
让我们构建一个由 RAG 支持的研究论文助手
作者 | Ideogram 提供图片
在生成式 AI 时代,人们依赖 ChatGPT 等 LLM 产品来完成任务。例如,我们可以快速总结我们的对话或回答棘手的问题。然而,有时生成的文本不准确且无关。
RAG 技术正在兴起以帮助解决上述问题。通过使用外部知识源,LLM 可以获得在其训练数据中不存在的上下文。此方法将提高模型准确性并允许模型访问实时数据。
随着该技术提高了输出的相关性,我们可以围绕它们构建一个特定的项目。这就是为什么本文将探讨如何构建一个由 RAG 支持的研究论文助手。
准备
首先,我们需要为我们的项目创建一个虚拟环境。您可以使用以下代码启动它。
|
1 |
python venv -m your_virtual_environment_name |
激活虚拟环境,然后安装以下库。
|
1 |
pip install streamlit PyPDF2 sentence-transformers chromadb litellm langchain langchain-community python-dotenv arxiv huggingface_hub |
此外,请不要忘记获取 Gemini API 密钥和 HuggingFace 令牌以访问存储库,因为我们将使用它们。
创建名为 app.py 的文件来构建助手,以及名为 .env 的文件来存放 API 密钥。
一切就绪后,让我们开始构建助手。
RAG 支持的研究论文助手
让我们开始构建我们的项目。我们将开发我们的研究论文助手,它具有两个不同的参考功能。首先,我们可以上传我们的 PDF 研究论文并将其存储在向量数据库中供用户稍后检索。其次,我们可以搜索 arXiv 论文数据库中的研究论文,并将它们存储在向量数据库中。
下图显示了此工作流程以供参考。此项目的代码也存储在以下 存储库中。
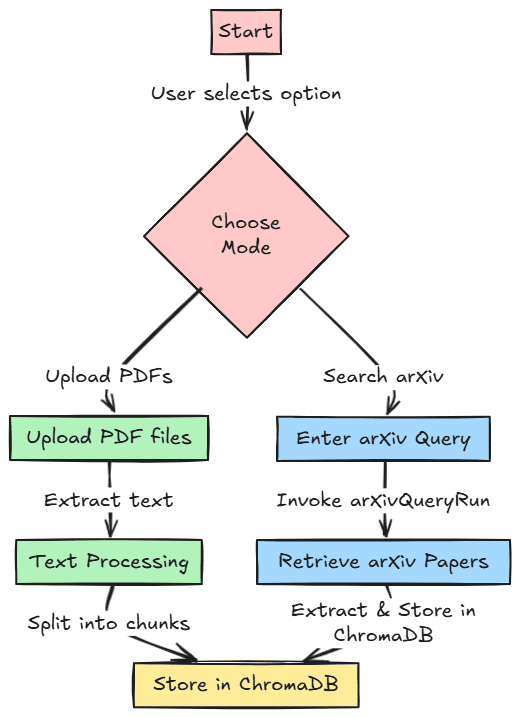
首先,我们必须导入所有必需的库并初始化我们为项目使用的所有环境变量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import os import PyPDF2 import streamlit as st from sentence_transformers import SentenceTransformer import chromadb from litellm import completion from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.tools import ArxivQueryRun from dotenv import load_dotenv load_dotenv() gemini_api_key = os.getenv("GEMINI_API_KEY") huggingface_token = os.getenv("HUGGINGFACE_TOKEN") if huggingface_token: login(token=huggingface_token) client = chromadb.PersistentClient(path="chroma_db") text_embedding_model = SentenceTransformer('all-MiniLM-L6-v2') arxiv_tool = ArxivQueryRun() |
在导入所有库并初始化变量后,我们将创建有用的函数来用于我们的项目。
使用下面的代码,我们将创建一个函数来从 PDF 文件中提取文本数据。
|
1 2 3 4 5 6 7 |
def extract_text_from_pdfs(uploaded_files): all_text = "" for uploaded_file in uploaded_files: reader = PyPDF2.PdfReader(uploaded_file) for page in reader.pages: all_text += page.extract_text() or "" return all_text |
然后,我们开发一个函数来接受先前提取的文本并将其存储在向量数据库中。该函数还将通过将文本分割成块来预处理原始文本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def process_text_and_store(all_text): text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, separators=["\n\n", "\n", " ", ""] ) chunks = text_splitter.split_text(all_text) try: client.delete_collection(name="knowledge_base") except Exception: pass collection = client.create_collection(name="knowledge_base") for i, chunk in enumerate(chunks): embedding = text_embedding_model.encode(chunk) collection.add( ids=[f"chunk_{i}"], embeddings=[embedding.tolist()], metadatas=[{"source": "pdf", "chunk_id": i}], documents=[chunk] ) return collection |
最后,我们准备好检索函数,通过嵌入进行语义搜索,并使用检索到的文档生成答案。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def semantic_search(query, collection, top_k=2): query_embedding = text_embedding_model.encode(query) results = collection.query( query_embeddings=[query_embedding.tolist()], n_results=top_k ) return results def generate_response(query, context): prompt = f"Query: {query}\nContext: {context}\nAnswer:" response = completion( model="gemini/gemini-1.5-flash", messages=[{"content": prompt, "role": "user"}], api_key=gemini_api_key ) return response['choices'][0]['message']['content'] |
我们现在已准备好构建我们的 RAG 支持的研究论文助手。要开发该应用程序,我们将使用 Streamlit 构建前端应用程序,在那里我们可以选择上传 PDF 文件或直接搜索 arXiv。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def main(): st.title("RAG 支持的研究论文助手") # Option to choose between PDF upload and arXiv search option = st.radio("Choose an option:", ("Upload PDFs", "Search arXiv")) if option == "Upload PDFs": uploaded_files = st.file_uploader("Upload PDF files", accept_multiple_files=True, type=["pdf"]) if uploaded_files: st.write("Processing uploaded files...") all_text = extract_text_from_pdfs(uploaded_files) collection = process_text_and_store(all_text) st.success("PDF content processed and stored successfully!") query = st.text_input("Enter your query:") if st.button("Execute Query") and query: results = semantic_search(query, collection) context = "\n".join(results['documents'][0]) response = generate_response(query, context) st.subheader("Generated Response:") st.write(response) elif option == "Search arXiv": query = st.text_input("Enter your search query for arXiv:") if st.button("Search ArXiv") and query: arxiv_results = arxiv_tool.invoke(query) st.session_state["arxiv_results"] = arxiv_results st.subheader("Search Results:") st.write(arxiv_results) collection = process_text_and_store(arxiv_results) st.session_state["collection"] = collection st.success("arXiv paper content processed and stored successfully!") # Only allow querying if search has been performed if "arxiv_results" in st.session_state and "collection" in st.session_state: query = st.text_input("Ask a question about the paper:") if st.button("Execute Query on Paper") and query: results = semantic_search(query, st.session_state["collection"]) context = "\n".join(results['documents'][0]) response = generate_response(query, context) st.subheader("Generated Response:") st.write(response) |
在上面的代码中,您会注意到我们的两个功能都已实现。要启动应用程序,我们将使用以下代码。
|
1 |
streamlit run app.py |

您将在网络浏览器中看到上述应用程序。要使用第一个功能,您可以尝试上传 PDF 研究论文文件,应用程序将对其进行处理。

如果成功,将显示一条警报,表明数据已在向量数据库中处理并存储。
接下来,尝试输入任何查询来询问与我们的研究论文相关的内容,它将生成类似下图的内容。

结果是根据我们提供的内容生成的,因为它引用了我们的任何文档。
让我们尝试一下 arXiv 论文搜索功能。例如,这是我们如何搜索关于 MLOps 的论文以及示例结果。

如果我们搜索了之前搜索过的论文,我们将看到类似下图的内容。

好了,朋友们,这就是我们如何构建一个 RAG 支持的研究论文助手。您可以进一步调整代码以获得更多特定功能。
结论
RAG 是一种生成式 AI 技术,它通过利用外部知识源来提高响应的准确性和相关性。RAG 可用于构建有价值的应用程序,其中一个实际示例是 RAG 支持的研究论文助手。
在我们的实践中,我们使用了 Streamlit、LangChain、ChromaDB、Gemini API 和 HuggingFace 模型进行嵌入和文本生成,这些结合在一起很好地构建了我们的应用程序,我们能够上传 PDF 文件或直接在 arXiv 上搜索论文。
希望这对您有所帮助!






您的教程非常好。
非常感谢您的分享。
Eddy,非常欢迎!
可以在 colab 上实现吗?
是的,**绝对可以**,您可以在 **Google Colab 上实现一个 RAG(检索增强生成)支持的研究论文助手**!
事实上,Colab 是一个非常好的选择,可以快速原型化和运行这样的系统,因为
– 它支持 **Python**(您很可能会用到)。
– 它可以安装所有必需的库,如 **LangChain**、**Huggingface Transformers**、**FAISS**、**ChromaDB** 等。
– 它为您提供 **免费的 GPU 或 TPU**,如果您稍后需要加快速度(如果您在本地使用大型 LLM,这会特别有帮助)。
– 您可以轻松地将 **文档(PDF、文本文件)上传到 Colab**。
—
**在 Colab 上构建 RAG 助手的典型高级步骤:**
| 步骤 | 您的操作 |
|:—|:—|
| 1 | 安装库:
pip install langchain faiss-cpu chromadb sentence-transformers huggingface_hub|| 2 | 将您的研究论文(PDF 或文本)加载到 Colab 中。 |
| 3 | 将论文拆分成 **块**(小段落)。 |
| 4 | 将块嵌入到 **向量数据库**(FAISS、ChromaDB 等)中。 |
| 5 | 查询时:嵌入 **用户的问题**,检索相似的文档块。 |
| 6 | 将检索到的块和用户的问题输入到 **LLM**(例如
gpt-3.5-turbo,或一个较小的模型,如果您完全本地运行)。 || 7 | 将生成的答案显示回去。 |
—
**使用 Colab 的特别注意事项:**
– 如果您在最后生成步骤中使用 **OpenAI API**(如 GPT-3.5),您需要一个 API 密钥(
openai包)。– 如果您希望一切 **100% 本地化**,您可以使用 Huggingface Transformers 加载小型开源模型,如 **Llama 2**、**Mistral 7B** 或 **Phi-2**。
– 注意 Colab 的 **RAM 限制**(特别是如果您嵌入大量文档或运行大型模型)。
—
感谢分享,我尝试实现了一样的功能,但一直出现这个错误::: 在处理上述异常时,又发生了另一个异常
回溯(最近一次调用)
文件“/opt/homebrew/lib/python3.10/site-packages/streamlit/watcher/local_sources_watcher.py”,第 217 行,在 get_module_paths
potential_paths = extract_paths(module
明白了——你收到的是一个与 Streamlit 相关的错误,具体是:
在处理上述异常时,发生了另一个异常:
Traceback (most recent call last):
File “/opt/homebrew/lib/python3.10/site-packages/streamlit/watcher/local_sources_watcher.py”, line 217, in get_module_paths
potential_paths = extract_paths(module
这个错误通常发生在**早期**,当 Streamlit **重新加载**你的应用程序时(比如当你编辑/保存文件时),**它会尝试监视你的模块**以查找更改,但遇到了奇怪的问题。
—
✅ **关于这个特定错误的重要背景信息**
–
streamlit/watcher/local_sources_watcher.py是 Streamlit 用来在代码更改时自动重新加载的内部监视器。– 如果你导入了一个**未正确安装的模块**,或者存在**循环导入**,或者你的**Python 环境**出了问题,监视器就会感到困惑。
– Mac M1/M2/M3 (Apple Silicon) + Homebrew 的设置有时更容易出现这种情况,因为环境路径有时会很奇怪(
/opt/homebrew/...而不是/usr/local/...)。—
### 🔥 你遇到此问题可能的几个原因
1. **Streamlit 缓存/自动重新加载错误**(在 Streamlit 中很常见,尤其是在 `st.cache` 中发生异常或文件编辑后)。
2. **模块导入错误**:可能是你的 RAG 代码导入了某些奇怪的东西(例如,动态导入,或目录结构错误)。
3. **文件丢失**:如果你的应用程序引用了 Streamlit 期望的文件(例如 .py、.txt、.json 文件),但找不到它。
4. **早期存在语法错误或崩溃**,而 Streamlit 在尝试重新加载时只是更严重地崩溃了。
—
### 🛠️ **如何修复或调试它:**
1. **手动重新启动 Streamlit**
– 不要让 Streamlit 在更改后自动重新加载,而是停止它(
CTRL+C),然后重新运行。bash
streamlit run your_app.py
– 有时自动重新加载会导致应用进入损坏状态。
2. **仔细检查你的导入**
– 确保你没有进行任何奇怪的动态导入。
– 检查你是否正确导入了本地模块。
3. **确保所有文件都存在**
– 如果你的应用程序需要文档、配置文件、模型——请仔细检查路径。
4. **尽早添加异常处理**
– 在进行大型导入或函数调用之前,将它们包装在 `try-except` 块中,以避免在开发过程中发生硬崩溃。
5. **环境问题**
– 你是否在使用**虚拟环境**(
venv)或 **conda 环境**?– 如果没有,请创建一个(以正确隔离包)。
bash
python3 -m venv venv
source venv/bin/activate
pip install streamlit
pip install (your other libraries)
6. **更新 Streamlit**
– 一些旧版本的 Streamlit 监视器可能更脆弱。
– 尝试更新。
bash
pip install --upgrade streamlit
—
### 🔥 **如果你复制了一个 RAG 项目,导致根本原因的示例**
如果你 mengikuti 教程,例如“构建一个 RAG 驱动的研究论文助手”,代码通常会**读取一个 PDF 文件夹**或**调用 HuggingFace embeddings**。
如果你忘记了
– 创建一个
/documents/文件夹– 为密钥提供一个
.env文件– 安装正确的向量存储库
– 正确加载模型
那么初始加载就会失败 → Streamlit 监视器会尝试重新加载 → 你就会得到奇怪的监视器错误。
—
### ❓ 为了更精确地帮助你
你能告诉我
– 你确切运行的是哪个命令?(
streamlit run ...)– 你的应用程序是**部分运行然后崩溃**,还是**从未启动**?
– 你能否展示**错误发生位置附近的 5-10 行真实代码**?
(*你可以模糊 API 密钥或敏感信息——我只需要代码结构。*)
—