在开始建模之前,您必须能够加载数据。
在本帖中,您将了解如何在Weka中加载CSV数据集。阅读本帖后,您将了解:
- ARFF文件格式及其作为Weka默认数据表示方式。
- 如何在Weka Explorer中加载CSV文件并以ARFF格式保存。
- 如何在ArffViewer工具中加载CSV文件并以ARFF格式保存。
本教程假定您已安装Weka。
通过我的新书《Weka机器学习精通》启动您的项目,书中包含分步教程和针对所有示例的清晰屏幕截图。
让我们开始吧。

如何在 Weka 中加载 CSV 机器学习数据
照片作者:Thales,保留部分权利。
如何在Weka中讨论数据
机器学习算法主要设计用于处理数字数组。
这被称为表格数据或结构化数据,因为它在电子表格中的外观,由行和列组成。
Weka在描述数据时有特定的计算机科学术语。
- 实例(Instance):一行数据称为一个实例,就像来自问题域的实例或观测值。
- 属性(Attribute):一列数据称为一个特征或属性,就像观测值的特征。
每个属性可以有不同的类型,例如:
- Real(实数):用于数值,如1.2。
- Integer(整数):用于不带小数部分的数值,如5。
- Nominal(标称):用于分类数据,如“狗”和“猫”。
- String(字符串):用于单词列表,如这个句子。
在分类问题中,输出变量必须是标称的。对于回归问题,输出变量必须是实数。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
Weka中的数据
Weka更倾向于加载ARFF格式的数据。
ARFF是Attribute-Relation File Format(属性-关系文件格式)的缩写。它是CSV文件格式的扩展,使用一个包含列中数据类型元信息的头部。
例如,经典的鸢尾花数据集在CSV格式下的前几行如下:
|
1 2 3 4 5 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa |
相同文件在ARFF格式下的前几行如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RELATION iris @ATTRIBUTE sepallength REAL @ATTRIBUTE sepalwidth REAL @ATTRIBUTE petallength REAL @ATTRIBUTE petalwidth REAL @ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica} @DATA 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa |
您可以看到,指令以“@”符号开头,有一条用于数据集名称(例如@RELATION iris),有一条指令用于定义每个属性的名称和数据类型(例如@ATTRIBUTE sepallength REAL),还有一条指令用于指示原始数据开始(例如@DATA)。
ARFF文件中以百分号(%)开头的行表示注释。
原始数据部分中带有问号(?)的值表示未知或缺失值。该格式支持数值和标称值(如上面的鸢尾花示例),也支持日期和字符串值。
根据您的Weka安装情况,您可能在Weka安装目录下的data/子目录中拥有一些默认数据集。这些随Weka分发的默认数据集是ARFF格式,文件扩展名为.arff。
在ARFF-Viewer中加载CSV文件
您的数据不太可能是ARFF格式。
事实上,它更可能是逗号分隔值(CSV)格式。这是一种简单的格式,数据以行和列的表格形式排列,使用逗号分隔一行中的值。引号也可能用于包围值,特别是当数据包含带有空格的文本字符串时。
CSV格式可以轻松地从Microsoft Excel导出,因此一旦您能将数据导入Excel,您就可以轻松地将其转换为CSV格式。
Weka提供了一个方便的工具来加载CSV文件并将其保存为ARFF。您只需要对数据集执行此操作一次。
使用以下步骤,您可以将数据集从CSV格式转换为ARFF格式,并在Weka工作台中进行使用。如果您手头没有CSV文件,可以使用鸢尾花数据集。从UCI机器学习存储库(直接链接)下载该文件,并将其保存到当前工作目录中,命名为iris.csv。
1. 启动Wekachooser。

Weka GUI Chooser的截图
2. 通过点击菜单中的“Tools”并选择“ArffViewer”来打开ARFF-Viewer。
3. 您将看到一个空的ARFF-Viewer窗口。
Weka ARFF Viewer
4. 在ARFF-Viewer中打开您的CSV文件,点击“File”菜单并选择“Open”。导航到您的当前工作目录。将“Files of Type:”过滤器更改为“CSV data files (*.csv)”。选择您的文件,然后点击“Open”按钮。
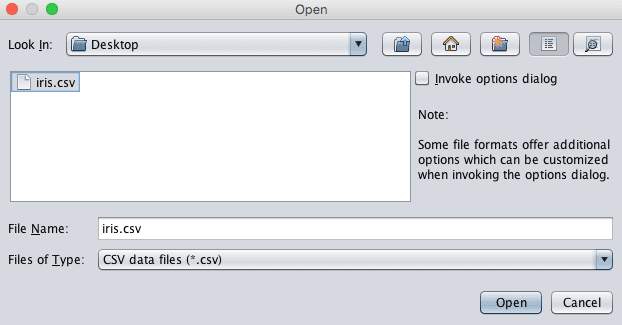
在ARFF Viewer中加载CSV
5. 您应该会在ARFF-Viewer中看到加载的CSV文件样本。
6. 通过点击“File”菜单并选择“Save as…”来以ARFF格式保存您的数据集。输入一个带有.arff扩展名的文件名,然后点击“Save”按钮。
您现在可以将保存的.arff文件直接加载到Weka中。
请注意,ARFF-Viewer提供了在保存之前修改数据集的选项。例如,您可以更改值、属性名称及其数据类型。
强烈建议您指定每个属性的名称,这将有助于您后续的数据分析。同时,请确保每个属性的数据类型都是正确的。
在Weka Explorer中加载CSV文件
您也可以直接在Weka Explorer界面中加载CSV文件。
如果您时间紧迫并想快速测试一个想法,这会很方便。
本节将向您展示如何在Weka Explorer界面中加载CSV文件。如果您没有CSV数据集可以加载,可以再次使用鸢尾花数据集进行练习。
1. 启动Weka GUI Chooser。
2. 点击“Explorer”按钮启动Weka Explorer。
Weka Explorer的截图
3. 点击“Open file…”按钮。
4. 导航到您的当前工作目录。将“Files of Type”更改为“CSV data files (*.csv)”。选择您的文件,然后点击“Open”按钮。
您可以直接处理数据。您也可以通过点击“Save”按钮并输入文件名来以ARFF格式保存您的数据集。
使用Excel处理其他文件格式
如果您有其他格式的数据,请先将其加载到Microsoft Excel中。
通常会以其他格式(如使用不同分隔符的CSV或固定宽度字段)获取数据。Excel具有加载各种格式的表格数据的强大工具。使用这些工具,并先将数据加载到Excel中。
将数据加载到Excel后,您可以将其导出为CSV格式。然后,您可以直接在Weka中使用它,或者先将其转换为ARFF格式。
资源
以下是一些在Weka中使用CSV数据时可能对您有用的附加资源。
总结
在本帖中,您了解了如何在Weka中加载CSV数据以进行机器学习。
具体来说,你学到了:
- ARFF文件格式以及Weka如何使用它来表示机器学习数据集。
- 如何使用ARFF-Viewer加载CSV数据并将其保存为ARFF格式。
- 如何直接在Weka Explorer中加载CSV数据并用于建模。
您对在Weka中加载数据或本帖有任何疑问吗?请在评论中提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






很棒的帖子
完全同意,这篇帖子非常有帮助。谢谢,非常感激。
谢谢!
感谢这篇有用的帖子。请问,我在WEKA中查看.CSV文件时遇到了java.io.IOException。我需要您的帮助。
很抱歉听到这个消息,Ayo。
也许您的文件太大了?
也许先在Excel中加载它,然后检查文件是否损坏?
嗨,Jason,
感谢您的辛勤工作。
Weka工作台可以将CSV文件转换成ARFF格式的大小限制是多少?
我有一个2GB以上的CSV文件,但Weka Arff Viewer或Explorer都无法加载以进行转换。
好问题,我不知道Sunkanmi。我猜可能是Java的内存限制(可以增加)以及您硬件的内存限制。
有关为Weka分配更多RAM的详细信息
https://weka.wikispaces.com/OutOfMemoryException
我收到一条错误消息:“java.io.IOE.exception 12 Problem encountered on line:2”
无论我尝试使用Tools加载还是直接使用Explorer加载,都是同样的错误。
抱歉听到这个消息,Rodney。我以前没见过这个。也许可以尝试发布到Stack Overflow或Weka邮件列表?
谢谢!
不客气,Farah。
我有一个包含产品数量、单价、关税、型号、规格、品牌名称的数据集。我最初使用了朴素贝叶斯,后来使用了Auto-Weka来确定我的理想算法是随机森林,并且在测试训练数据集时,它能以100%的准确率运行良好。
但是,当我复制相同的数据文件并删除品牌名称以用作测试数据集时,所有问题都出现了。我要么收到inputmappedclassifier选项,要么收到错误,如“problem evaluating classifier-index4-size1”或“different nos of lables 15!=1”。
也就是说,我将品牌名称列放在了测试和训练数据集的末尾。我进行了一些在线搜索,并在测试数据集的品牌列上使用了问号。我将它们转换成了arff格式,并交叉检查了两个文件中的属性数据类型,但似乎都没有帮助。我哪里做错了?我知道我离成功很近了。有人能帮忙吗?
应该是100%的准确率,而不是10%。
当我将数据加载到weka时,它显示无效的流。
你好,santanu,
这篇帖子可能有助于在新数据上进行预测。
https://machinelearning.org.cn/save-machine-learning-model-make-predictions-weka/
Jason,我如何使用质谱数据创建ARFF文件?每个实例(质谱)将包含数百个属性,每个属性都是光谱中每个峰信号的质量和强度值的对。通常,我会有这些质谱的重复样本,代表一种疾病状态,另一些代表正常状态/类别。其他数据类型的所有示例都显示每个属性的单个结果,而不是我描述的质量/强度对。一些质谱数据转换为Weka的示例将非常有帮助。
好问题,Tom。
也许这篇帖子能帮助您定义模型的输入和输出。
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
亲爱的 Jason,
我加载.csv文件到weka时遇到了两个问题:
1- 文件加载正确,但由于封闭字符,句子没有完全加载。
2- 尝试应用stringTowordvector过滤器时出现此错误(属性名称不唯一!原因:“class”)。
你好,Asmaa,抱歉,我没有加载文本数据的好的Weka示例。
一个属性有多个值,我该如何写入?
很好的问题!
考虑将其设为二进制属性。为每个值设置一列,然后在给定观测值的每列上标记1或0。
希望这能有所帮助。
嗨,Jason,
好帖子!只是好奇,能否实时设置?也就是说,如果我有一个通过CSV文件实时收集数据的过程,然后需要将其转换为arff。这可以做到吗?
然后,一旦完成,是否可以向arff对象添加和删除值?
谢谢!
我建议使用Weka的命令行界面来实现这一点。
抱歉,我没有示例,但可以查看Weka随附的Weka系统/用户指南。
我如何引入3个独立的实数属性类别?
即:不是一个包含3个值的类别,而是3个独立的实数属性类别。
我相信Weka不支持输出向量预测(例如3个类别)。
你好,杰森,
我已经按照本页的步骤成功地将我的CSV文件转换为arff。但是,现在当我将数据集加载到Weka中时,我无法使用j48树。我该如何构建一棵树并开始分析我的数据?谢谢!
祝好,
Nick
也许您需要将输出变量设为标称值,以便可以使用分类算法?
第一行的值被用作属性名,因此丢失了第一行的值。我们如何保留这些值并为它们指定明确的属性名称?
好问题。我暂时不确定,抱歉。
一种方法是在文件中指定列名。或者在文件开头添加一行虚拟数据。
我尝试在weka中打开我的csv数据,但它不起作用,错误是[[ file’data.csv’ not recognised as an csv data files file reaon : 1 problem encountered on line 2
请仔细检查您的文件是否为CSV文件。在文本编辑器或MS Excel中打开以确认。
尊敬的Brownlee先生,
我将在KDDcup99数据集上使用weka进行IDS(入侵检测系统)目的。
我需要在此数据集上使用SVM和Entropy,并根据此结果,我将从数据集中删除一些属性,并创建一个决策树以更快地检测入侵。
请告知我是否可以使用WEKA GUI?或者我应该使用Java中的weka库?
抱歉,我很多年没用过那个数据集了。我最好的建议是尝试一下。
你好Jason博士,
请问,我在kosarak数据集上遇到了问题,无法在weka中运行它。
抱歉,我对那个数据集不了解。也许把你的错误发布到Stack Overflow?
我可以在Weka中打开.mat文件吗?
我不知道,抱歉。
我正在MacBook上尝试在weka中运行.csv文件,但出现错误,显示:
invalid stream header:49642c53
请在文本编辑器中仔细检查您的数据文件,并确保格式符合您的预期。
非常棒的帖子!
谢谢。
嗨,Jason,
有没有办法在我的测试数据CSV文件中添加一个列,说明这是哪个数据样本,然后将相应的预测分数与单个样本关联起来?
感谢这篇精彩的帖子!
FS
也许在CSV中添加,然后使用过滤器来分离并保存单独的数据集。
您好。
我收到错误“java.lang.illegalArgumentException: Attribute names are not unique! Causes: ‘vhigh’ ‘2’”。请帮忙。
我尝试将.csv文件上传到weka explorer,但收到此异常,文件未加载。
请在文本编辑器或Excel中仔细检查您的数据?
嗨 Jason
加载.csv文件并将其另存为.arff文件并在WEKA中打开后,我的直方图都是黑白的。我尝试了很多方法,但都没有奏效。问题可能出在哪里?
感谢阅读。
Marie
Weka认为您的输出是实数值。也许请仔细检查您的文件?
是否有帖子解释如何正确编写标题才能在weka中查看文件?我尝试了很多次来创建标题,检查它,并使用文本编辑器纠正多余的逗号错误,但它根本无法在arff viewer中打开。无论我做什么,我都会收到一个错误,文件甚至无法打开。它看起来和我用文本编辑器从weka中打开的arff文件完全一样,但weka根本无法读取我的csv。
打开一个现有的.arff文件并为您的数据进行调整。
或者使用Weka提供的ARFF编辑器。
非常感谢您的指导。
我的问题发生在将csv文件转换为arff文件之后,我注意到添加了一个新的索引列作为属性,尽管arff提供了索引列。所以如果我的csv文件有5个属性,它在arff文件中变成了6个。
我不知道如何解决这个问题。
也许请检查您的CSV文件没有额外的列。可以在Excel或文本编辑器中查看?
每月平均日照小时数
月份/年份 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016
一月 5.3 4.4 7.5 4.5 2 5.2 5.4 5.4 5.5 6.4 5.2 4.6
二月 6.7 4.7 7.4 6 2.2 5.2 5.9 4.9 4.1 4.6 5.3 2.2
三月 5.5 2.9 5.8 4.7 8.0 3.3 6.1 5.4 5.7 5.6 4.4 4.3
四月 5.4 4.8 5.2 5 3.6 5.8 5.1 5.7 5.6 5.8 4.7 5.7
五月 4.8 3.7 6.1 6 5 5.3 5.6 5.1 5.9 5.8 5.2 5.1
六月 4.7 4.6 5.6 5 4.2 3.8 3.3 3.8 4.3 4.5 3 4.3
七月 2.2 2.3 4.4 3.1 2.9 2.9 2.4 1.7 2.7 2.5 2.1 4.2
八月 1.5 1.4 2.7 2.3 2.2 2.4 1.6 2.6 2.1 1.5 1.6 2.8
九月 3.8 2 3.9 3.1 3.4 3.6 2.5 3.6 2.8 1.8 2.5 2.2
十月 4.1 3.5 5.9 5.6 3.8 5.5 4.4 4.7 4.7 3.7 5.2 4.9
十一月 6.7 5.7 7.5 7.6 6.8 6 7 6.3 6.1 5.9 6.8 5.5
十二月 6.3 5.8 7.4 6.1 7.5 7.1 7.3 7.6 6.5 6.2 8.8 4.4
总计 57 45.8 70.4 59 44.4 56.1 56.6 56.8 56 54.3 54.8 50.2
平均 4.8 3.8 5.9 5 3.7 4.7 4.7 4.7 4.6 4.5 4.6 4.2
以上是天气数据的样本,一个Word文档。在将数据加载到WEKA之前,我需要进行任何修改吗?
这 realmente 取决于您项目的目标。
这个可能会有帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
谢谢 Jason 的这篇精彩文章。我更感兴趣的是如何使用 ARFF-Viewer 的选项在保存之前修改数据集。特别是更改数据类型。我尝试过界面上的这些选项,但没有得到任何线索。请帮助我。
抱歉,我没有关于在 ARFF 查看器中更改数据类型的示例。
Jason,谢谢,这篇文章很有帮助。
很高兴听到这个消息。
Jason,我在尝试利用 WEKA 进行我的论文研究时偶然发现了这篇帖子。仅仅几分钟,我就相信您提供给大家的资源(machinelearningmastery.com)将是我以及未来许多人成功的关键!仅仅学习如何将 .csv 转换为 .arff 已经为我打开了无数扇门。我现在有了研究的初步方法。太感谢您了!
干得好,Mark!很高兴听到你的进展!坚持下去。
很棒的文章
我需要为一个项目学习数据挖掘(带代码),有什么建议吗?链接?
谢谢
这个网站有很多带代码的教程,快去看看吧!
Jason,你能帮帮我吗。我无法在 Weka 中加载 .CSV 文件。当我在工具中时,我会收到消息:“java io.IOException 值数量错误。读取 11,期望 10。读取的 Token (EOL) 行 13。问题出现在第 13 行。”
我的文件是 CSV 格式。
请帮帮我!
也许您应该在文本编辑器中检查您的文件,并确认它是 CSV 格式,并且文件看起来是有效的。
Jason – 如何将 .txt 文件加载到 weka 中。我需要对电影评论进行分类,然后找出电影是好是坏。我有一堆 .txt 文件,分别是正面评论和负面评论文件。
请指导我如何将它们加载到 weka 中并执行分类。
抱歉,我没有在 Weka 中处理 .txt 文件的示例,无法给您好的建议。
嘿 Jason,这真是一篇很棒的文章!!它非常有帮助,尤其是对初学者来说。谢谢。
谢谢,很高兴对您有帮助。
嗨 Jason
请在这里帮助我,
我正在尝试将 csv 文件转换为 arff,但出现了这个错误:无法确定结构为 arff(原因:java io.ioexception:关键字 @data 预期,实际 token @attribute id numeric 行 3。我正在使用 wdbc 乳腺癌数据集进行研究。
听到这个消息我很遗憾,也许您可以在文本编辑器中检查文件,看看可能是什么问题?
我有一个来自 Kaggle 的数据集,即 train.csv 和 test.csv 文件。我如何一起处理这两个文件?
我阅读了一些教程,其中加载一个 CSV 文件,然后将其拆分为训练和测试文件。
通常 Kaggle 的测试集没有标签。
我建议您专注于如何仅加载训练集。
嗨,Jason,
我有一个 csv 文件,当我想用 weka 将它转换为 arff 时,我会遇到这个错误:
java.io.IOException: 42 问题出现在第 2 行:
也许文件太大,无法加载到内存中?
我的葡萄糖值类型是 >4 和 <4,但我想要实际的(数值)。
我该如何输入到 weka 中?
也许您需要收集这些数据?
一旦收集到数据,您就可以将数据文件加载为 CSV 并转换为 ARFF。
我有一个在 weka 中导入 csv 文件的条件。
‘weka.core.converters.CSVLoader 无法加载 News.csv’
原因:第 509 行出现 2 个问题’
我该如何修复它?谢谢。
也许您应该在文本编辑器中打开您的文件,看看第 509 行有什么不寻常的地方?
亲爱的 Jason,
我有一个 CSV 文件,当我尝试将其转换为 ARFF 时,会收到此错误:
java.io.IOexception:1 问题出现在第 2 行:
听到这个消息我很遗憾。也许您应该尝试将文件发布到 weka 用户组?
谢谢你
不客气。
感谢您写了这篇很棒的文章。它给了我很大的帮助。
谢谢,很高兴听到这个!
我有一个电子表格,我将其保存为 CSV。它有 48 个属性和 58 个实例。属性格式为两位小数的数字。当我加载它时,属性都显示为 1,并给出计数而不是实际数字。我该如何解决这个问题?
也许您应该确认使用“.”作为小数点,使用“,”来分隔列。
我有许多文件想要加载到 WEKA 中。我该如何做?
也许您应该先将它们合并到一个文件中?
嗨,Jason,
请原谅我这个显而易见的问题——对于回归项目,arff 文件中的实例顺序是怎样的?最新的数据是在文件的头部还是尾部?
非常感谢,
对于回归,我们假设所有实例(行)都是独立同分布的。实例创建的顺序无关紧要。
如果顺序很重要,那么您就遇到了时间序列问题,您应该尝试使实例随时间保持平稳——移除或建模时间效应。
你好,
我已经下载并安装了 weka workbench 用于 OLM 测试。我有一个社会工作者数据集(来自 Ben Davis 92 年的论文)。它是一个 CSV 格式文件,如下所示:
In1,“In2”,“In3”,“In4”,“In5”,“In6”,“In7”,“In8”,“In9”,“In10”,“Out1”
2,1,1,2,1,1,2,2,1,1,2
1,2,3,3,2,1,3,1,3,3,5
3,3,2,1,2,2,3,3,3,3,5
2,3,4,2,4,2,2,2,1,2,5
1,2,1,2,2,2,2,1,1,2,3
我正在尝试将其转换为 ARFF 格式,如下所示:
@attribute In1 numeric
@attribute In2 numeric
@attribute In3 numeric
@attribute In4 numeric
@attribute In5 numeric
@attribute In6 numeric
@attribute In7 numeric
@attribute In8 numeric
@attribute In9 numeric
@attribute In10 numeric
@attribute Out1 numeric
@data
1,2,3,3,2,1,3,1,3,3,5
1,2,1,2,2,2,2,1,1,2,3
1,3,3,1,4,2,1,1,2,3,4
1,2,2,3,3,2,2,1,1,2,4
1,3,3,1,4,2,1,1,2,3,3
1,3,3,1,4,2,1,1,2,3,4
1,3,1,3,2,1,1,1,3,2,5
在预处理步骤中一切似乎都运行正常,但当我进入分类步骤,并选择 OLM 算法及其所有属性时,我无法激活“开始”按钮。
可能是数据集文件(但一切在读取它的第一步看起来都正常)。
您知道是什么原因造成的吗?
提前感谢,并祝贺您的博客。它对我帮助很大!
此致,
Francisco
看起来您的数据是用于回归的,请确保您选择的是回归算法。
嗨 Jason
我正遇到这种错误:
索引 9 超出长度 9 的界限,问题出现在第 2 行:
我该怎么办?
抱歉,我不确定您错误的原因,也许这些步骤会有帮助:
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
嗨,你解决这个问题了吗?
我认为我现在可以将数据集加载到 weka 了。非常感谢您的时间和理解。
干得好!
嗨。当我重新打开一个已经修改过数据的 csv 文件时,我看到的是文件中已不再存在的老数据。您知道如何修复此错误吗?谢谢。
如果您之前关闭了文件(这会触发缓存刷新),那么就不应该这样了。