日志记录是一种存储有关脚本信息并跟踪发生的事件的方法。在 Python 中编写任何复杂的脚本时,日志记录对于在开发过程中调试软件至关重要。没有日志记录,在代码中找到问题的根源可能会非常耗时。
完成本教程后,您将了解:
- 为什么我们要使用日志记录模块
- 如何使用日志记录模块
- 如何自定义日志记录机制
通过我的新书《Python for Machine Learning》开始您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
Python中的日志记录(Logging)
照片来源:ilaria88。保留部分权利。
教程概述
本教程分为四个部分;它们是
- 日志记录的好处
- 基本日志记录
- 日志记录的高级配置
- 日志记录用法的示例
日志记录的好处
你可能会问:“为什么不直接使用打印?”
当您运行算法并想确认它的行为是否符合预期时,很自然地会在战略性位置添加一些 print() 语句来显示程序的狀態。打印可以帮助调试更简单的脚本,但随着代码变得越来越复杂,打印缺乏日志记录所具有的灵活性和健壮性。
通过日志记录,您可以精确地知道日志调用的来源,区分消息之间的严重性,并将信息写入文件,而打印无法做到这一点。例如,我们可以打开或关闭大型程序某个模块的消息。我们还可以调整日志消息的详细程度,而无需更改大量代码。
基本日志记录
Python 有一个内置库 logging 用于此目的。创建“记录器”以记录您想看到的日志或信息非常简单。
Python 中的日志系统在分层命名空间和不同的严重性级别下运行。Python 脚本可以在命名空间下创建记录器,每次记录消息时,脚本都必须指定其严重性。根据为命名空间设置的处理程序,记录的消息可以去到不同的地方。最常见的是将消息简单地打印在屏幕上,就像无处不在的 print() 函数一样。当我们启动程序时,我们可以注册一个新的处理程序并设置处理程序将响应的严重性级别。
有 5 个不同的日志记录级别,表示日志的严重性,按严重性递增显示
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
下面显示了一个非常简单的日志记录示例,使用默认记录器或根记录器
|
1 2 3 4 5 6 7 |
import logging logging.debug('Debug message') logging.info('Info message') logging.warning('Warning message') logging.error('Error message') logging.critical('Critical message') |
这些将发出不同严重级别的日志消息。虽然有五行日志记录,但如果您运行此脚本,您可能只会看到三行输出,如下所示
|
1 2 3 |
WARNING:root:This is a warning message ERROR:root:This is an error message CRITICAL:root:This is a critical message |
这是因为根记录器默认只打印严重性级别为 WARNING 或更高级别的日志消息。但是,这样使用根记录器与使用 print() 函数没有什么区别。
根记录器的设置并非一成不变。我们可以配置根记录器将输出到特定文件,更改其默认严重性级别,并格式化输出。 这是一个例子
|
1 2 3 4 5 6 7 8 9 10 11 |
import logging logging.basicConfig(filename = 'file.log', level = logging.DEBUG, format = '%(asctime)s:%(levelname)s:%(name)s:%(message)s') logging.debug('Debug message') logging.info('Info message') logging.warning('Warning message') logging.error('Error message') logging.critical('Critical message') |
运行此脚本将在屏幕上不产生任何输出,但会在新创建的文件 file.log 中包含以下内容
|
1 2 3 4 5 |
2022-03-22 20:41:08,151:DEBUG:root:Debug message 2022-03-22 20:41:08,152:INFO:root:Info message 2022-03-22 20:41:08,152:WARNING:root:Warning message 2022-03-22 20:41:08,152:ERROR:root:Error message 2022-03-22 20:41:08,152:CRITICAL:root:Critical message |
logging.basicConfig() 的调用是为了修改根记录器。在我们的示例中,我们将处理程序设置为输出到文件而不是屏幕,调整日志记录级别,使所有级别为 DEBUG 或更高级别的日志消息都能得到处理,并且还更改了日志消息输出的格式,以包含时间。
请注意,现在所有五个消息都已输出,因此根记录器记录的默认级别现在是“DEBUG”。可以 在日志记录文档中找到用于格式化输出的日志记录属性(例如 %(asctime)s)。
虽然有默认的记录器,但我们通常希望创建和使用可以单独配置的其他记录器。这是因为我们可能希望为不同的记录器设置不同的严重性级别或格式。可以使用以下方法创建新记录器
|
1 |
logger = logging.getLogger("logger_name") |
在内部,记录器按层次结构组织。使用以下方式创建的记录器
|
1 |
logger = logging.getLogger("parent.child") |
将被创建在名称为“parent”的记录器下,该记录器又在根记录器下。使用字符串中的点表示子记录器是父记录器的子代。在上面的例子中,一个名为“parent.child”的记录器被创建,同时隐式地创建了一个名为 "parent" 的记录器。
创建后,子记录器具有其父记录器的所有属性,直到重新配置。我们可以通过以下示例来演示这一点
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import logging # Create `parent.child` logger logger = logging.getLogger("parent.child") # Emit a log message of level INFO, by default this is not print to the screen logger.info("this is info level") # Create `parent` logger parentlogger = logging.getLogger("parent") # Set parent's level to INFO and assign a new handler handler = logging.StreamHandler() handler.setFormatter(logging.Formatter("%(asctime)s:%(name)s:%(levelname)s:%(message)s")) parentlogger.setLevel(logging.INFO) parentlogger.addHandler(handler) # Let child logger emit a log message again logger.info("this is info level again") |
此代码片段将只输出一行
|
1 |
2022-03-28 19:23:29,315:parent.child:INFO:this is info level again |
这是由 StreamHandler 对象及其自定义格式字符串创建的。这发生在重新配置 parent 记录器之后,因为否则,根记录器的配置将占主导地位,并且不会打印 INFO 级别的消息。
日志记录的高级配置
正如我们在最后一个示例中所看到的,我们可以配置我们创建的记录器。
级别阈值
与根记录器的基本配置一样,我们也可以配置记录器的输出目标、严重性级别和格式。以下是如何将记录器的**级别阈值**设置为 INFO
|
1 2 |
parent_logger = logging.getLogger("parent") parent_logger.setLevel(logging.INFO) |
现在,严重性级别为 INFO 或更高的命令将被 parent_logger 记录。但如果仅此而已,您将看不到任何来自 parent_logger.info("messages") 的内容,因为该记录器没有分配**处理程序**。事实上,根记录器也没有任何处理程序,除非您使用 logging.basicConfig() 设置一个。
日志处理程序
我们可以使用处理程序配置记录器的输出目标。处理程序负责将日志消息发送到正确的目的地。有几种类型处理程序;最常见的是 StreamHandler 和 FileHandler。使用 StreamHandler,记录器将输出到终端,而使用 FileHandler,记录器将输出到特定文件。
以下是使用 StreamHandler 将日志输出到终端的示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import logging # Set up root logger, and add a file handler to root logger logging.basicConfig(filename = 'file.log', level = logging.WARNING, format = '%(asctime)s:%(levelname)s:%(name)s:%(message)s') # Create logger, set level, and add stream handler parent_logger = logging.getLogger("parent") parent_logger.setLevel(logging.INFO) parent_shandler = logging.StreamHandler() parent_logger.addHandler(parent_shandler) # Log message of severity INFO or above will be handled parent_logger.debug('Debug message') parent_logger.info('Info message') parent_logger.warning('Warning message') parent_logger.error('Error message') parent_logger.critical('Critical message') |
在上面的代码中,创建了两个处理程序:一个由 logging.basicConfig() 为根记录器创建的 FileHandler,以及一个为 parent 记录器创建的 StreamHandler。
请注意,即使有一个将日志发送到终端的 StreamHandler,来自 parent 记录器的日志仍然会被发送到 file.log,因为它属于根记录器,并且根记录器的处理程序对子日志消息也同样有效。我们可以看到发送到终端的日志包含 INFO 级别及以上级别的消息
|
1 2 3 4 |
Info message 警告信息 错误消息 Critical message |
但是,终端输出没有格式化,因为我们还没有使用 Formatter。然而,file.log 的日志已经设置了 Formatter,并且将如下所示
|
1 2 3 4 |
2022-03-22 23:07:12,533:INFO:parent:Info message 2022-03-22 23:07:12,533:WARNING:parent:Warning message 2022-03-22 23:07:12,533:ERROR:parent:Error message 2022-03-22 23:07:12,533:CRITICAL:parent:Critical message |
或者,我们可以在上面 parent_logger 的示例中使用 FileHandler
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import logging # Set up root logger, and add a file handler to root logger logging.basicConfig(filename = 'file.log', level = logging.WARNING, format = '%(asctime)s:%(levelname)s:%(name)s:%(message)s') # Create logger, set level, and add stream handler parent_logger = logging.getLogger("parent") parent_logger.setLevel(logging.INFO) parent_fhandler = logging.FileHandler('parent.log') parent_fhandler.setLevel(logging.WARNING) parent_logger.addHandler(parent_fhandler) # Log message of severity INFO or above will be handled parent_logger.debug('Debug message') parent_logger.info('Info message') parent_logger.warning('Warning message') parent_logger.error('Error message') parent_logger.critical('Critical message') |
上面的示例演示了您还可以设置处理程序的级别。parent_fhandler 的级别会过滤掉非 WARNING 级别或更高级别的日志。但是,如果您将处理程序的级别设置为 DEBUG,那将与不设置级别相同,因为 DEBUG 日志将被记录器的级别(即 INFO)过滤掉。
在这种情况下,parent.log 的输出是
|
1 2 3 |
警告信息 错误消息 Critical message |
而 file.log 的输出与之前相同。总之,当记录器记录日志消息时,
- 记录器的级别将决定该消息是否足够严重以被处理。如果未设置记录器的级别,则将使用其父记录器(最终是根记录器)的级别进行此考虑。
- 如果日志消息将被处理,**所有**沿记录器层级(直至根记录器)添加的处理程序都将收到消息的副本。每个处理程序的级别将决定该特定处理程序是否应响应此消息。
格式化程序
为了配置记录器的格式,我们使用 Formatter。它允许我们设置日志的格式,类似于我们在根记录器的 basicConfig() 中所做的。以下是如何为我们的处理程序添加格式化程序
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import logging # Set up root logger, and add a file handler to root logger logging.basicConfig(filename = 'file.log', level = logging.WARNING, format = '%(asctime)s:%(levelname)s:%(name)s:%(message)s') # Create logger, set level, and add stream handler parent_logger = logging.getLogger("parent") parent_logger.setLevel(logging.INFO) parent_fhandler = logging.FileHandler('parent.log') parent_fhandler.setLevel(logging.WARNING) parent_formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(message)s') parent_fhandler.setFormatter(parent_formatter) parent_logger.addHandler(parent_fhandler) # Log message of severity INFO or above will be handled parent_logger.debug('Debug message') parent_logger.info('Info message') parent_logger.warning('Warning message') parent_logger.error('Error message') parent_logger.critical('Critical message') |
首先,我们创建一个格式化程序,然后将我们的处理程序设置为使用该格式化程序。如果我们愿意,我们可以创建多个不同的记录器、处理程序和格式化程序,以便我们可以根据自己的喜好进行混合搭配。
在此示例中,parent.log 将具有
|
1 2 3 |
2022-03-23 13:28:31,302:WARNING:Warning message 2022-03-23 13:28:31,302:ERROR:Error message 2022-03-23 13:28:31,303:CRITICAL:Critical message |
并且与根记录器关联的 file.log 将具有
|
1 2 3 4 |
2022-03-23 13:28:31,302:INFO:parent:Info message 2022-03-23 13:28:31,302:WARNING:parent:Warning message 2022-03-23 13:28:31,302:ERROR:parent:Error message 2022-03-23 13:28:31,303:CRITICAL:parent:Critical message |
下面是来自 日志记录模块文档的可视化日志记录器、处理程序和格式化程序的流程图:
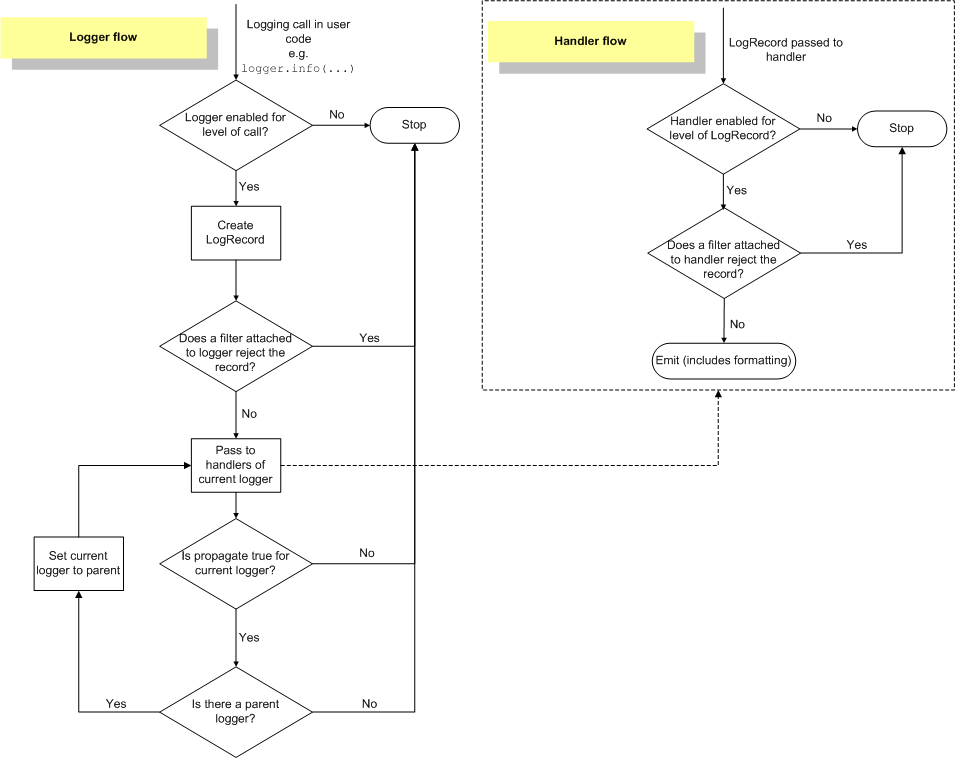
日志记录模块中日志记录器和处理程序的流程图
日志记录用法示例
让我们以 Nadam 算法为例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
# gradient descent optimization with nadam for a two-dimensional test function from math import sqrt from numpy import asarray from numpy.random import rand from numpy.random import seed # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # 生成初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 报告进度 print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 执行具有nadam的梯度下降搜索 best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) print('Done!') print('f(%s) = %f' % (best, score)) |
最简单的用例是使用日志记录来替换print()函数。我们可以进行如下更改:首先,在运行任何代码之前创建一个名为nadam的记录器,并为其分配一个StreamHandler。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... import logging ... # 添加:创建记录器并分配处理程序 logger = logging.getLogger("nadam") handler = logging.StreamHandler() handler.setFormatter(logging.Formatter("%(asctime)s|%(levelname)s|%(name)s|%(message)s")) logger.addHandler(handler) logger.setLevel(logging.DEBUG) # 初始化伪随机数生成器 seed(1) ... # 剩余代码 |
我们必须分配一个处理程序,因为我们从未配置过根记录器,而这将是创建的唯一处理程序。然后,在nadam()函数中,我们重新创建了一个名为nadam的记录器,但由于它已经被设置好了,所以级别和处理程序都得以保留。在nadam()的每个外部for循环结束时,我们将print()函数替换为logger.info(),这样日志消息就会被日志记录系统处理。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
... # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # 创建一个记录器 logger = logging.getLogger("nadam") # 生成一个初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减的移动平均值 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解决方案 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # 评估候选点 score = objective(x[0], x[1]) # 使用记录器报告进度 logger.info('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] ... |
如果我们对Nadam算法的更深层机制感兴趣,我们可以添加更多的日志。以下是完整的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# gradient descent optimization with nadam for a two-dimensional test function import logging from math import sqrt from numpy import asarray from numpy.random import rand from numpy.random import seed # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): logger = logging.getLogger("nadam") # 生成一个初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减的移动平均值 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): iterlogger = logging.getLogger("nadam.iter") # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解决方案 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat iterlogger.info("Iteration %d variable %d: mhat=%f nhat=%f", t, i, mhat, nhat) # 评估候选点 score = objective(x[0], x[1]) # 报告进度 logger.info('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # 创建记录器并分配处理程序 logger = logging.getLogger("nadam") handler = logging.StreamHandler() handler.setFormatter(logging.Formatter("%(asctime)s|%(levelname)s|%(name)s|%(message)s")) logger.addHandler(handler) logger.setLevel(logging.DEBUG) logger = logging.getLogger("nadam.iter") logger.setLevel(logging.INFO) # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 执行具有nadam的梯度下降搜索 best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) print('Done!') print('f(%s) = %f' % (best, score)) |
我们准备了两个级别的记录器,nadam和nadam.iter,并将它们设置为不同的级别。在nadam()的内部循环中,我们使用子记录器打印一些内部变量。运行此脚本时,它将打印以下内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 0 variable 0: mhat=-0.597442 nhat=0.110055 2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 0 variable 1: mhat=1.586336 nhat=0.775909 2022-03-29 12:24:59,421|INFO|nadam|>0 f([-0.12993798 0.40463097]) = 0.18061 2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 1 variable 0: mhat=-0.680200 nhat=0.177413 2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 1 variable 1: mhat=2.020702 nhat=1.429384 2022-03-29 12:24:59,421|INFO|nadam|>1 f([-0.09764012 0.37082777]) = 0.14705 2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 2 variable 0: mhat=-0.687764 nhat=0.215332 2022-03-29 12:24:59,421|INFO|nadam.iter|Iteration 2 variable 1: mhat=2.304132 nhat=1.977457 2022-03-29 12:24:59,421|INFO|nadam|>2 f([-0.06799761 0.33805721]) = 0.11891 ... 2022-03-29 12:24:59,449|INFO|nadam.iter|Iteration 49 variable 0: mhat=-0.000482 nhat=0.246709 2022-03-29 12:24:59,449|INFO|nadam.iter|Iteration 49 variable 1: mhat=-0.018244 nhat=3.966938 2022-03-29 12:24:59,449|INFO|nadam|>49 f([-5.54299505e-05 -1.00116899e-03]) = 0.00000 完成! f([-5.54299505e-05 -1.00116899e-03]) = 0.000001 |
设置不同的记录器不仅允许我们设置不同的级别或处理程序,还可以通过查看消息中记录器的名称来区分日志消息的来源。
事实上,一个方便的技巧是创建一个日志装饰器,并将该装饰器应用于某些函数。我们可以跟踪该函数被调用的每一次。例如,我们在下面创建了一个装饰器,并将其应用于objective()和derivative()函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
... # 一个用于记录函数调用和返回值的Python装饰器 def loggingdecorator(name): logger = logging.getLogger(name) def _decor(fn): function_name = fn.__name__ def _fn(*args, **kwargs): ret = fn(*args, **kwargs) argstr = [str(x) for x in args] argstr += [key+"="+str(val) for key,val in kwargs.items()] logger.debug("%s(%s) -> %s", function_name, ", ".join(argstr), ret) return ret return _fn return _decor # 目标函数 @loggingdecorator("nadam.function") def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 @loggingdecorator("nadam.function") def derivative(x, y): return asarray([x * 2.0, y * 2.0]) |
然后我们将在日志中看到以下内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
2022-03-29 13:14:07,542|DEBUG|nadam.function|objective(-0.165955990594852, 0.4406489868843162) -> 0.22171292045649288 2022-03-29 13:14:07,542|DEBUG|nadam.function|derivative(-0.165955990594852, 0.4406489868843162) -> [-0.33191198 0.88129797] 2022-03-29 13:14:07,542|INFO|nadam.iter|Iteration 0 variable 0: mhat=-0.597442 nhat=0.110055 2022-03-29 13:14:07,542|INFO|nadam.iter|Iteration 0 variable 1: mhat=1.586336 nhat=0.775909 2022-03-29 13:14:07,542|DEBUG|nadam.function|objective(-0.12993797816930272, 0.4046309737819536) -> 0.18061010311445824 2022-03-29 13:14:07,543|INFO|nadam|>0 f([-0.12993798 0.40463097]) = 0.18061 2022-03-29 13:14:07,543|DEBUG|nadam.function|derivative(-0.12993797816930272, 0.4046309737819536) -> [-0.25987596 0.80926195] 2022-03-29 13:14:07,543|INFO|nadam.iter|Iteration 1 variable 0: mhat=-0.680200 nhat=0.177413 2022-03-29 13:14:07,543|INFO|nadam.iter|Iteration 1 variable 1: mhat=2.020702 nhat=1.429384 2022-03-29 13:14:07,543|DEBUG|nadam.function|objective(-0.09764011794760165, 0.3708277653552375) -> 0.14704682419118062 2022-03-29 13:14:07,543|INFO|nadam|>1 f([-0.09764012 0.37082777]) = 0.14705 2022-03-29 13:14:07,543|DEBUG|nadam.function|derivative(-0.09764011794760165, 0.3708277653552375) -> [-0.19528024 0.74165553] 2022-03-29 13:14:07,543|INFO|nadam.iter|Iteration 2 variable 0: mhat=-0.687764 nhat=0.215332 ... |
其中,我们可以通过nadam.function记录器打印的消息看到对这两个函数每次调用的参数和返回值。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
随着日志消息越来越多,终端屏幕会变得非常繁忙。使日志更容易查看问题的一种方法是使用colorama模块用颜色高亮日志。您需要先安装该模块。
|
1 |
pip install colorama |
以下是如何将colorama模块与logging模块一起使用来更改日志颜色和文本亮度的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import logging import colorama from colorama import Fore, Back, Style # 初始化终端以支持颜色 colorama.init(autoreset = True) # 像往常一样设置记录器 logger = logging.getLogger("color") logger.setLevel(logging.DEBUG) shandler = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(name)s:%(message)s') shandler.setFormatter(formatter) logger.addHandler(shandler) # 发出带有颜色的日志消息 logger.debug('Debug message') logger.info(Fore.GREEN + 'Info message') logger.warning(Fore.BLUE + 'Warning message') logger.error(Fore.YELLOW + Style.BRIGHT + 'Error message') logger.critical(Fore.RED + Back.YELLOW + Style.BRIGHT + 'Critical message') |
从终端中,您将看到以下内容:
其中colorama模块中的Fore、Back和Style控制着打印文本的前景、背景和亮度样式。这利用了ANSI转义字符,并且只在支持ANSI的终端上有效。因此,这不适用于将日志记录到文本文件。
事实上,我们可以从Formatter类派生出
|
1 2 3 4 5 6 7 8 9 |
... colors = {"DEBUG":Fore.BLUE, "INFO":Fore.CYAN, "WARNING":Fore.YELLOW, "ERROR":Fore.RED, "CRITICAL":Fore.MAGENTA} class ColoredFormatter(logging.Formatter): def format(self, record): msg = logging.Formatter.format(self, record) if record.levelname in colors: msg = colors[record.levelname] + msg + Fore.RESET return msg |
并使用它而不是logging.Formatter。以下是我们如何进一步修改Nadam示例以添加颜色:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
# gradient descent optimization with nadam for a two-dimensional test function import logging import colorama from colorama import Fore from math import sqrt from numpy import asarray from numpy.random import rand from numpy.random import seed def loggingdecorator(name): logger = logging.getLogger(name) def _decor(fn): function_name = fn.__name__ def _fn(*args, **kwargs): ret = fn(*args, **kwargs) argstr = [str(x) for x in args] argstr += [key+"="+str(val) for key,val in kwargs.items()] logger.debug("%s(%s) -> %s", function_name, ", ".join(argstr), ret) return ret return _fn return _decor # 目标函数 @loggingdecorator("nadam.function") def objective(x, y): return x**2.0 + y**2.0 # 目标函数的导数 @loggingdecorator("nadam.function") def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): logger = logging.getLogger("nadam") # 生成一个初始点 x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # 初始化衰减的移动平均值 m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # 运行梯度下降 for t in range(n_iter): iterlogger = logging.getLogger("nadam.iter") # 计算梯度 g(t) g = derivative(x[0], x[1]) # 逐个变量构建解决方案 for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat iterlogger.info("Iteration %d variable %d: mhat=%f nhat=%f", t, i, mhat, nhat) # 评估候选点 score = objective(x[0], x[1]) # 报告进度 logger.warning('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # 准备彩色格式化器 colorama.init(autoreset = True) colors = {"DEBUG":Fore.BLUE, "INFO":Fore.CYAN, "WARNING":Fore.YELLOW, "ERROR":Fore.RED, "CRITICAL":Fore.MAGENTA} class ColoredFormatter(logging.Formatter): def format(self, record): msg = logging.Formatter.format(self, record) if record.levelname in colors: msg = colors[record.levelname] + msg + Fore.RESET return msg # 创建记录器并分配处理程序 logger = logging.getLogger("nadam") handler = logging.StreamHandler() handler.setFormatter(ColoredFormatter("%(asctime)s|%(levelname)s|%(name)s|%(message)s")) logger.addHandler(handler) logger.setLevel(logging.DEBUG) logger = logging.getLogger("nadam.iter") logger.setLevel(logging.DEBUG) # 初始化伪随机数生成器 seed(1) # 定义输入范围 bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # 定义总迭代次数 n_iter = 50 # 步长 alpha = 0.02 # 平均梯度因子 mu = 0.8 # 平均梯度平方因子 nu = 0.999 # 执行具有nadam的梯度下降搜索 best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) print('Done!') print('f(%s) = %f' % (best, score)) |
如果在支持的终端上运行它,我们将看到以下输出:

请注意,彩色输出可以帮助我们更轻松地发现任何异常行为。日志记录有助于调试,还可以让我们通过更改几行代码来轻松控制我们想要看到的详细程度。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
文章
总结
在本教程中,您学习了如何在脚本中实现日志记录技术。
具体来说,你学到了:
- 基本和高级日志记录技术
- 如何将日志记录应用于脚本及其好处
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






对 bee 开发者来说的好文章
感谢您的反馈!
Daniel 和 James,很棒的文章!一定会用起来!
不过有一个问题:在您的文章中我从没见过 f-string 的用法。有什么原因吗?我觉得 f-string 比其他替代方法可读性要强得多!
诚挚的问候
George
George,你好……谢谢你的反馈!这只是一个偏好的问题。我同意如果使用得当,它们会非常有益。