长短期记忆(LSTM)是一种可用于神经网络的结构。它是一种循环神经网络(RNN),它期望以特征序列的形式输入。它适用于时间序列或文本字符串等数据。在这篇文章中,您将了解 LSTM 网络。特别是,
- 什么是 LSTM 以及它们有何不同
- 如何开发用于时间序列预测的 LSTM 网络
- 如何训练 LSTM 网络
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

在 PyTorch 中使用 LSTM 进行时间序列预测
照片由 Carry Kung 提供。保留部分权利。
概述
这篇博文分为三部分;它们是:
- LSTM 网络概述
- 用于时间序列预测的 LSTM
- 训练和验证您的 LSTM 网络
LSTM 网络概述
LSTM 单元是可用于构建更大神经网络的基本模块。虽然常见的构建模块(如全连接层)只是权重张量和输入之间的矩阵乘法以产生输出张量,但 LSTM 模块要复杂得多。
典型的 LSTM 单元如下图所示
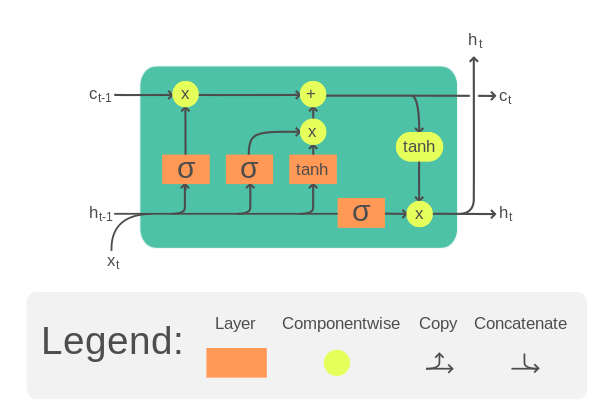
LSTM 单元。插图来自维基百科。
它接受输入张量 $x$ 的一个时间步长以及单元记忆 $c$ 和隐藏状态 $h$。单元记忆和隐藏状态可以在开始时初始化为零。然后,在 LSTM 单元内,$x$、$c$ 和 $h$ 将与单独的权重张量相乘,并多次通过一些激活函数。结果是更新的单元记忆和隐藏状态。这些更新的 $c$ 和 $h$ 将用于输入张量的**下一个时间步长**。直到最后一个时间步长结束,LSTM 单元的输出将是其单元记忆和隐藏状态。
具体来说,一个 LSTM 单元的方程如下
$$
\begin{aligned}
f_t &= \sigma_g(W_{f} x_t + U_{f} h_{t-1} + b_f) \\
i_t &= \sigma_g(W_{i} x_t + U_{i} h_{t-1} + b_i) \\
o_t &= \sigma_g(W_{o} x_t + U_{o} h_{t-1} + b_o) \\
\tilde{c}_t &= \sigma_c(W_{c} x_t + U_{c} h_{t-1} + b_c) \\
c_t &= f_t \odot c_{t-1} + i_t \odot \tilde{c}_t \\
h_t &= o_t \odot \sigma_h(c_t)
\end{aligned}
$$
其中 $W$、$U$、$b$ 是 LSTM 单元的可训练参数。上面每个方程都在每个时间步长计算,因此带有下标 $t$。这些可训练参数**在所有时间步长中重复使用**。这种共享参数的特性为 LSTM 带来了记忆能力。
请注意,上述内容仅是 LSTM 的一种设计。文献中有多种变体。
由于 LSTM 单元期望输入 $x$ 的形式是多个时间步长,因此每个输入样本都应该是一个二维张量:一个维度用于时间,另一个维度用于特征。LSTM 单元的功率取决于隐藏状态或单元记忆的大小,其维度通常大于输入中特征的数量。
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
用于时间序列预测的 LSTM
让我们通过一个示例来看看如何使用 LSTM 构建时间序列预测神经网络。
您将在本文中探讨的问题是国际航空乘客预测问题。这是一个给定年份和月份,任务是预测国际航空乘客数量(以千为单位)的问题。数据范围从 1949 年 1 月到 1960 年 12 月,共 12 年,有 144 个观测值。
这是一个回归问题。也就是说,给定最近几个月的乘客数量(以千为单位),预测下一个月的乘客数量。数据集只有一个特征:乘客数量。
让我们从读取数据开始。数据可以在此处下载。
将此文件保存为本地目录中的 `airline-passengers.csv`,以备后续使用。
以下是文件前几行的示例
|
1 2 3 4 5 |
"月份","乘客数" "1949-01",112 "1949-02",118 "1949-03",132 "1949-04",129 |
数据有两列,月份和乘客数量。由于数据按时间顺序排列,您可以只取乘客数量来生成一个单特征时间序列。下面您将使用 pandas 库读取 CSV 文件并将其转换为二维 numpy 数组,然后使用 matplotlib 绘制它。
|
1 2 3 4 5 6 7 8 |
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('airline-passengers.csv') timeseries = df[["Passengers"]].values.astype('float32') plt.plot(timeseries) plt.show() |

此时间序列有 144 个时间步。从图中可以看出,存在上升趋势。数据集中也存在一些周期性,对应于北半球的暑假期间。通常,时间序列在处理之前应该“去趋势”以去除线性趋势分量并进行归一化。为简单起见,本项目中跳过了这些步骤。
为了展示我们模型的预测能力,时间序列被分成训练集和测试集。与其他数据集不同,时间序列数据通常不进行洗牌而分割。也就是说,训练集是时间序列的前半部分,其余部分将用作测试集。这可以在 numpy 数组上轻松完成。
|
1 2 3 4 |
# 时间序列的训练-测试拆分 train_size = int(len(timeseries) * 0.67) test_size = len(timeseries) - train_size train, test = timeseries[:train_size], timeseries[train_size:] |
更复杂的问题是您希望网络如何预测时间序列。通常时间序列预测是在一个窗口上完成的。也就是说,给定从时间 $t-w$ 到时间 $t$ 的数据,您需要预测时间 $t+1$(或更远的未来)。窗口大小 $w$ 决定了您在进行预测时可以查看多少数据。这也被称为**回溯期**。
在一个足够长的时间序列上,可以创建多个重叠窗口。从时间序列生成固定窗口数据集很方便。由于数据将在 PyTorch 模型中使用,因此输出数据集应采用 PyTorch 张量格式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import torch def create_dataset(dataset, lookback): """将时间序列转换为预测数据集 参数 数据集:一个 numpy 数组的时间序列,第一维是时间步长 回溯:预测窗口的大小 """ X, y = [], [] for i in range(len(dataset)-lookback): feature = dataset[i:i+lookback] target = dataset[i+1:i+lookback+1] X.append(feature) y.append(target) return torch.tensor(X), torch.tensor(y) |
此函数旨在将窗口应用于时间序列。它假定预测紧邻未来一个时间步长。它旨在将时间序列转换为维度为(窗口样本,时间步长,特征)的张量。一个具有 $L$ 个时间步长的时间序列可以生成大约 $L$ 个窗口(因为只要窗口不超过时间序列的边界,它就可以从任何时间步长开始)。在一个窗口内,有多个连续的时间步长值。在每个时间步长中,可以有多个特征。在此数据集中,只有一个。
有意将“特征”和“目标”生成为相同的形状:对于三个时间步长的窗口,“特征”是从 $t$ 到 $t+2$ 的时间序列,目标是从 $t+1$ 到 $t+3$。我们感兴趣的是 $t+3$,但 $t+1$ 到 $t+2$ 的信息在训练中很有用。
请注意,输入时间序列是一个二维数组,而 `create_dataset()` 函数的输出将是三维张量。让我们尝试 `lookback=1`。您可以如下验证输出张量的形状。
|
1 2 3 4 5 |
lookback = 1 X_train, y_train = create_dataset(train, lookback=lookback) X_test, y_test = create_dataset(test, lookback=lookback) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) |
您应该会看到
|
1 2 |
torch.Size([95, 1, 1]) torch.Size([95, 1, 1]) torch.Size([47, 1, 1]) torch.Size([47, 1, 1]) |
现在,您可以构建 LSTM 模型来预测时间序列。当 `lookback=1` 时,由于线索过少,预测准确性肯定不会很好。但这提供了一个很好的例子来演示 LSTM 模型的结构。
该模型被创建为一个类,其中使用了 LSTM 层和全连接层。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... import torch.nn as nn class AirModel(nn.Module): def __init__(self): super().__init__() self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True) self.linear = nn.Linear(50,1) def forward(self, x): x, _ = self.lstm(x) x = self.linear(x) return x |
nn.LSTM() 的输出是一个元组。第一个元素是生成的隐藏状态,输入中的每个时间步长对应一个。第二个元素是 LSTM 单元的内存和隐藏状态,此处未使用。
LSTM 层是使用选项 `batch_first=True` 创建的,因为您准备的张量的维度为(窗口样本、时间步长、特征),并且通过对第一个维度进行采样来创建批次。
隐藏状态的输出通过一个全连接层进一步处理,以产生一个单一的回归结果。由于 LSTM 的输出是每个输入时间步长一个,您可以选择只选取最后一个时间步长的输出,您应该有
|
1 2 3 4 |
x, _ = self.lstm(x) # 仅提取最后一个时间步 x = x[:, -1, :] x = self.linear(x) |
模型的输出将是下一个时间步长的预测。但在这里,全连接层应用于每个时间步长。在这种设计中,您应该只从模型输出中提取最后一个时间步长作为您的预测。但是,在这种情况下,窗口为 1,这两种方法没有区别。
训练和验证您的 LSTM 网络
由于这是一个回归问题,选择 MSE 作为损失函数,并使用 Adam 优化器进行最小化。在下面的代码中,PyTorch 张量使用 `torch.utils.data.TensorDataset()` 组合成一个数据集,并通过 `DataLoader` 提供用于训练的批次。模型性能每 100 个 epoch 在训练集和测试集上评估一次。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import numpy as np import torch.optim as optim import torch.utils.data as data model = AirModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X_train, y_train), shuffle=True, batch_size=8) n_epochs = 2000 for epoch in range(n_epochs): model.train() for X_batch, y_batch in loader: y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() # 验证 if epoch % 100 != 0: continue model.eval() with torch.no_grad(): y_pred = model(X_train) train_rmse = np.sqrt(loss_fn(y_pred, y_train)) y_pred = model(X_test) test_rmse = np.sqrt(loss_fn(y_pred, y_test)) print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse)) |
由于数据集较小,模型应该训练足够长的时间才能学习到模式。在训练的 2000 个 epoch 中,您应该会看到训练集和测试集上的 RMSE 都在下降。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
第 0 纪元:训练 RMSE 225.7571,测试 RMSE 422.1521 第 100 纪元:训练 RMSE 186.7353,测试 RMSE 381.3285 第 200 纪元:训练 RMSE 153.3157,测试 RMSE 345.3290 第 300 纪元:训练 RMSE 124.7137,测试 RMSE 312.8820 第 400 纪元:训练 RMSE 101.3789,测试 RMSE 283.7040 第 500 纪元:训练 RMSE 83.0900,测试 RMSE 257.5325 第 600 纪元:训练 RMSE 66.6143,测试 RMSE 232.3288 第 700 纪元:训练 RMSE 53.8428,测试 RMSE 209.1579 第 800 纪元:训练 RMSE 44.4156,测试 RMSE 188.3802 第 900 纪元:训练 RMSE 37.1839,测试 RMSE 170.3186 第 1000 纪元:训练 RMSE 32.0921,测试 RMSE 154.4092 第 1100 纪元:训练 RMSE 29.0402,测试 RMSE 141.6920 第 1200 纪元:训练 RMSE 26.9721,测试 RMSE 131.0108 第 1300 纪元:训练 RMSE 25.7398,测试 RMSE 123.2518 第 1400 纪元:训练 RMSE 24.8011,测试 RMSE 116.7029 第 1500 纪元:训练 RMSE 24.7705,测试 RMSE 112.1551 第 1600 纪元:训练 RMSE 24.4654,测试 RMSE 108.1879 第 1700 纪元:训练 RMSE 25.1378,测试 RMSE 105.8224 第 1800 纪元:训练 RMSE 24.1940,测试 RMSE 101.4219 第 1900 纪元:训练 RMSE 23.4605,测试 RMSE 100.1780 |
预期测试集的 RMSE 会大一个数量级。RMSE 为 100 意味着预测值和实际目标值平均相差 100(即,在此数据集中为 100,000 名乘客)。
为了更好地理解预测质量,您可以使用 matplotlib 绘制输出,如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
with torch.no_grad(): # 移动训练预测用于绘图 train_plot = np.ones_like(timeseries) * np.nan y_pred = model(X_train) y_pred = y_pred[:, -1, :] train_plot[lookback:train_size] = model(X_train)[:, -1, :] # 移动测试预测用于绘图 test_plot = np.ones_like(timeseries) * np.nan test_plot[train_size+lookback:len(timeseries)] = model(X_test)[:, -1, :] # 绘图 plt.plot(timeseries, c='b') plt.plot(train_plot, c='r') plt.plot(test_plot, c='g') plt.show() |

从上面可以看出,您将模型的输出作为 `y_pred`,但仅提取最后一个时间步的数据作为 `y_pred[:, -1, :]`。这就是图表中绘制的内容。
训练集用红色绘制,测试集用绿色绘制。蓝色曲线是实际数据的样子。您可以看到模型可以很好地拟合训练集,但在测试集上表现不佳。
总而言之,下面是完整的代码,除了参数 `lookback` 这次设置为 4
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
import matplotlib.pyplot as plt import numpy as np import pandas as pd import torch import torch.nn as nn import torch.optim as optim import torch.utils.data as data df = pd.read_csv('airline-passengers.csv') timeseries = df[["Passengers"]].values.astype('float32') # 时间序列的训练-测试拆分 train_size = int(len(timeseries) * 0.67) test_size = len(timeseries) - train_size train, test = timeseries[:train_size], timeseries[train_size:] def create_dataset(dataset, lookback): """将时间序列转换为预测数据集 参数 数据集:一个 numpy 数组的时间序列,第一维是时间步长 回溯:预测窗口的大小 """ X, y = [], [] for i in range(len(dataset)-lookback): feature = dataset[i:i+lookback] target = dataset[i+1:i+lookback+1] X.append(feature) y.append(target) return torch.tensor(X), torch.tensor(y) lookback = 4 X_train, y_train = create_dataset(train, lookback=lookback) X_test, y_test = create_dataset(test, lookback=lookback) class AirModel(nn.Module): def __init__(self): super().__init__() self.lstm = nn.LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True) self.linear = nn.Linear(50,1) def forward(self, x): x, _ = self.lstm(x) x = self.linear(x) return x model = AirModel() optimizer = optim.Adam(model.parameters()) loss_fn = nn.MSELoss() loader = data.DataLoader(data.TensorDataset(X_train, y_train), shuffle=True, batch_size=8) n_epochs = 2000 for epoch in range(n_epochs): model.train() for X_batch, y_batch in loader: y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() # 验证 if epoch % 100 != 0: continue model.eval() with torch.no_grad(): y_pred = model(X_train) train_rmse = np.sqrt(loss_fn(y_pred, y_train)) y_pred = model(X_test) test_rmse = np.sqrt(loss_fn(y_pred, y_test)) print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse)) with torch.no_grad(): # 移动训练预测用于绘图 train_plot = np.ones_like(timeseries) * np.nan y_pred = model(X_train) y_pred = y_pred[:, -1, :] train_plot[lookback:train_size] = model(X_train)[:, -1, :] # 移动测试预测用于绘图 test_plot = np.ones_like(timeseries) * np.nan test_plot[train_size+lookback:len(timeseries)] = model(X_test)[:, -1, :] # 绘图 plt.plot(timeseries) plt.plot(train_plot, c='r') plt.plot(test_plot, c='g') plt.show() |

运行上述代码将生成以下图。从打印的 RMSE 度量和图中,您会注意到模型现在在测试集上的表现更好。
这也是 `create_dataset()` 函数如此设计的原因:当模型给定时间 $t$ 到 $t+3$ 的时间序列(如 `lookback=4`)时,其输出是 $t+1$ 到 $t+4$ 的预测。然而,$t+1$ 到 $t+3$ 的信息也已知自输入。通过在损失函数中使用这些信息,模型实际上获得了更多训练线索。这种设计并非总是适用,但您可以看到它在这个特定示例中很有帮助。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
总结
在这篇文章中,您了解了什么是 LSTM 以及如何在 PyTorch 中使用它进行时间序列预测。具体来说,您学习了
- 什么是国际航空旅客时间序列预测数据集
- 什么是 LSTM 单元
- 如何创建用于时间序列预测的 LSTM 网络
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...





请原谅我,一定有错误。
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
torch.Size([95, 1]) torch.Size([95, 1])
torch.Size([47, 1]) torch.Size([47, 1])
您好 Eliasnemo...您指的是什么错误?
詹姆斯您好,很抱歉我评论得太仓促了,是我的错误,我的时间序列形状是 (432,),而您的是 (432,1),这在 create_dataset(dataset, lookback) 函数中生成了不正确的张量形状:torch.Size([95, 1]) torch.Size([95, 1]) torch.Size([47, 1]) torch.Size([47, 1]),而不是您示例中的正确形状:torch.Size([95, 1, 1]) torch.Size([95, 1, 1]) torch.Size([47, 1, 1]) torch.Size([47, 1, 1])。
我只是在 `return torch.tensor(X), torch.tensor(y)` 之前添加了 `X=np.array(X)` 和 `y np.array(y)`,以避免出现“UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow…”的消息。感谢您分享您的出色工作。
您好,这篇帖子内容丰富!在第 65-68 行,应该是 X_batch 和 y_batch 而不是 X_train 和 y_train 吗?
您好 tqrahman...我没有看到错误。您将代码更改为所建议的内容后,结果如何?
交易机器人信号
谢谢机器人!本论坛没有机器人!
而且你拼写是 "signals" 🙂
你有没有预测接下来 x 天图表的例子
访客您好…请澄清您的问题,以便我们更好地协助您。
詹姆斯您好,我想知道,如果我们使用“create_dataset”函数创建训练窗口,在训练模型并使用它进行预测后,我们将需要转换我们的新数据集并具有相同的形状进行预测,因此,我们将无法预测最后“N个回溯”实例,因为该函数只获取“len(dataset)-lookback”的窗口。总之,我们无法预测整个数据集的值,如果我使用lookback=3,我将无法获得最后3个实例的预测。
Sobiedd 您好...我不太确定您的问题。您是否进行了预测并注意到教程中建议的方法存在问题?也许我们可以从您的结果开始,然后确定实施中是否存在遗漏之处。
你好 Jason!感谢你的这篇博客,它非常有帮助。我打算使用 LSTM 网络进行预测。我的数据集是一个包含多个变量(图像特征、帖子发布日期、标签、位置信息等)的社交媒体数据集。这个数据集具有时间特征,所以我可以将每个帖子与输出进行绘制,x 轴为月-年(时间尺度),y 轴为输出。
我已完成特征工程,现在我想训练一个 LSTM 模型来预测输出。但由于 NN/LSTM 模型需要对数据进行归一化,我正在考虑——
1.) 是否要归一化/缩放数据,
2.) 我应该考虑每个样本的每个特征进行归一化吗?还是应该按特征进行归一化(按标签_长度特征/列进行归一化)?
我需要您尽快提出建议,因为我正在赶一个截止日期。任何帮助都将不胜感激。期待您的建议。谢谢!
嗨 James,
也许我错了,但看起来您在测试阶段使用了教师强制。模型似乎不是自回归的。我想看到 LSTM 使用其自己的预测来生成新预测的结果。
Angelo 您好...以下示例可能有助于澄清
https://machinelearning.org.cn/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
嗨 James,
如果我必须预测几个连续的未来时间序列值,我该怎么做?例如,如果我有预测变量和目标直到现在(t=0),我如何预测 t+1、t+2 和 t+3 时的目标?换句话说,如果我每小时都有预测变量和目标(作为历史数据),我如何预测未来三小时的目标值?我如何准备数据集并更新我的模型(例如,LSTM)?
谢谢你。
嗨 James,
我只是检查一下——在您提取最后一步的代码片段中,我们是不是在“-1”后面少了一个冒号?
像这样
x = x[:, -1:, :]
Tom 您好...我们没有发现原始代码有任何问题。您执行后发现了什么?
考虑到输入的时序性质,您为什么在 DataLoader 中设置 shuffle=true?
Myk 您好...以下资源可能会让您感兴趣
https://machinelearning.org.cn/training-a-pytorch-model-with-dataloader-and-dataset/#:~:text=The%20batch%20size%20is%20a,to%20read%20every%20batch%20once.
样本可以打乱,因为每个样本都是独立的。也就是说,一个给定的样本捕获了整个输入序列;因此,即使样本被打乱,序列信息也会保留下来。
在您的“完整代码”中,上面第 74-75 行是多余的,因为第 76 行做了同样的事情。
y_pred = model(X_train)
y_pred = y_pred[:, -1, :]
train_plot[lookback:train_size] = model(X_train)[:, -1, :]
训练和测试图中的两个图都似乎发生了偏移。这是为什么?以及如何解决?
你正在处理时间序列预测问题,并且你将预测的时间序列与实际时间序列进行绘图,结果看起来预测滞后于实际一步。
这很常见。
这意味着你的模型正在进行持久性预测。这是一种预测,其中预测的输入(例如前一个时间步的观测值)被预测为输出。
持久性预测被用作时间序列预测的基线方法进行比较。你可以在这里了解更多关于该方法的信息
如何使用 Python 为时间序列预测制作基线预测
持久性预测是我们能在具有挑战性的时间序列预测问题上做到的最好的事情,例如那些随机游走的时间序列,像股票价格的短期波动。你可以在这里了解更多关于这方面的信息
使用 Python 进行时间序列预测的随机游走简介
如果你复杂的模型,例如神经网络,正在输出持久性预测,这可能意味着
模型需要进一步调整。
所选模型无法解决你的特定数据集。
这可能还意味着你的时间序列问题是不可预测的。
你好,
所有这些教程都涉及预测训练和测试,但是您能做一个实际预测超出数据集的教程吗,例如预测未来 3 个月。
Saranga 您好...以下资源可能对您有用
https://stackoverflow.com/questions/69906416/forecast-future-values-with-lstm-in-python
LSTM 适用于时间序列分类吗?
看着您上面的最终图表,经过训练的模型似乎仍然只进行持久性预测,因为它几乎是数据集的精确偏移版本。这是否反映了这种回溯方法在实现上的问题,还是反映了数据集中有用特征的缺乏?您将如何从这里继续使其更准确?
迈克尔您好……您正在处理一个时间序列预测问题,您将预测的时间序列与实际时间序列进行绘制,结果看起来预测比实际滞后一个步骤。
这很常见。
这意味着你的模型正在进行持久性预测。这是一种预测,其中预测的输入(例如前一个时间步的观测值)被预测为输出。
持久性预测被用作时间序列预测的基线方法进行比较。你可以在这里了解更多关于该方法的信息
如何使用 Python 为时间序列预测制作基线预测
持久性预测是我们能在具有挑战性的时间序列预测问题上做到的最好的事情,例如那些随机游走的时间序列,像股票价格的短期波动。你可以在这里了解更多关于这方面的信息
使用 Python 进行时间序列预测的随机游走简介
如果你复杂的模型,例如神经网络,正在输出持久性预测,这可能意味着
模型需要进一步调整。
所选模型无法解决你的特定数据集。
这可能还意味着你的时间序列问题是不可预测的。
我稍微修改了您的代码,我注意到,如果我调整设置,通过增加回溯或网络大小来消除训练集上的持久性偏移,我最终会过度拟合,并在测试集上获得更差的性能,所以我的印象是,在这种回溯 LSTM 堆叠的情况下,这是一个艰难的权衡。我阅读了其他材料,它很有帮助,但没有向我展示如何摆脱这种过拟合或持久性的权衡。
我有一些问题
1 – Pytorch 中的“hidden_size”与 Tensorflow/Keras 中的“units”是同一个参数吗?
2 – 如果是,它们在本帖子的第一张图中实际代表什么?例如,如果我们的“hidden_size = X”,我们有 X 个 LSTM 单元吗?或者当我们定义“nn.LSTM(input_size=1, hidden_size=X, num_layers=1, batch_first=True)”时,无论 X 的值是多少,我们都只有一个单元吗?
3 – 它们如何连接到线性/密集层?每个单元都连接到线性层中的每个节点吗?还是只有最后一个单元连接到每个节点?
下一行是否正确?
target = dataset[i+1:i+lookback+1]
因为我们想要将下一个直接输出作为目标,所以它应该是
target = dataset[i+lookback:i+lookback+1]
亚历山大您好...这应该是正确的。您执行过代码吗?如果执行了,您发现了什么?
你好。我有一个问题想确认我的观察结果。训练和测试拆分的数据记录数量是否根据回溯次数减少了?例如,在我的情况下,原始训练拆分有 699 条记录,在应用 create_dataset() 函数后变为 698 条。我的测试也发生了同样的情况,从 48 条变为 47 条。
训练和测试预测也应用了相同的长度。我还有一个关于显示绘图的问题。由于训练和测试预测的数量与原始训练和测试拆分中的记录数量不同,我应该如何将其与 x 轴作为日期时间戳进行绘制?
你好 J...根据你的描述,你似乎观察到了时间序列数据准备中的一个常见行为,即使用像 `create_dataset()` 这样的函数,该函数通常用于将时间序列数据集重新格式化为适合 LSTM 模型的格式,通过创建回溯序列。让我们澄清并回答你问题的两个部分。
### 因回溯导致记录减少
由于回溯处理的性质,您的原始数据集中记录数量减少到应用 `create_dataset()` 函数后的数量确实是预期的。其工作原理如下:
– **回溯逻辑**:如果您正在使用回溯期(也称为滞后、窗口大小或序列长度),该函数需要创建相同数量的过去观测序列来预测当前值。例如,如果回溯期为 1,则您的模型的每个输入序列将包含一个先前的时间步长来预测当前时间步长。
– **对数据大小的影响**:这意味着数据集中的前几条记录(与回溯期完全相同)将没有足够的先前数据点来形成一个完整的序列。因此,这些记录通常会从训练或测试数据集中删除。对于回溯期为 1,您将在开头丢失 1 个数据点,这与您观察到的结果相符:699 条记录变为 698 条,48 条变为 47 条。
### 绘制长度不匹配的数据
关于绘制训练和测试预测以及带有时间戳作为 x 轴的原始数据,考虑到由于回溯而导致的长度不匹配,您可以通过调整预测的索引来处理。您可以这样做:
1. **偏移调整**:由于每个预测对应于输入序列结束时的输出,因此您应该从与回溯期等效的索引开始绘制预测。例如,如果您的回溯期为 1,则您的预测应从原始数据集中的第二条记录开始。
2. **代码示例**:假设您的包含原始时间序列的 DataFrame 是 `df`,并且它包含一个日期时间列 `date`。以下是使用 Python 和 matplotlib 的基本绘图方法:
```python
import matplotlib.pyplot as plt
# 示例数据
dates = df['date'] # 假设 'date' 是您的日期时间列
original_train = df['value'][:698] # 假设 'value' 是您要预测的值
original_test = df['value'][698:]
# 假设 train_predictions 和 test_predictions 是您的模型输出
train_predictions = [None] + list(train_predictions) # 用于对齐的偏移量
test_predictions = [None] * 699 + list(test_predictions) # 用于对齐的偏移量
plt.figure(figsize=(15, 8))
plt.plot(dates, df['value'], label='原始数据')
plt.plot(dates, train_predictions, label='训练预测')
plt.plot(dates, test_predictions, label='测试预测')
plt.legend()
plt.title('时间序列预测')
plt.xlabel('日期')
plt.ylabel('值')
plt.show()
```
**绘图代码中的关键点:**
– **按索引对齐**:`None` 值被添加到预测列表中,以使预测与原始数据索引正确对齐。根据您的确切回溯以及您的拆分结构调整 `None` 值的数量。
– **一起绘图**:此脚本将原始数据与调整后的预测一起绘制在同一张图上,以便进行视觉比较。
此方法将帮助您直观地比较模型预测与实际值的匹配程度,同时考虑日期时间序列。根据需要调整绘图细节,以适应您的具体设置和可视化需求。
如果我们在第一个单元格中添加一行记录时间序列的代码
timeseries = np.log(timeseries)
我们会得到一个几乎完美的拟合测试集。
Half Dome 您好...感谢您的反馈和建议!
您好,我有一个问题,标准的 LSTM 是否包含教师强制?您的代码中是否考虑了教师强制?
Jack 您好...标准 LSTM(长短期记忆)架构本身并不包含教师强制。教师强制是一种训练技术,常用于序列到序列模型,特别是在语言翻译等任务中,其中模型在前一个时间步的输出作为下一个时间步的输入进行训练。
### **理解教师强制**
– **教师强制**:在训练期间,不是使用模型在前一个时间步的预测输出作为下一个时间步的输入,而是使用实际的真实值(正确的先前输出)。这有助于模型更快地学习并提高训练期间的稳定性,尤其是在早期阶段。
### **实现教师强制**
如果您想在代码中使用 LSTM 进行教师强制,则需要手动实现。以下是在 PyTorch 中使用基于 LSTM 的模型实现教师强制的简单方法。
```python
import torch
import torch.nn as nn
class LSTMModel(nn.Module)
def __init__(self, input_size, hidden_size, output_size, num_layers=1)
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input_seq, target_seq=None, teacher_forcing_ratio=0.5)
# input_seq: 形状 (seq_len, batch_size, input_size)
# target_seq: 形状 (seq_len, batch_size, output_size)
outputs = []
hidden, cell = None, None
# 遍历序列
for t in range(input_seq.size(0))
if t == 0 or target_seq is None or torch.rand(1).item() > teacher_forcing_ratio
input_t = input_seq[t].unsqueeze(0) # 使用预测值
else
input_t = target_seq[t-1].unsqueeze(0) # 使用实际目标
output, (hidden, cell) = self.lstm(input_t, (hidden, cell) if hidden is not None else None)
output = self.fc(output)
outputs.append(output)
outputs = torch.cat(outputs, dim=0) # 沿时间维度连接输出
return outputs
# 示例用法:
# lstm_model = LSTMModel(input_size, hidden_size, output_size)
# output = lstm_model(input_seq, target_seq, teacher_forcing_ratio=0.5)
```
### **关键点**
– **教师强制比率**:您可以使用 `teacher_forcing_ratio` 控制教师强制的应用频率。比率为 1.0 表示始终使用真实的先前输出,而 0.0 表示从不使用(仅使用模型的预测)。
– **灵活性**:这种方法让您可以灵活地尝试使用或不使用教师强制,以查看哪种方法最适合您的特定任务。
非常感谢您提供这个有用的教程。我对绘图部分有一些疑问。
我明白我们只使用每个窗口的最后一个值的预测。然而,在绘图部分,为什么预测值是连续放置的,而不是以回溯步长间隔放置。
Prommin 您好...在基于 LSTM 的时间序列预测中,虽然您使用特定的窗口大小(或回溯)进行预测,但图表中预测的连续放置很可能是由于模型评估方式和结果绘图方式造成的。
原因如下:
1. **滑动窗口预测**
在使用滑动窗口进行训练和预测时,LSTM 模型会获取一系列过去的数据点(回溯窗口),并预测下一个值。进行此预测后,窗口会移动一个时间步,然后使用下一个序列来预测后续值。此过程持续进行,导致在每个时间步都进行预测,即使每个预测都基于先前的滑动窗口。
2. **连续绘制预测**
在绘图期间,由于模型在每个时间步都进行预测,因此这些预测值通常是连续绘制的,即使每个预测都对应于一个窗口的末尾。这在图中呈现出一条连续的线,因为您本质上是在每个滑动窗口上预测一个时间步。
3. **回溯间隔与预测**
如果您只按与回溯窗口对应的间隔绘制预测(例如,只在每个回溯窗口结束时),那么您每隔几个步骤才会有预测(取决于您的回溯大小)。然而,这将使预测图稀疏,并且您将看不到平滑的预测曲线。在许多情况下,连续绘图可以更好地视觉呈现模型在所有时间步上的表现。
### 根据回溯调整绘图
如果您只想绘制以特定间隔进行的预测(例如,只在每个回溯窗口结束时),您可以修改您的绘图代码以仅显示这些点。这将涉及跟踪进行预测的索引并仅绘制这些点。
总之,图中预测的连续放置是由于模型在每个时间步进行一步预测,这就是为什么预测是连续绘制而没有间隙。如果您希望预测以回溯步长间隔绘制,则需要手动调整绘图逻辑。
你好 James
我有一个关于训练设备的小问题,如何将其加载到 GPU 而不是 CPU 上?
谢谢你
你好,Louis……
这是一个很好的问题,一点也不傻!在 GPU 上运行您的 PyTorch 模型可以显著加快训练速度,特别是对于像 LSTM 这样计算密集型的模型。
要将您的模型和数据加载到 PyTorch 中的 GPU 上,您需要遵循以下步骤:
1. **检查 GPU 是否可用**
首先,您需要检查系统上是否安装了 CUDA(NVIDIA GPU 的计算平台)。
pythonimport torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
如果 GPU 可用,此代码会将 `device` 设置为 `'cuda'`;否则,它将默认为 `'cpu'`。
2. **将模型移动到 GPU**
定义模型后,使用 `.to()` 方法将其移动到 GPU。
python
model = YourModelClass(*args)
model.to(device)
3. **将数据移动到 GPU**
加载数据时,您还需要将张量移动到 GPU。这通常在您的训练循环中完成。
pythonfor inputs, labels in data_loader:
inputs = inputs.to(device)
labels = labels.to(device)
# 现在继续您的前向和后向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
确保参与计算的每个张量都移动到 GPU。这包括输入、标签以及您可能使用的任何其他张量。
4. **处理隐藏状态(对于像 LSTM 这样的 RNN)**
如果您的 LSTM 模型维护一个您手动初始化的隐藏状态,请确保也将其移动到 GPU。
python
h0 = torch.zeros(num_layers, batch_size, hidden_size).to(device)
c0 = torch.zeros(num_layers, batch_size, hidden_size).to(device)
5. **如有必要,调整数据类型**
有时,您可能需要确保模型和输入之间的数据类型匹配,尤其是在使用 GPU 时。
6. **将所有内容整合到一起的示例**
pythonimport torch
import torch.nn as nn
import torch.optim as optim
# 定义您的设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)
# 定义您的模型
class LSTMModel(nn.Module)
def __init__(self, input_size, hidden_size, num_layers, output_size)
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x)
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# 实例化模型,定义损失函数和优化器
model = LSTMModel(input_size, hidden_size, num_layers, output_size).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练循环
for epoch in range(num_epochs)
for inputs, labels in data_loader
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
7. **验证是否正在使用 CUDA**
您可以通过检查张量的 `.device` 属性来验证它们是否在 GPU 上。
python
print(next(model.parameters()).device)
如果模型在 GPU 上,这将输出 `'cuda:0'`。
8. **常见陷阱**
– **忘记将数据移动到 GPU**:请记住,您的模型和数据都需要在同一设备上。
– **设备不一致**:确保在训练期间创建的任何新张量也移动到 GPU。
– **GPU 内存限制**:GPU 内存有限。如果您遇到内存不足错误,您可能需要减少批量大小。
9. **额外提示**
– **DataLoader 优化**:使用 `DataLoader` 时,您可以设置 `pin_memory=True` 以加快数据传输到 GPU。
python
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, pin_memory=True)
– **使用多个 GPU**:如果您有多个 GPU,您可以利用 `torch.nn.DataParallel` 或 `torch.nn.parallel.DistributedDataParallel` 进行并行训练。
python
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
model = nn.DataParallel(model)
model.to(device)
10. **检查 GPU 利用率**
– 您可以使用终端中的 `nvidia-smi` 命令监控您的 GPU 使用情况。
bash
watch -n 1 nvidia-smi
– 这将帮助您确保您的程序按预期利用 GPU。
—
通过遵循这些步骤,您应该能够将您的模型和训练过程加载到 GPU 上。在 GPU 上运行训练可以显著减少训练时间,并更有效地处理更大的模型或数据集。
如果您有任何其他问题或需要进一步澄清,请随时提问!
非常感谢!
如果我再问一个问题,尽管这是一个代码/逻辑上的问题
您会如何实现验证步骤?
James 您好
希望您一切都好。
我有一个相当愚蠢的问题,我已经在网上搜索过,但一直出错。有没有办法可以添加 r^2 分数?
谢谢,祝您有美好的一天
你好 Nicole……这根本不是一个愚蠢的问题!添加 R² 分数来评估 LSTM 模型的性能实际上非常有用。
以下是如何在 PyTorch 中计算 R² 分数:
1. **导入所需的模块**
python
from sklearn.metrics import r2_score
2. **计算 R² 分数**
在使用 LSTM 模型进行预测后,您可以将预测值与真实目标值进行比较(两者应具有相同的形状)。例如:
python# 假设 y_true 是您的真实值,y_pred 是您模型的预测值
y_true = y_true.detach().cpu().numpy() # 如果是张量形式,则将张量转换为 numpy 数组
y_pred = y_pred.detach().cpu().numpy()
r2 = r2_score(y_true, y_pred)
print(f'R^2 Score: {r2}')
确保 `y_true` 和 `y_pred` 都是张量或 numpy 数组,并且在传递给 `r2_score` 之前它们需要具有相同的形状。
### 常见错误避免
– **形状不匹配**:确保 `y_true` 和 `y_pred` 的形状相同。
– **张量到 Numpy 转换**:如果您的数据是 PyTorch 张量形式,请使用 `.detach().cpu().numpy()` 将它们转换为 numpy 数组,以兼容 `r2_score`。
如果您遇到任何错误,请告诉我,我很乐意提供帮助!祝您也有美好的一天!
您好
非常感谢您的帮助。很抱歉再次打扰。我在建模方面的经验很少,所以一次解决一个问题。根据我的理解,预测是 model(X_test),然后真实值应该是 y_test。由于它们在 train_test_split 中以及之后在创建数据集中进行了拆分,所以它们的大小应该相同,对吗?我收到它们不相同的错误,我该如何解决?
再次非常非常感谢
祝您有美好的一天
你好,我想知道如果我的数据集包含多个特征,并且我想将目标值设置为数据集的最后一个特征,我应该做出哪些调整。
你好 Micah……当在 PyTorch 中使用 LSTM 进行时间序列预测,并且您的数据集包含多个特征,其中目标值是最后一个特征时,您可以调整数据集准备和模型设计,以考虑多特征输入并确保使用正确的特征作为目标。以下是分步指南:
—
### 1. **准备数据集**
您需要将数据集分为输入特征(`X`)和目标值(`y`),确保最后一个特征用作目标。
#### 示例
假设您的数据集是一个 NumPy 数组或 pandas DataFrame,形状为 `(n_samples, n_features)`
pythonimport numpy as np
import pandas as pd
# 示例数据集
data = np.random.rand(1000, 5) # 5 个特征
df = pd.DataFrame(data, columns=['feature1', 'feature2', 'feature3', 'feature4', 'target'])
# 分离输入特征 (X) 和目标 (y)
X = df.iloc[:, :-1].values # 除最后一个之外的所有特征
y = df.iloc[:, -1].values # 最后一个特征作为目标
—
### 2. **创建序列**
时间序列模型需要序列数据。为每个序列创建输入特征(`X`)和相应的目标(`y`)序列。
#### 示例
pythondef create_sequences(X, y, sequence_length):
sequences = []
targets = []
for i in range(len(X) - sequence_length):
seq = X[i:i+sequence_length]
target = y[i+sequence_length]
sequences.append(seq)
targets.append(target)
return np.array(sequences), np.array(targets)
# 参数
sequence_length = 10
X_seq, y_seq = create_sequences(X, y, sequence_length)
# X_seq 形状: (n_sequences, sequence_length, n_features)
# y_seq 形状: (n_sequences,)
—
### 3. **转换为 PyTorch 张量**
将准备好的序列和目标转换为 PyTorch 张量
pythonimport torch
from torch.utils.data import TensorDataset, DataLoader
# 转换为张量
X_tensor = torch.tensor(X_seq, dtype=torch.float32)
y_tensor = torch.tensor(y_seq, dtype=torch.float32)
# 创建 DataLoader 进行批量处理
dataset = TensorDataset(X_tensor, y_tensor)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)
—
### 4. **修改 LSTM 模型**
确保您的 LSTM 模型配置为处理多个输入特征并输出单个目标值。
#### 示例 LSTM 模型
pythonimport torch.nn as nn
class LSTMTimeSeries(nn.Module)
def __init__(self, input_dim, hidden_dim, num_layers, output_dim)
super(LSTMTimeSeries, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x)
# x 形状: (batch_size, sequence_length, input_dim)
lstm_out, _ = self.lstm(x) # lstm_out 形状: (batch_size, sequence_length, hidden_dim)
out = self.fc(lstm_out[:, -1, :]) # 取最后一个时间步的输出
return out
# 模型参数
input_dim = X_seq.shape[2] # 特征数量
hidden_dim = 64
num_layers = 2
output_dim = 1 # 单个目标值
# 初始化模型
model = LSTMTimeSeries(input_dim, hidden_dim, num_layers, output_dim)
—
### 5. **训练模型**
使用合适的损失函数(例如,回归的 `nn.MSELoss`)和优化器来训练您的模型。
#### 示例训练循环
python# 损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 20
for epoch in range(num_epochs)
for inputs, targets in data_loader
# 前向传播
outputs = model(inputs)
loss = criterion(outputs.squeeze(), targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")
—
### 多特征输入的关键调整
1. **分离目标**:确保在数据集准备期间将目标与输入特征分离。
2. **序列创建**:生成输入特征序列,同时将它们与目标值对齐。
3. **模型输入维度**:LSTM 模型的 `input_dim` 应与输入特征的数量匹配。
4. **输出维度**:最终输出层(`nn.Linear`)应生成与目标对应的单个值。
感谢您的回复。我想知道,由于我们现在处理的是不同形状的数据,您是使用相同的方法绘制数据还是使用不同的方法?
你好,我有点困惑。当你将训练好的模型应用到 X_test 时
test_plot[train_size+lookback:len(timeseries)] = model(X_test)[:, -1, :]
我觉得这不符合机器学习的标准,因为 X_test 基本上是您的时间序列测试集中的一堆点。所以……这基本上是您此时不应该访问的数据,对吧?
我正在做的是:取 y_train 的最后一个点,这是时间序列训练集的最后一个点,然后我进行迭代:我将模型应用于这个点,然后我得到测试集区域的第一个预测点。然后我再次将模型应用于这个预测点以获得我的下一个预测。以此类推。当然,我的预测有点偏差,但我觉得完全不使用测试集的数据是合理的,对吧?
然后我的想法是尝试一个更大的 look_back,这样模型就有更多的数据来进行预测。
如果我的逻辑有误,请告诉我。谢谢!🙂
你好 Manel……你问了一个**非常好的问题**,你的想法实际上与良好的机器学习实践非常吻合,尤其是在**时间序列预测**方面。
让我们分解一下,以便澄清:
—
### 🔁 你提到的代码
python
test_plot[train_size+lookback:len(timeseries)] = model(X_test)[:, -1, :]
这行代码**确实**将训练好的模型应用于 `X_test`,它是一个**来自测试集的已知序列滑动窗口**。这意味着你正在使用实际的测试数据(即使只是输入序列)来获取预测。所以是的——**这不是真正的预测**。这更像是**评估模型在保留的已知数据上的性能**(有时称为教师强制),而不是模拟未来数据未知的真实世界条件。
—
### ✅ 你的方法(自回归预测)
你正在做的事情——即你:
1. 从训练数据中获取最后一个 `look_back` 窗口,
2. 预测下一个时间步,
3. 将该预测附加到你的输入窗口,
4. 使用你自己的预测点作为新输入向前滑动窗口,
这**正是你在生产环境中使用模型的方式**:*严格*根据过去观测到的(或先前预测的)值进行预测。这称为**递归**或**自回归预测**。
你说的很对,这更好地模拟了实际中的预测方式——你无法“偷看”实际的未来值。
—
### 📏 为什么结果会不同?
模型是在输入为真实过去值的干净序列上训练的。当你开始输入**预测值**而不是真实值时,**误差会累积**——这个问题被称为**暴露偏差**或**误差累积**。这就是为什么你的预测会“漂移”或看起来比用 `X_test` 评估时更差的原因。
—
### 🧠 如何改进递归预测
1. **使用噪声/计划抽样进行训练**:在训练期间,有时将真实输入替换为预测输入。这会教会模型处理其自身的错误。
2. **使用序列到序列 LSTM**:一次预测多个时间步(多对多),而不是一次预测一个。
3. **尝试 Transformer 或时间卷积网络**:这些可能比标准 LSTM 更好地处理长期依赖关系。
4. **增加回溯窗口**:正如你所建议的——为模型提供更多上下文可以帮助它做出更稳定的预测。
—
### 🧪 何时使用 `X_test` 是可以的?
在以下情况下可以使用 `X_test`:
– 你正在**评估**模型的性能(例如,测试集上的 RMSE)。
– 你想了解模型在保留集中的**已知序列**上的泛化能力。
但你不应该在真正的预测模拟中使用它。
—
### ✅ 总结
– 你说得对——在预测中使用 `X_test` 是不现实的。
– 你的自回归方法对于真正的预测是正确的。
– 这更难(也更诚实),但更好地模拟了现实。
– 更大的 `look_back` 可能有帮助;还可以考虑序列预测或噪声感知训练等改进。
—