集成可以为您在数据集上带来准确性的提升。
在本帖中,您将了解如何在 R 中创建三种最强大的集成类型。
本案例研究将逐步介绍您了解提升(Boosting)、装袋(Bagging)和堆叠(Stacking),并展示如何持续提高模型在您自身数据集上的准确性。
通过我的新书《R 机器学习精通》,开始您的项目,其中包括分步教程和所有示例的R 源代码文件。
让我们开始吧。

在 R 中构建机器学习算法集成
照片由 Barbara Hobbs 拍摄,保留部分权利。
提高模型的准确性
为数据集寻找表现良好的机器学习算法可能需要时间。这是因为应用机器学习具有反复试验的性质。
一旦有了表现良好的模型列表,您就可以通过算法调优来最大限度地发挥每种算法的作用。
另一种可以提高数据集准确性的方法是将多个不同模型的预测结果结合起来。
这被称为集成预测。
将模型预测组合成集成预测
组合不同模型预测的三种最流行的方法是:
- 装袋(Bagging)。从训练数据集的不同子集中构建多个模型(通常是同一类型的模型)。
- 提升(Boosting)。构建多个模型(通常是同一类型的模型),每个模型都学习纠正链中先前模型的预测错误。
- 堆叠(Stacking)。构建多个模型(通常是不同类型的模型)和一个监督模型,该模型学习如何最好地组合主模型的预测。
本帖不解释每种方法。它假设您对机器学习算法和集成方法有一般的了解,并且您正在寻找有关如何使用 R 创建集成的信息。
需要更多关于R机器学习的帮助吗?
参加我为期14天的免费电子邮件课程,了解如何在您的项目中使用R(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
R 中的集成机器学习
您可以在 R 中创建机器学习算法集成。
在 R 中创建机器学习算法集成的三种主要技术是:提升(Boosting)、装袋(Bagging)和堆叠(Stacking)。在本节中,我们将逐一介绍。
在开始构建集成之前,让我们定义我们的测试设置。
测试数据集
本案例研究中所有集成预测的示例都将使用电离层数据集。
该数据集来自UCI 机器学习库。该数据集描述了高能粒子在大气层中的高频天线返回信号,以及返回信号是否显示出结构。这是一个二分类问题,包含 351 个样本和 35 个数值属性。
让我们加载库和数据集。
|
1 2 3 4 5 6 7 8 9 10 |
# 加载库 library(mlbench) library(caret) library(caretEnsemble) # 加载数据集 data(Ionosphere) dataset <- Ionosphere dataset <- dataset[,-2] dataset$V1 <- as.numeric(as.character(dataset$V1)) |
请注意,第一个属性是一个因子(0,1),已转换为数值型,以与其他所有数值型属性保持一致。另请注意,第二个属性是一个常数,已被移除。
以下是电离层数据集前几行的预览。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
> head(dataset) V1 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 1 1 0.99539 -0.05889 0.85243 0.02306 0.83398 -0.37708 1.00000 0.03760 0.85243 -0.17755 0.59755 -0.44945 0.60536 2 1 1.00000 -0.18829 0.93035 -0.36156 -0.10868 -0.93597 1.00000 -0.04549 0.50874 -0.67743 0.34432 -0.69707 -0.51685 3 1 1.00000 -0.03365 1.00000 0.00485 1.00000 -0.12062 0.88965 0.01198 0.73082 0.05346 0.85443 0.00827 0.54591 4 1 1.00000 -0.45161 1.00000 1.00000 0.71216 -1.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 -1.00000 5 1 1.00000 -0.02401 0.94140 0.06531 0.92106 -0.23255 0.77152 -0.16399 0.52798 -0.20275 0.56409 -0.00712 0.34395 6 1 0.02337 -0.00592 -0.09924 -0.11949 -0.00763 -0.11824 0.14706 0.06637 0.03786 -0.06302 0.00000 0.00000 -0.04572 V16 V17 V18 V19 V20 V21 V22 V23 V24 V25 V26 V27 V28 1 -0.38223 0.84356 -0.38542 0.58212 -0.32192 0.56971 -0.29674 0.36946 -0.47357 0.56811 -0.51171 0.41078 -0.46168 2 -0.97515 0.05499 -0.62237 0.33109 -1.00000 -0.13151 -0.45300 -0.18056 -0.35734 -0.20332 -0.26569 -0.20468 -0.18401 3 0.00299 0.83775 -0.13644 0.75535 -0.08540 0.70887 -0.27502 0.43385 -0.12062 0.57528 -0.40220 0.58984 -0.22145 4 0.14516 0.54094 -0.39330 -1.00000 -0.54467 -0.69975 1.00000 0.00000 0.00000 1.00000 0.90695 0.51613 1.00000 5 -0.27457 0.52940 -0.21780 0.45107 -0.17813 0.05982 -0.35575 0.02309 -0.52879 0.03286 -0.65158 0.13290 -0.53206 6 -0.15540 -0.00343 -0.10196 -0.11575 -0.05414 0.01838 0.03669 0.01519 0.00888 0.03513 -0.01535 -0.03240 0.09223 V29 V30 V31 V32 V33 V34 Class 1 0.21266 -0.34090 0.42267 -0.54487 0.18641 -0.45300 good 2 -0.19040 -0.11593 -0.16626 -0.06288 -0.13738 -0.02447 bad 3 0.43100 -0.17365 0.60436 -0.24180 0.56045 -0.38238 good 4 1.00000 -0.20099 0.25682 1.00000 -0.32382 1.00000 bad 5 0.02431 -0.62197 -0.05707 -0.59573 -0.04608 -0.65697 good 6 -0.07859 0.00732 0.00000 0.00000 -0.00039 0.12011 bad |
有关更多信息,请参阅 UCI 机器学习库上电离层数据集的描述。
请参阅有关该数据集的已发表的世界级成果摘要。
1. 提升算法
我们可以看一下两种最流行的提升机器学习算法:
- C5.0
- 随机梯度提升
以下是 R 中 C5.0 和随机梯度提升(使用梯度提升建模实现)算法的示例。这两种算法都包含本示例中未调整的参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 提升算法示例 control <- trainControl(method="repeatedcv", number=10, repeats=3) seed <- 7 metric <- "Accuracy" # C5.0 set.seed(seed) fit.c50 <- train(Class~., data=dataset, method="C5.0", metric=metric, trControl=control) # 随机梯度提升 set.seed(seed) fit.gbm <- train(Class~., data=dataset, method="gbm", metric=metric, trControl=control, verbose=FALSE) # 总结结果 boosting_results <- resamples(list(c5.0=fit.c50, gbm=fit.gbm)) summary(boosting_results) dotplot(boosting_results) |
我们可以看到 C5.0 算法产生了更准确的模型,准确率为 94.58%。
|
1 2 3 4 5 6 7 |
模型:c5.0, gbm 重采样次数:30 准确度 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's c5.0 0.8824 0.9143 0.9437 0.9458 0.9714 1 0 gbm 0.8824 0.9143 0.9429 0.9402 0.9641 1 0 |
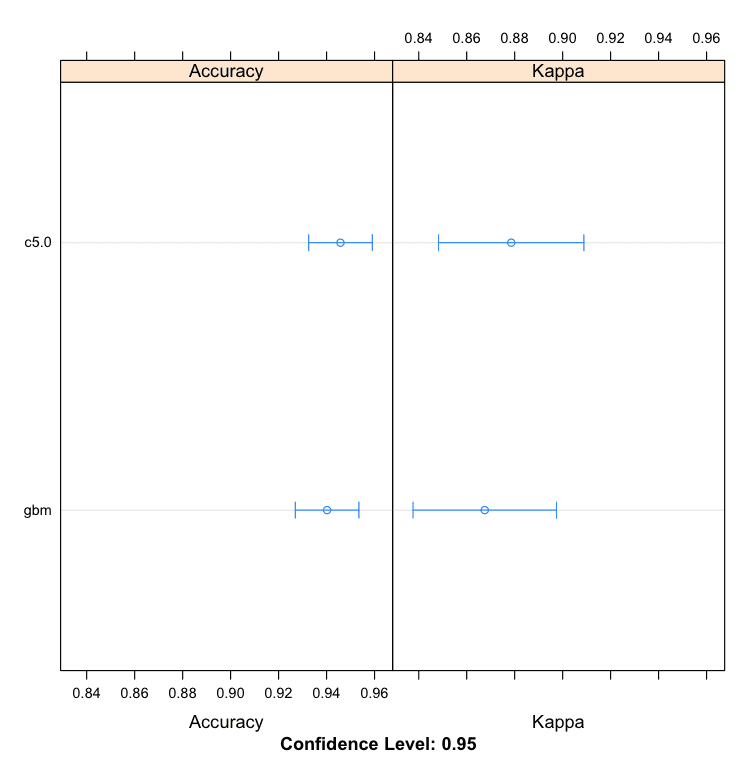
R 中的提升机器学习算法
在此处了解更多关于 caret 提升模型树的信息:提升模型。
2. 装袋算法
让我们看一下两种最流行的装袋机器学习算法:
- 装袋 CART
- 随机森林
以下是 R 中装袋 CART 和随机森林算法的示例。这两种算法都包含本示例中未调整的参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 装袋算法示例 control <- trainControl(method="repeatedcv", number=10, repeats=3) seed <- 7 metric <- "Accuracy" # 装袋 CART set.seed(seed) fit.treebag <- train(Class~., data=dataset, method="treebag", metric=metric, trControl=control) # 随机森林 set.seed(seed) fit.rf <- train(Class~., data=dataset, method="rf", metric=metric, trControl=control) # 总结结果 bagging_results <- resamples(list(treebag=fit.treebag, rf=fit.rf)) summary(bagging_results) dotplot(bagging_results) |
我们可以看到随机森林产生了更准确的模型,准确率为 93.25%。
|
1 2 3 4 5 6 7 |
模型:treebag, rf 重采样次数:30 准确度 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's treebag 0.8529 0.8946 0.9143 0.9183 0.9440 1 0 rf 0.8571 0.9143 0.9420 0.9325 0.9444 1 0 |
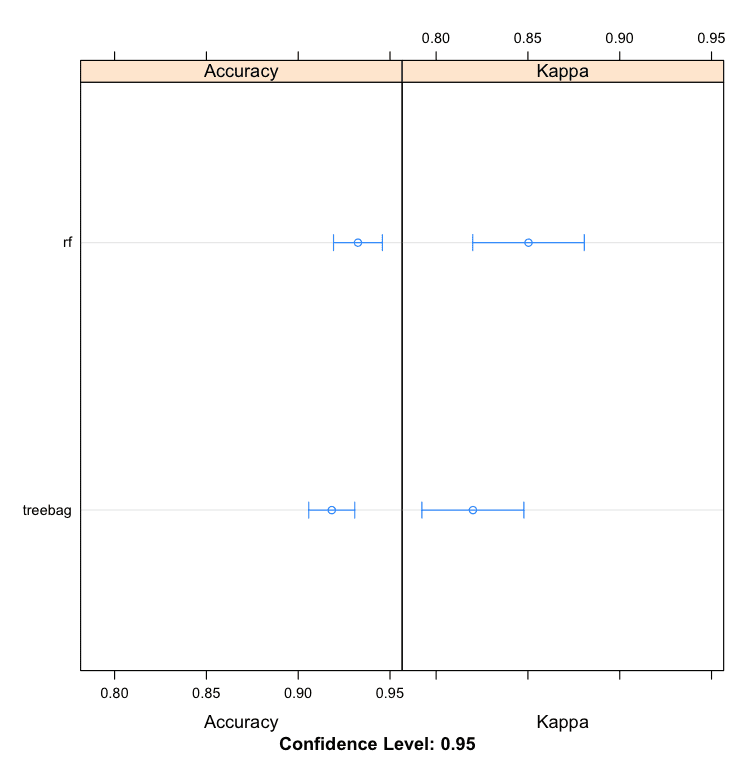
R 中的装袋机器学习算法
在此处了解更多关于 caret 装袋模型的信息:装袋模型。
3. 堆叠算法
您可以使用 `caretEnsemble` 包组合多个 `caret` 模型的预测结果。
给定一系列 caret 模型,可以使用 `caretStack()` 函数指定一个更高阶的模型,以学习如何最好地将子模型的预测结果组合在一起。
让我们先看看为电离层数据集创建 5 个子模型,具体来说:
- 线性判别分析(LDA)
- 分类与回归树(CART)
- 逻辑回归(通过广义线性模型或 GLM)
- k-近邻(kNN)
- 具有径向基核函数的支持向量机(SVM)
以下是创建这 5 个子模型的示例。请注意 `caretEnsemble` 包提供的新的有用的 `caretList()` 函数,用于创建标准 caret 模型列表。
|
1 2 3 4 5 6 7 8 9 |
# 堆叠算法示例 # 创建子模型 control <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE) algorithmList <- c('lda', 'rpart', 'glm', 'knn', 'svmRadial') set.seed(seed) models <- caretList(Class~., data=dataset, trControl=control, methodList=algorithmList) results <- resamples(models) summary(results) dotplot(results) |
我们可以看到 SVM 创建了最准确的模型,准确率为 94.66%。
|
1 2 3 4 5 6 7 8 9 10 |
模型:lda, rpart, glm, knn, svmRadial 重采样次数:30 准确度 Min. 1st Qu. Median Mean 3rd Qu. Max. NA's lda 0.7714 0.8286 0.8611 0.8645 0.9060 0.9429 0 rpart 0.7714 0.8540 0.8873 0.8803 0.9143 0.9714 0 glm 0.7778 0.8286 0.8873 0.8803 0.9167 0.9722 0 knn 0.7647 0.8056 0.8431 0.8451 0.8857 0.9167 0 svmRadial 0.8824 0.9143 0.9429 0.9466 0.9722 1.0000 0 |
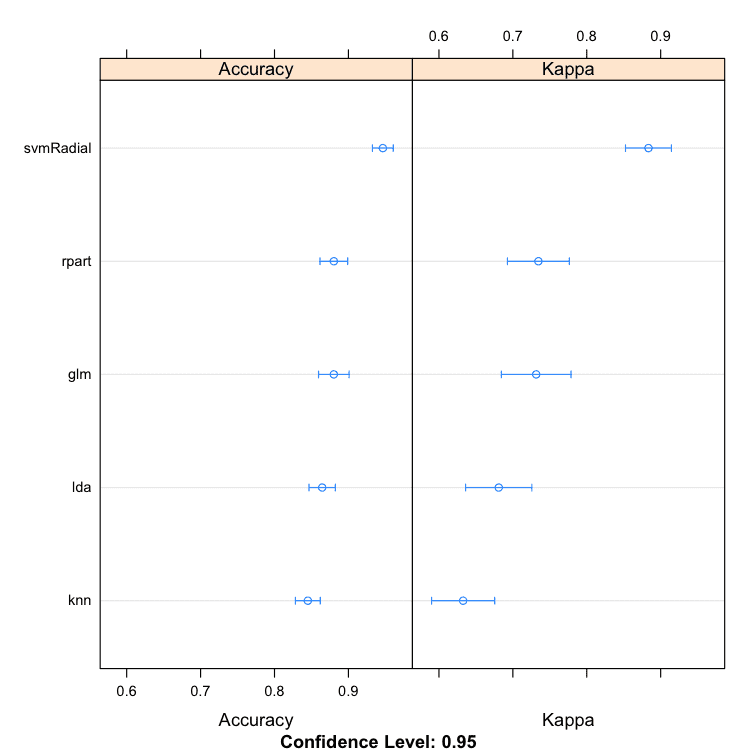
R 中堆叠子模型的比较
当我们使用堆叠组合不同模型的预测结果时,理想情况下子模型做出的预测应具有低相关性。这表明模型虽然有效,但方式不同,从而允许新的分类器找出如何最好地利用每个模型来获得更好的分数。
如果子模型的预测高度相关(>0.75),那么它们在大多数时候会做出相同或非常相似的预测,从而降低了组合预测的好处。
|
1 2 3 |
# 结果之间的相关性 modelCor(results) splom(results) |
我们可以看到,所有预测对的相关性普遍较低。预测之间相关性最高的两种方法是逻辑回归(GLM)和 kNN,相关性为 0.517,这被认为不高(>0.75)。
|
1 2 3 4 5 6 |
lda rpart glm knn svmRadial lda 1.0000000 0.2515454 0.2970731 0.5013524 0.1126050 rpart 0.2515454 1.0000000 0.1749923 0.2823324 0.3465532 glm 0.2970731 0.1749923 1.0000000 0.5172239 0.3788275 knn 0.5013524 0.2823324 0.5172239 1.0000000 0.3512242 svmRadial 0.1126050 0.3465532 0.3788275 0.3512242 1.0000000 |
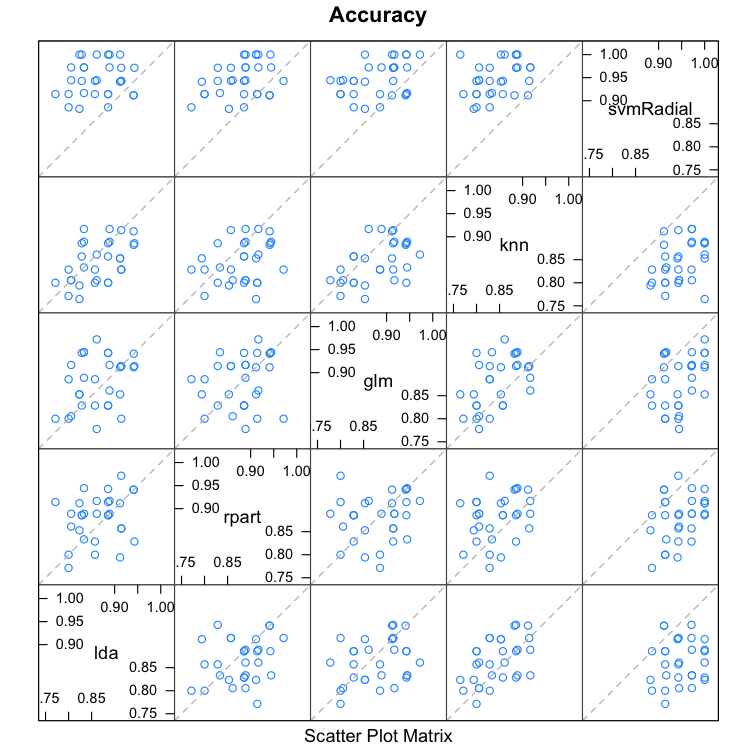
堆叠集成子模型之间的预测相关性
让我们使用一个简单的线性模型来组合分类器的预测结果。
|
1 2 3 4 5 |
# 使用 glm 进行堆叠 stackControl <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE) set.seed(seed) stack.glm <- caretStack(models, method="glm", metric="Accuracy", trControl=stackControl) print(stack.glm) |
我们可以看到,准确率提高到了 94.99%,比单独使用 SVM 有了小幅提高。这也比在数据集中单独使用随机森林(如上所述)有所提高。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
一个 glm 集成,包含 5 个基础模型:lda, rpart, glm, knn, svmRadial 集成结果 广义线性模型 1053 个样本 5 个预测变量 2 个类别:'bad', 'good' 无预处理 重采样:交叉验证(10 折,重复 3 次) 样本大小摘要:948, 947, 948, 947, 949, 948, ... 重采样结果 Accuracy Kappa Accuracy SD Kappa SD 0.949996 0.891494 0.02121303 0.04600482 |
我们还可以使用更复杂的算法来组合预测,以期区分何时最佳使用不同的方法。在这种情况下,我们可以使用随机森林算法来组合预测。
|
1 2 3 4 |
# 使用随机森林进行堆叠 set.seed(seed) stack.rf <- caretStack(models, method="rf", metric="Accuracy", trControl=stackControl) print(stack.rf) |
我们可以看到,这已将准确率提高到 96.26%,与单独使用 SVM 相比有了令人印象深刻的提升。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
一个 rf 集成,包含 5 个基础模型:lda, rpart, glm, knn, svmRadial 集成结果 随机森林 1053 个样本 5 个预测变量 2 个类别:'bad', 'good' 无预处理 重采样:交叉验证(10 折,重复 3 次) 样本大小摘要:948, 947, 948, 947, 949, 948, ... 跨调优参数的重采样结果 mtry Accuracy Kappa Accuracy SD Kappa SD 2 0.9626439 0.9179410 0.01777927 0.03936882 3 0.9623205 0.9172689 0.01858314 0.04115226 5 0.9591459 0.9106736 0.01938769 0.04260672 Accuracy 用于选择最佳模型,采用最大值。 为模型使用的最终值为 mtry = 2。 |
您可以在 R 中构建集成
您不需要成为 R 程序员。您可以复制代码并将其粘贴到此博客文章中以开始使用。使用 R 内置的帮助来研究示例中使用的函数。
您不需要成为机器学习专家。从头开始创建集成可能非常复杂。`caret` 和 `caretEnsemble` 包允许您在不深入了解它们如何工作的情况下开始创建和试验集成。稍后可以阅读每种类型的集成以获得更多收益。
您不需要收集自己的数据。本案例研究中使用的数据来自 `mlbench` 包。您可以使用这样的标准机器学习数据集来学习、使用和试验机器学习算法。
您不需要编写自己的集成代码。一些最强大的创建集成算法已由 R 提供,可供运行。使用本帖中的示例立即开始。您始终可以将其改编到您的特定案例,或在以后尝试自定义代码来尝试新想法。
总结
在本帖中,您了解到可以使用机器学习算法集成来提高模型的准确性。
您了解了可以在 R 中构建的三种机器学习算法集成类型:
- 提升
- Bagging
- 堆叠
您可以将此案例研究中的代码用作模板,用于您当前或下一个 R 机器学习项目。
下一步
您是否完成了案例研究?
- 启动您的 R 交互式环境。
- 键入或复制粘贴此案例研究中的所有代码。
- 花时间使用 R 函数的帮助来理解案例研究的每个部分。
您对此案例研究或在 R 中使用集成有任何疑问吗?请留言提问,我将尽力回答。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。





")
感谢发布 Jason,非常有帮助。
一个问题:在堆叠的随机森林和 GLM 集成模型中,如何为每个模型指定超参数(例如,kNN 的 k 值是多少,随机森林中有多少棵树)?我假设使用的是默认值,但这些值是否可以在 caretEnsemble 包中进行调整?
算法使用“合理的”默认值。我认为是 100 棵树用于 RF,我不记得 kNN 中 K 的值了。caret 文档会指定默认值,或者您可以在训练后打印模型。
构建模型后如何使 predict 函数工作
这些方法是否也适用于多类别分类,因为在进行 caretstack 时,我遇到了多类别分类的错误?
我看到的所有示例都是二分类的,是否有适用于多分类的示例?
是的,请看这个
https://machinelearning.org.cn/machine-learning-in-r-step-by-step/
你好,
感谢这个教程。我有一个关于模型验证的问题。我是否应该始终为整个评估过程使用相同的种子(折叠)(例如,调整单个模型,堆叠模型等)?我认为同时获得单个模型的超参数的有效数字、单个模型的良好性能和不相关的模型确实很难。例如,如果我使用 10 * 10 交叉验证,并且所有模型使用相同的种子(折叠),它们的性能相当稳定,但它们结果的内部相关性往往很高。
不,我认为最好评估模型,包括数据和模型中的方差(例如,对许多次运行取平均值)。
嗨,Jason,
我最近才开始关注您的帖子,到目前为止,这是我读过的最好的帖子之一,不仅是这个网站,而且是我访问过的所有 ML 网站中。我非常感谢您以简单清晰的方式解释这样一个有用的主题。我一定会尽快尝试这项技术。再次感谢..
谢谢 Sreenath。
我读过的最好的文章之一。超级有用。
谢谢!!
不客气 pradnya。
一个问题:如何将数据集不同子集的模型堆叠成一个模型?我尝试了 caretStack 但收到了一个错误。
听到这个消息很遗憾。你得到了什么错误?
上面的示例对您有用吗?
精彩的教程!!介绍集成的一种最简单优雅的方式。正如之前一位评论者所说,这是介绍集成的最可爱资源之一。
谢谢 Ramasubramaniam。
models <- caretList(Loan_Status~., data=train1, trControl=control, methodList=algorithmList)
引发了一个错误
Error in { : task 1 failed – "argument is not interpretable as logical"
此外:有 32 个警告(使用 warnings() 查看它们)
有什么建议吗?
看起来你正在改编示例来处理你自己的问题,做得好!
你能够先重现教程中的示例吗?这将确认你的环境工作正常。
我以前没见过这个错误,但我怀疑它与你的数据集有关。请确认数据是以易于建模的形式存在的,例如所有数值属性和一个要预测的因子。
您现在可以忽略这些警告。
嗨,Jason,
环境没问题,因为我也尝试过你其他的代码,它们也运行正常……
您可以通过电子邮件将我正在使用的数据集发送给我,您就可以帮我处理代码,并告诉我我犯了什么错误……。先给您打个招呼,我在应用算法之前已经将所有变量都转换为as.numeric,但仍然遇到同样的问题。
如果您能提供您的电子邮件地址,以便我发送数据集,我将不胜感激。
此致
Mudit
嗨,Jason,
有回复吗?
此致
Mudit
我很乐意回答具体问题
https://machinelearning.org.cn/contact/
但我很抱歉,我没有时间帮您调试问题。
嗨,Jason,
我完全尊重您的时间限制……只是当我对代码感到困惑时,调试起来会很困难……看到相同的代码在其他数据集上运行良好……。
此致
Mudit
你好 Mudit,
我看到您正在参加 AV Loan default prediction 竞赛。我也在以学习模式参加同一个竞赛,到目前为止我的得分和您一样。目前我正在使用 caretEnsemble 进行堆叠,我还没有遇到您看到的错误。您能否提供更多信息(或)分享代码?
谢谢,
Raj
我需要结合 6 个不同的预测模型,这是一个 7 类问题。
每个模型都预测属于所有七个类别的输出概率(使用 -b 1 选项的 lib SVM),我需要将它们组合起来以获得更好的模型。我只需要使用这些模型的预测来训练集成模型。
您能否告诉我如何为多类问题进行集成学习,以及如何在 matlab 中实现?请尽快回复。我将不胜感激。谢谢!
抱歉,我目前没有 matlab 的示例。
嗨,Jason,
我已经构建了许多模型,对每个模型都进行了不同的预处理,并且模型本身通过其自身的调优参数进行了独特的调优,现在我想对它们进行堆叠。如何将它们输入 caretStack,因为 caretStack 需要 caretList 作为其输入。但我已经通过 caret train 函数生成了模型。希望您能明白我的意思。感谢您的回复。
祝好,
Raj
Jason,没关系。我搞定了,谢谢。
您是怎么做到的?我目前正在处理一个类似的问题。您能否指导我如何进行?使用具有不同预处理和不同变量的 caretlist 来构建堆叠集成模型。
嗨,Jason,
我目前正在尝试使用堆叠技术构建分类器集成。我目前使用朴素贝叶斯和 j48 分类器作为基本学习器,以随机森林作为元学习器。在哪里可以在 Weka 中找到预测的相关值?
谢谢
您好 Seun,如果您想研究 Weka 中预测误差之间的相关性,您需要手动完成。我不认为有此功能。
您需要对每个分类器在测试数据集上进行预测,将它们保存到 CSV 文件中,然后在 MS Excel 或类似软件中计算 PEARSON() 相关性。
希望这能有所帮助。
您好 Jason,谢谢。这听起来像是一项繁重的工作。
如果我处理具有大量级别的分类特征空间,应该进行哪些更改?执行时,如果此代码显示错误“Error in train.default(x, y, weights = w, …) : Stopping
此外:有 33 个警告(使用 warnings() 查看它们)。”..
我指的是执行堆叠。
这是一个棘手的问题 babi。尝试将分类特征转换为二元特征,看看是否会有所不同。
非常感谢 Jason……这篇文章对于模型集成非常有帮助!
我尝试了一个回归问题,RMSE 值有所增加……
是否有除了 caret 之外的合并模型的文章?如果方便的话……
谢谢,
Narendra Prasad K
您可以手动合并模型预测,这是我们在 caretEnsemble 出现之前所做的。
我可以合并逻辑回归和线性回归等分类模型吗?如果可以,应该使用哪种方法?
您好 Siddhesh,
是的,您可以通过组合这些模型的预测来创建集成。您可以使用投票(多数)方法,取平均值,或者使用另一个模型来学习如何最佳地组合预测(称为堆叠泛化或堆叠)。
嗨,Jason,
教程很棒,但我无法为 R 版本 3.3.1 安装 caretEnsemble 包,是否有其他包可以用于相同的任务或有任何解决方法?
谢谢您的帮助……!
我很抱歉听到这个消息。
也许您可以更新到 3.3.2 再试一次?
也许可以查看 stack overflow,看看是否有其他人遇到您的错误?
您甚至可以尝试 R 邮件列表,如果您够勇敢的话。
models <- caretList(Item_Outlet_Sales~., data=BigMartimp, trControl=trainControl, methodList=algorithmList)
results <- resamples(models)
summary(results)
dotplot(results)
modelCor(results)
splom(results)
从上面我们发现决策树与先前方法列表中使用的所有其他模型的相关性较低。
那么在创建堆叠集成模型时,我们需要移除 rpart 并再次训练模型,然后再进行堆叠吗?
stack.rf <- caretStack(models, method="rf", metric="RMSE", trControl=stackControl)
好问题 Surya,
您可以自己创建堆叠模型。我认为 caretStack 的一个限制是它期望自己训练子模型。
您知道在哪里可以找到在 R 中实现堆叠模型的代码吗?我想调整我的 xgboost 模型并将它们与其他优化模型进行堆叠。任何指向示例/实现的指针都会很棒!
这篇文章中的堆叠示例不起作用吗?
XGBoost 在 R 和 caret 中都可用,并且可以从 caretEnsemble 中使用。
假设我们得到了两个高度相关的预测(>0.75)。我们应该对它们应用与下文相同的代码吗?
# 使用随机森林进行堆叠
set.seed(seed)
stack.rf <- caretStack(models, method="rf", metric="Accuracy", trControl=stackControl)
print(stack.rf)
我建议尝试一下,看看是否可以通过堆叠模型来提高性能。即使是几个更好的预测也能提高模型性能。
抱歉,如果您能详细说明一下,那将是很好的。当一个模型与其他所有模型相关性较低时,如何使用堆叠算法?
我不记得论文的具体细节了,但大致意思是当弱学习者之间的预测不相关时(或者可能是错误不相关)性能更好。这可能是在 PAC 学习理论中——已经过去一段时间了,抱歉。
您好,感谢您对集成技术的精彩介绍。
我有一个问题。我可以反复集成 1 种方法吗?
CaretEnsemble 似乎混合了不同的方法。
如果我想多次集成单个方法(如提升)怎么办?
“train”函数似乎有助于对数据进行重采样并反复应用方法。但这是否意味着 bagging 或 boosting?还是它只是有助于为单个方法选择最佳参数?
提前感谢。
您可以这样做,但可能不会获得任何收益 Gunwoo。
您可以创建 10 个神经网络并取平均预测——这可能比堆叠方法效果更好。
您可以将其他方法放入 bagging 中(我不记得确切的包名了),但 bagging 与高方差方法配合效果更好——例如未修剪的树或 KNN 中 k 值较低且具有子样本训练数据等。
归根结底,尝试不同的方法,看看在您的问题上哪种效果最好。
感谢您的文章!
我能问你一个问题吗?
此包支持的最大模型合并数量是多少?
我不知道 Anh。也许它受内存和 CPU 功率的限制。
我明白了。非常感谢您
这篇帖子是我见过最有用的关于集成建模的工作!!
我有一个问题。
以下句子似乎显示了各模型重采样准确性度量之间的相关性,
而不是预测之间的相关性。
# 结果之间的相关性
modelCor(results)
splom(results)
准确率比率之间的相关性可以被解释为它们之间的相关性
由每个模型?
Jason 您好,首先我想感谢您写了如此好的集成方法文章。我有一个可能很天真的问题,但我感到困惑,
我的问题是,既然集成方法用于基础分类器模型(朴素贝叶斯分类器、SVM 等)来提高基础模型的准确性,但如何选择在哪个分类器上应用集成方法?
我们如何知道哪个分类器最适合应用集成方法?
好问题 Aadi。
一般来说,我们无法预先知道。通过试错。
在堆叠泛化的情况下,也许我们可以集成一组表现良好的模型。
在 bagging 的情况下,也许我们可以集成一组表现良好且高方差的模型。
这真的很具体取决于问题。这篇文章将更深入地阐述算法选择这个开放性问题。
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
我见过的最好的集成解释。谢谢您的发布。
谢谢 Carl。
我们需要为我们的数据集组合 c5.0 和随机森林,我们可以这样做吗?如何做?
是的,上面的教程应该会有帮助。抱歉我不能为您编写代码。
您好 Jason,您的帖子确实给了我很多启发。但是,我有一个关于堆叠模型输出的问题。
“A rf ensemble of 2 base models: lda, rpart, glm, knn, svmRadial”,为什么只有 2 个基本模型?2 是通过准确率选择的吗?
好问题。
我认为这是 R 代码中的一个拼写错误。我建议忽略它。
我们可以有一个深度学习系统,包含 (n-1) 个神经网络层和一个具有不同算法(例如 SVM)的最终层吗?
是的。我认为这可以算作堆叠集成。
你好,
将第一列转换为数值而不是将其保留为因子有什么优势吗?
谢谢
这确实取决于具体数据和使用的算法。
大多数算法期望使用数值数据而不是因子。
你好,Jason。
在 python 中执行此类操作,您推荐哪个库?
谢谢。
好问题,也许可以手动实现,但首先要充分利用 sklearn。
https://machinelearning.org.cn/start-here/#python
这绝对是 R 中用于竞赛参与者集成学习的最佳教程之一。
能否提供一个关于赢得竞赛的多层集成模型的教程?
好建议,也许将来会实现。
谢谢 Jason,这是一个非常清晰且可靠的示例。我非常欣赏。我刚开始接触这个领域,这个方法给我留下了深刻的印象。
我发现提到了一个名为 SuperLearner 的 R 包。这个包也适用于此类示例,还是有限制?我快速查看了文档,看到了参数化模型的提及。您对 SuperLearner 有什么了解吗?
谢谢 Sergio。
抱歉,我对那个包不熟悉。
您是那里最棒、最无私的 ML 专家。可复现、简单且解释得很好。
谢谢 Pat,您能这么说真是太好了。
我很高兴听到您觉得这个例子有用!
谢谢 Jason 先生,讲解得非常好。您能否使用一些水文学数据上传相同的教程?
抱歉,我不能。
教程的一个改进之处是展示如何在测试数据集或新数据上使用堆叠模型进行预测。
感谢您的建议 Eric。
简直太棒了 Jason。非常感谢您提供关于集成方法的这个非常有用的教程。在过去的 5 年里,我购买了许多关于 R 中机器学习的书籍,我认为这是如何使用多种机器学习方法来选择最适合且最有效的选项的最佳总结。
再次感谢您,您拯救了我!
谢谢 Gary,我很高兴听到这个。
我能做一个集成来预测未知数据吗?
例如
https://archive.ics.uci.edu/ml/datasets/diabetes
数据集
包含
(1) 日期格式为 MM-DD-YYYY
(2) 时间格式为 XX:YY
(3) 代码
(4) 值
代码数量为 20
33 = 规律胰岛素剂量
34 = NPH 胰岛素剂量
35 = 超长效胰岛素剂量
48 = 未指定的血糖测量
57 = 未指定的血糖测量
58 = 早餐前血糖测量
59 = 早餐后血糖测量
60 = 午餐前血糖测量
61 = 午餐后血糖测量
62 = 晚餐前血糖测量
63 = 晚餐后血糖测量
64 = 零食前血糖测量
65 = 低血糖症状
66 = 正常进餐
67 = 比平时多进餐
68 = 比平时少进餐
69 = 正常运动
70 = 比平时多运动
71 = 比平时少运动
72 = 未指明的特殊事件
value 代表相应记录的代码
我已理解数据集并已将其转换为
输入代码和输出代码
即输入代码表示血糖值的代码值
输出代码表示胰岛素值
作为输出向量代码:33,34,35。
输入代码向量:48,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72。
data01的示例文件内容
日期 时间 代码 值
1 04-21-1991 9:09 58 100
2 04-21-1991 9:09 33 9
3 04-21-1991 9:09 34 13
4 04-21-1991 17:08 62 119
5 04-21-1991 17:08 33 7
转换后
示例表格
c48 c57 c58 c59 c60 c61 c62 c63 c64 c65 c66 c67 c68 c69 c70 c71 c72 c33 c34 c35 c33x c34x c35x
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 0 0 100 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 13 0 0 0 0
3 0 0 0 0 0 0 119 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0 0
4 123 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 216 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 13 0 2 0 0
我使用了 KNN
以及神经网络来预测,通过输入任何一个代码值,我得到了我训练过的机器相应的预测值。我的问题是,是否有可能预测机器没有训练过的未知数据?
例如
我训练机器的血糖值最高为 350
如果我输入 600,为什么它没有给出相关的输出,它显示的是最后一个,即最近邻的值作为神经网络中的预测值?
嗨 Jason,感谢您这项伟大的工作。
不客气。
Jason,这篇真的太棒了。我(已注明出处)将其用于 Kaggle 的泰坦尼克号比赛的公共内核。https://www.kaggle.com/bhavesh09/stacking-example
但是我的分数只有 40% 左右。我找不到原因。
您需要针对您的特定数据集进行调整。
嗨 jason,感谢您这项伟大的工作。
我有一个问题,如果我的数据集包含 Android 代码,并且我需要在此数据集上应用集成方法来提高准确性,我该如何应用集成技术?我可以使用 weka 工具吗?或者您有其他方法来应用这项工作?
谢谢你
包括 Weka 在内的大多数平台都提供集成算法的访问,例如
https://machinelearning.org.cn/use-ensemble-machine-learning-algorithms-weka/
嗨,Jason,
您为什么认为 C5.0 是一个提升算法?根据我的理解,C5.0 只是一个简单的决策树算法。
来自《应用预测建模》第 392 页
嗨,Jason,
我计划在我的研究工作中堆叠不同的算法,如人工神经网络、SVM、KNN、C5.0、随机森林来预测糖尿病……这是否可行??或者上面的库是否只适用于某些算法?
当然,试试看在您的特定数据集上效果如何。
在实施我的模型之前有什么建议吗?或者您能分享一下您之前的经验吗?
你好先生,
我正在为我的研究问题使用神经网络进行堆叠。我想知道在堆叠的情况下使用 NN 是否合适?
也许可以尝试探索在您的特定数据集上最有效的方法。
您不应该分割训练数据和测试数据吗?
您如何定义测试集和训练集?
你可以在这里了解更多
https://www.rdocumentation.org/packages/caret/versions/6.0-79/topics/trainControl
谢谢您的建议!我尝试了堆叠,但出现了以下错误
错误:回归模型类型错误
此外:警告信息
1: In trControlCheck(x = trControl, y = target)
x$savePredictions == TRUE 已弃用。现设置为“final”。
2: In trControlCheck(x = trControl, y = target)
trControl 中未定义索引。正在尝试自己设置它们,因此集成中的每个模型将具有相同的重采样索引。
您能给我一些建议吗?
抱歉,我没见过这个错误,也许可以发布到 stackoverflow?
我已解决上一个问题,还有其他问题
1.有办法添加 xgboost 模型吗?
2.可以改变 KAPPA 为 AUC 来验证模型吗?
谢谢你!
当然,您可以在 R 中使用 xgboost。将它们作为另一个集成(如投票或堆叠)的一部分可能不会增加太多价值。
我相信您可以计算任何您想要的指标。抱歉,我没有 AUC 的实际示例。
是的,这是在新数据上评估机器学习算法能力的好方法。
在这里,我们使用重复的 k-fold 交叉验证。
晚上好,Jason 先生。
我想问一下,用于逻辑回归和线性判别的集成学习模型是 bagging-boosting-random forest 吗?这些分类器是否有特定的 bagging-boosting-random forest 语法?
Bagging 可以与每种算法一起使用,它更适合高方差的算法,例如未剪枝的树。
你好,我想问一下为什么模型的相关性低于 0.75 是可行的?为什么不是 0.7 或 0.8?有论文支持这一点吗?谢谢
这只是相关性高的任意截止值。您可以选择其他值。
当您说“预测”不应该太相关时,您是指后验概率(而不是两种可能值的预测值)吗?
我指的是两种方法的预测样本。
但大多数情况下,由于这是一个二元分类问题,所有方法的预测都是相同的。相关性怎么会如此之小?
另一个问题:caretList 函数似乎不支持缺失值。您如何处理?
我不确定 caret 是否支持插补,也许可以提前准备好数据。
您能否帮助我找到该错误的解决方案(ValueError: could not convert string to float: ‘ [-5.67604346 -0.37017465 1.41012661 2.30903599 2.85538861] ‘)?
抱歉,我不知道您错误的根本原因。也许可以尝试将所有代码和数据发布到 stackoverflow?
嗨,Jason,
我正在尝试对癌症进行分类,将其分为恶性或良性。当我使用 caret 包中的 modelCor 函数比较这些模型(LDA、NN、KNN、RF、NB…)时,我从某些模型中得到负相关系数。这是可能的吗?以及如何解释(负相关)的模型?
谢谢,
是的,负相关意味着当一个值上升时,另一个值下降。
感谢本教程。非常有帮助。您能建议我如何为堆叠模型绘制 ROC 曲线吗?按照您的示例,我已经生成了 stack.svm,现在请告诉我如何为它绘制 ROC 曲线?
抱歉,我没有在 R 中绘制 ROC 曲线的示例。
你好,我有几个问题,
1.选择 5 个模型作为基础模型的原因是什么?选择 5 个模型是基于什么?
2.我们可以拥有多少个基础模型?
3.基础模型是否被视为随机森林算法的无相关决策树?如果不是,模型是如何使用随机森林组合的?
我随意选择了 5 个基础模型。
您可以拥有任意数量的模型,多或少都可以。也许可以通过测试来发现什么最适合您的问题。
理想情况下,基础模型应该做出预测(或产生错误),这些预测(或错误)应该彼此弱相关。
2.我们可以拥有多少个基础模型?
3.基础模型是否被视为随机森林算法的无相关决策树?如果不是,模型是如何使用随机森林组合的?
模型是如何使用随机森林组合的
拟合未剪枝的树,其中分裂点作用于随机特征子集。
没有限制。
在所有方法中,如果模型彼此弱相关,则会有所帮助。随机森林是 bagging 的一种扩展。
很棒的教程!谢谢 Jason。我很容易地将您的脚本改编用于我在俄勒冈州立大学的博士遥感研究。
很高兴它能帮助 Cory!
嗨,Jason,
当我运行我的代码时,遇到了一个错误。
> models <- caretList(Stroke~., data=d11, trControl=control, methodList=algorithmList)
错误:至少一个类级别不是有效的 R 变量名;这将在生成类概率时导致错误,因为变量名将被转换为 X0, X1。请使用有效的 R 变量名的因子级别(有关帮助,请参阅 ?make.names)。
此外:警告信息
1: In trControlCheck(x = trControl, y = target)
x$savePredictions == TRUE 已弃用。现设置为“final”。
2: In trControlCheck(x = trControl, y = target)
trControl 中未定义索引。正在尝试自己设置它们,因此集成中的每个模型将具有相同的重采样索引。
有什么建议吗?
感谢您的时间。
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您好 Jason!您的帖子对我帮助很大,我非常感谢您
您在堆叠示例中使用了多少层?
如果两层,底层的分类器有哪些,顶层的分类器有哪些?
在下面的代码行中,“glm”是在顶层吗?
stack.glm <- caretStack(models, method="glm", metric="Accuracy", trControl=stackControl)
根据什么条件我应该选择顶层模型来最佳地组合所有模型的预测?
这在帖子中有解释,我建议您重新阅读该部分。
我建议测试各种不同的模型,并找出最适合您的方法,理想情况下,它们在预测/错误方面应该有些不相关。
抱歉,Jason,我读了很多遍这一部分,但我没有弄清楚您的示例中堆叠集成有多少层?也许您在整篇文章中都隐含地提到了它,但我是个新手,没有理解?
抱歉,一层基础模型和一层集成模型。
谢谢 Jason,您真是太好了
嗨 Jason
您的解释非常清晰易懂
我有一个关于 modelCor() 函数的问题,它是根据 Pearson 或 Spearman 相关方法计算相关性的吗?
我想阅读更多关于 modelCor() 函数的工作原理,因为我想在 R 中打印 modelCor 函数输入的每个模型的预测矩阵,以便查看用于相关的矩阵
您是否可以提供 modelCor() 函数的链接或任何信息,因为我在 R 的帮助中阅读了该函数,但信息非常有限?
类型
?modelCor
嗨,Jason,
非常感谢您的指导。
我有 2 个问题,希望能得到您的解释。
1.在堆叠算法部分,我看到您使用了 5 个子模型,我该如何寻找其他模型,有什么目标吗?
2.为什么选择随机森林和 glm?其他呢?
非常感谢
这些问题的答案只能通过系统实验来找到——没有将算法映射到问题的理论,也没有基于问题类型的算法配置。
在您的问题上测试不同数量的子模型,看看什么效果最好。
测试不同的模型类型,看看什么最适合您的特定数据集。
嗨,Jason,
感谢本教程。非常棒。
堆叠算法是否仅适用于二元分类?
您知道如何修改堆叠代码以用于多类分类吗?
不,我相信您可以直接将其用于多类分类。
非常有用的例子和不错的教程。请告诉我 modelCOr() 使用哪种相关性函数以及为什么?我可以参考 modelCor() 的任何参考文献吗?
谢谢。
我猜是皮尔逊相关系数用于线性相关,但您可以查看该函数的文档以确保。
集成中的这项技术非常简单,但实际上它给我的准确性不如这项技术。
请问有人能告诉我这是为什么吗?
是的,这种情况可能发生。
在您的数据集中测试一套算法以发现最有效的方法非常重要。
嗨
感谢您出色的帖子。我有一些问题。关于集成中的参数调整呢?以及我们如何衡量准确性?
抱歉,我指的是方差,而不是准确性。
您可以收集重复的 k-fold 交叉验证中的准确率分数样本,并报告均值和标准差。
是的,您可以调整集成中的超参数。
您可以像处理任何其他模型一样衡量准确性。
亲爱的Jason
非常感谢您发表了如此精彩的帖子,我非常喜欢。我有一组10个 GCM 预测,我希望从中获得最佳预测(即最佳集成)。我清楚地理解了您的教程,但是否有可能为最佳集成提供一个时间序列数据文件?我想使用该时间序列进行进一步的研究。
不客气。
也许吧。我没有示例,抱歉。
嗨 Jason
如何在 R 中集成随机森林和神经网络。
也许可以尝试投票集成或堆叠集成。
谢谢。我需要一些帮助,您能举例说明如何执行吗?
抱歉,我没有能力为您准备自定义示例。
嗨 Jason – 我真的很喜欢这个例子和您所有的解释……每个都非常简洁易懂。
我只有一个问题:理论上,caretStack 应该只应用于像 GLM 和 SVM 这样的基学习器,还是也可以使用 caretStack 来组合提升和装袋算法,如 C5.0、GBM 和 RF,只要这些模型之间的相关性很小?
谢谢!
是的,很可能。
亲爱的 Jason,
“Bagging Models”不起作用。
感谢您的工作。
很遗憾听到这个消息,您遇到了什么具体问题?
亲爱的 Jason,
感谢您的教程。我尝试使用 modelCor() 来展示一些模型的相关性,以验证集成这些方法是否会提高结果。但是,有些相关性结果为“NA”。您知道有什么方法可以纠正这个问题吗?
提前感谢。
致以最诚挚的问候。
您是指对角线吗?如果是,则无需计算样本与其自身的关联性。
不,是矩阵中的其他值。例如:我考虑了四种方法:rf、svmRadialWeights、gbm 和 rpart。svmRadialWeights 和 rf 的相关性为 0.5722874,gbm 和 rf 的相关性为 -0.1273161,但当我计算 rpart 与任何方法的关联性时,结果为 NA。
当我单独运行 rpart 方法时,它可以正常工作。
如果您的某些值是 na,则结果也将是 na,您需要从这些值中删除它们。
我的数据中没有任何 NA 值,这就是为什么我无法理解在将 rpart 方法用于集成时的结果……
也许值得将您的代码、数据和错误发布到 stackoverflow。
嗨,Jason,
感谢您的教程。快速更新一下,截至2020年9月,我使用完全相同的代码得到的结果略有不同。问题不大,只是在“Boosting Algorithms”部分,gbm 现在比 c5.0 更准确。我在 R 4.0 和 3.6.3 中都测试过,结果相同。
这是意料之中的,请看这里
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
我们知道与上述相关的事情,或者我们之所以知道这些事情,是因为我们从基因中继承了部分知识。
抱歉,我不太明白。您能详细说明一下吗?
你好,杰森,
感谢您的解释!我想知道是否可以将这些技术用于非二元数值变量作为响应变量。或者是否有其他类型的算法可以使用?例如:使用机器学习技术来预测电影的 imdb 分数。
不客气。
是的,这称为回归。许多算法也可以用于回归。
你好!非常有帮助的文章!
一个问题。如果我有定性预测变量,例如
Q11={每周少于一次,每周1-2次,每周3次或更多次}
我想预测
Q15={非常差,差,好,非常好}
我需要将它们转换为数字吗?或者将它们转换为因子并输入到模型中是否可以?
一些算法可以直接处理它们作为因子,一些可能需要您先对它们进行编码。
确实是一篇好文章。
只是一个快速的问题。
我只有两个变量 X 和 Y,这是一个回归问题。我使用了幂函数来预测 Y,准确率为 47%。
如果我尝试使用线性回归进行提升或装袋,能否期待 R 平方值有显著提高?
如何获得预测函数和公式?
谢谢!
准确性无法用于回归,我们必须使用误差。
一些算法会为您提供一个公式(例如线性算法),而大多数则不会。您可能需要查看您正在使用的算法的文档。
嗨,Jason,
我收到了这个错误:“Error: wrong model type for regression”。
我该如何纠正?
换句话说,我对回归问题应用了此代码,我应该在代码中更改什么?
我尝试更改:metric <- "RMSE",但不起作用。
看起来您正试图将分类算法用于回归问题。