,其中包括根据照片中的主要物体为图像分配类别标签,以及“物体检测”,即在照片中定位物体。
ILSVRC 标注分为两类:(1)图像级标注,用于表示图像中是否存在某个物体类别的二元标签,[…] 和(2)物体级标注,用于在图像中围绕某个物体实例绘制紧密边界框和类别标签
—— ImageNet 大规模视觉识别挑战赛,2015 年。
大多数年份的一般挑战任务如下:
- 图像分类:预测图像中存在的物体类别。
- 单物体定位:图像分类 + 在每个存在的物体周围绘制一个边界框。
- 物体检测:图像分类 + 在每个存在的物体周围绘制一个边界框。
最近,鉴于静态照片技术发展的巨大成功,挑战任务正在转向更困难的任务,例如视频标注。
数据集包含约 100 万张图像和 1,000 个物体类别。挑战任务中使用的数据集有时会有所不同(取决于任务),并公开发布以促进学术界和工业界的广泛参与。
对于每年的挑战赛,都会发布一个带标注的训练数据集,以及一个未标注的测试数据集,参与者必须对测试数据集进行标注并提交到服务器进行评估。通常,训练数据集包含 100 万张图像,其中 5 万张用于验证数据集,15 万张用于测试集。
公开发布的数据集包含一组手动标注的训练图像。同时还会发布一组测试图像,但手动标注被保留。参与者使用训练图像训练他们的算法,然后自动标注测试图像。这些预测的标注会提交到评估服务器。评估结果将在竞赛期结束时公布。
—— ImageNet 大规模视觉识别挑战赛,2015 年。
比赛结果将在计算机视觉会议的年度研讨会上公布,以促进成功技术的分享和传播。
每年的挑战赛数据集仍然可用,但您必须注册。
ILSVRC 带来的深度学习里程碑
研究人员在 ILSVRC 任务上取得了突破性的计算机视觉研究进展,他们的方法和论文是计算机视觉、深度学习乃至更广泛的人工智能领域的里程碑。
ILSVRC 前五年,改进速度惊人,甚至让计算机视觉领域感到震惊。成功主要归功于在图形处理单元 (GPU) 硬件上运行的大型(深度)卷积神经网络 (CNNs),这激发了深度学习的兴趣,并将其从该领域推向了主流。
自 ILSVRC2010 至 ILSVRC2014,最先进的准确性显著提高,展示了过去五年在大规模目标识别方面所取得的巨大进展。
—— ImageNet 大规模视觉识别挑战赛,2015 年。
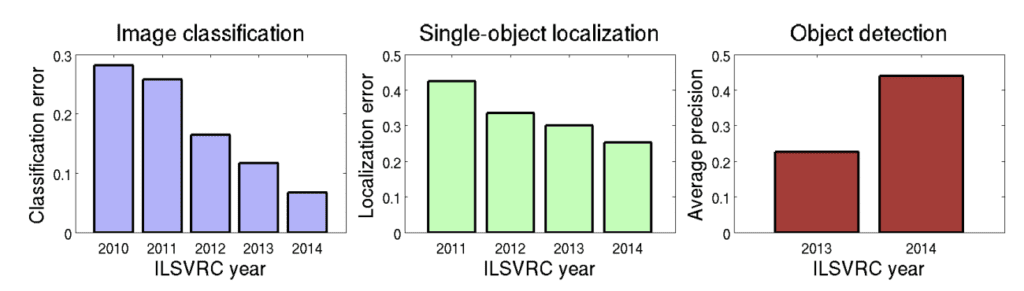
竞赛前五年 ILSVRC 任务改进总结。
摘自 ImageNet 大规模视觉识别挑战赛,2015 年。
多年来,ILSVRC 得到了广泛参与,取得了许多重要进展和大量的学术出版物。从如此多的工作中挑选里程碑本身就是一个挑战。
尽管如此,仍有一些技术,通常以其所属大学、研究小组或公司命名,脱颖而出,并成为深度学习和计算机视觉交叉领域的主流。描述这些方法的论文已成为必读材料,模型中使用的技术已成为实践中应用一般技术时的启发式方法。
在本节中,我们将重点介绍作为 ILSVRC 一部分提出的这些里程碑式技术,它们在何处被引入以及描述它们的论文。重点将放在图像分类任务上。
ILSVRC-2012
AlexNet (SuperVision)
多伦多大学的 Alex Krizhevsky 等人在其 2012 年题为《使用深度卷积神经网络进行 ImageNet 分类》的论文中,开发了一种卷积神经网络,在 ILSVRC-2010 和 ILSVRC-2012 图像分类任务中取得了最佳成绩。
这些结果激发了计算机视觉领域对深度学习的兴趣。
……我们训练了迄今为止最大的卷积神经网络之一,使用了 ILSVRC-2010 和 ILSVRC-2012 竞赛中使用的 ImageNet 子集,并取得了迄今为止在这些数据集上报告的最佳结果。
— 使用深度卷积神经网络进行 ImageNet 分类,2012。
ILSVRC-2013
ZFNet (Clarifai)
Matthew Zeiler 和 Rob Fergus 在他们 2013 年题为《可视化和理解卷积网络》的论文中提出了一种 AlexNet 的变体,通常被称为 ZFNet,其变体赢得了 ILSVRC-2013 图像分类任务。
ILSVRC-2014
Inception (GoogLeNet)
谷歌的 Christian Szegedy 等人凭借他们的 GoogLeNet 模型在目标检测方面取得了顶尖成果,该模型采用了 Inception 模块和架构。这种方法在他们 2014 年题为《更深层的卷积》的论文中有所描述。
我们提出了一种名为 Inception 的深度卷积神经网络架构,它在 2014 年 ImageNet 大规模视觉识别挑战赛(ILSVRC14)中为分类和检测设定了新的最先进水平。
— Going Deeper with Convolutions,2014。
VGG
牛津视觉几何小组(VGG)的 Karen Simonyan 和 Andrew Zisserman 凭借他们的 VGG 模型在图像分类和定位方面取得了顶尖成果。他们的方法在他们 2015 年题为《用于大规模图像识别的超深度卷积网络》的论文中有所描述。
……我们提出了显著更准确的 ConvNet 架构,它们不仅在 ILSVRC 分类和定位任务中实现了最先进的准确性,而且也适用于其他图像识别数据集,即使作为相对简单管道的一部分,它们也能获得出色的性能。
— Very Deep Convolutional Networks for Large-Scale Image Recognition,2015。
ILSVRC-2015
ResNet (MSRA)
微软研究院的何恺明等人凭借其残差网络(ResNet)在目标检测和带定位的目标检测任务中取得了顶尖成果,该网络在其 2015 年题为《用于图像识别的深度残差学习》的论文中进行了描述。
这些残差网络的集合在 ImageNet 测试集上取得了 3.57% 的错误率。这一结果赢得了 ILSVRC 2015 分类任务的第一名。
— 用于图像识别的深度残差学习,2015年。
我错过了重要的里程碑吗?
在下面的评论中告诉我。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- ImageNet:一个大规模分层图像数据库, 2009.
- ImageNet 大规模视觉识别挑战赛, 2015.
- 使用深度卷积神经网络进行 ImageNet 分类, 2012.
- 可视化与理解卷积网络, 2013.
- 使用卷积网络更深入, 2014.
- 用于大规模图像识别的超深度卷积网络, 2015.
- 用于图像识别的深度残差学习, 2015.
文章
总结
在这篇文章中,您了解了 ImageNet 数据集、ILSVRC 竞赛以及这些竞赛所带来的图像分类关键里程碑。
具体来说,你学到了:
- ImageNet 数据集是一个由学术界设计的大型人工标注照片集合,旨在开发计算机视觉算法。
- ImageNet 大规模视觉识别挑战赛(ILSVRC)是一个年度竞赛,它使用 ImageNet 数据集的子集,旨在促进最先进算法的开发和基准测试。
- ILSVRC 任务催生了计算机视觉和深度学习交叉领域中的里程碑式模型架构和技术。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。






感谢 Jason 的精彩教程。
我想问一下,有没有针对语音识别、语音增强或其他任何将深度神经网络应用于语音领域的挑战赛?
另一个问题是,这些 CNN 架构在语音增强方面也成功吗?
谢谢你。
抱歉,我对语音识别没有专业知识,希望将来能涉及。
是的,CNN 在语音识别方面表现出色,因为您可以以最佳方式(例如快速傅里叶变换)表示声音,并像 CNN 通常所做的那样从图像中收集数据。
感谢这个很棒的教程。
我很好奇他们是如何在训练、测试和验证之间分割数据的?
再次感谢。
通常是随机抽样。
一如既往,Jason,教程很棒!你知道为什么组织者停止举办挑战赛了吗?我们现在如何评估 2017 年之后出现的新模型哪个最好?
好问题,你可以在这里看到他们为什么停止/继续:
http://image-net.org/challenges/beyond_ilsvrc
更多内容在此
http://image-net.org/update-sep-17-2019
你能发一下接下来几年 ILSVRC 的获胜者详情吗?
这些比赛已停办,新的任务取代了它们。
我听说这项比赛从 2010 年持续到 2017 年。您的文章中没有提到其中一些年份。您能告诉我那些年份的获胜者信息吗?另外,请告诉我是否有其他类似的比赛(像 ILSVRC)。ImageNet 通常举办三个类别的比赛(分类、检测和定位),所以您能明确说明每个类别的获胜者是谁吗?
是的,您可以从“延伸阅读”部分的链接获取这些信息。