
LLM评估指标轻松入门
作者 | Ideogram 提供图片
指标是评估任何人工智能系统的基石,对于大型语言模型 (LLM) 也不例外。本文通过 Python 代码示例,揭示了一些流行的 LLM 语言任务评估指标的内部工作原理,并展示了如何轻松利用 Hugging Face 库使用这些指标。
虽然本文侧重于从实践角度理解 LLM 指标,但我们建议您查看这篇补充阅读材料,其中从概念上探讨了 LLM 评估的要素、准则和最佳实践。
安装和导入必要库的先决条件代码
|
1 2 3 |
!pip install evaluate rouge_score transformers torch import evaluate import numpy as np |
内部评估指标
我们将探讨的评估指标总结在下面的可视化图表中,以及它们通常用于的某些语言任务。
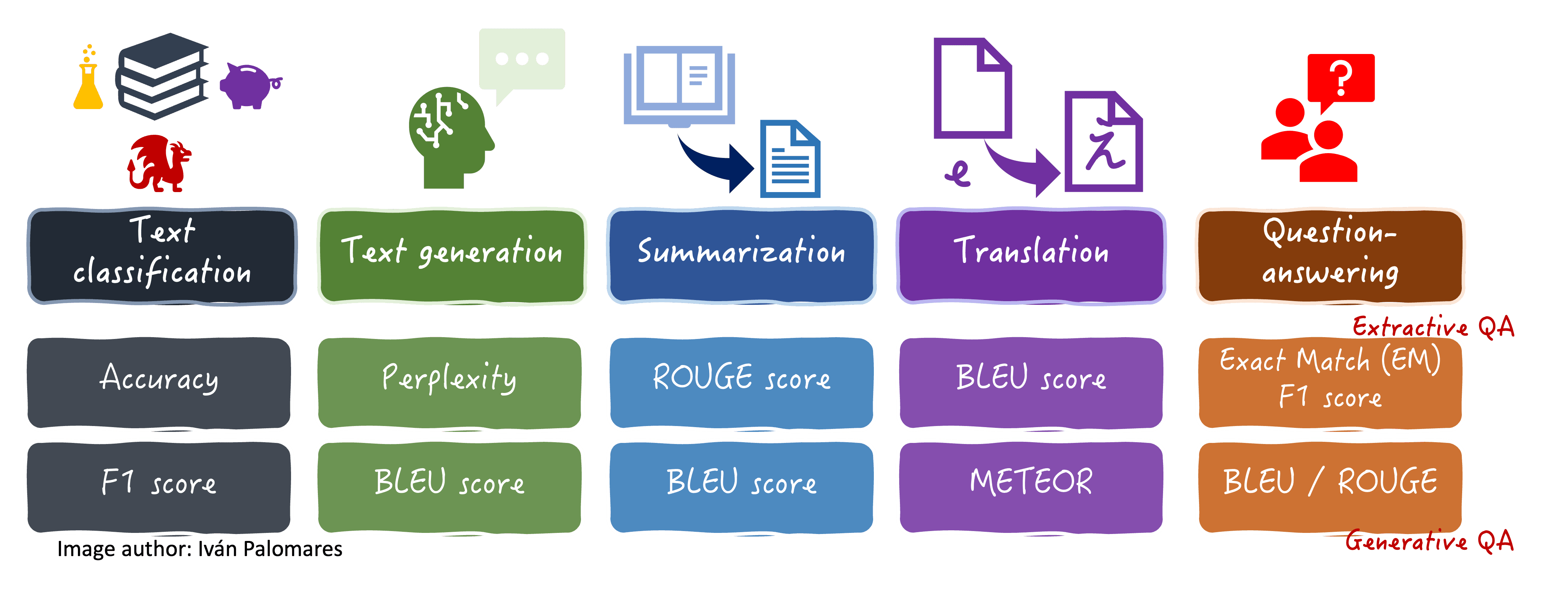
不同语言任务的评估指标
准确率和 F1 分数
准确率通过计算正确预测占总预测的百分比来衡量预测(通常是分类)的总体正确性。F1 分数提供了一种更细致的方法,特别适用于在不平衡数据集下评估分类预测,它结合了精确率和召回率。在 LLM 领域,它们既用于情感分析等文本分类任务,也用于从输入文本中提取答案或摘要等非生成任务。
假设您正在分析日本动漫评论的情感。虽然准确率会描述正确分类的总体百分比,但如果大多数评论普遍是积极的(或者相反,大多是消极的),F1 将特别有用,因为它能更好地捕捉模型在两个类别上的表现。它还有助于揭示预测中的任何偏差。
这个示例代码展示了这两个指标的实际应用,它使用 Hugging Face 库、预训练 LLM 和上述指标来评估多个文本是与日本茶道或茶の湯 (Cha no Yu) 相关还是不相关。目前,没有加载实际的 LLM,我们假设其分类输出已经在一个名为 pred_labels 的列表中。在 Python notebook 中试试看!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 关于日本茶道的样本数据集 references = [ "日本茶道是一种强调和谐与尊重的深厚文化习俗。", "抹茶在茶道中用传统方法精心准备。", "茶师在仪式中一丝不苟地遵循精确的步骤。" ] predictions = [ "日本茶道是一种强调和谐与尊重的文化习俗。", "抹茶在茶道中用传统方法准备。", "茶师在仪式中遵循精确的步骤。" ] # 准确率和 F1 分数 accuracy_metric = evaluate.load("accuracy") f1_metric = evaluate.load("f1") # 模拟二元分类(例如,茶道与非茶道) labels = [1, 1, 1] # 都与茶道有关 pred_labels = [1, 1, 1] # 模型预测全部正确 accuracy = accuracy_metric.compute(predictions=pred_labels, references=labels) f1 = f1_metric.compute(predictions=pred_labels, references=labels, average='weighted') print("准确率:", accuracy) print("F1 分数:", f1) |
随意修改上面 labels 和 pred_labels 列表中的二元值,看看这如何影响指标计算。下面的代码片段将使用相同的示例文本数据。
困惑度
困惑度通过查看每个生成词作为序列中下一个词的被选中概率,来衡量 LLM 预测样本生成文本的程度。换句话说,这个指标量化了模型的确定性。困惑度越低表示性能越好,即模型在预测序列中下一个词方面做得越好。例如,在关于准备抹茶茶的句子中,低困惑度意味着模型可以以最小的“惊讶”程度持续预测适当的后续词,例如“绿色”后跟“茶”,再后跟“粉末”等等。
以下是演示如何使用困惑度的后续代码
|
1 2 3 4 5 6 7 |
# 困惑度(使用小型 GPT2 语言模型) perplexity_metric = evaluate.load("perplexity", module_type="metric") perplexity = perplexity_metric.compute( predictions=predictions, model_id='gpt2' # 使用小型预训练模型 ) print("困惑度:", perplexity) |
ROUGE、BLEU 和 METEOR
BLEU、ROUGE 和 METEOR 特别用于翻译和摘要任务,这些任务同样需要语言理解和语言生成能力:它们评估生成文本与参考文本(例如由人工注释者提供)之间的相似性。BLEU 通过计算匹配的 n-gram 来关注精确度,主要用于评估翻译,而 ROUGE 通过检查重叠的语言单元来衡量召回率,常用于评估摘要。METEOR 通过考虑同义词、词干等附加方面来增加复杂性。
对于翻译关于樱花的俳句(日本诗歌)或总结《西游记》等大型中国小说,这些指标将有助于量化 LLM 生成的文本在多大程度上捕捉了原作的含义、词语选择和语言细微差别。
示例代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# ROUGE 分数(未加载 LLM,使用预定义文本列表作为 LLM 输出(预测)和参考) rouge_metric = evaluate.load('rouge') rouge_results = rouge_metric.compute( predictions=predictions, references=references ) print("ROUGE 分数:", rouge_results) # BLEU 分数(未加载 LLM,使用预定义文本列表作为 LLM 输出(预测)和参考) bleu_metric = evaluate.load("bleu") bleu_results = bleu_metric.compute( predictions=predictions, references=references ) print("BLEU 分数:", bleu_results) # METEOR (要求参考资料为列表的列表) meteor_metric = evaluate.load("meteor") meteor_results = meteor_metric.compute( predictions=predictions, references=[[ref] for ref in references] ) print("METEOR 分数:", meteor_results) |
精确匹配
一个非常直接但效果显著的指标,精确匹配(EM)用于抽取式问答用例,以检查模型生成的答案是否与“金标准”参考答案完全匹配。它通常与 F1 分数结合使用来评估这些任务。
在关于东亚历史的问答情境中,只有当 LLM 的整个回答与参考答案精确匹配时,EM 分数才计为 1(匹配),否则为 0。例如,如果问“德川幕府的第一位将军是谁?”,只有与“德川家康”逐字匹配的答案才能得到 EM 为 1,否则为 0。
代码(同样,通过假设 LLM 输出已收集到列表中进行简化)
|
1 2 3 4 5 6 |
# 6. 精确匹配 def exact_match_compute(predictions, references): return sum(pred.strip() == ref.strip() for pred, ref in zip(predictions, references)) / len(predictions) em_score = exact_match_compute(predictions, references) print("精确匹配分数:", em_score) |
总结
本文旨在简化对通常用于评估 LLM 在各种语言用例中性能的评估指标的实际理解。通过结合以示例为主的解释和通过 Hugging Face 库使用这些指标的说明性代码示例,我们希望您对这些在其他人工智能和机器学习模型评估中不常见的有趣指标有了更好的理解。






暂无评论。