K-means 聚类算法是一种无监督机器学习技术,它试图将相似的数据分组到不同的簇中,以揭示肉眼可能无法注意到的数据模式。
它可能是最广泛的数据聚类算法,并且已在 OpenCV 库中实现。
在本教程中,您将学习如何将 OpenCV 的 K-means 聚类算法应用于图像的色彩量化。
完成本教程后,您将了解:
- 在机器学习的背景下,数据聚类是什么。
- 在 OpenCV 中应用 K-means 聚类算法到一个包含明显数据簇的简单二维数据集。
- 如何在 OpenCV 中应用 K-means 聚类算法对图像进行色彩量化。
通过我的书《OpenCV 机器学习》启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

使用 OpenCV 进行色彩量化的 K-Means 聚类
照片作者:Billy Huynh,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 聚类作为一项无监督机器学习任务
- 在 OpenCV 中发现 K-Means 聚类
- 使用 K-Means 进行色彩量化
聚类作为一项无监督机器学习任务
聚类分析是一种无监督学习技术。
它涉及自动将数据分组到不同的组(或簇)中,其中每个簇内的数据是相似的,但与其他簇中的数据不同。它旨在揭示聚类之前可能不明显的数据模式。
如本教程中所述,有许多不同的聚类算法,其中 K-means 聚类是最广为人知的一种。
K-means 聚类算法处理未标记的数据点。它试图将这些数据点分配到 *k* 个簇中,其中每个数据点属于与最近的簇中心最近的簇,而每个簇的中心被视为属于它的数据点的平均值。该算法要求用户提供 k 的值作为输入;因此,此值需要预先知道或根据数据进行调整。
在 OpenCV 中发现 K-Means 聚类
在进行更复杂的任务之前,让我们先考虑将 K-means 聚类应用于一个包含明显数据簇的简单二维数据集。
为此,我们将生成一个包含 100 个数据点的(由 n_samples 指定)数据集,这些数据点平均分成 5 个高斯簇(由 centers 标识),标准差设置为 1.5(由 cluster_std 确定)。为了能够复现结果,我们还定义一个 random_state 值,并将其设置为 10。
|
1 2 3 4 5 6 |
# 生成二维数据点及其真实标签的数据集 x, y_true = make_blobs(n_samples=100, centers=5, cluster_std=1.5, random_state=10) # 绘制数据集 scatter(x[:, 0], x[:, 1]) show() |
上面的代码应该生成以下数据点图
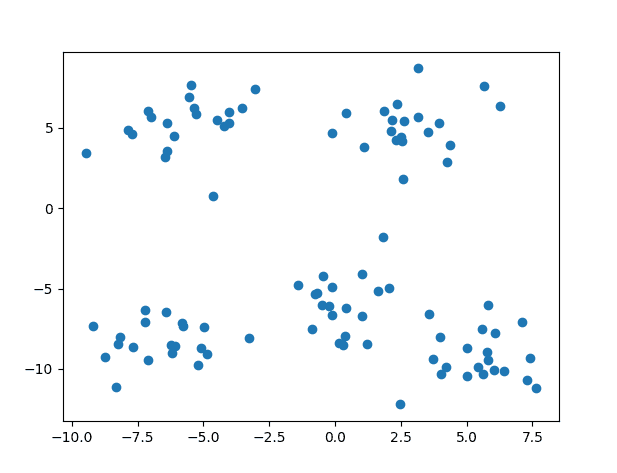
包含 5 个高斯簇的数据集散点图
想开始学习 OpenCV 机器学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如果我们查看此图,我们可能已经能够从视觉上区分一个簇与另一个簇,这意味着对于 K-means 聚类算法来说,这是一个足够直接的任务。
在 OpenCV 中,K-means 算法不包含在 ml 模块中,但可以直接调用。为了能够使用它,我们需要指定其输入参数值如下:
- 输入、未标记的
data。
- 所需簇的数量
K。
- 终止条件
TERM_CRITERIA_EPS和TERM_CRITERIA_MAX_ITER,分别定义了期望的精度和最大迭代次数,当达到这些条件时,算法迭代应停止。
attempts的数量,表示算法将执行的次数,每次使用不同的初始标记来找到最佳的簇紧密度。
- 簇中心将如何初始化,是随机的、用户提供的,还是通过诸如 kmeans++ 之类的中心初始化方法,由参数
flags指定。
OpenCV 中的 K-means 聚类算法返回
- 每个簇的
compactness,计算为每个数据点到其对应簇中心的平方距离之和。更小的紧密度值表示数据点更接近其对应的簇中心分布,因此簇更紧密。
- 预测的簇标签
y_pred,将每个输入数据点与其对应的簇相关联。
- 每个数据点簇的
centers坐标。
现在让我们将 K-means 聚类算法应用于之前生成的数据集。请注意,我们将输入数据类型转换为 float32,这是 OpenCV 中 kmeans() 函数所期望的。
|
1 2 3 4 5 6 7 8 9 10 |
# 指定算法的终止条件 criteria = (TERM_CRITERIA_MAX_ITER + TERM_CRITERIA_EPS, 10, 1.0) # 在输入数据上运行 K-means 聚类算法 compactness, y_pred, centers = kmeans(data=x.astype(float32), K=5, bestLabels=None, criteria=criteria, attempts=10, flags=KMEANS_RANDOM_CENTERS) # 绘制数据簇,每个簇具有不同的颜色,以及相应的簇中心 scatter(x[:, 0], x[:, 1], c=y_pred) scatter(centers[:, 0], centers[:, 1], c='red') show() |
上面的代码生成了以下图,其中每个数据点现在都根据其分配的簇着色,并且簇中心以红色标记
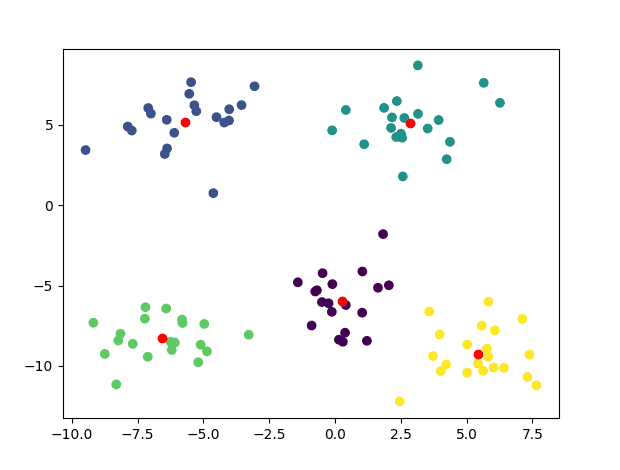
使用 K-Means 聚类识别簇的数据集散点图
完整的代码清单如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from cv2 import kmeans, TERM_CRITERIA_MAX_ITER, TERM_CRITERIA_EPS, KMEANS_RANDOM_CENTERS from numpy import float32 from matplotlib.pyplot import scatter, show from sklearn.datasets import make_blobs # 生成一个二维数据点及其真实标签的数据集 x, y_true = make_blobs(n_samples=100, centers=5, cluster_std=1.5, random_state=10) # 绘制数据集 scatter(x[:, 0], x[:, 1]) show() # 指定算法的终止条件 criteria = (TERM_CRITERIA_MAX_ITER + TERM_CRITERIA_EPS, 10, 1.0) # 在输入数据上运行 K-means 聚类算法 compactness, y_pred, centers = kmeans(data=x.astype(float32), K=5, bestLabels=None, criteria=criteria, attempts=10, flags=KMEANS_RANDOM_CENTERS) # 绘制数据簇,每个簇具有不同的颜色,以及相应的簇中心 scatter(x[:, 0], x[:, 1], c=y_pred) scatter(centers[:, 0], centers[:, 1], c='red') show() |
使用 K-Means 进行色彩量化
K-means 聚类的一个应用是图像的色彩量化。
色彩量化是指减少图像表示中使用的不同颜色数量的过程。
色彩量化对于在只能显示有限数量颜色的设备上显示具有许多颜色的图像至关重要,这通常是由于内存限制,并且可以实现某些类型图像的高效压缩。
色彩量化,2023 年。
在这种情况下,我们将提供给 K-means 聚类算法的数据点是每个图像像素的 RGB 值。正如我们将看到的,我们将以 $M \times 3$ 数组的形式提供这些值,其中 $M$ 表示图像中的像素数。
让我们尝试对这张图片(我将其命名为 bricks.jpg)应用 K-means 聚类算法。

这张图片中突出的主要颜色是红色、橙色、黄色、绿色和蓝色。然而,许多阴影和亮点在主要颜色中引入了额外的色调和颜色。
我们将首先使用 OpenCV 的 imread 函数读取图像。
请记住,OpenCV 加载此图像的顺序是 BGR 而不是 RGB。在将图像输入 K-means 聚类算法之前,无需将其转换为 RGB,因为后者无论像素值的顺序如何,仍然会对相似的颜色进行分组。但是,由于我们正在使用 Matplotlib 显示图像,因此我们将将其转换为 RGB,以便稍后能够正确显示量化结果。
|
1 2 3 4 5 |
# 读取图像 img = imread('Images/bricks.jpg') # 将其从 BGR 转换为 RGB img_RGB = cvtColor(img, COLOR_BGR2RGB) |
如前所述,下一步是重塑图像为一个 $M \times 3$ 数组,然后我们可以使用与上述主要颜色数量相对应的几个簇,将 K-means 聚类应用于结果数组值。
在下面的代码片段中,我还包含了一行,打印出图像总像素数中唯一的 RGB 像素值的数量。我们发现图像中有 14,155,776 个像素,其中有 338,742 个唯一的 RGB 值,这是一个相当大的数量。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 将图像重塑为 Mx3 数组 img_data = img_RGB.reshape(-1, 3) # 查找唯一 RGB 值的数量 print(len(unique(img_data, axis=0)), 'unique RGB values out of', img_data.shape[0], 'pixels') # 指定算法的终止条件 criteria = (TERM_CRITERIA_MAX_ITER + TERM_CRITERIA_EPS, 10, 1.0) # 在像素值上运行 K-means 聚类算法 compactness, labels, centers = kmeans(data=img_data.astype(float32), K=5, bestLabels=None, criteria=criteria, attempts=10, flags=KMEANS_RANDOM_CENTERS) |
此时,我们将使用实际的 RGB 值作为簇中心来应用预测的像素标签,并将结果数组重塑为原始图像的形状,然后再显示它。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 将簇中心的 RGB 值应用于所有像素标签 colours = centers[labels].reshape(-1, 3) # 查找唯一 RGB 值的数量 print(len(unique(colours, axis=0)), 'unique RGB values out of', img_data.shape[0], 'pixels') # 将数组重塑为原始图像形状 img_colours = colours.reshape(img_RGB.shape) # 显示量化后的图像 imshow(img_colours.astype(uint8)) show() |
再次打印量化图像中唯一的 RGB 值数量,我们发现这些值已减少到我们为 K-means 算法指定的簇数量。
|
1 |
14155776 个像素中的 5 个唯一 RGB 值 |
如果我们查看色彩量化后的图像,我们会发现属于黄色和橙色砖块的像素可能因为其 RGB 值相似而被分组到同一个簇中。相比之下,一个簇聚集了属于阴影区域的像素。
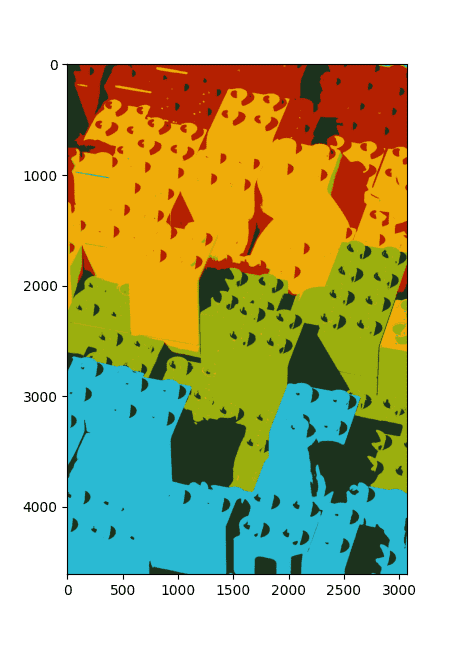
使用具有 5 个簇的 K-Means 聚类的色彩量化图像
现在尝试更改指定 K-means 聚类算法簇数量的值,并研究其对量化结果的影响。
完整的代码清单如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from cv2 import kmeans, TERM_CRITERIA_MAX_ITER, TERM_CRITERIA_EPS, KMEANS_RANDOM_CENTERS, imread, cvtColor, COLOR_BGR2RGB from numpy import float32, uint8, unique from matplotlib.pyplot import show, imshow # 读取图像 img = imread('Images/bricks.jpg') # 将其从 BGR 转换为 RGB img_RGB = cvtColor(img, COLOR_BGR2RGB) # 将图像重塑为 Mx3 数组 img_data = img_RGB.reshape(-1, 3) # 查找唯一 RGB 值的数量 print(len(unique(img_data, axis=0)), 'unique RGB values out of', img_data.shape[0], 'pixels') # 指定算法的终止条件 criteria = (TERM_CRITERIA_MAX_ITER + TERM_CRITERIA_EPS, 10, 1.0) # 在像素值上运行 K-means 聚类算法 compactness, labels, centers = kmeans(data=img_data.astype(float32), K=5, bestLabels=None, criteria=criteria, attempts=10, flags=KMEANS_RANDOM_CENTERS) # 将簇中心的 RGB 值应用于所有像素标签 colours = centers[labels].reshape(-1, 3) # 查找唯一 RGB 值的数量 print(len(unique(colours, axis=0)), 'unique RGB values out of', img_data.shape[0], 'pixels') # 将数组重塑为原始图像形状 img_colours = colours.reshape(img_RGB.shape) # 显示量化后的图像 imshow(img_colours.astype(uint8)) show() |
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
书籍
- OpenCV 机器学习, 2017.
网站
- 10 种 Python 聚类算法,https://machinelearning.org.cn/clustering-algorithms-with-python/
- OpenCV 中的 K-Means 聚类,https://docs.opencv.ac.cn/3.4/d1/d5c/tutorial_py_kmeans_opencv.html
- k-means 聚类,https://en.wikipedia.org/wiki/K-means_clustering
总结
在本教程中,您学习了如何在 OpenCV 中应用 K-means 聚类算法对图像进行色彩量化。
具体来说,你学到了:
- 在机器学习的背景下,数据聚类是什么。
- 在 OpenCV 中应用 K-means 聚类算法到一个包含明显数据簇的简单二维数据集。
- 如何在 OpenCV 中应用 K-means 聚类算法对图像进行色彩量化。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块



 From Scratch With Python")


感谢这些很棒的文章。
只有一个问题
K-Means 聚类只有一个中心是否等于平均所有像素值?
例如,如果我想计算汽车的主要颜色,我应该平均汽车图像的所有像素值来获得主要颜色,还是应该对所有像素进行一次聚类大小为 1 的 K-Means 聚类?
谢谢
你好 Mohammad…你的方法是合理的!请继续你的模型,并让我们知道你的发现!
Jason,你是最棒的。这是一篇很棒的文章。我喜欢它。
感谢您的反馈和支持 David!我们非常感激!如果您对我们的内容有任何疑问,请随时告知我们。
你好 Mohammad。恕我直言,如果你在图片中看到了汽车,那是因为有汽车和不是汽车的东西,我们称之为背景。必然地,背景与汽车的颜色不同,否则汽车将是看不见的。所以尝试一个至少有 2 种颜色的 K-means,这样其中一个组可以指示汽车的像素。然后你可以平均这些像素的颜色。