学习曲线是模型学习性能随经验或时间变化的图表。
学习曲线在机器学习中是一种广泛使用的诊断工具,适用于从训练数据集逐步学习的算法。在训练过程中每次更新后,可以在训练数据集和保留的验证数据集上评估模型,并创建测量性能的图表以显示学习曲线。
审查训练过程中模型的学习曲线可用于诊断学习问题,例如模型欠拟合或过拟合,以及训练和验证数据集是否具有足够的代表性。
在这篇文章中,您将了解学习曲线以及如何使用它们来诊断机器学习模型的学习和泛化行为,并附有显示常见学习问题的示例图。
阅读本文后,你将了解:
- 学习曲线是显示学习性能随经验变化而变化的图表。
- 模型在训练和验证数据集上的学习曲线可用于诊断欠拟合、过拟合或良好拟合的模型。
- 模型性能的学习曲线可用于诊断训练或验证数据集是否未相对代表问题领域。
用我的新书《更好的深度学习》来启动你的项目,书中包含分步教程和所有示例的 Python 源代码文件。
让我们开始吧。

学习曲线在诊断深度学习模型性能中的简要介绍
图片由Mike Sutherland提供,保留部分权利。
概述
本教程分为三个部分;它们是:
- 学习曲线
- 诊断模型行为
- 诊断无代表性的数据集
机器学习中的学习曲线
一般来说,学习曲线是一种图表,其中x轴表示时间或经验,y轴表示学习或改进。
学习曲线(LCs)被认为是监测接触新任务的工人表现的有效工具。LCs提供了随着任务重复而发生的学习过程的数学表示。
— 学习曲线模型与应用:文献综述与研究方向, 2011。
例如,如果您正在学习一种乐器,可以在一年中每周评估您在乐器上的技能并赋予一个数值分数。这些分数在52周内的图表就是一条学习曲线,它将显示您学习乐器的情况如何随时间变化。
- 学习曲线:学习(y轴)随经验(x轴)变化的线图。
学习曲线在机器学习中被广泛使用,适用于那些随时间逐步学习(优化其内部参数)的算法,例如深度学习神经网络。
用于评估学习的指标可能是最大化的,这意味着更好的分数(更大的数字)表示更多的学习。一个例子是分类准确度。
更常见的是使用最小化分数,例如损失或误差,其中更好的分数(更小的数字)表示更多的学习,而值为0.0表示训练数据集被完美学习且没有犯错误。
在机器学习模型的训练过程中,可以评估训练算法每一步的模型当前状态。可以在训练数据集上进行评估,以了解模型“学习”得如何。也可以在不属于训练数据集的保留验证数据集上进行评估。在验证数据集上的评估可以了解模型“泛化”得如何。
- 训练学习曲线:根据训练数据集计算的学习曲线,可了解模型学习情况。
- 验证学习曲线:根据保留验证数据集计算的学习曲线,可了解模型泛化情况。
通常会为机器学习模型在训练和验证数据集上创建双重学习曲线。
在某些情况下,也常为多个指标创建学习曲线,例如在分类预测建模问题中,模型可能会根据交叉熵损失进行优化,而模型性能则使用分类准确率进行评估。在这种情况下,会创建两个图,每个图对应一个指标的学习曲线,每个图可以显示两条学习曲线,分别对应训练和验证数据集。
- 优化学习曲线:根据模型参数优化所依据的指标(例如损失)计算的学习曲线。
- 性能学习曲线:根据模型将要评估和选择的指标(例如准确率)计算的学习曲线。
既然我们已经熟悉了学习曲线在机器学习中的使用,接下来让我们看看学习曲线图中观察到的一些常见形状。
想要通过深度学习获得更好的结果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
诊断模型行为
学习曲线的形状和动态可用于诊断机器学习模型的行为,进而可能建议可以进行哪些类型的配置更改以改进学习和/或性能。
在学习曲线中,您可能会观察到三种常见的动态;它们是:
- 欠拟合。
- 过拟合。
- 良好拟合。
我们将通过示例更仔细地研究每一种情况。示例将假定我们正在查看一个最小化指标,这意味着y轴上较小的相对分数表示更多或更好的学习。
欠拟合学习曲线
欠拟合是指模型无法学习训练数据集。
当模型在训练集上无法获得足够低的误差值时,就会发生欠拟合。
— 第111页,深度学习,2016年。
欠拟合模型可以仅从训练损失的学习曲线中识别出来。
它可能显示一条平线或相对较高的损失的噪声值,表明模型根本无法学习训练数据集。
下面提供了此示例,当模型容量不足以处理数据集的复杂性时,这种情况很常见。
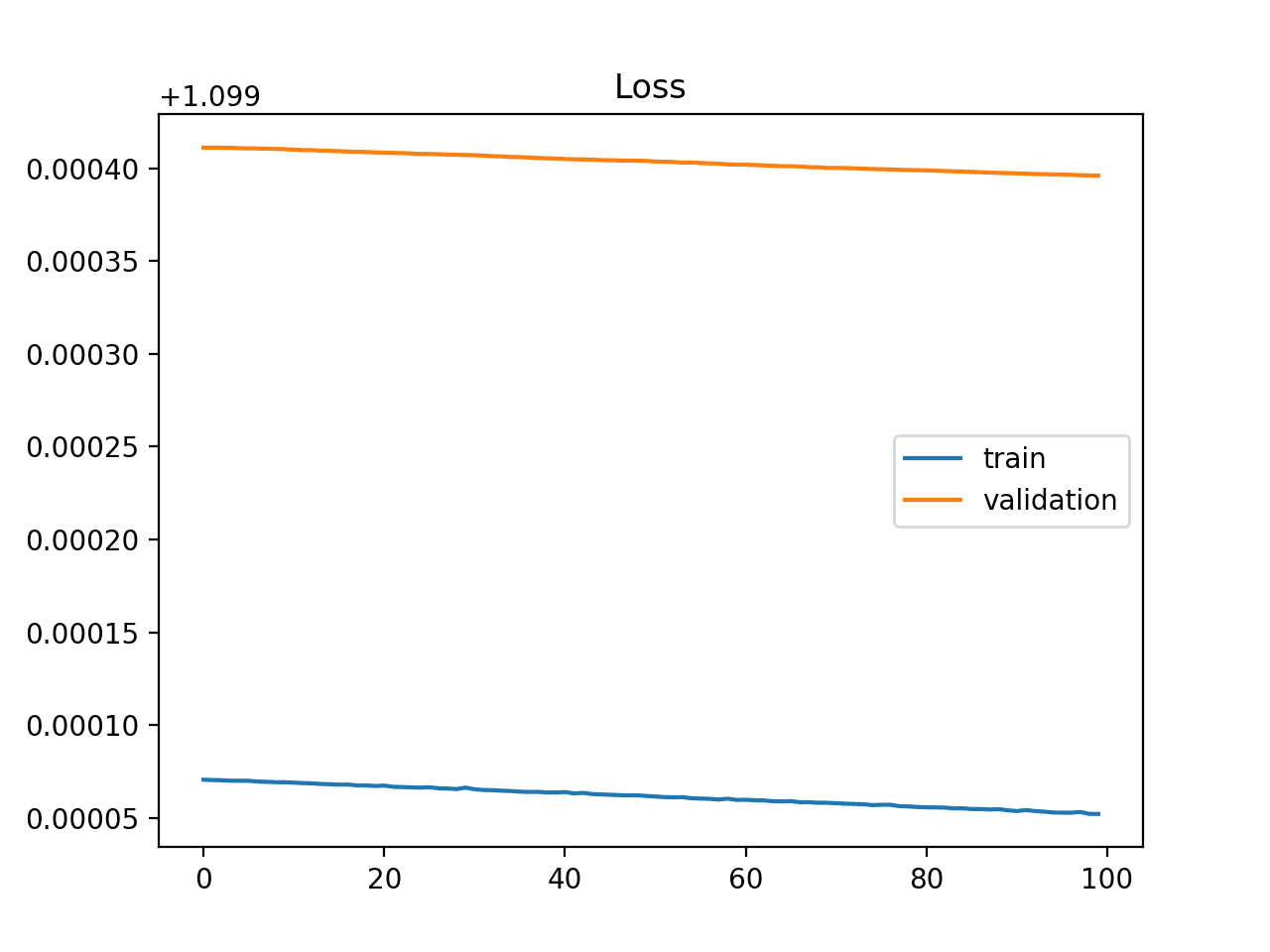
训练学习曲线显示容量不足的欠拟合模型示例
欠拟合模型也可以通过训练损失在图的末尾持续下降来识别。
这表明模型有能力进一步学习并可能进一步改进,并且训练过程过早停止。
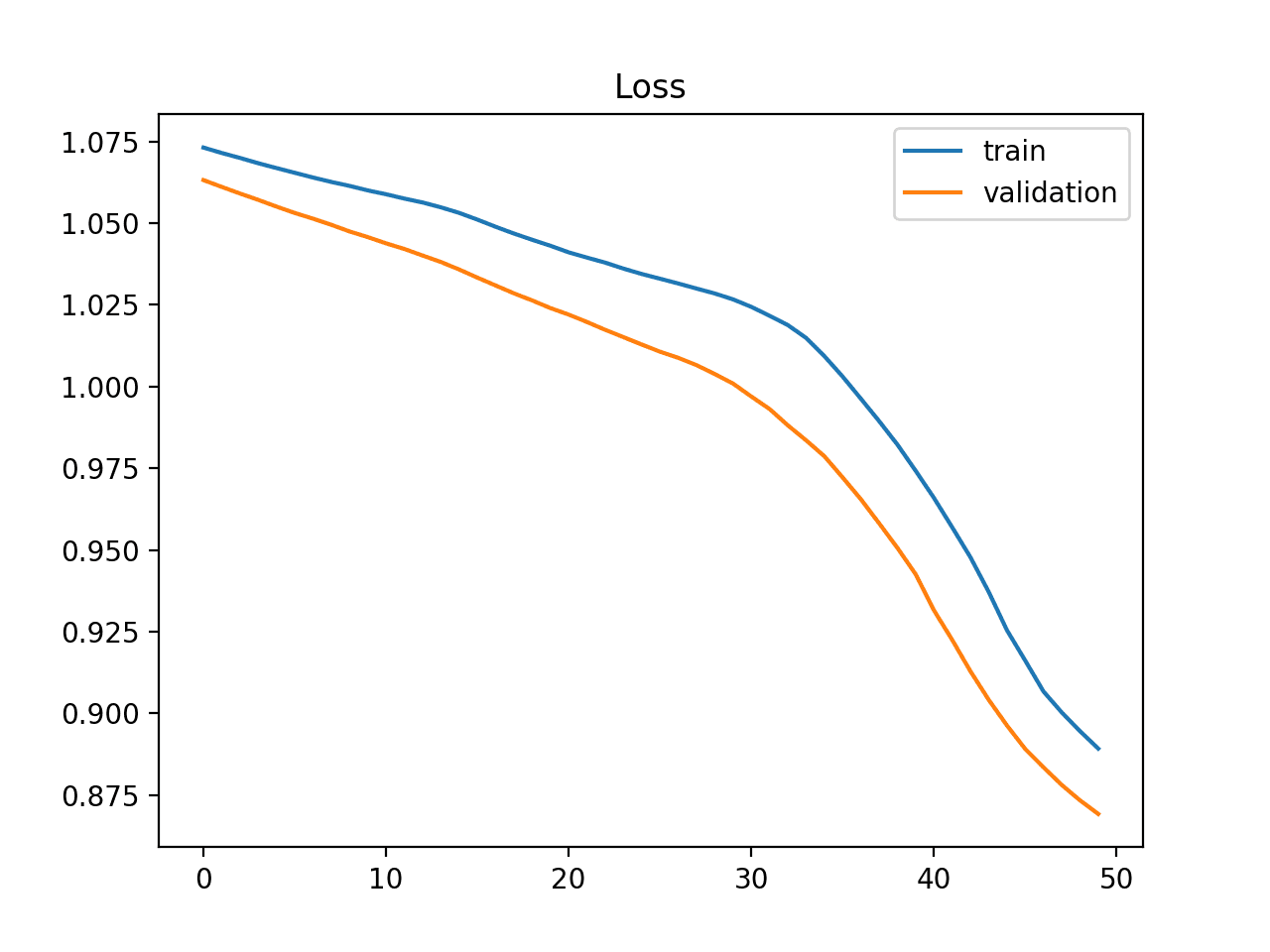
训练学习曲线显示需要进一步训练的欠拟合模型示例
学习曲线图显示欠拟合,如果:
- 训练损失无论训练如何保持平坦。
- 训练损失持续下降直至训练结束。
过拟合学习曲线
过拟合是指模型对训练数据集学习得太好,包括训练数据集中的统计噪声或随机波动。
……拟合一个更灵活的模型需要估计更多的参数。这些更复杂的模型可能导致一种称为数据过拟合的现象,这基本上意味着它们过于紧密地跟随误差或噪声。
— 第22页,统计学习导论:附R应用,2013年。
过拟合的问题在于,模型对训练数据越是专门化,其对新数据的泛化能力就越差,导致泛化误差增加。这种泛化误差的增加可以通过模型在验证数据集上的性能来衡量。
这是数据过拟合的一个例子,[…]。这是一种不理想的情况,因为获得的拟合在未包含在原始训练数据集中的新观测值上无法产生准确的响应估计。
— 第24页,统计学习导论:附R应用,2013年。
这种情况通常发生在模型容量超出问题所需,从而导致灵活性过大。如果模型训练时间过长,也可能发生这种情况。
学习曲线图显示过拟合,如果:
- 训练损失图随经验持续下降。
- 验证损失图下降到某一点后开始再次上升。
验证损失的拐点可能是训练可以停止的点,因为该点之后的经验显示了过拟合的动态。
下面的示例图演示了一个过拟合的案例。
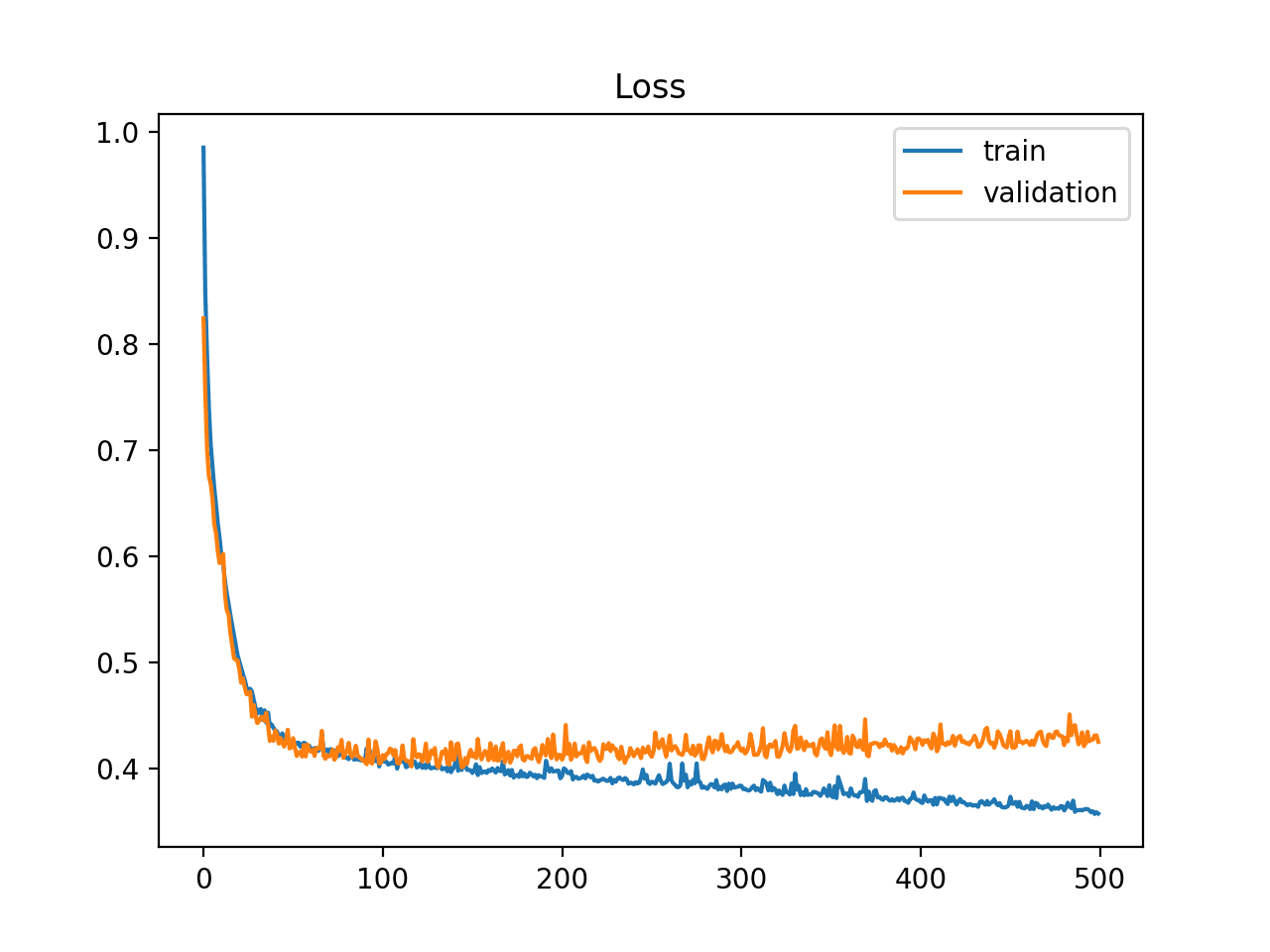
训练和验证学习曲线显示过拟合模型示例
良好拟合学习曲线
良好拟合是学习算法的目标,介于过拟合和欠拟合模型之间。
良好拟合通过训练和验证损失下降到稳定点,并且两个最终损失值之间存在最小差距来识别。
模型在训练数据集上的损失几乎总是低于验证数据集。这意味着我们应该期望训练和验证损失学习曲线之间存在一些差距。这个差距被称为“泛化差距”。
学习曲线图显示良好拟合,如果:
- 训练损失图下降到稳定点。
- 验证损失图下降到稳定点,并且与训练损失之间存在一个小差距。
良好拟合的持续训练很可能导致过拟合。
下面的示例图演示了一个良好拟合的案例。
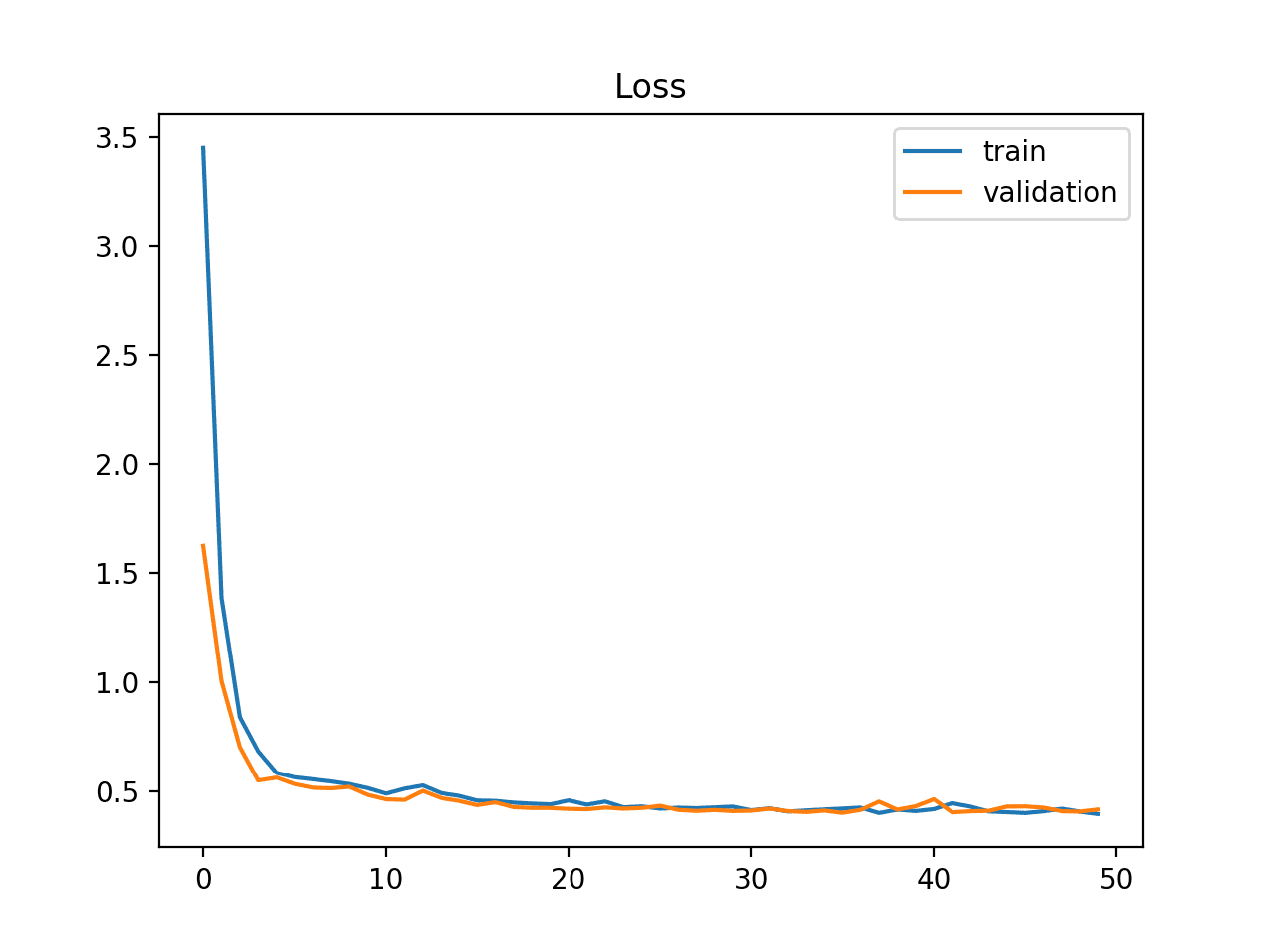
训练和验证学习曲线显示良好拟合示例
诊断无代表性的数据集
学习曲线还可用于诊断数据集的特性以及它是否具有相对代表性。
无代表性的数据集是指可能无法捕捉与从同一领域提取的另一个数据集(例如训练数据集和验证数据集之间)相关的统计特征的数据集。当数据集中的样本数量相对于另一个数据集而言过小时,通常会发生这种情况。
可能观察到两种常见情况;它们是:
- 训练数据集相对不具代表性。
- 验证数据集相对不具代表性。
无代表性训练数据集
无代表性的训练数据集意味着与用于评估的验证数据集相比,训练数据集没有提供足够的信息来学习问题。
如果训练数据集的示例数量与验证数据集相比过少,可能会发生这种情况。
这种情况可以通过训练损失的学习曲线显示出改进,同样,验证损失的学习曲线也显示出改进,但两条曲线之间仍然存在很大差距来识别。
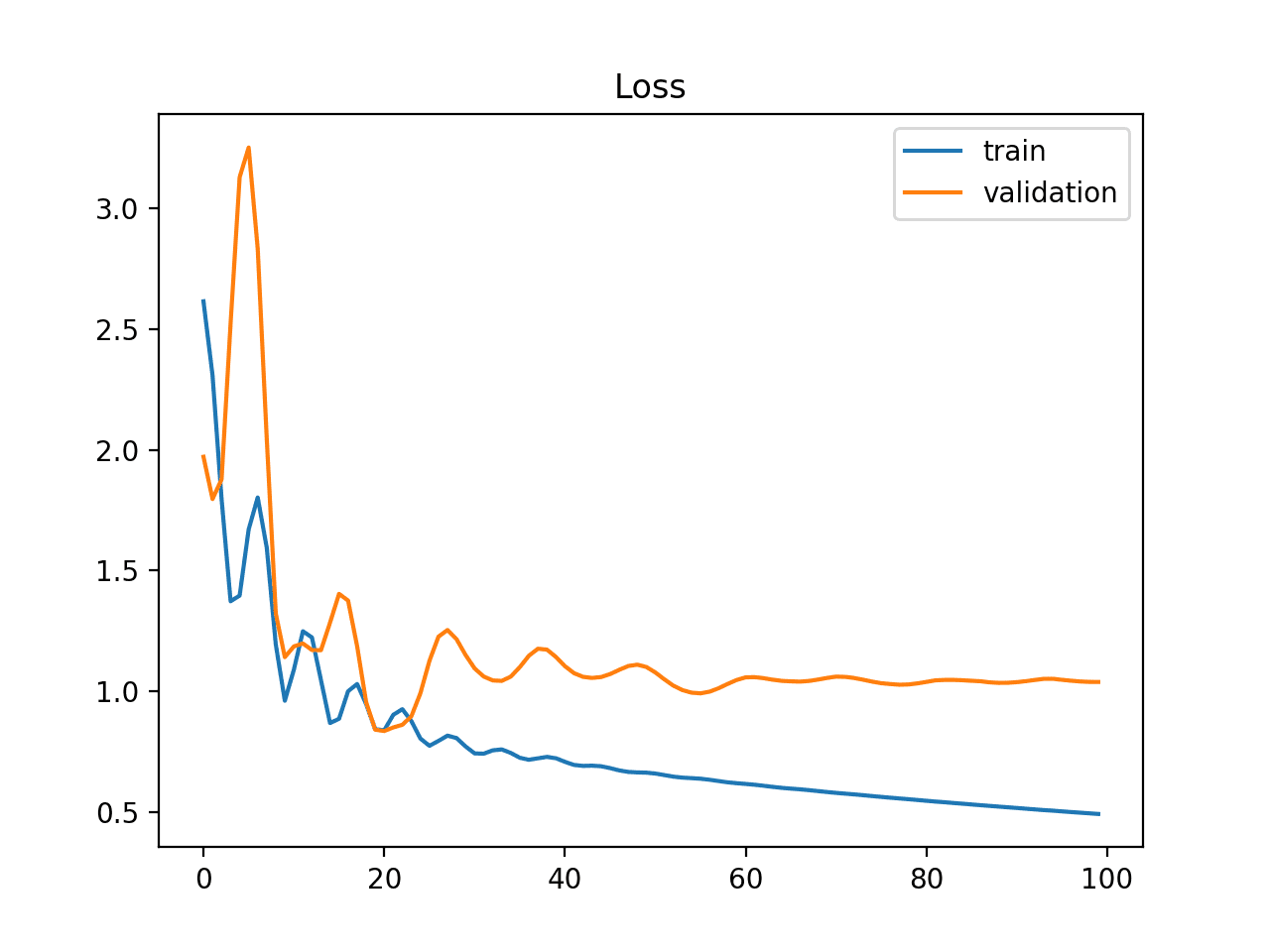
训练和验证学习曲线显示训练数据集可能相对于验证数据集过小的情况示例
无代表性验证数据集
无代表性验证数据集意味着验证数据集没有提供足够的信息来评估模型泛化能力。
如果验证数据集的示例数量与训练数据集相比过少,可能会发生这种情况。
这种情况可以通过训练损失的学习曲线看起来像良好拟合(或其他拟合),而验证损失的学习曲线显示出围绕训练损失的嘈杂波动来识别。
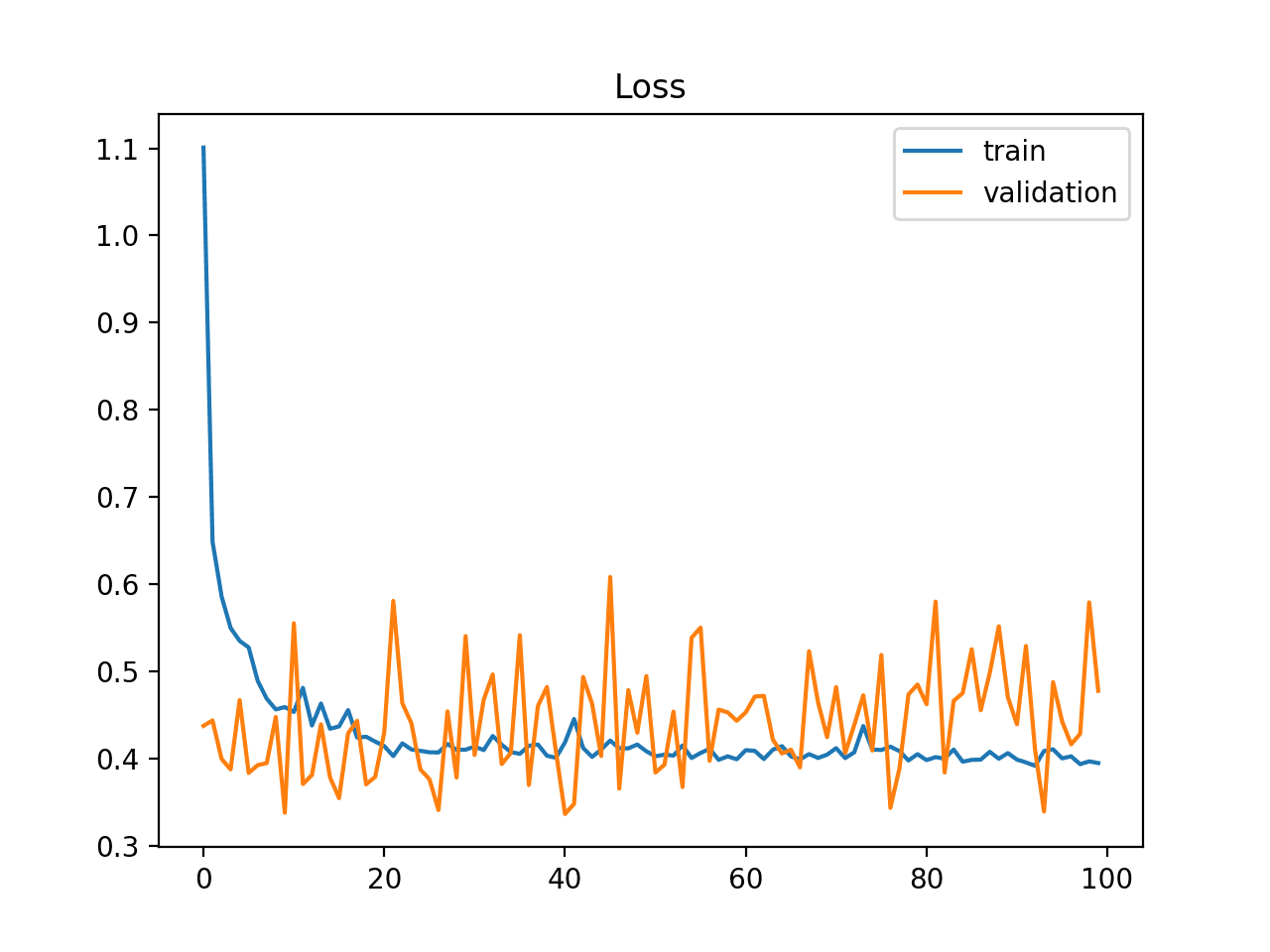
训练和验证学习曲线显示验证数据集可能相对于训练数据集过小的情况示例
它也可以通过验证损失低于训练损失来识别。在这种情况下,它表明验证数据集可能比训练数据集更容易让模型预测。
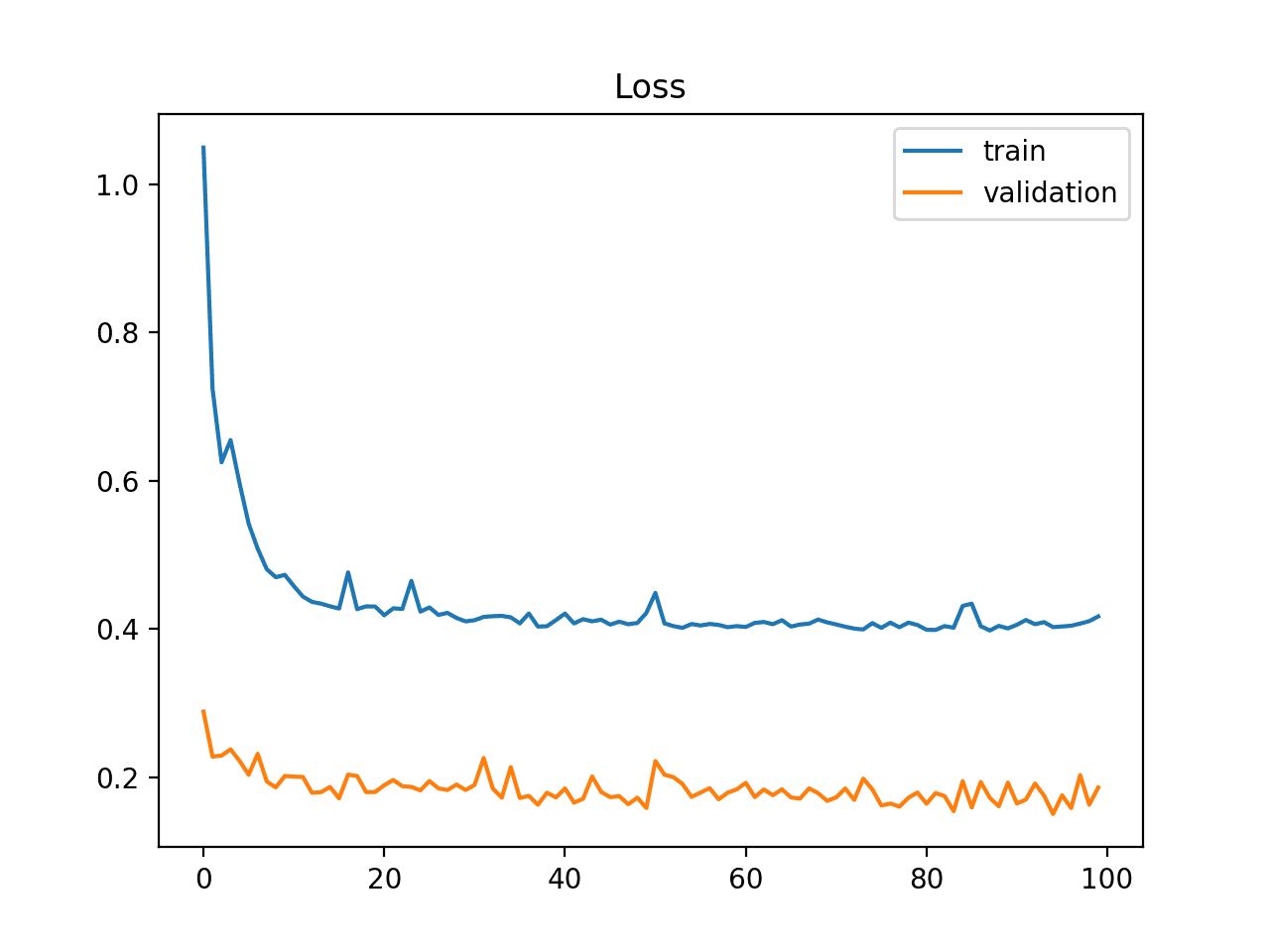
训练和验证学习曲线显示验证数据集比训练数据集更容易预测的示例
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
论文
- 学习曲线模型和应用:文献综述与研究方向, 2011.
文章
文章
总结
在这篇文章中,您了解了学习曲线以及如何使用它们来诊断机器学习模型的学习和泛化行为。
具体来说,你学到了:
- 学习曲线是显示学习性能随经验变化而变化的图表。
- 模型在训练和验证数据集上的学习曲线可用于诊断欠拟合、过拟合或良好拟合的模型。
- 模型性能的学习曲线可用于诊断训练或验证数据集是否未相对代表问题领域。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







感谢这篇关于核心机器学习技术的文章。第一个学习曲线示例似乎是欠拟合的一个糟糕例子,因为y轴上的损失已经很低了。另外,也许第二个图上显示的情况应该称为“训练不足”,以避免与欠拟合的“难以学习更多”的情况混淆。此外,欠拟合的总结段落有打字错误和数据“过拟合”。
谢谢罗兰。
我自己的打字错误 :)。上面倒数第二个词应该是“says”
信息量很大!
谢谢。
这里仍然有错别字
学习曲线图显示过拟合,如果:
训练损失无论训练如何保持平坦。
训练损失持续下降直至训练结束。
=> 这是欠拟合。
正确,已修复。谢谢!
泛化等方法是否只适用于这些情况?
抱歉,我不明白,您能详细说明或重新措辞问题吗?
我本会说,训练集上的误差应该增加以收敛到验证集上的误差,这表示拟合良好。您对此有何看法?(https://www.dataquest.io/blog/learning-curves-machine-learning )
根据我的经验,在实践中不会发生,因为通常测试/验证集比训练集小且代表性不足,并且具有不同的误差配置文件。
嗨,杰森,谢谢你的帖子。
我有一个与此帖子无关的问题,想听听您的意见。
假设我正在训练一些数据,在预处理过程中我正在清理这些数据。我从中删除了一些奇怪/错误的值。
现在,当我将预测应用于未见过的新数据时,在进行预测之前,我是否需要对这些数据应用相同的清理?
这样做或不这样做有什么需要注意的地方吗?
我想我应该进行相同的清理,但这让我很困惑,我们有未见过的数据,它可以是任何东西……
(我不是在谈论缩放或那种我已经在训练和未见过的数据上应用的预处理)
非常感谢!
George
很好的问题。
是的,如果您可以使用通用但特定于领域的知识来准备/过滤数据,那么在拟合和评估模型以及未来进行预测时,始终如一地使用此过程是一个好主意。
风险在于数据泄露,例如,利用关于“未见”/测试数据的知识来帮助更好地拟合模型。这可能有所帮助(而且可能有点过于严格)
https://machinelearning.org.cn/data-leakage-machine-learning/
杰森,这篇帖子写得太棒了。谢谢。
——我的总结,如果您能评估我是否对所有这些内容都理解正确,我将不胜感激:
过拟合发生在我们学习了太多与要学习的主流思想(通用概念)无关的细节时。这种情况可能是,一方面您有一个非常庞大复杂的模型(有很多层和很多需要调整的权重,即具有非常“高熵信息容量”),另一方面只有少量数据可供训练……因此解决方案可以是简化模型或增加训练数据集。
另一方面,欠拟合发生在我们模型需要更多经验(更多迭代次数)来训练时,因此学习曲线趋势持续下降……直到您通过适当的迭代次数获得正确的稳定。
——我的第二个问题是,当验证数据获得比训练数据更好的性能(高水平)时,您如何解释这种情况……这是良好泛化的一个好迹象吗?
杰森,感谢您允许我们分享您的知识!!
是的,但是如果模型没有足够的容量来从数据中学习,您可能会出现欠拟合。这可能来自迭代次数,也可能来自模型的复杂性/大小。
这表明验证数据集太小,无法代表问题——非常常见。
好文章!
非常感谢。
不客气,很高兴能帮到您。
嗨,Jason,
抱歉,我在领英上也问过这个问题。再次发布在这里,以便大家思考。
我用非常少量的数据运行了一个VGG16模型——验证准确率约为83%。
然而,当我预测测试数据集时,我只得到了大约53%的准确率。我的数据分为训练集、验证集和测试集。
这里可能出了什么问题?任何解释都会非常有帮助。另外,感谢您的学习曲线博客。确实很有帮助……
另外,您可以使用验证数据进行预测吗?这里可能出了什么问题/正确?
也许测试数据集太小或不能代表更广泛的数据集。
也许尝试50/50分割?或者获取更多数据?
谢谢!
先生,虽然这是个有点偏题的问题,但我还是想问一下。我如何“数学上”解释居中和缩放数据对机器学习模型的益处,而不是原始数据。归一化数据的准确性和收敛性无疑会提高,但我能用数学证明吗?
抱歉,我没有很好的答案。
使用三组数据(训练、验证和测试)创建学习曲线图是否正确?使用“训练”集来训练模型,并使用“验证”和“测试”集来生成学习曲线?
通常只使用训练集和验证集。
感谢您的帖子!!它帮助很大!!您能帮我检查一下我得到的学习曲线吗(http://zhuchen.org.cn/wp-content/uploads/2019/07/lc.png),是否欠拟合?这是一个使用随机森林的多分类问题。
看起来欠拟合。
一个非常棒且有用的教程,谢谢
谢谢。
我可以问一下欠拟合情况下“平线”的含义吗?
这表明模型对问题没有足够的容量。
如果损失增加然后减少,然后又增加然后减少,如此反复……
这意味着什么?
它意味着数据在该模型中不具代表性吗?或者
它意味着发生了过拟合吗?
很好的问题!
这可能意味着数据嘈杂/不具代表性,或者模型不稳定(例如批次大小或输入数据的缩放)。
嘿,杰森,我正好有这个问题。你说的模型不稳定——批次大小和缩放是什么意思?你能详细说明一下吗?另外,这个解释适用于训练数据集和验证数据集吗?还是只适用于其中一个?你说的损失波动是指哪个数据集——训练集还是验证集?
谢谢,很棒的帖子
更多关于批次大小的信息
https://machinelearning.org.cn/how-to-control-the-speed-and-stability-of-training-neural-networks-with-gradient-descent-batch-size/
更多关于缩放的信息
https://machinelearning.org.cn/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
谢谢 Jason!
另外——
我正在尝试训练和开发一个模型,用于对相机陷阱图像进行分类。
根据您的经验——解决相机陷阱图像分类以对野生动物进行分类的最佳模型是什么?图片中看到的动物有野猪、鹿、狐狸和猴子。
另外,如果我们的主要目标是检测野猪而不是其他动物——我是否可以像这样构建数据集:1000张有野猪的图片,其余1000张图片包含所有其他动物,包括猴子、鹿和狐狸——而不是每种动物都获取1000张图片
任何建议都会非常有用,一如既往地感谢
我推荐迁移学习
https://machinelearning.org.cn/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
没错。“野猪”类和“其他”类。
我使用皮尔逊相关系数作为回归问题的准确性指标。
我可以使用相关系数作为优化学习曲线吗?
考虑改用r^2作为您的指标?
抱歉,r^2是什么意思?
r平方或R^2
https://en.wikipedia.org/wiki/Coefficient_of_determination
你好,Jason。
我在这里发布了两张我的训练模型图片
https://stackoverflow.com/questions/57224353/is-my-training-data-set-too-complex-for-my-neural-network
您能告诉我我的模型是过拟合还是欠拟合吗?我认为是欠拟合。
我该如何解决这些问题?
再次感谢杰森,您对我的帮助之大无法言喻
上面的文章将帮助您确定是过拟合还是欠拟合。
我在这里教授如何诊断性能,然后改进性能
https://machinelearning.org.cn/start-here/#better
我可以问一下性能学习曲线的必要性吗?
我从本教程中了解到,优化学习曲线用于检查模型的拟合度?
但性能学习曲线的重要性是什么?
你说的性能学习曲线是什么意思?
性能学习曲线代表了每个epoch的准确性
我明白了,好问题。
性能曲线可以让你了解损失的变化是否与问题中技能的实际实质性提升相关。
我应该在模型达到最小损失时停止训练吗?
是的,在验证集上。
如果我达到了最小验证损失值,
然而,验证准确率不高。
在这种情况下,我应该停止学习吗?
最小损失是0,如果达到0损失,则表明问题微不足道(不需要机器学习)或者模型过拟合。
抱歉,我想说的是,如果我达到了最小验证损失值(不是0),但在这一迭代中验证准确率不是最高值(此迭代后,验证准确率更高)。
在这种情况下,我应该停止训练吗?
也许可以尝试一下。
我可以使用准确率学习曲线而不是损失学习曲线来衡量模型的拟合度吗?
当然。只是它在诊断学习动态方面可能没有那么有用。
你说的学习动态是什么意思?
模型如何随时间学习,反映在学习曲线中。
如果损失曲线是一条在迭代过程中下降的直线,这有问题吗?
损失应该减少。
如果您愿意,可以为我推荐一些阅读更多关于学习曲线的优秀参考资料吗?
是的,请参阅文章末尾的参考文献。
验证损失值必须低于训练损失值吗?
对于一个拟合良好的模型,验证损失和训练损失应该非常相似。
哪个更受青睐?
——提早停止训练,或者
——分析输出以找到最小验证损失
这取决于模型和数据集。
也许可以进行实验,看看哪种方法适用于您的特定场景。
哪个更优选:使用低容忍度值的提前停止还是高容忍度值?
这取决于您选择的模型和数据集。也许可以尝试一下?
如果我达到了最小验证损失值,而在这个epoch,训练准确率和验证准确率之间存在差距。
我应该停止学习还是不停止?
也许吧。或许可以测试一下这个策略。
为什么我应该在达到最小验证损失时停止,而不是在达到验证损失和训练损失之间最小差距时停止?
尝试各种方法,看看哪种方法能为您的数据集产生一个健壮且熟练的模型。
一般来说,您希望在训练和验证损失最低,并且在验证损失开始上升之前停止训练。
很棒的教程!
在显示训练不足模型的第二个图上,验证数据损失似乎应该高于训练数据损失,这与图中显示的不同。也许是编辑错误?
再次,这里的工作很棒。感谢分享。
没有错误,在这种情况下,验证集可能代表性不足。重点是训练/验证曲线的形状,表明进行更多有意义的训练是完全可能的。
嗨,杰森,这是一篇非常有用的文章。但是,关于“无代表性验证数据集”一节有一个问题:-
无代表性验证数据集意味着验证数据集没有提供足够的信息来评估模型泛化能力。
如果验证数据集的示例数量与训练数据集相比过少,可能会发生这种情况。
我的问题是,如果您有更多的验证示例,例如占整个数据集的30%,那么曲线会变得平滑吗?
或者,错误在于验证集本身的分布?(验证数据可能不包含与训练数据相同的分布)。
如果上述句子不是无代表性验证数据集的情况,那么当验证数据分布与训练数据集完全不同时,曲线会是什么样子?以及解决此问题的补救措施是什么?
这取决于数据的具体情况和您正在采样的数据集大小。
一个好的解决方案是获取更多数据并使用50/50的分割。
非常好!如果您能告诉我当应用于相同的训练/验证集时,以下哪个模型更好,我将不胜感激:一个产生较低验证损失和较低训练损失,但泛化差距高于另一个具有较高验证和训练集损失的模型。我给您举个例子。
模型1:训练损失 = 0.5 验证损失 = 1.5 差距 = 1
模型2:训练损失 = 0.8 验证损失 = 1.6 差距 = 0.8
谢谢!
一般来说,模型选择是项目特有的,我的建议可能帮不上忙。
选择一个符合项目利益相关者要求的模型是一个好主意,通常这意味着在保留数据集上表现良好且复杂度较低。
我明白了!
谢谢!
这个噪声有多糟糕?
https://imgur.com/sSL3DRJ
没那么糟!
嗨,Jason,
训练曲线能否用于评估预测时间序列的模型?
据我所知,时间序列不能使用交叉验证(只能使用步进验证),
那么使用学习曲线的意义何在?
“经验”是训练大小?还是迭代次数?
是的,每次模型拟合时,学习曲线都可以成为学习行为的宝贵诊断工具。
那么经验就是训练大小?
我如何在时间序列中获得更多的训练大小?(通过向后追溯(例如,每次增加1天并追加上次训练和测试损失)?
抱歉,我不太明白。
您可以通过增加历史数据,或者增加每个时间步测量到的输入变量来获得更多数据以训练时间序列模型。
不确定这与学习曲线有什么关系?
据我所知,学习曲线中的X轴不是迭代次数,
而是我们训练集的大小,对吗?
不行。
学习曲线图的x轴是迭代次数。
嗨,Jason,
我一直关注您的教程,非常有帮助!非常感谢!
我的问题是关于无代表性验证数据集(第二个图),在这种情况下,除了获取更多数据等之外,您会推荐什么补救措施?
是否也可以应用 dropout 技术,或者它仅限于过拟合?
谢谢!
亚历克斯..
您可以使用更大的验证数据集,例如训练数据集的一半。
更多关于如何减少过拟合的信息在这里
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
感谢您的回复!
再问一个问题,但与本节无关:我观察到,当我在Keras中使用一个特定的随机种子生成器(例如低至7-10)来获得可重复的结果,然后我将种子从一个值(例如高于30)再次更改时,我得到了不同的结果,包括图表的形状。
这正常吗?还是我必须始终坚持原始种子?
再次感谢!
Alex
是的,请看这个
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
这很正常。深度学习器(和一些经典机器学习算法)具有高度随机性。这就是为什么您应该始终进行多次实验并获取结果的统计数据。例如,对具有相同超参数的多次实验(仅通过RNG种子不同)的训练/验证损失和损失的标准差进行平均。这里有一些关于此博客上结果随机性的其他文章:https://machinelearning.org.cn/reproducible-results-neural-networks-keras/、https://machinelearning.org.cn/evaluate-skill-deep-learning-models/和https://machinelearning.org.cn/randomness-in-machine-learning/。
另外:一些伪随机数生成器在小种子下效果不佳。因此,如果您用多个不同的小种子获得了某些结果,而用显著更大的种子获得了不同的结果,这可能表明您的库使用的RNG在小种子下效果不佳。请改用更大的种子。
完全正确!
除了种子方面。我认为现在所有的库都使用良好的随机数生成器,不同种子下的结果很可能是“幸运的”,不具有代表性。
好的,这回答了我的问题!
非常感谢!
Alex
很高兴听到这个消息。
这些图中发生了一些非常奇怪的事情。训练损失似乎总是远高于验证损失。但这怎么可能呢?除了数据不具代表性的情况,当您训练模型时,您会期望在训练集上看到一个低得多的损失(模型的参数针对该集进行了优化),而在验证集上,训练模型需要泛化(参数并未针对该集进行优化)。
请查看吴恩达的笔记:http://www.holehouse.org/mlclass/10_Advice_for_applying_machine_learning.html
训练损失总是(除了特殊情况)低于验证集。
通常人们会使用训练集的30%或更小的部分作为验证集,这使得该集上的损失嘈杂/不可靠。
这很常见,可悲的是。
如果有足够的数据,50%的分割可能更合适。
我认为损失函数需要根据数据集的大小进行归一化。也就是说,在计算训练损失函数时使用1/m_{训练大小},对于另一个集使用1/m_{交叉验证大小}。
我不完全同意。
嗨,Jason,
感谢您的详细解释。帮助很大。我想知道我是否可以将其翻译成中文,并在我的博客上转载,并注明您的帖子地址?
谢谢!
请勿翻译这些帖子
https://machinelearning.org.cn/faq/single-faq/can-i-translate-your-posts-books-into-another-language
我想知道您是否能澄清损失值和边界。换句话说,损失值大于1意味着什么?
(对于每个epoch的准确率,所有值都在0和1之间——或0%和100%之间)
我还有另一个问题。根据这篇帖子,损失随迭代次数的变化在拟合方面提供了信息。那么准确率随迭代次数的变化(训练集和验证集的准确率)呢?
通常没有那么有用。太粗糙了。
损失是相对于模型/数据集而言的。
我建议只解释大体的动态,而不是具体的值。
非常感谢您的解释和澄清。
不客气。
我有一些情况是损失图在迭代过程中呈上升趋势。我在您的帖子中没有看到这个例子。我想知道它属于哪个类别。
如果训练损失增加,这可能表明过拟合。
在上面的教程中就有这样的例子。
您好,Jason,我实现了一个RNN,我的验证损失在2个epoch后开始增加,表明模型可能过拟合了。然而,我比较了2个epoch和10个epoch的精确度和召回率的评估结果,发现它们几乎相似。
我该如何解释呢?这是否意味着模型在2个epoch内收敛,不需要更多的训练?即使验证损失在2个epoch后增加并表明过拟合,我是否可以认为在2个epoch后停止是最佳点?
谢谢!
是的,你的推理听起来不错。也许可以尝试更小的学习率来减缓学习速度?
验证损失和训练损失之间的差距多大是可接受的?
好问题。
越小越好。在某个时候,这需要主观判断。
谢谢杰森。
您是如何生成这些图表的?另外,对于每种情况,我们需要调整什么参数?
您可以使用matplotlib在Python中生成线形图,并调用plot()函数。
请参阅有关减少过拟合的内容
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
早上好,我构建了一个神经网络来预测物理量(回归任务),我绘制了“训练损失/验证损失 vs epoch”图表,我可以看到,起初两者都在下降,然后变得恒定,但验证损失总是略低于训练损失(这个差异非常小)。这是过拟合吗?如果两者(训练和验证损失)都变得恒定(下降后),其中一个在另一个之上或之下重要吗?
我想给你发一些图表,但我不知道怎么做。
损失值之间的小差异可能意味着拟合良好。
感谢您的回答,我已将5个验证损失低于训练损失的损失函数图表上传到Google Drive文件夹中。您能检查一下这是否属于过拟合情况吗?因为我有点困惑。谢谢!
这是链接:https://drive.google.com/open?id=1sv1Qn9RhLRL7UXBgLOzFNWga5JHzJHCF
抱歉,我不能。
嗨,Jason,
感谢您的帖子。在训练数据集经过重采样的不平衡分类问题中,我们很可能会得到一个像您在“不具代表性的验证数据集”中解释的图表,因为验证数据集仍然不平衡,代表真实世界。在这种情况下,我们是否必须以不同的方式分析模型的性能?
谢谢。
也许吧。您可以尝试绘制用于评估的指标,而不是损失。
谢谢,这篇文章很有帮助。
但我仍然对如何定义一个好的拟合有疑问。你说可能存在一个小的泛化差距。但我应该如何定义“小”呢?
我得到了一条曲线,验证损失下降到0.06左右的稳定点,而训练损失稳定在0.03左右。我应该如何评估它?
好问题。它是相对的,例如,差距是否相对较小、正在缩小、稳定。
嘿,杰森,一如既往的棒。
关于罗兰·费尔南德斯的回复,也就是这篇文章的第一个回复。我建立了一些模型并用“mse”损失进行编译,在第一个epoch得到了0.0090的值,在第二个epoch得到了0.0077的值,并且它一直在学习,只是每个epoch学习得很少,最后绘制出一条几乎平坦的线,就像第一个学习曲线“显示容量不足的欠拟合模型的训练学习曲线示例”中的那条。所以我想听听你的看法。
这些模型是否像罗兰所说的那样,由于值很低而不代表欠拟合,或者实际上像您在文章中指出的那样是欠拟合?
我必须补充的是,这些模型获得的预测结果在预期范围内。
如果损失在学习过程中保持平坦,那就很奇怪了。这可能是问题要么微不足道,要么无法学习——在这种情况下,任何一组小权重都能产生良好预测,也许是前者。只是猜测,可能需要更多的研究。
那么您建议我该怎么做才能确定这些模型的可靠性,或者它们是否是该问题的适用解决方案。
首先选择一个最能体现您和利益相关者项目目标的指标。
然后设计一个测试工具,使用可用数据评估模型。例如,对于适量的数据进行回归/分类,请使用重复分层K折交叉验证。
使用每个得分样本的平均值比较结果。使用统计假设检验支持决策,以证明差异是真实的。
使用方差来评论模型的稳定性。使用集成方法来减少最终预测中的方差。
这些主题都在博客中涵盖,请使用搜索功能或联系我。
学习曲线可以为单个模型的单次运行提供有用的诊断,以帮助调整模型超参数。
非常感谢
不客气。
嗨,又来了,我之前解释的损失结果是每个epoch拟合所有样本,持续了将近100个epoch。
数据维度如下:
输入 5395,23,1。
输出 5395,23。
每个样本的格式,正如我之前解释的:
输入:________输出
1,2,3___________4, 5,6
2,3,4___________5, 6,7
3,4,5___________6, 7,8
这是否可能导致学习曲线几乎是平坦的?我应该按批次大小进行训练吗?
也许吧,很难说。
也许可以探索其他模型架构?其他学习率?其他优化器?等等。
嗨,Jason,
我尝试对CNN进行微调,用于14类图像分类。数据集有2000张图像。每个模型产生的损失值都在0.1到0.4之间。例如
最佳epoch:20/50
训练准确率:0.9268600344657898 训练损失:0.27140530943870544
验证准确率:0.9145728349685669 验证损失:0.358508825302124
您认为这些模型适合发表吗,还是一个好的模型损失值必须低于0.1?
我无法客观地判断结果是否良好。
好的结果是相对于朴素模型和同一数据集上的其他模型而言的。
1) 是否可以说我的模型仅从损失值来看还不够好,我应该将损失值降到0.1以下,并将准确率提高到0.95以上?
2) 或者对于具有高度相似性的14个类别,验证准确率(0.89 ~ 0.94)和验证损失(0.1 ~ 0.4)值是否足够?
不完全是,您可以客观地解释交叉熵,请参阅此处
https://machinelearning.org.cn/cross-entropy-for-machine-learning/
最好选择一个指标并以此方式比较模型。
https://machinelearning.org.cn/faq/single-faq/how-to-know-if-a-model-has-good-performance
你好 Jason,
损失值(y轴)是否有被认为是好的范围,比如说,最高损失值必须高于某个特定值?
还是说每个问题都有自己的值范围,只有曲线的形状才重要?
谢谢你
是的,你可以解释交叉熵
https://machinelearning.org.cn/cross-entropy-for-machine-learning/
通常,最好将结果与朴素模型进行比较。
您好,杰森。我两周前发现了您的网站。您激励了我。我希望能见到您并与您握手致谢。请不要停止写作。
伊斯坦布尔..
谢谢!
您好,先生
如果我获得了很高的验证准确率,但曲线不平滑怎么办?
造成这种情况的原因是什么?
谢谢
可能是数据集太小或者模型方差太大。
那么这是好是坏呢?如果是坏的,我该如何解决这个问题?
就我的情况而言:我使用AlexNet模型,数据集有1GB的.dicom文件(1000个.dicom),分为2个类别。
谢谢您,先生。
它只有相对于你在数据集上能达到的其他结果,例如相对于一个朴素模型,才是好或坏的。
什么是泛化误差?它是训练损失和验证损失之间的差距吗?
泛化误差是模型在未用于训练模型的数据上产生的误差。即在新数据上的误差。
你好,我不清楚学习曲线是否可以作为LSTM的准确率度量?我们可以在任何预测模型上使用学习曲线,无论使用何种预测算法吗?深度学习算法的最佳准确率度量是什么?
是的,请看这个
https://machinelearning.org.cn/diagnose-overfitting-underfitting-lstm-models/
这有助于为分类选择一个指标。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
这篇文章和图表非常有帮助。如果能提供Python代码以供详细理解,代码和图表可以并排显示,那就更好了。
您是否可以提供带代码的示例???
代码如何帮助解释这些图表?
嗨,Jason,
我有一个问题要问你。这与这篇帖子无关。
我正在做一个基于深度学习的小型研究项目。我试图根据用户给其他电影的评分来预测用户将给一部未看过的电影的评分。我正在使用movielens数据集。主文件夹ml-100k包含100,000部电影的信息。为了创建推荐系统,使用了“堆叠自编码器”模型。我正在使用PyTorch进行编码实现。
我将数据集分成训练集(80%)和测试集(20%)。我的损失函数是MSE。当我绘制训练损失曲线和验证曲线时,损失曲线看起来不错。它们之间显示出最小的差距。
但是当我把损失函数改为RMSE并绘制损失曲线时。训练损失曲线和验证损失曲线之间存在巨大的差距。(epoch:200 训练损失:0.0757。测试损失:0.1079)
在我的代码中,我只更改了损失函数部分(MSE到RMSE)。我应用了批量归一化和Dropout等正则化技术,但曲线之间仍然存在很大的差距。
我是深度学习新手,但你知道为什么应用RMSE时曲线之间会有巨大的差距吗?
这与评估指标有关,还是编码部分有问题?
谢谢。
我建议使用MSE损失,但可以计算RMSE的度量,例如不要使用RMSE训练模型,而只用于评估预测。
你好,Jason。
感谢您的反馈。
那么我只在测试模型时使用“RMSE”(损失函数)吗?
而对于训练模型,我是否忽略损失函数部分,或者使用“MSE”作为训练模型的损失函数?
https://towardsdatascience.com/stacked-auto-encoder-as-a-recommendation-system-for-movie-rating-prediction-33842386338
我的项目就是基于此。(点击链接)。
抱歉,我每周收到数百个链接/代码/数据。
我没有能力为您审查第三方内容。
https://machinelearning.org.cn/faq/single-faq/can-you-explain-this-research-paper-to-me
使用RMSE作为度量。不要使用RMSE作为损失函数(例如,在拟合模型时不要最小化RMSE),使用MSE。
谢谢 Jason。
我会尝试一下。
顺便问一下,我有一些问题要请教你。
我刚接触深度学习,对验证损失和测试损失的术语感到困惑。它们是相同的还是完全不同的?
而且你不能在测试数据上训练模型吗?
它是否只用于测试(评估预测)?
我知道您不能审查我的数据,但是当我在代码中添加验证损失时,我重新使用了训练循环并删除了backward和optimizer.step()调用。我的度量标准是MSE。我假设验证损失与测试损失相同。但我可能错了。
我想听听你对此的反馈。
是的,我们可以在训练期间计算不同数据集上的损失,例如测试集和验证集,请参阅此处定义它们
https://machinelearning.org.cn/difference-test-validation-datasets/
选择模型和配置后,我们可以在所有可用数据上拟合最终模型。我们不能在测试数据上拟合模型来评估它,因为模型必须在未用于训练的数据上进行评估,才能给出公平的性能估计。
谢谢 Jason。
现在我理解了验证集和训练集的概念。
在我的小项目中,我根据用户给其他电影的评分来预测用户将给一部未看过的电影的评分。我使用的模型是堆叠自编码器。
对于我的另一个任务,我想与其他深度学习模型进行比较。例如,我想使用MLP(多层感知器)或逻辑回归(机器学习模型)。是否可以使用这些模型进行0到5的电影评分预测?
谢谢。
是的。
我正在构建一个用于预测的LSTM模型。验证误差曲线是平坦的,最终验证MSE小于训练MSE。val_loss=0.00002,training_loss = 0.013533。
我仔细阅读了您的文章,但我不敢确定我的验证集是否不具代表性。我应该扩大我的验证集吗?
这是图表和问题
https://stackoverflow.com/questions/62877425/validation-loss-curve-is-flat-and-training-loss-curve-is-higher-than-validation
谢谢。
可能您的验证集不具有训练的代表性,或者太小。
你好,Jason。
感谢您的帖子,我知道了什么是欠拟合、过拟合和良好拟合。
我目前也在构建一个小型ANN模型(95个输入,3个类别输出,2个隐藏层分别有200个节点和30个节点)。
我的数据集很小(105个样本,每个样本有95个特征),形状为(105, 95)。我将数据分为训练数据(80个样本)、验证数据(10个样本)和测试数据(15个样本)。
我的问题是我尝试训练、验证和预测我的模型10次。大约7或8次我观察到良好的拟合(训练-验证准确率和损失图),而另外3或2次我得到了过拟合。这种现象正常吗?即使它过拟合,对测试数据的预测也相当好(超过85%)。
非常感谢您的帮助。
也许您可以更改配置,使模型平均而言更稳定。
嗨,杰森。谢谢你的回复。
您这里说的配置是指超参数(比如层数、节点数或训练测试拆分等)对吗?
正确。
我们有学习曲线的真实世界例子吗????
那样会更好地理解和绘制它。
是的,有很多——在博客中搜索,也许这会有帮助
https://machinelearning.org.cn/how-to-develop-a-cnn-from-scratch-for-cifar-10-photo-classification/
嗨,Jason,
感谢您的巨大支持。
我想问一下,在训练周期中,验证曲线呈锯齿状/拥挤的可能原因,以及如何最小化/缓解它。通常,训练曲线变化平滑,但验证曲线不平滑。请指导。
可能验证集太小和/或不具代表性。
嗨,Jason,
有没有办法将这些行为归因于模型架构/超参数设置,而不是训练/验证数据分布?我之所以问,是因为我在使用完全相同的训练/验证数据进行超参数搜索时,得到了具有与您给出的上述三个示例相似的训练/验证曲线的模型(如果我能在这里嵌入图片,我会的)。
模型1:曲线看起来像您给出的“不具代表性的训练数据集”示例;模型2:看起来像您给出的“不具代表性的验证数据集”示例;模型3:看起来像您给出的“验证数据集可能比训练数据集更容易让模型预测”示例。
您对此有什么直觉吗?不胜感激。
感谢您的博客,我多次引用它!
学习曲线受模型结构和学习算法配置的影响较大,数据的影响较小——如果处理得当的话。
这里“不具代表性”意味着您的样本太小。
你好!
这篇帖子很有趣,谢谢。不过,我有一个关于我所做的训练的问题。我是深度学习的新手,我使用了一个已经写好的代码。我未能成功绘制验证曲线(我想你指的是我所说的“测试”)。我只有训练+验证的损失曲线,但没有测试的损失曲线。我训练我的神经网络50个epoch,我只知道
-验证(不是测试)的中间准确率值(在每5个epoch保存权重后)
-所有epoch结束后训练+验证的准确率值
-测试集的准确率。
我在训练+验证后获得了94%的准确率,在测试后获得了89.5%的准确率。关于训练+验证的损失函数,它在35个训练epoch后稳定在0.1以下的值。总共有50个训练epoch。
训练+验证和测试的准确率之间只有很小的差异,是否足以说明我的网络没有过拟合?
我想说的是“它停滞在一个值...”
谢谢!
没问题,用val代替test。
如果保留数据集太小,结果会不稳定。
谢谢您的回答。我不明白您为什么说“用val代替test”。实际上,我的代码唯一能做的就是
-绘制验证的准确率曲线(每5个epoch已知准确率)
-已知50个epoch后验证的准确率值
-已知测试的准确率值
嗨,Jason,
再次感谢您的文章。
在整个深度网络训练过程中,验证数据损失和训练数据损失都随着epoch的增加而减少。但是验证数据损失的减少量远小于训练数据损失的减少量,这正常且具有代表性吗?
当epoch从0开始较小时,训练数据损失曲线开始时较高,然后随着epoch的增加而减少,但验证数据损失曲线已经开始较小,然后随着epoch的增加而略微减少。
谢谢你。
也许你的验证数据集太小了?
谢谢您,Jason,我尝试从训练数据中获取更多样本到验证数据中以增加验证数据样本大小,但学习曲线仍然显示,尽管验证数据损失和训练数据损失都随着epoch的增加而减少,但验证数据损失的减少量远小于训练数据,最终,训练数据损失(mse,均值0和标准差1的标准化数据)为0.25,而验证数据损失为0.41,这仍然是过拟合吗?
不同的文献总是说好的拟合是验证损失略高于训练损失,但“略高于”有多高,您能否给些提示?
一如既往地感谢您。
干得不错。
也许可以尝试使用备用学习率或添加正则化来减缓学习速度。
如果行为顽固地保持不变,也许您已达到了所选模型在您的数据集上的极限。
感谢您8月12日的回复。但我仍然不确定是否理解。在这篇文章(本页面)中,您所说的“训练”和“验证”是指什么?它的含义与这篇文章中相同吗?:https://machinelearning.org.cn/difference-test-validation-datasets/
我在神经网络的最后一次验证(=最终模型在验证数据集上的结果)后得到了结果(F1分数、精确度、召回率等)。我还使用测试集评估了神经网络在新图像上的性能后的结果。验证集和测试集上的结果略有不同(准确率相差4.5%),测试集上的准确率略差(4.5%)。这就是我们所说的“泛化差距”吗?为什么测试集上的结果会略差(4.5%)?
感谢您的帮助
是的,您可以预期不同数据样本之间在性能上存在细微差异,也许这会有所帮助
https://machinelearning.org.cn/different-results-each-time-in-machine-learning/
非常感谢您的回答。这篇其他文章非常有趣。就我的情况而言,我使用神经网络进行语义分割(SegNet)。在最后一次验证(=最终模型在验证数据集上的结果)后,我获得了91.1%的准确率。使用此最终模型在测试数据集上,我获得了85.9%的准确率。从您的文章“每次结果都不同……”来看,我猜测我可以将这种差异解释为我的模型具有高方差(验证数据集和测试数据集具有不同的图像,每张5000*5000像素的图像有3张)。这是正确的吗?在您的文章中,您似乎只谈论训练数据的方差,所以我不确定我的假设是否正确。
感谢您的帮助
干得好!
是的,最终模型中存在方差是很常见的,可以通过使用最终模型的集成来克服
https://machinelearning.org.cn/ensemble-methods-for-deep-learning-neural-networks/
嗨,Jason,感谢您的这篇帖子和您的博客!我最近开始了我的ML/DL之旅,我发现您的博客非常有帮助。
我有一个关于训练/验证损失的问题。如果一个模型只在最初的n次迭代中学习,然后损失和准确率在第一个epoch期间就达到了一个平台,并且第一个epoch后的验证损失很大,那该怎么办?我正在使用Adam,参数默认。
当模型停止学习时就停止训练。也许可以尝试模型或学习算法的其他配置。
对于第三个图,它显然是过拟合现象。但是继续训练有害吗?因为继续训练无论如何都不会增加验证损失,至少目前是这样。我之所以问这个问题,是因为我见过一种特定的行为,即模型像第三个图一样过拟合,但如果训练过程继续,验证集的准确率和IoU仍然会增加。您怎么看?
第三张图名为“训练和验证学习曲线示例,显示过拟合模型”,显示了过拟合。
在这种情况下继续训练将导致训练集上的性能更好,而在保留集和任何其他新数据上的泛化误差更差。
损失的行为通常与其他指标相对应。但这是一个好点,也许可以绘制您打算用来选择模型的指标。
在训练数据集不具代表性的情况下(如果我无法增加数据集),可以采取哪些改进措施?
您的模型效果只与您的训练数据集一样有效。
也许可以尝试过采样,例如SMOTE。
也许可以尝试数据清洗,使决策边界更清晰。
也许可以尝试变换以找到更合适的表示。
您好,文章很棒。不过我有一个问题。
以下两者有什么区别?
– 机器学习学习曲线(如本文所述)和
– 学习曲线理论作为图形表示人对某项任务的熟练程度与经验量之间关系的方式)https://en.wikipedia.org/wiki/Learning_curve
感谢您的宝贵时间
谢谢!
没有关系。
嗨,Jason,
您对模型学习曲线在第一个epoch就出现损失0和准确率1的现象有什么建议?
另外,这可能的原因是什么?
有没有相关链接讨论这个问题?
一如既往地感谢。
这表明这是一个微不足道的问题,可能不需要机器学习。
https://machinelearning.org.cn/faq/single-faq/why-cant-i-get-100-accuracy-or-zero-error-with-my-model
你好 Jason,
我有一个关于我的学习曲线的问题。我本来想把我的问题发布到stat.stackexchange上,但我觉得我更信任你....
1. 我有一个包含23,000条记录的数据集,我有一个二分类任务。目标变量的分布是87%对13%。XGB分类器在我的数据上表现最好,总体准确率达到97.88%。
我的曲线看起来像这样:
https://ibb.co/NsnY1qH
如您所见,我正在使用对数损失进行评估。我的解释是它没有过拟合或欠拟合数据,并且我可以继续。
2. 我对数据的最后13%(正样本)有一个回归任务,我必须预测不同的合同值。
我的学习曲线看起来像这样
https://ibb.co/MnZbB15
我在这里的解释是,我需要更多数据才能做出好的预测。合同价值范围从0到200,000美元,分布非常偏斜…
一如既往地感谢您的支持!
马龙
抱歉,我尽量避免为读者解释结果。
相反,我提供一般性建议,以便您自己解释结果。或许可以探索额外的模型、配置和数据预处理,看看是否能取得更好的结果,否则可能您已经达到了数据集的极限。
对不起,我不知道,谢谢
非常棒的帖子,信息量很大。如果您不介意,我还有几个问题想问。
1. 当您提到验证集时,您实际上是指三部分数据集(训练/验证/测试)中的验证集吗?只是想确认一下,因为有些地方将测试集称为验证测试。
2. 有没有可用的代码,我们可以用来复现您展示的图表?(如果能提供,将不胜感激)
3. 如果我错了,请纠正我,如果我进行嵌套交叉验证,我认为我不需要绘制学习曲线,因为我理论上已经达到了最佳可能的模型性能和泛化(在数据量充足、迭代次数和特征数量正确以及超参数值正确的情况下)。所以,在我看来,通过使用嵌套交叉验证,我无法再做任何事情来减少过拟合,因此学习曲线是不必要的,对吗?
谢谢!
正确,验证集是训练集的一个子集。
https://machinelearning.org.cn/difference-test-validation-datasets/
是的,我在博客上有很多例子,请使用搜索框。或许从这里开始:
https://machinelearning.org.cn/display-deep-learning-model-training-history-in-keras/
没错,学习曲线是对模型性能不佳的诊断,对模型选择/通用测试工具(如嵌套交叉验证)没有帮助。
嗨,Jason,
如果数据集有3个或更多特征X1、X2、…,我想绘制一个输出变化与所有特征X1、X2、…的图表,我该怎么做?它在机器学习中有什么意义?
谢谢你
也许是成对散点图,每对变量一个。
非常感谢您的帮助。
我看了这篇文章 https://machinelearning.org.cn/visualize-machine-learning-data-python-pandas/
嗨,Jason
我的模型学习曲线,损失曲线——训练和测试——都正常,但是训练和测试的准确率从第一个epoch开始就达到了100%。
我该怎么办?
有什么建议吗?
一如既往地感谢您!
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-does-it-mean-if-i-have-0-error-or-100-accuracy
你好,
如果您能诊断我的学习曲线,我将不胜感激:https://imgur.com/a/z5ge9QI
我得到的准确率是97%,但我不知道根据我得到的学习曲线,模型是过拟合还是欠拟合。
谢谢你。
抱歉,我避免尝试为读者解释结果。
相反,我提供一般性建议,以便您自己解释结果。
嗨,谢谢您的信息丰富的帖子!如果我的Python应用程序每次运行时生成的学习曲线彼此差异太大怎么办?有时验证曲线太嘈杂,有时它与训练曲线收敛。这说明了数据集什么问题,还是我的曲线生成代码有问题?谢谢!
不客气。
好问题,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
你好 Jason,
谢谢教程,没有什么比刷新基础知识更好的了。
你知道,我多次遇到与标有“训练和验证学习曲线示例,显示验证数据集比训练数据集更容易预测”的图表相似的行为。我们应该增加验证集的大小,并减少训练集的大小,对吗?
举个例子:如果我以80%训练和20%验证的比例获得了这个图表,那么为了更好地拟合,一个好的方法是尝试70%-30%吗?我希望在这里得到一些“基于经验”的回答,因为你知道,“试错法”有时可能需要几个小时……
我一直通过使用回调来解决这个问题,但也许我限制了模型的学习能力,所以这可能是意识到我(可能)一直做错了什么的时机……
谢谢你,祝好。
谢谢。
我经常选择50-50,然后重复几次实验来平均结果。
您好,先生,
我的问题是回归,我有两个模型
当我用第一个模型绘图时:得到了一个很好的拟合,但RMSE的值不好
但当我用第二个模型绘图时,测试损失曲线位于训练损失曲线下方,两者之间的差异与“不具代表性的验证数据集”的情况几乎相似(训练损失下降并稳定),但RMSE值优于第一个模型
我有191981个训练样本/47996个测试样本
请问第二个模型正确吗?
也许可以测试一套不同的模型,然后使用针对您选择的特定指标表现最佳的模型。
感谢Jason的信息丰富文章。
请问有什么可能的解决方案来解决不具代表性的验证数据集问题吗?
我正在将其应用于心电图问题,其中不同患者具有不同的心动周期模式。因此,尽管有大约4000个正常的训练模式可供学习,但由于问题本身的固有性质(即每个患者的心电图模式都有一些差异),它们看起来都不同。
谢谢。
您可以尝试使用大型数据集进行验证,例如50/50的训练分割。
不确定验证集如何用于时间序列,可能不是一个有效的概念。
好的,谢谢。
你好,Jason
我总是得到 loss: 0.0000e+00 – val_loss: 0.0000e+00 从模型训练的第一个epoch开始,因此学习曲线是一条直线在0。
您对这种模型行为有什么可能的建议,可以进行调整吗?谢谢。
这可能表明您的问题很容易解决/微不足道,例如
https://machinelearning.org.cn/faq/single-faq/what-does-it-mean-if-i-have-0-error-or-100-accuracy
你好,
这是过拟合吗?
https://ibb.co/Z6nrXM4
非常感谢
抱歉,我尽量避免为读者解释结果。
好的,非常感谢您提供的参考资料。
不客气。
https://docs.google.com/document/d/1Va__vfW7JaXSLOsRuC5mXX4T1333AUPI/edit?usp=sharing&ouid=107190645093315861813&rtpof=true&sd=true
我想问Jason,找到拐点的最佳实践是什么?
在上面的学习曲线中,我们可以看到损失持续下降,但val_loss有一个突起。
val_loss@ 0,01 ( epoch 0 – 20) 点A 拐点给出更接近的预测。
人们是否使用相同时间内损失的百分比下降和val_loss的百分比增加来识别拐点。
我之前在epoch 40-60之间使用拐点B,当时val_loss约为0.02,但这会产生较大的预测误差。
然后我观察到,在epoch 15-50之间(这些是近似值),损失下降了8%,而val_loss增加了100%。
这是否足以作为停止训练并选择点A作为拐点的标准?
谢谢
在训练时,损失持续下降而验证损失在一段时间后可能上升是正常的。那就是过拟合的开始。你可以查看关于提前停止的帖子以了解更多信息:https://machinelearning.org.cn/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
除非我没有正确理解提前停止和最佳模型,否则我认为以下算法将给出最佳epoch,而且我不认为它是由两者中的任何一个给出的。
对于一个epoch要成为最佳epoch,损失在所有epoch中应该是最小的,并且该epoch的验证损失也应该是最小的。例如,如果最佳epoch的损失为0.01,验证损失为0.001,则不存在其他epoch的损失小于等于0.01且验证损失小于0.001。
最佳模型只单独考虑验证损失。它应该与损失协调一致。
因此,我们需要实现上述算法来获得最佳epoch,因为并非所有的学习曲线都是平滑的,并且存在凹凸不平的情况。
不确定提前停止在这里也有助于准确地获得那个最佳epoch。
想法?
根据Keras关于提前停止模块的文档,“当监控的指标停止改进时停止训练。”您可以决定要监控哪个指标。默认是val_loss,希望能有所帮助。
你好,
我正在尝试构建一个3D CNN回归网络。我的输入数据是(64,64,64)体素。输出是0-5之间的数值。我尝试了一些文献中的模型进行特征选择。我还对输出数据使用了最小-最大归一化、对数归一化和标准化。尽管我使用了Dropout和小型网络以及全连接部分的节点,但我的验证损失并没有像训练损失那样得到很好的下降。
验证损失略有增加,例如从 0.016 增加到 0.018。但即使在第一个 epoch 中,验证损失也以非常小的数字开始。我该怎么办?
谢谢回复
验证损失值取决于数据的规模。值 0.016 可能没问题(例如,预测一天的股票市场回报),也可能太小(例如,预测股票市场的总交易量)。要检查,您可以查看验证损失的定义方式以及输入的规模,并思考这是否有意义。
先生,这些是我的模型结果。https://snipboard.io/7kWsuz.jpg 想必这是因为我的数据集不具代表性,如果您能澄清一下就太好了。谢谢
看起来验证集很小/有噪声。可能 epoch 数量也太少了。
你好,Jason 博士;
我的数据集训练有 30,000 张图像,测试有 5000 张。我得到了这样的图表
https://ibb.co/Wpmzmh3
请问如何解决这个问题?epoch 在第 26 个 epoch 停止
训练损失和验证损失之间的差异不是很大。这是一个问题吗?我看到你的模型收敛很快。
你好,Jason 博士,你的帖子非常有用。我训练了四个回归模型,学习曲线显示在链接中。你对这些模型有什么看法?我可以使用它们进行预测吗?
https://docs.google.com/document/d/1_OjzPLk9QBPVR1aNFNQGDOZIJSUfTUcF5mFvEGZa0A0/edit?usp=sharing
你好 Bruce……虽然我不能直接评论你的项目,但我建议你利用一个朴素模型来建立一个性能基线,然后根据均方根误差将每个模型的性能与此基线进行比较。
大家好
我正在尝试理解一个分类问题的学习曲线。但我不太确定要推断出什么。我相信我存在过拟合,但我不能确定。
1. 训练损失非常低,在添加训练示例时略有增加。
2.“在添加训练示例时,验证损失逐渐下降(没有变平)”。
然而,我没有看到线条末端有任何间隙,这通常可以在过拟合模型中找到
另一方面,我可能存在欠拟合,因为
1. 欠拟合模型的学习曲线在开始时具有较低的训练损失,在添加训练示例时逐渐增加并保持平坦,表明添加更多训练示例无法提高模型在未见数据上的性能
2. 训练损失和验证损失在末尾彼此接近
然而,训练误差并不是很大,这通常在欠拟合模型中发现
我很困惑,您能给我一些建议吗?
https://i.stack.imgur.com/xGKAj.png
https://i.stack.imgur.com/gkRMn.png
你好 Aggelos……以下内容可能对你感兴趣
https://machinelearning.org.cn/improve-deep-learning-performance/
欠拟合的第二个示例曲线是如何工作的?为什么验证损失低于训练损失?这是标签错误,还是我遗漏了什么?谢谢。
你好 Jurrian……以下内容希望能澄清
https://machinelearning.org.cn/diagnose-overfitting-underfitting-lstm-models/
健康领域学习曲线的类型以及过去和现在的区别是什么
你好 Belal……请详细说明和/或重新措辞你的问题,以便我更好地帮助你。
健康领域学习曲线的类型以及过去和现在的区别是什么
“模型的损失几乎总是低于验证数据集的训练数据集”,然后你直接继续展示一个验证损失低于训练损失的图。你能解释一下吗?
你好 Dion……以下内容可能对你感兴趣
https://pyimagesearch.com/2019/10/14/why-is-my-validation-loss-lower-than-my-training-loss/
嗨 James,
我实际上遇到了一个让我困惑的情况,即训练损失持续下降,而验证损失趋于稳定(大约在 60/100 epoch)。“泛化差距”越来越大(10/100 epoch 后验证损失高于训练损失)。
你认为这是一种欠拟合吗?
非常感谢!
你好 Wyatt……你可能会发现以下内容很有趣
https://machinelearning.org.cn/overfitting-and-underfitting-with-machine-learning-algorithms/
谢谢!我在这篇文章中学到了很多,但我仍然有一个问题要问。我认为我存在训练数据不具代表性的问题(我的数据是图像),但我在训练集和验证集中都有相同类别的分布。对于如何解决这个问题,你有什么建议吗?我也无法改变分割比例(我的分割是 8:1:1 训练:验证:测试),因为我的数据非常有限,我已经进行了数据增强,但无济于事,差距仍然存在。这可能是什么问题?
你好 RJ……非常欢迎你!你能详细说明你的模型性能出现的问题,以便我们更好地帮助你吗?
我正在处理一个分类问题,我在学习曲线中遇到了一个奇怪的行为。我绘制了损失曲线和准确率曲线。我的模型在训练集上的准确率为 84%,在测试集上为 72%,但当我观察损失图时,训练损失正在下降,但验证损失没有。
你好 Talal……你可能会发现以下内容很有趣
https://machinelearning.org.cn/overfitting-machine-learning-models/
你好 James,你能给我一个提示吗,为什么我的 MLP 模型的训练损失看起来像是一个很好的拟合模型,但它的验证损失几乎是一条直线,就像这篇文章中第一个欠拟合学习曲线中的那样?
你好 Jane……以下资源可能对你感兴趣
https://machinelearning.org.cn/overfitting-machine-learning-models/
https://machinelearning.org.cn/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/