大量数据、标记数据、噪声数据。机器学习项目都需要关注数据。数据是机器学习项目的一个关键方面,而我们处理数据的方式是我们项目的一个重要考虑因素。当数据量增长,需要管理它们,让它们服务于多个项目,或者只是需要一种更好的方法来检索数据时,考虑使用数据库系统是很自然的。它可以是关系数据库,也可以是平面文件格式。它可以是本地的,也可以是远程的。
在本帖中,我们将探讨您可以在 Python 中用来存储和检索数据的不同格式和库。
完成本教程后,您将学习到:
- 使用 SQLite、Python dbm 库、Excel 和 Google Sheets 管理数据
- 如何使用外部存储的数据来训练您的机器学习模型
- 在机器学习项目中使用数据库的优缺点是什么
开始您的项目,阅读我的新书《Python for Machine Learning》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧!
使用 Python 管理数据
照片作者:Bill Benzon。部分权利保留。
概述
本教程分为七个部分,它们是:
- 在 SQLite 中管理数据
- SQLite 实操
- 在 dbm 中管理数据
- 在机器学习管道中使用 dbm 数据库
- 在 Excel 中管理数据
- 在 Google Sheets 中管理数据
- 数据库的其他用途
在 SQLite 中管理数据
当我们提到数据库时,通常指的是以表格格式存储数据的关系数据库。
首先,让我们从 sklearn.dataset 获取一个表格数据集(想了解更多关于获取机器学习数据集的信息,请看我们的上一篇文章)。
|
1 2 3 |
# 从 OpenML 读取数据集 from sklearn.datasets import fetch_openml dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] |
以上几行代码从 OpenML 读取“PimaIndiansDiabetes 数据集”并创建一个 pandas DataFrame。这是一个分类数据集,具有多个数值特征和一个二元类别标签。我们可以用以下方式探索 DataFrame:
|
1 2 |
print(type(dataset)) print(dataset.head()) |
这给我们带来了
|
1 2 3 4 5 6 7 |
<class 'pandas.core.frame.DataFrame'> preg plas pres skin insu mass pedi age class 0 6.0 148.0 72.0 35.0 0.0 33.6 0.627 50.0 tested_positive 1 1.0 85.0 66.0 29.0 0.0 26.6 0.351 31.0 tested_negative 2 8.0 183.0 64.0 0.0 0.0 23.3 0.672 32.0 tested_positive 3 1.0 89.0 66.0 23.0 94.0 28.1 0.167 21.0 tested_negative 4 0.0 137.0 40.0 35.0 168.0 43.1 2.288 33.0 tested_positive |
这不是一个非常大的数据集,但如果它太大了,可能无法全部加载到内存中。关系数据库是帮助我们高效管理表格数据而不必将所有数据保留在内存中的工具。通常,关系数据库会理解 SQL 方言,这是一种描述数据操作的语言。SQLite 是一种无服务器的数据库系统,无需任何设置,并且 Python 内置了库支持。在下面,我们将演示如何使用 SQLite 管理数据,但使用 MariaDB 或 PostgreSQL 等不同的数据库,它们的操作方式非常相似。
现在,让我们开始创建一个 SQLite 中的内存数据库,并获取一个游标对象,以便我们可以在新数据库上执行查询。
|
1 2 3 4 |
import sqlite3 conn = sqlite3.connect(":memory:") cur = conn.cursor() |
如果我们想将数据存储在磁盘上,以便稍后重用或与另一个程序共享,我们可以将数据库存储在数据库文件中,而不是在上面的代码片段中用文件名(例如 `example.db`)替换 `:memory:` 这个特殊字符串,如下所示:
|
1 |
conn = sqlite3.connect("example.db") |
现在,让我们创建一个新的表来存储我们的糖尿病数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... create_sql = """ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) """ cur.execute(create_sql) |
cur.execute() 方法执行我们作为参数传递的 SQL 查询。在本例中,SQL 查询创建了 `diabetes` 表,其中包含不同的列及其相应的数据类型。此处不描述 SQL 语言,但您可以从许多数据库书籍和课程中了解更多信息。
接下来,我们可以从存储在 pandas DataFrame 中的糖尿病数据插入到我们新创建的内存 SQL 数据库的糖尿病表中。
|
1 2 3 4 |
# 准备一个用于插入的参数化 SQL insert_sql = "INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)" # 使用 dataset.to_numpy().tolist() 中的每个元素多次执行 SQL cur.executemany(insert_sql, dataset.to_numpy().tolist()) |
让我们分解一下上面的代码:dataset.to_numpy().tolist() 为我们提供了 dataset 中数据的行列表,我们将此列表作为参数传递给 cur.executemany()。然后,cur.executemany() 多次运行 SQL 语句,每次使用 dataset.to_numpy().tolist() 中的一个元素,该元素是 dataset 的一行数据。参数化 SQL 每次都期望一个值的列表,因此我们应该将列表的列表传递给 executemany(),这正是 dataset.to_numpy().tolist() 生成的。
现在,我们可以检查以确认所有数据都已存储在数据库中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pandas as pd def cursor2dataframe(cur): """从游标读取列标题,然后读取其中的 数据。之后,创建一个 DataFrame""" header = [x[0] for x in cur.description] # 获取上次执行的 SQL 查询的数据 data = cur.fetchall() # 将数据转换为 pandas DataFrame return pd.DataFrame(data, columns=header) # 从 diabetes 表中随机获取 5 行数据 select_sql = "SELECT * FROM diabetes ORDER BY random() LIMIT 5" cur.execute(select_sql) sample = cursor2dataframe(cur) print(sample) |
在上面,我们使用 SQL 的 SELECT 语句查询 diabetes 表,获取 5 行随机数据。结果将以元组列表(每行一个元组)的形式返回。然后,我们通过为每列关联名称,将元组列表转换为 pandas DataFrame。运行上面的代码片段,我们会得到以下输出:
|
1 2 3 4 5 6 |
preg plas pres skin insu mass pedi age class 0 2 90 68 42 0 38.2 0.503 27 tested_positive 1 9 124 70 33 402 35.4 0.282 34 tested_negative 2 7 160 54 32 175 30.5 0.588 39 tested_positive 3 7 105 0 0 0 0.0 0.305 24 tested_negative 4 1 107 68 19 0 26.5 0.165 24 tested_negative |
这是使用 sqlite3 为糖尿病数据集创建、插入和检索关系数据库样本的完整代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import sqlite3 import pandas as pd 从 sklearn.datasets 导入 fetch_openml # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] print("Data from OpenML:") print(type(dataset)) print(dataset.head()) # 创建数据库 conn = sqlite3.connect(":memory:") cur = conn.cursor() create_sql = """ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) """ cur.execute(create_sql) # 使用参数化 SQL 将数据插入表中 insert_sql = "INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)" rows = dataset.to_numpy().tolist() cur.executemany(insert_sql, rows) def cursor2dataframe(cur): """从游标读取列标题,然后读取其中的 数据。之后,创建一个 DataFrame""" header = [x[0] for x in cur.description] # 获取上次执行的 SQL 查询的数据 data = cur.fetchall() # 将数据转换为 pandas DataFrame return pd.DataFrame(data, columns=header) # 从 diabetes 表中随机获取 5 行数据 select_sql = "SELECT * FROM diabetes ORDER BY random() LIMIT 5" cur.execute(select_sql) sample = cursor2dataframe(cur) print("Data from SQLite database:") print(sample) # 关闭数据库连接 conn.commit() conn.close() |
当数据集不是从互联网获取,而是随着时间的推移由您自己收集时,使用数据库的好处就显得尤为突出。例如,您可能在许多天里收集来自传感器的数据。您可能通过一个自动化作业将每小时收集的数据写入数据库。然后,您的机器学习项目可以使用数据库中的数据集运行,并且随着数据的积累,您可能会看到不同的结果。
让我们看看如何将我们的关系数据库构建到机器学习管道中!
SQLite 实操
既然我们已经探讨了如何使用 sqlite3 从关系数据库存储和检索数据,我们可能对如何将其集成到我们的机器学习管道中感兴趣。
通常,在这种情况下,我们将有一个过程来收集数据并将其写入数据库(例如,在许多天内读取传感器数据)。这将类似于上一节中的代码,除了我们更愿意将数据库写入磁盘以进行持久存储。然后,我们将在机器学习过程中从数据库读取数据,用于训练或预测。根据模型,有不同的方法可以使用数据。让我们考虑 Keras 的糖尿病二元分类模型。我们可以构建一个生成器来从数据库中读取随机批次数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def datagen(batch_size): conn = sqlite3.connect("diabetes.db", check_same_thread=False) cur = conn.cursor() sql = f""" SELECT preg, plas, pres, skin, insu, mass, pedi, age, class FROM diabetes ORDER BY random() LIMIT {batch_size} """ while True: cur.execute(sql) data = cur.fetchall() X = [row[:-1] for row in data] y = [1 if row[-1]=="tested_positive" else 0 for row in data] yield np.asarray(X), np.asarray(y) |
上面的代码是一个生成器函数,它从 SQLite 数据库获取 batch_size 行数据,并将它们作为 NumPy 数组返回。我们可以使用此生成器的数据来训练我们的分类网络。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from keras.models import Sequential from keras.layers import Dense # 创建二元分类模型 model = Sequential() model.add(Dense(16, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(datagen(32), epochs=5, steps_per_epoch=2000) |
运行上面的代码会得到以下输出:
|
1 2 3 4 5 6 7 8 9 10 |
第 1/5 周期 2000/2000 [==============================] - 6s 3ms/step - loss: 2.2360 - accuracy: 0.6730 第2/5个周期 2000/2000 [==============================] - 5s 2ms/step - loss: 0.5292 - accuracy: 0.7380 第3/5个周期 2000/2000 [==============================] - 5s 2ms/step - loss: 0.4936 - accuracy: 0.7564 第4/5个周期 2000/2000 [==============================] - 5s 2ms/step - loss: 0.4751 - accuracy: 0.7662 第5/5个周期 2000/2000 [==============================] - 5s 2ms/step - loss: 0.4487 - accuracy: 0.7834 |
请注意,我们在生成器函数中只读取了批次数据,而不是全部数据。我们依赖数据库为我们提供数据,而不必担心数据库中数据集的大小。虽然 SQLite 不是客户端-服务器数据库系统,因此不能扩展到网络,但还有其他数据库系统可以做到这一点。因此,您可以设想使用一个异常大的数据集,而为我们的机器学习应用程序提供的内存量有限。
以下是完整的代码,从准备数据库到使用实时从数据库读取的数据训练 Keras 模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
import sqlite3 import numpy as np from sklearn.datasets import fetch_openml from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 创建数据库 conn = sqlite3.connect("diabetes.db") cur = conn.cursor() cur.execute("DROP TABLE IF EXISTS diabetes") create_sql = """ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) """ cur.execute(create_sql) # 从 OpenML 读取数据,使用参数化 SQL 将数据插入表中 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] insert_sql = "INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)" rows = dataset.to_numpy().tolist() cur.executemany(insert_sql, rows) # 提交以将更改刷新到磁盘,然后关闭连接 conn.commit() conn.close() # 为 Keras 分类器模型创建数据生成器 def datagen(batch_size): """生成器,用于从数据库生成样本 """ # Tensorflow 可能在不同的线程中运行,因此需要 check_same_thread=False conn = sqlite3.connect("diabetes.db", check_same_thread=False) cur = conn.cursor() sql = f""" SELECT preg, plas, pres, skin, insu, mass, pedi, age, class FROM diabetes ORDER BY random() LIMIT {batch_size} """ while True: # 从数据库读取行 cur.execute(sql) data = cur.fetchall() # 提取特征 X = [row[:-1] for row in data] # 提取目标,编码为二元(0 或 1) y = [1 if row[-1]=="tested_positive" else 0 for row in data] yield np.asarray(X), np.asarray(y) # 创建二元分类模型 model = Sequential() model.add(Dense(16, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(datagen(32), epochs=5, steps_per_epoch=2000) |
在继续下一节之前,我们应该强调所有数据库都略有不同。我们使用的 SQL 语句在其他数据库实现中可能不是最优的。此外,请注意 SQLite 并不是非常先进,因为它旨在成为一个不需要服务器设置的数据库。使用大规模数据库以及如何优化使用是一个很大的话题,但这里演示的概念应该仍然适用。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
在 dbm 中管理数据
关系数据库非常适合表格数据,但并非所有数据集都具有表格结构。有时,数据最好存储在 Python 字典这样的结构中,即键值存储。有很多键值数据存储。MongoDB 可能是最知名的,它需要像 PostgreSQL 一样的服务器部署。GNU dbm 就像 SQLite 一样是无服务器存储,并且几乎安装在所有 Linux 系统中。在 Python 的标准库中,我们有 dbm 模块来处理它。
让我们探索 Python 的 dbm 库。该库支持两种不同的 dbm 实现:GNU dbm 和 ndbm。如果系统中没有安装其中任何一个,则 Python 自身有一个实现作为后备。无论底层的 dbm 实现如何,我们在 Python 程序中使用相同的语法。
这次,我们将演示使用 scikit-learn 的 digits 数据集。
|
1 2 3 4 |
import sklearn.datasets # 获取 digits 数据集(8x8 的数字图像) digits = sklearn.datasets.load_digits() |
dbm 库使用类似字典的接口来存储和检索 dbm 文件中的数据,将键映射到值,其中键和值都是字符串。将 digits 数据集存储在 `digits.dbm` 文件中的代码如下:
|
1 2 3 4 5 6 7 |
import dbm import pickle # 如果文件不存在则创建,否则以读/写方式打开 with dbm.open("digits.dbm", "c") as db: for idx in range(len(digits.target)): db[str(idx)] = pickle.dumps((digits.images[idx], digits.target[idx])) |
上面的代码片段会在 `digits.dbm` 文件不存在时创建它。然后,我们选择每个 digits 图像(来自 `digits.images`)和标签(来自 `digits.target`)并创建一个元组。我们将数据偏移量作为键,将元组的 pickled 字符串作为值存储在数据库中。与 Python 的字典不同,dbm 只允许字符串键和序列化值。因此,我们使用 `str(idx)` 将键转换为字符串,并且只存储 pickled 数据。
您可以在我们的上一篇文章中了解更多关于序列化的信息。
以下是如何从数据库中读回数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import random import numpy as np # 我们样本中所需的图像数量 batchsize = 4 images = [] targets = [] # 打开数据库并读取样本 with dbm.open("digits.dbm", "r") as db: # 从数据库获取所有键 keys = db.keys() # 随机采样 n 个键 for key in random.sample(keys, batchsize): # 遍历随机样本中的每个键 image, target = pickle.loads(db[key]) images.append(image) targets.append(target) print(np.asarray(images), np.asarray(targets)) |
在上面的代码片段中,我们从数据库中获取 4 个随机键,然后获取它们相应的值,并使用 pickle.loads() 进行反序列化。如我们所知,反序列化后的数据将是一个元组;我们将它们分配给变量 image 和 target,然后将每个随机样本收集到列表 images 和 targets 中。为了方便在 scikit-learn 或 Keras 中进行训练,我们通常希望整个批次都以 NumPy 数组的形式呈现。
运行上面的代码会得到以下输出:
|
1 2 3 4 5 6 7 8 9 10 |
[[[ 0. 0. 1. 9. 14. 11. 1. 0.] [ 0. 0. 10. 15. 9. 13. 5. 0.] [ 0. 3. 16. 7. 0. 0. 0. 0.] [ 0. 5. 16. 16. 16. 10. 0. 0.] [ 0. 7. 16. 11. 10. 16. 5. 0.] [ 0. 2. 16. 5. 0. 12. 8. 0.] [ 0. 0. 10. 15. 13. 16. 5. 0.] [ 0. 0. 0. 9. 12. 7. 0. 0.]] ... ] [6 8 7 3] |
将所有内容放在一起,这是检索 digits 数据集,然后创建、插入和采样 dbm 数据库的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import dbm import pickle import random import numpy as np import sklearn.datasets # 获取 digits 数据集(8x8 的数字图像) digits = sklearn.datasets.load_digits() # 如果文件不存在则创建,否则以读/写方式打开 with dbm.open("digits.dbm", "c") as db: for idx in range(len(digits.target)): db[str(idx)] = pickle.dumps((digits.images[idx], digits.target[idx])) # 我们样本中所需的图像数量 batchsize = 4 images = [] targets = [] # 打开数据库并读取样本 with dbm.open("digits.dbm", "r") as db: # 从数据库获取所有键 keys = db.keys() # 随机采样 n 个键 for key in random.sample(keys, batchsize): # 遍历随机样本中的每个键 image, target = pickle.loads(db[key]) images.append(image) targets.append(target) print(np.array(images), np.array(targets)) |
接下来,让我们看看如何在机器学习管道中使用我们新创建的 dbm 数据库!
在机器学习管道中使用 dbm 数据库
在这里,您可能会意识到,我们可以像在 SQLite 数据库示例中那样,创建生成器和 Keras 模型来进行数字分类。以下是如何修改代码。首先是我们的生成器函数。我们只需要在一个循环中选择随机键,然后从 dbm 存储中获取数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def datagen(batch_size): """生成器,用于从数据库生成样本 """ with dbm.open("digits.dbm", "r") as db: keys = db.keys() while True: images = [] targets = [] for key in random.sample(keys, batch_size): image, target = pickle.loads(db[key]) images.append(image) targets.append(target) yield np.array(images).reshape(-1,64), np.array(targets) |
然后,我们可以为数据创建一个简单的MLP模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense model = Sequential() model.add(Dense(32, input_dim=64, activation='relu')) model.add(Dense(32, activation='relu')) model.add(Dense(10, activation='softmax')) model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["sparse_categorical_accuracy"]) history = model.fit(datagen(32), epochs=5, steps_per_epoch=1000) |
运行上述代码将得到以下输出
|
1 2 3 4 5 6 7 8 9 10 |
第 1/5 周期 1000/1000 [==============================] - 3s 2ms/step - loss: 0.6714 - sparse_categorical_accuracy: 0.8090 第2/5个周期 1000/1000 [==============================] - 2s 2ms/step - loss: 0.1049 - sparse_categorical_accuracy: 0.9688 第3/5个周期 1000/1000 [==============================] - 2s 2ms/step - loss: 0.0442 - sparse_categorical_accuracy: 0.9875 第4/5个周期 1000/1000 [==============================] - 2s 2ms/step - loss: 0.0484 - sparse_categorical_accuracy: 0.9850 第5/5个周期 1000/1000 [==============================] - 2s 2ms/step - loss: 0.0245 - sparse_categorical_accuracy: 0.9935 |
这就是我们如何使用 dbm 数据库为数字数据集训练 MLP。使用 dbm 训练模型的完整代码在此处:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import dbm import pickle import random import numpy as np import sklearn.datasets from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 获取 digits 数据集(8x8 的数字图像) digits = sklearn.datasets.load_digits() # 如果文件不存在则创建,否则以读/写方式打开 with dbm.open("digits.dbm", "c") as db: for idx in range(len(digits.target)): db[str(idx)] = pickle.dumps((digits.images[idx], digits.target[idx])) # 从数据库检索模型数据 def datagen(batch_size): """生成器,用于从数据库生成样本 """ with dbm.open("digits.dbm", "r") as db: keys = db.keys() while True: images = [] targets = [] for key in random.sample(keys, batch_size): image, target = pickle.loads(db[key]) images.append(image) targets.append(target) yield np.array(images).reshape(-1,64), np.array(targets) # Keras 中的分类模型 model = Sequential() model.add(Dense(32, input_dim=64, activation='relu')) model.add(Dense(32, activation='relu')) model.add(Dense(10, activation='softmax')) model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["sparse_categorical_accuracy"]) # 使用 dbm 存储中的数据进行训练 history = model.fit(datagen(32), epochs=5, steps_per_epoch=1000) |
在像 MongoDB 或 Couchbase 这样的更高级的系统中,我们可以简单地要求数据库系统为我们读取随机记录,而不是从所有键的列表中选择随机样本。但理念仍然是相同的;我们可以依赖外部存储来保存我们的数据并管理我们的数据集,而不是在我们的 Python 脚本中这样做。
在 Excel 中管理数据
有时,内存并不是我们将数据放在机器学习脚本之外的原因。这是因为有更好的工具来处理数据。也许我们想使用工具在屏幕上显示所有数据并允许我们滚动,并进行格式化和突出显示等。或者我们想与不关心我们 Python 程序的其他人共享数据。在可以使用关系数据库的情况下,人们使用 Excel 来管理数据的情况相当普遍。虽然 Excel 可以读取和导出 CSV 文件,但很可能我们希望直接处理 Excel 文件。
在 Python 中,有几个库可以处理 Excel 文件,OpenPyXL 是其中最著名的之一。在使用它之前,我们需要安装这个库
|
1 |
pip install openpyxl |
如今,Excel 使用“Open XML Spreadsheet”格式,文件名以 .xlsx 结尾。较旧的 Excel 文件是二进制格式,文件名后缀为 .xls,OpenPyXL 不支持(您可以在其中使用 xlrd 和 xlwt 模块进行读写)。
让我们考虑上面 SQLite 示例的相同情况。我们可以打开一个新的 Excel 工作簿并将我们的糖尿病数据集作为工作表写入
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd from sklearn.datasets import fetch_openml import openpyxl # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] header = list(dataset.columns) data = dataset.to_numpy().tolist() # 创建 Excel 工作簿并将数据写入默认工作表 wb = openpyxl.Workbook() sheet = wb.active # 使用默认工作表 sheet.title = "Diabetes" for n,colname in enumerate(header): sheet.cell(row=1, column=1+n, value=colname) for n,row in enumerate(data): for m,cell in enumerate(row): sheet.cell(row=2+n, column=1+m, value=cell) # 保存 wb.save("MLM.xlsx") |
上面的代码是为了准备工作表中每个单元格(由行和列指定)的数据。当我们创建一个新的 Excel 文件时,默认会有一个工作表。然后单元格由行和列偏移量标识,从 1 开始。我们使用以下语法写入单元格
|
1 |
sheet.cell(row=3, column=4, value="my data") |
要从单元格读取,我们使用
|
1 |
sheet.cell(row=3, column=4).value |
逐个单元格写入 Excel 数据很繁琐,实际上我们可以逐行添加数据。以下是我们如何修改上述代码以按行而不是按单元格操作
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd from sklearn.datasets import fetch_openml import openpyxl # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] header = list(dataset.columns) data = dataset.to_numpy().tolist() # 创建 Excel 工作簿并将数据写入默认工作表 wb = openpyxl.Workbook() sheet = wb.create_sheet("Diabetes") # 或者 wb.active 用于默认工作表 sheet.append(header) for row in data: sheet.append(row) # 保存 wb.save("MLM.xlsx") |
将数据写入文件后,我们可以使用 Excel 可视化浏览数据、添加格式等: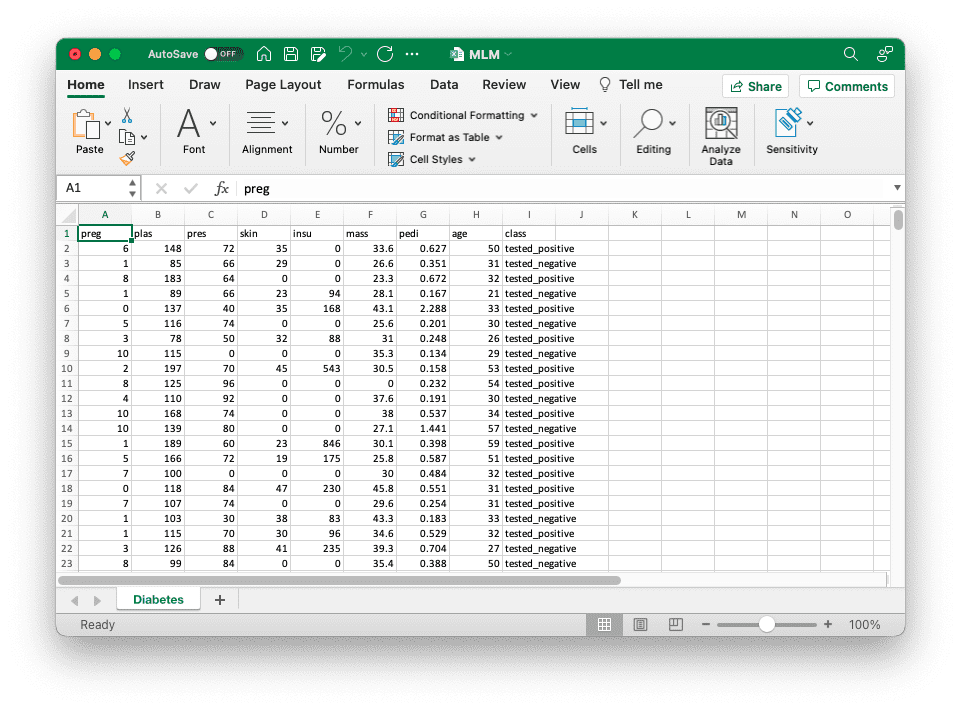
将其用于机器学习项目并不比使用 SQLite 数据库更难。以下是 Keras 中的相同二元分类模型,但生成器正在从 Excel 文件读取
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import random import numpy as np import openpyxl from sklearn.datasets import fetch_openml from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 从 OpenML 读取数据 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] header = list(dataset.columns) rows = dataset.to_numpy().tolist() # 创建 Excel 工作簿并将数据写入默认工作表 wb = openpyxl.Workbook() sheet = wb.active sheet.title = "Diabetes" sheet.append(header) for row in rows: sheet.append(row) # 保存 wb.save("MLM.xlsx") # 为 Keras 分类器模型创建数据生成器 def datagen(batch_size): """生成器,用于从数据库生成样本 """ wb = openpyxl.load_workbook("MLM.xlsx", read_only=True) sheet = wb.active maxrow = sheet.max_row while True: # 从 Excel 文件读取行 X = [] y = [] for _ in range(batch_size): # 数据从第 2 行开始 row_num = random.randint(2, maxrow) rowdata = [cell.value for cell in sheet[row_num]] X.append(rowdata[:-1]) y.append(1 if rowdata[-1]=="tested_positive" else 0) yield np.asarray(X), np.asarray(y) # 创建二元分类模型 model = Sequential() model.add(Dense(16, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(datagen(32), epochs=5, steps_per_epoch=20) |
在上面,我们特意将 steps_per_epoch=20 的参数传递给 fit() 函数,因为上面的代码会非常慢。这是因为 OpenPyXL 是用 Python 实现的,以最大化兼容性,但它牺牲了编译模块可以提供的速度。因此,最好避免每次都从 Excel 读取数据行。如果我们确实需要使用 Excel,更好的选择是将所有数据一次性读入内存,然后直接使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import random import numpy as np import openpyxl from sklearn.datasets import fetch_openml from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # 从 OpenML 读取数据 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] header = list(dataset.columns) rows = dataset.to_numpy().tolist() # 创建 Excel 工作簿并将数据写入默认工作表 wb = openpyxl.Workbook() sheet = wb.active sheet.title = "Diabetes" sheet.append(header) for row in rows: sheet.append(row) # 保存 wb.save("MLM.xlsx") # 从 Excel 文件读取整个工作表 wb = openpyxl.load_workbook("MLM.xlsx", read_only=True) sheet = wb.active X = [] y = [] for i, row in enumerate(sheet.rows): if i==0: continue # 跳过标题行 rowdata = [cell.value for cell in row] X.append(rowdata[:-1]) y.append(1 if rowdata[-1]=="tested_positive" else 0) X, y = np.asarray(X), np.asarray(y) # 创建二元分类模型 model = Sequential() model.add(Dense(16, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(X, y, epochs=5) |
在 Google 表格中管理数据
除了 Excel 工作簿之外,有时我们可能会发现 Google 表格更方便处理数据,因为它“在云端”。我们也可以通过类似于 Excel 的逻辑来管理 Google 表格中的数据。但首先,我们需要安装一些模块,然后才能在 Python 中访问它
|
1 |
pip install google-api-python-client google-auth-httplib2 google-auth-oauthlib |
假设您有一个 Gmail 帐户,并且您创建了一个 Google 表格。您在地址栏中看到的 URL,在 /edit 部分之前,告诉您表格的 ID,我们稍后将使用此 ID
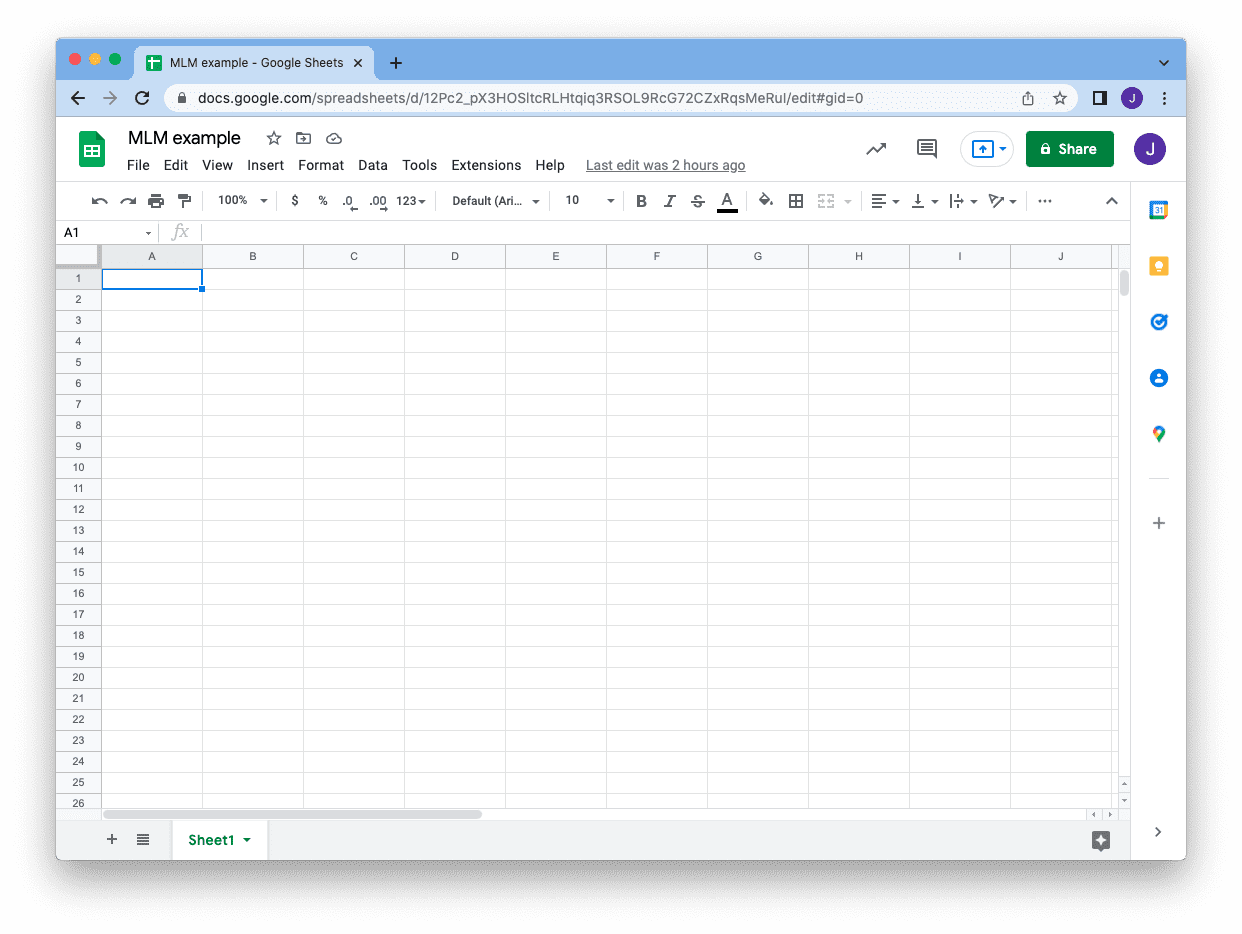
要从 Python 程序访问此表格,最好为您的代码创建一个 **服务帐户**。这是一个机器可操作的帐户,它使用密钥进行身份验证,但可以由帐户所有者管理。您可以控制此服务帐户可以做什么以及何时过期。由于服务帐户独立于您的 Gmail 帐户,您也可以随时撤销它。
要创建服务帐户,首先,您需要转到 Google 开发人员控制台,https://console.developers.google.com,然后单击“创建项目”按钮创建一个项目
您需要提供一个名称,然后可以单击“创建”
它会将您带回控制台,但您的项目名称将显示在搜索框旁边。下一步是单击搜索框下方的“启用 API 和服务”以启用 API
由于我们将创建一个服务帐户来使用 Google 表格,因此我们在搜索框中搜索“sheets”
然后单击 Google Sheets API
并启用它
之后,我们将被送回控制台主屏幕,我们可以单击右上角的“创建凭据”来创建服务帐户
有不同类型的凭据,我们选择“服务帐户”
我们需要提供一个名称(供我们参考)、一个帐户 ID(作为项目的唯一标识符)和一个描述。在“服务帐户 ID”框下方显示的电子邮件就是此服务帐户的电子邮件。复制它,我们稍后将其添加到我们的 Google 表格中。在我们创建完所有这些之后,我们可以跳过其余部分,然后单击“完成”
完成后,我们将返回到控制台主屏幕,如果我们在“服务帐户”部分下看到它,就表明服务帐户已创建
接下来,我们需要单击帐户右侧的铅笔图标,这将带我们到以下屏幕
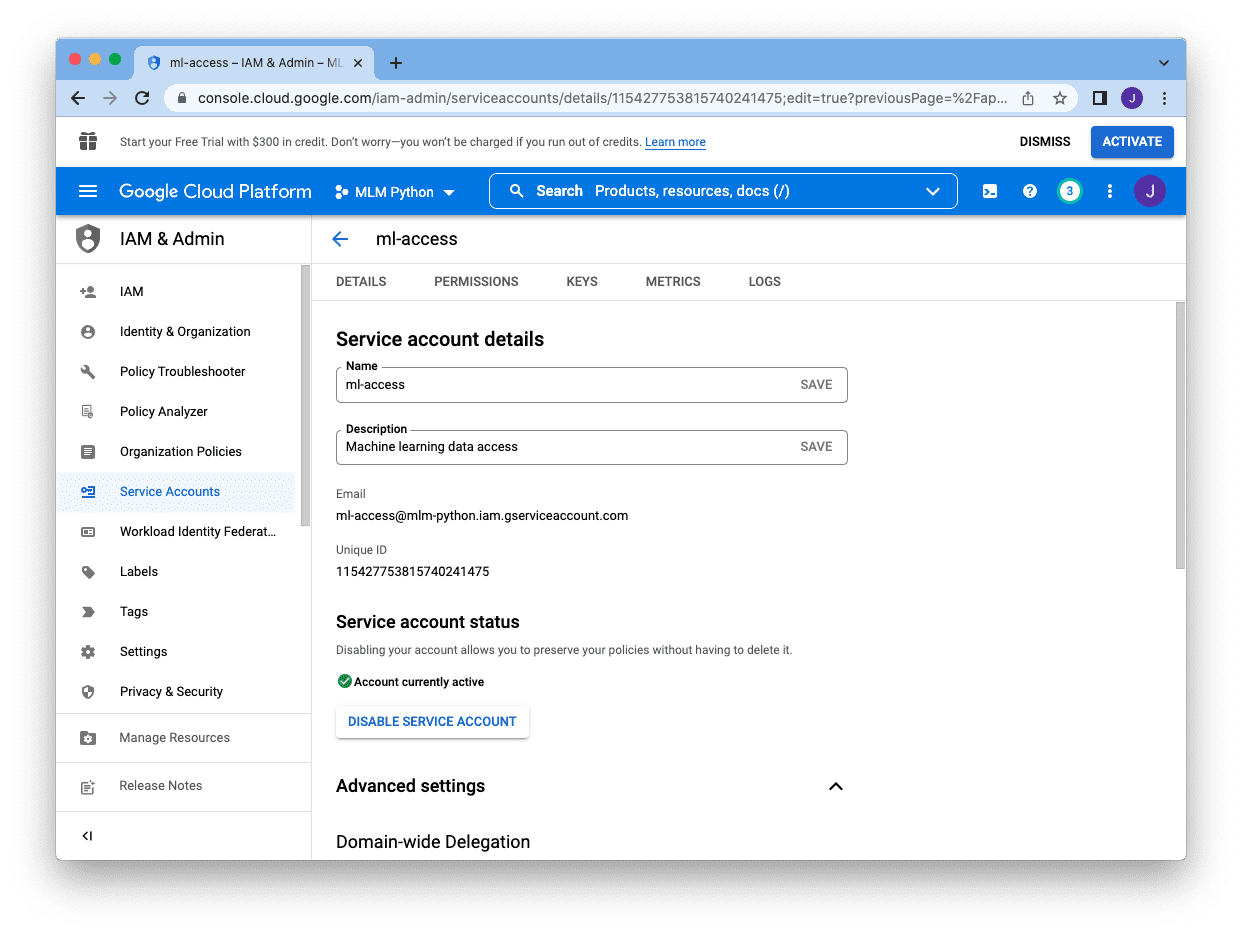
而不是密码,我们需要为该帐户创建一个密钥。我们单击顶部的“密钥”页面,然后单击“添加密钥”并选择“创建新密钥”
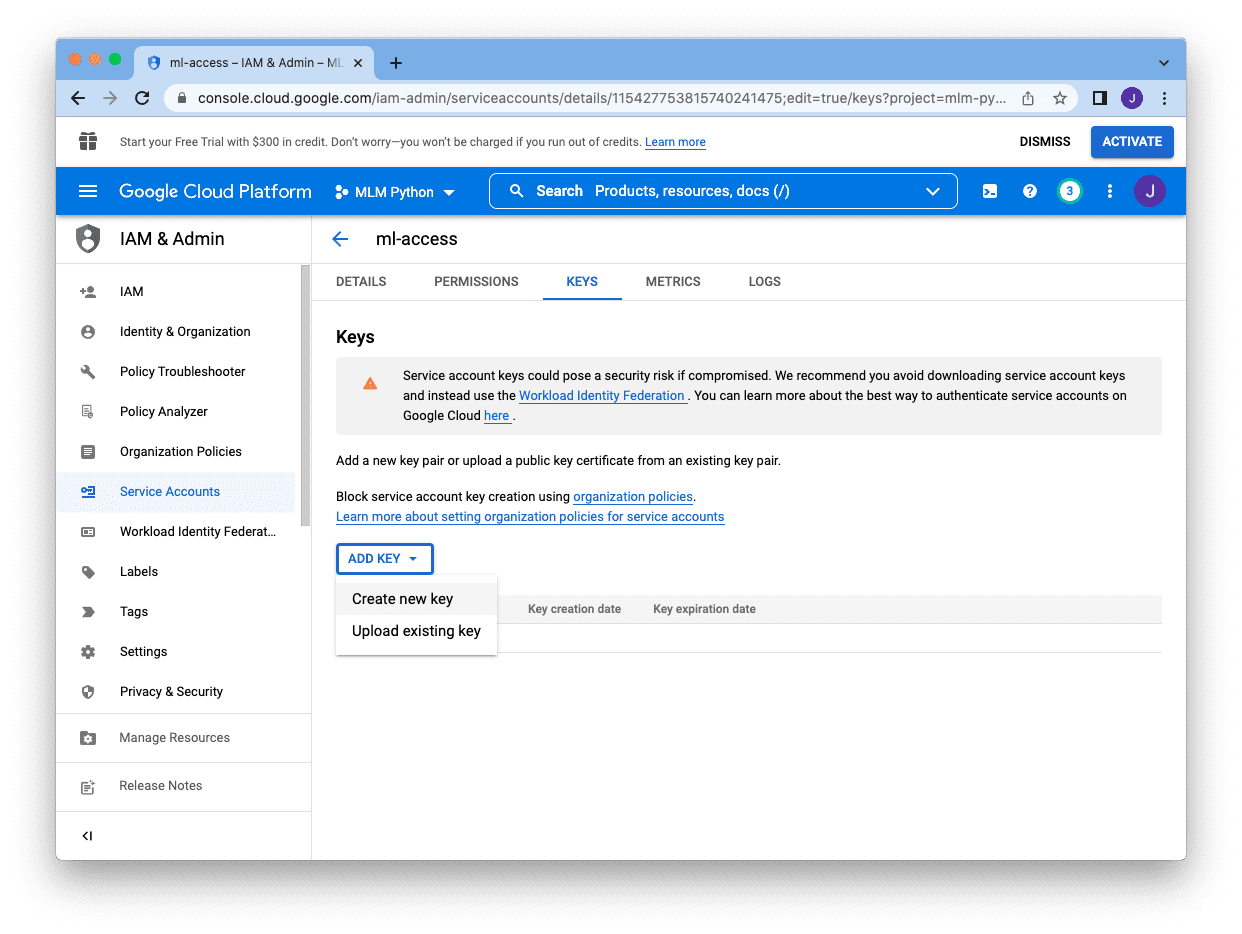
密钥有两种不同的格式,JSON 是首选格式。选择 JSON 并单击底部的“创建”将在 JSON 文件中下载密钥
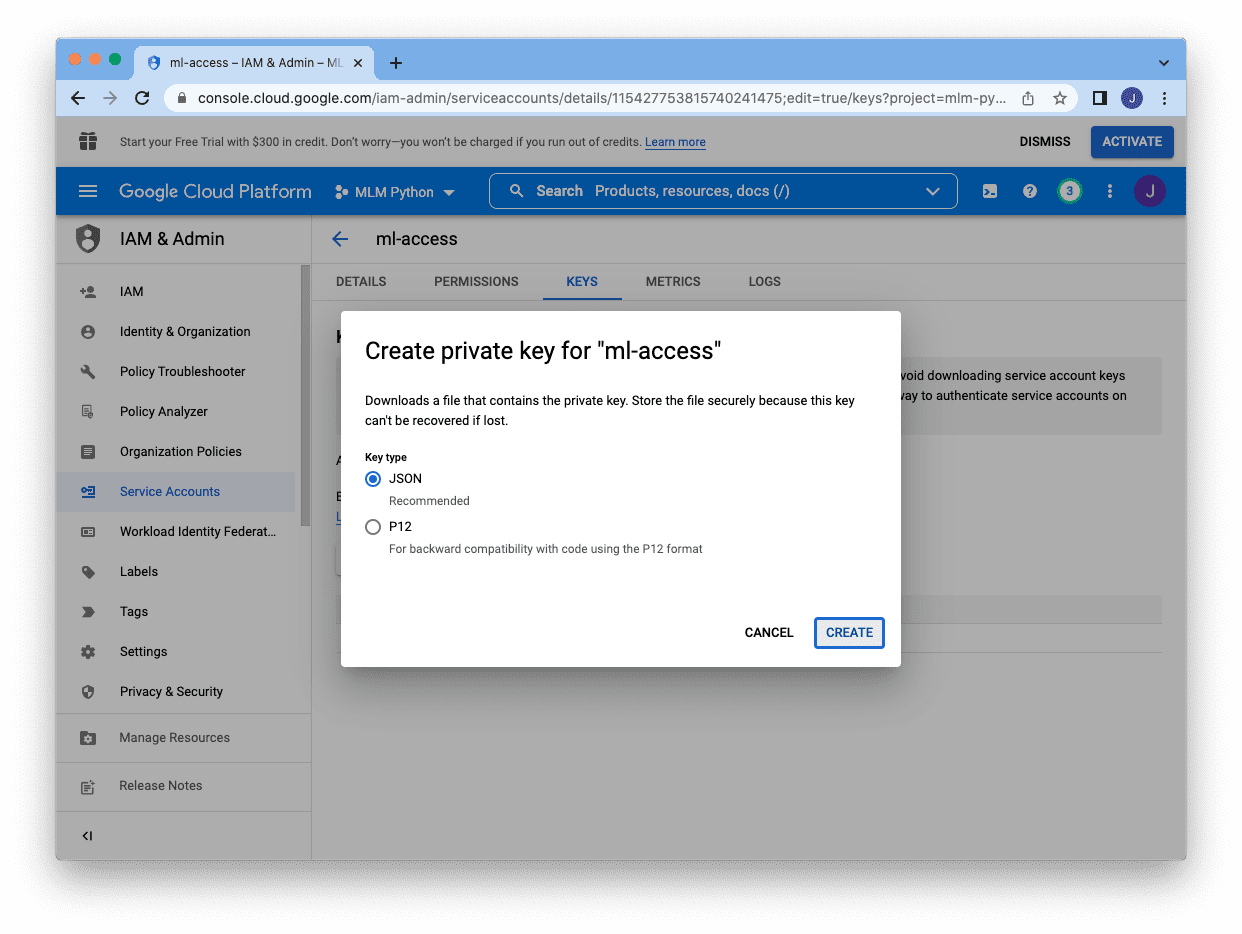
JSON 文件将如下所示
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "type": "service_account", "project_id": "mlm-python", "private_key_id": "3863a6254774259a1249", "private_key": "-----BEGIN PRIVATE KEY-----\n MIIEvgIBADANBgkqh... -----END PRIVATE KEY-----\n", "client_email": "ml-access@mlm-python.iam.gserviceaccount.com", "client_id": "11542775381574", "auth_uri": "https://#/o/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/ml-access%40mlm-python.iam.gserviceaccount.com" } |
保存 JSON 文件后,我们就可以返回到我们的 Google 表格,并将表格与我们的服务帐户共享。单击右上角的“共享”按钮,然后输入服务帐户的电子邮件地址。您可以跳过通知,只需单击“共享”。然后我们就准备好了!
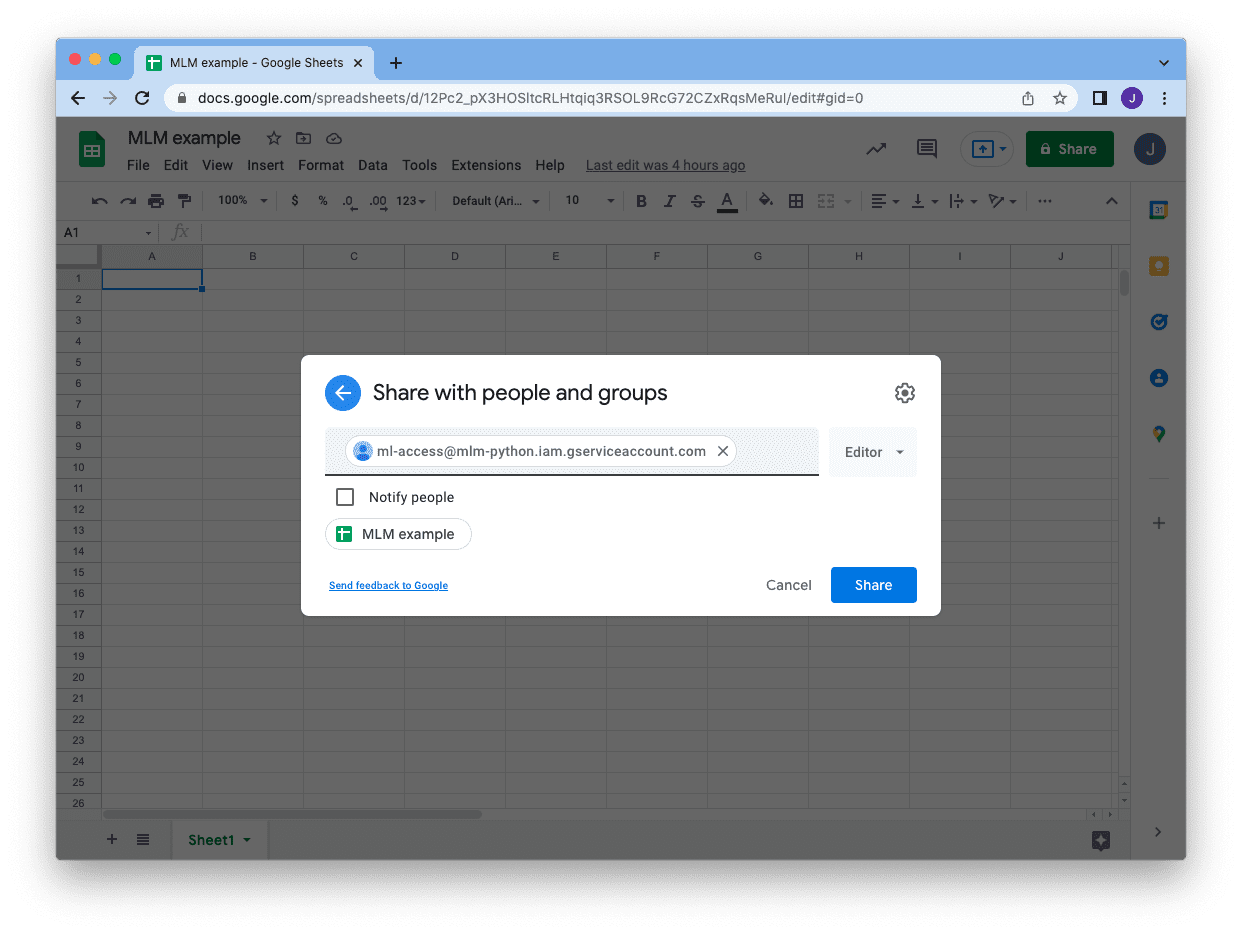
此时,我们就可以从 Python 程序中使用服务帐户访问这个特定的 Google 表格了。要写入 Google 表格,我们可以使用 Google 的 API。我们首先依赖于我们刚才下载的服务帐户的 JSON 文件(在本例中为 mlm-python.json)来建立连接
|
1 2 3 4 5 6 7 8 9 |
from oauth2client.service_account import ServiceAccountCredentials from googleapiclient.discovery import build from httplib2 import Http cred_file = "mlm-python.json" scopes = ['https://www.googleapis.com/auth/spreadsheets'] cred = ServiceAccountCredentials.from_json_keyfile_name(cred_file, scopes) service = build("sheets", "v4", http=cred.authorize(Http())) sheet = service.spreadsheets() |
如果我们刚刚创建它,文件中应该只有一个工作表,其 ID 为 0。所有使用 Google API 的操作都是 JSON 格式的。例如,以下是我们如何删除整个工作表中的所有内容,使用我们刚刚创建的连接
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... sheet_id = '12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul' body = { "requests": [{ "deleteRange": { "range": { "sheetId": 0 }, "shiftDimension": "ROWS" } }] } action = sheet.batchUpdate(spreadsheetId=sheet_id, body=body) action.execute() |
假设我们像第一个示例一样,将糖尿病数据集读入一个 DataFrame。然后,我们可以一次性将整个数据集写入 Google 表格。为此,我们需要创建一个列表的列表,以反映表格单元格的二维数组结构,然后将数据放入 API 查询中。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... 行 = [list(数据集.columns)] 行 += 数据集.to_numpy().tolist() 最大列 = max(len(行) for 行 in 行) 最大列 = chr(ord("A") - 1 + 最大列) 动作 = 表格.values().append( spreadsheetId = sheet_id, body = {"values": 行}, valueInputOption = "RAW", range = "Sheet1!A1:%s" % maxcol ) action.execute() |
在上面,我们假设工作表名为“Sheet1”(如屏幕底部所示的默认名称)。我们将数据从左上角开始对齐,从单元格 A1(左上角)开始填充。我们使用 dataset.to_numpy().tolist() 将所有数据收集到列表中,但我们在开头添加了列标题作为额外的行。
从 Google 表格中读取数据也很类似。以下是我们如何读取随机一行数据的方法。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 检查工作表 sheet_properties = 表格.get(spreadsheetId=sheet_id).execute()["sheets"] print(sheet_properties) # 读回 最大行 = sheet_properties[0]["properties"]["gridProperties"]["rowCount"] 最大列 = sheet_properties[0]["properties"]["gridProperties"]["columnCount"] 最大列 = chr(ord("A") - 1 + 最大列) 行 = random.randint(1, 最大行) readrange = f"A{row}:{maxcol}{row}" data = 表格.values().get(spreadsheetId=sheet_id, range=readrange).execute() |
首先,我们可以通过检查其属性来确定工作表中有多少行。上面的 print() 语句将产生以下输出:
|
1 2 |
[{'properties': {'sheetId': 0, 'title': 'Sheet1', 'index': 0, 'sheetType': 'GRID', 'gridProperties': {'rowCount': 769, 'columnCount': 9}}}] |
由于我们只有一个工作表,列表只包含一个属性字典。使用此信息,我们可以选择一个随机行并指定要读取的范围。上面的 data 变量将是一个类似的字典,数据将以列表的列表形式存在,并且可以通过 data["values"] 访问。
|
1 2 3 4 5 6 7 8 9 10 11 |
{'range': 'Sheet1!A536:I536', 'majorDimension': 'ROWS', 'values': [['1', '77', '56', '30', '56', '33.3', '1.251', '24', 'tested_negative']]} |
将所有这些结合起来,以下是将数据加载到 Google 表格并从中读取随机行数据的完整代码:(运行它时请务必更改 sheet_id)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
import random from googleapiclient.discovery import build from httplib2 import Http from oauth2client.service_account import ServiceAccountCredentials 从 sklearn.datasets 导入 fetch_openml # 连接到 Google 表格 cred_file = "mlm-python.json" scopes = ['https://www.googleapis.com/auth/spreadsheets'] cred = ServiceAccountCredentials.from_json_keyfile_name(cred_file, scopes) service = build("sheets", "v4", http=cred.authorize(Http())) sheet = service.spreadsheets() # Google 表格 ID,已授予服务帐户访问权限 sheet_id = '12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul' # 删除电子表格 0 上的所有内容 body = { "requests": [{ "deleteRange": { "range": { "sheetId": 0 }, "shiftDimension": "ROWS" } }] } action = sheet.batchUpdate(spreadsheetId=sheet_id, body=body) action.execute() # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] 行 = [list(数据集.columns)] # 列标题 行 += 数据集.to_numpy().tolist() # 数据行 # 写入电子表格 0 最大列 = max(len(行) for 行 in 行) 最大列 = chr(ord("A") - 1 + 最大列) 动作 = 表格.values().append( spreadsheetId = sheet_id, body = {"values": 行}, valueInputOption = "RAW", range = "Sheet1!A1:%s" % maxcol ) action.execute() # 检查工作表 sheet_properties = 表格.get(spreadsheetId=sheet_id).execute()["sheets"] print(sheet_properties) # 读取随机一行数据 最大行 = sheet_properties[0]["properties"]["gridProperties"]["rowCount"] 最大列 = sheet_properties[0]["properties"]["gridProperties"]["columnCount"] 最大列 = chr(ord("A") - 1 + 最大列) 行 = random.randint(1, 最大行) readrange = f"A{row}:{maxcol}{row}" data = 表格.values().get(spreadsheetId=sheet_id, range=readrange).execute() print(data) |
不可否认,以这种方式访问 Google 表格过于冗长。因此,我们有一个第三方模块 gspread 来简化操作。安装该模块后,我们可以像下面这样简单地检查电子表格的大小。
|
1 2 3 4 5 6 7 |
import gspread cred_file = "mlm-python.json" gc = gspread.service_account(filename=cred_file) 表格 = gc.open_by_key(sheet_id) spreadsheet = 表格.get_worksheet(0) print(spreadsheet.row_count, spreadsheet.col_count) |
清除工作表、向其中写入行以及读取随机行可以按以下方式完成。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 清除所有数据 spreadsheet.clear() # 写入电子表格 spreadsheet.append_rows(行) # 读取随机一行数据 最大列 = chr(ord("A") - 1 + spreadsheet.col_count) 行 = random.randint(2, spreadsheet.row_count) readrange = f"A{row}:{maxcol}{row}" data = spreadsheet.get(readrange) print(data) |
因此,前面的示例可以简化为以下更短的版本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import random import gspread 从 sklearn.datasets 导入 fetch_openml # Google 表格 ID,已授予服务帐户访问权限 sheet_id = '12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul' # 连接到 Google 表格 cred_file = "mlm-python.json" gc = gspread.service_account(filename=cred_file) 表格 = gc.open_by_key(sheet_id) spreadsheet = 表格.get_worksheet(0) # 清除所有数据 spreadsheet.clear() # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] 行 = [list(数据集.columns)] # 列标题 行 += 数据集.to_numpy().tolist() # 数据行 # 写入电子表格 spreadsheet.append_rows(行) # 检查电子表格中的行数和列数 print(spreadsheet.row_count, spreadsheet.col_count) # 读取随机一行数据 最大列 = chr(ord("A") - 1 + spreadsheet.col_count) 行 = random.randint(2, spreadsheet.row_count) readrange = f"A{row}:{maxcol}{row}" data = spreadsheet.get(readrange) print(data) |
与读取 Excel 类似,使用存储在 Google 表格中的数据集,最好一次性读取,而不是在训练循环中逐行读取。这是因为每次读取时,您都会发送一个网络请求并等待 Google 服务器的回复。这不可能很快,因此最好避免。以下是如何将来自 Google 表格的数据与 Keras 代码结合进行训练的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import random import numpy as np import gspread from sklearn.datasets import fetch_openml from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense # Google 表格 ID,已授予服务帐户访问权限 sheet_id = '12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul' # 连接到 Google 表格 cred_file = "mlm-python.json" gc = gspread.service_account(filename=cred_file) 表格 = gc.open_by_key(sheet_id) spreadsheet = 表格.get_worksheet(0) # 清除所有数据 spreadsheet.clear() # 从 OpenML 读取数据集 dataset = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"] 行 = [list(数据集.columns)] # 列标题 行 += 数据集.to_numpy().tolist() # 数据行 # 写入电子表格 spreadsheet.append_rows(行) # 读取整个电子表格,不包括标题 最大行 = spreadsheet.row_count 最大列 = chr(ord("A") - 1 + spreadsheet.col_count) data = spreadsheet.get(f"A2:{maxcol}{maxrow}") X = [row[:-1] for row in data] y = [1 if row[-1]=="tested_positive" else 0 for row in data] X, y = np.asarray(X).astype(float), np.asarray(y) # 创建二元分类模型 model = Sequential() model.add(Dense(16, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 训练模型 history = model.fit(X, y, epochs=5) |
数据库的其他用途
前面的示例向您展示了如何从电子表格访问数据库。我们假设数据集存储在训练循环中并由机器学习模型使用。虽然这是使用外部数据存储的一种方式,但并非唯一的方式。数据库的其他一些用途可能包括:
- 作为日志存储,以记录程序的详细信息,例如脚本在何时执行。当脚本会修改某些内容时,例如下载某个文件并覆盖旧版本,这对于跟踪更改特别有用。
- 作为数据收集工具。就像我们可以使用 scikit-learn 的
GridSearchCV一样,我们经常希望使用不同的超参数组合来评估模型性能。如果模型很大且复杂,我们可能希望将评估分发到不同的机器并收集结果。将几行代码添加到程序末尾,将交叉验证结果写入数据库或电子表格会很方便,这样我们就可以根据选定的超参数来制表结果。将这些数据存储在结构化格式中,可以让我们稍后报告结论。 - 作为模型配置工具。除了写入超参数组合和验证分数外,我们还可以使用它作为一种工具,为运行程序提供超参数选择。如果我们决定更改参数,只需打开一个 Google 表格(例如)即可进行更改,而无需修改代码。
进一步阅读
以下是一些您可以深入了解的资源:
书籍
- Practical SQL,第二版,作者:Anthony DeBarros
- SQL Cookbook,第二版,作者:Anthony Molinaro 和 Robert de Graaf
- Automate the Boring Stuff with Python,第二版,作者:Al Sweigart
API 和库
文章
软件
总结
在本教程中,您了解了如何使用外部数据存储,包括数据库或电子表格。
具体来说,你学到了:
- 如何让您的 Python 程序使用 SQL 语句访问如 SQLite 这样的关系数据库。
- 如何使用 dbm 作为键值存储,并像 Python 字典一样使用它。
- 如何读取 Excel 文件并写入其中。
- 如何通过 Internet 访问 Google 表格。
- 我们如何利用所有这些来托管数据集并在我们的机器学习项目中使用它们。
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






暂无评论。