Python 中的 Pandas 库 为时间序列数据提供了出色的内置支持。
一旦加载,Pandas 还提供工具来探索和更好地理解您的数据集。
在这篇文章中,您将学习如何加载和探索您的时间序列数据集。
完成本教程后,您将了解:
- 如何使用 Pandas 从 CSV 文件加载时间序列数据集。
- 如何查看加载的数据并计算摘要统计信息。
- 如何绘制和查看您的时间序列数据。
用我的新书《Python 时间序列预测入门》来启动您的项目,包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019 年 8 月更新:数据加载已更新为使用新 API。
每日女性出生数据集
在这篇文章中,我们将使用每日女性出生数据集作为示例。
这个单变量时间序列数据集描述了 1959 年加利福尼亚州每日女性出生人数。
单位是计数,共有 365 个观测值。数据集的来源归功于 Newton (1988)。
以下是数据的前 5 行样本,包括标题行。
|
1 2 3 4 5 6 |
“日期”,“1959 年加利福尼亚州每日女性出生总数” "1959-01-01",35 "1959-01-02",32 "1959-01-03",30 "1959-01-04",31 "1959-01-05",44 |
以下是整个数据集的图。
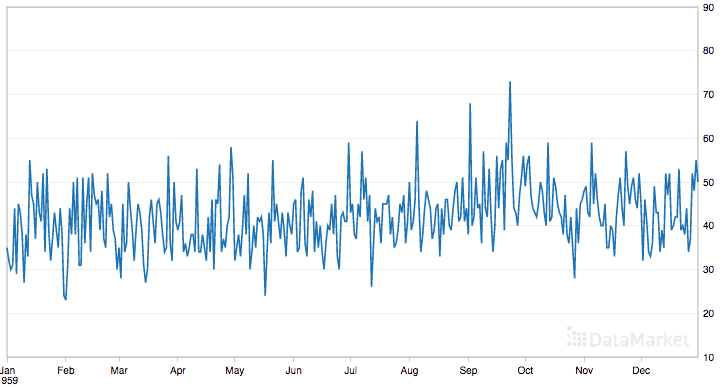
每日女性出生数据集
下载数据集并将其放置在您的当前工作目录中,文件名为“daily-total-female-births-in-cal.csv”。
加载时间序列数据
Pandas 将时间序列数据集表示为 Series。
一个 Series 是一个一维数组,每行都有一个时间标签。
该 Series 有一个名称,即数据列的列名。
您可以看到每行都有一个关联的日期。这实际上不是一个列,而是一个值的时间索引。作为索引,一个时间可以有多个值,并且值在时间上可以均匀或不均匀地分布。
Pandas 中用于加载 CSV 数据的主要函数是 read_csv() 函数。我们可以用它将时间序列加载为 Series 对象,而不是 DataFrame,如下所示:
|
1 2 3 4 5 |
# 使用 read_csv 加载出生数据 from pandas import read_csv series = read_csv('daily-total-female-births-in-cal.csv', header=0, parse_dates=[0], index_col=0, squeeze=True) print(type(series)) print(series.head()) |
请注意 read_csv() 函数的参数。
我们提供了许多提示以确保数据作为 Series 加载。
- header=0:我们必须在第 0 行指定标题信息。
- parse_dates=[0]:我们提示函数第一列中的数据包含需要解析的日期。此参数接受一个列表,因此我们为其提供一个包含一个元素(即第一列的索引)的列表。
- index_col=0:我们提示第一列包含时间序列的索引信息。
- squeeze=True:我们提示我们只有一个数据列,并且我们对 Series 而不是 DataFrame 感兴趣。
您自己的数据可能需要使用的另一个参数是 date_parser,用于指定解析日期时间值的函数。在此示例中,日期格式已推断,并且在大多数情况下有效。在少数不起作用的情况下,请指定您自己的日期解析函数并使用 date_parser 参数。
运行上面的示例会打印相同的输出,但也确认时间序列确实作为 Series 对象加载。
|
1 2 3 4 5 6 7 8 |
<class 'pandas.core.series.Series'> 日期 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 名称:1959 年加利福尼亚州每日女性出生总数,dtype:int64 |
在 DataFrame 中执行时间序列数据操作通常比在 Series 对象中更容易。
在这种情况下,您可以轻松地将加载的 Series 转换为 DataFrame,如下所示:
|
1 |
dataframe = DataFrame(series) |
进一步阅读
- 更多关于 pandas.read_csv() 函数的信息。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
探索时间序列数据
Pandas 还提供了探索和汇总时间序列数据的工具。
在本节中,我们将介绍一些常见的操作,以探索和汇总您加载的时间序列数据。
查看数据
最好查看加载的数据,以确认类型、日期和数据是否按预期加载。
您可以使用 head() 函数查看前 5 条记录,或指定要查看的前 n 条记录。
例如,您可以按如下方式打印前 10 行数据。
|
1 2 3 |
from pandas import read_csv series = read_csv('daily-total-female-births-in-cal.csv', header=0, index_col=0) print(series.head(10)) |
运行示例会打印以下内容
|
1 2 3 4 5 6 7 8 9 10 11 |
日期 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 1959-01-06 29 1959-01-07 45 1959-01-08 43 1959-01-09 38 1959-01-10 27 |
您还可以使用 tail() 函数获取数据集的最后 n 条记录。
观察值数量
对数据执行的另一个快速检查是已加载观察值的数量。
这有助于发现列标题未按预期处理的问题,并了解如何有效地划分数据以供以后与监督学习算法一起使用。
您可以使用 size 参数获取 Series 的维度。
|
1 2 3 |
from pandas import read_csv series = read_csv('daily-total-female-births-in-cal.csv', header=0, index_col=0) print(series.size) |
运行此示例,我们可以看到,正如我们所期望的,有 365 个观测值,即 1959 年一年中的每一天都有一个观测值。
|
1 |
365 |
按时间查询
您可以使用时间索引对 Series 进行切片、分块和查询。
例如,您可以按如下方式访问一月份的所有观测值
|
1 2 3 |
from pandas import read_csv series = read_csv('daily-total-female-births-in-cal.csv', header=0, parse_dates=[0], index_col=0, squeeze=True) print(series['1959-01']) |
运行此命令会显示 1959 年 1 月份的 31 个观测值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
日期 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 1959-01-06 29 1959-01-07 45 1959-01-08 43 1959-01-09 38 1959-01-10 27 1959-01-11 38 1959-01-12 33 1959-01-13 55 1959-01-14 47 1959-01-15 45 1959-01-16 37 1959-01-17 50 1959-01-18 43 1959-01-19 41 1959-01-20 52 1959-01-21 34 1959-01-22 53 1959-01-23 39 1959-01-24 32 1959-01-25 37 1959-01-26 43 1959-01-27 39 1959-01-28 35 1959-01-29 44 1959-01-30 38 1959-01-31 24 |
这种基于索引的查询有助于在探索数据集时准备摘要统计信息和图表。
描述性统计学
计算时间序列的描述性统计量可以帮助了解值的分布和传播。
这可能有助于数据缩放甚至数据清理的想法,您可以在以后作为准备数据集进行建模的一部分执行。
describe() 函数创建加载时间序列的 7 项统计摘要,包括观测值的均值、标准差、中位数、最小值和最大值。
|
1 2 3 |
from pandas import read_csv series = read_csv('daily-total-female-births-in-cal.csv', header=0, index_col=0) print(series.describe()) |
运行此示例会打印出生率数据集的摘要。
|
1 2 3 4 5 6 7 8 |
count 365.000000 mean 41.980822 std 7.348257 min 23.000000 25% 37.000000 50% 42.000000 75% 46.000000 max 73.000000 |
绘制时间序列图
绘制时间序列数据图,特别是单变量时间序列,是探索数据的重要组成部分。
此功能通过调用 plot() 函数在加载的 Series 上提供。
下面是绘制整个加载时间序列数据集的示例。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-total-female-births-in-cal.csv', header=0, index_col=0) pyplot.plot(series) pyplot.show() |
运行此示例会创建一个时间序列图,其中 y 轴显示每日出生人数,x 轴显示时间(天)。
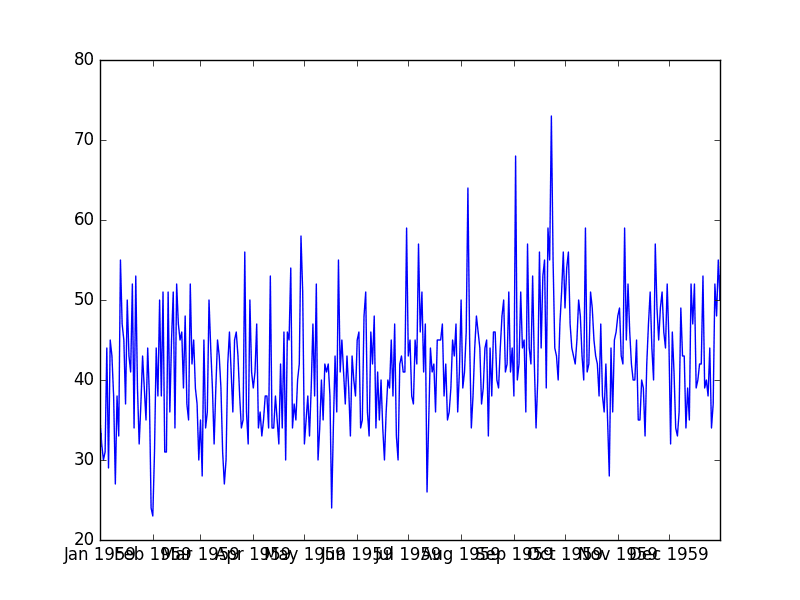
每日女性出生总数图
进一步阅读
如果您有兴趣了解更多关于 Pandas 处理时间序列数据的功能,请参阅下面的链接。
总结
在这篇文章中,您学习了如何使用 Pandas Python 库加载和处理时间序列数据。
具体来说,你学到了:
- 如何将时间序列数据加载为 Pandas Series。
- 如何查看和计算时间序列数据的摘要统计信息。
- 如何绘制时间序列数据。
您对使用 Python 处理时间序列数据或本文有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






您可能会觉得这个有用:https://github.com/blue-yonder/tsfresh
谢谢 Vishal,我很想深入研究这个。
关于本教程,我们如何从 Series 对象中提取 X 和 Y?
https://machinelearning.org.cn/5-step-life-cycle-neural-network-models-keras/
这篇帖子解释了如何将时间序列转换为具有 X 和 y 组件的监督学习问题
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
这篇帖子中标题为“将时间序列转换为监督学习”的部分提供了 Python 代码
https://machinelearning.org.cn/time-series-forecasting-long-short-term-memory-network-python/
当我使用 print(series[‘1959-01’]) 时,它给我一个 key error。
抱歉,我没见过这种情况。
确认您的数据正确,也许在文本编辑器中打开 CSV 文件并确认没有页脚。
考虑打印所有加载的数据,以查看它是否确实按预期加载。
告诉我进展如何。
我遇到了同样的问题,看起来它没有被解析为日期格式,但我不知道如何转换它。
我搞明白了。问题在于我忘记删除 csv 文件的页脚信息。
很高兴听到这个消息。
嗨,如果您有大量这样的文件,手动删除尾部不是一个好选择。有没有办法用 pandas 自动处理这个问题?
运行第一段代码时出错 🙁
回溯(最近一次调用)
文件“/usr/lib/python2.7/site.py”,第 68 行,在
import os
文件“/usr/lib/python2.7/os.py”,第 400 行,在
import UserDict
文件“/usr/lib/python2.7/UserDict.py”,第 116 行,在
import _abcoll
文件“/usr/lib/python2.7/_abcoll.py”,第 11 行,在
from abc import ABCMeta, abstractmethod
听到这个消息我很难过。看起来您的环境可能没有设置好。
这个教程会有帮助
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
我使用 pyplot(series) 时收到错误
ValueError: 无法将字符串转换为浮点数:'1959-12-31'
我找到了将对象更改为 datetime 对象,然后使用 date2num 使其工作的方法,但我很好奇为什么您传递数据的方式对我不起作用?我使用的是 Python 3。
我遇到了以下错误。
FileNotFoundError: 文件 b’daily-total-female-births-in-cal.csv’ 不存在
您需要下载数据集并将其放置在与您的代码相同的目录中。
我正在使用 Python 3。因此,对于绘制时间序列图,我必须将索引更改为日期时间索引。否则会发生“值错误”异常。错误发生是因为索引值是字符串格式,而对于绘制图表,索引值应该不是字符串。在我们的例子中,它应该采用日期时间格式。
import matplotlib.pyplot as plt
plt.plot(pd.to_datetime(series.index),series.values)
plt.show()
或者您可以这样做
series.plot()
plt.show()
谢谢。
谢谢。这让我摆脱了巨大的困惑。
我写了以下代码
from pandas import read_csv
from matplotlib import pyplot
from sklearn.metrics import mean_squared_error
from math import sqrt
series = read_csv(‘daily_births.csv’, header=0, index_col=0, parse_dates=True, squeeze=True)
#series = read_csv(‘daily_births.csv’, header=0, index_col=0)
series.plot()
pyplot.show()
print(‘——————————————————————–‘)
predictions = []
actual = series.values[1:]
print(actual)
print(actual[363])
print(‘——————————————————————–‘)
rmse = sqrt(mean_squared_error(actual, predictions))
print(rmse)
出现错误:ValueError: 发现输入变量的样本数量不一致:[364, 0]。请帮忙
也许再次检查您的数据形状?
嗨,Jason,您如何设置稀疏且分组的时间序列数据?
这些想法中是否有任何一个可行
(1)根据最大时间跨度创建平均值,以消除任何空白
(2)以某种方式平滑空白
抱歉继续说,但如果您试图在 xgboost 模型中建模时间序列数据,并且需要预测最新的时间序列周期,您将如何处理此周期中明显缺乏数据的情况?xgboost 会自动为我们处理这个问题,还是您会建议更传统的时间序列方法?
谢谢!
我建议尽可能多地集思广益,提出不同的问题框架,并逐一测试以查看哪个有效。
回到这个教程,为什么会这样呢
—————————————————————————
AttributeError Traceback (最近一次调用)
in
----> 1 series=Series.from_csv(‘daily-total-female-births.csv’,headers=0)
AttributeError: 类型对象 'Series' 没有属性 'from_csv'
错误提示您的 Pandas 版本可能不是最新的?
试图访问 Pandas Series 的网站,但它关闭了?不得不将其更改为
series = pd.read_csv(‘daily-total-female-births.csv’, header=0)
现在可以了!
很高兴听到这个消息。
如果您使用 Python 2.7,这会很好用,您不会在使用 Series.from_csv('filename.csv') 或打印统计结果时遇到问题,例如 print(series.describe())
但请务必在 pyplot.plot() 之前尽早执行此操作,以获取旧版本的 Python 2.7 中的 matplotlib:
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
谢谢您的留言。
这里也对 series 到 dataframe 的转换做了一些修改
import pandas as pd
dataframe =pd.DataFrame(series)
嗨,Jason,
使用以下代码片段
# 使用 read_csv 加载出生数据
from pandas import read_csv
series = read_csv(‘daily-total-female-births-in-cal.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
print(type(series))
print(series.head())
返回的类型是数据框而不是序列。您有什么建议吗?
然后当我尝试打印系列时,出现 KeyError '1959-01'。有什么想法吗?
感谢您的帮助,
诚挚的问候,
Dominique
谢谢,
Dominique
我确认代码运行正确。
这是数据集
https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv
这是复制粘贴代码的帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
嗨,Jason,
午饭时我修改了代码。我的理解是您的代码适用于 Python 2.7。由于我正在运行 Python 3.7,这可能解释了它为何不起作用。
以下是适用于我的 Python 3.7 的代码片段。
无论如何,非常感谢您始终有帮助且指导良好的帖子。
诚挚的问候
Dominique
# Python version
import sys
print(‘Python: {}’.format(sys.version))
# 使用 read_csv 加载出生数据
import pandas as pd
sr = pd.read_csv(‘daily-total-female-births.csv’, delimiter=’;’)
print(type(sr))
# 使用 head() 函数打印前几行。
print(f’\nThe type is: {type(sr)}’)
print(sr.head(10))
# 使用 size 属性打印数据集的维度。
print(f’\nSize is:{sr.Date.size}’)
# 使用日期时间字符串查询数据集。
print(f’\n所有三月之前的日期:’)
print(sr[sr.Date <= '1959-01-03'])
# 打印观测值的汇总统计信息。
print(f'\nSummary:')
print(sr.describe())
# 数据可视化
from matplotlib import pyplot
sr.plot()
pyplot.show()
教程中的代码在 Python 2 和 3 中无需更改即可运行。
很高兴听到您解决了问题。
假设我读取了一些像您示例一样的数据
1959-01-04 31
1959-01-05 44
1959-01-06 29
或者可能还有以逗号分隔的值,包含小时、分钟和秒。
但我有一个函数,它只接受自 1970 年纪元以来的秒数形式的时间。
是否有将日期时间列转换为秒的通用方法?我知道如何转换单个值,但我想一次转换数千个值,并且最好不要在循环中。
谢谢
是的,我相信 Python 会在内部将日期时间表示为自纪元以来的时间,并提供一个直接检索纪元时间的函数。我建议查看 Python 或 Pandas API 文档,了解日期时间处理。
我实际上花了几个小时研究 Python 和 pandas 文档,并在各种论坛上浏览,试图弄清楚如何做到这一点。我曾期望它是一个微不足道的练习,而且答案可能会非常简单。问题是,我来自 Matlab 背景,习惯于使用数组……我找到了十几种将单个日期时间值转换为“自纪元以来的秒数”的方法,但它们都不能接受多个输入时间。不过,还是要谢谢你。
听到这个消息我很抱歉,约翰。我很乐意帮忙,但我不知道 API 调用。
也许可以尝试将您的问题发布到 stackoverflow.com
好主意,我会这么做的。谢谢
不客气。
这是一个在 flask python 中部署 LSTM 模型,我上传用于预测的 csv 文件中的第一列是 datetime,在进行预测并下载为新的 csv 文件后,如何再次保留第一列 datetime,请分享一些技巧,这真的困扰了我一段时间
app.py
from flask import Flask, make_response, request, render_template
import io
from io import StringIO
import csv
import pandas as pd
import numpy as np
import pickle
import os
from keras.models import load_model
from sklearn.preprocessing import MinMaxScaler
from statsmodels.tsa.arima_model import ARIMAResults
app = Flask(__name__)
@app.route(‘/’)
def form()
return “””
让我们尝试预测..
插入您的 CSV 文件,然后下载结果
预测
"""
@app.route(‘/transform’, methods=[“POST”])
def transform_view()
if request.method == ‘POST’
f = request.files[‘data_file’]
if not f
return “No file”
stream = io.StringIO(f.stream.read().decode(“UTF8”), newline=None)
csv_input = csv.reader(stream)
#print(“文件内容:”, file_contents)
#print(type(file_contents))
print(csv_input)
for row in csv_input
print(row)
stream.seek(0)
result = stream.read()
df = pd.read_csv(StringIO(result), usecols=[1])
# 从磁盘加载模型
model = load_model(‘model.h5’)
dataset = df.values
dataset = dataset.astype(‘float32′)
scaler = MinMaxScaler(feature_range=(0, 1))
数据集 = scaler.fit_transform(数据集)
dataset = np.reshape(dataset, (dataset.shape[0], 1, dataset.shape[1]))
df = model.predict(dataset)
transform = scaler.inverse_transform(df)
df_predict = pd.DataFrame(transform, columns=[“predicted value”])
response = make_response(df_predict.to_csv(index = True , encoding=’utf8’))
response.headers[“Content-Disposition”] = “attachment; filename=result.csv”
return response
if __name__ == “__main__”
app.run(debug=True, port = 9000, host = “localhost”)
您可以通过保存模型、加载模型并使用新文件继续训练来更新模型。
这可能会给您一些启发
https://machinelearning.org.cn/update-lstm-networks-training-time-series-forecasting/