机器学习是许多任务的绝佳工具。OpenCV 是一个用于图像处理的优秀库。如果能将它们结合起来,那将是非常棒的。
在这个为期 7 天的速成课程中,您将通过示例学习如何利用机器学习和 OpenCV 的图像处理 API 来实现一些目标。本迷你课程面向已经熟悉 Python 编程、了解机器学习基本概念并对图像处理有一定背景的实践者。让我们开始吧。

OpenCV 中的机器学习(7 天迷你课程)
图片来源:Nomadic Julien。保留部分权利。
本迷你课程适合谁?
在开始之前,请确保您来对了地方。以下列表提供了一些关于本课程设计受众的一般指导。如果您不完全符合这些要求,请不要惊慌,您可能只需要在某个方面稍作温习即可跟上。
- 了解如何编写少量代码的开发人员。这意味着您用 Python 完成任务并知道如何在工作站上设置生态系统(一个先决条件)不是什么大问题。这不意味着您是编程奇才,但意味着您不害怕安装包和编写脚本。
- 了解少量机器学习的开发人员。这意味着您了解一些常见的机器学习算法,如回归或神经网络。这不意味着您是机器学习博士,只是您知道里程碑或知道在哪里查找它们。
- 了解一点图像处理的开发人员。这意味着您知道如何读取图像文件、如何操作像素以及如何裁剪子图像。最好使用 OpenCV。这不意味着您是图像处理专家,但您理解数字图像是像素数组。
本迷你课程不是机器学习、OpenCV 或数字图像处理的教科书。相反,它是一个项目指南,逐步引导您从一个知识最少的开发人员成长为一个能够自信地在 OpenCV 中使用机器学习的开发人员。
迷你课程概述
本迷你课程分为 7 个部分。
每节课的设计时间约为普通开发人员 30 分钟。有些您可能会更快完成,有些您可能会选择深入研究并花费更多时间。
您可以根据自己的喜好快慢完成每个部分。一个舒适的时间表可能是七天内每天完成一节课。强烈推荐。
您将在接下来的 7 节课中涵盖的主题如下:
- 第 1 课:OpenCV 简介
- 第 2 课:使用 OpenCV 读取和显示图像
- 第 3 课:查找圆形
- 第 4 课:提取子图像
- 第 5 课:匹配硬币
- 第 6 课:构建硬币分类器
- 第 7 课:在 OpenCV 中使用 DNN 模块
这将非常有趣。
不过,您需要做一些工作,包括阅读、研究和编程。您想学习机器学习和计算机视觉,对吗?
在评论中发布您的结果;我会为您加油!
坚持下去;不要放弃。
第 01 课:OpenCV 简介
OpenCV 是一个流行的开源图像处理库。它在 Python、C++、Java 和 Matlab 中都有 API 绑定。它拥有数千个函数,并实现了许多高级图像处理算法。如果您使用 Python,OpenCV 的一个常见替代品是 PIL(Python 图像库,或其继任者 Pillow)。与 PIL 相比,OpenCV 具有更丰富的功能集,并且通常更快,因为它使用 C++ 实现。
本迷你课程旨在将机器学习应用于 OpenCV。在本迷你课程的后续课程中,您还将需要 Python 中的 TensorFlow/Keras 和 tf2onnx 库。
在本课中,您的目标是安装 OpenCV。
对于基本的 Python 环境,您可以使用 pip 安装包。要使用 pip 安装 OpenCV,以及 TensorFlow 和 tf2onnx,您可以使用
|
1 |
sudo pip install opencv-python tensorflow tf2onnx |
OpenCV 在 PyPI 中被命名为 opencv-python 包,但它只包含“免费”算法和主要模块。还有一个 opencv-contrib-python 包,其中也包含了“额外”模块。这些额外模块的稳定性较差,测试也不充分。如果您更喜欢安装后者,您应该使用以下命令代替
|
1 |
sudo pip install opencv-contrib-python tensorflow tf2onnx |
但是,如果您使用的是 Anaconda 或 miniconda 环境,包的名称就是 opencv,您可以使用 conda install 命令安装它。
要了解您的 OpenCV 安装是否正常工作,您只需运行一个简单的脚本并检查其版本
|
1 2 |
import cv2 print(cv2.version.opencv_version) |
要了解更多关于 OpenCV 的信息,您可以从其在线文档开始。
您的任务
重复上面的代码,确保您已正确安装 OpenCV。您还能通过向代码添加几行来打印 TensorFlow 模块的版本吗?
在下一课中,您将使用 OpenCV 读取并显示图像。
第 02 课:使用 OpenCV 读取和显示图像
OpenCV,即开源计算机视觉库,是图像处理和计算机视觉任务的强大工具。但在深入研究复杂算法之前,让我们掌握基础知识:读取和显示图像。
使用 OpenCV 读取图像是使用 cv2.imread() 函数。它接受图像文件路径并返回一个 NumPy 数组。该数组通常是三维的,按高度×宽度×通道排列,每个元素都是一个无符号的 8 位整数。“通道”在 OpenCV 中通常是 BGR(蓝-绿-红)。但是,如果您喜欢以灰度加载图像,可以添加一个额外的参数,例如
|
1 2 3 4 |
import cv2 image = cv2.imread("path/filename.jpg", cv2.IMREAD_GRAYSCALE) print(image.shape) |
上面的代码将打印数组维度。虽然我们通常将图像描述为宽度×高度,但数组维度被描述为高度×宽度。如果图像以灰度读取,则只有一个通道,因此输出将是一个二维数组。
如果您删除了第二个参数,使其变为 cv2.imread("path/filename.jpg"),则对于三个 BGR 通道,数组的形状应为高度×宽度×3。
要显示图像,您可以使用 OpenCV 的 cv2.imshow() 函数。这将创建一个窗口来显示图像。但是,除非您要求 OpenCV 等待您与窗口交互,否则此窗口不会显示。通常,您使用
|
1 2 3 4 |
... cv2.imshow("我的图像", 图像) cv2.waitKey(0) cv2.destroyAllWindows() |
cv2.imshow() 的第一个参数是窗口标题。要显示的图像应采用 BGR 通道顺序。cv2.waitKey() 函数将根据其函数参数中指定的毫秒数等待您的按键。如果为零,它将无限期等待。按键将以其整数代码点形式返回,在这种情况下,您将其忽略了。作为一种良好做法,您在程序结束之前关闭了窗口。
将其全部结合起来
|
1 2 3 4 5 6 |
import cv2 image = cv2.imread("path/filename.jpg", cv2.IMREAD_GRAYSCALE) cv2.imshow("我的图像", 图像) cv2.waitKey(0) cv2.destroyAllWindows() |
您的任务
修改上面的代码,将路径指向您磁盘中的图像并尝试一下。您如何修改上面的代码,使其等待直到按下 Esc 键,但忽略所有其他键?(提示:Esc 键的代码点是 27)
在下一课中,您将看到如何查找图像中的模式。
第 03 课:查找圆形
由于数字图像表示为矩阵,您可以设计您的算法并检查图像的每个像素以识别图像中是否存在某些模式。多年来,已经发明了许多巧妙的算法,您可以在任何数字图像处理教科书中学习其中一些。
在本迷你课程中,您将解决一个简单的问题:给定一张包含许多硬币的图像,识别并计数特定类型的硬币。硬币是圆形。要识别图像中的圆形,一个有前景的算法是使用霍夫圆变换。
霍夫变换是一种利用图像梯度信息的算法。因此,它作用于灰度图像而不是彩色图像。要将彩色图像转换为灰度,您可以使用 OpenCV 中的 cv2.cvtColor() 函数。由于霍夫变换基于梯度信息,它对图像噪声敏感。应用高斯模糊是减少霍夫变换噪声的常用预处理步骤。在代码中,您对读取的 BGR 图像应用以下操作
|
1 2 3 |
... gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) |
此处使用 $25\times 25$ 核应用高斯模糊。您可以根据图像中的噪声水平使用更小或更大的核。
霍夫圆变换用于从图像中查找圆形,使用以下函数
|
1 2 |
circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) |
参数很多。第一个参数是灰度图像,第二个是要使用的算法。其余参数如下
dp: 图像分辨率与累加器分辨率之比。通常使用 1.0 到 2.0。minDist: 检测到的圆形中心之间的最小距离。值越小,假阳性越多。param1这是 Canny 边缘检测器的阈值param2: 当使用算法cv2.HOUGH_GRADIENT时,这是累加器阈值。值越小,误报越多。minRadius和maxRadius: 要检测的最小和最大圆形半径
函数 cv2.HoughCircles() 的返回值是一个 NumPy 数组,其中包含圆形,表示为包含中心坐标和半径的行。
让我们尝试使用一个示例图像
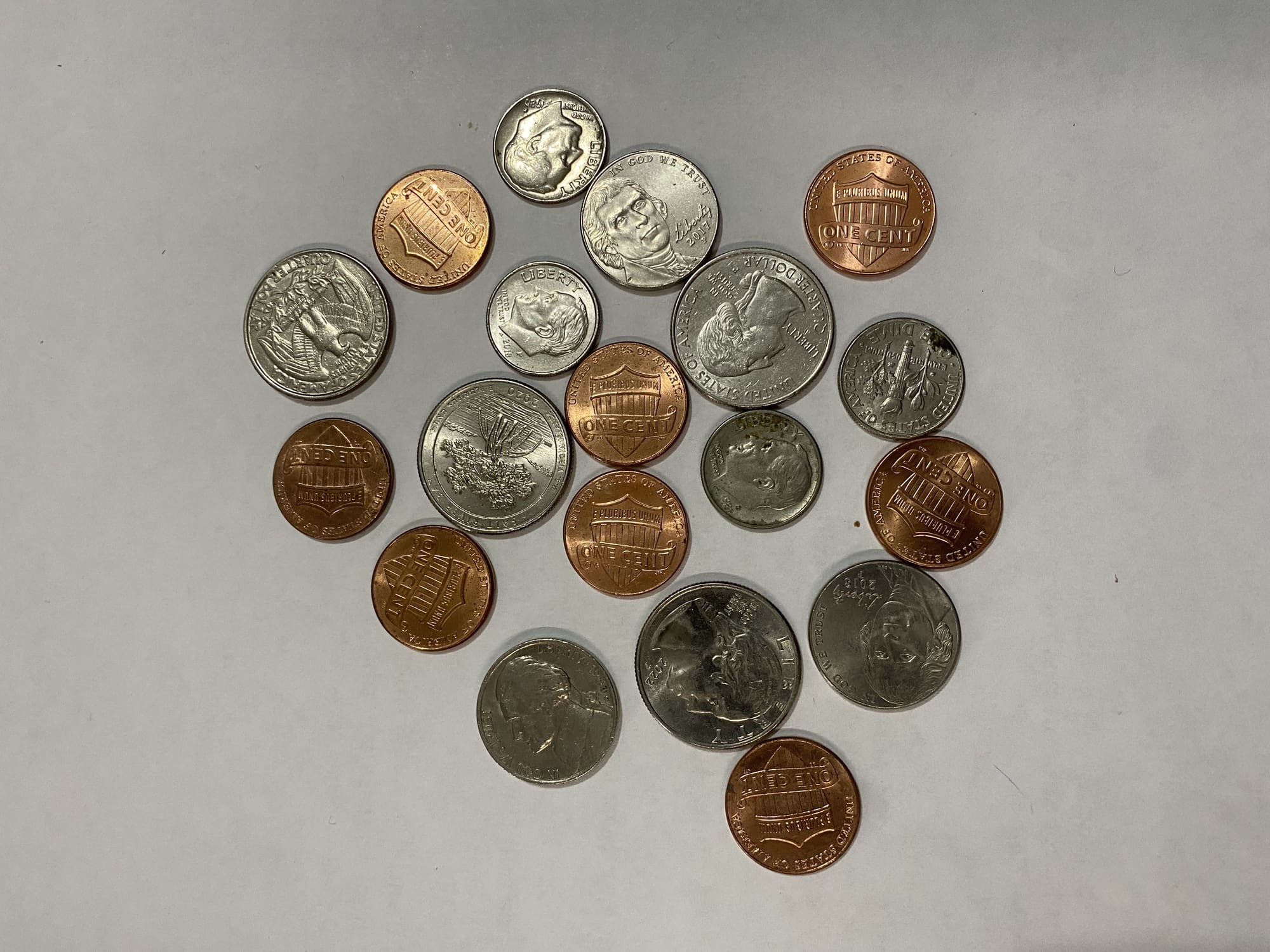
硬币
下载图像,将其另存为 coins-1.jpg,然后运行以下代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import cv2 import numpy as np image_path = "coins-1.jpg" img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) if circles is not None: for c in np.uint16(np.round(circles[0])): cv2.circle(img, (c[0], c[1]), c[2], (255,0,0), 10) cv2.circle(img, (c[0], c[1]), 2, (0,0,255), 20) cv2.imshow("圆形", img) cv2.waitKey() cv2.destroyAllWindows() |

蓝色检测到的圆形,红色中心
上面的代码首先将检测到的圆形数据四舍五入并转换为整数。然后相应地在原始图像上绘制圆形。从上面的插图中,您可以看到霍夫圆变换如何帮助您很好地找到图像中的硬币。
进一步阅读
- P. E. Hart. “霍夫变换是如何发明的”. IEEE 信号处理杂志, 26(6), 2009 年 11 月, 第 18–22 页. DOI: 10.1109/msp.2009.934181。
- R. O. Duda 和 P. E. Hart. “使用霍夫变换检测图片中的线条和曲线”. Comm. ACM, 15, 1 月 11–15 日. DOI: 10.1145/361237.361242。
您的任务
检测对您提供给 cv2.HoughCircles() 函数的参数很敏感。尝试修改参数并查看其结果。您还可以尝试为不同的图片找到最佳参数,尤其是那些具有不同光照条件或不同分辨率的图片。
在下一课中,您将看到如何根据检测到的圆形从图像中提取硬币。
第 04 课:提取子图像
您使用 OpenCV 读取的图像是一个 NumPy 数组,其形状为高度×宽度×通道。要提取图像的一部分,您只需使用 NumPy 切片语法。例如,从 BGR 彩色图像中,您可以使用以下方式提取红色通道
|
1 |
red = img[:, :, 2] |
因此,要提取图像的一部分,您可以使用
|
1 |
subimg = img[y0:y1, x0:x1] |
这样您将获得较大图像的一个矩形部分。请记住,在矩阵中,您首先从上到下计算垂直元素(像素),然后从左到右计算水平元素。因此,您应该在切片语法中首先描述 $y$ 坐标范围。
让我们修改上一课中的代码,以提取我们找到的每个硬币
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import cv2 import numpy as np image_path = "coins-1.jpg" img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) for c in np.uint16(np.round(circles[0])): x, y, r = c subimg = img[y-r:y+r, x-r:x+r] cv2.imshow("硬币", subimg) cv2.waitKey(0) cv2.destroyAllWindows() |
这段代码为霍夫变换找到的每个圆形提取一个正方形子图像。然后子图像显示在一个窗口中,并等待您的按键,直到显示下一个图像。

OpenCV 窗口显示一个检测到的硬币
您的任务
运行此代码。您会注意到每个检测到的圆形可能大小不同,提取的子图像也如此。您如何调整子图像的大小,使其在窗口中显示时保持一致?
在下一课中,您将学习如何将提取的子图像与参考图像进行比较。
第 05 课:匹配硬币
我们的任务是识别并计数图像中的美分硬币。您可以从 维基百科 获取美国美分硬币的图像。
以这张图像作为参考,您如何将识别出的硬币与参考进行比较?这是一个比听起来更困难的问题。旧硬币可能生锈、暗淡或有划痕。图片中的硬币可能旋转了。比较像素并判断它们是否是同一枚硬币并不容易。
更好的方法是使用关键点匹配算法。OpenCV 中有几种关键点算法。让我们尝试 ORB,这是 OpenCV 团队的一项发明。从上面链接下载参考图像,并将其保存为 penny.png,您可以使用以下代码提取关键点和关键点描述符
|
1 2 3 4 5 6 |
import cv2 reference_path = "penny.png" sample = cv2.imread(reference_path) orb = cv2.ORB_create(nfeatures=500) kp, ref_desc = orb.detectAndCompute(sample, None) |
元组 kp 是关键点对象,但不如 ref_desc 数组重要,后者是关键点描述符。这是一个 NumPy 数组,形状为 $K\times 32$,表示检测到的 $K$ 个关键点。每个关键点的 ORB 描述符是一个 32 个整数的向量。
如果您从另一张图像中获取描述符,您可以将其与参考描述符进行比较,以查看是否有任何关键点匹配。您不应该期望描述符完全匹配。相反,您可以应用 Lowe's 比例测试 来判断关键点是否匹配
|
1 2 3 4 5 |
... bf = cv2.BFMatcher() kp, desc = orb.detectAndCompute(coin_gray, None) matches = bf.knnMatch(ref_desc, desc, k=2) count = len([1 for m, n in matches if m.distance < 0.80*n.distance]) |
在这里,您使用 cv2.BFMatcher() 的暴力匹配器来运行 kNN 算法,以获取每个参考关键点到候选图像关键点的两个最近邻。然后比较向量距离(距离越短意味着匹配越好)。Lowe 比例测试用于判断匹配是否足够好。您可以尝试使用与上面 0.8 不同的常数。我们计算良好匹配的数量,如果找到足够多的良好匹配,我们将声称硬币已被识别。
下面是完整的代码,我们将使用 Matplotlib 显示和识别找到的每个硬币。由于 Matplotlib 期望彩色图像采用 RGB 通道而不是 BGR 通道,因此您需要在使用 plt.imshow() 显示图像之前使用 cv2.cvtColor() 转换图像。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import math import cv2 import numpy as np import matplotlib.pyplot as plt image_path = "coins-1.jpg" reference_path = "penny.png" img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) sample = cv2.imread(reference_path) orb = cv2.ORB_create(nfeatures=500) bf = cv2.BFMatcher() kp, ref_desc = orb.detectAndCompute(sample, None) plt.figure(2) N = len(circles[0]) rows = math.ceil(N / 4) for i, c in enumerate(np.uint16(np.round(circles[0]))): x, y, r = c coin = img[y-r:y+r, x-r:x+r] coin_gray = cv2.cvtColor(coin, cv2.COLOR_BGR2GRAY) kp, desc = orb.detectAndCompute(coin_gray, None) matches = bf.knnMatch(ref_desc, desc, k=2) count = len([1 for m, n in matches if m.distance < 0.80*n.distance]) plt.subplot(rows, 4, i+1) plt.imshow(cv2.cvtColor(coin, cv2.COLOR_BGR2RGB)) plt.title(f"{count}") plt.axis('off') plt.show() |
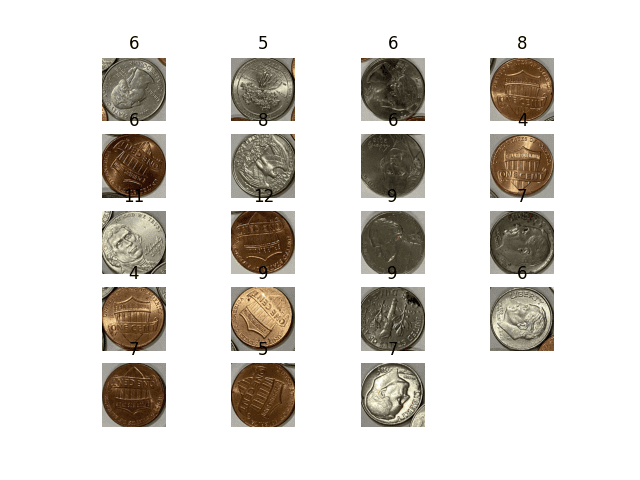
检测到的硬币和匹配的关键点数量
您可以看到,匹配的关键点数量不能提供明确的指标来帮助将美分硬币与其他硬币区分开来。您能想到除了 kNN 之外可能有用的其他算法吗?
进一步阅读
您的任务
上面的代码使用了 ORB 关键点。您也可以尝试 SIFT 关键点。如何修改上面的代码?您会看到匹配关键点数量的变化吗?此外,由于 ORB 特征是向量。您能否构建一个逻辑回归分类器来识别良好的关键点,从而不需要依赖参考图像?
在下一课中,您将研究一个更好的硬币识别器。
第 06 课:构建硬币分类器
给定一枚硬币的图像,并识别它是否是美国便士硬币,对人类来说很容易,但对计算机来说却不是。众所周知,进行这种分类的最佳方法是使用机器学习。您应该首先从图像中提取特征向量,然后运行机器学习算法作为分类器来判断它是否匹配。
决定使用哪个特征本身就是一个难题。但是,如果您使用卷积神经网络,您可以让机器学习算法自己找出特征。但是要训练神经网络,您需要数据。幸运的是,您不需要太多。让我们看看如何构建一个。
首先,您可以在这里找到一些硬币的图片
- https://machinelearning.org.cn/wp-content/uploads/2024/01/coins-2.jpg
- https://machinelearning.org.cn/wp-content/uploads/2024/01/coins-3.jpg

要提取为数据集以训练神经网络的硬币图片
将它们保存为 coins-2.jpg 和 coins-3.jpg,然后使用霍夫圆变换提取硬币图像,并将它们保存到 dataset 目录中
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import cv2 import numpy as np idx = 1 for image_path in ["coins-2.jpg", "coins-3.jpg"]: img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) for c in np.uint16(np.around(circles[0])): x, y, r = c cv2.imwrite(f"dataset/{idx}.jpg", img[y-r:y+r, x-r:x+r]) idx += 1 |
图片不多。您可以手动将每张图片标记为便士硬币(正例)或非便士硬币(负例)。一种方法是将正例样本移动到子目录 dataset/pos 中,将负例样本移动到 dataset/neg 中。为了您的方便,您可以在 zip 文件 此处 找到标记图像的副本。
有了这些,让我们使用 Keras 和 TensorFlow 为这个二分类问题构建一个卷积神经网络。
在数据准备阶段,您将读取每个正例和负例图像样本。为了简化卷积神经网络,您首先将图像大小调整为 $256\times 256$ 像素,以固定输入大小。为了增加数据集中的变化,您可以将每个图像旋转 90、180 和 270 度并添加到数据集中(因为图像样本都是正方形,所以这很容易)。然后,您可以使用 scikit-learn 中的 train_test_split() 函数以 7:3 的比例将数据集分为训练集和测试集。
要创建模型,您可以使用多个 Conv2D 层和 MaxPooling 的分类架构,然后是输出处的 Dense 层。请注意,这是一个二分类模型。因此,在最终输出层,您应该使用 sigmoid 激活函数。
在训练时,您可以简单地使用大量的迭代次数(例如,epochs=200)并进行早期停止,这样您就不必担心欠拟合。您应该监控测试集上评估的损失,以确保不会出现过拟合。在代码中,您可以这样训练模型并将模型保存为 penny.h5
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import glob import cv2 import numpy as np from sklearn.model_selection import train_test_split from tensorflow.keras.callbacks import EarlyStopping from tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, Flatten from tensorflow.keras.models import Sequential images = [] labels = [] for filename in glob.glob("dataset/pos/*"): img = cv2.imread(filename) img = cv2.resize(img, (256,256)) images.append(img) labels append(1) for _ in range(3): img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE) images.append(img) labels append(1) for filename in glob.glob("dataset/neg/*"): img = cv2.imread(filename) img = cv2.resize(img, (256,256)) images.append(img) labels append(0) for _ in range(3): img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE) images.append(img) labels append(0) images = np.array(images) labels = np.array(labels) X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.3) model = Sequential([ Conv2D(16, (5,5), input_shape=(256,256,3), padding="same", activation="relu"), MaxPooling2D((2,2)), Conv2D(32, (5,5), activation="relu"), MaxPooling2D((2,2)), Conv2D(64, (5,5), activation="relu"), MaxPooling2D((2,2)), Conv2D(128, (5,5), activation="relu"), Flatten(), Dense(256, activation="relu"), Dense(1, activation="sigmoid") ]) # 训练 earlystopping = EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True) model.compile(loss="binary_crossentropy", optimizer="adagrad", metrics=["accuracy"]) model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=200, batch_size=32, callbacks=[earlystopping]) model.save("penny.h5") |
观察其输出,您应该很容易看到准确率在不多次迭代后达到 90% 以上。
您的任务
运行上面的代码,并在 penny.h5 中创建一个训练好的模型,您将在下一课中使用它。
您可以修改模型设计,看看是否可以提高准确性。您可以尝试的一些想法是:使用不同数量的 Conv2D-MaxPooling 层,不同大小的每个层(除了上面 16-32-64-128 之外),或者使用 ReLU 以外的激活函数。
在下一课中,您将把在 Keras 中创建的模型转换为在 OpenCV 中使用。
第 07 课:在 OpenCV 中使用 DNN 模块
既然您已经在上一课中构建了一个卷积神经网络,现在可以将其与 OpenCV 一起使用了。如果您先将其转换为 ONNX 格式,OpenCV 将更容易使用您的模型。为此,您需要 Python 中的 tf2onnx 模块。安装后,您可以使用以下命令转换模型
|
1 |
python -m tf2onnx.convert --keras penny.h5 --output penny.onnx |
当您将 Keras 模型保存为 penny.h5 时,此命令将创建文件 penny.onnx。
有了 ONNX 模型文件,您现在可以使用 OpenCV 的 cv2.dnn 模块。用法如下
|
1 2 3 4 5 |
import cv2 net = cv2.dnn.readNetFromONNX("penny.onnx") net.setInput(blob) output = float(net.forward()) |
也就是说,您使用 OpenCV 创建一个神经网络对象,分配输入,然后运行 forward() 模型来获取输出,根据您设计模型的方式,输出是一个介于 0 和 1 之间的浮点值。根据神经网络的约定,即使您只提供一个输入样本,输入也是批处理的。因此,在将图像发送到神经网络之前,您应该为图像添加批处理维度。
现在让我们看看如何实现数便士的目标。您可以从修改第 05 课的代码开始,如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import math import cv2 import numpy as np import matplotlib.pyplot as plt image_path = "coins-1.jpg" model_path = "penny.onnx" img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) plt.figure(2) N = len(circles[0]) rows = math.ceil(N / 4) net = cv2.dnn.readNetFromONNX("penny2.onnx") for i, c in enumerate(np.uint16(np.round(circles[0]))): x, y, r = c coin = img[y-r:y+r, x-r:x+r] coin = cv2.resize(coin, (256,256)) blob = coin[np.newaxis, ...] net.setInput(blob) score = float(net.forward()) plt.subplot(rows, 4, i+1) plt.imshow(cv2.cvtColor(coin, cv2.COLOR_BGR2RGB)) plt.title(f"{score:.2f}") plt.axis('off') plt.show() |
我们没有使用 ORB 并计算良好关键点来匹配,而是使用卷积神经网络读取 S 型输出。输出如下
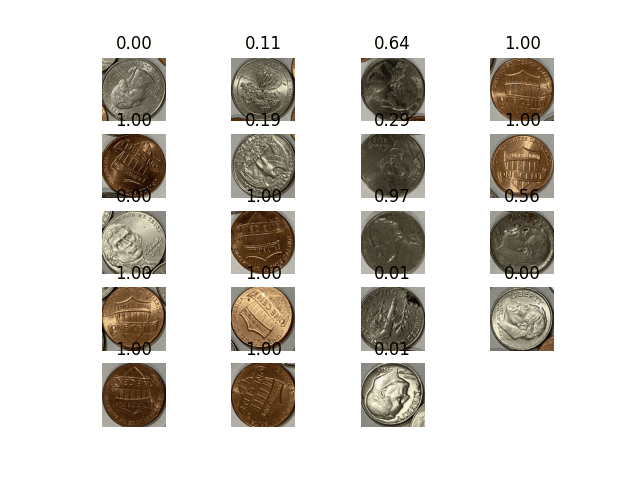
检测到的硬币和神经网络的匹配分数
您可以看到这个模型的结果相当不错。所有便士都以接近 1 的分数被识别。负样本效果不佳(可能是因为我们没有提供足够的负样本)。让我们使用 0.9 作为分数截止值,并重写程序以给出计数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import math import cv2 import numpy as np import matplotlib.pyplot as plt image_path = "coins-1.jpg" model_path = "penny.onnx" img = cv2.imread(image_path) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur = cv2.GaussianBlur(gray, (25,25), 1) circles = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=80, param2=60, minRadius=90, maxRadius=150) positive = 0 negative = 0 net = cv2.dnn.readNetFromONNX(model_path) for i, c in enumerate(np.uint16(np.round(circles[0]))): x, y, r = c coin = img[y-r:y+r, x-r:x+r] coin = cv2.resize(coin, (256,256)) blob = coin[np.newaxis, ...] net.setInput(blob) score = float(net.forward()) 如果 分数 >= 0.9: 正面 += 1 else: 反面 += 1 打印(f"{positive} out of {positive+negative} coins identified are pennies") |
您的任务
运行上述代码进行测试。你也可以尝试另一张图片,比如这张
你能修改上面的代码,使其能连续读取网络摄像头图像并报告计数吗?
这是最后一课。
结束!(看看你已经走了多远)
您做到了。干得好!
花点时间回顾一下您已经走了多远。
- 除了图像处理功能,你还发现了 OpenCV 作为一种机器学习库。
- 你利用 OpenCV 提取图像特征作为数值向量,这是任何机器学习算法的基础。
- 你构建了一个神经网络模型,并将其转换为与 OpenCV 一起使用。
- 最后,你构建了一个硬币计数程序。虽然它不完美,但它展示了如何将 OpenCV 与机器学习结合起来。
不要轻视这一点,你在短时间内取得了长足的进步。这只是你计算机视觉与机器学习之旅的开始。继续练习和发展你的技能。
总结
您对这个迷你课程的学习情况如何?
您喜欢这个速成课程吗?
您有任何问题吗?有没有遇到什么难点?
告诉我。在下面留言。
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块






{kind=link}
{kind=link}
{kind=link}
{kind=link}
您好,Adrian Tam,
您的迷你课程非常好。它对深度学习很有用。
当我运行此代码 model.save(“penny.h5”) 时,显示以下错误。我在 stackoverflow 其他网站上尝试过,但还没有得到解决方案
Message=无法同步创建数据集(名称已存在)
Source=G:\Python Projects\PythonApplication1\PythonApplication1.py
StackTrace
File “G:\Python Projects\PythonApplication1\PythonApplication1.py”, line 101, in (当前帧)
model.save(“penny.h5”)
ValueError: 无法同步创建数据集(名称已存在)
你好 Amrut…你遇到的错误,
ValueError: 无法同步创建数据集(名称已存在),通常发生在尝试将模型保存到已存在的文件时。这可能是因为文件被另一个进程锁定,或者与 Keras 使用的 HDF5 文件格式存在冲突。以下是解决此问题的一些步骤:
1. **检查文件是否存在并删除它:**
在保存模型之前,检查文件
penny.h5是否已存在,如果必要,将其删除。这可以确保与现有文件没有冲突。pythonimport os
if os.path.exists("penny.h5")
os.remove("penny.h5")
model.save("penny.h5")
2. **确保文件未打开或锁定:**
确保
penny.h5未在其他应用程序中打开或被其他进程锁定。您可以重新启动 Python 环境或系统,以确保没有其他进程正在使用该文件。3. **使用不同的文件名:**
有时,简单地使用不同的文件名就可以解决问题。
python
model.save("penny_new.h5")
4. **更新 h5py 和 TensorFlow/Keras:**
确保您已安装最新版本的
h5py和TensorFlow/Keras,因为此问题可能与这些库中已在新版本中修复的错误有关。bash
pip install --upgrade h5py tensorflow keras
5. **以不同格式保存模型:**
如果问题仍然存在,您可以以不同的格式保存模型,例如 TensorFlow SavedModel 格式。
python
model.save("penny_saved_model", save_format="tf")
如果您已尝试上述所有步骤但问题仍然存在,请提供有关您的环境(例如 TensorFlow、Keras 和 h5py 的版本)以及您正在运行的确切代码的更多详细信息。这将有助于进一步诊断问题。
你好 James
请帮助解决这个问题
python -m tf2onnx.convert –keras penny.h5 –output penny.onnx 出现错误
AttributeError: 模块 'keras._tf_keras.keras.backend' 没有属性 'set_learning_phase'