自回归积分移动平均模型或 ARIMA 模型对于初学者来说可能令人生畏。
揭开该方法面纱的一个好方法是使用训练好的模型手动进行预测。这表明 ARIMA 本质上是一个线性回归模型。
使用拟合的 ARIMA 模型进行手动预测也可能是您项目中的一项要求,这意味着您可以保存拟合模型的系数,并在自己的代码中将其用作配置来进行预测,而无需在生产环境中依赖繁重的 Python 库。
在本教程中,您将学习如何使用 Python 中训练好的 ARIMA 模型进行手动预测。
具体来说,您将学习
- 如何对自回归模型进行手动预测。
- 如何对移动平均模型进行手动预测。
- 如何使用自回归积分移动平均模型进行预测。
快速启动您的项目,阅读我的新书 《Python 时间序列预测入门》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。
- 2020 年 12 月更新:将 ARIMA API 更新为最新版本的 statsmodels。

如何使用 Python 为 ARIMA 模型进行手动预测
图片由 Bernard Spragg. NZ 拍摄,保留部分权利。
日最低气温数据集
此数据集描述了墨尔本市 10 年(1981-1990 年)的每日最低气温。
单位是摄氏度,共有3650个观测值。数据来源归功于澳大利亚气象局。
下载数据集,并将其放入您当前的工作目录中,文件名为“daily-minimum-temperatures.csv”。
下面的示例演示了如何将数据集加载为 Pandas Series 并绘制加载的数据集。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0) series.plot() pyplot.show() |
运行示例将生成时间序列的折线图。
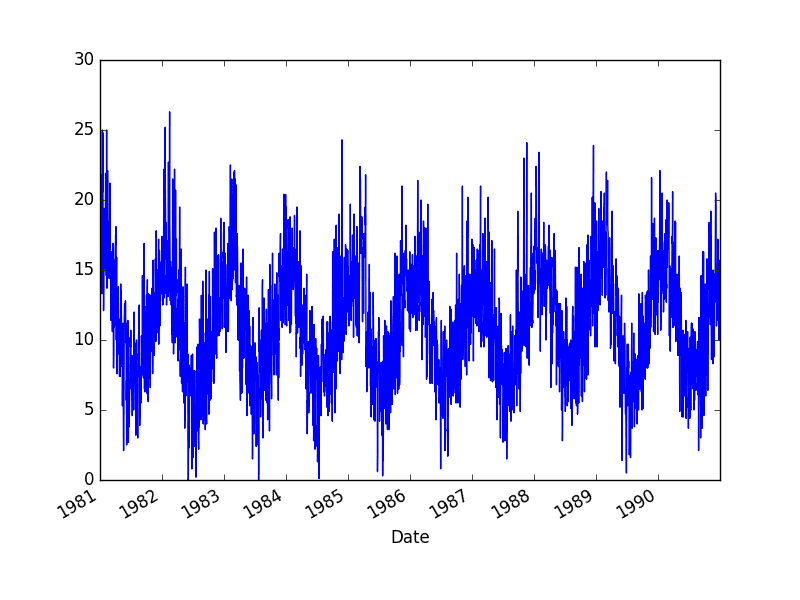
每日最低气温数据集图
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
ARIMA 测试设置
我们将使用一致的测试框架来拟合 ARIMA 模型并评估其预测。
首先,加载的数据集被分成训练集和测试集。数据集的大部分用于拟合模型,最后 7 个观测值(一周)作为测试集,用于评估拟合模型。
采用以下向前滚动验证或滚动预测方法:
- 遍历测试数据集中的每个时间步。
- 在每次迭代中,都会在所有可用历史数据上训练一个新的 ARIMA 模型。
- 该模型用于对下一天进行预测。
- 存储预测值,并从测试集中检索“真实”观测值,然后将其添加到历史数据中,以便在下一次迭代中使用。
- 模型性能在最后通过计算所有预测值与测试数据集中的预期值之间的均方根误差 (RMSE) 来进行汇总。
开发了简单的 AR、MA、ARMA 和 ARMA 模型。它们未优化,仅用于演示目的。稍加调整,您肯定可以获得更好的性能。
使用了 statsmodels Python 库中的 ARIMA 实现,并通过拟合模型返回的 ARIMAResults 对象提取 AR 和 MA 系数。
ARIMA 模型通过 predict() 和 forecast() 函数支持预测。
尽管如此,在本教程中我们将使用学习到的系数进行手动预测。
这很有用,因为它表明从训练好的 ARIMA 模型中只需要系数。
statsmodels 实现的 ARIMA 模型中的系数不包含截距项。这意味着我们可以通过将学习到的系数与滞后值(对于 AR 模型)和滞后残差(对于 MA 模型)进行点积来计算输出值。例如:
|
1 |
y = dot_product(ar_coefficients, lags) + dot_product(ma_coefficients, residuals) |
可以使用以下方法从 ARIMAResults 对象访问学习到的 ARIMA 模型的系数:
- AR 系数:model_fit.arparams
- MA 系数:model_fit.maparams
我们可以使用这些检索到的系数,通过以下自定义的predict() 函数进行预测。
|
1 2 3 4 5 |
def predict(coef, history): yhat = 0.0 for i in range(1, len(coef)+1): yhat += coef[i-1] * history[-i] return yhat |
供参考,您可能会发现以下资源很有用







嗨,Jason,
感谢这篇教程。
现在出现以下错误,请告知。
我也认为代码没有错误。
—> 23 model_fit = model.fit(trend=’nc’, disp=False)
ValueError: 无法将字符串转换为浮点数:“?0.2”
谢谢
打开下载的数据文件,删除所有“?”字符实例。
它运行正常。
我没想到这会是由将文件转换为 CSV 引起的。
谢谢你,Jason。
很高兴听到这个消息!
嗨 Jason
非常感谢您的文章,我有一个问题:在本例中,为什么我们使用迭代的方式来确定 ARIMA 参数?能否在测试数据集的循环之前固定模型参数,然后进行验证过程?
非常感谢您提供更多见解。
我不确定您的意思是“迭代”?您能否详细说明一下?
感谢您的反馈,Jason,我之前的意思是:
…
for t in range(len(test))
model = ARIMA(history, order=(1,1,1))
…
我们看到在每个循环中,我们都会重新训练模型并获得一组新的参数。为什么不只根据训练集来训练模型,并固定模型中的所有参数,然后遍历所有测试集并验证它们的误差呢?
再次感谢您的回复。
你可以这样做,但如果我们有新数据(例如,下一个月有一个新的观测值),那么我们应该使用它。
这就是我们在这里模拟的。这叫做“前向验证”。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
非常感谢 Jason。
链接里的例子很好。我发现您的帖子中有很多非常有用的信息,我会阅读其他帖子并提问(如果我有的话)。
再次感谢您的工作,做得很好。🙂
谢谢你,Luca!
假设我每周有两组数据记录了几年,例如周一和周五的数据。这会影响模型吗?这对于差分函数有意义吗?
可能会,这取决于具体问题。
我读过您网站上关于ARIMA的几篇教程。有些使用差分函数,有些不使用,比如参数调优。我什么时候需要差分函数?
当你有趋势时,请阅读这个。
https://machinelearning.org.cn/difference-time-series-dataset-python/
嗨 Jason
由于该数据集似乎具有很强的季节性,在这种情况下,我们是否需要先分解数据,去除季节性因素,然后应用ARIMA等模型?
谢谢
先对数据集进行季节性调整会是个好主意。
https://machinelearning.org.cn/time-series-seasonality-with-python/
嗨,Jason,
感谢所有 ARIMA 教程!我正在准备分析去年夏天在生物力学实验室进行的步态数据,这些教程帮助我掌握了模型。
可以考虑神经网络模型吗?
嗨,Jason,
想象一个场景,我们正在使用拟合的 ARIMA 模型,即在新的(样本外)数据集上的系数。计算 AR 部分很容易。使用长度为“p”的先前数据(历史)。而对于 MA 部分,则需要过去“q”值的残差。在没有对新数据进行拟合的情况下,如何计算新数据的残差?我们是否使用训练数据中的残差?这对于 q>0(即有 MA 系数)的 ARIMA 模型很有用。
好问题。我认为 ARIMA 模型会在“model_fit.resid”中提供这些。
感谢您的帖子,很有帮助。
但我有个问题,为什么在每个循环中历史数据都需要附加测试数据?
model = ARIMA(history, order=(1,0,0))
obs = test[t]
history.append(obs)
如果我不知道测试数据的值,例如只预测 6 个月或 1 年(365 天范围)的值,如何使用模型进行预测?就像机器学习一样,使用训练集训练模型,然后预测新数据。
因为我们正在使用前向验证来评估模型。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
嗨,Jason,
非常感谢这些 ARIMA 帖子,我对时间序列知之甚少,我正在学习这些内容,以便完成一个查找交叉相关矩阵的项目。我需要预白化数据,并使用了您的教程来拟合一个模型到我的一个序列上。接下来,我必须将这个模型(滤波器)应用于另一个序列,我想知道您是否可以详细说明如何使用 predict 来做到这一点。我一直在网上搜索资料,但我不知道“params”字段的具体内容和格式应该是什么。
非常感谢!
这可能是一个很好的时间序列入门。
https://machinelearning.org.cn/start-here/#timeseries
抱歉,我没有关于如何白化时间序列的资料。
您好,是否可以将其他变量集成到 ARIMA 模型中进行预测?
我找不到关于这个问题的答案。
是的,这被称为外生变量。
抱歉,我没有例子。
您好!我该如何预测例如 20 个读数?
mod =ARIMA(X, order=(self.p, self.d, self.q)
res = mod.fit()
res.forecast(20)
也许这篇文章会有所帮助
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
你好 Jason,
在示例中,您说有 3650 个观测值,并将最后 7 天作为测试集……我对我自己的数据集有点困惑。我有 30 年的 7 个天气参数的周数据。我该如何选择训练集和测试集?
也许可以尝试一下,看看需要多少历史数据才能用您的特定数据拟合一个有技巧的模型。
这篇帖子可能会给您一些启发。
https://machinelearning.org.cn/sensitivity-analysis-history-size-forecast-skill-arima-python/
我尝试了您手动预测序列的方法(我认为是正确的)以及 statsmodels 的 .predict()。您能解释一下为什么它们不完全相同吗?statsmodels 对它们如何进行预测并不太清楚。谢谢!
predict() 和 forecast() 函数应该返回相同的结果。
在此处了解如何使用它们。
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
我有一个问题,这里的 ACF 和 PACF 是如何获得的?我有一个类似的数据集,有近 1100 个观测值,根据我的 ACF 和 PACF,ACF 在 1 到 27 的滞后项中非常显著。我还想知道当我们有如此大的值时,ARIMA 模型是否存在限制。
我使用了 statsmodels 的绘图函数。
嗨,我认为 ARIMA 模型在差分方面存在一个大错误。
当我们使用 AIRMA(p,d,q) 时,如果 d 不等于 0,模型已经完成了差分步骤。
因此,预测结果数据也已经进行了差分,所以我们需要恢复数据。
但是恢复后的结果(无差分)是错误的。预测误差非常大。
在您的许多 ARIMA 示例中,例如 ARIMA(5,1,0),d = 1,但我没有找到恢复差分。
如果 ARIMA(5,0,0),则不需要恢复差分。
我所说的差分是 ARIMA(p,d,q) 中的参数 d。
我认为也许 python 的 ARIMA 模型有一些小错误。
模型将在进行预测时反转差分(如果需要)。
嗨,Jason,我有一个关于训练和验证的问题。
在这四个例子中,您将数据分为训练集和测试集。但在您的预测中,您还将测试集中的数据添加到历史数据中。这样做可以吗?根据我的理解,使用测试集中的数据是不正确的。
另一个问题是关于预测。根据文档(https://statsmodels.cn/dev/generated/statsmodels.tsa.arima_model.ARMAResults.forecast.html#statsmodels.tsa.arima_model.ARMAResults.forecast),我们可以进行多步预测。为什么您不直接使用这些步数呢?
是的,这被称为前向验证,更多内容请参见此处。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
我看到了链接。它很详细。我也查看了其他网页。似乎“前向验证”在机器学习中并不常见。如果我们想将结果与其他方法进行比较,我们应该怎么做?
如果我们使用其他复杂的方法并使用“前向验证”,这将浪费大量时间来训练模型。
谢谢。
这在时间序列预测问题中很常见。
其他方法应该采用这种方法,如果它们不这样做,例如使用交叉验证,那么它们的结果几乎肯定无效。
我如何计算时间序列的训练误差?
通常我们使用均方误差 (MSE) 或均方根误差 (RMSE)。
这太棒了,谢谢!我一直在寻找一种手动计算参数预测的方法,因为我需要在其他上下文中保存参数进行预测。我找不到任何让我信服的文档,所以谢谢你!
我很高兴它有帮助!
是的,我们计算 RMSE,但是怎么计算呢?实际值和预测值将是什么?
您可以使用 sklearn 来计算 RMSE。
计算 MSE,然后取平方根。
https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.mean_squared_error.html
嗨,Jason,
首先,感谢您的教程。我脑子里有几个问题。首先,如果我进行多步预测,并且用一些数字定义 AR 和 MA 项,这是否意味着模型会回顾一定数量的过去步骤进行预测?如果我将整个历史时间序列引入模型,模型如何利用所有历史数据进行多步预测?AR 和 MA 项中的系数是如何更新的?如果我能理解它们,我将非常感激。
此致,
古奈
也许这会有帮助。
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
嗨,Jason,
感谢您的教程!我有一个关于设置 yhat 的问题。在 (0,0,0)、(0,1,1)、(1,1,0) 和 (0,1,0) 的情况下,yhat 会等于什么?对于这些情况,我们应该为 predict 函数使用什么参数?
谢谢你,
Emilio
我不太明白。
yhat 是模型做出的预测。
顺序(例如 (0,1,0))是模型的配置。
这有帮助吗?
所以,假设我有一个 0,1,0 ARIMA 模型。我需要一个常数项才能运行它。我应该如何将常数项纳入 predict 函数?对于 0,1,0 以及其他情况都是如此吗?
好问题,也许可以查看源代码,了解 statsmodels 的实现是如何纳入常数的。
或者直接使用 statsmodels 模型。
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
感谢这篇文章。那么,我能否问一下如何使用这个模型来预测未来的日期?这个实践展示了对当前数据的预测。
谢谢
是的,我在这里展示了如何操作
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
感谢您撰写此文。我一直很喜欢您的文章。
对于像 ARIMA(4,1,1) 这样的高阶模型,这会如何工作?
基本原理相同,尽管诉诸 forecast() 或 predict() 函数可能会更容易。
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
这是我的代码:
from statsmodels.tsa.arima_model import ARIMA
from sklearn.metrics import mean_squared_error
train= training_set[‘Close’].values.reshape(-1, 1) # reshaping training values
test = test_set.values.reshape(-1, 1)
history = [x for x in train]
predictions = list()
for t in range(len(test))
model = ARIMA(history, order=(1,2,1))
model_fit = model.fit(trend=’nc’, disp=False)
ar_coef, ma_coef = model_fit.arparams, model_fit.maparams
resid = model_fit.resid
diff = difference(history)
yhat = history[-1] + predict(ar_coef, diff) + predict(ma_coef, resid)
predictions.append(yhat)
obs = test[t]
history.append(obs)
print(‘>predicted=%.3f, expected=%.3f’ % (yhat, obs))
rmse = sqrt(mean_squared_error(test, predictions))
print('Test RMSE: %.3f' % rmse)
输出
>predicted=3366.015, expected=3370.000
>predicted=3371.046, expected=3390.000
>predicted=3369.670, expected=3370.000
>predicted=3392.017, expected=3377.800
>predicted=3373.568, expected=3460.000
>predicted=3369.171, expected=3460.000
>predicted=3452.457, expected=3400.000
>predicted=3469.630, expected=3458.100
>predicted=3402.823, expected=3490.000
>predicted=3449.645, expected=3490.000
>predicted=3488.853, expected=3442.200
>predicted=3498.426, expected=3468.300
>predicted=3447.526, expected=3489.000
>predicted=3465.161, expected=3510.000
>predicted=3486.675, expected=3485.000
>predicted=3513.211, expected=3498.900
>predicted=3489.170, expected=3500.000
>predicted=3499.777, expected=3580.000
>predicted=3493.101, expected=3495.200
>predicted=3583.419, expected=3545.500
>predicted=3503.000, expected=3720.000
—————————————————————————
ValueError 回溯 (最近一次调用)
in
8 for t in range(len(test))
9 model = ARIMA(history, order=(1,2,1))
—> 10 model_fit = model.fit(trend=’nc’, disp=False)
11 ar_coef, ma_coef = model_fit.arparams, model_fit.maparams
12 resid = model_fit.resid
~/anaconda3/lib/python3.7/site-packages/statsmodels/tsa/arima_model.py in fit(self, start_params, trend, method, transparams, solver, maxiter, full_output, disp, callback, start_ar_lags, **kwargs)
1155 arima_fit.mle_retvals = mlefit.mle_retvals
1156 arima_fit.mle_settings = mlefit.mle_settings
-> 1157
1158 return ARIMAResultsWrapper(arima_fit)
1159
~/anaconda3/lib/python3.7/site-packages/statsmodels/tsa/arima_model.py in fit(self, start_params, trend, method, transparams, solver, maxiter, full_output, disp, callback, start_ar_lags, **kwargs)
944 kwargs.setdefault(‘pgtol’, 1e-8)
945 kwargs.setdefault(‘factr’, 1e2)
–> 946 kwargs.setdefault(‘m’, 12)
947 kwargs.setdefault(‘approx_grad’, True)
948 mlefit = super(ARMA, self).fit(start_params, method=solver,
~/anaconda3/lib/python3.7/site-packages/statsmodels/tsa/arima_model.py in _fit_start_params(self, order, method, start_ar_lags)
560 pgtol=1e-7, factr=1e3,
561 bounds=bounds, iprint=-1)
–> 562 start_params = mlefit[0]
563 if self.transparams
564 start_params = self._transparams(start_params)
~/anaconda3/lib/python3.7/site-packages/statsmodels/tsa/arima_model.py in _fit_start_params_hr(self, order, start_ar_lags)
546 return start_params
547
–> 548 def _fit_start_params(self, order, method, start_ar_lags=None)
549 if method != ‘css-mle’: # use Hannan-Rissanen to get start params
550 start_params = self._fit_start_params_hr(order, start_ar_lags)
ValueError: The computed initial MA coefficients are not invertible
您应该强制执行可逆性,选择不同的模型顺序,或者您可以
传递您自己的 start_params。
是的,某些配置将导致模型不稳定。
老师您好,我有一个关于使用手动预测和使用库进行预测的问题。
我比较了两个结果,但它们显示的结果不同。
我使用了这个模型拟合:
model_fit = model.fit(trend=’nc’, disp=False)。我使用的库模型显示了恒定的结果。例如 [10.234,10.235,10.235,….10.235,]。您能帮帮我吗?🙂
您可能需要深入研究 statsmodels 的源代码,看看使用了哪些额外的步骤。
我想知道为什么我们不在此教程中使用常数,以及为什么 disp= False?我尝试使参数相同,但结果与预测不同。
我们将 display 设置为 False 以删除冗余输出。
先生您好,感谢您的贡献。
我的数据已经预处理为 -1 到 1 的范围。我正在对 ARIMA 进行前向验证。
模型会为某些观测值预测出该范围之外的极高值。
有什么原因吗?
谢谢你。
也许模型需要针对您的数据集进行进一步调整?
也许您需要将数据缩放到不同的范围?
也许尝试替代模型?
先生您好,我想确认几点。假设我的数据集需要“2”阶差分。
那么它将是
def difference(dataset)
diff = list()
for i in range(1, len(dataset))
value = dataset[i] – dataset[i – 2]
diff.append(value)
return numpy.array(diff)
model = ARIMA(history, order=(0,2,0))
这样对吗?
我其实对这个函数有点困惑。