LSTM 自动编码器是适用于序列数据的一种自动编码器实现,它采用了编码器-解码器 LSTM 架构。
训练完成后,该模型的一部分编码器可以用于对序列数据进行编码或压缩,这些压缩后的数据可用于数据可视化,或者作为监督学习模型的特征向量输入。
在本教程中,您将了解 LSTM 自动编码器模型及其在 Keras 中使用 Python 实现的方法。
阅读本文后,你将了解:
- 自动编码器是一种自监督学习模型,可以学习输入数据的压缩表示。
- LSTM 自动编码器可以学习序列数据的压缩表示,并已应用于视频、文本、音频和时间序列序列数据。
- 如何使用 Keras 深度学习库在 Python 中开发 LSTM 自动编码器模型。
开始您的项目,阅读我的新书《Python 长短期记忆网络》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。

LSTM自编码器简明介绍
照片由 Ken Lund 提供,部分权利保留。
概述
本文分为六个部分:
- 什么是自动编码器?
- 序列数据的问题
- 编码器-解码器 LSTM 模型
- 什么是 LSTM 自动编码器?
- LSTM 自动编码器的早期应用
- 如何在 Keras 中创建 LSTM 自动编码器
什么是自动编码器?
一个 自动编码器 是一个旨在学习输入数据压缩表示的神经网络模型。
它们是一种无监督学习方法,尽管从技术上讲,它们是使用监督学习方法进行训练的,被称为自监督学习。它们通常作为更广泛模型的一部分进行训练,该模型试图重构输入。
例如
|
1 |
X = model.predict(X) |
自动编码器模型的设计通过在模型中间设置瓶颈(bottleneck)来有意地增加这一难度,然后从瓶颈处进行输入数据的重构。
自动编码器有很多类型,其用途各不相同,但最常见的用途可能是作为学习到的或自动化的特征提取模型。
在这种情况下,一旦模型被训练,就可以丢弃重构部分,并使用模型直到瓶颈的部分。瓶颈处的模型输出是一个固定长度的向量,它提供了输入数据的压缩表示。
然后可以将来自领域的数据输入模型,瓶颈处的模型输出可用作监督学习模型的特征向量,用于可视化,或更普遍地用于降维。
序列数据的问题
序列预测问题具有挑战性,尤其是因为输入序列的长度可能不同。
这很有挑战性,因为机器学习算法,特别是神经网络,是为处理固定长度的输入而设计的。
序列数据的另一个挑战是,观测值的时序顺序可能使得提取适合用作监督学习模型输入的特征变得困难,这通常需要深厚的领域知识或信号处理领域的专业知识。
最后,许多涉及序列的预测建模问题需要预测本身也是一个序列。这些被称为序列到序列(sequence-to-sequence)或 seq2seq 的预测问题。
您可以在这里了解更多关于序列预测问题的信息。
编码器-解码器 LSTM 模型
循环神经网络,例如长短期记忆(LSTM)网络,专门设计用于支持输入数据序列。
它们能够学习输入序列时序顺序中的复杂动态,并利用内部记忆在长的输入序列中记住或使用信息。
LSTM 网络可以组织成一种称为编码器-解码器 LSTM 的架构,该架构允许模型既支持可变长度的输入序列,又能预测或输出可变长度的输出序列。
这种架构是许多复杂序列预测问题(如语音识别和文本翻译)进步的基础。
在这种架构中,编码器 LSTM 一步一步地读取输入序列。在读取完整个输入序列后,隐藏状态或此模型的输出表示整个输入序列的内部学习表示,作为固定长度向量。然后,在生成输出序列的每个步骤时,该向量被用作解码器模型的输入。
您可以在这里了解更多关于编码器-解码器架构的信息。
什么是 LSTM 自动编码器?
LSTM 自动编码器是适用于序列数据的一种自动编码器实现,它采用了编码器-解码器 LSTM 架构。
对于给定的序列数据集,编码器-解码器 LSTM 被配置为读取输入序列,对其进行编码,然后解码并重构它。模型的性能评估基于模型重构输入序列的能力。
一旦模型达到了所需的重构序列性能水平,就可以移除解码器部分,只剩下编码器模型。然后,此模型可用于将输入序列编码为固定长度的向量。
生成的向量随后可用于各种应用,包括作为另一个监督学习模型的输入序列的压缩表示。
LSTM 自动编码器的早期应用
LSTM 自动编码器最早且被广泛引用的一项应用是 2015 年的论文《使用 LSTM 无监督学习视频表示》。
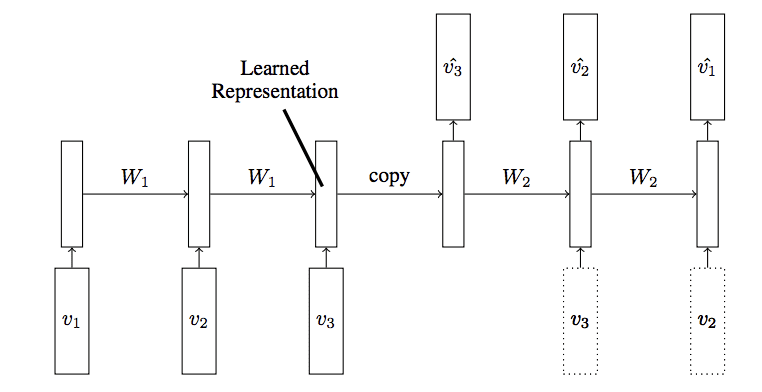
LSTM 自动编码器模型
摘自《使用 LSTM 无监督学习视频表示》
在论文中,Nitish Srivastava 等人将 LSTM 自动编码器描述为编码器-解码器 LSTM 的扩展或应用。
他们将该模型用于视频输入数据,以重构视频帧序列以及预测视频帧,这两种都被描述为无监督学习任务。
模型的输入是向量序列(图像块或特征)。编码器 LSTM 读取此序列。在读取完最后一个输入后,解码器 LSTM 接管,并输出目标序列的预测。
— 使用 LSTM 无监督学习视频表示,2015。
除了直接使用模型之外,作者还探讨了一些有趣的架构选择,这些选择可能有助于未来的模型应用。
他们以相反的顺序设计模型以重构目标视频帧序列,声称这使得模型解决的优化问题更容易处理。
目标序列与输入序列相同,但顺序相反。反转目标序列可以简化优化,因为模型可以通过观察低范围的关联来开始工作。
— 使用 LSTM 无监督学习视频表示,2015。
他们还探索了训练解码器模型的两种方法:一种是条件化于解码器生成的上一个输出,另一种是没有任何此类条件化。
解码器可以有两种类型——条件式或无条件式。条件式解码器将最后一个生成的输出帧作为输入[...]。无条件式解码器则不接收此输入。
— 使用 LSTM 无监督学习视频表示,2015。
还有一个更复杂的自动编码器模型被探索,其中一个编码器使用了两个解码器:一个用于预测序列中的下一帧,另一个用于重构序列中的帧,这被称为复合模型。
…重构输入和预测未来可以组合起来创建一个复合[...]。在这里,编码器 LSTM 被要求生成一个状态,我们可以从中预测接下来的几帧以及重构输入。
— 使用 LSTM 无监督学习视频表示,2015。
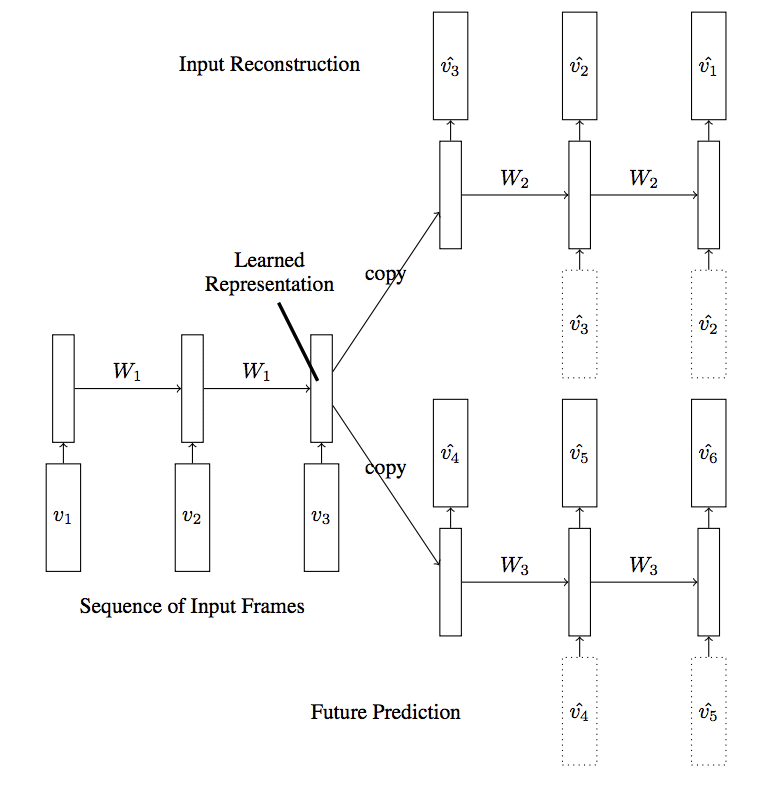
带两个解码器的 LSTM 自动编码器模型
摘自《使用 LSTM 无监督学习视频表示》
这些模型以多种方式进行了评估,包括使用编码器来初始化分类器。似乎他们没有将编码器的输出作为分类的输入,而是选择直接使用编码器模型的权重来初始化一个独立的 LSTM 分类器。考虑到实现的复杂性,这令人惊讶。
我们使用从该模型中学到的编码器 LSTM 的权重来初始化一个 LSTM 分类器。
— 使用 LSTM 无监督学习视频表示,2015。
在他们的实验中,没有对解码器进行条件化的复合模型表现最好。
表现最好的模型是复合模型,它结合了自动编码器和未来预测器。尽管条件式变体在微调后的分类准确性方面没有带来显著的改进,但它们的预测误差略低。
— 使用 LSTM 无监督学习视频表示,2015。
LSTM 自动编码器的许多其他应用也得到了证明,包括文本序列、音频数据和时间序列。
如何在 Keras 中创建 LSTM 自动编码器
在 Keras 中创建 LSTM 自动编码器可以通过实现编码器-解码器 LSTM 架构并配置模型来重构输入序列来实现。
让我们看几个例子来具体说明。
重构 LSTM 自动编码器
最简单的 LSTM 自动编码器是能够学会重构每个输入序列的。
在这些演示中,我们将使用一个包含一个样本、九个时间步和一个特征的数据集。
|
1 |
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] |
我们可以从定义序列开始,并将其重塑为首选的 [样本,时间步,特征] 形状。
|
1 2 3 4 5 |
# 定义输入序列 sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) # 将输入重塑为 [样本, 时间步, 特征] n_in = len(sequence) sequence = sequence.reshape((1, n_in, 1)) |
接下来,我们可以定义一个编码器-解码器 LSTM 架构,它期望输入序列具有九个时间步和一个特征,并输出一个具有九个时间步和一个特征的序列。
|
1 2 3 4 5 6 7 |
# 定义模型 model = Sequential() model.add(LSTM(100, activation='relu', input_shape=(n_in,1))) model.add(RepeatVector(n_in)) model.add(LSTM(100, activation='relu', return_sequences=True)) model.add(TimeDistributed(Dense(1))) model.compile(optimizer='adam', loss='mse') |
接下来,我们可以在我们构造的数据集上训练模型。
|
1 2 |
# 拟合模型 model.fit(sequence, sequence, epochs=300, verbose=0) |
完整的示例如下所示。
模型的配置,例如单元数量和训练周期,完全是任意的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# lstm 自动编码器重构序列 from numpy import array from keras.models import Sequential 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import RepeatVector from keras.layers import TimeDistributed from keras.utils import plot_model # 定义输入序列 sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) # 将输入重塑为 [样本, 时间步, 特征] n_in = len(sequence) sequence = sequence.reshape((1, n_in, 1)) # 定义模型 model = Sequential() model.add(LSTM(100, activation='relu', input_shape=(n_in,1))) model.add(RepeatVector(n_in)) model.add(LSTM(100, activation='relu', return_sequences=True)) model.add(TimeDistributed(Dense(1))) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(sequence, sequence, epochs=300, verbose=0) plot_model(model, show_shapes=True, to_file='reconstruct_lstm_autoencoder.png') # 演示重构 yhat = model.predict(sequence, verbose=0) print(yhat[0,:,0]) |
运行该示例将训练自动编码器并打印重构后的输入序列。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行该示例几次,并比较平均结果。
结果非常接近,只有很小的舍入误差。
|
1 2 |
[0.10398503 0.20047213 0.29905337 0.3989646 0.4994707 0.60005534 0.70039135 0.80031013 0.8997728 ] |
将创建模型架构图以供参考。
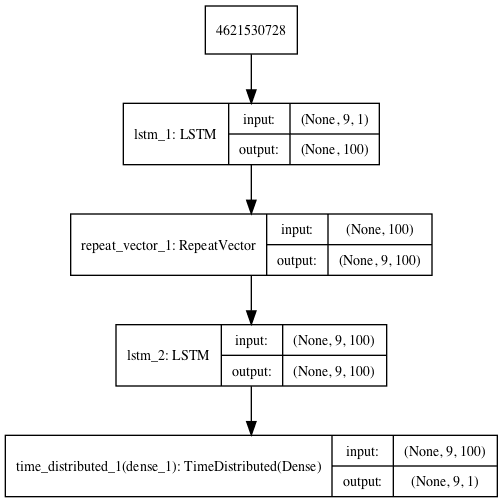
用于序列重构的 LSTM 自动编码器
预测 LSTM 自动编码器
我们可以修改重构 LSTM 自动编码器,使其能够预测序列中的下一个时间步。
在我们这个小的构造问题中,我们期望输出是序列
|
1 |
[0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] |
这意味着模型将期望每个输入序列有九个时间步,而输出序列有八个时间步。
|
1 2 3 4 5 6 |
# 将输入重塑为 [样本, 时间步, 特征] n_in = len(seq_in) seq_in = seq_in.reshape((1, n_in, 1)) # 准备输出序列 seq_out = seq_in[:, 1:, :] n_out = n_in - 1 |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# lstm 自动编码器预测序列 from numpy import array from keras.models import Sequential 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import RepeatVector from keras.layers import TimeDistributed from keras.utils import plot_model # 定义输入序列 seq_in = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) # 将输入重塑为 [样本, 时间步, 特征] n_in = len(seq_in) seq_in = seq_in.reshape((1, n_in, 1)) # 准备输出序列 seq_out = seq_in[:, 1:, :] n_out = n_in - 1 # 定义模型 model = Sequential() model.add(LSTM(100, activation='relu', input_shape=(n_in,1))) model.add(RepeatVector(n_out)) model.add(LSTM(100, activation='relu', return_sequences=True)) model.add(TimeDistributed(Dense(1))) model.compile(optimizer='adam', loss='mse') plot_model(model, show_shapes=True, to_file='predict_lstm_autoencoder.png') # 拟合模型 model.fit(seq_in, seq_out, epochs=300, verbose=0) # 演示预测 yhat = model.predict(seq_in, verbose=0) print(yhat[0,:,0]) |
运行该示例将打印输出序列,预测每个输入时间步的下一个时间步。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行该示例几次,并比较平均结果。
我们可以看到模型是准确的,除了小的舍入误差。
|
1 2 |
[0.1657285 0.28903174 0.40304852 0.5096578 0.6104322 0.70671254 0.7997272 0.8904342 ] |
将创建模型架构图以供参考。

用于序列预测的 LSTM 自动编码器
复合 LSTM 自动编码器
最后,我们可以创建一个复合 LSTM 自动编码器,它有一个编码器和两个解码器,一个用于重构,一个用于预测。
我们可以使用 Keras 的函数式 API 来实现这个多输出模型。您可以在这篇博文中了解更多关于函数式 API 的信息。
首先,定义编码器。
|
1 2 3 |
# 定义编码器 visible = Input(shape=(n_in,1)) encoder = LSTM(100, activation='relu')(visible) |
然后是用于重构的第一个解码器。
|
1 2 3 4 |
# 定义重构解码器 decoder1 = RepeatVector(n_in)(encoder) decoder1 = LSTM(100, activation='relu', return_sequences=True)(decoder1) decoder1 = TimeDistributed(Dense(1))(decoder1) |
然后是用于预测的第二个解码器。
|
1 2 3 4 |
# 定义预测解码器 decoder2 = RepeatVector(n_out)(encoder) decoder2 = LSTM(100, activation='relu', return_sequences=True)(decoder2) decoder2 = TimeDistributed(Dense(1))(decoder2) |
然后我们将整个模型连接起来。
|
1 2 |
# 连接起来 model = Model(inputs=visible, outputs=[decoder1, decoder2]) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# lstm 自动编码器重构和预测序列 from numpy import array from keras.models import Model from keras.layers import Input 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import RepeatVector from keras.layers import TimeDistributed from keras.utils import plot_model # 定义输入序列 seq_in = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) # 将输入重塑为 [样本, 时间步, 特征] n_in = len(seq_in) seq_in = seq_in.reshape((1, n_in, 1)) # 准备输出序列 seq_out = seq_in[:, 1:, :] n_out = n_in - 1 # 定义编码器 visible = Input(shape=(n_in,1)) encoder = LSTM(100, activation='relu')(visible) # 定义重构解码器 decoder1 = RepeatVector(n_in)(encoder) decoder1 = LSTM(100, activation='relu', return_sequences=True)(decoder1) decoder1 = TimeDistributed(Dense(1))(decoder1) # 定义预测解码器 decoder2 = RepeatVector(n_out)(encoder) decoder2 = LSTM(100, activation='relu', return_sequences=True)(decoder2) decoder2 = TimeDistributed(Dense(1))(decoder2) # 连接起来 model = Model(inputs=visible, outputs=[decoder1, decoder2]) model.compile(optimizer='adam', loss='mse') plot_model(model, show_shapes=True, to_file='composite_lstm_autoencoder.png') # 拟合模型 model.fit(seq_in, [seq_in,seq_out], epochs=300, verbose=0) # 演示预测 yhat = model.predict(seq_in, verbose=0) print(yhat) |
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行该示例几次,并比较平均结果。
运行该示例将使用两个解码器同时重构和预测输出序列。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[array([[[0.10736275], [0.20335874], [0.30020815], [0.3983948 ], [0.4985725 ], [0.5998295 ], [0.700336 , [0.8001949 ], [0.89984304]]], dtype=float32), array([[[0.16298929], [0.28785267], [0.4030449 ], [0.5104638 ], [0.61162543], [0.70776784], [0.79992455], [0.8889787 ]]], dtype=float32)] |
将创建模型架构图以供参考。
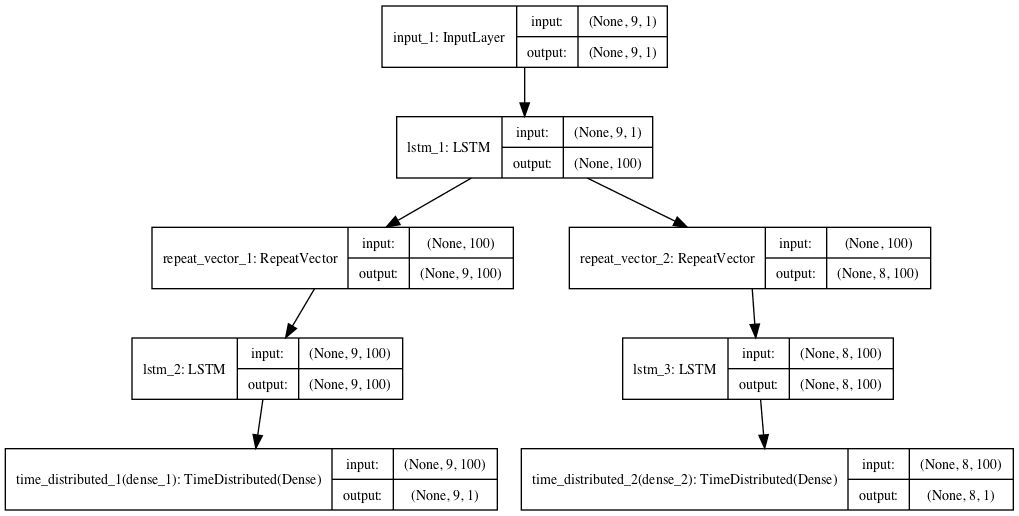
用于序列重构和预测的复合 LSTM 自动编码器
保留独立的 LSTM 编码器
无论选择哪种方法(重构、预测或复合),一旦自动编码器被训练,就可以移除解码器,并保留编码器作为独立模型。
然后,编码器可用于将输入序列转换为固定长度的编码向量。
我们可以通过创建一个新模型来实现这一点,该模型具有与我们原始模型相同的输入,并直接从编码器模型的末端输出,在 RepeatVector 层之前。
|
1 2 |
# 将 LSTM 编码器连接为输出层 model = Model(inputs=model.inputs, outputs=model.layers[0].output) |
以下是一个使用重构 LSTM 自动编码器的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# lstm 自动编码器重构序列 from numpy import array from keras.models import Sequential from keras.models import Model 从 keras.layers 导入 LSTM from keras.layers import Dense from keras.layers import RepeatVector from keras.layers import TimeDistributed from keras.utils import plot_model # 定义输入序列 sequence = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]) # 将输入重塑为 [样本, 时间步, 特征] n_in = len(sequence) sequence = sequence.reshape((1, n_in, 1)) # 定义模型 model = Sequential() model.add(LSTM(100, activation='relu', input_shape=(n_in,1))) model.add(RepeatVector(n_in)) model.add(LSTM(100, activation='relu', return_sequences=True)) model.add(TimeDistributed(Dense(1))) model.compile(optimizer='adam', loss='mse') # 拟合模型 model.fit(sequence, sequence, epochs=300, verbose=0) # 将 LSTM 编码器连接为输出层 model = Model(inputs=model.inputs, outputs=model.layers[0].output) plot_model(model, show_shapes=True, to_file='lstm_encoder.png') # 获取输入序列的特征向量 yhat = model.predict(sequence) print(yhat.shape) print(yhat) |
运行示例将创建一个独立的编码器模型,该模型可以用于或保存以备将来使用。
我们通过预测序列并获得编码器的 100 个元素输出来演示编码器。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。可以尝试运行该示例几次,并比较平均结果。
对于我们这个九步输入序列的微小例子来说,这显然是过度设计了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[[0.03625513 0.04107533 0.10737951 0.02468692 0.06771207 0. 0.0696108 0. 0. 0.0688471 0. 0. 0. 0. 0. 0. 0. 0.03871286 0. 0. 0.05252134 0. 0.07473809 0.02688836 0. 0. 0. 0. 0. 0.0460703 0. 0. 0.05190025 0. 0. 0.11807001 0. 0. 0. 0. 0. 0. 0. 0.14514188 0. 0. 0. 0. 0.02029926 0.02952124 0. 0. 0. 0. 0. 0.08357017 0.08418129 0. 0. 0. 0. 0. 0.09802645 0.07694854 0. 0.03605933 0. 0.06378153 0. 0.05267526 0.02744672 0. 0.06623861 0. 0. 0. 0.08133873 0.09208347 0.03379713 0. 0. 0. 0.07517676 0.08870222 0. 0. 0. 0. 0.03976351 0.09128518 0.08123557 0. 0.08983088 0.0886112 0. 0.03840019 0.00616016 0.0620428 0. 0. ] |
将创建模型架构图以供参考。
独立的编码器 LSTM 模型
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- 用序列进行预测
- 编码器-解码器长短期记忆网络
- 自动编码器,维基百科
- 使用 LSTM 无监督学习视频表示,ArXiv 2015。
- 使用 LSTM 无监督学习视频表示,PMLR,PDF,2015。
- 使用 LSTM 无监督学习视频表示,GitHub 仓库。
- 在 Keras 中构建自动编码器, 2016.
- 如何使用 Keras 函数式 API 进行深度学习
总结
在本教程中,您了解了 LSTM 自动编码器模型以及如何使用 Keras 在 Python 中实现它。
具体来说,你学到了:
- 自动编码器是一种自监督学习模型,可以学习输入数据的压缩表示。
- LSTM 自动编码器可以学习序列数据的压缩表示,并已应用于视频、文本、音频和时间序列序列数据。
- 如何使用 Keras 深度学习库在 Python 中开发 LSTM 自动编码器模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






解释得很棒……。
谢谢。
我正在尝试将自动编码器应用于我的无标签文本数据列以减小数据大小,您能否提供相关资源?
你好 Sai…以下资源是针对您查询的绝佳起点。
https://machinelearning.org.cn/implementing-the-transformer-encoder-from-scratch-in-tensorflow-and-keras/
非常好的和详细的 LSTM 表示。
我有一个包含 3000 个值的 CSV 文件,当我在 Google Colab 或 Jupyter Notebook 中运行它时,速度非常慢。可能是什么原因?
谢谢。
或许可以尝试在更快的机器上运行,例如 EC2?
或许可以尝试使用更高效的实现?
或许可以尝试使用更少训练数据?
感谢您的精彩博文!我从中学到了很多。
这个方法可以用于分类问题,例如情感分析吗?
也许可以。
嗨,Jason,
感谢您的博文,我真的很喜欢阅读。
我正尝试使用此方法来处理时间序列数据异常检测,这里有一些问题。
当您将序列重塑为 [样本, 时间步, 特征] 时,样本和特征始终等于 1。这里的值是如何选择的?如果输入序列的长度可变,如何设置时间步,是否总是选择最大长度?
另外,如果输入是二维表格数据,且每行长度不同,您将如何进行重塑或归一化?
提前感谢!
时间步应提供足够的历史记录以做出预测,特征是每个时间步记录的观测值。
此处有更多关于为 LSTM 准备数据的信息。
https://machinelearning.org.cn/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
你好,
我想知道为什么编码器的输出维度更高(100),因为我们通常使用编码器来创建低维度表示!
如果您错了,您能给我举些例子吗?
还有,关于样本的可变长度呢?您一直说 LSTM 对可变长度很有用。那么它如何处理像这样的训练集呢:
dataX[0] = [1,2,3,4]
dataX[1] = [2,5,7,8,4]
dataX[2] = [0,3]
我对第二个问题感到非常困惑,非常感谢您的帮助!🙂
模型重构输出,例如一个包含 9 个元素的 1D 向量。
您可以通过用0填充可变长度输入,并使用掩码层来忽略填充值。
“我想知道为什么编码器的输出具有更高的维度(100),因为我们通常使用编码器来创建更低的维度!”,我也有同样的问题,您能详细解释一下吗?
这只是架构的演示,请随意为您的特定问题更改模型配置。
你好,我想知道如何在编码器中添加一个层,只是添加一个叫做LSTM的层?非常感谢
您可以直接堆叠LSTM层,本教程提供了一个示例
https://machinelearning.org.cn/stacked-long-short-term-memory-networks/
很棒的文章。但读完后,我认为您正在处理序列最重要的一个问题——那就是它们具有可变长度。结果发现不是。您有机会写一篇关于使用掩码来中和填充值的教程吗?这似乎比模型其余部分更难。
是的,我相信我有很多关于这个主题的教程。
也许从这里开始
https://machinelearning.org.cn/handle-missing-timesteps-sequence-prediction-problems-python/
我真的很喜欢您的帖子,它们很重要。我从您的帖子中获得了许多知识。
今天,我要寻求您的帮助。我正在研究本地音乐分类。音乐的关键特征是其序列,并且它使用了七个音阶中的五个音阶,我们称之为音阶。
1. C – E – F – G – B。这是大三度、小二度、大二度、大三度和小二度
2. C – Db – F – G – Ab。这是小二度、大三度、大二度、小二度和大三度。
3. C – Db – F – Gb – A。这是小二度、大三度、小二度、小三度和小三度。
4. C – D – E – G – A。这是大二度、大二度、小三度、大二度和小三度
它不依赖于音程、节奏、旋律和其他特征。
这些音符必须按顺序排列。否则就会超出音阶。
那么,我需要使用哪些工具/算法来进行研究,以及任何可以从每个音轨中采样30秒而不影响音符顺序的采样机制?
此致
也许可以尝试一套模型,找出最适合您特定数据集的模型。
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
您好,能否请您解释一下编码器和解码器之间RepeatVector的使用?
编码器将1个特征的时间序列编码成固定长度的100维向量。据我理解,解码器应该接收这个100维向量并将其转换为1个特征的时间序列。
所以,编码器就像多对一的LSTM,解码器是一对多的(即使那个“一”是一个长度为100的向量)。我的理解正确吗?
RepeatVector将输入的内部表示重复n次,以获得所需的输出步数。
你好Jason?
“将输入表示为n次以获得所需的输出步数”的直观解释是什么?这里的n次表示,比如说在一个简单的LSTM AE中,是9,即输出步数。
从repeatvector我了解到,这里序列被读取并转换为一个单一向量(9x100),这个向量与100维向量相同,然后模型使用该向量来重构原始序列。对吗?
对于所需的输出步数,使用除了9之外的任何数字怎么样?
提前感谢。
为每个输出时间步的一个样本提供LSTM的输入。
哪个模型最适合股票市场预测?
根据我所读到的,价格的时间序列是一种随机游走。
更多信息在这里
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
你好,
感谢这篇信息丰富的帖子!
我正在尝试使用不同的Keras语法来重复您的第一个示例(重构LSTM自动编码器);代码如下
import numpy as np
from keras.layers import Input, LSTM, RepeatVector
from keras.models import Model
timesteps = 9
input_dim = 1
latent_dim = 100
# input placeholder
inputs = Input(shape=(时间步长, input_dim))
# “encoded”是输入的编码表示
encoded = LSTM(latent_dim,activation=’relu’)(inputs)
# “decoded”是输入的有损重构
decoded = RepeatVector(时间步长)(encoded)
decoded = LSTM(input_dim, activation=’relu’, return_sequences=True)(decoded)
sequence_autoencoder = Model(inputs, decoded)
encoder = Model(inputs, encoded)
# 编译模型
sequence_autoencoder.compile(optimizer=’adadelta’, loss=’mse’)
# run model
sequence_autoencoder.fit(sequence,sequence,epochs=300, verbose=0)
# 预测
sequence_autoencoder.predict(sequence,verbose=0)
我不知道为什么,但我总是得到比使用您的代码的模型差的结果。
那么我的问题是:这两种方法(语法)在底层有什么区别吗?或者它们实际上是相同的?
谢谢。
如果您在教程中的代码遇到问题,请确认您的Keras版本是2.2.4或更高版本,并且TensorFlow是最新版本。
我觉得可以对如何设置LSTM自动编码器进行更多的描述。特别是如何调整瓶颈。目前,当我将它应用于我的数据时,它基本上只是返回所有内容的平均值,这表明它太激进了,但我不清楚在哪里进行更改。
感谢您的建议。
Jason您好,感谢您提供的精彩文章,我花了一些时间在Kaggle上编写了一个受您内容启发的内核,展示了使用LSTM的常规时间序列方法,以及使用MLP但使用LSTM自动编码器编码的特征,如这里所示,有兴趣的朋友请看链接:https://www.kaggle.com/dimitreoliveira/time-series-forecasting-with-lstm-autoencoders
我很想得到一些反馈。
干得好!
嘿!我正在尝试将217行的数据压缩到单行。运行程序后,预测值返回NaN,您能指导我哪里做错了什么吗?
我这里有一些建议
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
亲爱的Jason
在构建和训练上述模型后,如何评估模型?(比如在常用的LSTM中的model.evaluate(train_x, train_y…))
非常感谢
模型的评估在于它重构输入的能力。您可以使用evaluate函数或手动进行预测的评估。
我从您的网站学到了很多。自动编码器可用于降维。是否有可能使用RNN自动编码器将多个时间序列输入合并为一个?我的数据形状是(9500, 20, 5) => (样本数,时间步,特征)。如何编码-解码成(9500, 20, 1)?
非常感谢,
也许需要一些仔细的设计。将所有数据合并为单个输入可能更容易。
感谢您的回复。将(9500,100,1) => (9500,20,1)会更容易吗?
也许可以测试一下看看。
嗨,Jason,
我是您网站的常客,从您的帖子和书中我学到了很多!
这篇也很有信息量,但有一点我不太明白:如果编码器的输入是[0.1, 0.2, …, 0.9],而期望的解码器输出是[0.2, 0.3, …, 0.9],这基本上是输入序列的一部分。我不确定您为什么说它是“为每个输入步骤预测下一步”。您能解释一下吗?自动编码器适合多步时间序列预测吗?
另一个问题:训练复合自动编码器是否意味着误差是针对两个期望输出([seq_in, seq_out])平均计算的?
我展示了两种学习编码的方式:重构输入和预测下一个时间步的输出。
请记住,模型一次输出一个时间步,以构建一个序列。
问得好,我认为报告的误差是两个输出的平均值。我不确定。
嗨,Jason,
您能多阐述一下第一个问题吗?
正如Jimmy所指出的,我真的不明白您在哪里预测了输出中的下一个时间步。
例如,如果我们输入的为[0.1, 0.2, …, 0.8],输出为[0.2, 0.3, …, 0.9],这对我来说是说得通的。
但是,既然我们已经提供了“下一个时间步”,我们到底在学习什么?
你好Nick……下面的内容可能对您感兴趣
这是一个深刻的问题。
从高层次来看,算法通过从许多历史例子中归纳学习,例如
这样的输入通常在这样的输出之前。
然后,归纳结果(即学习到的模型)可以在未来应用于新示例,以预测预期会发生什么或预期的输出是什么。
技术上,我们将此称为归纳或归纳决策。
https://zh.wikipedia.org/wiki/归纳推理
另请参阅此帖子
为什么机器学习算法能够处理从未见过的数据?
https://machinelearning.org.cn/what-is-generalization-in-machine-learning/
你好,我是JT。
首先,感谢您的帖子,它对LSTM AE模型的概念和代码提供了出色的解释。
如果我正确理解您的AE模型,那么您的LSTM AE向量层[shape (,100)]的特征似乎不是时间相关的。
因此,我尝试通过修改您的代码来构建一个时间相关的AE层。
如果您不介意,能否请您检查一下我的代码,看它们是否正确构建了一个包含时间维度AE层的AE模型?
我的代码如下。
from numpy import array
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
## 数据生成
# 定义输入序列
seq_in = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9])
# 将输入重塑为 [样本, 时间步, 特征]
n_in = len(seq_in)
seq_in = seq_in.reshape((1, n_in, 1))
# 准备输出序列
seq_out = array([3, 5, 7, 9, 11, 13, 15, 17, 19])
seq_out = seq_out.reshape((1, n_in, 1))
## 模型规范
# 定义编码器
visible = Input(shape=(n_in,1))
encoder = LSTM(60, activation=’relu’, return_sequences=True)(visible)
# AE Vector
AEV = LSTM(30, activation=’relu’, return_sequences=True)(encoder)
# 定义重构解码器
decoder1 = LSTM(60, activation=’relu’, return_sequences=True)(AEV)
decoder1 = TimeDistributed(Dense(1))(decoder1)
# 定义预测解码器
decoder2 = LSTM(30, activation=’relu’, return_sequences=True)(AEV)
decoder2 = TimeDistributed(Dense(1))(decoder2)
# 连接起来
model = Model(inputs=visible, outputs=[decoder1, decoder2])
model.summary()
model.compile(optimizer=’adam’, loss=’mse’)
# 拟合模型
model.fit(seq_in, [seq_in,seq_out], epochs=2000, verbose=2)
## 将seq_in馈送到预测seq_out的模型
hat1= model.predict(seq_in)
## 将seq_in馈送到预测AE Vector值的模型
model2 = Model(inputs=model.inputs, outputs=model.layers[2].output)
hat_ae= model2.predict(seq_in)
## 将AE Vector值馈送到预测seq_out的模型
input_vec = Input(shape=(n_in,30))
dec2 = model.layers[4](input_vec)
dec2 = model.layers[6](dec2)
model3 = Model(inputs=input_vec, outputs=dec2)
hat_= model3.predict(hat_ae)
非常感谢
我很乐意回答问题,但我没有能力审查和调试您的代码,抱歉。
感谢您的精彩帖子。作为一个机器学习初学者,您的帖子非常有帮助。
我想为大量人的名字数据集构建一个自动编码器。我想编码整个字段,而不是逐个字符地编码,例如[“Neil Armstrong”]而不是[“N”,“e”,“i”,“l”,“”,“A”,“r”,“m”,“s”,“t”,“r”,“o”,“n”,“g”]或[“Neil”,“Armstrong”]。我该怎么做?
将字符串列表包装在另一个列表/数组中。
嘿,谢谢你的帖子,我觉得很有帮助……虽然我有一个,在我看来,一个主要观点让我感到困惑。
– 如果自动编码器用于获得输入的压缩表示,那么在编码器部分之后获取输出的目的是什么,即使它现在是100个元素而不是9个?我很难找到100个元素数据的意义,以及如何使用这100个元素数据来预测异常值。这似乎与示例之前的解释所说的正好相反。非常希望能得到解释。
– 最后,我想真正理解如何通过最小化训练集在AE中的重构误差来学习权重,以及如何使用这个训练好的模型来预测交叉验证集和测试集中的异常值。
--
这只是一个演示,也许我可以举一个更好的例子。
例如,您可以将输入扩大到1000个输入,用10或100个值进行汇总。
Jason您好,Benjamin说得对。您为使用独立LSTM编码器提供的最后一个示例。输入序列是9个元素,但编码器的输出是100个元素,尽管在本教程的第一部分解释了编码器部分压缩输入序列并可用作特征向量。我也对100个元素的输出如何用作9个元素的输入序列的特征表示感到困惑。更详细的解释将会有帮助。谢谢!
感谢您的建议。
感谢您的精彩帖子。
正如您在第一部分提到的,“拟合后,模型的一部分编码器可用于编码或压缩序列数据,这些数据可以作为监督学习模型的特征向量输入”。我将特征向量(编码部分)输入到1个前馈神经网络的1个隐藏层
n_dimensions=50
fit()时出错:ValueError: Error when checking input: expected input_1 to have 3 dimensions, but got array with shape (789545, 50)。
我将自动编码器与FFNN混合,这是我的方法,对吗?你能帮我将特征向量塑形后再馈送给FFNN吗?
将LSTM更改为在解码器中不返回序列。
感谢您尽快回复。
我看到了您的帖子,解码器中的LSTM层设置为“return_sequences=True”,我遵循了它,然后出现了您看到的错误。实际上,我认为解码器不是堆叠LSTM(只有一个LSTM层),所以“return_sequences=False”是合适的。我已按照您的建议进行更改。又一个错误
decoded = TimeDistributed(Dense(features_n))(decoded)
File “/usr/local/lib/python3.4/dist-packages/keras/engine/topology.py”, line 592, in __call__
self.build(input_shapes[0])
File “/usr/local/lib/python3.4/dist-packages/keras/layers/wrappers.py”, line 164, in build
assert len(input_shape) >= 3
AssertionError。
您能给我一些建议吗?
谢谢你
我不确定这个错误,抱歉。也许可以把代码和错误发布到stackoveflow或者尝试调试?
嗨,Jason,
我找到了另一种构建full_model的方法。我不使用autoencoder.predict(train_x)来输入full_model。我使用原始输入,保存了autoencoder模型中编码器部分的状态,然后将这些状态设置为encoder模型。有点像这样
autoencoder.save_weights(‘autoencoder.h5′)
for l1,l2 in zip(full_model.layers[:a],autoencoder.layers[0:a]): #a:编码器部分中的层数
l1.set_weights(l2.get_weights())
训练full_model
full_model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history_class=full_model.fit(train_x, train_y, epochs=2, batch_size=256, validation_data=(val_x, val_y))
我的full_model运行了,但结果很糟糕。嘿,训练0%,测试/验证100%。
有趣,这似乎需要更多的调试。
嗨,Jason,
感谢您花费精力撰写这些帖子,它们非常有帮助。
是否可以同时学习多个时间序列的表示?这里的多个时间序列不是指多元。
例如,如果我有来自10个传感器的时间序列数据,我如何同时将它们输入以获得10个表示,而不是一个组合的表示?
祝好,
Anshuman
是的,每个序列将是用于训练一个模型的一个不同样本。
嗨,Jason,
我使用MinMaxScaler函数来规范化我的训练和测试数据。
之后,我进行了一些训练过程来获取model.h5文件。
然后,我使用这个文件来预测我的测试数据。
之后,我得到了一些范围在(0,1)的预测结果。
我使用MinMaxScaler的inverse_transform函数来反转我的原始数据。
但是,当我将我的原始数据(在缩放器之前)与我的预测数据进行比较时,x,y坐标发生了变化,如下所示
Ori_data = [7.6291,112.74,43.232,96.636,61.033,87.311,91.55,115.28,121.22,136.48,119.52,80.53,172.08,77.987,199.21,94.94,228.03,110.2,117.83,104.26,174.62,103.42,211.92,109.35,204.29,122.91,114.44,125.46,168.69,124.61,194.97,134.78,173.77,141.56,104.26,144.11,125.46,166.99,143.26,185.64,165.3,205.14]
预测数据 = [94.290375, 220.07372, 112.91617, 177.89548, 133.5322, 149.65489,
161.85602, 99.74797, 178.18903, 60.718987, 86.012276, 113.3682,
111.641655, 90.18026, 134.16464, 82.28861, 155.12575, 78.26058,
99.82883, 145.162, 98.78825, 98.62861, 130.25414, 62.43494,
143.52762, 74.574684, 99.36809, 169.79303, 107.395615, 131.40468,
124.29078, 114.974014, 135.11014, 107.4492, 90.64477, 188.39305,
121.55309, 174.63484, 138.58575, 167.6933, 144.91512, 162.34071]
当我将这些预测数据可视化到我的图像上时,方向改变了90度(即原始数据是水平的,而预测数据是垂直的)。
为什么会出现这种情况,以及如何解决?
调用 `transform()` 和 `inverse_transform()` 时,您必须确保列匹配。
请看这个教程
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨,Jason,
非常感谢您这篇精彩的文章。我希望您能用一个真实的数据集,比如20 newsgroup数据集来完成这个任务。
起初,并不清楚为不同目标准备数据的不同方法。
我的理解是,使用LSTM Autoencoder,我们可以根据目标以不同的方式准备数据。我说对了吗?
或者您能否提供一个链接,介绍如何准备20 news_group这样的文本数据以用于此类模型?
再次感谢您精彩的材料。
如果您正在处理文本数据,也许可以从这里开始。
https://machinelearning.org.cn/start-here/#nlp
Jason,非常感谢您提供的链接。我已经详细阅读了大量的材料,包括几个月前您在链接中提到的迷你课程。
我的主要问题是这里的标签数据。
例如,在您的代码中,重构部分,您为数据和标签都提供了序列。然而,在预测部分,您将 `seq_in` 和 `seq_out` 作为数据和标签,它们之间的区别在于 `seq_out` 向前看一个时间步长。
根据您的示例,我的问题是,如果我想使用这个LSTM自编码器进行主题建模,我是否需要遵循重构部分,因为我不需要任何预测?
我想我已经找到了答案。谢谢Jason 🙂
不。也许这个模型可以作为一个更好的起点。
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
我说的“基于不同的目标”是指,例如,如果我们使用这种架构进行主题建模、序列生成等,那么数据准备是否应该不同?
感谢您的文章!当您使用 `RepeatVectors()` 时,我猜您使用的是无条件解码器,对吗?
我猜是的。您是指与哪个特定的模型进行比较吗?
感谢这篇文章。这可以被表述为一个序列预测研究问题吗?
演示就是一个序列预测问题。
嗨,Jason,
多么棒的教程!
我对复合模型中使用的损失函数有一个疑问。
假设您为重构部分和预测/分类部分使用了不同的损失函数,并且预先训练了重构部分。
在Keras中,在训练模型时能否将这两个损失函数合并为一个,
这样模型在训练预测/分类部分时就不会失去或削弱其重构能力?
如果可以;您能否指引我正确的方向。
诚挚的问候
Kristian
是的,一个很好的问题!
您可以为网络的每个输出指定一个损失函数列表。
亲爱的,
在编码器-解码器的LSTM层上设置 `stateful = True` 有意义吗?
谢谢
这确实取决于您是想控制何时重置内部状态,还是不控制。
Jason,谢谢,但我还是没有得到我问题的答案。
换一种说法:这个模型中的潜在空间是什么?它只是输入数据的压缩版本吗?
您认为如果我使用“Many to one”的架构,我会为每个数据序列获得一个单词表示吗?
为什么我能在自编码器中轻松打印出主题的聚类,但在这种架构中却迷失了方向!
在某种意义上是的,但一个值的表示是对输入的激进投影/压缩,可能没有用。
你到底遇到了什么问题?
嗨,Jason,
我很欣赏您的教程!
我现在正在实现论文“使用LSTM进行视频表示的无监督学习”。但我的结果不太好。预测的图片很模糊,不像论文中的结果那样好。
(您可以在这里看到我的结果
https://i.loli.net/2019/03/28/5c9c374d68af2.jpg
https://i.loli.net/2019/03/28/5c9c37af98c65.jpg)
我不认为我的Keras模型与论文模型之间存在差异。但这个问题困扰了我两周,我找不到一个好的解决方案。我真的非常感谢您的帮助!
这是我的Keras模型代码。
听起来是一个很棒的项目!
抱歉,我没有能力调试您的代码,但我这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
谢谢您的回复。
我想知道根据您的经验,什么可能导致输出图像模糊?谢谢~
具体是在什么情况下?
你好 John!
我对您实现我刚读过的论文的Keras代码感到兴奋。
您能分享完整的代码(尤其是图像处理部分)供我学习您所做的吗?
因为我是ML新手,但正努力适应使用Autoencoder LSTM进行视频预测。
我如何将这个“Standalone LSTM Encoder”模型的单元状态用作另一个模型的输入层?假设在您的“Keep Standalone LSTM Encoder”代码中,您为 encoder LSTM 层提供了 `return_state=True` 选项,并像这样创建模型:
model = Model(inputs=model.inputs, outputs=[model.layers[0].output, hidden_state, cell_state])
然后可以通过 `model.outputs[2]` 检索单元状态。
问题是,这将返回一个“Tensor”,而Keras抱怨它只接受“Input Layer”作为 `Model()` 的输入。我该如何将这个单元状态作为输入馈送到另一个模型?
我认为使用单元状态作为输入会很奇怪,我不确定您想做什么。
尽管如此,您可以使用Keras来评估张量,获取数据,创建一个numpy数组,并将其作为模型输入。
另外,这可能会有帮助
https://machinelearning.org.cn/return-sequences-and-return-states-for-lstms-in-keras/
这是这篇论文中使用的方法:https://arxiv.org/pdf/1709.01907.pdf
“在编码器-解码器预训练后,它被视为一个智能特征提取黑盒。具体来说,编码器的最后一个LSTM单元状态被提取为学习到的嵌入。然后,训练一个预测网络,利用学习到的嵌入作为特征来预测未来一个或多个时间步长。”
他们训练了一个LSTM自编码器,并将最后一个编码器层的最后一个单元状态馈送到另一个模型。是我误解了吗?
听起来很奇怪,也许与作者确认一下他们是否没有指的是隐藏状态(输出)?
你好 Jason,
有没有办法堆叠LSTM自编码器?
例如
model = Sequential()
model.add(LSTM(units, activation=activation, input_shape=(n_in,d)))
model.add(RepeatVector(n_in))
model.add(LSTM( units/2, activation=activation))
model.add(RepeatVector(n_in)
model.add(LSTM(units/2, activation=activation,return_sequences=True))
model.add(LSTM(units, activation=activation, return_sequences=True))
model.add(TimeDistributed(Dense(d)))
这是一个正确的方法吗?
堆叠自编码器有什么好处吗?
我从未见过这样的东西 🙂
你好 George,
在Keras网站的“Deep autoencoder”部分有一个教程,其中使用了堆叠的编码器/解码器和收窄瓶颈。
https://blog.keras.org.cn/building-autoencoders-in-keras.html
该教程声称更深层次的架构比前一个示例中更浅的模型定义能产生稍好的结果。这个教程在其模型中使用了简单的密集层,所以我很好奇是否可以用LSTM层做类似的事情。
感谢分享。
我有一个关于自编码器的理论问题。我知道自编码器应该在输出处重构输入,通过这样做它们将学习到输入的一个较低维表示。现在我想知道是否有可能在输出处使用自编码器来重构其他东西(比如输入的一个修改版本)。
当然可以。
也许可以看看条件生成模型、VAE、GAN。
谢谢回复。我会去看看的。我考虑过降噪自编码器,但我不确定它是否适用于我的情况。
假设我有一个特征向量的两个版本,一个是 X,另一个是 X',它包含一些有意义的噪声(技术上不是噪声,而是有意义的信息)。那么,在这种情况下,使用降噪自编码器来学习 X 到 X' 的转换是否合适?
条件GAN对此用于图像到图像的转换。
Jason,您能解释一下 `RepeatVector` 和 `return_sequence` 之间的区别吗?
看起来它们都将向量重复了几次,但有什么区别呢?
我们是否只能在最后一个LSTM编码器层中使用 `return_sequence`,而在第一个LSTM解码器层之前不使用 `RepeatVector`?
是的,它们在操作上非常不同,但在效果上很相似。
“return_sequence”参数返回每个输入时间步长的LSTM层输出。
“RepeatVector”层复制LSTM在最后一个输入时间步长的输出,并将其重复n次。
Jason,谢谢,我现在明白了它们之间的区别。但是,这里还有一个问题,我们可以这样做吗?
”’
encoder = LSTM(100, activation=’relu’, input_shape=(n_in,1), return_sequence=True)
(这里没有RepeatVector层,但encoder层中的return_sequence为True)
decoder = LSTM(100, activation=’relu’, return_sequences=True)(encoder)
decoder = TimeDistributed(Dense(1))(decoder)
”’
如果可以,这与您分享的(在编码器和解码器之间使用RepeatVector层,但在编码器层中return_sequence为False)有什么区别?
RepeatVector允许解码器在创建每个输出时间步长时使用相同的表示。
堆叠的LSTM不同之处在于,它将在形成输出之前读取所有输入时间步长,在您的情况下,它将为每个输入时间步长输出一个激活。
没有“最好的”方法,为您的问题测试一系列模型,并使用效果最好的。
谢谢您回答我的问题。
尊敬的先生,
我想提的一点是Srivastava等人使用的无条件模型。a) 他们没有在解码器模型中提供任何输入。这个教程只使用了条件模型吗?
b) 即使我们使用了论文中提到的两个模型中的任何一个,我们也应该将编码器的隐藏状态,甚至可能是单元状态,传递给模型的第一时间步,而不是所有时间步。
这里的教程告诉我们,repeat vector为解码器模型的所有时间步提供了输入,而这在任何模型中都不应该发生。
此外,自动重建解码器模型中的目标时间步应该被反转。
如果我对论文的理解有误,请纠正我。期待您澄清我的疑问。提前感谢。
也许可以。
你可以认为这里的实现是受到论文的启发,而不是直接复现。
感谢您的澄清……感谢您的帖子,它很有帮助。
不客气。
我的理解是,repeatvector函数利用了原始输入的“更密集”的表示。对于一个具有100个隐藏单元的编码器lstm,所有信息都被压缩到一个100个元素的向量中(然后由repeatvector复制以获得所需的输出时间步)。对于return_sequence=TRUE,情况完全不同——你最终会得到100 x输入时间步的潜在变量。这更像是一个稀疏自动编码器。如果我错了,请纠正我。
嗨,Jason,
这篇博文非常有趣。我之前发表的一篇论文使用了LSTM自动编码器进行德语和荷兰语方言分析。
祝好,
Taraka
谢谢。
嗨,Jason,
(Forgot to paste the paper link)
这篇博文非常有趣。我之前发表的一篇论文使用了LSTM自动编码器进行德语和荷兰语方言分析。
https://www.aclweb.org/anthology/W16-4803
祝好,
Taraka
感谢分享。
嗨,Jason,
感谢您的教程,它真的很有帮助。
这里有一个关于编码器和解码器之间连接的问题。
在您的实现中,您将编码器的H维隐藏向量复制T次,并将其作为T*H时间序列传递给解码器。
为什么选择这种方式?我很好奇,还有其他方法可以这样做
将隐藏向量作为解码器第一时间步的初始状态,输入序列为零。
这种方式可以吗?
祝好,
Geralt
因为这是使用Keras库实现论文所需效果的简单方法。
不,我认为你的方法不是论文的精神。试试看会发生什么!?
你好 Jason 先生
我想用RNN和lstm开始手写孤立字符识别。
我的意思是,我们有一些字符图像,我想要一个代码来识别那个字符。
您能否帮助我找到一个基本的python代码来实现这个目的,以便我开始工作?
谢谢你
这听起来是个很棒的问题。
也许CNN-LSTM模型会是一个不错的选择!
你好,Brownlee 博士
感谢您的帖子,我想在这里使用LSTM来预测一个时间序列。例如,序列为(1 2 3 4 5 6 7 8 9),并将其用于训练。然后输出序列是多步预测的序列,直到达到理想值,例如(9.9 10.8 11.9 12 13.1)。
请看这篇文章
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
抱歉,我可能没有说清楚。我想在这里使用LSTM来预测一个时间序列。序列可能像这样 [10,20,30,40,50,60,70],并用它进行训练,如果时间步是3。当输入 [40,50,60] 时,我们希望输出是70。完成模型训练后,预测开始。当输入 [50,60,70] 时,输出可能是79,然后用于下一步预测,输入是 [60,70,79],输出可能是89。直到满足某个条件(例如输出 >= 100)迭代才结束。
那么我该如何实现上述预测过程,在哪里可以找到代码?
请,希望得到您的回复。
是的,您可以通过这篇帖子开始使用LSTM进行时间序列预测。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我在这里有更高级的帖子。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
感谢您的快速回复。
我还有一个问题,多步LSTM模型使用最后三个时间步作为输入并预测接下来的两个时间步。但在我的情况下,我想预测锂离子电池的容量衰减趋势,例如,将循环次数 < 160 的容量衰减曲线数据作为训练数据,然后我想预测容量的未来趋势,直到达到某个值(可能 <= 0.7Ah)——故障阈值,这可能在循环次数约为 250 时实现。在循环次数 160 和 220 之间,大约需要预测 90 个数据点。所以我不知道如何定义时间步和样本,如果输出时间步定义为 60(220-160=60),那么输入的时间步应该如何定义,这似乎不合理。
我非常希望得到您的回复,非常感谢!
您可以定义模型具有所需的任何数量的输入或输出。
如果您在处理numpy数组时遇到困难,也许这会有帮助。
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
尊敬的教授,
我有一个列表如下
[5206, 1878, 1224, 2, 329, 89, 106, 901, 902, 149, 8]
当 আমি এটিকে reconstruction LSTM-তে ইনপুট হিসাবে পাস করি (একটি অতিরিক্ত LSTM এবং repeat vector স্তর এবং 1000 epoch সহ), তখন আমি নিম্নলিখিত predicted output পাই।
[5066.752 1615.2777 1015.1887 714.63916 292.17035 250.14038
331.69427 356.30664 373.15497 365.38977 335.48383]
虽然有些值非常准确,但大多数其他值与原始值有很大偏差。
可能是什么原因?您建议我如何解决这个问题?
没有模型是完美的。
您可以在任何模型中预期误差,以及神经网络在不同训练运行中的方差,更多内容请看这里。
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
谢谢,教授。
如果我有一个列表,其中包含 2 和 1000 这样的不同数字,是否最好通过将每个元素除以最高元素来标准化列表,然后将结果序列作为自动编码器的输入?
是的,总的来说,标准化输入是一个好主意。
https://machinelearning.org.cn/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
你好,
我有两个问题,如果您能帮忙,我将非常感激——
1) 上面的序列非常小。
如果向量的长度约为 800 呢?我尝试过,但花费了太长时间。
您有什么建议?
2) 另外,是否可以将矩阵编码为向量?
谢谢
也许可以减小序列的长度?
也许可以尝试在更快的电脑上运行?
也许可以尝试另一种方法?
谢谢您的快速回复……我有一个困惑,现在您提到“训练”,它只是一个向量……您如何用多个向量的批次真正地训练它。
如果您是 Keras 的新手,也许可以从这个教程开始。
https://machinelearning.org.cn/5-step-life-cycle-neural-network-models-keras/
你好 Jason,我真的很感谢您提供的信息丰富的帖子。但我有两个问题。
问题1. `model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))` 是否意味着您正在创建一个拥有100个隐藏状态的LSTM层?
LSTM结构除了input_t之外,还需要隐藏状态(h_t)和单元状态(c_t),对吗?那么这里的100表示,对于形状为(9,1)(时间步=9,输入特征数=1)的数据,LSTM层会产生一个100个单元的隐藏状态(h_t)?
问题2. 在“维度约简”方面,它减小了多少?您能告诉我(9,1)的数据在潜在向量中减小了多少吗?
100 指的是第一个隐藏层中的 100 个单元/节点,也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
您可以尝试不同大小的瓶颈,看看哪种最适合您的特定数据集。
你好 Jason!这种方法可以用于句子纠错吗?也就是说,输入文本的拼写或语法错误?
例如,我有一个庞大的未标记文本语料库,并使用自动编码器技术进行了训练。我想构建一个模型,该模型接受(可变长度)句子作为输入,并根据训练数据分布输出最可能或最正确的句子,这是否可能?
也许可以,我鼓励您先查阅文献。
如果我有多个样本,如何为自动编码器塑造数据?
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
你好 Jason,感谢您提供的精彩文章!我有一个项目,我获得了数百个星系光谱(x轴上具有连续频率数,y轴上是从每个星系接收的光子数;它类似于连续的直方图)。我需要对所有这些光谱进行无监督聚类。您认为这个LSTM自动编码器是一个好选择吗?(每个光谱有 4000 对频率-通量)。
我正在考虑将自动编码器的特征空间与 K-means 算法或类似算法结合起来进行聚类(或者更好的是,类似这样:https://arxiv.org/abs/1511.06335)。
也许可以试试看结果?
你好,感谢您的教程……您有类似的关于LSTM但具有多个特征的教程吗?
我之所以问多个特征,是因为我构建了多个具有不同结构的自动编码器模型,但时间步长都为 30……在训练过程中,损失、均方根误差、验证损失和验证均方根误差似乎都在可接受的范围内 ~ 0.05,但当我进行预测并将预测与原始数据绘制在同一张图上时,它们似乎都完全不同。
我使用了MinMaxScaler,所以我在反变换之前和之后都尝试绘制原始数据和预测数据,但原始数据和预测数据甚至不接近。所以,我认为我在正确绘制预测方面遇到了麻烦。
您可以改编这篇帖子中的示例。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
感谢您的精彩帖子,但我希望您能包含更复杂的模型。
例如,同样的事情,但有 2 个特征而不是 1 个特征。
感谢您的建议。
这里的示例将会有帮助。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨 Jason
谢谢您的教程。
我有一个序列 A B C。每个 A B 和 C 都是长度为 25 的向量。
我的样本是这样的:A B C 标签,A’ B’ C’ 标签’,……。
我应该如何重塑数据?
输入维度的大小是多少?
抱歉,我没跟上。
你具体遇到了什么问题?
我的数据集是一个形状为 (10,3,25) 的数组。(3个特征,每个特征有25个特征,以向量形式)。
有必要重塑它吗?
这个数组的 input_shape 值是多少?
也许先阅读这篇帖子,以确认您的数据格式是否正确。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
谢谢你,Jason。
不客气。
嗨,Jason,
感谢您所做的出色工作。
我有一个关于层概念的疑问。LSTM层 (100) 是指,来自第一个LSTM层的100个神经元的隐藏层输出,以及所有这些100个层的输出将被视为最终状态值。这样对吗?
是的。
你好 Jason,
感谢您快速回复并回复我的疑问。我仍然对 Keras 提供的图感到困惑。
https://github.com/MohammadFneish7/Keras_LSTM_Diagram
在这里,他们解释说,每个层的输出是“我们要预测的 Y 变量的数量 * 时间步”。
我的疑问是,输出大小是“Y – 预测值”还是“隐藏值”?
谢谢
也许可以问一下图表的作者?
我有一些通用建议,可能会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
感谢 Jason 的回复。
我已阅读您的帖子,并对第一个 LSTM 层的输入格式感到清楚。
我对 Keras 的内部结构有以下疑问。
假设我的代码如下。
step_size = 3
model = Sequential()
model.add(LSTM(32, input_shape=(2, step_size), return_sequences = True))
model.add(LSTM(18))
model.add(Dense(1))
model.add(Activation(‘linear’))
我得到了以下摘要。
_________________________________________________________________
层(类型) 输出形状 参数 #
=================================================================
lstm_1 (LSTM) (None, 2, 32) 4608
_________________________________________________________________
lstm_2 (LSTM) (None, 18) 3672
_________________________________________________________________
dense_1 (Dense) (None, 1) 19
_________________________________________________________________
activation_1 (Activation) (None, 1) 0
=================================================================
Total params: 8,299
Trainable params: 8,299
不可训练参数: 0
_________________________________________________________________
无
并且我有以下内部层矩阵数据。
Layer 1
(3, 128)
(32, 128)
(128,)
Layer 2
(32, 72)
(18, 72)
(72,)
Layer 3
(18, 1)
(1,)
我找不到输出大小和每层矩阵大小之间的任何关系。但在每一层,指定的参数大小是权重矩阵大小的总和。您能否帮助我了解这些数字的实现?
我相信这能帮助您理解 LSTM 模型的输入形状。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嗨,Jason,
谢谢您的回复。
我已经阅读了这篇帖子。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
我能够理解输入到第一个 LSTM 层的结构。但我无法识别第一层的矩阵结构以及与第二层的连接。您能否提供更多指导来理解层中的矩阵维度?
谢谢
如果 LSTM 的 return_states=False,那么 LSTM 层的输出是每个节点的一个值,例如 LSTM(50) 返回一个包含 50 个元素的向量。
如果 LSTM 的 return_states=True,例如在堆叠 LSTM 层时,那么返回值将是每个节点的序列,序列的长度是该层的输入长度,例如 LSTM(50, input_shape=(100,1)),那么输出将是 (100,50) 或 100 个时间步的 50 个节点。
这有帮助吗?
感谢 Jason 的回复。
非常感谢您抽出时间和精力给我答复。这对我帮助很大。非常感谢您。您正在教导全世界!太棒了!!!
谢谢,很高兴对您有帮助。
您好,我是一名学生,我想预测未来 24 小时的时间序列(电力负荷)。
我想通过使用增强了 LSTM 的自动编码器来做到这一点。
我正在寻找一个合适的拓扑和结构。您能帮我吗?
此致
也许这里的某些教程可以作为第一步的帮助。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好,
我有一个关于复合模型的问题。在您的教程中,您将所有数据都输入了 LSTM 编码器。解码器 1 试图重建传递给编码器的任何内容。第二个解码器则尝试预测下一个序列。
我的问题是,一旦编码器看到了所有数据,它对预测分支还有意义吗?因为它已经看到了所有数据,肯定能预测得足够好,对吧?
我不知道编码器部分是如何工作的?它对两个分支的工作方式不同吗?编码器部分是否创建了一个单一的编码潜在空间,从该空间中两个解码器各自执行其任务?
您能否帮助我弄清楚。谢谢。
也许可以关注数据的样本方面,模型接收一个样本,然后预测输出,接着处理下一个样本,并预测输出,依此类推。
我们碰巧在训练模型时一起提供数据集中的所有样本。
这有帮助吗?
谢谢您的回复,但我仍然不清楚。
例如
我们有 10 个时间步的数据,大小为 120(N, 10, 120)。(N 是样本数)
f5 = 前 5 个时间步
l5 = 最后 5 个时间步
训练期间
1 选项()
seq_in = (N, f5, 120)
seq_out = (N, l5, 120)
model.fit(seq_in, [seq_in, seq_out], epochs=300, verbose=0)
2 选项()
seq_in = (N, 10, 120)
seq_out = (N, l5, 120)
model.fit(seq_in, [seq_in, seq_out], epochs=300, verbose=0)
上面选项的区别是什么?哪种方式是训练网络的正确方式?谢谢。
抱歉,我不明白。
len(f5) == 5?
那么您是在问 (N,5,120) 和 (N,10,120) 之间的区别吗?
区别在于时间步的数量。
如果您是数组形状的新手,这将有所帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
抱歉带来不便。
我想问您的是,我们是否应该将所有时间步(在此情况下为 10 个)传递,还是传递前 5 个时间步(在此情况下)来预测接下来的 5 个步骤。(我有一个 10 个时间步的数据,我希望用两个解码器来训练一个网络。第一个解码器应返回输入的重构,第二个解码器预测下一个值)。
问题是,如果我将所有 10 个时间步传递给网络,它将看到所有时间步,这意味着它将编码所有看到的数据。从编码空间,两个解码器将尝试重构和预测。这似乎使两个解码器看起来相似,那么使用重构分支解码器有什么意义呢?它如何帮助复合模型中的预测解码器?
再次感谢。
是的,目标不是训练一个预测模型,而是训练一个有效的输入编码。
使用预测模型作为解码器并不保证更好的编码,它只是一个可以尝试的替代策略,可能在某些问题上有用。
如果您想使用 LSTM 进行时间序列预测,可以从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
非常感谢您的回答。
嗨,Jason,
当我将重建自动编码器应用于我的数据 (1,1000,1) 时,我得到了 NaN 值。
这可能是什么原因?如何解决?
我正在探索数据重塑对 LSTM 的作用,并尝试将我的数据分成每批 5 个,每个批次有 200 个时间步长,但想了解 (1,1000,1) 的工作方式。
很抱歉听到这个消息,这可能有助于重塑数据。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
感谢回复。
你能识别用于重建的 LSTM 模型吗?是 1 对 1 还是多对 1?
在哪里可以在网站上找到 LSTM 模型的具体示例?
您可以从这里开始学习 LSTMs
https://machinelearning.org.cn/start-here/#lstm
包括教程、迷你课程和我的书。
你好,
我有一个问题。如果我在网络的第一个部分使用 Masking 层,那么 RepeatVector() 层是否支持掩码?因为如果它不支持掩码并用相同的值复制每个时间步长,那么我们的输出损失将无法正确计算。因为理想情况下,在我们的 MSE 损失中,对于每个示例,我们不希望包含我们进行了零填充的时间步长。
您能否分享如何忽略零填充值来计算 MSE 损失函数?
掩码仅对输入是必需的。
瓶颈层将具有输入的内部表示——在掩码之后。
掩码值将从输入中跳过。
你好,
但是,如果重构的对应于填充部分的时间步长不为零,那么我认为均方误差损失会非常大?如果我错了,你能告诉我吗,因为我的 MSE 损失在某些时期后变成“nan”。是进行后填充还是前填充更好?
谢谢,
Sounak Ray。
正确。
目标不是创建一个出色的预测模型,而是学习一个出色的中间表示。
很抱歉听到您遇到 NAN 值,我在这里有一些建议可能会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason,感谢这篇文章。我和 Sounak 遇到了同样的问题,即当 LSTM return_sequence = False 时,掩码实际上会丢失(RepeatVector 也不明确支持掩码,因为它实际上改变了时间步长维度),因为掩码无法传递到模型末端,损失也会为那些填充的时间步长(我在一个简单的例子中验证过)计算,而这些是我们不希望的。
我想知道您是否可以进行实验,看看它对学习到的瓶颈表示是否有影响?
嗨,Jason,
我非常喜欢您的帖子。感谢分享您的专业知识。非常感谢!
我也有一个关于这篇帖子的疑问。在“预测自动编码器”中,您不应该将时间序列分成两半,并通过将前半部分输入编码器来预测后半部分吗?您实现解码器的方式并没有真正预测序列,因为整个序列已经被编码器总结并提供给它了。这是真的吗,还是我遗漏了什么?
您可以尝试一下——序列预测问题有很多种表述方式,但这并不是本例中使用的模型。
请记住,我们不是在开发预测模型,而是在开发自动编码器。
你好,
我正在进行数据重建,输入是数据集的 [0:8] 列,而所需的输出是第 9 列。但是,LSTM 自动编码器模型在 10 到 15 个时间步长后会返回与输出相同的数值。我已经将模型应用于不同的数据集,但遇到了类似的问题。
我需要进行哪些参数调整才能获得独特的重构值?
也许可以尝试使用不同的模型架构或不同的训练超参数?
太棒了!我希望您能因此获得报酬。😉
谢谢。
是的,有些读者会购买电子书来支持我。
https://machinelearning.org.cn/products/
你好,
感谢这篇精彩的文章!
我读了关于 RepeatVector() 的评论,但我仍然不确定我是否正确理解了它。
我们只是复制了编码器 LSTM 的最后一个输出来将其馈送到解码器 LSTM 的每个单元以生成无条件序列。这是正确的吗?
另外,我对编码器 LSTM 的内部状态发生了什么感到好奇。它是否就被丢弃了,并且永远不会用于解码器?我想知道使用编码器最后一个 LSTM 单元的内部状态作为解码器 LSTM 的初始内部状态是否会有任何好处。或者它是否完全不必要,因为我们想要的只是训练编码器?
感谢您的时间!
正确。
编码器的内部状态已被丢弃。解码器使用状态来创建输出。
每个输出步骤的构建都取决于瓶颈向量和创建先前输出步骤的状态。
非常感谢您的辛勤工作和出色的教程。我学到了很多。您能否写一篇关于编码器-解码器架构中教师强制法的教程?这将非常有帮助。
谢谢!
是的,我认为我所有的编码器-解码器教程都使用了教师强制法。
我想知道做一个自动编码器的意义何在。
这似乎相当于一侧构建编码器-解码器,另一侧构建预测模型,因为两个输出似乎没有相互使用。
也许将解码器用作预测的判别器(如 GAN)会更有意义。
它可以用作序列数据的特征提取模型。
例如,您可以拟合解码器或任何模型并进行预测。
有什么方法可以构建一个过拟合的自动编码器(训练自动编码器时需要处理过拟合吗)。
以及如何证明获得的编码特征是重建原始数据所需的最佳压缩?
另外,您能否解释一下 TimeDistributed 层与其输入的关系?TimeDistributed 层有什么作用?它是否仅在处理 LSTM 层时才有用?
感谢您所有的帖子和书籍,它们在理解概念和应用方面非常有帮助。
好问题!
是的。例如,一个在训练集上表现良好但无法很好地重建测试数据的自动编码器。
关于 TimeDistributed 层更多内容请参见这里。
https://machinelearning.org.cn/timedistributed-layer-for-long-short-term-memory-networks-in-python/
我很难看到瓶颈。是输入后面的 100 个单元层吗?通常情况下,对于您的示例中的非平凡数据集,这应该比时间步长小得多,对吗?
是的,第一个隐藏层(编码器)的输出就是编码后的表示。
嗨,Jason,
非常感谢您写这篇精彩的文章!但我有一个让我非常困惑的问题。问题是这样的。由于 Encoder-Decoder LSTM 可以受益于可变输出长度的训练,我想知道它是否支持可变多步输出。我正在尝试使用另一个帖子中的“Multiple Parallel Input and Multi-Step Output”示例来改变输出步长的长度 https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/,所以输出序列是
[[[ 40 45 85]
[ 0 0 0]
[ 0 0 0]]
[[ 50 55 105]
[ 60 65 125]
[ 70 75 145]]
[[ 60 65 125]
[ 70 75 145]
[ 0 0 0]]
[[ 70 75 145]
[ 80 85 165]
[ 0 0 0]]
[[ 80 85 165]
[ 0 0 0]
[ 0 0 0]]]
但我预测的结果并不好。您能否给我一些指导?填充值 0 是否不合适?Encoder-Decoder LSTM 是否不支持可变长度的步长?
再次感谢。
是的,但您必须填充值。如果不能用 0 填充,也许可以尝试 -1。
或者,您可以使用动态 LSTM 并一次处理一个时间步长。这会向您展示如何操作。
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
感谢您建议我一次处理一个时间步长。我突然意识到没有必要使输出时间步长可变,因为我们可以逐个时间步长进行预测。我这样理解对吗?此外,我认为这两个帖子中的两个 Encoder-Decoder 模型之间没有本质区别,除了预测不同的时间步长和使用不同的 Keras 函数。这个理解对吗?
希望能得到您的回复。再次感谢。
也许可以。
我尝试了您的模型与我的输入。损失在 10 个周期之前收敛,正如预期的那样。但是,在第 10 个周期的某个点之后,损失变大了。
5536/42706 [==>………………………] – ETA: 39s – loss: 0.4187
5600/42706 [==>………………………] – ETA: 39s – loss: 0.4190
5664/42706 [==>………………………] – ETA: 39s – loss: 0.4189
5728/42706 [===>……………………..] – ETA: 39s – loss: 0.4188
5792/42706 [===>……………………..] – ETA: 39s – loss: 0.4189
5856/42706 [===>……………………..] – ETA: 39s – loss: 0.4184
5920/42706 [===>……………………..] – ETA: 38s – loss: 0.4185
5984/42706 [===>……………………..] – ETA: 38s – loss: 0.4188
6048/42706 [===>……………………..] – ETA: 38s – loss: 7.7892
6112/42706 [===>……………………..] – ETA: 38s – loss: 8.6366
6176/42706 [===>……………………..] – ETA: 38s – loss: 8.5517
6240/42706 [===>……………………..] – ETA: 38s – loss: 8.4680
6304/42706 [===>……………………..] – ETA: 38s – loss: 8.3862
6368/42706 [===>……………………..] – ETA: 38s – loss: 8.3056
6432/42706 [===>……………………..] – ETA: 38s – loss: 8.2270
6496/42706 [===>……………………..] – ETA: 38s – loss: 8.1499
6560/42706 [===>……………………..] – ETA: 38s – loss: 8.0738
6624/42706 [===>……………………..] – ETA: 38s – loss: 7.9993
6688/42706 [===>……………………..] – ETA: 38s – loss: 7.9269
6752/42706 [===>……………………..] – ETA: 38s – loss: 7.8556
6816/42706 [===>……………………..] – ETA: 38s – loss: 7.7855
6880/42706 [===>……………………..] – ETA: 37s – loss: 7.7169
6944/42706 [===>……………………..] – ETA: 37s – loss: 7.6496
7008/42706 [===>……………………..] – ETA: 37s – loss: 7.5831
7072/42706 [===>……………………..] – ETA: 37s – loss: 7.5183
7136/42706 [====>…………………….] – ETA: 37s – loss: 7.4546
7200/42706 [====>…………………….] – ETA: 37s – loss: 7.3912
7264/42706 [====>…………………….] – ETA: 37s – loss: 7.3297
7328/42706 [====>…………………….] – ETA: 37s – loss: 7.2693
7392/42706 [====>…………………….] – ETA: 37s – loss: 7.2094
7456/42706 [====>…………………….] – ETA: 37s – loss: 7.1505
7520/42706 [====>…………………….] – ETA: 37s – loss: 7.0928
7584/42706 [====>…………………….] – ETA: 37s – loss: 7.0363
7648/42706 [====>…………………….] – ETA: 37s – loss: 6.9807
7712/42706 [====>…………………….] – ETA: 37s – loss: 6.9260
7776/42706 [====>…………………….] – ETA: 37s – loss: 6.8724
7840/42706 [====>…………………….] – ETA: 37s – loss: 6.8196
7904/42706 [====>…………………….] – ETA: 36s – loss: 6.7676
7968/42706 [====>…………………….] – ETA: 36s – loss: 6.7163
8032/42706 [====>…………………….] – ETA: 36s – loss: 6.6655
8096/42706 [====>…………………….] – ETA: 36s – loss: 6.6160
8160/42706 [====>…………………….] – ETA: 36s – loss: 6.5667
8224/42706 [====>…………………….] – ETA: 36s – loss: 6.5184
8288/42706 [====>…………………….] – ETA: 36s – loss: 6.4707
8352/42706 [====>…………………….] – ETA: 36s – loss: 6.4239
8416/42706 [====>…………………….] – ETA: 36s – loss: 6.3782
8480/42706 [====>…………………….] – ETA: 36s – loss: 2378.7514
8544/42706 [=====>……………………] – ETA: 36s – loss: 27760.9716
8608/42706 [=====>……………………] – ETA: 36s – loss: 27755.8645
8672/42706 [=====>……………………] – ETA: 36s – loss: 27978.9607
8736/42706 [=====>……………………] – ETA: 36s – loss: 28032.9492
8800/42706 [=====>……………………] – ETA: 35s – loss: 28025.2542
8864/42706 [=====>……………………] – ETA: 35s – loss: 27902.1603
8928/42706 [=====>……………………] – ETA: 35s – loss: 27837.8133
8992/42706 [=====>……………………] – ETA: 35s – loss: 27830.6104
9056/42706 [=====>……………………] – ETA: 35s – loss: 27731.7000
9120/42706 [=====>……………………] – ETA: 35s – loss: 27630.7813
9184/42706 [=====>……………………] – ETA: 35s – loss: 27768.5311
9248/42706 [=====>……………………] – ETA: 35s – loss: 28076.0159
干得不错。
也许可以再次尝试拟合模型看看是否得到不同的结果?
嗨,Jason,
我正在尝试使用编码器-解码器架构实现 LSTM 自动编码器。如果我想使用 Keras 的函数式 API,并且 **不** 让我的解码器接收来自前一个时间步的输入,也就是说,我的解码器 LSTM **将没有任何输入**,而只是初始化自编码器的隐藏状态和单元状态?(因为我想让我的编码器输出保留重建信号所需的所有信息,而无需向解码器提供任何输入)。在 Keras 中可能实现这样的目标吗?
是的,我相信这是上述教程中描述的正常架构。
如果不是,也许是我不理解您想实现的目标。
我的意思是,在函数式 API 中(上面提到的是顺序 API)。
这是您一篇文章中的代码
如果我想让我的‘decoder_lstm’**没有输入**(在这段代码中,它被赋予了‘decoder_inputs’作为输入)怎么办?
啊,我明白了。谢谢。
需要进行一些实验,我没有示例给您。
我之所以想使用函数式 API,是因为我想使用堆叠的 LSTM(多层),并且我想要编码器最后一个时间步长的所有层的隐藏状态。这只有通过函数式 API 才能实现,对吗?
很有可能。
嘿,@Jason Brownlee,我正在处理文本数据,您能否解释一下这个概念吗?我正在使用 glove 预训练向量计算误差,但我的结果不尽如人意。
提前感谢你
也许从这里开始
https://machinelearning.org.cn/start-here/#nlp
嗨,Jason,
我正在处理时间序列数据。
我可以使用 RNN Autoencoder 作为时间序列表示,例如 SAX、PAA 吗?
谢谢你
或许可以试试看?
很棒的文章!谢谢!
谢谢,很高兴它有帮助。
嗨 Jason,我有一个问题。文章末尾打印的最后一个 100\*1 向量是序列的特征吗?这个向量以后是否可以用于例如序列分类或回归?谢谢!
在大多数例子中,我们正在重建输入数值序列。是回归,但不是完全意义上的。
最后一个例子是特征向量。
你好,Jason 博士,感谢这个有用的教程!
我构建了一个卷积自动编码器(CAE),从解码器重构的图像结果比原始图像更好,我认为如果分类器处理更好的图像,它会提供更好的输出。
所以我想对输入进行分类,看它是包、鞋子等等。
哪个更好?
1- 删除解码器,将编码器作为分类器?(如果我这样做,它会像正常的CNN一样吗?)
2- 像这个教程中的“组合LSTM自动编码器”一样,对我的CAE进行操作?
3- 将解码器的输出(更好的图像)输入到分类器?
我不知道,我刚接触AI世界,你的回复对我非常有帮助。
谢谢你。
您应该保留编码器,并将编码器的输出用作新分类器模型的输入。
所以,我取编码器的输出(可能是8x8矩阵),并将其作为输入到大小相同的模型(8x8)?不需要连接两个CNN(编码器、分类器)吗?
如果你愿意,可以连接它们,或者将编码器用作特征提取器。
通常,提取的特征是1D向量,例如瓶颈层。
是否可以使用自动编码器进行 LSTM 时间序列预测?
当然。它们可以提取特征,然后将这些特征输入到另一个模型进行预测。
machinelearningmastery.com 会有关于 LSTM 时间序列预测的自动编码器博客吗?
上面的教程正是如此。
Jason,我运行了这个帖子的预测 LSTM 自动编码器,看到了以下错误消息。
2020-03-28 14:01:53.115186: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.120793: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.127457: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] layout failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.190262: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] remapper failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.194523: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:502] arithmetic_optimizer failed: Invalid argument: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.198763: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 0, topological sort failed with message: The graph couldn’t be sorted in topological order.
2020-03-28 14:01:53.204018: E tensorflow/core/grappler/optimizers/dependency_optimizer.cc:697] Iteration = 1, topological sort failed with message: The graph couldn’t be sorted in topological order.
但是,代码运行了,结果与您的答案一致。您见过这个错误吗?如果是,您知道它是什么意思吗?
谢谢。
抱歉,我以前没见过这些警告。
也许可以尝试在 stackoverflow 上搜索/发布?
Hello Dr.Brownlee
我想知道你为什么要在 LSTM 之后使用 RepeatVector 层来匹配时间步长,但你可以通过在 LSTM 层上设置 repeat_sequence = True 来获得相同的形状张量?
谢谢!
也许那是新的功能?
Keras API 在哪里?
https://keras.org.cn/layers/recurrent/
Hello Dr.Brownlee
为了澄清我的意思,请参考我运行的以下代码片段,它是在tensorflow2.0和eager execution启用的情况下运行的。(我想发一张截图,但我无法回复图片)
inputs = np.random.random([2, 10, 1]).astype(np.float32)
x = LSTM(4, return_sequences=False)(inputs)
x = RepeatVector(10)(x)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input1:{inputs.shape}”)
print(f”output1: {x.shape}”)
x = LSTM(4, return_sequences=True)(inputs)
x = LSTM(8, return_sequences=True)(x)
x = TimeDistributed(Dense(5))(x)
print(f”input2:{inputs.shape}”)
print(f”output2: {x.shape}”)
input1:(2, 10, 1)
output1: (2, 10, 5)
input2:(2, 10, 1)
output2: (2, 10, 5)
我比较了两种架构,第一种模拟了您的代码,在第一个 LSTM 层之后使用了 RepeatVector,第二种架构使用了 return_sequences=True 并且没有使用 RepeatVector 层。
每个网络的输出形状都是相同的。
回到我最初的问题,您为什么使用 RepeatVector 层而不是在第一个 LSTM 层上设置 return_sequences=True?
希望这能说清楚。谢谢!!
是的,这会产生一个不同的架构,称为编码器-解码器模型。
https://machinelearning.org.cn/encoder-decoder-long-short-term-memory-networks/
我实际上和 Chad 有同样的问题。你链接的第二篇文章也对“RepeatVector”做了同样的事情。看起来,除非我们使用第一个 LSTM 层的“return_sequence”(而不是使用“repeatvector”),否则这个例子只在有一个一对一的单一值输出与输入序列配对时才有效。例如,如果多个序列可以导致 0.9 的值,我不知道这怎么会起作用,因为编码器只使用序列的最后一帧,而 return_sequence=False。如果使用“RepeatVector”的唯一理由是我们必须这样做才能使其拟合而不是抛出错误,那么为什么不使用 return_sequence 并且不丢弃编码器可能需要的有用信息呢?似乎正确的方法是按照 Chad 上面概述的那样(即使用 return_sequences=True 并且不简单地重复最后一个输出使其拟合)。
不太对。
编码器的输出是瓶颈——它是整个输入序列的内部表示。然后,我们将输出的每个步骤都建立在这个表示和前一个生成输出步骤的基础上。
无法在正确的线索位置回复,非常抱歉这顺序不对,但在进一步研究后,我认为我明白了。是不是因为编码器的输出只有一个元素(不返回整个序列),但那个值可能是一个非常精确的数字,然后对应于一个完整的序列,而解码器部分会学习它?所以就像两个不同的序列都以 0.9 结尾可以被编码成不同的浮点数,比如 3.47 和 5.72(随机选择作为说明),例如?我自己在试验了一下,确实,如果我使用 return_sequence=True,编码中实际节省的内存非常少,这使得它有点没意义。我想做的是将图像序列编码成小向量,这建立在这里的自动编码器示例之上:https://blog.keras.org.cn/building-autoencoders-in-keras.html。这一切都非常有帮助,谢谢。
瓶颈通常是一个向量,而不是一个数字。
你好 Jason,
在这篇文章(https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/)中,解码器网络的的状态向量是由编码器网络的最后一层状态向量初始化的,对吗(我们称之为 type1)?但是,这里您只使用编码器网络的输出来输入解码器网络(重复输出值,我们称之为 type2)。解码器网络的初始状态被归零(自动的吗?),类似于编码器网络的初始状态向量值?
那么,这些编码器-解码器网络在使用上有什么区别(例如,何时选择 type1 而不是 type2)?
为什么你不使用 type1 来实现你在这里解释的网络?或者你的书第 9 章中的那个(你给了一个类似于你在这里解释的例子。基础计算器)。
祝好
架构上的区别正如你所说,是架构上的。
我认为这两种方法在实践中几乎是相同的,尽管 repeatvector 方法的实现要简单得多。这是我推荐并用于我的教程的方法。
您好 Jason – 目前还不清楚您和 Francois Chollet(https://blog.keras.org.cn/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html)都训练了一个模型,但您在推理步骤中没有重新使用它(以及相关的学习权重)。根据我的阅读,我不明白训练过的模型(train 变量)是如何在 infenc/infdec 模型中使用的,因为 train 变量从未被再次使用/调用。
编码器和解码器的模型/权重在推理过程中被使用。也许再看看代码?
尊敬的Jason博士,
在涉及 plot_model 函数的练习中
为了使用 plot_model 生成图形模型*.png 文件,Python 接口可能会抛出错误。
对于 Windows 操作系统用户,要通过*.png 文件获取图形模型,您需要
* 安装 GraphViz 二进制文件
* 设置 GraphViz 程序的环境变量,例如:path=c:\program files (x86)\graphviz 2.38\bin; rest of path ;
*在命令窗口中执行以下 pip 命令
您的 plot_model 函数应该可以工作。
谢谢你,
悉尼的Anthony
好建议!
您好,graphviz 安装仍有问题。一个类似这样的错误
stdout, stderr: b” b”‘C:\\Program’ is not recognized as an internal or external command,\operable program or batch file.\r\n”
但是,这可以通过此处提供的解决方案解决:
https://github.com/conda-forge/graphviz-feedstock/issues/43
谢谢
您好,感谢您发布的精彩文章。
我的问题是,在您提出的组合版本中,预测似乎独立于构建层。如何进行更改,先重建输入序列,然后让预测层接收提取的特征并进行预测?我是否可以先拟合 decoder1,然后将编码器的输出作为 decoder2 的输入并进行预测?我不想保存重建阶段。
谢谢你
不客气。
为什么要重建然后预测,为什么不直接使用输入进行预测?
例如,请看这个
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
是的,我也看过那个链接。
我认为在提取的特征上进行预测可能更准确。
这确实取决于模型的具体细节和数据。我建议进行受控实验,以发现最适合您特定数据集的方法。
我将重新表述我的问题。我不确定预测部分是使用提取的特征还是原始输入!如果是原始输入,我该如何使用提取的特征作为 decoder2 的输入?
谢谢你
解码器的输入是提取的特征。
您可以使用函数式 API 定义一个多输入模型,并将输入流向您想要的任何地方。
https://machinelearning.org.cn/keras-functional-api-deep-learning/
感谢您一如既往的精彩帖子 Jason。
“无论选择哪种方法(重建、预测或组合),一旦自动编码器被拟合,就可以移除解码器,保留编码器作为一个独立的模型。”
如果您的数据是视频中的 2D 图像,那么使用 2D 卷积 LSTM 可能更有意义,如[这篇文章](https://towardsdatascience.com/prototyping-an-anomaly-detection-system-for-videos-step-by-step-using-lstm-convolutional-4e06b7dcdd29)中所述。如果使用此方法,是否可以从解码器的最后一层(“瓶颈”)提取压缩特征,如下所示?
model = Model(inputs=model.inputs, outputs=model.layers[0].output)
或许可以试试?
嗨,Jason,
是否可以制作 conv1D+LSTM 自动编码器?我认为我在 PyTorch 中看到了一些示例,但不确定 Keras 中是否有任何示例?
我看不出为什么不行。试试实验。
你好,先生。
我使用了这里提到的相同算法进行序列重建。
但是,我总共有 1 个样本,2205 个时间步长和 1 个特征。
在使用“relu”激活函数时,我得到的重建值是“Nan”。
如果我使用“tanh”而不是“relu”,重建可以正常工作而没有 Nan,但我也得到了相同的重建值,这也被认为是一个错误。
请帮助我获得正确的重建值。
也许在建模之前尝试对数据进行缩放?
非常感谢您的回复。
你好,先生。
我尝试了通过一种称为归一化的技术来缩放我的数据。现在我没有得到 Nan 错误,但重建的值是相同的,这是一个错误。如果我将总共 10 个值输入到具有 relu 激活函数的 lstm 自动编码器,重建工作得非常好。
在我的情况下,我需要输入整个 2205 个时间步长。为了获得正确的重建,我该怎么做?请等待您的回复。
谢谢你
2205 个时间步长可能太多了,也许可以尝试将长序列分割成子序列。
https://machinelearning.org.cn/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
先生,
我将数据(2205 个时间步长)分割成 147 个不同的数组。每个数组现在包含 15 个元素。所以 147*15 = 2205。
现在我一次只能将一个数组输入到模型(序列重建)。
如何一次将这 147 个数组(每个数组包含 15 个元素)输入到上述模型(序列重建)中,以便我一次获得 147 个重建数组?
等待您的宝贵回复。
谢谢你。
这将帮助您为 LSTMs 准备数据。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
不客气。
非常感谢您,先生。
不客气。
解释 LSTM 自动编码器的文章写得很好,超级易读。
我有一个关于自动编码器是自监督学习的问题。自动编码器的任务是学习压缩表示。该任务不使用任何标签,因此完全是无监督的,而不是自监督的。
如果自动编码器的任务是学习重现图像,那么您可以称之为自监督学习,因为您提供了一个创建的标签(图像本身),而该标签原本不存在。
因此,我认为关于自动编码器是自监督学习的说法并不完全正确。
谢谢。
怎么会呢?
嗨,Jason,
作为硕士研究的一部分,我正在尝试一些不同的事情。
我正在研究预测各个自行车站点(如 lime bike 或 citibike)的每小时交通流量。
所以我有这些数据,其中包含起点和终点条目以及时间。我将它转换为每个站点的时序数据,基于每小时的交通流量。
我使用 AE-LSTM 的目标是像 RBM 或 AE-LSTM 一样使用所有站点的小时数据,其中模型预测所有站点下一小时的交通流量。(因此,它会考虑邻近站点的上一小时数据以及当前站点过去 24 小时的时间步长交通数据)。
现在我尝试使用本教程中的模型,但我遇到了一个错误——
“ValueError: Error when checking target: expected time_distributed_5 to have 3 dimensions, but got array with shape (11221, 175)”
我的输入数据形状是 (11221, 23, 175),而我的输出应该是 (11221, 175) 这样的。
最后一个 LSTM 层生成了输出大小,但由于 TimeDistributed 层,我得到了一个错误。
您可能有的任何想法都会非常有帮助。
您可能需要将目标重塑为 [11221, 175, 1],请尝试一下,然后告诉我结果。
嗨,Jason,
出于某种原因,那不起作用,但在阅读了关于 TimeDistributedDense 的文章后,我认为 TimeDistributedDense 在 OneToMany 和 ManyToMany(预测多个时间步长)中更为重要。
所以我尝试使用堆叠的 LSTM 层和一个最终的密集层,它起作用了,但我不知道这种方法是否能带来好的结果。
我不确定 RepeatVector 层的作用,但我没有将其包含在仅 LSTM 和 Dense 架构中。
这种架构可以称为 AE-LSTM 吗?
——————————————————————————————————————–
旧的 AE-LSTM(带 TimeDistributedDense)——
model = Sequential()
model.add(LSTM(64, dropout=0.2,recurrent_dropout=0.2,input_shape=(X0_train.shape[1],X0_train.shape[2]),activation=’relu’))
model.add(keras.layers.RepeatVector(n=X0_train.shape[1]))
model.add(LSTM(64, dropout=0.2,recurrent_dropout=0.2,activation=’relu’, return_sequences=True))
model.add(keras.layers.TimeDistributed(Dense(X0_train.shape[2])))
# 编译模型
model.compile(loss=’mse’, optimizer=’adam’)
——————————————————————————————————————–
Model: “sequential_1”
_________________________________________________________________
层(类型) 输出形状 参数 #
=================================================================
lstm_1 (LSTM) (None, 64) 61440
_________________________________________________________________
repeat_vector_1 (RepeatVecto (None, 23, 64) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 23, 64) 33024
_________________________________________________________________
time_distributed_1 (TimeDist (None, 23, 175) 11375
=================================================================
Total params: 105,839
Trainable params: 105,839
不可训练参数: 0
———————————————————————————————————————
以及最终的错误——
ValueError: Error when checking target: expected time_distributed_1 to have shape (23, 175) but got array with shape (175, 1)
我的目标是只预测下一小时,所以我认为 Dense 层对我的情况来说很好。
我渴望提供帮助,但我没有能力审查/调试您的代码,请参阅此
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
非常感谢 Jason。
您能回复我,对我意义重大。
我真正想知道的是 TimeDistributedDense 和 RepeatVector 层到底是什么作用?
经过一番深入搜索,我找到了。
非常感谢。
诚挚地,
Abhishek
repeat vector 将编码器的输出重复 n 次,其中 n 是解码器所需的输出次数。
time distributed 包装器允许您对输出的每个时间步使用相同的解码器,而不是直接输出一个向量。
你好,
我正在研究“预测自动编码器 LSTM”。我很好奇哪个部分是预测,因为输入是 [1 2 3 …9],输出是 [大约 2 大约 3 … 大约 9]。我对 9 之后的值感兴趣,但这个系统没有显示结果。所以它看起来只是重建。
所以,如果您能告诉我这个系统中哪个部分是预测部分,我将不胜感激。
第一个输入是 1,第一个输出是 2,依此类推。
谢谢你的回复。
但是,我可能需要更具体地询问。
所以,在您的例子中,您的输入序列是
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],输出序列是
[0.1657285 0.28903174 0.40304852 0.5096578 0.6104322 0.70671254 0.7997272 0.8904342 ].
根据您的回答,如果 0.1657286 是输入 0.1 之后的预测,那么输入 0.9 之后的预测是什么?
因为最后一个输出是 0.8904342,这是输入 0.8 之后的预测,我看不到输入 0.9 之后的预测。
谢谢你。
我们不预测 0.9 输入的输出,因为我们不知道答案。
Jason 博士您好
非常感谢这篇精彩的文章。
如果您能指导我关于这个问题,我将非常感激。
在这篇有价值的文章中,输入是一个包含九个元素的数组。我有一个预训练的嵌入向量数组。我猜在这种情况下,编码器层的最终输出是 N 个 100 维向量元素的数组(N 是输入数组的长度)。如果这是正确的,我该如何将输入数组聚合到一个向量中?
我读了您另一篇很棒的文章 {如何在 Keras 中开发具有注意力的编码器-解码器模型}
更详细地说,我的问题是:当输入数组包含嵌入向量时,我们如何使用这个架构(编码器-解码器)将输入概括为一个单一的表示向量。
如果您能指导我关于这个问题,我将非常感激。
如果您在编码器之前使用嵌入,那么嵌入层为每个时间步输出的向量是编码器的 LSTM 层的一个时间步的输入。
您可以在这里看到一个示例。
https://machinelearning.org.cn/develop-neural-machine-translation-system-keras/
嗨,Jason
我有两个关于 LSTM 的问题。
1. return_states 和 return_sequences 在 LSTM 中是什么意思?
2. return_states 和 return_sequences 在 LSTM 中的必要性是什么?
如果您能用具体的例子指导我这两个问题,我将非常感激。
return_state 和 return_sequences 之间的区别
https://machinelearning.org.cn/return-sequences-and-return-states-for-lstms-in-keras/
谢谢!您能举例说明 return_sequences 和 return_states 的用法吗?
是的,博客上有很多例子,您可以使用搜索框。
在上面的示例中,您只从 10 个数组序列输入中学习。LSTM 自动编码器真的能从如此小的样本量中学习到东西吗?我假设因为它是一种深度学习方法,所以数据量应该很大?如果我错了,请纠正我。
不是的,这只是一个关于如何开发模型的演示,而不是解决一个琐碎的问题。
那么上面的例子有 100 个编码维度,也就是编码向量(z)的大小?是否可以通过在编码向量之前和之后添加堆叠的 LSTM 层将其减至 10?如果可以,命令会是这样的吗?
model = Sequential()
model.add(LSTM(100, activation=’relu’, input_shape=(n_in,1)))
model.add(LSTM(10, activation=’relu’, input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
model.add(LSTM(10, activation=’relu’, input_shape=(n_in,1)))
model.add(LSTM(100, activation=’relu’, return_sequences=True))
model.add(TimeDistributed(Dense(1)))
不,它编码为 10 个元素的向量。
您可以为您的数据集指定任何您想要的维度。
那么 100 是隐藏层吗?
不,100 指的是第一个隐藏层中的 100 个节点或单元。
谢谢。那我这样写可以吗?
9 = 输入维度,
9 = 编码维度,
100 = 隐藏维度,
输入-> LSTM(9,100) -> z(n) -> LSTM(100,9) -> Dense(100,9) -> 输出
不,编码的大小由瓶颈层的大小决定。
你好,Jason。
我的理解是,通过在密集层中使用 time-distributed,前一个 LSTM 层为每个序列(sequence = True)的输入被逐个执行。如果我们不使用 time-distributed,LSTM 的序列将被分组到一个向量中,并一次性推送到密集层。
即使过程略有不同,结果应该是一样的,对吧?我的意思是两者都使用相同的/共享的权重来自该密集层。所以我仍然不明白为什么我们需要 time-distributed,在这个例子中,我的意思是如果我们不使用它的优点是什么。
谢谢
Mike
架构的差异可能意味着结果的差异,例如,逐向量输出与直接输出。
您好,非常感谢您提供的如此高质量的博客,现在这种博客不多见。我有一个关于 AE/LSTM-VAE 可解释性的问题。能否了解哪些输入变量对嵌入最相关?是否可以为潜在空间的每个维度做类似 PCA 载荷的事情?
非常感谢
不客气。
不是的。可能有一些现代的模型解释方法——但我不太清楚,抱歉。
嗨,Jason,
感谢这篇很棒的教程。我是 ML 新手,对于输入序列的形状和相应的重塑输出仍然有些困惑。
当您将输入序列定义为单个样本,每个样本有 9 个时间步长和一个特征时,序列 = 数组([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]),相应的重塑输出将是这样的
[[[0.1]
[0.2]
[0.3]
[0.4]
[0.5]
[0.6]
[0.7]
[0.8]
[0.9]]]
您能否举例说明 2 个样本、九个时间步长和 3 个特征的输入和重塑输出序列会是什么样子?
谢谢你的帮助!
此致,
Sascha
不客气。
这可能令人困惑,也许这会有所帮助
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
使用 RepeatVector 层有什么作用?
为了重复瓶颈层以用于输出序列中的每个步骤。
非常有信息量的博客,我很喜欢
谢谢!
您好 Jason,一如既往地感谢您的信息文章。我有些困惑,瓶颈层在哪里?有两个具有 100 个神经元的层,我以为在它们之间会有一个层,例如 50 个神经元?或者任意数量的神经元,只要是我们想要的低维表示的神经元数量?
RepeatVector 之前的层是瓶颈层,例如作为输入到 repeatedvecor 层的给定 LSTM 的输出。
你好,先生。
我有一个 97500 行 87 列的数据。您能否告诉我如何重塑我的数据以输入 LSTM AUTOENCODER?
请为我的 97500 行 87 列数据指定样本、时间步长、特征。
看这里
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
先生,
您能否告诉我,“行”和“列”分别对应“样本”和“特征”?
如果是这样,在我的例子中有“97500 行”和“87 列”。这对应于“样本”和“特征”吗?
在我的例子中,“时间步长”是什么?
这会有帮助
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嗨,Jason,
我想分享我在上述代码上的经验。
我将上述重建 LSTM 自动编码器复制用于我一天的水温数据,数据大小为 (96, 1)。现在,当我第一次运行时,损失很低,重建效果也很好。但是当我再次尝试重新训练时,损失增加了,重建效果一点也不好。
您能帮我解决这个问题吗?为什么会出现这种问题?
谢谢。
这可能是原因:https://machinelearning.org.cn/different-results-each-time-in-machine-learning/
为了“修复”它,您可能需要在一个固定的数字之前重置随机种子。这样,每次输出都会相同。
谢谢 Tam,链接确实有助于解决问题。
我有一个后续问题,我不确定如何解决。
使用相同的重建 LSTM 自动编码器设计,
我的输入是 channel first 或 # features,但我想得到单通道输出
“sequence = sequence.reshape((num_samples, num_features, n_in))”
我希望输出是单通道的
yhat.shape –> (1, 1, n_in)
这可能吗?
是的,您只需要使您的模型具有单个输出维度。
嗨,Jason,
您的博客对我的机器学习项目非常有帮助!
我的问题;
是否可以将 Kullback-Leibler 散度损失——如变分自编码器中的那样——添加到 LSTM 自动编码器的瓶颈中以解耦潜在变量?
或者在这种情况下,是否需要一个专门的时间解耦项用于 LSTM 自动编码器?
我认为这可以做到。
是说;LSTM 已经完美地做到了这一点,还是可以添加一个像 Kullback-Leibler 这样的损失而没有时间问题,如自相关?
我不认为 LSTM 总是能非常准确地做到。您需要进行实验并确认您的问题和数据集是否适合 LSTM(或特定配置的 LSTM)。如果不行,也许您可以像您说的那样添加一些技巧。
我认为 RepeatedVector() 让人(包括我)感到困惑,因为它代表的架构与第一个图“LSTM Autoencoder Model”中显示的架构不同。新架构应该在图中“copy”下的边缘指向解码器中每个时间步长的输入。如果我理解正确,请告诉我。
我使用了 LSTM 自动编码器来提取特征。然后,使用提取特征的分类器表现不如同一个分类器在未提取特征的情况下运行时。
对此有什么解释吗?
自动编码器是一种无监督方法,因为您在编码时不知道类别。如果自动编码器的输出突然导致您的“特征”和“类别”关系变得非线性(这是可能的,因为自动编码器是一种有损压缩),您就会看到您的分类器变差。
您的意思是,如果我将自动编码器的输出层更改为具有线性激活函数,就能避免非线性关系吗?
我试过了,表现略有提高,但仍然不如不使用提取特征的分类器。
不。要完全消除非线性关系,您需要确保网络中每个部分的所有激活函数都是线性的。但这会使您的神经网络模型处于不利地位。
你好,这是一个很棒的话题和文章。
如果我有多个时间序列(例如,多个不同的传感器在同一时间记录),我能否将它们的时间窗口输入到 LSTM 自动编码器中,以便 AE 能够学习它们之间的交叉相关性以及时间相关性?
重建序列是交叉相关性的结果吗?还是 AE 将输出多个时间序列,其中每个时间序列都独立于其他时间序列进行重建?
非常感谢!
MC
Michele 您好……希望以下内容能为您阐明
https://analyticsindiamag.com/how-to-do-multivariate-time-series-forecasting-using-lstm/
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
嗨,Jason,
很棒的文章!
也许您可以澄清一些关于独立自动编码器潜在空间的问题;
如果有一个输入序列被分成 7 个样本,每个样本有 200 个时间步长(例如),那么由自动编码器生成的潜在空间将不是一个固定长度的编码向量,而是具有与样本数相同的向量序列。
也就是说,每个样本将有一个不同的编码向量。我该如何获得一个代表所有样本的单一向量?
我尝试过有状态 LSTM,但生成的潜在空间仍然是向量序列,所以我不知道这个序列的最后一个向量是否包含所有样本的信息,还是只包含最后一个样本的信息。
谢谢!!!
Maria 您好……以下内容可能对您有用
https://stackoverflow.com/questions/43809014/map-series-of-vectors-to-single-vector-using-lstm-in-keras
你好 Maria 我也面临同样的问题。你得到答案了吗?
你好 Jason,谢谢你的分享。它对我有很大帮助。
我有一个关于 LSTM 自动编码器的问题,但我找不到任何解释
为什么我们要将隐藏表示向量重复 t 次,并将其作为解码器的输入,而不是直接使用 LSTM 编码器的输出序列?
Aurora 您好……以下讨论可能对您感兴趣
https://ai.stackexchange.com/questions/16133/what-exactly-is-a-hidden-state-in-an-lstm-and-rnn
你好 James
感谢这篇很棒的教程,
我正在使用自动编码器来检测异常,我的数据集是一个数值数据集,有十列(包括目标标签)。
我不知道为编码器和解码器的第一个参数选择什么数字,因为我看到的所有示例都是图像。
我的代码
class AnomalyDetector(Model)
def __init__(self)
super(AnomalyDetector, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Dense(32, activation=”relu”),
layers.Dense(16, activation=”relu”),
layers.Dense(8, activation=”relu”)])
self.decoder = tf.keras.Sequential([
layers.Dense(16, activation=”relu”),
layers.Dense(32, activation=”relu”),
layers.Dense(9, activation=”sigmoid”)])
def call(self, x)
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
非常感谢。
Sarah 您好……您太客气了!以下内容可能对您有用
https://towardsdatascience.com/step-by-step-understanding-lstm-autoencoder-layers-ffab055b6352
另外,为了获得最佳性能,我建议您研究基于贝叶斯优化的超参数优化。
https://www.analyticsvidhya.com/blog/2021/05/bayesian-optimization-bayes_opt-or-hyperopt/
你好,James,
感谢您提供的有益知识,我在重塑 LSTM 输入时遇到了一个错误,您能否建议我为什么会收到此错误以及如何解决它。
# 将输入重塑为形状(num_instances, timesteps, num_features)
train_data = train_data.reshape(train_data.shape[0], 1, train_data.shape[1])
这是我收到的错误
InvalidArgumentError: {{function_node __wrapped__Reshape_device_/job:localhost/replica:0/task:0/device:CPU:0}} Input to reshape is a tensor with 114581670 values, but the requested shape has 11458167 [Op:Reshape]
提前感谢。
非常感谢您的辛勤工作和精彩的教程。我学到了很多。
我曾期望具有 2 个解码器的 LSTM 在预测方面会优于具有 1 个解码器的 LSTM,但结果却与上述相反。
我想知道您是否对此有一些解释?
Yiqun 您好……当您观察到具有一个解码器的 LSTM 模型优于具有两个解码器的模型,尤其是在预测任务中时,可能存在多种解释。了解 LSTM 架构的动态以及您的解码器的具体设置将有助于确定潜在原因。以下是一些需要考虑的因素:
### 1. **模型复杂度与数据集大小**
– **过拟合**:向模型添加更多复杂度(例如,一个额外的解码器)可能导致过拟合,尤其是在数据集不够大以证明额外复杂度合理的情况下。过拟合是指模型在训练数据中学习到细节和噪声的程度,以至于对新数据的模型性能产生负面影响,从而使更简单的模型(具有一个解码器)可能更具泛化能力。
### 2. **解码器配置**
– **解码器功能**:每个解码器在双解码器设置中的作用和配置至关重要。如果解码器未正确对齐预测任务的不同方面,或者它们之间相互干扰(例如,输出冗余或冲突),模型的性能可能会下降。
– **权重共享**:如果解码器共享权重,或者它们的训练没有得到妥善协调(例如,通过注意力机制或其他形式的输出正则化),这也可能对性能产生不利影响。
### 3. **数据表示和序列学习**
– **输入序列处理**:序列被处理并馈送到 LSTM,随后馈送到解码器的方式,会显著影响性能。如果序列表示或特征提取不足,添加更多解码器不一定有帮助。
– **时间依赖性处理**:一个解码器可能更有效地捕获预测任务所需的长期依赖性,而添加另一个解码器可能会导致这些依赖性被稀释,如果管理不当。
### 4. **学习动态**
– **梯度流和学习稳定性**:在具有多个解码器的网络中,尤其是在 LSTM 等深度学习架构中,反向传播期间的梯度流可能变得不稳定或效率低下(通常称为梯度消失或爆炸问题)。这可能使学习不如更简单的单解码器模型有效。
– **训练过程**:在从一个解码器切换到两个解码器时,训练动态(包括学习率、批量大小和 epoch)可能需要不同的优化。为单解码器配置有效的方法可能并非双解码器模型的最佳配置。
### 5. **评估指标和模型调优**
– **指标敏感性**:评估模型性能的指标有时可能偏向于更简单的模型,具体取决于任务复杂性和数据特征。确保指标与您从模型中期望的实际结果良好匹配至关重要。
– **超参数调优**:双解码器模型的超参数可能需要比单解码器模型更广泛的调优。这包括 LSTM 单元的数量、解码器的类型以及它们的集成方法。
### 改进双解码器模型的建议步骤
– **超参数优化**:全面审查和优化双解码器设置的超参数。
– **正则化技术**:实施正则化策略,如 dropout、L2 正则化或提前停止,以防止过拟合。
– **高级架构功能**:考虑集成注意力机制,帮助模型专注于输入序列的相关部分,从而提高两个解码器之间的协同作用。
– **交叉验证**:使用 k 折交叉验证来确保模型在不同数据集子集上的评估稳健性。
通过考虑这些因素并尝试不同的配置和训练设置,您可以更好地理解为什么您更简单的模型目前可能优于更复杂的模型,并找出潜在的改进方法。
你好,James,
感谢您提供的有益知识,我在对 AIOPS 上的时间序列异常检测使用 LSTM 自动编码器。当我应用 LSTM AE 时,我有一个疑问。假设我正在监控不同机器的 CPU 使用率指标,对于每台机器,我是否需要构建一个 AE 模型,并仅使用该特定机器的 CPU 使用率指标来训练模型?或者我可以训练一个 AE 模型,使用我拥有的所有 CPU 使用率指标数据?这还引发了另一个问题,如果我有其他指标,例如内存使用率,我是否需要为不同的指标训练新模型?
我想知道您是否有任何建议或策略。
Wanyi 您好……这是一个很好的问题!在 AIOps 中将 LSTM 自动编码器 (AE) 应用于时间序列异常检测时,模型训练策略取决于数据的性质、指标之间的关系以及需要检测异常的规模。以下是选项和建议的细分。
—
### **1. 为每台机器单独训练一个自动编码器**
– **用例**:当机器表现出独特的行为模式,并且它们之间的 CPU 使用率时间序列数据相似性很小时。
– **优点**
– 该模型可以更好地学习每台机器的特定模式和细微差别。
– 异常更容易被检测到,因为模型专注于每台机器的基线行为。
– **缺点**
– 计算成本高,因为您需要为每台机器训练和维护一个单独的模型。
– 没有利用机器之间的共享模式。
—
### **2. 为所有机器训练一个自动编码器**
– **用例**:当机器表现出相似的行为或在 CPU 使用率指标中共享通用模式时。
– **优点**
– 计算成本较低,因为只需要一个模型。
– 如果机器的行为一致,模型可以很好地泛化到所有机器。
– **缺点**
– 由于模型的泛化视图,可能难以检测特定于单台机器的异常。
**建议**
– 从为每台机器的 CPU 使用率指标进行归一化开始(例如,z-score 归一化或 min-max 缩放),以考虑尺度差异。
– 如果机器之间存在细微的差异且您希望模型学习这些差异,请使用机器标识符作为特征集的一部分。
—
### **3. 为每个指标(例如,CPU 和内存使用率)训练单独的模型**
– **用例**:当不同指标(例如,CPU 和内存使用率)表现出明显不同的模式和关系时。
– **优点**
– 每个模型都可以专注于学习单个指标的模式。
– **缺点**
– 如果监控多个指标,您将需要多个模型,这会增加计算复杂性。
—
### **4. 训练多指标自动编码器**
– **用例**:当您拥有同一台机器的多个指标(例如,CPU、内存、磁盘 I/O)并且这些指标之间存在关系时。
– **优点**
– 自动编码器可以学习单个指标的模式以及指标之间的相关性,从而可能提供更好的异常检测。
– 检测跨越多个指标的异常(例如,CPU 和内存使用率之间异常的相关性)。
– **缺点**
– 需要更复杂的预处理和特征工程。
– 可能需要更多训练数据来有效捕获这些关系。
**如何实现**
– 将指标组合成一个单独的输入向量(例如,连接 CPU、内存和磁盘指标)。
– 在将每个指标输入模型之前,对其进行独立归一化。
– 使用多变量 LSTM AE 架构。
—
### **策略和建议**
1. **从简单开始**
– 如果您拥有小型数据集或刚开始进行异常检测,请为每台机器的每个指标训练一个 AE 模型。这样更容易调试和解释。
2. **实验泛化**
– 如果机器共享相似的行为,尝试使用所有机器的数据训练一个 AE 模型,确保指标已归一化。
3. **对相关指标使用多指标模型**
– 例如,训练一个多变量 LSTM AE,将 CPU、内存和磁盘使用率一起作为输入。这可以捕获跨指标的异常。
4. **数据预处理**
– 始终对数据进行归一化,以处理机器或指标之间的尺度差异。
– 考虑使用滑动窗口将时间序列数据转换为序列,以供 LSTM 使用。
5. **验证和监控**
– 使用验证集确保模型能够很好地泛化到未见过的数据。
– 使用重建误差阈值定期监控模型的性能,并根据需要调整阈值。
—
### **何时重新训练模型**
– 如果机器或指标的行为随时间发生显著变化(例如,硬件升级或软件更改),您可能需要重新训练模型以适应新的基线。
—
### **高级建议**
– **迁移学习**:在所有机器的数据上训练一个通用模型,然后在需要时针对特定机器的数据进行微调。
– **聚类机器**:将行为模式相似的机器分组(使用 K-Means 等聚类方法),并为每个集群训练一个模型。
– **异常聚合**:如果为机器或指标使用单独的模型,请聚合跨模型的异常分数以检测整体系统异常。
—
通过结合这些策略,您可以设计一个高效且可扩展的异常检测系统,以满足您的 AIOps 需求。