您想使用 R 进行机器学习,但却难以入门吗?
在本篇文章中,您将使用 R 完成您的第一个机器学习项目。
在本循序渐进的教程中,您将:
- 下载并安装 R,并获取 R 中最有用的机器学习包。
- 加载数据集,并通过统计摘要和数据可视化来了解其结构。
- 创建 5 个机器学习模型,挑选出最好的模型,并确信其准确性是可靠的。
如果您是机器学习初学者,并希望最终开始使用 R,本教程是为您量身定制的。
借助我的新书 《R 语言机器学习精通》,包括循序渐进的教程和所有示例的R 源代码文件,来**启动您的项目**。
让我们开始吧!

R 语言的第一个机器学习项目:一步一步指南
照片由 Henry Burrows 拍摄,保留部分权利。
如何开始 R 语言的机器学习?
学习机器学习的最佳方式是设计并完成小型项目。
R 语言在入门时可能会令人望而生畏
R 是一种语法有些奇怪的脚本语言。此外,还有数百个包和数千个函数可供选择,提供了多种完成任务的方式。这可能会让人感到不知所措。
开始使用 R 语言进行机器学习的最佳方法是完成一个项目。
- 它将迫使您至少安装和启动 R。
- 它将让您对如何逐步完成小型项目有一个鸟瞰图。
- 它将为您带来信心,或许还能激励您开始自己的小型项目。
初学者需要一个小型端到端项目
书籍和课程会令人沮丧。它们为您提供了大量的“食谱”和代码片段,但您从未能看到它们如何协同工作。
当您将机器学习应用于自己的数据集时,您就是在进行一个项目。
机器学习项目的过程可能不是线性的,但有一些众所周知的步骤:
- 定义问题。
- 准备数据。
- 评估算法。
- 改进结果。
- 呈现结果。
有关机器学习项目步骤的更多信息,请参阅此清单和更多关于流程的内容。
真正掌握一个新平台或工具的最佳方法是端到端地完成一个机器学习项目,涵盖关键步骤,即从加载数据、汇总数据、评估算法到进行预测。
如果您能做到这一点,您就拥有了一个可以用于一个又一个数据集的模板。一旦您有了更多的信心,就可以稍后填补诸如进一步数据准备和改进结果等方面的空白。
机器学习的“Hello World”
在新工具上开始的最佳小型项目是鸢尾花分类(例如,鸢尾花数据集)。
这是一个很好的项目,因为它非常成熟。
- 属性是数值型的,因此您必须弄清楚如何加载和处理数据。
- 这是一个分类问题,允许您练习可能更简单的监督学习算法。
- 这是一个多类分类问题(多项式),可能需要一些专门的处理。
- 它只有 4 个属性和 150 行,这意味着它很小,并且可以轻松地放入内存(以及屏幕或 A4 纸)。
- 所有数值属性都具有相同的单位和相同的尺度,无需任何特殊的缩放或转换即可开始。
让我们开始您的 R 语言机器学习“Hello World”项目。
需要更多关于R机器学习的帮助吗?
参加我为期14天的免费电子邮件课程,了解如何在您的项目中使用R(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
R 语言机器学习:循序渐进的教程(从这里开始)
在本节中,我们将端到端地完成一个小型机器学习项目。
以下是我们即将涵盖的内容概述:
- 安装 R 平台。
- 加载数据集。
- 汇总数据集。
- 可视化数据集。
- 评估一些算法。
- 进行一些预测。
慢慢来。逐步完成每个步骤。
尝试自己输入命令,或者复制粘贴命令以加快速度。
如有任何问题,请在文章底部留言。
1. 下载、安装和启动 R
如果您的系统尚未安装 R 平台,请将其安装好。
更新:本教程是使用 R 版本 3.2.3 编写和测试的。建议您使用此版本或更高版本的 R。
我不想详细介绍,因为其他人已经做过了。这已经相当直接了,特别是如果您是开发人员。如果您确实需要帮助,请在评论中提问。
以下是我们将在此步骤中涵盖的内容:
- 下载 R。
- 安装 R。
- 启动 R。
- 安装 R 包。
1.1 下载 R
您可以从 R 项目网页下载 R。
当您单击下载链接时,您将需要选择一个镜像。然后,您可以为您的操作系统选择 R,例如 Windows、OS X 或 Linux。
1.2 安装 R
R 很容易安装,我相信您能处理好。它没有特殊要求。如果您有关于安装的问题或需要帮助,请参阅 R 安装与管理。
1.3 启动 R
您可以从操作系统使用的任何菜单系统启动 R。
对我来说,我更喜欢命令行。
打开您的命令行,切换(或创建)到您的项目目录,然后键入以下命令来启动 R:
|
1 |
R |
您应该会在新窗口或终端中看到类似下图的截图。
R 交互式环境
1.4 安装包
安装我们今天要使用的包。包是我们可以用在 R 中的第三方附加组件或库。
|
1 |
install.packages("caret") |
更新:我们可能还需要其他包,但 caret 应该会询问我们是否要加载它们。如果您在使用包时遇到问题,可以通过键入以下命令来安装 caret 包以及您可能需要的所有包:
|
1 |
install.packages("caret", dependencies=c("Depends", "Suggests")) |
现在,让我们加载我们将在本教程中使用到的包,即 caret 包。
|
1 |
library(caret) |
caret 包为数百种机器学习算法提供了一致的接口,并提供了有用的便捷方法,用于数据可视化、数据重采样、模型调优和模型比较等功能。它是 R 语言机器学习项目的必备工具。
有关 caret R 包的更多信息,请参阅 caret 包主页。
2. 加载数据
我们将使用鸢尾花数据集。这个数据集很有名,因为它几乎被所有人用作机器学习和统计学的“Hello World”数据集。
该数据集包含 150 个鸢尾花样本。有四列是鸢尾花的测量值,单位为厘米。第五列是观察到的花的种类。所有观察到的花都属于三个种类之一。
您可以在维基百科上了解更多关于这个数据集的信息。.
以下是我们将在这一步中进行的操作:
- 以简单的方式加载鸢尾花数据。
- 从 CSV 加载鸢尾花数据(可选,仅为纯粹主义者)。
- 将数据分为训练数据集和验证数据集。
选择您喜欢的数据加载方式,或尝试两种方法。
2.1 以简单方式加载数据
幸运的是,R 平台为我们提供了鸢尾花数据集。按如下方式加载数据集:
|
1 2 3 4 |
# 将 iris 数据集附加到环境中 data(iris) # 重命名数据集 dataset <- iris |
现在您已经在 R 中加载了鸢尾花数据,可以通过 `dataset` 变量访问。
我喜欢将加载的数据命名为“dataset”。如果您想在项目之间复制粘贴代码,并且数据集始终具有相同的名称,这样做会很有帮助。
2.2 从 CSV 加载
也许您是个纯粹主义者,您想像在自己的机器学习项目中所做的那样,从 CSV 文件加载数据。
按如下方式从 CSV 文件加载数据集:
|
1 2 3 4 5 6 |
# 定义文件名 filename <- "iris.csv" # 从本地目录加载 CSV 文件 dataset <- read.csv(filename, header=FALSE) # 设置数据集中的列名 colnames(dataset) <- c("Sepal.Length","Sepal.Width","Petal.Length","Petal.Width","Species") |
现在您已经在 R 中加载了鸢尾花数据,可以通过 `dataset` 变量访问。
2.3. 创建验证数据集
我们需要知道我们创建的模型是否够好。
稍后,我们将使用统计方法来估计我们创建的模型在未见过的数据上的准确性。我们还希望通过在实际未见过的数据上进行评估,来获得对最佳模型在未见过的数据上的准确性的更具体的估计。
也就是说,我们将留出一部分数据,算法将无法看到这些数据,我们将使用这些数据来获得对最佳模型实际可能有多准确的第二次独立看法。
我们将把加载的数据集分成两部分,其中 80% 用于训练模型,20% 作为验证数据集保留。
|
1 2 3 4 5 6 |
# 创建原始数据集中 80% 的行的列表,可用于训练 validation_index <- createDataPartition(dataset$Species, p=0.80, list=FALSE) # 选择 20% 的数据用于验证 validation <- dataset[-validation_index,] # 使用剩余的 80% 数据来训练和测试模型 dataset <- dataset[validation_index,] |
现在您已将训练数据存储在 `dataset` 变量中,并将验证集存储在稍后将使用的 `validation` 变量中。
请注意,我们用数据集的 80% 样本替换了我们的 dataset 变量。这是为了使其余代码更简洁易读。
3. 汇总数据集
现在是时候看看数据了。
在本节中,我们将以几种不同的方式查看数据:
- 数据集的维度。
- 属性的类型。
- 数据的预览。
- 类别属性的级别。
- 每个类别中实例的分布。
- 所有属性的统计摘要。
不用担心,每一次数据查看都只需要一个命令。这些命令很有用,您可以在未来的项目中反复使用。
3.1 数据集维度
我们可以通过 `dim` 函数快速了解数据包含多少实例(行)和多少属性(列)。
|
1 2 |
# 数据集维度 dim(dataset) |
您应该看到 120 个实例和 5 个属性。
|
1 |
[1] 120 5 |
3.2 属性类型
了解属性的类型是一个好主意。它们可以是双精度浮点数、整数、字符串、因子等类型。
了解类型很重要,因为它会让您知道如何更好地汇总您拥有的数据,以及在使用转换来准备数据后再进行建模。
|
1 2 |
# 列出每个属性的类型 sapply(dataset, class) |
您应该看到所有输入都是双精度浮点数,而类别值是因子。
|
1 2 |
Sepal.Length Sepal.Width Petal.Length Petal.Width Species "numeric" "numeric" "numeric" "numeric" "factor" |
3.3 预览数据
实际查看数据也总是一个好主意。
|
1 2 |
# 预览数据的前 5 行 head(dataset) |
您应该看到数据的前 5 行。
|
1 2 3 4 5 6 7 |
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa |
3.4 类别的级别
类别变量是因子。因子是一种具有多个类别标签或级别的类别。让我们看看这些级别:
|
1 2 |
# 列出类别的级别 levels(dataset$Species) |
请注意,上面我们可以通过名称将属性引用为数据集的一个属性。在结果中,我们可以看到该类别有 3 个不同的标签:
|
1 |
[1] "setosa" "versicolor" "virginica" |
这是一个多类或多项式分类问题。如果有两个级别,它将是一个二元分类问题。
3.5 类别分布
现在让我们看看每个类别包含的实例(行)数。我们可以将其显示为绝对计数和百分比。
|
1 2 3 |
# 总结类别分布 percentage <- prop.table(table(dataset$Species)) * 100 cbind(freq=table(dataset$Species), percentage=percentage) |
我们可以看到每个类别都具有相同数量的实例(40 个,即数据集的 33%)。
|
1 2 3 4 |
freq percentage setosa 40 33.33333 versicolor 40 33.33333 virginica 40 33.33333 |
3.6 统计摘要
最后,我们可以看一下每个属性的摘要。
这包括均值、最小值和最大值,以及一些百分位数(25th、50th 或中位数和 75th,例如,按排序顺序排列的属性值)。
|
1 2 |
# 汇总属性分布 summary(dataset) |
我们可以看到所有数值都具有相同的尺度(厘米)和相似的范围 [0,8] 厘米。
|
1 2 3 4 5 6 7 |
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Min. :4.300 Min. :2.00 Min. :1.000 Min. :0.100 setosa :40 1st Qu.:5.100 1st Qu.:2.80 1st Qu.:1.575 1st Qu.:0.300 versicolor:40 Median :5.800 Median :3.00 Median :4.300 Median :1.350 virginica :40 Mean :5.834 Mean :3.07 Mean :3.748 Mean :1.213 3rd Qu.:6.400 3rd Qu.:3.40 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.40 Max. :6.900 Max. :2.500 |
4. 可视化数据集
现在我们对数据有了基本了解。我们需要通过一些可视化来扩展它。
我们将查看两种图表:
- 单变量图,以便更好地理解每个属性。
- 多变量图,以便更好地理解属性之间的关系。
4.1 单变量图
我们从一些单变量图开始,即每个单独变量的图。
为了方便可视化,最好能只引用输入属性和输出属性。让我们进行设置,将输入属性称为 `x`,输出属性(或类别)称为 `y`。
|
1 2 3 |
# 分离输入和输出 x <- dataset[,1:4] y <- dataset[,5] |
鉴于输入变量是数值型的,我们可以创建每个变量的箱须图。
|
1 2 3 4 5 |
# 在一张图上绘制每个属性的箱须图 par(mfrow=c(1,4)) for(i in 1:4) { boxplot(x[,i], main=names(iris)[i]) } |
这让我们对输入属性的分布有了更清晰的了解。
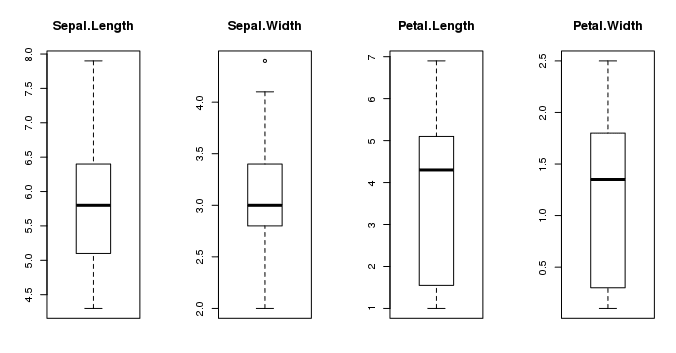
R 语言中的箱须图
我们还可以绘制物种类别变量的条形图,以图形方式表示类别分布(通常不那么有趣,因为它们是均匀的)。
|
1 2 |
# 类别的条形图 plot(y) |
这证实了我们在上一节中学到的内容,即实例在三个类别中分布均匀。
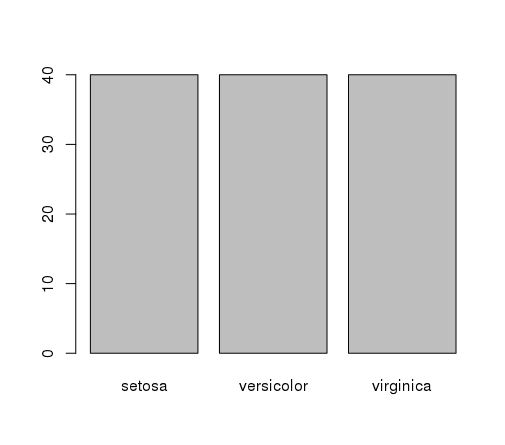
鸢尾花种类的条形图
4.2 多变量图
现在我们可以查看变量之间的交互。
首先,让我们查看所有属性对的散点图,并按类别对点进行着色。此外,由于散点图显示每个类别的点通常是分开的,因此我们可以围绕它们绘制椭圆。
|
1 2 |
# 散点图矩阵 featurePlot(x=x, y=y, plot="ellipse") |
我们可以看到输入属性之间(趋势)以及属性与类别值之间(椭圆)存在明显的关联。

R 语言鸢尾花数据的散点图矩阵
我们还可以再次查看每个输入变量的箱须图,但这次是按每个类别分开绘制的。这有助于区分类之间明显的线性分离。
|
1 2 |
# 每个属性的箱须图 featurePlot(x=x, y=y, plot="box") |
这有助于我们看出每个类别的属性分布存在明显差异。
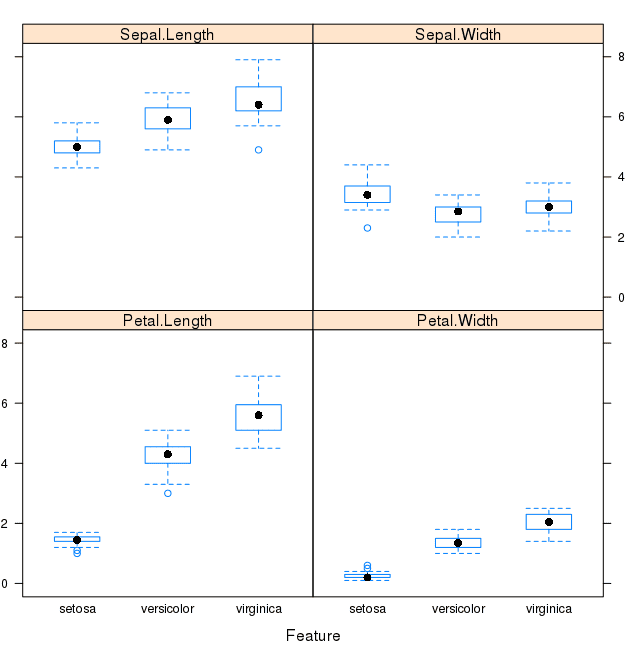
按类别值划分的鸢尾花数据的箱须图
接下来,我们可以通过每个类别的分布来了解每个属性的分布,同样类似于箱须图。有时直方图对此很有用,但在本例中,我们将使用一些概率密度图来为每个分布生成漂亮的平滑曲线。
|
1 2 3 |
# 按类别值划分的每个属性的密度图 scales <- list(x=list(relation="free"), y=list(relation="free")) featurePlot(x=x, y=y, plot="density", scales=scales) |
与箱须图类似,我们可以看到每个属性按类别值的分布差异。我们还可以看到每个属性的类似高斯分布(钟形曲线)。
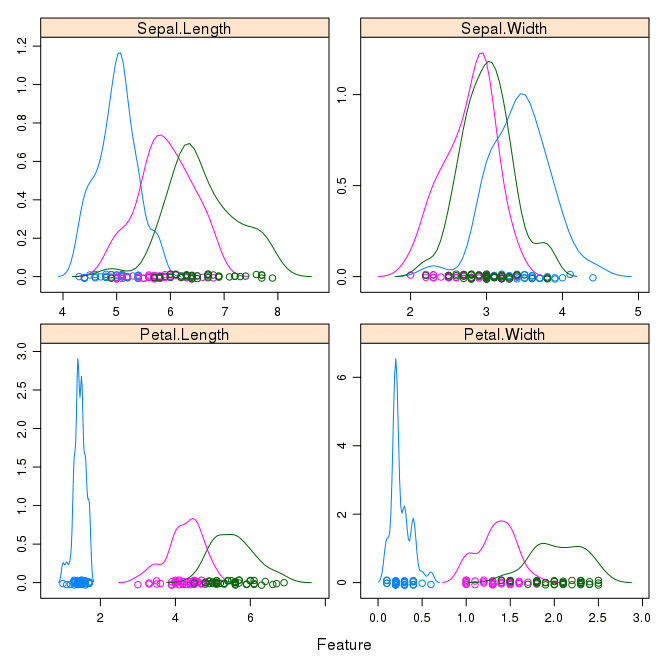
按类别值划分的鸢尾花数据密度图
5. 评估一些算法
现在是时候创建一些数据模型并估计它们在未见过的数据上的准确性了。
以下是我们将在此步骤中涵盖的内容:
- 设置使用 10 折交叉验证的测试框架。
- 构建 5 种不同的模型来预测花的测量值对应的种类。
- 选择最佳模型。
5.1 测试框架
我们将使用 10 折交叉验证来估计准确性。
这将把我们的数据集分成 10 部分,在 9 个部分上训练,在 1 个部分上测试,并对所有训练-测试分割组合进行评估。我们还将对每个算法重复此过程 3 次,使用不同的数据分割成 10 组,以获得更准确的估计。
|
1 2 3 |
# 使用 10 折交叉验证运行算法 control <- trainControl(method="cv", number=10) metric <- "Accuracy" |
我们使用“Accuracy”(准确性)作为评估模型的指标。这是正确预测的实例数除以数据集中的总实例数,再乘以 100 得到百分比(例如,准确性为 95%)。在下一步构建和评估每个模型时,我们将使用 `metric` 变量。
5.2 构建模型
我们不知道哪些算法会在此问题上表现良好,也不知道应使用哪些配置。从图表中我们可以看出,某些类别在某些维度上是部分线性可分的,因此我们预计结果总体上会很好。
让我们评估 5 种不同的算法:
- 线性判别分析 (LDA)
- 分类和回归树 (CART)。
- k-最近邻 (kNN)。
- 具有线性核的支持向量机 (SVM)。
- 随机森林 (RF)
这是一种简单的线性(LDA)、非线性(CART、kNN)和复杂的非线性方法(SVM、RF)的良好混合。我们在每次运行时都会重置随机数种子,以确保使用相同的数据分割来执行每个算法的评估。这确保了结果具有可比性。
让我们构建我们的五个模型:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# a) 线性算法 set.seed(7) fit.lda <- train(Species~., data=dataset, method="lda", metric=metric, trControl=control) # b) 非线性算法 # CART set.seed(7) fit.cart <- train(Species~., data=dataset, method="rpart", metric=metric, trControl=control) # kNN set.seed(7) fit.knn <- train(Species~., data=dataset, method="knn", metric=metric, trControl=control) # c) 高级算法 # SVM set.seed(7) fit.svm <- train(Species~., data=dataset, method="svmRadial", metric=metric, trControl=control) # 随机森林 set.seed(7) fit.rf <- train(Species~., data=dataset, method="rf", metric=metric, trControl=control) |
Caret 支持配置和调优每个模型的配置,但本次教程不会涵盖这方面内容。
5.3 选择最佳模型
现在我们有了 5 个模型以及它们各自的准确率估算。我们需要将这些模型进行比较,并选择最准确的一个。
我们可以通过首先创建一个模型列表并使用 summary 函数来报告每个模型的准确率。
|
1 2 3 |
# 总结模型的准确率 results <- resamples(list(lda=fit.lda, cart=fit.cart, knn=fit.knn, svm=fit.svm, rf=fit.rf)) summary(results) |
我们可以看到每个分类器的准确率,以及 Kappa 等其他指标。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
模型:lda、cart、knn、svm、rf 重采样次数:10 准确度 最小值 四分位数 中位数 平均值 四分位数 最大值 NA值 lda 0.9167 0.9375 1.0000 0.9750 1 1 0 cart 0.8333 0.9167 0.9167 0.9417 1 1 0 knn 0.8333 0.9167 1.0000 0.9583 1 1 0 svm 0.8333 0.9167 0.9167 0.9417 1 1 0 rf 0.8333 0.9167 0.9583 0.9500 1 1 0 Kappa 最小值 四分位数 中位数 平均值 四分位数 最大值 NA值 lda 0.875 0.9062 1.0000 0.9625 1 1 0 cart 0.750 0.8750 0.8750 0.9125 1 1 0 knn 0.750 0.8750 1.0000 0.9375 1 1 0 svm 0.750 0.8750 0.8750 0.9125 1 1 0 rf 0.750 0.8750 0.9375 0.9250 1 1 0 |
我们还可以绘制模型评估结果的图,并比较每个模型的分布和平均准确率。由于每个算法都进行了 10 次评估(10 折交叉验证),因此每个算法都有一个准确率度量集合。
|
1 2 |
# 比较模型的准确率 dotplot(results) |
在此案例中,我们可以看到 LDA 是最准确的模型。

R 中机器学习算法比较:鸢尾花数据集
我们可以总结 LDA 模型的具体结果。
|
1 2 |
# 总结最佳模型 print(fit.lda) |
这很好地总结了用于训练模型的内容以及达到的平均准确率和标准差(SD),具体为 97.5% 的准确率 +/- 4%。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
线性判别分析 120 个样本 4 个预测变量 3 个类别:'setosa'、'versicolor'、'virginica' 无预处理 重采样:交叉验证(10 折) 样本大小摘要:108, 108, 108, 108, 108, 108, ... 重采样结果 准确率 Kappa 准确率 SD Kappa SD 0.975 0.9625 0.04025382 0.06038074 |
6. 进行预测
LDA 是最准确的模型。现在我们想了解模型在验证集上的准确率。
这将为我们提供对最佳模型准确率的独立最终检查。保留验证集很有价值,以防在过拟合训练集或数据泄露等环节出现失误。这两种情况都会导致过于乐观的结果。
我们可以直接在验证集上运行 LDA 模型,并在混淆矩阵中总结结果。
|
1 2 3 |
# 评估 LDA 在验证数据集上的技能 predictions <- predict(fit.lda, validation) confusionMatrix(predictions, validation$Species) |
我们可以看到准确率为 100%。虽然验证数据集较小(20%),但该结果在我们预期的 97% +/-4% 的误差范围内,这表明我们可能拥有一个准确且可靠的模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
混淆矩阵和统计数据 参考 预测 setosa versicolor virginica setosa 10 0 0 versicolor 0 10 0 virginica 0 0 10 总体统计 准确率:1 95%置信区间:(0.8843, 1) 无信息率:0.3333 P值[Acc > NIR]:4.857e-15 Kappa:1 McNemar检验 P值:NA 各类别统计量 类别:setosa 类别:versicolor 类别:virginica 灵敏度 1.0000 1.0000 1.0000 特异度 1.0000 1.0000 1.0000 阳性预测值 1.0000 1.0000 1.0000 阴性预测值 1.0000 1.0000 1.0000 患病率 0.3333 0.3333 0.3333 检测率 0.3333 0.3333 0.3333 检测患病率 0.3333 0.3333 0.3333 平衡准确率 1.0000 1.0000 1.0000 |
你可以在 R 中进行机器学习
完成以上教程。最多需要 5 到 10 分钟!
你不必理解所有内容。(至少现在不用)你的目标是端到端地完成教程并获得结果。你不需要在第一次运行时理解所有内容。在过程中记录下你的问题。大量使用 R 中的?FunctionName帮助语法来了解你使用的所有函数。
你不需要知道算法的工作原理。了解机器学习算法的局限性和配置方法很重要。但算法的学习可以稍后进行。你需要花很长时间慢慢积累算法知识。今天,先从熟悉平台开始。
你不需要是 R 程序员。R 语言的语法可能令人困惑。与其他语言一样,专注于函数调用(例如function())和赋值(例如a <- “b”)。这将让你基本掌握。你是一个开发者,你知道如何快速掌握一门语言的基础。现在就开始,以后再深入细节。
你不需要是机器学习专家。你可以在以后了解各种算法的优点和局限性,并且有很多文章可以供你以后回顾机器学习项目的步骤以及交叉验证评估准确性的重要性。
机器学习项目的其他步骤呢?。我们没有涵盖机器学习项目的所有步骤,因为这是你的第一个项目,我们需要关注关键步骤。即加载数据、查看数据、评估一些算法并进行一些预测。在以后的教程中,我们可以研究其他数据准备和结果改进任务。
总结
在这篇文章中,你了解了如何在 R 中完成你的第一个机器学习项目的详细步骤。
你发现,完成一个小型端到端项目,从加载数据到进行预测,是熟悉新平台的最有效方法。
你的下一步
你是否完成了本教程?
- 完成以上教程。
- 列出你所有的问题。
- 搜索或研究答案。
记住,你可以在 R 中使用?FunctionName来获取任何函数的帮助。
你有什么问题吗?在下面的评论中提出。
在R中发现更快的机器学习!

在几分钟内开发您自己的模型
...只需几行R代码
在我的新电子书中探索如何实现
精通 R 语言机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到您自己的项目中
跳过学术理论。只看结果。






这就是我无法忍受 R(以及 Python、LibreOffice)这样的开源包的地方:没有人付出必要的努力来确保一切正常工作,几乎不可能复制工作环境,而且错误消息非常隐晦难懂。尝试生成上面的散点图矩阵,将命令复制粘贴到 R 中,我收到了以下错误消息:
Error in grid.Call.graphics(L_downviewport, name$name, strict)
Viewport ‘plot_01.panel.1.1.off.vp’ was not found
谷歌搜索没有提供帮助。在让 featurePlot 除了“ellipse”选项之外的所有选项都能工作后,我终于找到了解决方案,那就是你需要在你的系统上安装“ellipse”包。我猜这个包是你系统上的默认库,所以你没有指明使用该函数需要它。但是有多少人会读到这篇帖子并能弄清楚这一点呢?
感谢 Leszek 指出这一点。说实话,我以前没听说过那个包。也许它是随“caret”或“lattice”包一起自动安装的?
感谢您的发帖……安装 ellipse 包后可以工作。并非与 caret 一起安装。
很高兴听到这个消息,Rajendra。
安装 ellipse 包后仍然可以工作。
太棒了!
感谢您的发帖。当我看到错误时,我首先尝试了谷歌搜索,有趣的是,第五个搜索结果就是指向此帖子的链接。 🙂 安装 ellipse 包后可以工作。
感谢 Jason 提供如此出色的学习教程!
很高兴听到这个消息!
文本中最重要的缺失信息
install.packages(“ellipse”)
谢谢 Rajendra!!!
谢谢您的提示!
他没有将“ellipse”包作为其系统上的默认包。他所做的是使用他上面提供的代码安装了“caret”包:
install.packages(“caret”, dependencies = c(“Depends”, “Suggests”))
结果是“caret”包可能使用的所有包都一起安装了……包括“ellipse”包。你本可以避免你的沮丧,只要遵循教程中的说明。
错误。我完全按照列出的说明操作,对我来说也不起作用。当我明确安装 ellipse 库时,它就正常工作了。
评论得很好。一如既往地遵循教程的说明。Jason,这是一个很棒的教程,一如既往。
谢谢。
感谢您强调了这个问题。确实,在网上其他地方很难找到解决方案!
谢谢!您的评论救了我!
嗨,Jason,
我最近才开始用 R。教程很棒!
我想问您一个问题,希望能得到您的指导。
去年我购买了一款开发股票交易系统的软件。
它一天可以生成数千个交易系统,
价格历史可以分为三部分:样本内、样本外和验证。
对于每个交易系统和每个价格部分,我都有诸如净利润、回撤、平均交易结果等指标。
我想使用样本内和样本外结果(指标)来尝试预测验证期内的结果(指标)。因此,我可以根据样本内和样本外指标以及算法来确定哪些交易系统表现最好。
在这种特定情况下,您建议使用哪种算法?
再次感谢 Jason!
Sharon
我不知道如何预测股票,据我所知,持续模型是最好的。更多信息请看这里:
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
尽管如此,我还是推荐这种评估时间序列模型的方法。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
我想知道如何评估单个案例。
假设我构建了一个模型来对水果进行分类。我构建了一个模型并用数据对其进行了训练。
但是当这一切都完成后,我想测试一个单独的案例,我该怎么做?
“这是什么水果?”
也许这会有帮助。
https://machinelearning.org.cn/train-final-machine-learning-model/
感谢评论!我遇到了同样的问题。
在执行“创建验证数据集”代码时,我收到了错误:
Error in createDataPartition(dataset$Species, p = 0.8, list = FALSE)
找不到函数“createDataPartition”
在多元图代码中也一样:
Error in featurePlot(x = x, y = y, plot = “ellipse”)
找不到函数“featurePlot”
我该怎么办?
这个可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
一样……解决了没?
此外,在继续操作时,我发现还需要安装和加载其他包,然后得到了一个准确率表,其结果与您的不同,尽管我复制粘贴了所有命令。这让我对 R 中的可复现性没有太大的信心。
发布你的结果!
确实,在 R 中要实现严格可复现的结果是困难的。我认为你需要到处添加很多 `set.seed(...)` 调用,但即使那样也很困难。
你的准确率表之所以不同,主要原因在于“createDataPartition()”函数是随机选择数据集中样本的。这意味着训练集和验证集对于每个人来说基本上是不同的。因此,最终结果也会略有不同。
是的。
关于 `createDataPartition()` 的一点很好。我会在它前面添加一个 `setSeed()`。
嗨,Jason,
当我使用以下查询加载 caret 包时:
> require(caret)
输出
Loading required package: caret
Error in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]])
没有名为‘pbkrtest’的包
此外:警告信息
package ‘caret’ was built under R version 3.2.3
我将 iris 数据集分配给了 dataset2。然后我执行了以下查询:
createDataPartition(dataset2$Species, p=0.80, list=FALSE) 不起作用。当我执行上述查询时,我收到了错误消息。
错误消息
Error: could not find function "createDataPartition"
请告知我哪里出错了。
此致,
Mohan
这看起来是您环境特有的问题。考虑重新安装带有所有依赖项的 caret 包。
install.packages(“caret”, dependencies = c(“Depends”, “Suggests”))
我已将此命令添加到安装包部分,以防其他人发现它有用。
你好,
如果 R 版本为 3.2.1 或更低,caret 包可能不兼容。我遇到了类似的问题。卸载旧版本后,我安装了 R 3.2.3,这解决了错误。
希望这有帮助。
-Rajesh
谢谢 Rajesh,我更新了帖子并添加了使用 R 3.2.3 或更高版本的说明。
感谢分享。我需要再安装一个包(kernlab)来运行 SVM fit,但其他一切都很顺利。这是一次很好的 15 分钟入门!
很高兴听到这个消息,谢谢 CW!
你好 Jason,这是一个有趣的教程,我还在努力学习 Caret。问题是:在散点图矩阵(我认为它来自 caret)中,我们如何知道哪些颜色对应哪个类别?此致 Ajit
这是一个很好的问题。为您的图表添加图例是一个好主意。
在这种情况下,我没有添加图例,因为我们不关心哪个类是哪个类,只关心类的总体分离。键入 ?featurePlot 了解有关添加图例的更多信息。
谢谢 Jason。但更重要的是……代码中的哪个地方您分配了图例(或者图例是自动获取的,即哪个颜色对应哪个类)。如果它是隐式进行的,我怎么知道哪个颜色对应哪个类?
还有另一个问题
它说:“我们将使用 10 折交叉验证来估计准确性。这将把我们的数据集分成 10 部分,在 9 部分上训练,在 1 部分上测试,并针对所有训练-测试分割组合进行发布。我们还将为每种算法重复该过程 3 次,使用不同的数据分组,以期获得更准确的估计。”因此,我应该看到 15 个步骤(每种算法重复 3 次,使用不同的分割),但我们在这里看到 5 个步骤(一次),另外两次在哪里进行? Ajit
嗨 Ajit,
重复次数应该在 trainControl 函数中指定。我读的时候以为 3 是默认值,但根据文档 ?trainControl,似乎不是这样。
根据这个(http://stats.stackexchange.com/questions/44343/in-caret-what-is-the-real-difference-between-cv-and-repeatedcv),
method参数应该是“repeatedcv”而不是“cv”,然后参数repeats应该是 3。trainControl(method=”repeatedcv”, number=10, repeat=3)
您可以验证训练时间会更长,并且图表的置信区间会更小,所以我可能是对的。但是,我不能完全确定这是否正确,因为我不知道如何直观地检查折叠。另外,我不知道如何从拟合中获取每次 cv 和重复的每个单独结果,例如 fit.lda。
谢谢
感谢 Jason 的精彩教程。我通过仔细遵循您的说明,成功地重现了相同的结果。顺便说一句,我查看了上面的一些其他帖子,通过在开头加载 library(caret),大多数依赖项都可以解决。在加载 library(caret) 之前,我确实遇到了一个问题,出现错误:找不到函数“createDataPartition”。加载所需的 library(caret) 解决了此错误。这加载了其他必需的包。
> library(caret)
正在加载所需的包:lattice
正在加载所需的包:ggplot2
>
编码愉快/赚钱愉快!
谢谢 Kiri。
如果有人想进行更多练习,我已经尽力回忆 Chad Hines 和我添加到教程中的代码,以便可以检查 LDA 在训练集上的不匹配情况。感谢 Jason Brownlee 的教程,以及 Kevin Feasel 和 Jamie Dixon 上周协调的 .NET Triangle “R 入门” dojo。
https://github.com/RickPack/R-Dojo/blob/master/RDojo_MachLearn.R
更正:Chad Kimes
谢谢 Rick
嗨,Jason Brownlee,
感谢您的教程。但是,我有一个关于 featurePlot 函数与 plot = “density ” 选项的问题。我无法弄清楚这些图中每个特征的垂直轴的含义。为什么在密度大于 1 的情况下,垂直轴的值会大于 1?
嗨 Jason,非常全面,对我这样的新手来说是很好的练习。我一定会经常回顾这一点。
很高兴您觉得它有用,Johnny。
谢谢 Brownlee。我想知道如何选择最好的模型。一个给出最高准确率的模型就能保证在测试数据上给出最高准确率的结果吗?在此示例中,您通过比较所用模型的准确率来选择 lda 作为最佳模型。但它在测试时可能无法预测得最好。那么我的问题是:我们应该何时选择模型?是在训练模型后还是测试模型后?
我们不能确定我们选择了最好的模型。
我们必须收集证据来支持某个决定。
通过 k 折交叉验证和留存验证数据集进行更多测试可以增加我们的信心。
那么,下一步是什么?
如何才能做得更好?有什么练习吗?有没有什么能在此基础上进行发展的?
当数据中存在“噪声”时会发生什么?我们如何清理它并将其正确地应用于 ML?
好问题 Justin,
我的建议是练习 UCI ML Repo 中的一系列问题,然后一旦您有了信心,就可以开始练习过去的 Kaggle 数据集。
这里有一个很棒的数据集列表可供尝试
https://machinelearning.org.cn/tour-of-real-world-machine-learning-problems/
在 rstudio-ide 中测试。运行正常!需要两个小更改
-1-
# 安装包
install.packages(‘caret’, repos=’http://cran.rstudio.com/’)
library(caret)
-2-
# e1071
install.packages(‘e1071’, dependencies=TRUE)
好极了,谢谢分享 Jerry。
哪个算法需要 e1071?我能够运行所有算法,但需要(或者 R 自己完成了)安装 rpart 和 kernlab 包。
e1071 提供了 caret 使用的各种算法。在此处了解更多信息
https://cran.r-project.cn/web/packages/e1071/index.html
这是这个页面上的一个拼写错误吗?
“机器学习项目可能不是线性的,但(它有)一些众所周知的步骤:“
是的,我本来想谈谈机器学习项目过程的非线性性。
我已修复此拼写错误,谢谢。
这确实是一篇好文章,但由于它是为 ML 学习者设计的,本可以更清晰地详细解释每个部分,例如,4.1 条形图部分,本可以解释理解图的数量。仅仅走一遍没有帮助。
感谢您的反馈 Rajendra。
太棒了,谢谢,我用自己的数据集做到了,但在绘制 ROC 曲线时遇到了麻烦。您能否发布绘制 ROC 曲线的代码?谢谢!
抱歉,我没有例子 Stef,请参阅 pROC 包:https://cran.r-project.cn/web/packages/pROC/index.html
谢谢 Jason,我会看看的。
我刚开始学习 R,并试图使用此教程将我的数据集放入其中,遇到了一些问题,例如缺少包。我确实注意到,当您 library(caret) 时,它会显示缺少的包,因此只需 install.packages(缺少的包名称) 即可。
但是,我想将我的数据集分割得更多一些。本教程使用
“validation_index <- createDataPartition(dataset$Species, p=0.80, list=FALSE)”
我的数据集相当大,我想将其分成 3 或 4 部分,比如,与其进行 80/20 分割,不如进行 50/25/25 或 40/30/30。如我所述,我对 R 还很陌生,如果我的分割方式不正确,请告诉我:)。
嗨 Lewis,
我相信 createDataPartition() 用于创建训练/测试分割。
您可以将其用于创建一个分割,然后根据需要重新分割其中一半。
希望这能有所帮助。
非常好的文章。谢谢。对于我这个 R 新手来说,这是一个很好的开始。
但是我有一个问题是在第 6 部分(“进行预测”)。
我理解我们在该部分中预测模型的准确性。但是,您能否详细说明如何为一些新数据集进行预测?我对预测部分不太清楚。
这非常有帮助。谢谢。但我有一个问题。如果我有两个数据集,我将它们命名为 trainingdata.csv 和 testdata.csv,如何将它们加载到 R 中,然后在训练数据上训练我的算法,并在 test data 上进行测试?
谢谢。
这篇文章将帮助您加载数据
https://machinelearning.org.cn/how-to-load-your-machine-learning-data-into-r/
我知道如何加载这些数据。我的问题是,如果我有两个数据集,训练数据和测试数据。我必须使用哪些函数让 R 识别我的训练数据来构建模型,并识别测试数据来验证模型?这与 Iris 项目不同,在 Iris 项目中,他们有一个数据并将其分割为 80%/20%?
抱歉,我不明白你的问题。也许你可以重新措辞?
在 Iris 项目中,分割数据的函数出现了错误。下面是命令。
> #将 iris 数据集附加到环境中
> data(iris)
> #重命名数据集
> dataset # 创建一个包含原始数据集 80% 行的列表,用于训练
> validation_index validation_index <- createDataPartition(dataset$Species, p=0.80, list=FALSE)
错误:找不到函数“createDataParti
请检查您是否已安装 caret 包。
好文章,谢谢。我成功了。但当我用我的数据替换 iris 时,我得到了一个错误
“Metric Accuracy not applicable for regression models” 对于所有非线性模型。这是我的数据
https://www.dropbox.com/s/ppg0zdfuzz7p0mo/MyData.csv?dl=0
有什么建议吗?
听起来您的输出变量是一个实值(回归),而不是一个标签(分类)。
您可能需要将问题转换为分类问题,或者使用回归算法和评估指标。
谢谢 Jason 的这篇精彩文章,非常有帮助!
不客气 Jonatan。
谢谢您,先生!这真的是最好的教程。我从中学习了很多,并将其应用于了不同的数据集。但是,如何使用 caret 包中的 ROC 曲线来比较模型?
很高兴听到这个消息。
好建议!
在多元变量图中,尝试绘制散点图矩阵时,我收到以下错误:-
Error in grid.Call.graphics(C_downviewport, name$name, strict)
Viewport ‘plot_01.panel.1.1.off.vp’ was not found
我正在使用 R x64 3.4.0。
抱歉,我以前没见过这个错误。也许可以在 stackoverflow 上发布一个问题?
这已经解决了。请在讨论中查看。
1) 您必须安装“ellipse”包,这是缺失的
install.packages(“ellipse”)
2) 如果您将 plot=pairs 更改为,您可以看到输出。如果您想要 ellipse,请安装 ellipse 包。
这非常有趣,先生,但我希望得到关于如何更好地解释图表及其含义的帮助,尤其是散点图。我指的是在我需要向观众解释的情况下。
您可以在此处了解更多关于散点图的信息
https://en.wikipedia.org/wiki/Scatter_plot
对于 print(fit.lda),我没有看到 Accuracy SD 或 Kappa SD 被打印/显示……有什么提示吗?谢谢。
我认为 caret API 自我发布示例以来已经发生了变化。
使用 fit.lda$results 显示标准差
Jason 工作做得很好,但我可以在 R 中绘制 SVM 结果吗?这样我就可以得到超平面和支持向量点?
可以,我很久没做过了。我记不起函数名了,抱歉。
你好 Jason!感谢您制作这个 ML 教程。我在模型构建部分遇到问题。我在“rpart”、“knn”中收到错误。当我运行 rpart 代码时,错误是“Something is wrong: all the accuracy metric values are missing:” “Error: Stopping” “In addition: There were 26 warnings (use warnings() to see them)”,而对于“knn”,我遇到的最后一个错误行是 50 个警告。
此外,当我运行“svmRadial”时,它似乎运行正常,但是当我运行“rf”的代码时,我得到这个
正在加载所需的包:randomForest
randomForest 4.6-12
键入 rfNews() 可查看新功能/更改/错误修复。
正在附加包:‘randomForest’
以下对象已从‘package:dplyr’中屏蔽
combine
以下对象已从‘package:ggplot2’中屏蔽
margin
我的 RStudio 版本是 1.0.136。您的帮助非常感谢!
很抱歉听到这个。请确保您拥有最新版本的 R 和 caret 包。您可能还想安装所有推荐的依赖项。
您是否有适用于回归问题的 R 教程?
是的,搜索“R 回归”
这篇帖子正是我想要的。写得非常好,我很兴奋。我会和 UCSF 的一些学生分享。对于正在阅读评论的人来说,我将所有内容都手动输入,直接从 Brownlee 博士的脚本中输入。你通过这种方式学到更多,因为你在输入时很可能会犯某个错误。
谢谢 Sunny,很高兴您觉得它有用!
这篇帖子很有帮助,但由于我是 ML 和 R 的新手,需要对箱线图和条形图进行更多澄清。您能否向我解释一下?这对我来说会更有帮助
这段代码告诉我们什么?我无法理解,请帮助我
par(mfrow=c(1,4))
for(i in 1:4) {
boxplot(x[,i], main=names(iris)[i])
}
它创建了 4 个并排的组合图表(箱线图)。
sudi,
par(mfrow=c(1,4)) /此代码指定 GUI 使 1 行 4 列的图形显示
for(i in 1:4) { / 此行表示对于 1:4 列中的每一列,执行 { 代码块} 中的内容
boxplot(x[,i], main = names(iris)[i) / 绘制列数据的箱线图,以列名标记
}
非常感谢您,先生。这非常有帮助。先生,我有一个问题。
当我运行 LDA、SVM、RF、CART 模型时,总是显示“Loading required package: MASS”用于 LDA,依此类推用于所有您提到的方法。虽然我得到结果而无需为每种方法加载特定包,但加载特定包或不加载有关系吗?
如果我为每种方法加载包,那么函数会改变,例如对于随机森林,我们需要调用模型:randomForest(...),包为“randomForest”。
caret 加载其预测所需的所有包是正常的。
嗨,我已经安装了“caret”包。但是之后当我通过 library(caret) 加载它时,我收到了以下错误
正在加载所需的包:ggplot2
Error: package or namespace load failed for ‘ggplot2’ in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]])
没有名为‘munsell’的包
Error: package ‘ggplot2’ could not be loaded
抱歉,我没见过这个错误。也许可以在 stackoverflow 上检查一下是否有人遇到过此故障,或者考虑在那里发布错误。
嗨,Jason,
一些研发人员解决了这个问题。以下是我所做的操作。
install.packages(“lattice”)
install.packages(“ggplot2”)
install.packages(“munsell”)
install.packages(“ModelMetrics”)
library(lattice)
library(munsell)
library(ggplot2)
library(caret)
干得好,很高兴知道您解决了问题。
嗨,Jason,
需要再次帮助。提前感谢。
这是我的第一个数据科学项目,所以这个问题。
如何从箱线图的结果中解读?如果您能稍微解释一下箱线图的结果,将不胜感激。
箱线图显示了数据的中间值。箱子是第25到第75个百分位数,一条线显示了第50个百分位数(中位数)。这是一种快速了解数据分布的方法。
更多信息在这里
https://en.wikipedia.org/wiki/Box_plot
Brownlee博士您好,
我是机器学习新手,正在尝试完成您的教程。
我一直收到一个错误,说准确性矩阵的值在此行缺失:
results <- resamples(list(lda=fit.lda, cart=fit.cart, knn=fit.knn, svm=fit.svm, rf=fit))
lda的准确性矩阵工作正常,但cart、knn、svn和rf则不起作用。
您对如何解决这个问题有什么建议吗?
谢谢
很遗憾听到这个消息。请确认您的软件包已更新。
先生,我该如何绘制这个混淆矩阵“confusionMatrix(predictions, validation$Species)”?
看起来不错。
> predictions confusionMatrix(predictions, validation$Species)
Error in confusionMatrix(predictions, validation$Species)
object ‘predictions’ not found
有谁能解释一下这个错误吗?
predictions confusionMatrix(predictions, validation$Species)
Error in confusionMatrix(predictions, validation$Species)
object ‘predictions’ not found
有谁能解释一下这个错误吗?之前我发的东西可能错了
也许双重检查您是否包含了帖子中的所有代码?
出现了同样的错误,我该如何解决?
你好,
我在这方面是初学者,所以我想问的问题可能没有意义,但我还是请求您回答。
所以,当我们说“让我们预测一些东西”时,我们究竟在预测什么?
如果是机器(电机、泵等)的数据(电流、转速、振动),那么可以预测什么?
此致,
Saurabh
在本教程中,给定鸢尾花的花测量值,我们使用模型来预测花的种类。
set.seed(7)
> fit.lda <- train(Species~., data = data, method = "lda", metric = metric, trControl = control)
我收到的错误,并且也尝试安装mass包,但它没有正确安装,并且一直显示错误,请帮助我。
错误:
Loading required package: MASS
Error in unloadNamespace(package)
namespace ‘MASS’ is imported by ‘lme4’, ‘pbkrtest’, ‘car’ so cannot be unloaded
Failed with error: ‘Package ‘MASS’ version 7.3.45 cannot be unloaded’
Error in unloadNamespace(package)
namespace ‘MASS’ is imported by ‘lme4’, ‘pbkrtest’, ‘car’ so cannot be unloaded
Error in library(p, character.only = TRUE)
Package ‘MASS’ version 7.3.45 cannot be unloaded
很遗憾听到这个消息。也许可以尝试在新会话中单独安装MASS包?
你好 Jason,
我的问题是关于缩放的。对于一些算法,如adaboost/xgboost,建议缩放所有数据。我的问题是如何取消缩放最终预测?我使用了R中的scale()函数。unscale()函数需要预测值的中心(可能是均值/中位数)值。但我的预测值已经被缩放了。如何将它们取消缩放到合适的预测值?我指的是在未标记数据集上的预测。
我在许多网站上搜索过这个问题,但没有找到任何答案。
也许可以自己缩放数据,并使用系数的min/max或mean/stdev来反转缩放?
我在汇总模型准确性时遇到一个错误,
Error in summary(results) : object ‘results’ not found
您可能错过了一些代码?
> library(tidyverse)
先生,在R中添加这个库时,我已经安装了包,但它仍然显示以下错误:请帮助我
Error in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]])
there is no package called ‘bindrcpp’
Error: package or namespace load failed for ‘tidyverse’
抱歉,我对那个包或错误不太熟悉。也许试试在stackoverflow上发帖?
亲爱的 Jason,
我对R工具不熟悉。当我开始阅读这个教程时,我想到要安装R。安装后,当我输入R命令时,我收到了以下错误消息。请给我建议……
> install.packages(“caret”)
Installing package into ‘C:/Users/Ratna/Documents/R/win-library/3.4’
(as ‘lib’ is unspecified)
— Please select a CRAN mirror for use in this session —
trying URL ‘http://ftp.iitm.ac.in/cran/bin/windows/contrib/3.4/caret_6.0-77.zip’
Content type ‘application/zip’ length 5097236 bytes (4.9 MB)
downloaded 4.9 MB
package ‘caret’ successfully unpacked and MD5 sums checked
已下载的二进制包位于
C:\Users\Ratna\AppData\Local\Temp\RtmpQLxeTE\downloaded_packages
>
干得漂亮!
你好 Jasson,
我尝试了以下方法,但收到了错误:
> library(caret)
正在加载所需的包:lattice
正在加载所需的包:ggplot2
Error: package or namespace load failed for ‘caret’ in loadNamespace(i, c(lib.loc, .libPaths()), versionCheck = vI[[i]])
there is no package called ‘kernlab’
>
看起来您可能需要安装“kernlab”包。
谢谢 Jasson!!!!
不客气。
e1071 错误,我已经安装了所有包……
您收到了什么错误?
大家好,
当我在第2.3步创建更新的“dataset”时,有120个观察值,但由于某种原因,数据集中有24个NA值,只剩下96个实际观察值。我复制粘贴了上面帖子中的代码。您知道是什么原因造成的,或者如何修复,以便“dataset”包含所有训练数据的观察值吗?看起来鸢尾花数据集或任何验证索引或验证数据集都没有问题。
也许双重检查您是否拥有最新版本的R?
更新到 OP,我重新运行了该部分的原有命令,并能够拉取训练数据中的所有120个观察值。不确定为什么第一次没有获取所有数据,但现在看起来没问题了。
很高兴听到这个消息。
只是确认一下,上面的教程是一个多分类问题吗?因此,我应该能够将上述方法应用于另一个 k=3 的问题。这是正确的吗?
是的。
Jason,
这是我第一个机器学习项目,这个教程非常有帮助,非常感谢您的教程。我没有遇到任何问题地完成了脚本,甚至将其应用到模拟数据集上,而且效果很好。所以,谢谢您。
我的问题更多地与自动化有关。与其手动评估每个模型的准确性来确定使用哪个模型进行预测,有没有办法在“predictions <- predict([best model], validation)”脚本中自动调用准确性最高的模型?希望尽快收到您的回复。
干得好!
好问题。通常,一旦我们找到表现最好的模型,我们就会训练一个最终模型,将其保存/加载并用于在新数据上进行预测。这篇帖子将向您展示如何操作。
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
这篇帖子涵盖了该方法的理念。
https://machinelearning.org.cn/train-final-machine-learning-model/
我没有得到100%的准确性,尽管我遵循了教程示例。我得到了
混淆矩阵和统计数据
参考
Prediction Iris-setosa Iris-versicolor Iris-virginica
Iris-setosa 10 0 0
Iris-versicolor 0 8 0
Iris-virginica 0 2 10
总体统计
Accuracy : 0.9333
95% CI : (0.7793, 0.9918)
No Information Rate : 0.3333
P-Value [Acc > NIR] : 8.747e-12
Kappa : 0.9
Mcnemar’s Test P-Value : NA
各类别统计量
Class: Iris-setosa Class: Iris-versicolor Class: Iris-virginica
Sensitivity 1.0000 0.8000 1.0000
Specificity 1.0000 1.0000 0.9000
Pos Pred Value 1.0000 1.0000 0.8333
Neg Pred Value 1.0000 0.9091 1.0000
Prevalence 0.3333 0.3333 0.3333
Detection Rate 0.3333 0.2667 0.3333
Detection Prevalence 0.3333 0.2667 0.4000
Balanced Accuracy 1.0000 0.9000 0.9500
>
也许可以多次运行示例?
先生,我想通过视频教程学习R编程,哪个是快速学习R编程的最佳教程?
抱歉,我没有关于如何学习R的好建议,我专注于教授如何在R中学习机器学习。
为了学习R,我强烈推荐Coursera.org的“R Programming”认证课程,当我参加时它是免费的,现在是付费的,大约是50美元。
谢谢提示。
Json,不错的文章。我在这个存储库中留下了工作代码,只需要做一些小的修复,请评论一下,谢谢,Carlos
https://github.com/bandaidrmdy/caret-template
感谢分享。
如果数据集是EuStockMarkets,我仍然收到错误
抱歉,我对那个数据集不太了解。
成功完成,并得到了结果。感谢精彩的教程。
但是现在我想知道,下一步该做什么,如何以通用方式为任何数据集使用它。
如何使用创建的pred.model?
是的,您可以使用此过程来处理其他数据集。
好的,但是要使用任何数据集,我们需要使数据集类似于鸢尾花数据集,例如4个数值列,以及一个类。
此外,准确性输出在训练数据集和验证数据集上是相似的,但这对我预测现在提供类似参数时会是什么类型的话有什么帮助?
现在,例如,我需要创建一个模型来预测我vCenter或整个数据中心服务器的CPU利用率,我该如何创建一个模型,该模型将采用我的连续数据集并预测CPU利用率何时会变高,以便我可以采取主动措施?
这个过程将帮助你系统地解决你的预测建模问题
https://machinelearning.org.cn/start-here/#process
你好 Jason,
感谢您清晰和分步的说明。但我只是想了解在创建模型并计算其准确性后我需要做什么?您能否解释一下如何对我们使用的鸢尾花数据集进行一些结论/预测?
您可以最终确定并开始使用它。
在这里查看整个过程。
https://machinelearning.org.cn/start-here/#process
先生,您好,
对于 confusionMatrix(predictions, validation$Species) 命令,我得到了如下输出
[,1] [,2]
[1,] 0 0
[2,] 0 10
我的输出与您的不同。您是否对可能我做错了什么有什么建议?代码在此命令之前一直工作正常。
也许双重检查您是否复制了教程中的所有代码?
以及您的Python环境和库是否已更新?
您好,Jason。
非常感谢您的教程,我受益匪浅,但我有一个问题,“print (fit.lda)”部分没有显示“Accuracy SD Kappa SD”。
如果一切都与教程完全一致,那么这还剩下什么呢?您能否帮我解决这个疑问?
问候。
在我写这篇帖子近2年前,API可能已经发生了一些变化。
Jason,这是一篇很棒的文章,适合像我这样的初学者!感谢您分享您的知识和教学。
是否存在适合“多项逻辑回归”算法的模型?
谢谢!
是的,但是我不推荐它。试试LDA。
在进一步阅读了您的其他文章后,我意识到我可能不需要使用“回归”。我的数据集有类别变量作为输入,也有类别属性作为输出(有7个级别)。所以,这是一个分类问题,我假设我可以在这个鸢尾花项目中使用的5个模型/拟合模型中使用其中一个。我的理解是否正确?
—— 谢谢
这篇帖子可能有助于您区分分类和回归。
https://machinelearning.org.cn/classification-versus-regression-in-machine-learning/
我对鸢尾花数据有效。非常感谢 Jason!但是,模型输出中没有“Accuracy SD Kappa SD”。我应该更改一些设置来获取它们吗?
我相信API可能已经改变了。
尊敬的Jason Brownlee先生
我有一个包含36个预测变量和一个类别变量(“1”、“2”、“3”)的数据集,这个数据集是我在上一步中通过聚类得到的。
我的问题是:如何将我所有的预测变量减少到代表我研究中特定维度的五个变量?
我应该单独运行PCA来生成一个包含5个预测变量和一个类别变量的新数据集,还是有其他方法?
先谢谢您了。
是的,您应该先运行降维来创建一个具有相同行数的新输入数据集。
你好 Jason,我收到了错误:
Error: could not find function “trainControl”
当我输入 tc<-trainControl(method="cv",number=10) 时。
这有什么解决方案吗?
也许 caret 没有安装,或者 caret 没有加载?
也许是一个非常愚蠢的问题。但我读到“构建5种不同的模型来根据花朵测量值预测种类”。所以现在我想知道模型的预测对我有什么意义,我该如何使用它?例如,我现在去森林里进行一些测量,假设这种花是测试过的花之一,我想确切地知道是哪种花。在传统的回归公式中,这是很直接的,因为您可以将您的测量值放入公式和计算出的估计值中,然后得到一个结果。但我不知道如何在此类情况下使用结果。
很好的问题。
一旦我们选择了一个模型和配置,我们就会开发一个在所有数据上训练的最终模型并将其保存。我在这里写过。
https://machinelearning.org.cn/train-final-machine-learning-model/
然后您可以加载模型,输入一个输入(例如,一组测量值),并使用它来为这些测量值进行预测。
这有帮助吗?
您的教程太棒了。感谢,它真的很有帮助。
谢谢,听到这个我很高兴。
这个教程真的很有帮助。谢谢 Jason。
谢谢,听到这个我很高兴。
你好 Json,你好吗?
我是机器学习的新手。我想在伊斯兰银行和传统银行方面发明一个独特的想法并进行证明。我该如何做到?如果您有任何建议,请告诉我,我找不到任何伊斯兰银行的数据集,例如贷款信息或存款等等。我想要您的宝贵信息。
抱歉,我对银行业务不了解。
先生,我遇到了以下错误
Error in `[.data.frame`(out, , c(x$perfNames, “Resample”))
undefined columns selected
当我执行
results <- resamples(list(lda=fit.lda,nb=fit.nb, cart=fit.cart, knn=fit.knn, svm=fit.svm, rf=fit.rf))
这有什么解决方案吗?
您是否复制了教程中的所有代码?
你好 Jason,首先,工作做得很好。愿上帝保佑您所有真诚的努力分享知识!您正在对人们的生活产生重大影响。感谢您。
我有一个基本问题。现在我们有了最好的拟合模型——如何将其用于日常使用——是否有办法测量一朵花的大小,然后“应用”它们到一个方程中,该方程将给出预测的花名?如何使用结果?请您有空时告知。
你好 Jason——找到了您的另一篇帖子。
https://machinelearning.org.cn/deploy-machine-learning-model-to-production/
谢谢你。
Jason,您好——这篇帖子很好地说明了应该做什么。但是,“如何”部分仍然缺失。因此,我仍然需要帮助。谢谢。
你可以按如下方式进行预测
yhat = predict(Xnew)
其中 Xnew 是新的花朵测量值。
谢谢。
另请参阅此帖子
https://machinelearning.org.cn/train-final-machine-learning-model/
亲爱的 Jason,
非常感谢您的回复。是的——我正要发布,这个链接确实有助于将结果付诸实践。
非常感谢。请继续保持出色的工作。
Hussain。
很高兴听到这个消息。
嗨,Jason,
感谢您分享您的方法和代码。它非常有用且易于遵循。您能否分享一下如何使用其中一个模型对新数据集进行评分?例如,在我的训练中,随机森林的准确性最高。现在我想将该模型应用于一个没有结果变量的新数据集,并进行预测。
谢谢你
好问题,我在这一篇帖子中回答了
https://machinelearning.org.cn/train-final-machine-learning-model/
谢谢 Jason。我通读了链接。我已经确定了我的模型,现在我需要保存模型并将其应用于生产环境。我想评分的数据集没有结果变量。我不确定在拥有最终模型后应该使用哪个命令进行预测。您能否提供 R 代码来执行此操作?
您可以使用 predict() 函数来使用您已完成的模型进行预测。
Jason,您好!很棒的帖子!我和 @TNguyen 有同样的疑问。我已经完成了模型,并且我们知道 LDA 是最适合这种情况的模型。如何预测没有此变量的新数据框中的结果变量(物种)?总之,如何将模型部署到新数据集?抱歉,我刚接触这个领域,一直在学习新东西!
好问题,我在这里有一个可能有所帮助的答案
https://machinelearning.org.cn/faq/single-faq/how-do-i-make-predictions
这是一篇关于在 R 中完成模型的教程
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
嗨,
感谢精彩的教程。我遇到了一个问题,不知道哪里出了问题
3.1 维度。当我执行 dim(datset) 时,我得到答案 NULL。
您知道为什么 R Studio 不显示“dataset”的维度吗?
此致
马丁
也许确认您已加载数据?
非常好,它为在 R 中编写 ML 提供了整体结构。
谢谢!
嘿,我正在研究一个名为 polisci 的包,我被要求构建一个多元线性回归模型。我的因变量是人类发展指数,我的自变量是经济自由。您能否告诉我如何执行多元线性回归模型?我该如何进行步骤以及 R 中的语法才能得到结果并获得图形?任何帮助将不胜感激。请帮助我,因为我是一名本科生,这是我第一次学习这个
提前感谢
抱歉,我没有时间序列预测的 R 示例。
这里有一些可供您使用的资源
https://machinelearning.org.cn/books-on-time-series-forecasting-with-r/
谢谢 Jason,
能够一次性执行程序.. 精彩的描述
干得好!
Jason,非常感谢您的上述工作。它太棒了,我是数据科学的新手,想在数据科学领域发展我的事业。我觉得这超级有用……
不客气,我很高兴它有所帮助。
请逐步指导我成为数据科学家,以及如何在 R 和 Python 中成为冠军?
当然,从这里开始
https://machinelearning.org.cn/start-here/
谢谢 Jason!这篇帖子非常有帮助。我完全按照建议操作了,但是当我打印(fir.lda)时,我没有看到准确率 SD 或 kappa SD。我该如何获取它们?谢谢
也许 API 已经改变了。
精彩的教程!
我只需要安装 2 个包:e1071 和 Ellipse
之后,我写下了每一行代码,我真的很感激您为清晰解释所付出的巨大努力!!!
谢谢你
很高兴它有帮助。
感谢精彩的教程。我遇到了一个问题,不知道哪里出了问题
6. Make predictions 。当我执行 predictions <- predict(fit.lda, validation) 时
confusionMatrix(predictions, validation$Species) 我得到错误“data and reference should be factors with the same levels.” (数据和参考应该是具有相同级别的因子。)
您知道为什么 R Studio 不显示“dataset”的“Make predictions”吗?
也许可以尝试从命令行运行脚本?
https://stackoverflow.com/questions/19871043/r-package-caret-confusionmatrix-with-missing-categories
请查看上面的链接 ^
当我尝试执行 featurePlots 时,我得到 NULL。我已经安装了 ellipse 包,没有报错。
featurePlot(x=x, y=y, plot=”ellipse”)
NULL
> # box and whisker plots for each attribute
> featurePlot(x=x, y=y, plot=”box”)
NULL
> # density plots for each attribute by class value
> scales featurePlot(x=x, y=y, plot=”density”, scales=scales)
NULL
到目前为止的一切都运行正常
我很遗憾听到这个消息。也许还有其他您必须安装的包?
尊敬的Jason博士,
两种情况——(i) NULL 问题——已解决,以及 (ii) 显示多变量图。和 (iii) 拼写错误
(i) NULL 问题已解决。
我也在 4.2 节的多变量图部分遇到了问题。该问题已解决。
您说得对,还有其他您必须安装的包。那是 2018 年的事了。参考页面顶部的 2019 年更新标题,有必要通过输入以下命令来安装其他包
我的网络连接上的包花费了将近 2 个小时。但这是值得的。
(ii) 显示 4.1 节中的条形图和 4.2 节中的多变量图。
为了在整个窗口中显示 4.1 节和 4.2 节中的条形图和多变量图,我会添加这一行
否则,条形图和 featurePlots 会因为命令
从 4.1 节继续,并对条形图和 featurePlots 进行操作。
所以一旦你在 4.1 节处理完条形图,就插入这一行
另外,4.2 节有一个拼写错误。它说
“就像箱线图一样,我们可以看到每个属性按类别值的分布差异。我们还可以看到每个属性的类高斯分布(钟形曲线)。”
将“Like he boxplots”替换为“Like the boxplots”。
谢谢你,
悉尼的Anthony
谢谢,已修正。
我也遇到了同样的错误。
您可能想查看下面的链接以获取解决方案
https://stackoverflow.com/questions/19871043/r-package-caret-confusionmatrix-with-missing-categories
感谢分享。
很棒的教程 Jason!激励我去查找并学习更多关于 LDA 和 KNN 等的知识,这是一个额外的收获!很棒的自学体验。我มี与分析相关的经验,但我是 R 的新手,但我能够理解并跟随一些关于底层方法和 R 函数的研究……所以,谢谢!
一件事……我对 LDA 模型结果的最终比较(第 5.3 节)在我这里有所不同,而且每次运行它的结果都不同。原因很可能是因为在第 2.3 步之前没有 set.seed()。因此,当您创建验证数据集(在 createDataPartition() 中进行随机抽样)时……结果最终会不同?
谢谢。
干得好。
谢谢。是的,应该会有些小的差异。
Jason Brownlee,你才是真正的 MVP!我在 R 3.5 中运行了此程序。
谢谢,很高兴这个教程对您有帮助。
你好,这很有帮助,但我不知道如何读取散点图矩阵
每个图都比较了一个变量与另一个变量。它可以帮助您了解变量之间是否存在明显的关系。
我在这里遇到了问题……
# 创建原始数据集中 80% 的行的列表,可用于训练
validation_index <- createDataPartition(dataset$Species, p=0.80, list=FALSE)
# 选择 20% 的数据用于验证
validation <- dataset[-validation_index,]
# 使用剩余的 80% 数据来训练和测试模型
dataset <- dataset[validation_index,]
1
2
3
4
5
6
# 创建原始数据集中 80% 的行的列表,可用于训练
validation_index <- createDataPartition(dataset$Species, p=0.80, list=FALSE)
# 选择 20% 的数据用于验证
validation <- dataset[-validation_index,]
# 使用剩余的 80% 数据来训练和测试模型
dataset <- dataset[validation_index,]
请帮帮我
问题究竟是什么?
它找不到对象……和函数!我该怎么办?
什么对象?
Jason,你真是 MVP!我在 R 3.5 中运行了此程序。
1. install.packages(“caret”, dependencies = c(“Depends”, “Suggests”)) 运行了将近一个小时。可能是连接到镜像的问题。
2. install.packages(“randomForest”) & library(“randomForest”) 是必需的
绝对会向所有 ML 从业者推荐它作为“Hello World!”
衷心感谢!
干得好!
谢谢你的建议。
首先,我要感谢您提供此内容!它给了我追求其他 ML 事业的勇气!
我遇到的唯一问题是,当总结 LDA 模型的结果时,使用 print(fit.lda),我的结果不显示标准差。您知道这是否是由于 R 中需要更改的设置?
任何帮助都将不胜感激!
祝好,
Giovanni
是的,我认为 API 自我编写教程以来已经发生了变化。
嗨!
首先,这是个很棒的教程,我照做了并取得了预期的结果
它真的帮助我克服了 ML 的恐惧。非常非常感谢您。
但我真的很想知道这些算法的数学原理,它们做什么以及如何做?
另外,
如果您能解释像“relaxation=free”(这是什么意思?)这样在谷歌上找不到直接答案的问题,那就太好了
谢谢
此致
感谢 Shane 的反馈。
我们在这里专注于 ML 的应用方面。关于数学,我推荐一本学术教材。
非常棒的教程。caret 包是一项伟大的发明。在哪里可以找到方法的快速理论以便更好地理解它?
就在这里
https://machinelearning.org.cn/start-here/#algorithms
谢谢,Brownlee。
不客气。
Jason,您是否可能
1. 发布一个无监督随机森林教程。我认为 Caret 只支持监督学习。如果不支持,您能否指向一个除 Breiman 之外的示例?
2. 更具体地说,我正在寻找一个预测程序,该程序可以接受一个已保存的模型,例如随机森林,并通过一个包含类别/类型预测的输入 .csv 文件进行循环。我认为我已经解决了概率问题
感谢您的建议。我通常没有关于无监督方法的内容,而且我从未听说过无监督随机森林!
嗨,Jason,
感谢教程。这在我的研究中帮助了我很多。我正在运行 Rick Pack 贡献的这个示例代码,来自 https://github.com/RickPack/R-Dojo/blob/master/RDojo_MachLearn.R
当我将我的 mysql 数据库数据插入到数据集中并尝试运行上述示例时,我收到错误
> validation_index <- createDataPartition(dataset$containsreason, p=0.80, list=FALSE)
Error in cut.default(y, unique(quantile(y, probs = seq(0, 1, length = groups))),
invalid number of intervals (无效的区间数)
我尝试搜索,但找不到此错误的任何实例。
请
如果您对别人的代码有问题,也许可以和他们谈谈?
你好,
我刚弄明白。数据太稀疏了,因为我包含了某些不想要的列。删除后,它工作正常。
很高兴听到这个消息。
这真的很棒……请指导我进行其他项目以练习和提高我的技能集。
谢谢你
谢谢。更多项目想法在这里
https://machinelearning.org.cn/faq/single-faq/what-machine-learning-project-should-i-work-on
这对我来说确实是救命的,因为当时我正在考虑如何构建我的气候研究考试报告。非常非常感谢!
不客气,我很高兴它有帮助!
运行完美。不得不安装许多包。但这一切都通过一些点击和谷歌解决了。我的第一个成功的机器学习教程!!!非常感谢 Jason!!——来自印度的爱和尊重。
干得好!
Brownlee,您好,首先非常感谢您提供的精彩教程。
我想了解的是,当我们找到最准确的模型时,我们如何要求我们的模型测试更多样本,也就是说,我们如何对另一个样本数据运行我们的测试?
例如,在您的测试中 LDA 是最准确的,那么如果您想让您的程序检查另一个数据,代码是什么?
谢谢
isa
您必须创建一个在所有数据上训练的最终模型。在此了解更多
https://machinelearning.org.cn/train-final-machine-learning-model/
嘿 Jason,我和 isa 有同样的问题,我已阅读您关于创建最终模型的帖子。选择最终模型并让它分析未见过数据的方法如何转化为 R 代码?例如,在上面的代码中,假设我想给鸢尾花特质的一行数据拟合 lda,并让它猜测它是什么物种。我该怎么做?感谢您的帮助。
这是一个例子
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
你好,
感谢教程!我复制了代码,它在预测部分运行正常。我收到一个错误:“Error in eval(predvars, data, env) : object ‘Sepal.Length’ not found”。您能帮我解决吗?先谢谢了!
如何使用 R 包 e1071 来分析古吉拉特语文本以进行可读性研究?
我不知道,抱歉。
嗨 Jason
您能否指导我们如何获得数据集中每个实例的预测值(尤其是在回归中)?例如,我们有 5 个变量,那么如何获得这五个预测(数字)值,以便我们可以将这些值与数据集的实际值进行比较。
嗨,jason
我是 R 语言的爱好者。我是一名助理教授和研究学者,所以我正在研究 ML 和 R。这篇帖子非常有用。我已经与其他包合作过,但这个比其他所有都简单得多。我需要一个小建议,我如何让 R 成为我 b.tech 学生的首选语言。他们强烈支持 Python,但我也想让他们对 R 产生同样的兴趣。
也许展示一下 R 可以做而 Python 不能做的事情?
嗨 Jason,我快要疯了。我挠光了头发。我已经放弃了谷歌。到处搜寻,但无法理解/找到这个问题的答案。
我创建了一个垃圾邮件/垃圾邮件分类器……它还可以。但现在我想在全新的数据上使用它。或者让它运行 1000 行全新的数据。我该如何做到这一点?
我使用了 predict 函数,它在测试数据上运行正常,但在新数据上(在我进行了所有预处理之后),我得到了一个对象未找到的错误……对象是一个单词,我假设它不存在于其中一个集合中……我完全不知道。
所以我想我遗漏了某个步骤?请帮忙
听到这个消息我很难过。
也许将您的代码和错误发布到 stackoverflow 或 crossvalidated?
很棒的帖子!非常有用的。所有步骤在有一些基本知识的情况下都可以正常工作。需要安装依赖项。
干得好!
非常感谢,非常有帮助
很高兴听到这个消息。
嗨 Jason,非常感谢您分享这篇有用的帖子。我正在做我的研究生项目,关于使用 AI 优化供应链系统。所以我想问您,对于预测需求和优化此类流程(供应链)的最佳分支是 ML 结合神经网络吗?我在哪里可以找到更多关于您课程的信息。再次感谢,圣诞快乐
也许 Silvio,这里是一个不错的开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
这是我的第一次 R 体验,您的教程帮助了我很多。
但是,那个似乎很长。
例如:fit 是否也支持其他算法,如 TensorFlow?
当我进入帮助系统时,我找不到关于可能算法的任何信息。
祝好,
Fred
干得好!
在本教程中,我们没有直接使用算法,而是使用了一个有用的包装器,称为 caret。
您可以学习直接使用算法,但您必须参考并学习如何使用每个单独的 R 包,这可能会花费很多时间。
嗨,杰森,
我可以使用这个进行实时数据分析吗?请回复
也许可以。
嗨,Jason,
不错的教程。在我尝试拟合线性算法“lda”时,除了这一点,其他对我来说都运行得很好。
无论我使用什么变量(我也尝试了您的示例)。
我收到此错误
有什么问题;所有准确率指标值都丢失了
Accuracy Kappa
最小值:NA 最小值:NA
1st Qu.:NA 1st Qu.:NA
中位数:NA 中位数:NA
平均值:NaN 平均值:NaN
3rd Qu.:NA 3rd Qu.:NA
最大值:NA 最大值:NA
NA's :1 NA's :1
错误:停止
另外:还有 11 个警告(使用 warnings() 查看它们)
其余的模型运行得都很好。
提前感谢,
J
也许 API 自发布以来已经发生了变化,也许可以跳过该算法?
谢谢 Jason,这个教程太棒了,而且你真的很有耐心
谢谢。
非常好的教程!!
我想知道:在我得到一个可以对新数据集进行良好预测的模型之后,我如何知道哪些参数对预测更重要?换句话说,哪些是重要的特征?例如,在这种情况下,我可以说明 I.Setosa 具有短萼片和短花瓣(等等)。但是我能从脚本中打印出相同的信息吗?
提前感谢!
也许可以尝试一个消融实验,其中逐个移除特征并重新拟合模型,看看哪个或哪些特征对模型性能的影响最大?
谢谢 Jason。我有一个关于将数据集分为 3 部分的担忧:70% 用于训练,15% 用于验证,15% 用于测试。
我该如何划分?我需要使用 caret 包吗?
inTrain <- createDataPartition(y = data$CSC, p = 0.70, list = FALSE)
还是我必须将验证作为训练的一部分?
我不明白为什么要在测试之前划分验证,以及为什么它有必要……
我需要这方面的详细描述,如果可能的话,还需要 R 代码。我在网上找不到任何相关的简洁描述。
请帮助
也许先将训练/测试分开,然后将训练分成训练/验证?
关于为什么需要验证的更多信息,请参见此处
https://machinelearning.org.cn/difference-test-validation-datasets/
你好,
这对我来说是一个很好的教程。
但是,我遇到了这个问题:
Error in createDataPartition(fhg$`Historic_Glucose(mg/dL)`, p = 0.8, list = FALSE)
找不到函数“createDataPartition”
我该如何解决这个问题?
确保 caret 已安装并已加载。
它已经安装并加载了。我参考了其他来源,并加载了其他支持的包来使其运行。
谢谢
干得好!
您加载了哪些包?
你好 Jason,感谢您提供关于这些算法的演示。解释非常清晰且切中要点。
但是,我的问题是,我使用上面的代码运行了一个项目,但在模型中出现了一些错误,以下是我的数据描述……
1. 我有 19 个预测变量和 1 个响应变量。但响应变量是分类的,1 表示是,0 表示否。所以,我导入数据并逐步遵循您的代码,但在模型中,我使用了“metric = metric”,但那不起作用,我使用“metric = Accuracy”,但结果仍然一样,在使用 LDA、kNN 和几乎所有模型时,我都会出现错误,并且错误表明这不能用于回归。但我的结果是分类的,最初我将其更改为因子。在所有错误之后,
2. 第二部分是,我现在使用具有 19 个预测变量的数据,并且我使用一个有 3 个级别而不是 2 个级别的结果变量。但这次我只保持“metric = Accuracy”,并且它在所有模型上运行都没有错误。唯一的错误发生在我想进行预测的部分。以下是进行预测时出现的错误:
“错误:
data和reference应该是具有相同级别的因子。”这个错误是什么意思?谢谢,我需要您对我两个问题的回复。
也许您需要将数据中的输出变量从数字转换为因子?尝试对变量使用 as.factor()。
你好 Jason;
非常感谢您提供信息丰富的教程。我可能错过了一些地方,每次我运行算法时,我都会得到不同的结果。我的意思是,一次 LDA 是最准确的模型,另一次是 kNN,还有一次 LDA、Cart 和 rf 具有相同的准确率值。当然,每次使用了不同的训练数据集,但结果令人困惑。有一件事,我如何看到模型的系数,或者我可以吗?
提前感谢你
考虑到算法的实现/更新方式可能发生变化,您可以预期会有细微的差异。
另外,随机种子的差异,更多详情请参见此处
https://machinelearning.org.cn/randomness-in-machine-learning/
你好 Jason’
谢谢,您的教程对我的工作非常有帮助。我能问一个问题吗?如何在“按类别值划分的鸢尾花数据密度图”中为每条线(蓝色、粉色和绿色线)添加标签,说明它们的物种(“setosa”、“versicolor”、“virginica”)?
非常感谢
你好 Jason,
非常好的教程。
我遇到了一个错误——
> set.seed(7)
> fit.lda <- train(Species~., dataset=dataset, method="lda", metric=metric, trControl=control)
Error in terms.formula(formula, data = data)
公式中的“.”和没有“data”参数
请建议——如何修复错误?
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好!与其他很多人一样,我在 featureplot 行上遇到了麻烦。我尝试更新 R,并单独安装“ellipse”,最后使用了安装 caret 的额外代码和附加说明。我仍然收到“error in featurePlot (x=x, y=y, plot= “ellipse”) : could not find function “featurePlot””。
任何帮助将不胜感激。
请忽略/删除上面的内容,包没有正确安装,现在一切都好了 🙂
很高兴听到您解决了!
非常感谢 Jason!您是一位出色的导师。非常有帮助。我未能成功安装 caret 包到 R 中(收到了一些我无法解决的错误消息),但您的教程在 RStudio 中对我来说效果非常好。
很高兴听到这个消息。
我是一名意大利学生,我想在以下 4 种分类方法中找到(多项回归、判别分析(线性或二次)、KNN
分类器)中,哪一种在误分类记录最少方面是最好的,以及为什么?附带评论和考虑。输入是 IRIS 数据集,目标是根据
第五列(标记为“species”,值为:setosa、versicolor 和 virginica)进行数据分类,
相对于四种测量值:“Sepal.length”、“Sepal.width”、
“Petal.length”和“Petal.width”,显示在第 1-4 列。
请帮帮我!我想学习
也许可以先尝试上面的教程?
嗨,Jason,
对于像我这样的 R 初学者来说,这真是一个很棒的帖子。
我有一些问题
1) 我的数据集比 Iris 的要大。我有 170 列(不同的变量)和 4000 行,但在每列中约有 3-8% 的数据缺失。我发现我们可以用中位数、平均值来填充这些缺失的数据点,或者不将它们包含在分析中。我选择中位数,但这比不分析它们要好吗?
2) 出于学习目的,我选择了 13 列(那些几乎没有缺失数据的列)+ 所有行,并且效果很好,值为 98% 或更高。但是,当使用所有列时,准确率/敏感度等下降到大约 60%。那么,如果我包含影响最大的变量,这“可以”吗?
3) 当数据库有缺失数据时,箱须图不会出现(4.1. 单变量图)。我通常会收到“error in call.Graphics……”或列未定义。
希望您能澄清这些问题,
感谢您的帮助。
此致,
Alan
也许可以尝试不同的缺失数据处理方法,看看哪种方法能带来更好的模型技能。
听起来不错,继续使用结果来指导建模决策。
也许缺失数据需要标记为 na,或者绘图函数需要被告知忽略 na?
你好 Jason。这个循序渐进的指南对机器学习初学者来说非常有帮助。
我尝试稍微修改代码以适应我自己的数据,运行算法来基于逻辑回归输出来建模信用风险。
也许你想分享一下我该如何修改你的代码来建模一个信用风险模型?
感谢您的建议。
感谢您发布这个精彩的教程。我非常不熟悉机器学习,有一个快速、可能很天真的问题。
我如何看到用于预测分类的最终方程?鸢尾花数据集和我自己的另一个数据集让我确信其有效性。我想知道每个变量在确定预测分类中的权重。
大多数模型都不提供方程,它们过于复杂,或者即使可以,它也不可读。
你好 Jason,感谢这篇帖子!它非常有帮助。我想知道,如果看不到方程,是否有其他方法可以让我们了解哪些变量在模型中对预测结果最有影响力?
你好先生,我是 R 的新手,感谢您上面的第一个项目解释,
现在我的疑问,
1. 我的文件是 Excel,包含超过 1000 行,近 20 列(带名称),最后一列是类别(2 个类别,如是/否)。在其他列中,一些列的值是数字,而 4 列包含字符串(一列的值如是/否,另一列的值如 11 个地名等)。为了执行您上面的第一个 R 项目,我可以应用(Excel 转换为)CSV 文件,或者在将字符串列值转换为数字后应用?如果可以,我是否可以给 1,2,3,4,5,6……不同的地名?
2. 我如何使用 R 来对我的数据集进行分类或分析,通过更改分类方法中的一些内容?
谢谢你,
作者:
Suresh Kumar
是的,您可以加载您的文件为 CSV,并且您可能需要花一些时间将分类字段转换为 R 中的因子。
关于 R 用于机器学习的一个好起点在这里
https://machinelearning.org.cn/start-here/#r
你好!
您能帮我一把吗?我正在做我的毕业设计,不小心选择了人工智能项目。在我们的项目中,我们需要实现人工神经网络。它基于学生的学业成绩预测,我们将通过过去的学业数据预测哪些领域对学生未来的学习最有利。现在我甚至不知道从哪里开始……我们应用程序的剩余模块已经完成,但我们卡在了最后一个模块。你能告诉我我们应该如何开始,使用哪些工具进行编码,以及如何根据学生分类来训练我们的网络吗?训练完成后,我们必须将其集成到我们的Android Studio项目中。请帮忙!
提前感谢!
我在机器学习方面是零基础……所以请您给我一些时间回复,指导我从哪里开始,应该使用什么工具……
从这里开始
https://machinelearning.org.cn/tutorial-first-neural-network-python-keras/
然后这里
https://machinelearning.org.cn/start-here/#deeplearning
嗨,Jason,
我如何在caret中绘制ROC曲线?
抱歉,我没有例子。
Jason,
感谢这篇精彩的文章。我刚开始接触这个领域,可能有一些愚蠢的问题
1. 对于这5种模型,尤其是随机森林模型,我如何找出模型的选定参数?例如,对于rf,使用了哪些预测变量?每个预测变量用于预测结果的参数是什么?
2. 我如何知道新数据集的预测结果是什么?换句话说,如果我们提供一组新的“Sepal.Length”、“Sepal.Width”、“Petal.Length”、“Petal.Width”值,并想知道模型预测的物种是什么,该如何操作?
谢谢。
Yue
我们不太关心模型为何有效,只关心它是否有效。这被称为模型可解释性。
https://machinelearning.org.cn/faq/single-faq/how-do-i-interpret-the-predictions-from-my-model
我们可以使用拟合模型对新数据进行预测,例如通过调用predict()。
你好Jason Brownlee,你发表的作品很棒,谢谢……运行代码时我遇到了这些错误……我已将代码和错误复制在此,请指导我问题出在哪里?
set.seed(7)
> fit.knn # c) advanced algorithms
> # SVM
> set.seed(7)
> fit.svm # Random Forest
> set.seed(7)
> fit.lda fit.rf <- train(Species~., data=dataset, method="rf", metric=metric)
Error in metric %in% c("RMSE", "Rsquared") : object 'metric' not found
你可能漏掉了一行定义metric的代码。
我想要一个用于单类分类的高斯算法的代码
也许可以从谷歌搜索开始?
嗨,Jason,
library(e1071)
set.seed(7)
fit.svm <- train(LoE_DI~., data=dataset2, method="svmRadial", metric=metric, trControl=control)
print(fit.svm)
运行需要很长时间?
比如超过1.5小时?
我需要安装任何包来使其运行得更快吗?
也许可以尝试使用更少的数据?
也许尝试替代模型?
很棒的教程
谢谢
不客气。
这非常有帮助。谢谢Jason。
谢谢,很高兴听到这个。
嗨,Jason,
感谢如此精彩的指南。您能解释一下如何解释散点图矩阵吗?如果用它来绘制两个变量之间的关系,我可以理解。我无法通过您在本教程中绘制的图来理解三个变量之间的关系。
是的,矩阵的每个单元格显示一个变量与另一个变量的关系,所有单元格都显示所有变量与所有其他变量的关系。
它可以帮助我们看到任何明显的变量间依赖关系。
您知道Dodger Loop Sensor问题的有效示例吗?我目前在合并两个CSV数据并使用正确的列时遇到困难。
Dodger Loop Sensor问题是什么?
https://archive.ics.uci.edu/ml/datasets/dodgers+loop+sensor
使用两个数据文件中的数据构建预测模型,以根据环路传感器数据预测棒球比赛的发生。我不知道如何清理和合并数据。似乎没有人解决过这个问题……我被难住了。任何帮助都将不胜感激。
感谢分享。
感谢这篇精彩的教程。您能告诉我如何显示交叉验证步骤的混淆矩阵(总和和/或平均值)吗?虽然评估20%的验证子数据集很有信息量,但我的数据集非常小,因此查看交叉验证步骤的混淆矩阵会更有信息量。
通常,混淆矩阵用于单个训练/测试分割,而不是k折交叉验证。
谢谢Jason,这个网站和它的教程太棒了!我读了很多教科书,目前也正在该领域工作,但在遇到您的网站之前,我仍然感到有些困惑。您让它变得如此简单!非常感谢。
谢谢Kim,很高兴听到这个!
我刚接触机器学习,最后这个模型究竟预测了什么?
我们通过花的测量值来预测花的物种。
你好!感谢您提供本教程。我正在做一个与您的示例非常相似的项目——区别在于它是线性回归。我正在使用caret包和train函数,方法是“full model”、“forward selection/leapForward”和“ridge regression”,并使用“RMSE”作为性能指标。我需要选择RMSE最低的模型。我使用的脚本几乎与示例中的相同。我的问题是我对我的理论感到困惑。以下是我所知道的和我感到困惑的地方:
1) 创建了训练集和测试集
2) 预处理了训练集——居中、缩放并移除了零方差特征
3) 设置了训练控制
4) 构建了3个模型
5) 使用“resamples”比较了结果
6) 选择了RMSE最低的模型(即forward_selection/leapForward模型)
7) 使用“predict”将观测值与forward selection的预测值进行比较
8) 最后,我创建了一个显示观测值和预测值之间误差的表格,并绘制了这些误差。
接下来我该怎么做?使用“lm”时,您会得到一个显示系数、p值、r平方的汇总统计量——但如何使用“leapForward”做到这一点?
我使用了“VarImp”,发现对于forward_selection模型,只有一个特征高度相关——我是否应该使用它来运行另一个使用该单一特征的线性回归?
我快要明白了,但还不够接近,无法弄清楚接下来该怎么做……
我将非常感谢您对此的回复,因为我在构建模型之后的“下一步”上遇到了瓶颈。我们能否使用这个新构建的模型预测全新的数据点,而不仅仅是将其用作训练与测试数据的比较?
感谢您的所有工作!
这个可能会有帮助
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
先生,我的名字是Surya,我来自印度尼西亚,我想问您,我能否将您的机器学习电子书用于教学和商业用途进行翻译?
不可以,请不要这样做。我在这里解释得更详细
https://machinelearning.org.cn/faq/single-faq/can-i-translate-your-posts-books-into-another-language
我遇到了和Muriel一样的问题。当我调用
“install.packages(“caret”, dependencies=c(“Depends”, “Suggests”))”时,未能安装caret包。我能否从任何地方独立下载caret包并在R中安装它?
听到这个消息我很难过。
不可以,您必须使用install.packages()来安装。
Jason,这是一个制作精良的教程。它对我来说真的很有帮助——是的,可能在附加包方面存在一些问题,比如e1071,在我看来需要即时安装。
但是,一个人越是深入研究,就越能理解。我只需要进行更多类似的实际项目。
我来自Power BI领域,想深入了解数据分析和……是的,机器学习和人工智能——谁知道呢!
很棒的教程,真的非常感谢。
谢谢Raivo。
亲爱的 Jason,
非常感谢您的帮助。我有一个问题。在我用测试数据集测试了最佳模型之后,我如何将模型应用于新的未标记数据(例如,根据模型数据对患者或健康个体进行分类)或者甚至只根据模型数据对单个个体进行分类(患病与健康)?
有相关的代码吗?
非常感谢
您可以调用predict()。
请看这个教程
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
对于步骤4.2,我收到以下消息:
Error in stack.data.frame(x) : no vector columns were selected
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
#由于输入变量是数值的,我们创建箱形图
> par(mfrow=c(1,4))
> for(i in 1:4) {
+ boxplot(x[,i], main=names(iris_train)[i])
+ }
Error in oldClass(stats) <- cl
adding class "factor" to an invalid object
这里出了错误,请帮忙
这可能有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
我真的需要这个Hello, World类型的ML项目。谢谢!
我学习了整本《商业数据科学》这本书,这本书在概念理解方面非常棒。他们的意图明确不涵盖算法。尽管如此,一整个学期的零实践未能建立我的信心。
我认为那并不是一个坏计划,因为现在当我运行算法时,我知道它们是什么,这很酷。尽管如此,我真的需要运行一些东西!这个做到了。太棒了。
Error in terms.formula(formula, data = data)
data frame中使用“.”时重复名称“NA”。
我一直收到这个错误。您能告诉我如何调试吗?
很抱歉听到这个消息,也许这个会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
学习过程就这样了。我所做的只是与错误作斗争并寻找帮助,以便通过这个“教程”。
这是一个开始。
从一开始就无法加载我的数据。在您让我命名文件为“iris.csv”的早期步骤中,我做到了,但R-studio之后没有加载任何内容。我不断收到错误消息,并且无法完成第2.2部分。请帮忙!
也许可以尝试将代码复制粘贴到文本编辑器中,然后从命令行运行。我怀疑r-studio正在引入问题。
尊敬的Jason教授,
这是我曾遇到过的最好的R教程。我一步一步地跟着做,它产生了正确的输出。
谢谢。
嗨,这对我很有用。
我有一个疑问。
“R平台为我们提供了iris数据集”,上面有这句话
如果R平台没有提供我想要使用的数据集怎么办?
那么该如何进行呢?
您可以自己加载数据,例如从CSV文件加载。
这里有一个例子
https://machinelearning.org.cn/how-to-load-your-machine-learning-data-into-r/
嗨,Jason,
当我尝试进行预测时,我遇到了一个问题。
当我尝试用所有基数(5952个观测值,23个变量)进行预测时
“Error: `data` and `reference` should be factors with the same levels”
然后,我有一个20%的划分,并显示
“Error in model.frame.default(Terms, newdata, na.action = na.action, xlev = object$xlevels) factor SECTOR.ADH has new levels Sector No Definido (solo para bolsas y envoltorios)
非常感谢,
很抱歉听到您遇到的问题,我不知道错误的原因,也许这会给您一些启发
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
为了解决一些人报告的rpart问题,请使用:data = data.frame(name of your data)。下面提供了一个示例。
fit.cart <- train(Species~., data = data.frame(trainset), method="rpart", metric=metric, trControl=control)
感谢分享!
另外,Jason,非常感谢您的出色工作!
不客气!
你好,Jason。
您对如何准备包含不同尺度和单位的数据(例如,年龄、性别、开始时间、开始日期、距离等)进行机器学习项目有什么想法吗?
是的,在建模之前通常需要将数据缩放到相同的范围。
日期可能需要分解成相关的元素(日/月/等)。
亲爱的 Jason,
我刚读完您的电子书《R语言机器学习精通》,非常感谢您,我非常享受这本书的旅程。这是一项优秀而令人印象深刻的务实工作。
我在我的博客上发表了一篇文章,地址是:http://questioneurope.blogspot.com/2020/05/machine-learning-mastery-with-r-jason.html
诚挚的问候,
Dominique
做得好,Dominique!
很棒的文章,我是写书评/报告的忠实粉丝。
嗨,内容很棒。
我从上周日开始就一直在与rlang 0.4.6包斗争。当我输入library(caret)时,程序显示
Error: package or namespace load failed for ‘caret’ in loadNamespace(i, c(lib.loc, .libPaths()), versionCheck = vI[[i]])
namespace ‘rlang’ 0.4.5 is already loaded, but >= 0.4.6 is required
请问您能解释一下如何解决这个问题吗?我已经按照您上面的指示安装了整个包。我也尝试使用这个链接https://cran.r-project.cn/web/packages/rlang/index.html,但显示的消息相同。
谢谢您的回答。
附注:我使用的是win 10上的r 4.0.0版本。
很抱歉听到您遇到的问题,也许可以尝试在stackoverflow或r用户列表上发帖。
嗨,又来了
在我尝试了许多次在R中运行library(caret)之后。我下载了Rstudio中的rlang包,然后我之前无法在R中运行的所有库现在都可以使用了。也许Rstudio在重新启动程序后会执行正确的包安装步骤。
谢谢您的回答。
我建议不要使用rstudio,而是直接从R提示符运行示例。
@luis,首先从R studio重新启动R会话,这有助于卸载所有已加载的包。重新启动后,在加载任何包之前更新所有包。您遇到的错误是因为您试图更新一个已加载的包。
我想问一下
R和Python有什么区别?
因为在我看来,它们都是一样的,只是具有不同的优势。
那么,如果存在差异,R相对于Python的优势是什么?
如果它们没有区别,那么为什么使用R而不是Python,Python更受欢迎,因为使用它的人越多,我们获得的来自用户的支持就越多,例如错误解决方案等。
客观差异:R功能更丰富但更难使用,Python方法较少但更系统、更易于使用。
如果你的观点成立,那么R语言适合一次性项目和研发项目,而Python则适合运维/生产系统。
事实上,人们使用他们喜欢的东西。是品味,而非客观价值。
感谢Jason的精彩博文。我是数据科学新手,事实上我才刚开始几天。每次下载数据集在 R 中练习时,我都会感到非常困惑。虽然有时我花了比平常更长的时间来弄清楚如何仅使用置信水平来计算 Z 分数和 T 分数。我对下载的数据集感到非常茫然,因为它们没有附带任何业务问题。由于只有数据集,我通常会运行绘图命令,查找缺失值,查找正态分布等,因为我发现一些数据集与回归等完全无关。您会如何建议新手在数据集中寻找业务问题或数据收集的目的?这将非常有帮助。
我正在寻找像您一样的导师。
提前感谢!
啊……还有,我来自生物技术背景,没有编码经验,我查阅了《R in Action》,并尝试模仿其中的命令来理解代码。
不客气。
也许可以找一些你更能产生共鸣的示例数据集,这会有帮助。
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-dataset-on-___
当我尝试构建模型时,会收到以下错误:
> set.seed(7)
> fit.lda <- train(Species~., data=dataset, method="lda", metric=metric, trControl=control)
Error: package e1071 is required
找不到要安装的软件包。
尝试安装 e1071。
Jason,感谢您提供了关于 R 和分类问题的精彩入门教程。我已经完成了它,并将其首次应用于我自己的数据。我的问题是:
我如何才能获得对未知分类的质量或拟合优度的指示?毕竟,新数据可能不如训练/验证数据集与模型匹配得好。此外,新数据可能属于训练练习中未包含的类别,因此您不应该期望获得良好的匹配。
谢谢。
不客气。
大多数模型都可以预测一个概率,这有助于解释预测的不确定性。
模型无法预测训练期间未见过的新类别。
你好,Jason Brownlee,
感谢这个很棒的免费教程。请问,当我执行
“# list types for each attribute
sapply(dataset, class)”
时,会得到不同的结果。以下是我的输出:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
“numeric” “numeric” “numeric” “numeric” “character”
我得到的是“character”而不是“factor”,当我执行
# 列出类别的级别
levels(dataset$Species)
时,输出是 NULL。
请问,我该如何解决这个问题?
非常感谢
也许可以确保您是在命令行或 R 提示符下运行示例,并且您的 R 版本是最新的。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢您的回复。但我使用的是最新版本的 R,我从命令行提示符运行,但问题仍未解决,我仍然得到“character”而不是“factor”。
听到这个消息我很难过。我会进行调查。
更新:代码本身就可以工作。请确保您复制的代码完全正确。
很棒的教程。我想知道:在对观测值进行二分类预测时,我该如何考虑我更关心特异性而不是敏感性?我想在几十个观测值中进行特征选择,同时牢记特异性不应低于某个阈值。
乐于听取建议!
谢谢。
好问题。您可以设置您偏好的指标,并使用类似 RFE 的方法来选择优化该指标的特征。
非常感谢……我们从实践中学习……我最喜欢的。
不客气。
谢谢。
对于那些收到 CreateDataPartition() 错误的读者:
这是解决方案:
install.packages(“caret”)
install.packages(“caret”, dependencies=c(“Depends”, “Suggests”))
install.packages(“ellipse”, dependencies = TRUE)
好建议!
当我尝试使用导入的 .csv 文件进行绘图时,会收到警告:
NAs introduced by coercion
然后绘图为空。对此有什么建议吗?
也许可以在绘图前检查已加载数据的 contents,以确保数据已正确加载。
install.packages(“caret”, dependencies=c(“Depends”, “Suggests”)) 的建议是个笨办法。半小时后……
不过剩下的部分都相当不错 :)
谢谢!
在某些系统上可能会很慢。
这里有很多好东西。我很高兴看到您的文章。
非常感谢,我期待与您联系。
您能否给我发封电子邮件?
谢谢。
你随时可以在这里联系我
https://machinelearning.org.cn/contact/
感谢本教程。
我正在尝试处理(训练)一个数据集,并收到此错误消息。
> lda <- train(rating ~ ., method = "lda", data = train_set)
Error in na.fail.default(list(rating = c(5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
missing values in object
请问,我对哪里出错或未做的事情有什么建议吗?
也许可以检查您的数据集是否符合模型期望。
这是来自流行的 movielens。我以前处理过 movielens 的数据,但不知道为什么这次不行。
另外,我尝试使用本教程中学到的 featurePlot() 处理数据集,但都返回 NULL。
请问我还能检查什么,或者我如何检查模型是否符合期望?
我真的很感激您的帮助。
也许您可以回顾一下加载的数据,也可以查阅您尝试使用的模型的文档。
谢谢,我会试试的。
请问,我如何获得本教程的续集?也就是 RMSE、推荐等内容的制作。
本教程将为您提供使用 RMSE 评估回归模型的示例:
https://machinelearning.org.cn/spot-check-machine-learning-algorithms-in-r/
嗨,Jason,
我尝试了这些代码片段,并且一切正常,直到 plot(y)。执行 “plot(y)” 时,我收到以下错误。您能帮忙吗?
“Error in plot.window(…) : need finite ‘ylim’ values’ “
很抱歉听到这个消息,也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢这篇教程。
只是一个问题……我怎么知道哪种颜色对应哪种响应类别?
我借用了这段代码来玩我自己的数据集,但我不知道蓝色、粉色和绿色分别对应哪个级别在 featurePlots 中。
也许您可以在图中添加一个图例。
也许您可以指定类别到颜色的映射。
你好,
我的以下任何一个都无法正常工作。我想知道正确的数值或参数,如果您能帮助至少一种模型的话。
# a) 线性算法
set.seed(7)
fit.lda <- train(Species~., data=dataset, method="lda", metric=metric, trControl=control)
# b) 非线性算法
# CART
set.seed(7)
fit.cart <- train(Species~., data=dataset, method="rpart", metric=metric, trControl=control)
# kNN
set.seed(7)
fit.knn <- train(Species~., data=dataset, method="knn", metric=metric, trControl=control)
# c) 高级算法
# SVM
set.seed(7)
fit.svm <- train(Species~., data=dataset, method="svmRadial", metric=metric, trControl=control)
# 随机森林
set.seed(7)
fit.rf <- train(Species~., data=dataset, method="rf", metric=metric, trControl=control)
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢这个很棒的教程!
只是一个问题……在预测步骤中,我们是否应该只将自变量发送到 “validation” (即 x_test),而不是所有的 validation?
这不应该是
predictions <- predict(fit.lda, validation[1:4]) ?
谢谢!
是的,模型是在未用于训练的数据上进行评估的。
你好 Jason,
感谢教程,我能否将上述代码用于连续变量,以便从没有分类问题的 数据集中预测模型?
不客气。
请看这个教程:
https://machinelearning.org.cn/spot-check-machine-learning-algorithms-in-r/
你好,
感谢您的教程 Jason!
我正在尝试使用机器学习、基于树的方法、随机森林、PCA、Boosting、聚类等来构建预测模型。如果响应变量是离散变量,我可以使用上述教程吗?或者您会推荐我查看什么?
谢谢
也许您可以将上述教程作为一个起点。
请问,我还是一个新手。
在进行这个项目时,
1. 项目的目的是什么?
2. 在哪个阶段实现了目标?
Aaron Chidi
我们开发了一个预测模型,该模型以花朵的测量值为输入,并预测或分类花朵的种类。
更广泛地说,该项目旨在让您熟悉 R 中的预测建模——这是一个入门项目。
谢谢 Jason。我是 R 的新手。
我通过这个项目并让它在 Google Colab 的 R 中运行成功了。
干得好!
先生,它显示物种的类为字符
并且 levels(dataset$Species) 也为 NULL。
你好,
感谢您的帖子。我是在搜索完成我部分工作(这里提到的)后的客户交接清单时来到这里的。
我如何将其交给非技术人员?我需要一个完整的项目示例,也就是说,在我交付后,他们将如何操作才能获得结果并根据需要打印报告。
作者或任何人能帮我解决这个问题吗?
再次感谢。
抱歉,我无法帮助您将模型交给非技术人员。
你好,
不错的教程!但是当我运行它时,我收到了这个错误消息:
“Error:
dataandreferenceshould be factors with the same levels”.当我运行这个命令时:
confusionMatrix(predictions, validation$Species)
请指教。
谢谢你
听到这个消息很抱歉,这可能会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason,
不幸的是,我早就遇到了我的第一个问题。我已按照所有步骤和所有代码进行操作,但没有出现 120 个实例(行)和 5 个属性(列),而是出现了 30 个实例和 5 个属性。
请协助。
谢谢你,
Georgie
很抱歉听到这个消息,也许这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
感谢这个很棒的教程!
一切顺利 +/- 建议的修复,并且它提供了一个非常有意义的学习体验。
一个小问题,当我运行代码 print(fit.lda) 时,输出与您显示的一样,除了 SD。我的屏幕上的准确度和 Kappa 结果仅显示以下内容:
Accuracy Kappa
0.975 0.9625
没有附带的 SD。
问题出在哪里?感谢您的建议。谢谢!
干得好!
我怀疑 API 自教程编写以来已经发生了变化。
知道了,谢谢。
嗨 Nai,
我遇到了同样的问题,可以通过以下代码解决。
fit.lda$results
顺便说一句,非常感谢 Jason 的精彩教程!!
祝好,
谢谢 Jason!一个新手能够从头到尾经历所有阶段,这是非常罕见的。
谢谢你。很高兴你喜欢。
嗨 Jason,感谢这份指南。我在 predict 时遇到了一个错误。Error in eval(predvars, data, env) : object ‘Septal.Length’ not found。我已仔细检查了代码,一切都与教程一致。Stack Overflow 也没能提供帮助。
您对这个错误有什么建议或如何修复它吗?
谢谢,Jack
嗨 Jack…请提供您的完整代码列表,以便我们查看是否能发现任何问题。
此致,
嗨,这个教程很好而且很有帮助,但是在最后两行代码时,我收到了和 JACK 一样的错误?
嗨 TD…请粘贴准确的错误描述,以便我更好地帮助您。
我觉得这里缺少了什么,您能向我们展示如何实际输入一些值来展示模型将如何预测吗?难道这不正是预测模型的意义所在吗?
是我错过了什么吗?
所以如果我输入一些预测值,它应该会猜测它属于哪个类别?
谢谢!
嗨 Ray…您可能会对以下内容感兴趣:
https://www.dataquest.io/blog/statistical-learning-for-predictive-modeling-r/
我希望您能用您的例子来展示!我知道如何预测简单的线性模型,但不知道如何使用您有 4 个预测变量的例子来预测类别,这是否可以通过几行代码就可以简单地完成?
雷
嗨,我想问一下,为什么我运行这个代码仍然出错,而我的朋友运行它却没问题?
代码:model_svm_rbf <- svm(Class~., data = trainData, method= "svmRadial", trControl=fitcontrol)
错误:Error in svm.default(x, y, scale = scale, …, na.action = na.action)
回归需要数值因变量。
嗨 Qin…您是输入代码还是复制粘贴的代码?另外,您是否尝试过在 Google Colab 中运行代码?
亲爱的朋友们
我是物种分布建模的初学者。我有一个问题,为什么我们使用 25% 的数据进行测试,而 75% 的数据用于训练?为什么研究人员经常使用这些比例?
嗨 Alia…以下资源可能对您有益:
https://machinelearning.org.cn/training-validation-test-split-and-cross-validation-done-right/