将数据管道构建成可以轻松链接到深度学习模型的结构,是任何基于深度学习的系统的重要组成部分。PyTorch 提供了所有必要的工具来实现这一点。
在上一个教程中,我们使用了简单的数据集,但在现实世界场景中,我们需要处理更大的数据集,以充分发挥深度学习和神经网络的潜力。
在本教程中,您将学习如何在 PyTorch 中构建自定义数据集。虽然这里只关注图像数据,但本会话中学到的概念可以应用于任何形式的数据集,例如文本或表格数据集。因此,您将学到:
- 如何在 PyTorch 中处理预加载的图像数据集。
- 如何将 torchvision 变换应用于预加载的数据集。
- 如何在 PyTorch 中构建自定义图像数据集类并对其应用各种变换。
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中加载和提供数据集
图片来源:Uriel SC。部分权利保留。
概述
本教程分为三个部分;它们是
- PyTorch 中的预加载数据集
- 将 Torchvision 变换应用于图像数据集
- 构建自定义图像数据集
PyTorch 中的预加载数据集
PyTorch 领域库中提供了各种预加载的数据集,例如 CIFAR-10、MNIST、Fashion-MNIST 等。您可以从 torchvision 导入它们并进行实验。此外,您还可以使用这些数据集来对模型进行基准测试。
接下来,我们将从 torchvision 导入 Fashion-MNIST 数据集。Fashion-MNIST 数据集包含 70,000 张 28x28 像素的灰度图像,分为十个类别,每个类别包含 7,000 张图像。其中 60,000 张用于训练,10,000 张用于测试。
让我们开始导入本教程中将使用的一些库。
|
1 2 3 4 5 6 7 |
import torch from torch.utils.data import Dataset from torchvision import datasets import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt torch.manual_seed(42) |
我们还将定义一个辅助函数,使用 matplotlib 显示数据集中样本的元素。
|
1 2 3 4 |
def imshow(sample_element, shape = (28, 28)): plt.imshow(sample_element[0].numpy().reshape(shape), cmap='gray') plt.title('Label = ' + str(sample_element[1])) plt.show() |
现在,我们将使用 `torchvision.datasets` 中的 `FashionMNIST()` 函数加载 Fashion-MNIST 数据集。此函数接受一些参数:
root:指定我们将要存储数据的路径。train:指示是训练数据还是测试数据。我们将其设置为 False,因为我们目前不需要它进行训练。download:设置为 `True`,表示将从互联网下载数据。transform:允许我们使用任何可用的变换,我们将其应用于我们的数据集。
|
1 2 3 4 5 6 |
dataset = datasets.FashionMNIST( root='./data', train=False, download=True, transform=transforms.ToTensor() ) |
让我们通过 Fashion-MNIST 数据集中类名及其对应的标签来检查一下。
|
1 2 |
classes = dataset.classes print(classes) |
输出结果为:
|
1 |
['T恤/上衣', '裤子', '套衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '踝靴'] |
同样,对于类别标签
|
1 |
print(dataset.class_to_idx) |
输出结果为:
|
1 |
{'T恤/上衣': 0, '裤子': 1, '套衫': 2, '连衣裙': 3, '外套': 4, '凉鞋': 5, '衬衫': 6, '运动鞋': 7, '包': 8, '踝靴': 9} |
使用上面定义的辅助函数,我们可以可视化数据集的第一个元素及其对应的标签。
|
1 |
imshow(dataset[0]) |
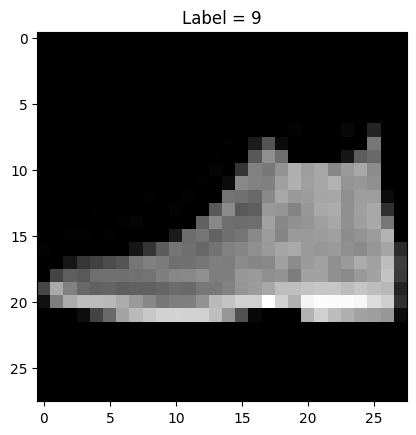
Fashion MNIST 数据集的第一项
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
将 Torchvision 变换应用于图像数据集
在许多情况下,我们需要在将图像馈送给神经网络之前应用多种变换。例如,很多时候我们需要对图像进行 `RandomCrop` 以进行数据增强。
如下所示,PyTorch 允许我们从各种变换中进行选择。
|
1 |
print(dir(transforms)) |
这显示了所有可用的变换函数。
|
1 2 3 4 5 6 7 8 9 10 |
['AugMix', 'AutoAugment', 'AutoAugmentPolicy', 'CenterCrop', 'ColorJitter', 'Compose', 'ConvertImageDtype', 'ElasticTransform', 'FiveCrop', 'GaussianBlur', 'Grayscale', 'InterpolationMode', 'Lambda', 'LinearTransformation', 'Normalize', 'PILToTensor', 'Pad', 'RandAugment', 'RandomAdjustSharpness', 'RandomAffine', 'RandomApply', 'RandomAutocontrast', 'RandomChoice', 'RandomCrop', 'RandomEqualize', 'RandomErasing', 'RandomGrayscale', 'RandomHorizontalFlip', 'RandomInvert', 'RandomOrder', 'RandomPerspective', 'RandomPosterize', 'RandomResizedCrop', 'RandomRotation', 'RandomSolarize', 'RandomVerticalFlip', 'Resize', 'TenCrop', 'ToPILImage', 'ToTensor', 'TrivialAugmentWide', ...] |
例如,让我们将 `RandomCrop` 变换应用于 Fashion-MNIST 图像,并将它们转换为张量。我们可以使用 `transform.Compose` 来组合多个变换,正如我们在上一个教程中学到的那样。
|
1 2 3 4 5 6 |
randomcrop_totensor_transform = transforms.Compose([transforms.CenterCrop(16), transforms.ToTensor()]) dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=randomcrop_totensor_transform) print("shape of the first data sample: ", dataset[0][0].shape) |
输出如下:
|
1 |
第一个数据样本的形状: torch.Size([1, 16, 16]) |
正如您所见,图像现在已被裁剪为 16x16 像素。现在,让我们绘制数据集的第一个元素,看看它们是如何被随机裁剪的。
|
1 |
imshow(dataset[0], shape=(16, 16)) |
这显示了以下图像
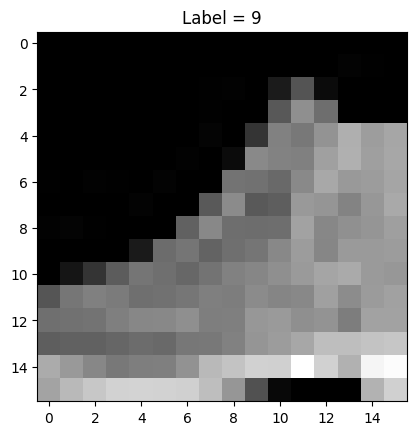
从 Fashion MNIST 数据集中裁剪的图像
将所有内容放在一起,完整的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import torch from torch.utils.data import Dataset from torchvision import datasets import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt torch.manual_seed(42) def imshow(sample_element, shape = (28, 28)): plt.imshow(sample_element[0].numpy().reshape(shape), cmap='gray') plt.title('Label = ' + str(sample_element[1])) plt.show() dataset = datasets.FashionMNIST( root='./data', train=False, download=True, transform=transforms.ToTensor() ) classes = dataset.classes print(classes) print(dataset.class_to_idx) imshow(dataset[0]) randomcrop_totensor_transform = transforms.Compose([transforms.CenterCrop(16), transforms.ToTensor()]) dataset = datasets.FashionMNIST( root='./data', train=False, download=True, transform=randomcrop_totensor_transform) ) print("shape of the first data sample: ", dataset[0][0].shape) imshow(dataset[0], shape=(16, 16)) |
构建自定义图像数据集
到目前为止,我们一直在讨论 PyTorch 中预先构建的数据集,但如果我们必须为自己的图像数据集构建一个自定义数据集类呢?虽然在上一个教程中我们仅对 `Dataset` 类的组件进行了简要概述,但在这里我们将从头开始构建一个自定义图像数据集类。
首先,在构造函数中,我们定义了类的参数。类中的 `__init__` 函数实例化 `Dataset` 对象。存储图像和注释的目录以及要应用于数据集的变换(如果需要)都会被初始化。这里我们假设我们有一些图像,它们的目录结构如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
attface/ |-- imagedata.csv |-- s1/ | |-- 1.png | |-- 2.png | |-- 3.png | ... |-- s2/ | |-- 1.png | |-- 2.png | |-- 3.png | ... ... |
并且注释是一个 CSV 文件,如下所示,位于图像的根目录下(即上面的“attface”)
|
1 2 3 4 5 6 7 |
s1/1.png,1 s1/2.png,1 s1/3.png,1 ... s12/1.png,12 s12/2.png,12 s12/3.png,12 |
其中 CSV 数据的第一列是图像的路径,第二列是标签。
同样,我们在类中定义 `__len__` 函数,它返回图像数据集中样本的总数;而 `__getitem__` 方法则读取并返回数据集中给定索引处的数据元素。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import os import pandas as pd import numpy as np from torchvision.io import read_image # 创建我们图像数据集的对象 class CustomDatasetForImages(Dataset): # 定义构造函数 def __init__(self, annotations, directory, transform=None): # 包含图像的目录 self.directory = directory annotations_file_dir = os.path.join(self.directory, annotations) # 加载包含图像信息的 csv 文件 self.labels = pd.read_csv(annotations_file_dir) # 要应用于图像的变换 self.transform = transform # 数据集中的图像数量 self.len = self.labels.shape[0] # 获取长度 def __len__(self): return len(self.labels) # 获取数据项 def __getitem__(self, idx): # 定义图像路径 image_path = os.path.join(self.directory, self.labels.iloc[idx, 0]) # 读取图像 image = read_image(image_path) # 图像对应的类别标签 label = self.labels.iloc[idx, 1] # 如果未设置为 None,则应用变换 if self.transform: image = self.transform(image) # 返回图像和标签 return image, label |
现在,我们可以创建我们的数据集对象并对其应用变换。我们假设图像数据位于名为“attface”的目录下,注释 CSV 文件位于“attface/imagedata.csv”。然后,数据集的创建如下:
|
1 2 3 4 |
directory = "attface" annotations = "imagedata.csv" custom_dataset = CustomDatasetForImages(annotations=annotations, directory=directory) |
可选地,您也可以将变换函数添加到数据集中:
|
1 2 3 4 |
randomcrop_totensor_transform = transforms.RandomCrop(16) dataset = CustomDatasetForImages(annotations=annotations, directory=directory, transform=randomcrop_totensor_transform) |
您可以使用此自定义图像数据集类来处理存储在您的目录中的任何数据集,并根据您的需求应用变换。
总结
在本教程中,您学习了如何在 PyTorch 中处理图像数据集和变换。具体来说,您学习了:
- 如何在 PyTorch 中处理预加载的图像数据集。
- 如何将 torchvision 变换应用于预加载的数据集。
- 如何在 PyTorch 中构建自定义图像数据集类并对其应用各种变换。
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...
")





暂无评论。