随机梯度下降是机器学习中一种重要且广泛使用的算法。
在本帖中,您将了解如何通过最小化训练数据集上的误差来使用随机梯度下降为简单的线性回归模型学习系数。
阅读本文后,您将了解
- 简单线性回归模型的形式。
- 梯度下降与随机梯度下降的区别
- 如何使用随机梯度下降学习简单的线性回归模型。
通过我的新书《精通机器学习算法》来启动您的项目,其中包含分步教程以及所有示例的Excel电子表格文件。
让我们开始吧。
- 2021年2月更新:修正了预测值中的拼写错误。

用于机器学习的梯度下降线性回归教程
照片由Stig Nygaard拍摄,部分权利保留。
教程数据集
我们使用的数据集是完全虚构的。
这是原始数据。属性 x 是输入变量,y 是我们要预测的输出变量。如果我们获得更多数据,我们将只有 x 值,并且我们会对预测 y 值感兴趣。
|
1 2 3 4 5 6 |
x y 1 1 2 3 4 3 3 2 5 5 |
下面是 x 与 y 的简单散点图。
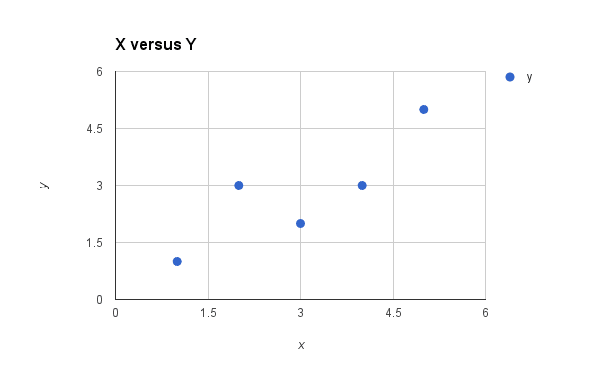
用于简单线性回归的数据集图
我们可以看到 x 和 y 之间的关系有点线性。也就是说,我们可能可以在图的左下角到右上角画一条对角线来大致描述数据之间的关系。这表明对这个小数据集使用线性回归可能是合适的。
获取您的免费算法思维导图
方便的机器学习算法思维导图样本。
我创建了一份方便的思维导图,其中包含60多种按类型组织的算法。
下载、打印并使用它。
还可以独家访问机器学习算法电子邮件迷你课程。
简单线性回归
当我们只有一个输入属性(x)并想使用线性回归时,这被称为简单线性回归。
使用简单线性回归,我们希望按如下方式建模数据
y = B0 + B1 * x
这是一条线,其中 y 是我们想要预测的输出变量,x 是我们已知的输入变量,B0 和 B1 是我们需要估计的系数。
B0 被称为截距,因为它决定了线在 y 轴上的截距。在机器学习中,我们可以称之为偏差,因为它会加到我们进行的所有预测上。B1 项被称为斜率,因为它定义了线的斜率,或者 x 在我们添加偏差之前如何转换为 y 值。
该模型被称为简单线性回归,因为它只有一个输入变量(x)。如果存在更多输入变量(例如 x1、x2 等),则称为多元回归。
随机梯度下降
梯度下降是通过沿着成本函数的梯度来最小化函数的过程。
这涉及知道成本的形式以及其导数,以便从给定点知道梯度并可以朝该方向移动,例如朝向最小值向下移动。
在机器学习中,我们可以使用一种称为随机梯度下降的类似技术来最小化模型在训练数据上的误差。
其工作原理是每个训练实例一次仅展示给模型。模型对训练实例进行预测,计算误差,并更新模型以减少下一次预测的误差。
此过程可用于查找模型中导致模型在训练数据上误差最小的系数集。每次迭代,系数(在机器学习语言中称为权重 w)都会使用以下方程进行更新
w = w – alpha * delta
其中 w 是正在优化的系数或权重,alpha 是您必须配置的学习率(例如 0.1),gradient 是模型在训练数据上归因于该权重的误差。
使用随机梯度下降进行简单线性回归
简单线性回归中使用的系数可以通过随机梯度下降找到。
线性回归是一个线性系统,系数可以通过线性代数进行解析计算。在实践中(在大多数情况下),随机梯度下降不用于计算线性回归的系数。
线性回归为学习随机梯度下降提供了一个有用的练习,随机梯度下降是机器学习算法通过最小化成本函数来使用的重要算法。
如上所述,我们的线性回归模型定义如下
y = B0 + B1 * x
梯度下降迭代 #1
让我们从两个系数的值都为 0.0 开始。
B0 = 0.0
B1 = 0.0
y = 0.0 + 0.0 * x
我们可以按如下方式计算预测误差
error = p(i) – y(i)
其中 p(i) 是我们数据集中第 i 个实例的预测值,y(i) 是数据集中第 i 个实例的第 i 个输出变量。
现在,我们可以使用我们起始系数为第一个训练实例计算 y 的预测值
x=1, y=1
p(i) = 0.0 + 0.0 * 1
p(i) = 0
使用预测输出,我们可以计算我们的误差
error = 0 – 1
error = -1
我们现在可以在梯度下降方程中使用此误差来更新权重。我们将从更新截距开始,因为它更容易。
我们可以说 B0 应该对所有误差负责。也就是说,更新权重将仅使用误差作为梯度。我们可以按如下方式计算 B0 系数的更新
B0(t+1) = B0(t) – alpha * error
其中 B0(t+1) 是我们将在下一个训练实例中使用的更新后的系数,B0(t) 是 B0 的当前值,alpha 是我们的学习率,error 是我们为训练实例计算的误差。让我们使用 0.01 的小学习率,并将值代入方程以计算 B0 的新且略有优化的值
B0(t+1) = 0.0 – 0.01 * -1.0
B0(t+1) = 0.01
现在,让我们看看更新 B1 的值。我们使用相同的方程,只是有一个小的变化。误差会根据导致它的输入进行过滤。我们可以使用以下方程更新 B1
B1(t+1) = B1(t) – alpha * error * x
其中 B1(t+1) 是更新后的系数,B1(t) 是当前版本的系数,alpha 是上面描述的相同学习率,error 是上面计算的相同误差,x 是输入值。
我们可以将我们的数字代入方程并计算 B1 的更新值
B1(t+1) = 0.0 – 0.01 * -1 * 1
B1(t+1) = 0.01
我们刚刚完成了梯度下降的第一次迭代,并将权重更新为 B0=0.01 和 B1=0.01。此过程必须对我们数据集中的其余 4 个实例重复。
一次通过训练数据集称为一个 epoch。
梯度下降迭代 #20
我们跳到后面。
您可以再重复此过程 19 次。这是训练数据暴露给模型并更新系数的 4 个完整 epoch。
这是您应该看到的 20 次迭代中所有系数值的列表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
B0 B1 0.01 0.01 0.0397 0.0694 0.066527 0.176708 0.08056049 0.21880847 0.1188144616 0.410078328 0.1235255337 0.4147894001 0.1439944904 0.4557273134 0.1543254529 0.4970511637 0.1578706635 0.5076867953 0.1809076171 0.6228715633 0.1828698253 0.6248337715 0.1985444516 0.6561830242 0.2003116861 0.6632519622 0.1984110104 0.657549935 0.2135494035 0.7332419008 0.2140814905 0.7337739877 0.2272651958 0.7601413984 0.2245868879 0.7494281668 0.219858174 0.7352420252 0.230897491 0.7904386102 |
我认为 20 次迭代或 4 个 epoch 是一个不错的整数,也是一个可以停止的好地方。如果您愿意,可以继续。
您的值应该非常接近,但由于不同的电子表格程序和不同的精度,可能会略有差异。您可以将每对系数重新代入简单线性回归方程。这很有用,因为我们可以为每个训练实例计算一个预测,进而计算误差。
下图显示了随着学习过程的进行,每个系数集的误差。这是一个有用的图,因为它表明误差随着每次迭代而减小,并在最后开始有一些波动。
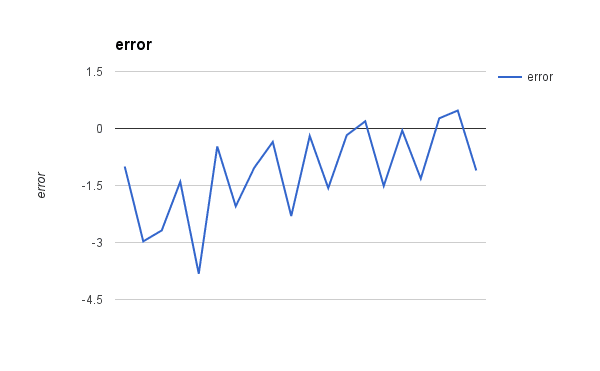
线性回归梯度下降误差与迭代次数的关系
您可以看到,我们的最终系数值为 B0=0.230897491 和 B1=0.7904386102
让我们将它们代入我们的简单线性回归模型,并为我们训练数据集中的每个点进行预测。
|
1 2 3 4 5 6 |
x 预测 1 1.02133610122753 2 1.81177471140694 4 3.39265193176576 3 2.60221332158635 5 4.18309054194517 |
我们可以再次绘制数据集,并叠加这些预测(x vs y 和 x vs prediction)。通过 5 个预测值画一条线,可以让我们大致了解模型与训练数据的拟合程度。
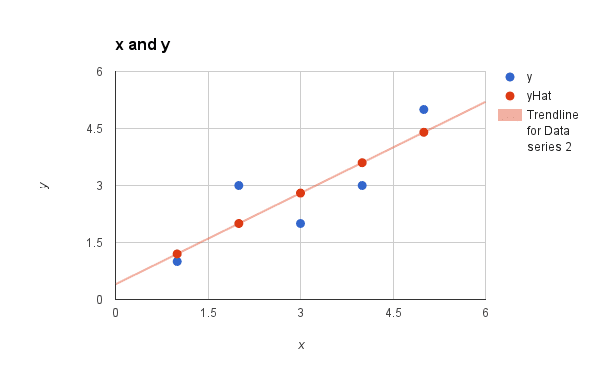
简单线性回归模型
总结
在本帖中,您了解了简单线性回归模型以及如何使用随机梯度下降对其进行训练。
您完成了梯度下降更新规则的应用。您还学习了如何使用学习到的线性回归模型进行预测。
您对这篇帖子或随机梯度下降的简单线性回归有任何疑问吗?请留言提问,我会尽力回答。







上帝保佑你和你家人。你的职责非常清晰,请继续保持。
我主耶稣保佑你的思想和你的职责。我无话可说了。
谢谢 Tadele。
你解释得很清楚。非常感谢。
谢谢你的美言 effa。我很高兴你觉得这篇帖子有用。
我开始对 epoch 和 iteration 感到困惑。epoch 或 iteration 是否取决于训练数据集中的观测数量?
我的数据集是 (year,cost)= [(2005,40.15), (2006,49.8), (2007,60), (2008,75), (2009,83), (2010,90), (2011,111), (2012,128). (2013,128), (2014,138), (2015,160),(2016,175) 我想应用带有随机梯度下降的线性回归。我应该设置多少 epoch 或 iteration?
一个 epoch 是完整遍历一次训练数据集。
迭代可能是一个 epoch,也可能是一个训练观测值(训练数据中的一行)的更新,具体取决于上下文(训练迭代 vs 更新迭代)。
你好 Jason,我正在研究具有多个响应变量的逻辑回归的随机梯度下降,并且遇到了困难。
我尝试使用相同的公式,但对误差项进行了不同的计算 [error=Y-(1/1+exp(-BX))]
我已将此代入您提供的方程,但系数似乎没有收敛。我是否遗漏了什么? A
请看这个教程 Alex
https://machinelearning.org.cn/implement-logistic-regression-stochastic-gradient-descent-scratch-python/
嗨,Jason,
在更新过程中,参数 m(训练示例数)在哪里?在其他教程中是这样的
B0(t+1) = B0(t) – alpha / m * error
B1(t+1) = B1(t) – alpha / m * error * x
我不确定你的意思 Serb。上面没有“m”。
是的,我看到没有 m,但它应该在那里。因为成本函数定义如下
J(B0, B1) = 1/(2*m) * (p(i) – y(i))^2
为了确定参数 B0 和 B1,需要使用梯度下降来最小化此函数并找到成本函数相对于 B0 和 B1 的偏导数。最后您将得到 B0 和 B1 的方程,其中有“m”。
Jason,
您提到了这些权重更新方程
B0(t+1) = B0(t) – alpha / m * error
B1(t+1) = B1(t) – alpha / m * error * x
B0 代表我们将要创建的回归线的斜率,B1 代表截距。
在其他教程中,我看到有人(https://www.youtube.com/watch?v=JsX0D92q1EI&t=16s)将 x 乘以斜率权重更新计算,而不是像这样乘以截距
B0(t+1) = B0(t) – alpha / m * error * x
B1(t+1) = B1(t) – alpha / m * error
您能否解释一下这是否不正确,或者我错在哪里了?
嗨,丹尼尔,
本文使用的更新方程基于教科书《人工智能:一种现代方法》第 18.6.1 节单变量线性回归第 718 页的方程。有关推导,请参阅此参考文献。
我无法评论 YouTube 视频中的方程。
嗨,丹尼尔,
我相信您可能将随机梯度下降和批量梯度下降混淆了。
在批量梯度下降中,您计算所有示例的总误差,然后除以示例数以得到“平均误差”。
另一方面,在随机梯度下降中,就像本文一样,您一次处理一个示例,因此无需除以示例数来计算平均值。
希望这有帮助。
另外,这篇帖子可能有助于澄清一些问题
https://machinelearning.org.cn/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
实际上 m 不是必需的。这完全取决于所选择的学习率,整个(alpha / m)可以被视为一个常数。关键是,学习率决定一切,m 只是另一个常数。
你能否为逻辑回归写一篇类似的帖子,让我们实际看到梯度下降的一些迭代?
谢谢。
你好 Akash,
这是带有 SGD 的逻辑回归教程
https://machinelearning.org.cn/implement-logistic-regression-stochastic-gradient-descent-scratch-python/
当我尝试计算第二个示例时,我得到的数值是 .03 和 0.06,而不是图片中显示的数值……请帮助我
请记住,在当前迭代中使用上一次迭代的更新值作为起始值。
我在我的书中提供了完整的电子表格示例
https://machinelearning.org.cn/master-machine-learning-algorithms/
你的 .03 是当 b0 = .01 和 b1= .01 时的 y(x) 值
要获得第二次迭代,你需要将输入代入此公式:b0= b0 – alpha* error 和 b1 = b1 – alpha * error*x,其中 x 是 3
好建议。
我的意思是,在第二次迭代中,我得到的数值是 0.03 和 0.06,而不是 0.0397 0.0694。请尽快帮助我
你好,收敛点在哪里?我们如何知道它就是函数的最小值点?您在计算 B0=0.230897491 和 B1=0.7904386102 处停止了计算。然后计算了预测值。您能否解释一下为什么它会停在这些 B0 B1 值上?应该是 error=0?我们如何看到它?谢谢!
很好的问题。
您可以评估每次更新后的系数,以了解模型的误差。
然后您可以使用模型误差来确定何时停止更新模型,例如当误差水平趋于平稳并停止下降时。
感谢 Jason 的帖子/教程!关于 Jenny 关于模型何时收敛的问题——在您显示的图中,误差似乎每迭代一次就越来越接近零(我认为我们可以说它在被最小化)。我想确认两点
1 – 您绘制的误差是模型误差(通过评估系数并与正确值进行比较计算)对吗?
2 – 我们经常看到绘制误差与迭代次数的图,其中误差随时间减小(http://i42.tinypic.com/dvmt6o.png);您图中的误差是否只是以不同的比例绘制?或者为什么大多数训练图都有误差从一个正数减小到零?
非常感谢您的澄清,再次感谢您的教程!
Belal
误差是在数据上计算的,以及模型在进行预测时犯了多少错误。
非常感谢您写了这么好的帖子,我有一个关于使用 B0 和 B1 值计算 y 坐标的疑问。根据我的计算,我们使用 y=B0+B1*x (来计算预测的 y),但是考虑到 B0=0.230897491 和 B1=0.7904386102,第一个实例(x=1,y=1)的答案应该是 y(predicted)=1.0213361012 (因为 y=(0.230897491)+(0.7904386102)*1),但在您的帖子中是 0.9551001992。所以是我做错了什么还是我理解错了?
如果我有什么遗漏,请指导我!
我也遇到了同样的问题。
B0=0.230897491 和 B1=0.7904386102 的值实际上是第 21 次迭代的值,所以是错误的。如果您查看这些值的图,您会注意到第 20 次迭代的值分别是 0.219858174 和 0.7352420252。代入这些值可以得到正确的预测(.95…)。可能是小小的笔误 🙂
如果有人想了解更多关于简单线性回归的知识,请访问以下链接 http://yasirchoudhary.blogspot.in/2017/06/linear-regression.html?m=1
感谢分享。
非常感谢!
终于明白了。
很高兴听到这个消息!
如何找到给定训练集(x,y)的 theta 0 和 theta 1 值?这样线性回归就能完美拟合数据?
除非数据是人为设计的,否则模型很少能完美拟合数据。
如果数据可以放入内存,使用线性代数方法将提供更稳健的估计。
模型是一种权衡。
SGD 和反向传播是相同的吗?在将图像分类到两个类别(例如猫和狗)时,模型是否在进行线性回归?如果不是,这将属于什么分类?
不,梯度下降是一种搜索算法,反向传播是估算神经网络中误差的一种方法。
布朗利博士:绝对是一个很棒的教程!我能够重现相同的结果。这个算法可以修改以处理多个参数吗?我正在尝试理解多参数的线性回归,但我找到的教程都使用 Excel 或其他工具,这些工具将实际算法黑盒化了。
是的,线性回归可以有多个输入。
我错过了这里的导数吗?
我没有涵盖推导。
我读了这篇文章,但对于梯度下降和随机梯度下降在此特定示例中的区别不是非常清楚。您已经展示了在随机梯度下降中,我们一次取一个样本并更新系数。但在梯度下降的情况下会发生什么?
也许这篇帖子会让你更清楚
https://machinelearning.org.cn/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
您好,我是 Maruthi,请告诉我步骤。作为一个新手,我只理解了 50%。
为什么您选择不平方损失函数中的距离之和?在我的课上,我们做了与您概述的几乎相同的事情,除了那一部分,以使函数可微。
对于 b0=0.01, b1=0.01 的值,对应的 x 和 y 值是 1。当我们把它们代入线性方程时,我们得到 y_predict=0.01+0.01*1,我没有得到第一个值 0.95。我做错了什么吗?
请告诉我
该预测是在模型使用系数 B0=0.230897491 和 B1=0.7904386102 学习之后进行的。
你好 Jason,
我应该如何为我的模型确定学习率,有什么建议吗?
反复试验,在对数尺度上测试一系列值,例如 [0.1, 0.01, 0.001, …]
当我将 B0 和 B1 值应用于线性回归时,我得到的预测值不同。你能帮我解决这个疑问吗?
也许你的系数与教程不同?
Jason,
感谢您的帖子。它非常具有启发性。
我想知道如何在您的示例中实现带 mini-batch 的梯度下降。在更新 B1 时,B1(t+1) = B1(t) – alpha * error * x 中的 x 的值是什么?
仍在 mini-batch 示例中,B0 和 B1 方程中的误差会等于平方误差之和的平方根吗?
非常感谢。
使用 batch 时,值会针对 batch/mini-batch 中的所有示例进行平均。
什么是成本函数?
它是我们用来估算模型误差并寻求在训练过程中最小化的函数。
嗨,Jason,
当我们在线性回归中使用梯度下降时,为什么不能在 sklearn 模块中使用 alpha 学习率作为参数?它是必需的,还是背后有其他理论?
因为 sklearn 不使用梯度下降,它使用线性代数,就像这篇帖子一样。
https://machinelearning.org.cn/solve-linear-regression-using-linear-algebra/
预测值是从哪里来的?你能分解一下这个步骤:“将值代入简单线性回归模型并为训练数据集中的每个点进行预测。”
谢谢你
将输入乘以系数并求和以得到预测。
非常非常棒的文章。Jason,您的文章非常详细。非常感谢。
谢谢,很高兴对您有帮助。
谢谢 Jason,您的教程非常有帮助
我想问您以下问题
我尝试将梯度下降用于逻辑回归,并使用了这段代码来计算准确率
def accuracy(self, x, actual_classes, probab_threshold=0.5)
predicted_classes = (self.predict(x) >= probab_threshold).astype(int)
predicted_classes = predicted_classes.flatten()
accuracy = np.mean(predicted_classes == actual_classes)
return accuracy * 100
我想获得用于获得此结果的混淆矩阵,因为 sklearn 的混淆矩阵给出的准确率值不同。
是的,sklearn 不使用梯度下降,它使用不同的优化算法,因此会给出不同的结果。
感谢您的快速回复
那么在这种情况下,如果我们想计算精确率和召回率,该如何做呢?
是否有不同的方法?因为我需要将算法结果与其他机器学习分类器的结果进行比较。
您必须计算误差,例如 MAE 或 MSE 或 RMSE。
好的,非常感谢
不客气。
使用梯度下降进行线性回归有哪些缺点?
与最小二乘法解决方案相比,它速度慢且效率低下。
你好,我想知道如果我们除了 b0 和 b1 还有其他系数,比如 b2、b3 等,我们如何通过梯度下降找到它们的值?
它会是
B2(t+1) = B2(t) – alpha * error * x2
B3(t+1) = B3(t) – alpha * error * x3
等等?
谢谢你
我在这里给出了一个例子
https://machinelearning.org.cn/implement-linear-regression-stochastic-gradient-descent-scratch-python/
嗨,Jason,
如果我们使用具有 9 到 10 个输入的线性回归算法,那么它是使用线性代数来计算参数值,还是使用梯度下降来计算参数?
谢谢。
使用线性代数,除非数据违反线性代数方法的期望或不适合内存。
嗨,Jason,
您是否有任何关于计算多元回归的标准误差和所有统计参数的全面教程?如果没有,请推荐一个好的资源。
恐怕没有,抱歉。
你好 Jason。我们如何计算 20 次迭代的系数?也就是说,从第二次迭代开始,我不明白 BO 和 B1 的值是如何得出的。
将该过程重复 20 次。
或者看这个例子
https://machinelearning.org.cn/implement-linear-regression-stochastic-gradient-descent-scratch-python/
谢谢你。
你好,先生,
感谢这篇清晰的文章。
我有一个疑问,请。
为什么我们使用公式
b0(1) = b0(0) * alpha * error
同样,为什么我们使用
b1(1) = b1(0) * alpha * error * x
为什么我们乘以 x,即 b1 的输入?
此实现基于《人工智能:一种现代方法》中的描述,我认为是这样。
您为什么想使用那个公式?
如何计算 m?
m 是什么?
很好,非常有帮助
谢谢。
要为简单线性回归实现梯度下降,以下哪个在初始设置中是不需要的?
1)。定义成本函数
2)。斜率和截距的更新规则
3)。斜率和截距的最佳学习率
4)。斜率和截距的初始猜测……
这看起来像是个面试题!
我认为是 3。
学习率越大收敛越快是真的吗????
或
梯度下降的小学习率总是最好的吗????
没有普遍的最佳学习率,我们必须看看什么最适合给定的目标函数/数据集。
很棒的分享,信息量很大,我一直在寻找。您完整的指导给了我一个精彩的结局。继续努力。
谢谢。
我如何将其实现到多元线性回归中?
也许这会有帮助。
https://machinelearning.org.cn/solve-linear-regression-using-linear-algebra/
你好,
我跟着您的方法进行应用,作为练习,我构建了一个代码来测试该方法。我注意到对于 X 值小的点,该方法效果很好,但当存在大量 X 值大的点时,该方法无法收敛,事实上我们遇到了梯度爆炸。
有没有办法解决这个问题?
谢谢
线性回归由于其线性度应该最容易执行。但事实上,您看到的场景并非不可能。一种方法是在将数据馈送到模型之前对其进行预处理。在您的情况下,您可能需要对 X 进行归一化以避免极大的范围。