在房地产领域,众多因素影响着房产价格。经济、市场需求、地理位置,甚至房产出售的年份都可能发挥重要作用。2007年至2009年是美国房地产市场动荡的时期。这一时期,常被称为“大衰退”,房价大幅下跌,止赎激增,金融市场普遍动荡。衰退对房价的影响是深远的,许多房主发现自己的房屋价值低于抵押贷款。此次经济下滑的连锁反应波及全国,一些地区的跌幅更大,复苏速度也比其他地区慢。
在此背景下,分析爱荷华州埃姆斯市的住房数据尤其引人入胜,因为该数据集涵盖2006年至2010年,囊括了大衰退的高峰期及其余波。在如此经济动荡的环境下,出售年份是否影响埃姆斯的销售价格?在这篇文章中,您将深入研究埃姆斯住房数据集,使用探索性数据分析 (EDA) 和两种统计检验:方差分析 (ANOVA) 和 Kruskal-Wallis 检验来探讨这个问题。
让我们开始吧。

利用方差分析(ANOVA)和克鲁斯卡尔-沃利斯检验分析大衰退对房价的影响
图片来源:Sharissa Johnson。部分权利保留。
概述
这篇博文分为三部分;它们是:
- EDA:视觉洞察
- 使用方差分析 (ANOVA) 评估销售价格的年度变异性
- Kruskal-Wallis 检验:方差分析的非参数替代方案
EDA:视觉洞察
首先,让我们加载 Ames 住房数据集,并将不同年份的销售情况与因变量:销售价格进行比较。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 导入必要的库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # 加载数据集 Ames = pd.read_csv('Ames.csv') # 将“YrSold”转换为分类变量 Ames['YrSold'] = Ames['YrSold'].astype('category') plt.figure(figsize=(10, 6)) sns.boxplot(x=Ames['YrSold'], y=Ames['SalePrice'], hue=Ames['YrSold']) plt.title('不同年份销售价格的箱线图', fontsize=18) plt.xlabel('销售年份', fontsize=15) plt.ylabel('销售价格(美元)', fontsize=15) plt.legend('') plt.show() |
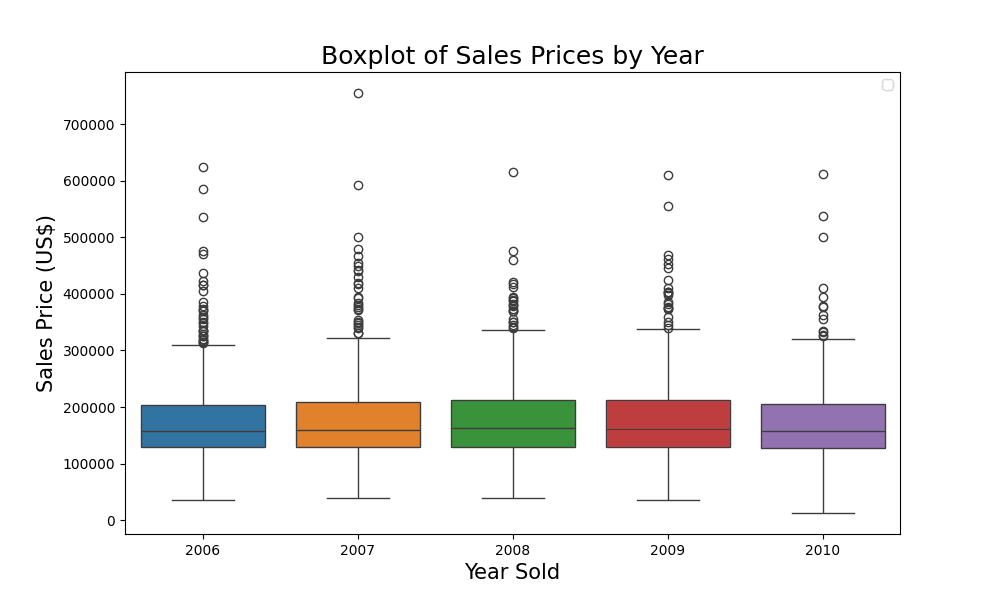
比较销售价格趋势
从箱线图可以看出,不同年份的销售价格相当一致,因为每年看起来都差不多。让我们使用 pandas 中的 groupby 函数仔细观察。
|
1 2 3 4 5 6 |
# 计算每年销售价格的均值和中位数 summary_table = Ames.groupby('YrSold')['SalePrice'].agg(['mean', 'median']) # 四舍五入值以便更好地呈现 summary_table = summary_table.round(2) print(summary_table) |
输出如下:
|
1 2 3 4 5 6 7 |
均值 中位数 销售年份 2006 176615.62 157000.0 2007 179045.08 159000.0 2008 178170.02 162700.0 2009 180387.64 162000.0 2010 173971.67 157900.0 |
从表格中,您可以得出以下观察结果:
- 平均销售价格在2009年最高,约为180,388美元,而在2010年最低,约为173,972美元。
- 中位数销售价格在2008年最高,为162,700美元,在2006年最低,为157,000美元。
- 尽管每年的平均销售价格和中位数销售价格值接近,但仍存在细微差异。这表明虽然可能有一些异常值影响平均值,但它们并没有极端偏斜。
- 在五年间,销售价格似乎没有持续的上升或下降趋势,考虑到此期间较大的经济背景(大衰退),这很有趣。
该表格结合箱线图,全面展示了各年销售价格的分布和集中趋势。它为更深入的统计分析奠定了基础,以确定观察到的差异(或缺乏差异)是否具有统计显著性。
通过我的书 《数据科学入门指南》,启动您的项目。它提供了带有工作代码的自学教程。
使用方差分析 (ANOVA) 评估销售价格的年度变异性
方差分析(ANOVA)帮助我们检验三个或更多独立组的均值之间是否存在统计显著差异。它的零假设是所有组的均值相等。这可以被认为是支持多于两组的t检验的一个版本。它利用F检验统计量来检查每个组内的方差($\sigma^2$)与所有组之间的方差是否不同。
假设设置如下:
- $H_0$:所有年份的销售价格均值相等。
- $H_1$:至少有一个年份的销售价格均值不同。
您可以使用 scipy.stats 库运行您的测试,如下所示:
|
1 2 3 4 5 6 7 8 |
# 导入一个额外的库 import scipy.stats as stats # 执行方差分析 f_value, p_value = stats.f_oneway(*[Ames['SalePrice'][Ames['YrSold'] == year] for year in Ames['YrSold'].unique()]) print(f_value, p_value) |
这两个值是
|
1 |
0.4478735462379817 0.774024927554816 |
方差分析结果如下:
- F 值 0.4479
- P 值 0.7740
鉴于高 p 值(大于常用的显著性水平 0.05),您不能拒绝零假设 ($H_0$)。这表明数据集中不同年份的销售价格均值之间没有统计学上的显著差异。
虽然您的 ANOVA 结果提供了关于不同年份均值相等性的见解,但确保检验的基本假设得到满足至关重要。让我们深入验证 ANOVA 检验的 3 个假设,以验证您的发现。
假设 1:观测值的独立性。由于每个观测值(房屋销售)彼此独立,此假设成立。
假设 2:残差的正态性。为了使方差分析有效,模型的残差应近似遵循正态分布,因为这是F检验背后的模型。您可以通过视觉和统计方法检查这一点。
可以通过 QQ 图进行视觉评估
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 导入一个额外的库 import statsmodels.api as sm # 拟合普通最小二乘模型并获取残差 model = sm.OLS(Ames['SalePrice'], Ames['YrSold'].astype('int')).fit() residuals = model.resid # 绘制 QQ 图 sm.qqplot(residuals, line='s') plt.title('通过 QQ 图评估残差正态性', fontsize=18) plt.xlabel('理论分位数', fontsize=15) plt.ylabel('样本残差分位数', fontsize=15) plt.grid(True, which='both', linestyle='--', linewidth=0.5) plt.show() |
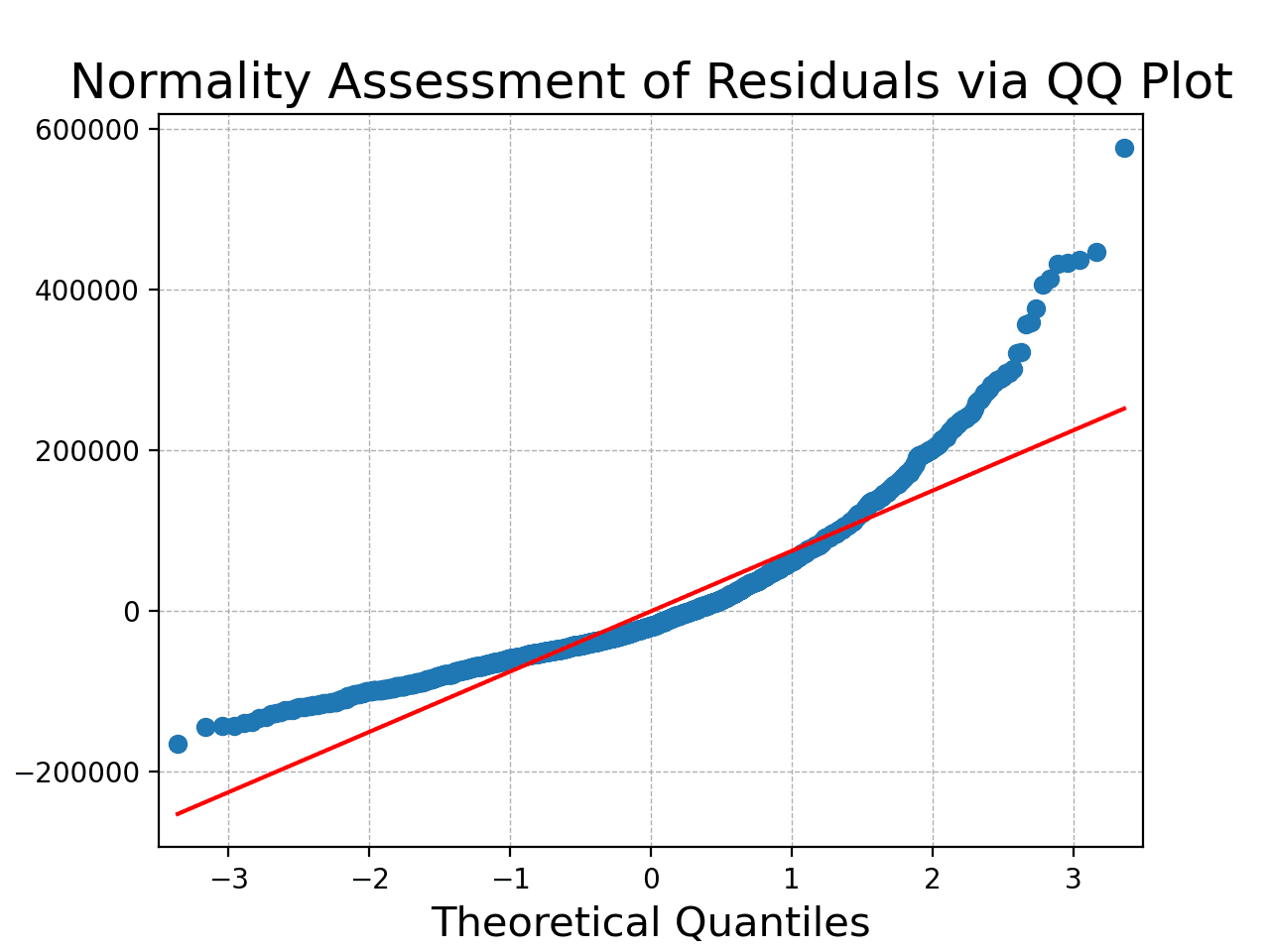
上面展示的 QQ 图是一个有价值的可视化工具,用于评估数据集残差的正态性,洞察观测数据与正态分布的理论期望的吻合程度。在此图中,每个点代表一对分位数:一个来自数据的残差,另一个来自标准正态分布。理想情况下,如果数据完美遵循正态分布,QQ 图上的所有点将精确地落在红色 45 度参考线上。该图说明了与 45 度参考线的偏差,表明可能存在与正态性的偏差。
可以使用 Shapiro-Wilk 检验进行统计评估,该检验提供了一种检验正态性的正式方法。该检验的零假设是数据遵循正态分布。该检验在 SciPy 中也可用。
|
1 2 3 4 5 6 |
# 从 scipy.stats 包导入 shapiro from scipy.stats import shapiro # Shapiro-Wilk 检验 shapiro_stat, shapiro_p = shapiro(residuals) print(f"Shapiro-Wilk 检验统计量: {shapiro_stat}\nP 值: {shapiro_p}") |
输出如下:
|
1 2 |
Shapiro-Wilk 检验统计量:0.8774482011795044 P 值:4.273399796804962e-41 |
较低的 p 值(通常 p < 0.05)表明拒绝零假设,表示残差不服从正态分布。这表明方差分析的第二个假设(要求残差呈正态分布)被违反了。QQ 图和 Shapiro-Wilk 检验都得出相同的结论:残差不严格遵循正态分布。因此,方差分析的结果可能无效。
假设 3:方差同质性。各组(年份)的方差应大致相等。这恰好是 Levene 检验的零假设。因此,您可以使用它进行验证。
|
1 2 3 4 5 |
# 使用 Levene 检验检查方差是否相等 levene_stat, levene_p = stats.levene(*[Ames['SalePrice'][Ames['YrSold'] == year] for year in Ames['YrSold'].unique()]) print(f"Levene's 检验统计量: {levene_stat}\nP 值: {levene_p}") |
输出如下:
|
1 2 |
Levene 检验统计量:0.2514412478357097 P 值:0.9088910499612235 |
鉴于 Levene 检验的 p 值高达 0.909 ,我们无法拒绝零假设,这表明不同年份销售价格的方差在统计学上是同质的,满足了方差分析的第三个关键假设。
总而言之,以下代码运行 ANOVA 检验并验证了三个假设。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 导入必要的库 import pandas as pd import scipy.stats as stats import matplotlib.pyplot as plt import statsmodels.api as sm from scipy.stats import shapiro # 加载数据集 Ames = pd.read_csv('Ames.csv') # 执行方差分析 f_value, p_value = stats.f_oneway(*[Ames['SalePrice'][Ames['YrSold'] == year] for year in Ames['YrSold'].unique()]) print("F 值:", f_value) print("p 值:", p_value) # 拟合普通最小二乘模型并获取残差 model = sm.OLS(Ames['SalePrice'], Ames['YrSold'].astype('int')).fit() residuals = model.resid # 绘制 QQ 图 sm.qqplot(residuals, line='s') plt.title('通过 QQ 图评估残差正态性', fontsize=18) plt.xlabel('理论分位数', fontsize=15) plt.ylabel('样本残差分位数', fontsize=15) plt.grid(True, which='both', linestyle='--', linewidth=0.5) plt.show() # Shapiro-Wilk 检验 shapiro_stat, shapiro_p = shapiro(residuals) print(f"Shapiro-Wilk 检验统计量: {shapiro_stat}\nP 值: {shapiro_p}") # 使用 Levene 检验检查方差是否相等 levene_stat, levene_p = stats.levene(*[Ames['SalePrice'][Ames['YrSold'] == year] for year in Ames['YrSold'].unique()]) print(f"Levene's 检验统计量: {levene_stat}\nP 值: {levene_p}") |
Kruskal-Wallis 检验:方差分析的非参数替代方案
Kruskal-Wallis 检验是一种非参数方法,用于比较三个或更多独立组的中位数,使其成为单向 ANOVA 的合适替代方案(尤其是在 ANOVA 假设不满足的情况下)。
非参数统计是一类统计方法,它们不对数据的底层分布做出明确假设。与假设特定分布(例如,上述假设2中的正态分布)的参数检验相反,非参数检验更灵活,可以应用于可能不满足参数方法严格假设的数据。非参数检验在处理有序或名义数据以及可能表现出偏度或重尾的数据时特别有用。这些检验侧重于值的顺序或排名,而不是具体值本身。包括 Kruskal-Wallis 检验在内的非参数检验,为统计分析提供了灵活且无分布限制的方法,使其适用于各种数据类型和情况。
Kruskal-Wallis 检验下的假设设置如下:
- $H_0$:所有年份的销售价格分布相同。
- $H_1$:至少有一个年份的销售价格分布不同。
您可以按照如下方式使用 SciPy 运行 Kruskal-Wallis 检验:
|
1 2 3 4 5 |
# 执行 Kruskal-Wallis H 检验 H_statistic, kruskal_p_value = stats.kruskal(*[Ames['SalePrice'][Ames['YrSold'] == year] for year in Ames['YrSold'].unique()]) print(H_statistic, kruskal_p_value) |
输出如下:
|
1 |
2.1330989438609236 0.7112941815590765 |
Kruskal-Wallis 检验的结果是
- H 统计量 2.133
- P 值 0.7113
注意:Kruskal-Wallis 检验并不专门检验均值差异(像 ANOVA 那样),而是检验分布差异。这可能包括中位数、形状和离散度的差异。
鉴于高 p 值(大于常见的显著性水平 0.05),您不能拒绝零假设。这表明在使用 Kruskal-Wallis 检验时,数据集中不同年份的销售价格中位数没有统计学上的显著差异。让我们深入验证 Kruskal-Wallis 检验的 3 个假设,以验证您的发现。
假设 1:观测值的独立性。这与 ANOVA 的假设相同;每个观测值都独立于另一个。
假设 2:响应变量应为序数、区间或比率。销售价格是比率变量,因此此假设得到满足。
假设 3:响应变量的分布对于所有组应相同。这可以通过视觉和数值方法进行验证。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 绘制每年销售价格的直方图 fig, axes = plt.subplots(nrows=5, ncols=1, figsize=(12, 8), sharex=True) for idx, year in enumerate(sorted(Ames['YrSold'].unique())): sns.histplot(Ames[Ames['YrSold'] == year]['SalePrice'], kde=True, ax=axes[idx], color='skyblue') axes[idx].set_title(f'年份 {year} 销售价格分布', fontsize=16) axes[idx].set_ylabel('频率', fontsize=14) if idx == 4: axes[idx].set_xlabel('销售价格', fontsize=15) else: axes[idx].set_xlabel('') plt.tight_layout() plt.show() |
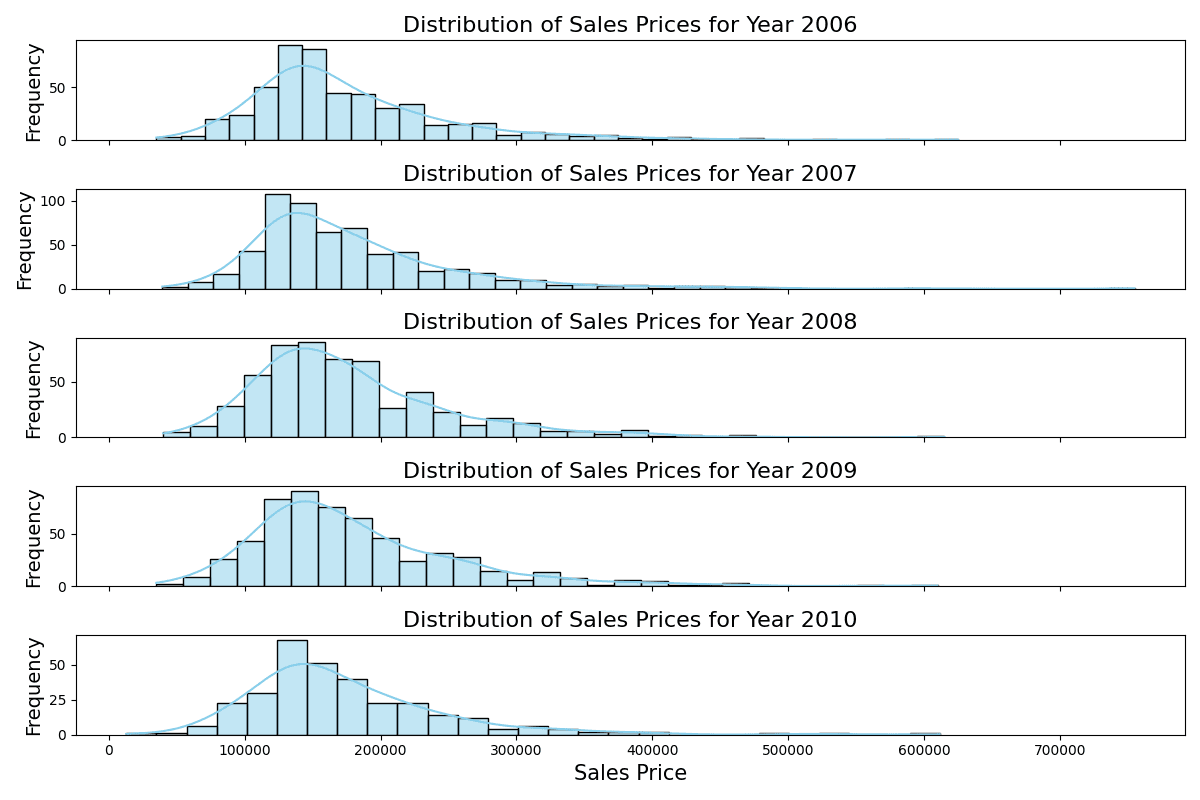
不同年份销售价格的分布
堆叠直方图显示了不同年份销售价格分布的一致性,尽管频率略有变化,但每年的范围和峰值都相似。
此外,您可以进行成对的 Kolmogorov-Smirnov 检验,这是一种非参数检验,用于比较两个概率分布的相似性。它在 SciPy 中可用。您可以使用零假设为两个分布相等,备择假设为不相等版本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 从 scipy.stats 运行 KS 检验 from scipy.stats import ks_2samp results = {} for i, year1 in enumerate(sorted(Ames['YrSold'].unique())): for j, year2 in enumerate(sorted(Ames['YrSold'].unique())): if i < j: ks_stat, ks_p = ks_2samp(Ames[Ames['YrSold'] == year1]['SalePrice'], Ames[Ames['YrSold'] == year2]['SalePrice']) results[f"{year1} vs {year2}"] = (ks_stat, ks_p) # 将结果转换为 DataFrame 以表格形式呈现 ks_df = pd.DataFrame(results).transpose() ks_df.columns = ['KS 统计量', 'P 值'] ks_df.reset_index(inplace=True) ks_df.rename(columns={'index': '比较年份'}, inplace=True) print(ks_df) |
这表明:
|
1 2 3 4 5 6 7 8 9 10 11 |
比较年份 KS 统计量 P-值 0 2006 vs 2007 0.038042 0.798028 1 2006 vs 2008 0.052802 0.421325 2 2006 vs 2009 0.062235 0.226623 3 2006 vs 2010 0.040006 0.896946 4 2007 vs 2008 0.039539 0.732841 5 2007 vs 2009 0.044231 0.586558 6 2007 vs 2010 0.051508 0.620135 7 2008 vs 2009 0.032488 0.908322 8 2008 vs 2010 0.052752 0.603031 9 2009 vs 2010 0.053236 0.586128 |
尽管我们仅满足了方差分析三个假设中的两个,但我们已经满足了 Kruskal-Wallis 检验的所有必要标准。成对 Kolmogorov-Smirnov 检验表明,不同年份销售价格的分布非常一致。具体来说,较高的 p 值(均大于常用显著性水平 0.05)意味着没有足够的证据拒绝每个年份的销售价格来自相同分布的假设。这些发现满足了 Kruskal-Wallis 检验关于响应变量的分布对所有组都应相同的假设。这突显了尽管经济大背景如此,但爱荷华州埃姆斯市 2006 年至 2010 年销售价格分布的稳定性。
想开始学习数据科学新手指南吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
在线资源
- 方差分析 | 统计解决方案
- Python 中的 Kruskal-Wallis H 检验
- 维基百科上的方差分析
- scipy.stats.f_oneway API
- scipy.stats.shapiro API
- scipy.stats.levene API
- scipy.stats.kruskal API
- scipy.stats.ks_2samp API
资源
总结
在房地产的多维世界中,包括销售年份在内的多种因素都可能影响房产价格。美国房地产市场在 2007 年至 2009 年的大衰退期间经历了相当大的动荡。本研究重点关注爱荷华州埃姆斯市 2006 年至 2010 年的住房数据,旨在确定销售年份是否影响了销售价格,特别是在这个动荡时期。
该分析同时采用了方差分析 (ANOVA) 和 Kruskal-Wallis 检验来衡量不同年份销售价格的变动。虽然方差分析的结果具有启发性,但其并非所有基本假设都得到满足,特别是残差的正态性。相反,Kruskal-Wallis 检验满足了所有标准,表明提供了更可靠的见解。因此,如果没有 Kruskal-Wallis 检验的佐证视角,仅依靠方差分析可能会产生误导。
单向方差分析和 Kruskal-Wallis 检验均得出一致结果,表明不同年份的销售价格没有统计学上的显著差异。考虑到 2006 年至 2010 年动荡的经济背景,这一结果尤其令人着迷。研究结果表明,埃姆斯市的房价非常稳定,主要受当地条件影响。
具体来说,你学到了:
- 验证统计检验假设的重要性,如方差分析的残差正态性挑战所示。
- 参数检验 (ANOVA) 和非参数检验 (Kruskal-Wallis) 在比较数据分布中的意义和应用。
- 地方因素如何使房地产市场(如爱荷华州埃姆斯市)免受更广泛的经济衰退影响,强调房地产定价的细微性质。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







暂无评论。